Creación y consulta de un índice de búsqueda vectorial
En este artículo se describe cómo crear y consultar un índice de búsqueda vectorial mediante Mosaic AI Vector Search.
Puede crear y administrar componentes de búsqueda vectorial, como un punto de conexión de búsqueda vectorial e índices de búsqueda vectorial, mediante la interfaz de usuario, el SDK de Python de o la API REST de .
Requisitos
- Área de trabajo habilitada para Unity Catalog.
- Proceso sin servidor habilitado. Para obtener instrucciones, consulte Conectar a la computación sin servidor.
- La fuente de datos table debe tener habilitada la función Cambio de Alimentación de Datos. Para obtener instrucciones, consulte Uso de la fuente de distribución de datos de cambios de Delta Lake en Azure Databricks.
- Para crear un índice de búsqueda vectorial, debe tener CREATE TABLE privilegios en el catalogschemawhere, donde se creará el índice.
- Para consultar un índice que sea propiedad de otro usuario, debe tener privilegios adicionales. Vea Consulta de un punto de conexión de vector de búsqueda.
El permiso para crear y administrar puntos de conexión de búsqueda vectorial se configura mediante listas de control de acceso. Consulte ACL del punto de conexión de búsqueda vectorial.
Instalación
Para usar el SDK de búsqueda vectorial, debe instalarlo en el cuaderno. Use el código siguiente:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
from databricks.vector_search.client import VectorSearchClient
Autenticación
Consulte Protección de datos y autenticación.
Crear un endpoint de búsqueda vectorial
Puede crear un punto de conexión de búsqueda vectorial mediante la interfaz de usuario de Databricks, el SDK de Python o la API.
Creación de un punto de conexión de búsqueda vectorial mediante la interfaz de usuario
Siga estos pasos para crear un punto de conexión de búsqueda vectorial mediante la interfaz de usuario.
En la barra lateral izquierda, haga clic en Proceso.
Haga clic en la pestaña Búsqueda de vectores y después haga clic en Crear.

Se abre el formulario Crear punto de conexión. Escriba un nombre para este punto de conexión.
Haga clic en Confirmar.
Creación de un punto de conexión de búsqueda vectorial mediante el SDK de Python
En el ejemplo siguiente se usa la función create_endpoint() SDK para crear un punto de conexión de búsqueda vectorial.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearch(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD"
)
Creación de un punto de conexión de búsqueda vectorial mediante la API REST
Consulte la documentación de referencia de la API REST: POST /api/2.0/vector-search/endpoints.
(Opcional) Creación y configuración de un punto de conexión para atender el modelo de inserción
Si decide hacer que Databricks calcule las inserciones, puede usar un punto de conexión de api de Foundation Model preconfigurado o crear un punto de conexión de servicio de modelo para atender el modelo de inserción que prefiera. Consulta API de Foundation Model de pago por token o Creación de puntos de conexión de servicio del modelo de base para obtener instrucciones. Para obtener cuadernos de ejemplo, vea Ejemplos de cuaderno para llamar a un modelo de inserción.
Al configurar un punto de conexión de incrustación, Databricks recomienda remove la selección predeterminada de Escalar a cero. Los puntos de conexión de servicio pueden tardar un par de minutos en preparación y la consulta inicial en un índice con un punto de conexión de reducción vertical podría tardar un tiempo de espera.
Nota
La inicialización del índice de búsqueda vectorial puede agotar el tiempo de espera si el punto de conexión de inserción no está configurado correctamente para el conjunto de datos. Solo debe usar puntos de conexión de CPU para pequeños conjuntos de datos y pruebas. Para conjuntos de datos más grandes, use un punto de conexión de GPU para obtener un rendimiento óptimo.
Crear un índice de búsqueda vectorial
Puede crear un índice de búsqueda vectorial mediante la interfaz de usuario, el SDK de Python o la API REST. La interfaz de usuario es el enfoque más sencillo.
Hay dos tipos de índices:
- Delta Sync Index se sincroniza automáticamente con un Delta Tablede origen, actualizando automáticamente e incrementalmente el índice a medida que los datos subyacentes en Delta Table cambian.
- Direct Vector Access Index admite lectura directa y escritura de vectores y metadatos. El usuario es responsable de actualizar este table mediante la API REST o el SDK de Python. Este tipo de índice no se puede crear mediante la interfaz de usuario. Debe usar la API REST o el SDK.
