CI/CD con Jenkins en Azure Databricks
Nota:
En este artículo se describe Jenkins, desarrollado por un tercero. Para ponerse en contacto con el proveedor, consulte Ayuda de Jenkins.
Hay numerosas herramientas de CI/CD que puede usar para administrar y ejecutar la canalización de CI/CD. En este artículo se muestra cómo usar el servidor de automatización Jenkins. CI/CD es un patrón de diseño, por lo que los pasos y las fases descritos en este artículo deberían transferirse con algunos cambios en el lenguaje de definición de la canalización en cada herramienta. Además, gran parte del código de esta canalización de ejemplo ejecuta código estándar de Python, que se puede invocar en otras herramientas. Para obtener información general sobre CI/CD en Azure Databricks, consulte ¿Qué es CI/CD en Azure Databricks?
Para obtener información sobre el uso de Azure DevOps con Azure Databricks, consulte Integración y entrega continuas en Azure Databricks con Azure DevOps.
Flujo de trabajo de desarrollo CI/CD
Databricks sugiere el siguiente flujo de trabajo para el desarrollo de CI/CD con Jenkins:
- Cree un repositorio o use un repositorio existente con el proveedor de Git de terceros.
- Conecte la máquina de desarrollo local al mismo repositorio de terceros. Para obtener instrucciones, consulte la documentación del proveedor de Git de terceros.
- Extraiga los artefactos actualizados existentes (como cuadernos, archivos de código y scripts de compilación) del repositorio de terceros en la máquina de desarrollo local.
- Según sea necesario, cree, actualice y pruebe artefactos en la máquina de desarrollo local. A continuación, envíe cualquier artefacto nuevo o modificado desde su máquina de desarrollo local al repositorio de terceros. Para obtener instrucciones, consulte la documentación del proveedor de Git de terceros.
- Repita los pasos 3 y 4 según sea necesario.
- Use Jenkins periódicamente como enfoque integrado para extraer automáticamente artefactos del repositorio de terceros en la máquina de desarrollo local o en el área de trabajo de Azure Databricks; compilar, probar y ejecutar código en la máquina de desarrollo local o en el área de trabajo de Azure Databricks; e informes de pruebas y ejecución de resultados. Aunque se puede ejecutar Jenkins manualmente, en el mundo real se le indicaría al proveedor de Git que ejecute Jenkins cada vez que ocurra un evento específico, como una solicitud de PR de un repositorio.
El resto de este artículo usa un proyecto de ejemplo para describir una manera de usar Jenkins para implementar el flujo de trabajo de desarrollo de CI/CD anterior.
Para obtener información sobre el uso de Azure DevOps en lugar de Jenkins, consulte Integración y entrega continuas en Azure Databricks mediante Azure DevOps.
Configuración de la máquina de desarrollo local
En el ejemplo de este artículo se usa Jenkins para indicar a la CLI de Databricks y las agrupaciones de recursos de Databricks que hagan lo siguiente:
- Compile un archivo de wheel de Python en su máquina de desarrollo local.
- Implemente el archivo de wheel de Python compilado junto con archivos de Python adicionales y cuadernos de Python desde su máquina de desarrollo local a un área de trabajo de Azure Databricks.
- Pruebe y ejecute el archivo de wheel de Python cargado y los cuadernos de esa área de trabajo.
Para configurar la máquina de desarrollo local para indicar al área de trabajo de Azure Databricks que realice las fases de compilación y carga de este ejemplo, haga lo siguiente en la máquina de desarrollo local:
Paso 1: Instalar las herramientas necesarias
En este paso, instale la CLI de Databricks, Jenkins, jq y las herramientas de compilación del wheel de Python en su máquina de desarrollo local. Estas herramientas son necesarias para ejecutar este ejemplo.
Instale Databricks CLI versión 0.205 o superior, si aún no lo ha hecho. Jenkins usa la CLI de Databricks para pasar la prueba de este ejemplo y ejecutar instrucciones en el área de trabajo. Consulte Instalación o actualización de la CLI de Databricks.
Instale e inicie Jenkins, si aún no lo ha hecho. Consulte Instalación de Jenkins para Linux, macOSo Windows.
