Paso 1. Clonación de un repositorio de código y creación de un proceso
Consulte el repositorio de GitHub para ver el código de ejemplo de esta sección. También puede usar el código del repositorio como plantilla con la que crear sus propias aplicaciones de inteligencia artificial.
Siga estos pasos para cargar el código de ejemplo en el área de trabajo de Databricks y configurar las opciones globales de la aplicación.
Requisitos
- Un área de trabajo de Azure Databricks con un proceso sin servidor y Unity Catalog habilitado.
- Un punto de conexión de vector de búsqueda de Mosaic AI existente o permisos para crear un punto de conexión de vector de búsqueda (el cuaderno de configuración crea uno automáticamente en este caso).
- Acceso de escritura a un esquema de Unity Catalog existente donde se almacenan las tablas Delta de salida que incluyen los documentos analizados y fragmentados y los índices del vector de búsqueda, o bien los permisos para crear un catálogo y un esquema (el cuaderno de configuración los crea automáticamente en este caso).
- Un único clúster de usuario que ejecute DBR 14.3 o superior que tenga acceso a Internet. Se requiere acceso a Internet para descargar los paquetes necesarios de Python y del sistema. No use un clúster que ejecute Databricks Runtime para Machine Learning, ya que estos tutoriales tienen conflictos de paquetes de Python con Databricks Runtime ML.
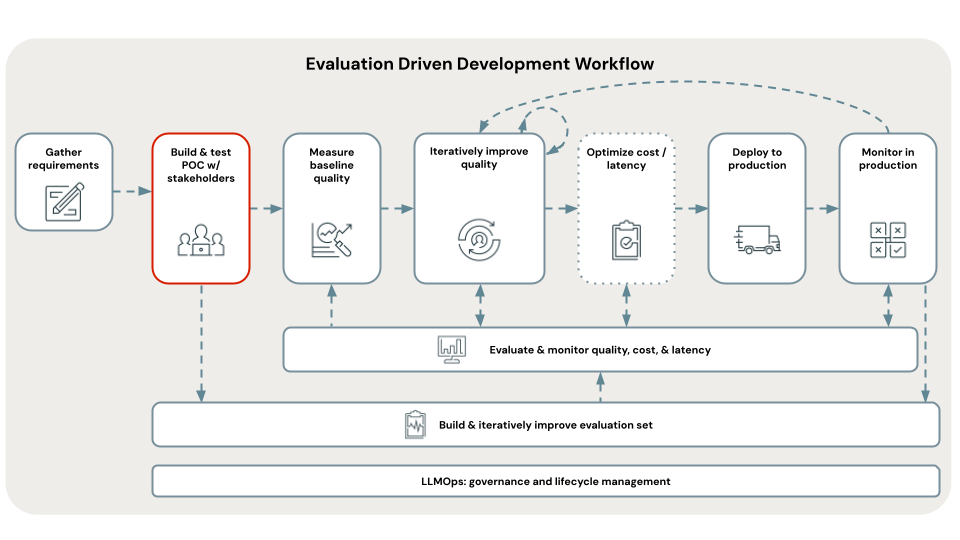
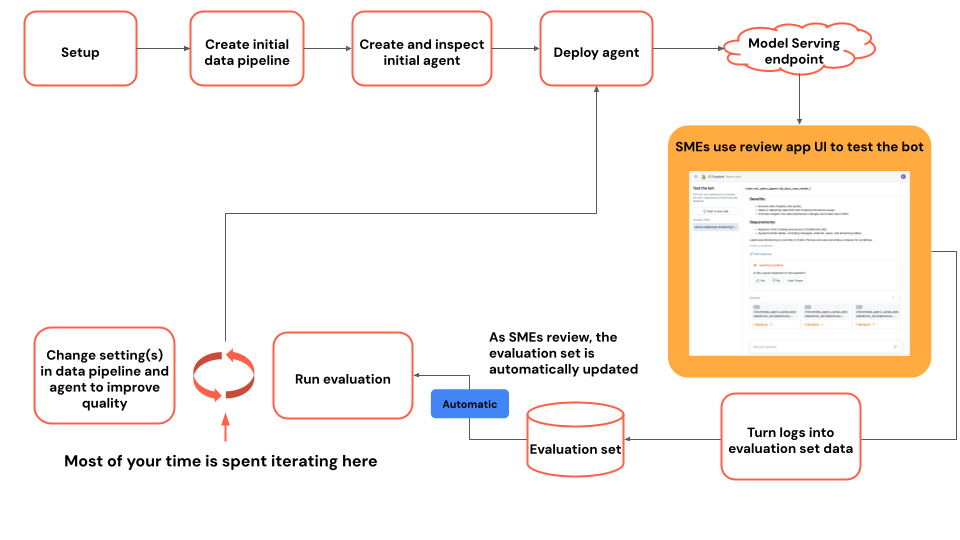
Diagrama de flujo del tutorial
En el diagrama se muestra el flujo de pasos que se usan en este tutorial.