Crear índice mediante la interfaz de usuario
En la barra lateral izquierda, haga clic en Catalog para abrir la interfaz de usuario del Explorador de Catalog.
Vaya al Delta table que desea usar.
Haga clic en el botón Crear en la esquina superior derecha y seleccione selectÍndice de búsqueda de vectores en el menú desplegable.
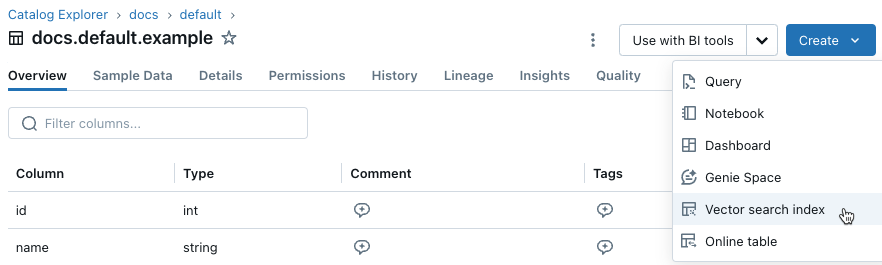
Use los selectores del cuadro de diálogo para configurar el índice.
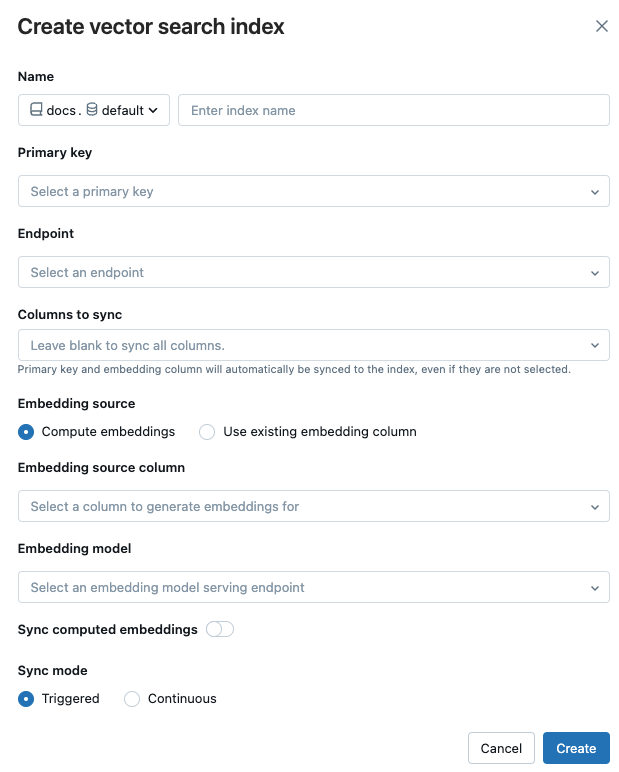
Nombre: nombre que se usará para la table en línea en Unity Catalog. El nombre requiere un espacio de nombres de tres niveles,
<catalog>.<schema>.<name>. Solo se permiten caracteres alfanuméricos y caracteres de subrayado.Clave principal: Column a utilizar como clave principal.
Punto de conexión: Select el punto de conexión de búsqueda vectorial que prefiera utilizar.
Columns a sync: Select las columns para sync con el índice vectorial. Si deja este campo en blanco, todas las columns de la table de origen se sincronizan con el índice. La clave principal column y la fuente de incrustación column o el vector de incrustación column siempre están sincronizados.
Origen de la incrustación: indique si quiere que Databricks calcule las incrustaciones de una column de texto en la table Delta (Calcular incrustaciones), o si su table Delta contiene incrustaciones precalculadas (Usar la column de incrustación existente).
- Si seleccionó Calcular incrustaciones, select la column para el que quiere calcular incrustaciones y el punto de conexión que sirve al modelo de incrustación. Solo se admiten columns de texto.
- Si seleccionó Usar la column de incrustación existente, select la column que contiene las incrustaciones precalculadas y la dimensión de incrustación. El formato de la column de incrustaciones precalculadas debe ser
array[float].