Instale jq. Este ejemplo se utiliza
jqpara analizar la salida de un comando con formato JSON.Use
pippara instalar las herramientas de compilación del wheel de Python con el siguiente comando (es posible que algunos sistemas requieran que usepip3en lugar depip):pip install --upgrade wheel
Paso 2: Creación de una canalización de Jenkins
En este paso, usará Jenkins para crear una canalización de Jenkins para el ejemplo de este artículo. Jenkins proporciona varios tipos de proyecto diferentes para crear canalizaciones de CI/CD. Las canalizaciones de Jenkins proporcionan una interfaz para definir fases en una canalización de Jenkins mediante código Groovy para llamar y configurar complementos de Jenkins.
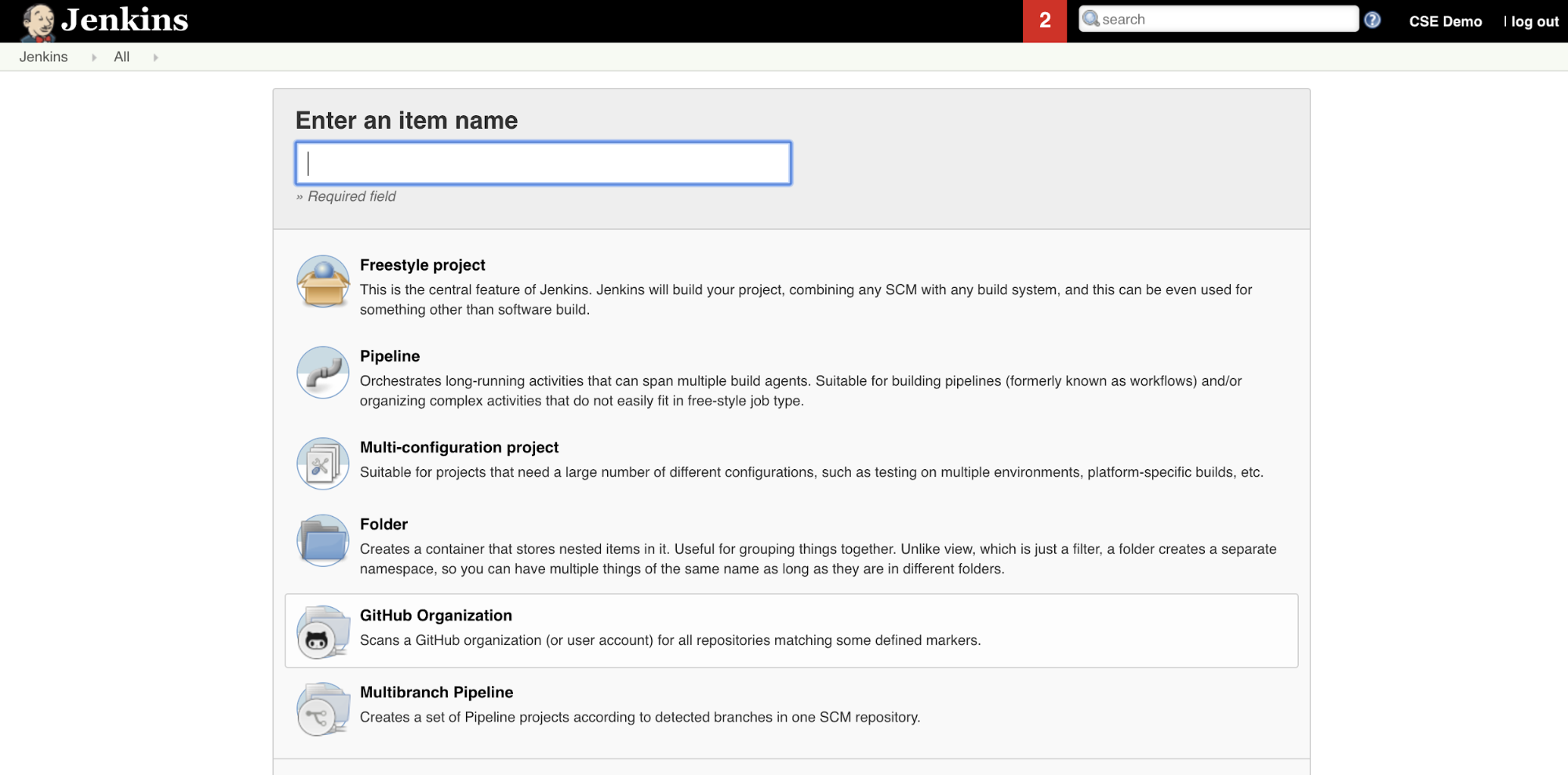
Para crear la canalización de Jenkins en Jenkins:
- Después de iniciar Jenkins, desde el panel de Jenkins, haga clic en Nuevo elemento.
