Cadena RAG para la inferencia
En este artículo se describe el proceso que se produce cuando el usuario envía una solicitud a la aplicación RAG en un entorno en línea. Una vez que la canalización de datos ha procesado los datos, son adecuados para su uso en la aplicación RAG. La serie o la cadena de pasos que se invocan en el momento de la inferencia se conoce normalmente como la cadena RAG.
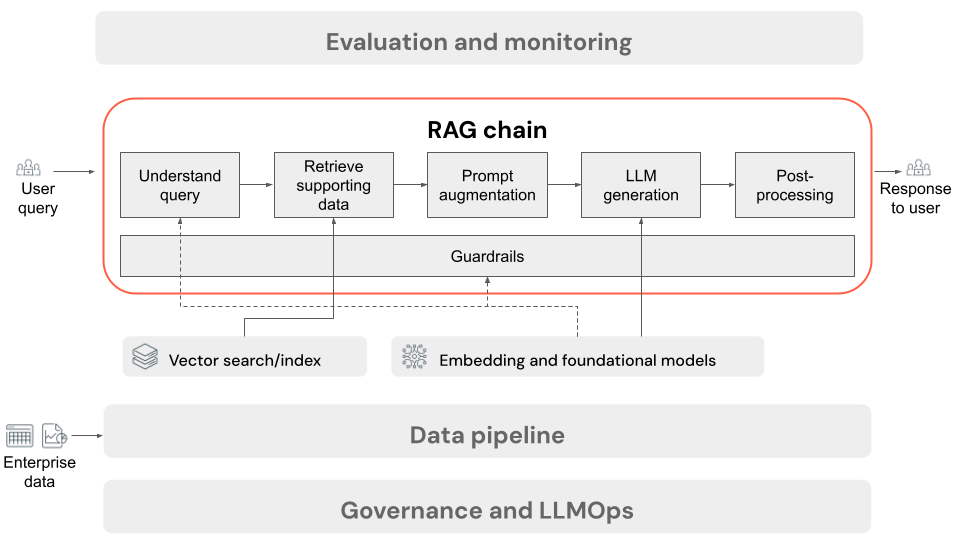
- (Opcional) Preprocesamiento de consultas de usuario: en algunos casos, la consulta del usuario se preprocesa para que sea más adecuada para consultar la base de datos vectorial. Esto puede implicar dar formato a la consulta dentro de una plantilla, usar otro modelo para volver a escribir la solicitud o extraer palabras clave para ayudar a la recuperación. La salida de este paso es una consulta de recuperación que se usará en el paso de recuperación posterior.
- Recuperación: para recuperar información auxiliar de la base de datos vectorial, la consulta de recuperación se traduce en una inserción mediante el mismo modelo de inserción que se usó para insertar los fragmentos de documento durante la preparación de datos. Estas incrustaciones permiten comparar la similitud semántica entre la consulta de recuperación y los fragmentos de texto no estructurados, mediante medidas como la similitud coseno. A continuación, los fragmentos se recuperan de la base de datos vectorial y se clasifican en función de la similitud con la solicitud insertada. Se devuelven los resultados principales (más similares).
- Aumento de la solicitud: la indicación que se enviará al LLM se forma aumentando la consulta del usuario con el contexto recuperado, en una plantilla que indica al modelo cómo usar cada componente, a menudo con instrucciones adicionales para controlar el formato de respuesta. El proceso de iteración en la plantilla de solicitud derecha que se va a usar se conoce como ingeniería de indicaciones.
- Generación de LLM: el LLM toma la indicación aumentada, que incluye la consulta del usuario y recupera los datos auxiliares, como entrada. A continuación, genera una respuesta que se basa en el contexto adicional.
- (Opcional) Posprocesamiento: la respuesta del LLM se puede procesar más para aplicar lógica de negocios adicional, agregar citas o refinar el texto generado en función de las reglas o restricciones predefinidas.
Al igual que con la canalización de datos de aplicaciones RAG, hay muchas decisiones de ingeniería consecuentes que pueden afectar a la calidad de la cadena RAG. Por ejemplo, determinar cuántos fragmentos recuperar en el paso 2 y cómo combinarlos con la consulta del usuario en el paso 3 puede afectar significativamente a la capacidad del modelo para generar respuestas de calidad.
A lo largo de la cadena, se pueden aplicar varios límites de protección para garantizar el cumplimiento de las directivas empresariales. Esto puede implicar el filtrado de solicitudes adecuadas, la comprobación de los permisos de usuario antes de acceder a los orígenes de datos y la aplicación de técnicas de moderación de contenido en las respuestas generadas.