Sync incrustaciones calculadas: cambie esta configuración para guardar las incrustaciones generadas en una table de Unity Catalog. Para obtener más información, consulte Guardar table de incrustaciones generadas.
Modo de Sync: Continuo mantiene el índice sync con segundos de latencia.ddd Sin embargo, tiene un costo mayor asociado, ya que se aprovisiona un clúster de computación para ejecutar la canalización continua de streaming de sync. Para ambos, Continuo y Desencadenado, la update es un proceso incremental — solo se procesan los datos que han cambiado desde la última sync.
Con el modo Desencadenadosync, use el SDK de Python o la API REST para iniciar la sync. Consulte Update un índice de Sync Delta.
Cuando haya terminado de configurar el índice, haga clic en Crear.
Creación de un índice mediante el SDK de Python
En el ejemplo siguiente se crea un índice delta Sync con incrustaciones calculadas por Databricks.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2"
)
En el siguiente ejemplo se crea un índice Delta Sync con incrustaciones autoadministradas. En este ejemplo también se muestra el uso del parámetro opcional columns_to_sync para select solo un subconjunto de columns que se usarán en el índice.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
De forma predeterminada, todas las columns de la table de origen se sincronizan con el índice. Para sync solo un subconjunto de columns, utilice columns_to_sync. La clave principal y la incrustación columns siempre se incluyen en el índice.
Para syncsolo la clave principal y la column incrustada, debe especificarlas en columns_to_sync tal como se muestra:
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
Para synccolumnsadicionales, especifíquelas como se muestra. No es necesario incluir la clave principal y el embedding column, ya que se sincronizan siempre.
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
En el ejemplo siguiente se crea un índice de acceso vectorial directo.
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name="{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
Creación de un índice mediante la API REST
Consulte la documentación de referencia de la API REST: POST /api/2.0/vector-search/indexes.
Guardar la inserción generada table
Si Databricks genera las incrustaciones, puede guardar las incrustaciones generadas en una table en Unity Catalog. Esta table se crea en el mismo schema que el índice de vectores y está vinculado desde la página del índice de vectores.
El nombre del table es el nombre del índice de búsqueda vectorial, anexado por _writeback_table. El nombre no se puede editar.
Puede acceder al table y consultarlo como cualquier otro table de Unity Catalog. Sin embargo, no debe quitar ni modificar el table, ya que no está pensado para actualizarse manualmente. El table se elimina automáticamente si se elimina el índice.
Update un índice de búsqueda vectorial
Update un índice de Sync delta
Los índices creados con modo Continuosync se update automáticamente cuando cambia la table delta de origen. Si usa el modo Desencadenadosync, use el SDK de Python o la API REST para iniciar la sync.
Python SDK
index.sync()
REST API
Consulte la documentación de referencia de la API REST: POST /api/2.0/vector-search/indexes/{index_name}/sync.
Update un índice de acceso vectorial directo
Puede usar el SDK de Python o la API REST para insert, updateo eliminar datos de un índice de acceso vectorial directo.
Python SDK
index.upsert([{"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0, 2.0, 3.0]
},
{"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1, 2.1, 3.0]
}
])
REST API
Consulte la documentación de referencia de la API REST: POST /api/2.0/vector-search/indexes.
En el ejemplo de código siguiente se muestra cómo update un índice mediante un token de acceso personal (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
En el ejemplo de código siguiente se muestra cómo update un índice mediante una entidad de servicio.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
Consultar un endpoint de búsqueda vectorial
Solo puedes consultar el endpoint de búsqueda vectorial mediante el SDK de Python, la API REST o la función de IA SQL vector_search().
Nota
Si el usuario que consulta el punto de conexión no es el propietario del índice de búsqueda vectorial, el usuario debe tener los siguientes privilegios de UC:
- USE CATALOG en el catalog que contiene el índice de búsqueda vectorial.
- USE SCHEMA en el schema que contiene el índice de búsqueda vectorial.
- SELECT en el índice de búsqueda vectorial.
Para realizar una búsqueda híbrida de similitud de palabras clave, set el parámetro query_type en hybrid. El valor predeterminado es ann (vecino más cercano aproximado).