- En Escriba un nombre de elemento, escriba un nombre para la canalización de Jenkins, por ejemplo
jenkins-demo. - Haga clic en el icono tipo de proyecto de Canalización.
- Haga clic en OK. Aparece la página Configurar de la canalización de Jenkins.
- En el área Canalización, en la lista desplegable Definición, seleccione Script de canalización en SCM.
- En la lista desplegable SCM, seleccione Git.
- En Dirección URL del repositorio, escriba la dirección URL del repositorio hospedado por el proveedor de Git de terceros.
- En Especificador de rama, escriba
*/<branch-name>, donde<branch-name>es el nombre de la rama en el repositorio que desea usar, por ejemplo*/main. - En Ruta de acceso de script, escriba
Jenkinsfile, si aún no está establecido. CreeJenkinsfilemás adelante en este artículo. - Desactive la casilla titulada Restauración ligera, si ya está activada.
- Haga clic en Save(Guardar).
Paso 3: Agregar variables de entorno globales a Jenkins
En este paso, agregará tres variables de entorno globales a Jenkins. Jenkins pasa estas variables de entorno a la CLI de Databricks. La CLI de Databricks necesita los valores de estas variables de entorno para autenticarse con el área de trabajo de Azure Databricks. En este ejemplo se usa la autenticación de máquina a máquina (M2M) de OAuth para una entidad de servicio (aunque también hay otros tipos de autenticación disponibles). Para configurar la autenticación de OAuth M2M para el área de trabajo de Azure Databricks, consulte Autorizar acceso desatendido a recursos de Azure Databricks con una entidad de servicio mediante OAuth.
Las tres variables de entorno globales para este ejemplo son:
DATABRICKS_HOST, definido en la dirección URL del área de trabajo de Azure Databricks, empezando porhttps://. Consulte Nombres, direcciones URL e identificadores de instancias de áreas de trabajo.DATABRICKS_CLIENT_ID, se establece en el id. de cliente de la entidad de servicio, que también se conoce como id. de aplicación.DATABRICKS_CLIENT_SECRET, se establece en el secreto de OAuth de la entidad de servicio de Azure Databricks.
Para establecer variables de entorno globales en Jenkins, desde el panel de Jenkins:
- En la barra lateral, haga clic en Administración de Jenkins.
- En la sección Configuración del sistema, haga clic en Sistema.
- En la sección Propiedades globales, active la casilla Variables de entorno.
- Haga clic en Sumar y escriba el nombre y el valor de la variable de entorno. Repita esto para cada variable de entorno adicional.
- Cuando haya terminado de agregar variables de entorno, haga clic en Guardar para volver al panel de Jenkins.
Diseño de la canalización de Jenkins
Jenkins proporciona varios tipos de proyecto diferentes para crear canalizaciones de CI/CD. En este ejemplo se implementa una canalización de Jenkins. Las canalizaciones de Jenkins proporcionan una interfaz para definir fases en una canalización de Jenkins mediante código Groovy para llamar y configurar complementos de Jenkins.
