Uso de las utilidades UCX para actualizar el área de trabajo al Unity Catalog
En este artículo se presenta UCX, un proyecto de Databricks Labs que proporciona herramientas para ayudarle a actualizar el área de trabajo que no es Unity-Catalog a Unity Catalog.
Nota:
UCX, como todos los proyectos de la cuenta de GitHub de databrickslabs, se proporciona solo para la exploración y no es compatible formalmente con Databricks con acuerdos de nivel de servicio (SLA). Se proporciona tal cual. No hacemos ninguna garantía de ningún tipo. No envíe una incidencia de soporte técnico de Databricks relacionada con los problemas que surgen del uso de este proyecto. En su lugar, abra un problema de GitHub. Los problemas se revisarán a medida que se permita el tiempo, pero no hay acuerdos de nivel de servicio formales para el soporte técnico.
El proyecto UCX proporciona las siguientes herramientas y flujos de trabajo de migración:
- Flujo de trabajo evaluación para ayudarle a planear la migración.
- Flujo de trabajo de migración de grupos para ayudarle a actualizar la pertenencia a grupos del área de trabajo a la cuenta de Databricks y migrar permisos a los nuevos grupos de nivel de cuenta.
- Flujo de trabajo de migración de tablas para ayudarle a actualizar las tablas registradas en el metastore de Hive del área de trabajo al metastore del catálogo de Unity. Este flujo de trabajo también le ayuda a migrar las ubicaciones de almacenamiento y las credenciales necesarias para acceder a ellas.
En este diagrama se muestra el flujo de migración general, que identifica los flujos de trabajo de migración y las utilidades por nombre:
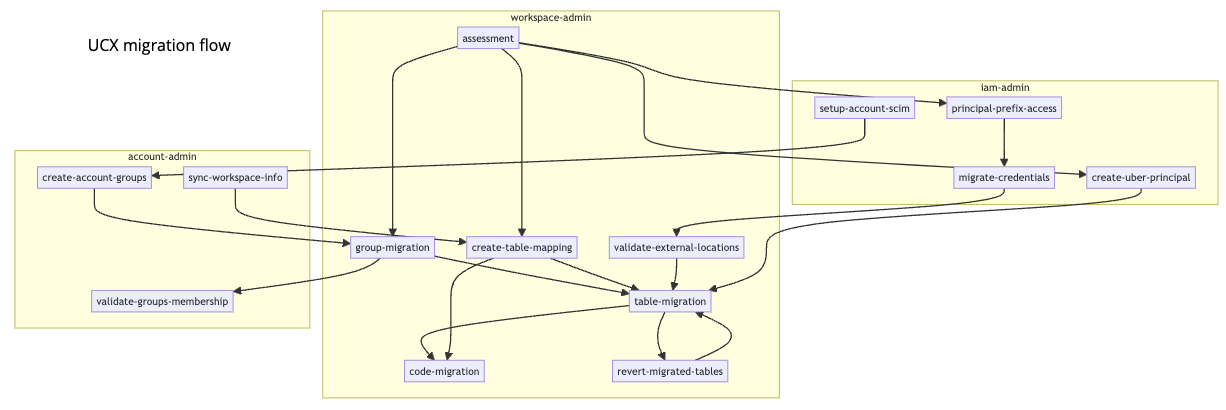
Nota:
El flujo de trabajo de migración de código que se muestra en el diagrama permanece en desarrollo y aún no está disponible.
Antes de empezar
Para poder instalar UCX y ejecutar los flujos de trabajo de UCX, el entorno debe cumplir los siguientes requisitos.
Paquetes instalados en el equipo donde se ejecuta UCX:
CLI de Databricks v0.213 o superior. Consulte Instalación o actualización de la CLI de Databricks.
Debe tener un archivo de configuración de Databricks con perfiles de configuración para el área de trabajo y la cuenta de Databricks.
Python 3.10 o superior.
Si quiere ejecutar el flujo de trabajo de UCX que identifica las ubicaciones de almacenamiento usadas por las tablas de Hive en el área de trabajo (recomendada, pero no necesaria), debe tener la CLI del proveedor de almacenamiento en la nube (CLI de Azure o la CLI de AWS) instalada en el equipo donde ejecuta los flujos de trabajo de UCX.
Acceso a la red:
- Acceso de red desde el equipo que ejecuta la instalación de UCX al área de trabajo de Azure Databricks que va a migrar.
- Acceso de red a Internet desde el equipo que ejecuta la instalación de UCX. Esto es necesario para acceder a pypi.org y github.com.
- Acceso de red desde el área de trabajo de Azure Databricks a pypi.org para descargar los paquetes de
databricks-sdkypyyaml.
Roles y permisos de Databricks:
- Roles de administrador de cuentas y de administrador del área de trabajo de Azure Databricks para el usuario que ejecuta la instalación de UCX. No se puede ejecutar la instalación como una entidad de servicio.
Otros requisitos previos de Databricks:
Un metastore de Unity Catalog creado para cada región que hospeda un área de trabajo que desea actualizar, con cada una de esas áreas de trabajo de Azure Databricks asociadas a un metastore de Unity Catalog.