Python SDK
# Delta Sync Index with embeddings computed by Databricks
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2
)
# Delta Sync Index using hybrid search, with embeddings computed by Databricks
results3 = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2,
query_type="hybrid"
)
# Delta Sync Index with pre-calculated embeddings
results2 = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
num_results=2
)
REST API
Consulte la documentación de referencia de la API REST: POST /api/2.0/vector-search/indexes/{index_name}/query.
En el ejemplo de código siguiente se muestra cómo consultar un índice mediante un token de acceso personal (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Query Vector Search index with `query_vector`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index with `query_text`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
En el ejemplo de código siguiente se muestra cómo consultar un índice mediante un principal de servicio.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "ReadVectorIndex"}'
# If you are using an route_optimized embedding model endpoint (TODO: link), then you need to have additional authorization details to invoke the serving endpoint
# export EMBEDDING_MODEL_SERVING_ENDPOINT_ID=...
# export AUTHORIZATION_DETAILS="$AUTHORIZATION_DETAILS"',{"type":"workspace_permission","object_type":"serving-endpoints","object_path":"/serving-endpoints/'"$EMBEDDING_MODEL_SERVING_ENDPOINT_ID"'","actions": ["query_inference_endpoint"]}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
SQL
Importante
La función de IA vector_search() se encuentra en versión preliminar pública.
Para usar la función de IA , consulte la función de búsqueda de vectores .
Usar filtros en consultas
Una consulta puede definir filtros en función de cualquier column en el Delta table. similarity_search devuelve solo las filas que coinciden con los filtros especificados. Se admiten los siguientes filtros:
| Operador de filtro | Comportamiento | Ejemplos |
|---|---|---|
NOT |
Niega el filtro. La clave debe terminar con "NOT". Por ejemplo, el valor "color NO" con "rojo" coincide con los documentos where el color no es rojo, como el documento. | {"id NOT": 2}{“color NOT”: “red”} |
< |
Comprueba si el valor del campo es menor que el valor de filtro. La clave debe terminar con " <". Por ejemplo, "price <" con el valor 200 coincide con los documentos where donde el precio es inferior a 200. | {"id <": 200} |
<= |
Comprueba si el valor del campo es menor o igual que el valor de filtro. La clave debe terminar con " <=". Por ejemplo, "price <=" con el valor 200 coincide con los documentos where el precio es menor o igual que 200. | {"id <=": 200} |
> |
Comprueba si el valor del campo es mayor que el valor de filtro. La clave debe terminar con " >". Por ejemplo, "price >" con el valor 200 corresponde a los documentos where donde el precio es mayor que 200. | {"id >": 200} |
>= |
Comprueba si el valor del campo es mayor o igual que el valor del filtro. La clave debe terminar con " >=". Por ejemplo, "price >=" con el valor 200 coincide con los documentos where el precio es mayor o igual que 200. | {"id >=": 200} |
OR |
Comprueba si el valor del campo coincide con cualquiera del filtro values. La clave debe contener OR para separar varias subclaves. Por ejemplo, color1 OR color2 con el valor ["red", "blue"] coincide con los documentos wherecolor1 es red o color2 es blue. |
{"color1 OR color2": ["red", "blue"]} |
LIKE |
Coincide con cadenas parciales. | {"column LIKE": "hello"} |
| No se ha especificado ningún operador de filtro | El filtro busca una coincidencia exacta. Si se especifican varios values, coincide con cualquiera de los values. | {"id": 200}{"id": [200, 300]} |
Consulte los ejemplos de código siguientes:
Python SDK
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title": ["Ares", "Athena"]},
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title OR id": ["Ares", "Athena"]},
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title NOT": "Hercules"},
num_results=2
)
REST API
Vea POST /api/2.0/vector-search/indexes/{index_name}/query.
Cuadernos de ejemplo
Los ejemplos de esta sección muestran el uso del SDK de Python de búsqueda vectorial.
Ejemplos de LangChain
Consulte Uso de LangChain con Vector de búsqueda de Mosaic AI para usar Vector de búsqueda de Mosaic AI en integración con paquetes LangChain.
En el cuaderno siguiente se muestra cómo convertir los resultados de búsqueda de similitud en documentos LangChain.
Búsqueda de vectores con el cuaderno del SDK de Python
Ejemplos de cuadernos para llamar a un modelo de incrustaciones
En los siguientes cuadernos se muestra cómo configurar un punto de conexión de servicio de modelo de IA de Mosaic para la generación de inserciones.