Escribe una definición de canalización de Jenkins en un archivo de texto denominado Jenkinsfile, que a su vez se comprueba en un repositorio de control de código fuente del proyecto. Para más información, consulte Canalización de Jenkins. Este es el ejemplo de canalización de Jenkins para este artículo. En este ejemplo Jenkinsfile, reemplace los siguientes marcadores de posición:
- Reemplace
<user-name>y<repo-name>por el nombre de usuario y del repositorio para el proveedor de Git hospedado de terceros. En este artículo se usa una dirección URL de GitHub como ejemplo. - Reemplace
<release-branch-name>por el nombre de la rama de versión en el repositorio. Por ejemplo, podría sermain. - Reemplace
<databricks-cli-installation-path>por la ruta de acceso de la máquina de desarrollo local donde está instalada la CLI de Databricks. Por ejemplo, en macOS podría ser/usr/local/bin. - Reemplace
<jq-installation-path>por la ruta de acceso de la máquina de desarrollo local dondejqestá instalada. Por ejemplo, en macOS podría ser/usr/local/bin. - Reemplace
<job-prefix-name>con alguna cadena para ayudar a identificar de forma única los trabajos de Azure Databricks que se crean en el área de trabajo para este ejemplo. Por ejemplo, podría serjenkins-demo. - Tenga en cuenta que
BUNDLETARGETse establece endev, que es el nombre del destino de agrupación de recursos de Databricks que se define más adelante en este artículo. En las implementaciones del mundo real, cambiaría esto por el nombre de su propio destino de agrupación. Más información sobre los destinos de agrupación se proporcionan más adelante en este artículo.
Este es el Jenkinsfile, que se debe agregar a la raíz del repositorio:
// Filename: Jenkinsfile
node {
def GITREPOREMOTE = "https://github.com/<user-name>/<repo-name>.git"
def GITBRANCH = "<release-branch-name>"
def DBCLIPATH = "<databricks-cli-installation-path>"
def JQPATH = "<jq-installation-path>"
def JOBPREFIX = "<job-prefix-name>"
def BUNDLETARGET = "dev"
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
-t ${BUNDLETARGET} \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
}
En el resto de este artículo se describe cada fase de esta canalización de Jenkins y cómo configurar los artefactos y comandos para que Jenkins se ejecute en esa fase.
Extracción de los artefactos más recientes del repositorio de terceros
La primera fase de esta canalización de Jenkins, la fase de Checkout, se define de la siguiente manera:
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
Esta fase se asegura de que el directorio de trabajo que Jenkins utiliza en su máquina de desarrollo local tiene los últimos artefactos de su repositorio Git de terceros. Normalmente, Jenkins establece este directorio de trabajo en <your-user-home-directory>/.jenkins/workspace/<pipeline-name>. Esto le permite, en la misma máquina de desarrollo local, mantener su propia copia de artefactos en desarrollo separada de los artefactos que Jenkins utiliza de su repositorio Git de terceros.
Validación de la agrupación de recursos de Databricks
La segunda fase de esta canalización de Jenkins, la fase Validate Bundle, se define de la siguiente manera:
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
Esta fase garantiza que la agrupación de recursos de Databricks, que define los flujos de trabajo para probar y ejecutar los artefactos, es sintácticamente correcta. Las agrupaciones de recursos de Databricks, conocidas simplemente como agrupaciones, permiten expresar proyectos completos de datos, análisis y ML como una colección de archivos de origen. Consulte ¿Qué son las agrupaciones de recursos de Databricks?
Para definir la agrupación de este artículo, cree un archivo denominado databricks.yml en la raíz del repositorio clonado en la máquina local. En este ejemplo del archivo databricks.yml, reemplace los siguientes marcadores de posición:
- Reemplace
<bundle-name>por un nombre de programación único para la agrupación. Por ejemplo, podría serjenkins-demo. - Reemplace
<job-prefix-name>con alguna cadena para ayudar a identificar de forma única los trabajos de Azure Databricks que se crean en el área de trabajo para este ejemplo. Por ejemplo, podría serjenkins-demo. Debe coincidir con el valorJOBPREFIXdel archivo Jenkins. - Reemplace
<spark-version-id>por el id. de versión de Databricks Runtime para los clústeres de trabajos, por ejemplo13.3.x-scala2.12. - Reemplace
<cluster-node-type-id>con el ID del tipo de nodo para sus clústeres de trabajo, por ejemploStandard_DS3_v2. - Tenga en cuenta que
deven la asignacióntargetses el mismo queBUNDLETARGETen su Jenkinsfile. Un destino de agrupación especifica el host y los comportamientos de implementación relacionados.