Para obtener información sobre cómo determinar si ya tiene un metastore de Unity Catalog en las regiones de área de trabajo pertinentes, cómo crear un metastore si no lo hace y cómo adjuntar un metastore de Unity Catalog a un área de trabajo, vea Paso 1: Confirmar que el área de trabajo está habilitada para Unity Catalog en el artículo de configuración deUnity Catalog. Como alternativa, UCX proporciona una utilidad para asignar metastores de Unity Catalog a áreas de trabajo que puede usar después de instalar UCX.
La asociación de un metastore de Unity Catalog a un área de trabajo también permite federación de identidades, en la que centraliza la administración de usuarios en el nivel de cuenta de Azure Databricks, que también es un requisito previo para usar UCX. Vea Habilitación de la federación de identidades.
Si el área de trabajo usa un metastore externo de Hive (como AWS Glue) en lugar del metastore de Hive local del área de trabajo predeterminada, debe realizar alguna configuración de requisitos previos. Vea Integración de metastore de Hive externo en el repositorio databrickslabs/ucx.
Un almacenamiento SQL Pro o sin servidor que se ejecuta en el área de trabajo donde se ejecutan flujos de trabajo de UCX, necesarios para representar el informe generado por el flujo de trabajo de evaluación.
Instalación de UCX
Para instalar UCX, use la CLI de Databricks:
databricks labs install ucx
Se le pedirá que seleccione lo siguiente:
Perfil de configuración de Databricks para el área de trabajo que desea actualizar. El archivo de configuración también debe incluir un perfil de configuración para la cuenta primaria de Databricks del área de trabajo.
Nombre de la base de datos de inventario que se usará para almacenar la salida de los flujos de trabajo de migración. Normalmente, es correcto seleccionar el valor predeterminado, que es
ucx.Un almacén de SQL para ejecutar el proceso de instalación.
Lista de grupos locales del área de trabajo que desea migrar a grupos de nivel de cuenta. Si lo deja como predeterminado (
<ALL>), cualquier grupo de nivel de cuenta existente cuyo nombre coincida con un grupo local del área de trabajo se tratará como el reemplazo de ese grupo local del área de trabajo y heredará todos sus permisos de área de trabajo al ejecutar el flujo de trabajo de migración de grupo después de la instalación.Tiene la oportunidad de modificar la asignación workspace-group-to-account-group después de ejecutar el instalador y antes de ejecutar la migración de grupos. Vea Resolución de conflictos de nombres de grupo en el repositorio UCX.
Si tiene un metastore de Hive externo, como AWS Glue, tiene la opción de conectarse a él o no. Vea Integración de metastore de Hive externo en el repositorio databrickslabs/ucx.
Indica si se va a abrir el cuaderno README generado.
Cuando se realiza la instalación, implementa un cuaderno README, paneles, bases de datos, bibliotecas, trabajos y otros recursos del área de trabajo.
Para obtener más información, vea las instrucciones de instalación en el archivo Léame del proyecto. También puede instalar UCX en todas las áreas de trabajo de la cuenta de Databricks.
Abra el cuaderno README.
Cada instalación crea un cuaderno README que proporciona una descripción detallada de todos los flujos de trabajo y tareas, con vínculos rápidos a los flujos de trabajo y paneles. Vea cuaderno Léame.
Paso 1. Ejecución del flujo de trabajo de evaluación
El flujo de trabajo de evaluación evalúa la compatibilidad del Unity Catalog de identidades de grupo, ubicaciones de almacenamiento, credenciales de almacenamiento, controles de acceso y tablas en el área de trabajo actual y proporciona la información necesaria para planear la migración al Unity Catalog. Las tareas del flujo de trabajo de evaluación se pueden ejecutar en paralelo o secuencialmente, en función de las dependencias especificadas. Una vez finalizado el flujo de trabajo de evaluación, se rellena un panel de evaluación con conclusiones y recomendaciones comunes.
La salida de cada tarea de flujo de trabajo se almacena en tablas Delta en el esquema de $inventory_database que especifique durante la instalación. Puede usar estas tablas para realizar más análisis y toma de decisiones mediante un informe de evaluación. Puede ejecutar el flujo de trabajo de evaluación varias veces para asegurarse de que todas las entidades incompatibles se identifican y se tienen en cuenta antes de iniciar el proceso de migración.
Puede desencadenar el flujo de trabajo de evaluación desde el cuaderno README generado por UCX y la interfaz de usuario de Azure Databricks (flujos de trabajo > Trabajos > evaluación [UCX] o ejecutar el siguiente comando de la CLI de Databricks:
databricks labs ucx ensure-assessment-run
Para obtener instrucciones detalladas, vea Flujo de trabajo de evaluación.
Paso 2. Ejecución del flujo de trabajo de migración de grupos
El flujo de trabajo de migración de grupos actualiza los grupos locales del área de trabajo a grupos de nivel de cuenta para admitir el Unity Catalog. Garantiza que los grupos de nivel de cuenta adecuados estén disponibles en el área de trabajo y replique todos los permisos. También quita los grupos y permisos innecesarios del área de trabajo. Las tareas del flujo de trabajo de migración de grupos dependen de la salida del flujo de trabajo de evaluación.