Instrucciones
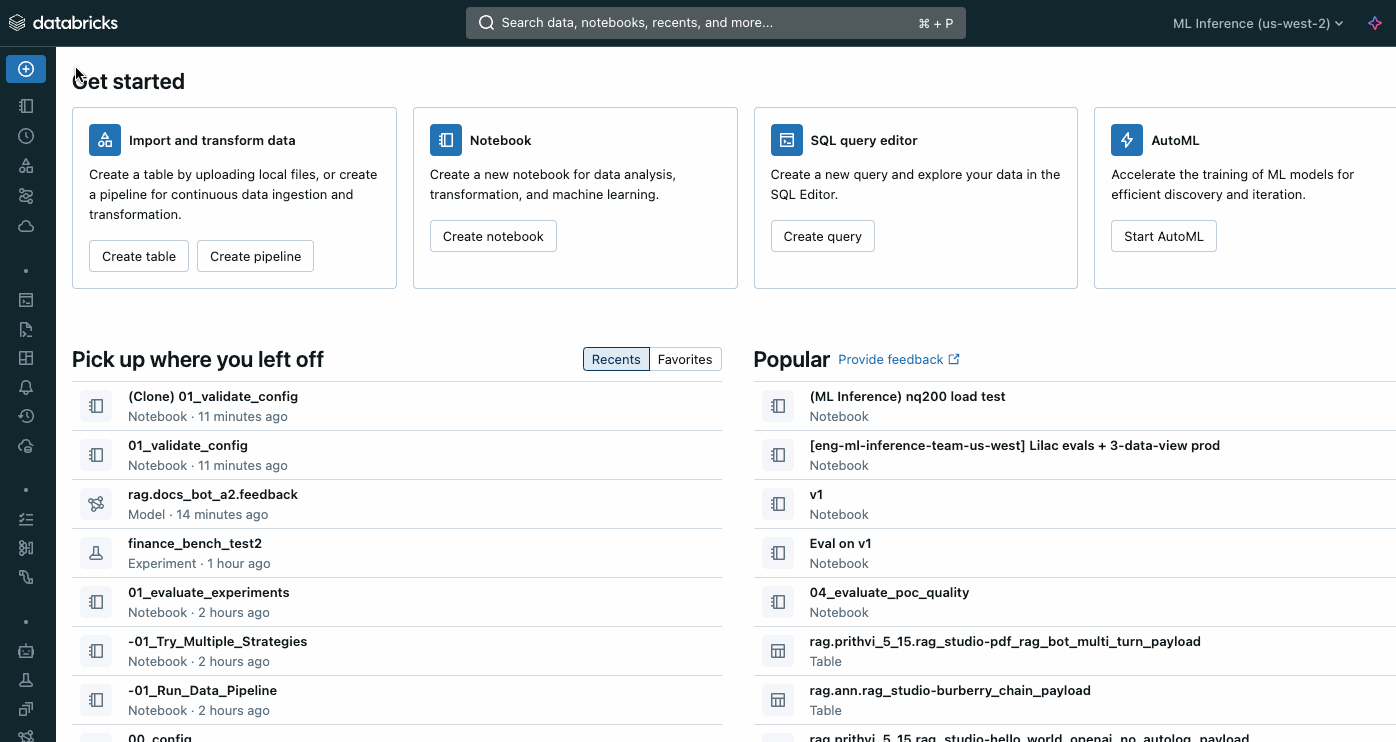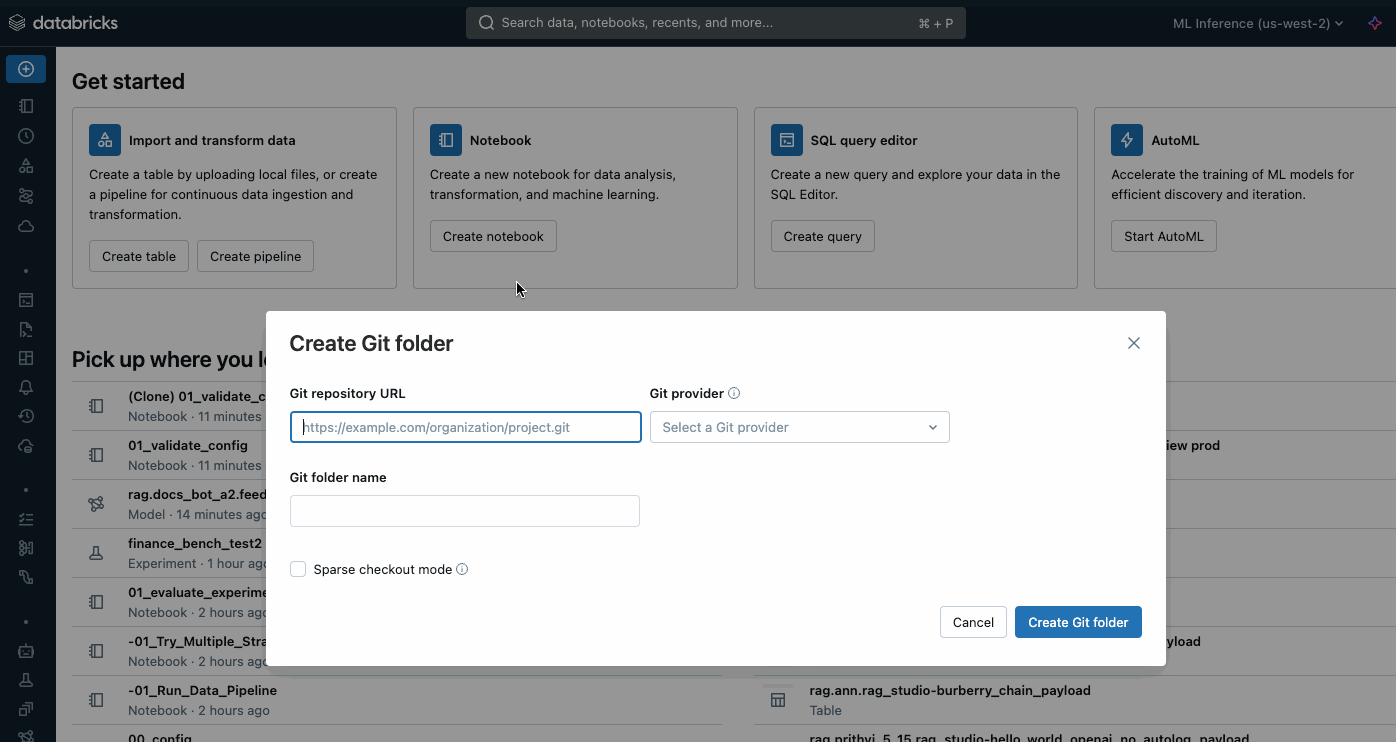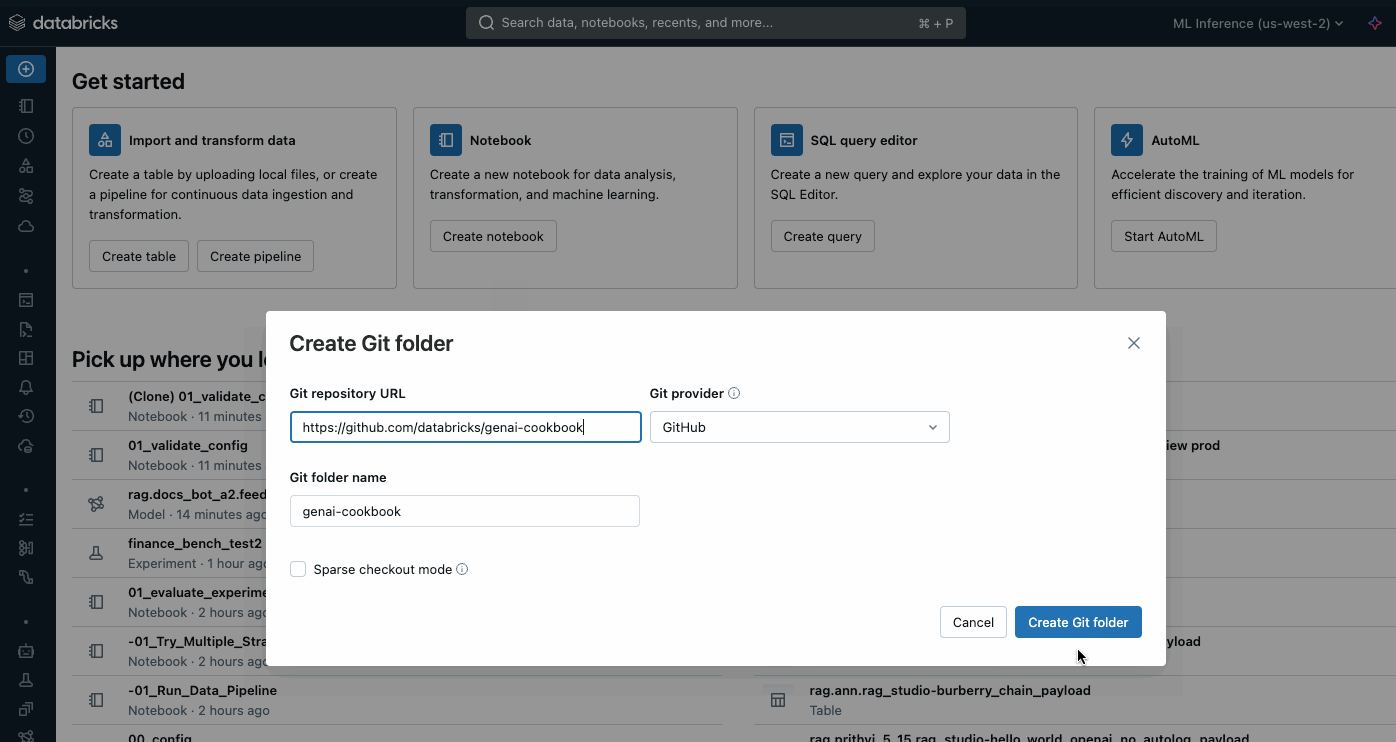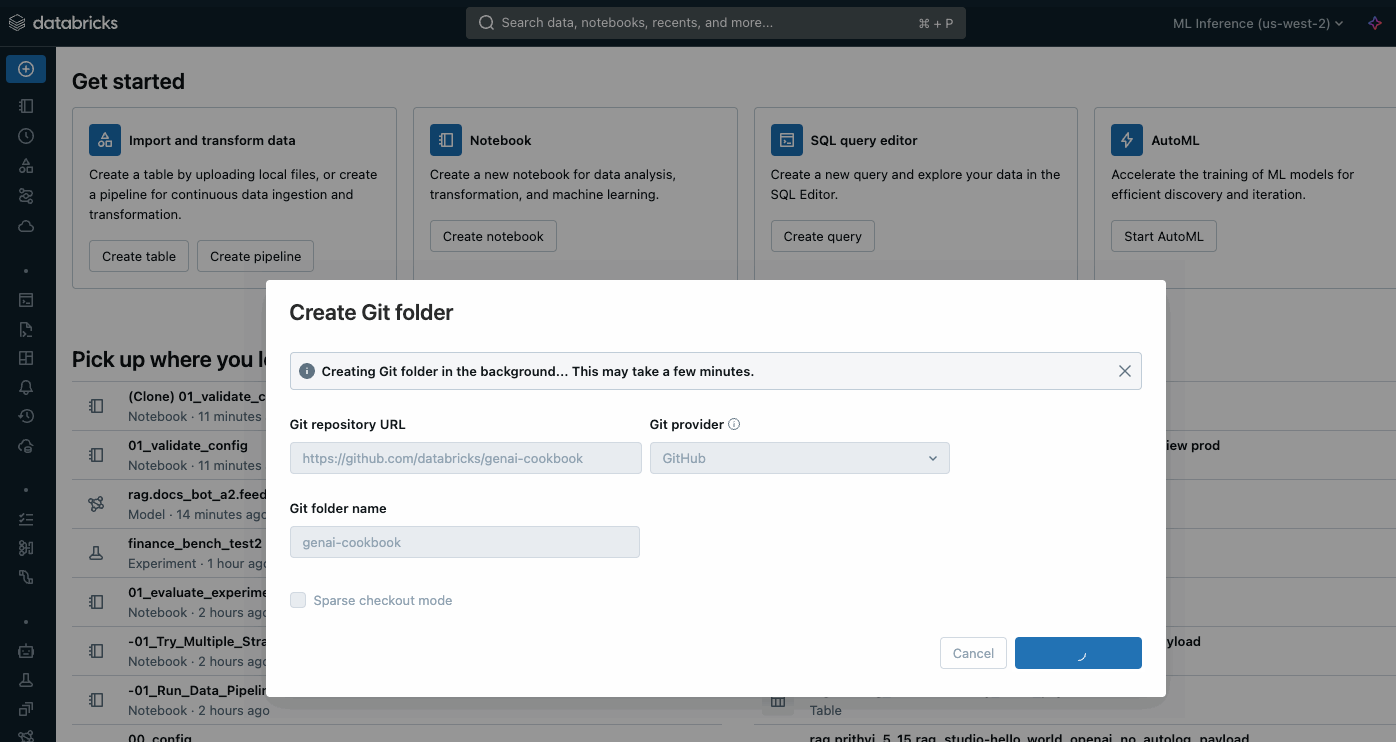
Clone este repositorio en el área de trabajo mediante carpetas de Git.
Abra el cuaderno rag_app_sample_code/00_global_config y ajuste la configuración allí.
# The name of the RAG application. This is used to name the chain's model in Unity Catalog and prepended to the output Delta tables and vector indexes RAG_APP_NAME = 'my_agent_app' # Unity Catalog catalog and schema where outputs tables and indexes are saved # If this catalog/schema does not exist, you need create catalog/schema permissions. UC_CATALOG = f'{user_name}_catalog' UC_SCHEMA = f'rag_{user_name}' ## Name of model in Unity Catalog where the POC chain is logged UC_MODEL_NAME = f"{UC_CATALOG}.{UC_SCHEMA}.{RAG_APP_NAME}" # Vector Search endpoint where index is loaded # If this does not exist, it will be created VECTOR_SEARCH_ENDPOINT = f'{user_name}_vector_search' # Source location for documents # You need to create this location and add files SOURCE_PATH = f"/Volumes/{UC_CATALOG}/{UC_SCHEMA}/source_docs"Abra y ejecute el cuaderno 01_validate_config_and_create_resources.
Paso siguiente
Continúe con Implementación de POC.
< Anterior: Requisitos previos
Siguiente: Paso 2. Implementación de POC y recopilación de comentarios >