Aquí está el archivo databricks.yml, que debe ser agregado a la raíz de su repositorio para que este ejemplo funcione correctamente:
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
data_security_mode: SINGLE_USER
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: '/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl'
evaluate-notebook-runs:
name: ${var.job_prefix}-evaluate-notebook-runs
tasks:
- task_key: ${var.job_prefix}-evaluate-notebook-runs-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
spark_python_task:
python_file: ./evaluate_notebook_runs.py
source: WORKSPACE
libraries:
- pypi:
package: unittest-xml-reporting
targets:
dev:
mode: development
Para obtener más información sobre el archivo databricks.yml, consulta Configuración de agrupación de recurso de Databricks.
Implementación de la agrupación en su área de trabajo
La tercera fase de la canalización de Jenkins, titulada Deploy Bundle, se define de la siguiente manera:
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
Esta fase hace dos cosas:
- Dado que la asignación de
artifacten el archivodatabricks.ymlestá establecida enwhl, esto indica a la CLI de Databricks que compile el archivo de rueda de Python mediante el archivosetup.pyen la ubicación especificada. - Una vez creado el archivo de wheel de Python en la máquina de desarrollo local, la CLI de Databricks implementa el archivo de rueda de Python compilado junto con los archivos y cuadernos de Python especificados en el área de trabajo de Azure Databricks. De manera predeterminada, Databricks Asset Bundles implementa el archivo wheel de Python y otros archivos en
/Workspace/Users/<your-username>/.bundle/<bundle-name>/<target-name>.
Para permitir que el archivo de wheel de Python se compile tal como se especifica en el archivo databricks.yml, cree las siguientes carpetas y archivos en la raíz del repositorio clonado en el equipo local.
Para definir la lógica y las pruebas unitarias para el archivo de rueda de Python en el que se ejecutará el cuaderno, cree dos archivos denominados addcol.py y test_addcol.py, y agréguelos a una estructura de carpetas denominada python/dabdemo/dabdemo dentro de la carpeta Libraries del repositorio, visualizados como se indica a continuación (los puntos suspensivos indican carpetas omitidas en el repositorio, por brevedad):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ └── dabdemo
│ ├── addcol.py
│ └── test_addcol.py
├── ...
El archivo addcol.py contiene una función de biblioteca integrada más adelante en un archivo de wheel de Python y a continuación, se instala en un clúster de Azure Databricks. Es una función sencilla que agrega una nueva columna, rellenada por un literal, a un DataFrame de Apache Spark:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
El archivo test_addcol.py contiene pruebas para pasar un objeto DataFrame ficticio a la función with_status, definida en addcol.py. A continuación, el resultado se compara con un objeto DataFrame que contiene los valores esperados. Si los valores coinciden, lo que en este casó pasará, se habrá superado la prueba.
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Para permitir que la CLI de Databricks empaquete correctamente este código de biblioteca en un archivo de wheel de Python, cree dos archivos denominados __init__.py y __main__.py en la misma carpeta que los dos archivos anteriores. Además, cree un archivo denominado setup.py en la carpeta python/dabdemo, visualizado de la siguiente manera (los puntos suspensivos indican carpetas omitidas, por motivos de brevedad):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ ├── dabdemo
│ │ ├── __init__.py
│ │ ├── __main__.py
│ │ ├── addcol.py
│ │ └── test_addcol.py
│ └── setup.py
├── ...
El archivo __init__.py contiene el número de versión y el autor de la biblioteca. Reemplace <my-author-name> por su nombre:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
El archivo __main__.py contiene el punto de entrada de la biblioteca:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
El archivo setup.py contiene configuraciones adicionales para compilar la biblioteca en un archivo wheel de Python. Reemplace <my-url>, <my-author-name>@<my-organization> y <my-package-description> por valores significativos:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Prueba de la lógica del componente del paquete wheel de Python
La fase Run Unit Tests, la cuarta fase de esta canalización de Jenkins, usa pytest para probar la lógica de una biblioteca para asegurarse de que funciona según lo compilado. Esta fase se define de la siguiente manera:
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
Esta fase usa la CLI de Databricks para ejecutar un trabajo de cuaderno. Este trabajo ejecuta el cuaderno de Python con el nombre de archivo de run-unit-test.py. Este cuaderno ejecuta pytest en la lógica de la biblioteca.