La salida de cada tarea de flujo de trabajo se almacena en tablas Delta en el esquema de $inventory_database que especifique durante la instalación. Puede usar estas tablas para realizar más análisis y toma de decisiones. Puede ejecutar el flujo de trabajo de migración de grupos varias veces para asegurarse de que todos los grupos se actualizan correctamente y de que se asignan todos los permisos necesarios.
Para obtener información sobre cómo ejecutar el flujo de trabajo de migración de grupos, vea el cuaderno README generado por UCX y Flujo de trabajo de migración de grupos en el archivo Léame UCX.
Paso 3. Ejecución del flujo de trabajo de migración de tablas
El flujo de trabajo de migración de tablas actualiza las tablas desde el metastore de Hive al metastore de Unity Catalog. Las tablas externas del metastore de Hive se actualizan como tablas externas en Unity Catalog mediante SYNC. Las tablas administradas en el metastore de Hive que se almacenan en el almacenamiento del área de trabajo (también conocida como raíz de DBFS) se actualizan como tablas administradas en Unity Catalog, mediante DEEP CLONE.
Las tablas administradas de Hive deben estar en formato Delta o Parquet para actualizarse. Las tablas de Hive externas deben estar en uno de los formatos de datos enumerados en Trabajar con tablas externas.
Ejecución de los comandos preparatorios
La migración de tablas incluye una serie de tareas preparatorias que se ejecutan antes de ejecutar el flujo de trabajo de migración de tablas. Estas tareas se realizan mediante los siguientes comandos de la CLI de Databricks:
- El comando
create-table-mapping, que crea un archivo CSV que asigna un catálogo, esquema y tabla de Unity Catalog de destino a cada tabla de Hive que se actualizará. Debe revisar y actualizar el archivo de asignación antes de continuar con el flujo de trabajo de migración. - El comando
create-uber-principal, que crea una entidad de servicio con acceso de solo lectura a todos los almacenamientos usados por las tablas de esta área de trabajo. El recurso de proceso del trabajo de flujo de trabajo usa esta entidad de seguridad para actualizar las tablas del área de trabajo. Desaprovisione esta entidad de servicio cuando haya terminado con la actualización. - (Opcional) El comando
principal-prefix-access, que identifica las cuentas de almacenamiento y las credenciales de acceso de almacenamiento usadas por las tablas de Hive en el área de trabajo. - (Opcional) El comando
migrate-credentials, que crea credenciales de almacenamiento del Unity Catalog a partir de las credenciales de acceso de almacenamiento identificadas porprincipal-prefix-access. - (Opcional) El comando
migration locations, que crea ubicaciones externas del Unity Catalog desde las ubicaciones de almacenamiento identificadas por el flujo de trabajo de evaluación, mediante las credenciales de almacenamiento creadas pormigrate-credentials. - (Opcional) El comando
create-catalogs-schemas, que crea catálogos y esquemas del Unity Catalog que contendrán las tablas actualizadas.
Para más información, incluidos los comandos y opciones adicionales del flujo de trabajo de migración de tablas, vea Comandos de migración de tablas en el archivo Léame UCX.
Ejecución de la migración de tablas
Una vez que haya ejecutado las tareas preparatorias, puede ejecutar el flujo de trabajo de migración de tablas desde el cuaderno README generado por UCX o desde Flujos de trabajo> Trabajos en la interfaz de usuario del área de trabajo.
La salida de cada tarea de flujo de trabajo se almacena en tablas Delta en el esquema de $inventory_database que especifique durante la instalación. Puede usar estas tablas para realizar más análisis y toma de decisiones. Es posible que tenga que ejecutar el flujo de trabajo de migración de tablas varias veces para asegurarse de que todas las tablas se actualizan correctamente.
Para obtener instrucciones completas sobre la migración de tablas, vea el cuaderno README generado por UCX y el Flujo de trabajo de migración de tablas en el archivo Léame de UCX.
Herramientas adicionales
UCX también incluye herramientas de depuración y otras utilidades para ayudarle a realizar correctamente la migración. Para obtener más información, vea el cuaderno README generado por UCX y el Archivo Léame del proyecto UCX.
Actualización de la instalación de UCX
El proyecto UCX se actualiza periódicamente. Para actualizar la instalación de UCX a la versión más reciente:
Compruebe que UCX está instalado.
databricks labs installed Name Description Version ucx Unity Catalog Migration Toolkit (UCX) 0.20.0Ejecute la actualización:
databricks labs upgrade ucx
Obtener ayuda
Para obtener ayuda con la CLI de UCX, ejecute:
databricks labs ucx --help
Para obtener ayuda con un comando UCX específico, ejecute:
databricks labs ucx <command> --help
Para solucionar problemas:
- Ejecute
--debugcon cualquier comando para habilitar los registros de depuración. - Use el cuaderno de depuración generado automáticamente por UCX.
Para presentar un problema o solicitud de característica, abra un problema de GitHub.
Notas de la versión de UCX
Consulte el registro de cambios en el repositorio de GitHub de UCX.