Para ejecutar las pruebas unitarias para este ejemplo, agregue un archivo de cuaderno de Python denominado run_unit_tests.py con el siguiente contenido a la raíz del repositorio clonado en la máquina local:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Uso del paquete wheel de Python compilado
La quinta fase de esta canalización de Jenkins, titulada Run Notebook, ejecuta un cuaderno de Python que llama a la lógica en el archivo de rueda de Python integrado, como se indica a continuación:
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
Esta fase ejecuta la CLI de Databricks, que a su vez indica al área de trabajo que ejecute un trabajo de cuaderno. Este cuaderno crea un objeto DataFrame, lo pasa a la función with_status de la biblioteca, imprime el resultado e informa de los resultados de ejecución del trabajo. Cree el cuaderno agregando un archivo de cuaderno de Python denominado dabdaddemo_notebook.py con el siguiente contenido en la raíz del repositorio clonado en la máquina de desarrollo local:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │first_name │last_name │email │status |
# +============+===========+=========================+=========+
# │paula │white │paula.white@example.com │checked |
# +------------+-----------+-------------------------+---------+
# │john │baer │john.baer@example.com │checked |
# +------------+-----------+-------------------------+---------+
Evaluación de los resultados de la ejecución del trabajo del cuaderno
La fase Evaluate Notebook Runs, la sexta fase de esta canalización de Jenkins, evalúa los resultados de la ejecución del trabajo del cuaderno anterior. Esta fase se define de la siguiente manera:
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
Esta fase ejecuta la CLI de Databricks, que a su vez indica al área de trabajo que ejecute un trabajo de archivo de Python. Este archivo Python determina los criterios de fallo y éxito para la ejecución del trabajo de cuaderno e informa de este resultado de fallo o éxito. Cree un archivo denominado evaluate_notebook_runs.py con el siguiente contenido en la raíz del repositorio clonado en la máquina de desarrollo local:
import unittest
import xmlrunner
import json
import glob
import os
class TestJobOutput(unittest.TestCase):
test_output_path = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output"
def test_performance(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
duration = data['tasks'][0]['execution_duration']
if duration > 100000:
status = 'FAILED'
else:
status = 'SUCCESS'
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
def test_job_run(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
status = data['state']['result_state']
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
if __name__ == '__main__':
unittest.main(
testRunner = xmlrunner.XMLTestRunner(
output = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output/test-results",
),
failfast = False,
buffer = False,
catchbreak = False,
exit = False
)
Importación e informe de resultados de pruebas
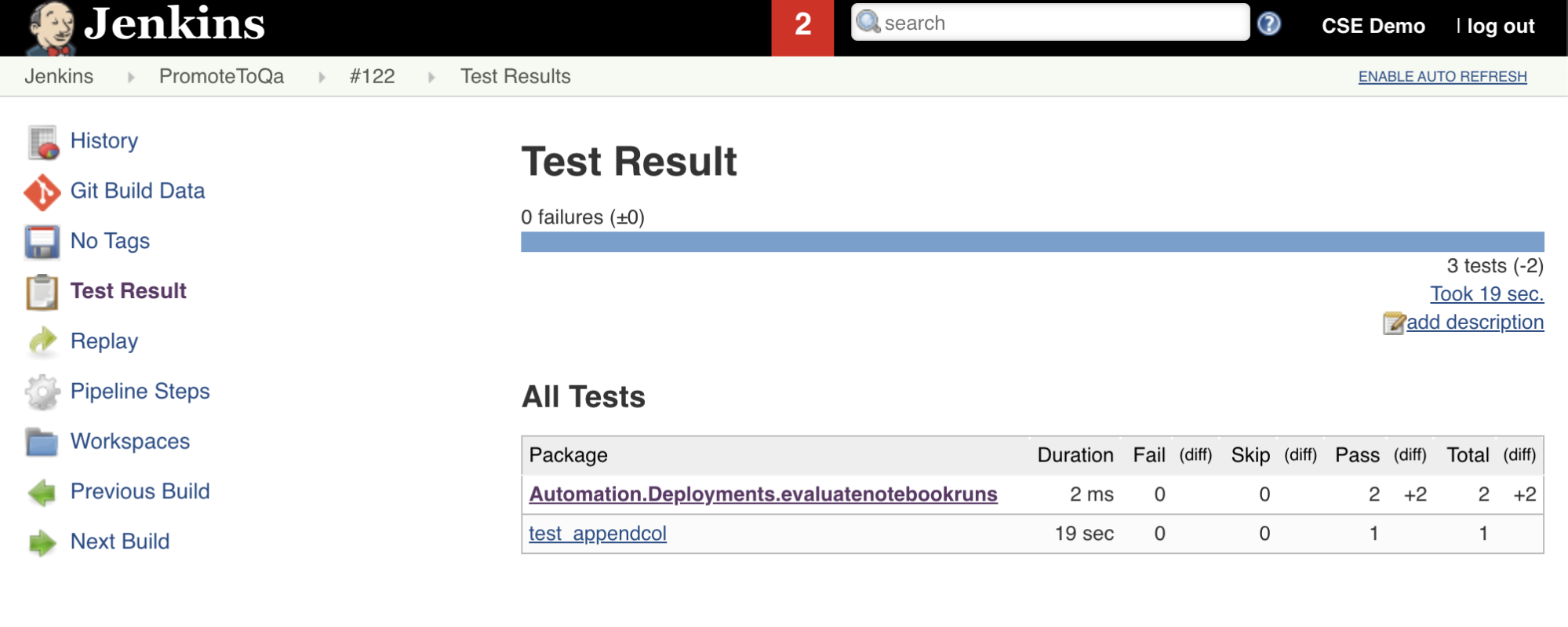
La séptima fase de esta canalización de Jenkins, titulada Import Test Results, usa la CLI de Databricks para enviar los resultados de la prueba desde el área de trabajo a la máquina de desarrollo local. La octava y última fase, titulada Publish Test Results, publica los resultados de las pruebas en Jenkins mediante el complemento Jenkins junit. Esto le permite visualizar informes y paneles relacionados con el estado de los resultados de la prueba. Estas fases se definen de la siguiente manera:
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
Envío de todos los cambios de código en el repositorio de terceros
Ahora debe insertar el contenido del repositorio clonado en la máquina de desarrollo local en el repositorio de terceros. Antes de hacer el envío de cambios, debe agregar las siguientes entradas al archivo .gitignore en su repositorio clonado, ya que probablemente no debería enviar cambios de archivos de trabajo internos de la agrupación de recursos de Databricks, informes de validación, archivos de compilación de Python y cachés de Python en su repositorio de terceros. Normalmente, querrá regenerar nuevos informes de validación y las compilaciones del paquete wheel de Python más reciente en el área de trabajo de Azure Databricks, en lugar de usar informes de validación y compilaciones de paquete wheel de Python obsoletos:
.databricks/
.vscode/
Libraries/python/dabdemo/build/
Libraries/python/dabdemo/__pycache__/
Libraries/python/dabdemo/dabdemo.egg-info/
Validation/
Ejecución de la canalización de Jenkins
Ya está listo para ejecutar manualmente la canalización de Jenkins. Para ello, siga estos pasos desde el panel de Jenkins:
- Haga clic en el nombre de la canalización de Jenkins.
- En la barra lateral, haga clic en Compilar ahora.
- Para ver los resultados, haga clic en la ejecución de canalización más reciente (por ejemplo,
#1) y, a continuación, haga clic en Salida de la consola.
En este momento, se ha completado un ciclo de integración e implementación mediante la canalización de CI/CD. Al automatizar este proceso, se asegura de que el código se prueba e implementa mediante un proceso eficaz, coherente y repetible. Para indicar a su proveedor de Git de terceros que ejecute Jenkins cada vez que se produzca un evento específico, como una solicitud de incorporación de cambios del repositorio, consulte la documentación del proveedor de Git de terceros.