Procesamiento de flujos con Apache Kafka y Azure Databricks
En este artículo se describe cómo puede usar Apache Kafka como origen o receptor al ejecutar cargas de trabajo de Structured Streaming en Azure Databricks.
Para más información sobre Kafka, consulte la documentación de Kafka.
Leer datos desde Kafka
A continuación se muestra un ejemplo de una transmisión leída desde Kafka:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "latest")
.load()
)
Azure Databricks también admite la semántica de lectura por lotes para orígenes de datos de Kafka, como se muestra en el ejemplo siguiente:
df = (spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()
)
Para la carga por lotes incremental, Databricks recomienda usar Kafka con Trigger.AvailableNow. Consulte Configuración del procesamiento por lotes incremental.
En Databricks Runtime 13.3 LTS y versiones posteriores, Azure Databricks proporciona una función SQL para leer datos de Kafka. El streaming con SQL solo se admite en Delta Live Tables o con tablas de streaming en Databricks SQL. Consulte read_kafka función con valores de tabla.
Configuración del lector de Structured Streaming de Kafka
Azure Databricks proporciona la palabra clave kafka como formato de datos para configurar las conexiones a Kafka 0.10 y versiones posteriores.
A continuación se muestran las configuraciones más comunes para Kafka:
Hay varias maneras de especificar a qué temas suscribirse. Debe proporcionar únicamente uno de estos parámetros:
| Opción | Value | Descripción |
|---|---|---|
| subscribe | Lista de temas separados por comas. | Lista de temas a la que suscribirse. |
| subscribePattern | Cadena regex de Java. | Patrón utilizado para suscribirse a los temas. |
| asignar | Cadena JSON {"topicA":[0,1],"topic":[2,4]}. |
Elemento topicPartitions específico que se va a consumir. |
Otras configuraciones importantes:
| Opción | Value | Valor predeterminado | Descripción |
|---|---|---|---|
| kafka.bootstrap.servers | Lista separada por comas de host:puerto. | empty | [Obligatorio] Configuración bootstrap.servers de Kafka. Si descubre que no hay ningún dato de Kafka, compruebe primero la lista de direcciones del agente. Si la lista de direcciones del agente es incorrecta, es posible que no haya errores. Esto se debe a que el cliente de Kafka supone que los agentes estarán disponibles finalmente y, en caso de errores de red, vuelve a intentarlo indefinidamente. |
| failOnDataLoss | true o false. |
true |
[Opcional] Indica si se debe producir un error en la consulta cuando sea posible que se hayan perdido datos. Las consultas pueden no leer datos de Kafka de forma permanente debido a muchos escenarios, como temas eliminados, el truncamiento de temas antes del procesamiento, etc. Intentamos calcular de forma conservadora si es posible que hayan perdido datos o no. A veces, esto puede provocar falsas alarmas. Establezca esta opción en false si no funciona según lo previsto o si desea que la consulta continúe con el procesamiento a pesar de la pérdida de datos. |
| minPartitions | Entero >= 0, 0 = deshabilitado. | 0 (Deshabilitado) | [Opcional] Número mínimo de particiones que se van a leer de Kafka. Puede configurar Spark para que use un mínimo arbitrario de particiones para leer desde Kafka mediante la opción minPartitions. Normalmente, Spark tiene una asignación de 1 a 1 entre los elementos topicPartitions de Kafka y las particiones de Spark que consumen desde Kafka. Si establece la opción minPartitions en un valor mayor que el elemento topicPartitions de Kafka, Spark dividirá las particiones de Kafka de gran tamaño en partes más pequeñas. Esta opción se puede establecer en momentos de cargas máximas, de asimetría de datos y cuando el flujo se está quedando atrás para aumentar la tasa de procesamiento. Esto tiene el costo de inicializar los consumidores de Kafka en cada desencadenador, lo que puede afectar al rendimiento si usa SSL al conectarse a Kafka. |
| kafka.group.id | Identificador del grupo de consumidores de Kafka. | Sin establecer | [Opcional] Identificador de grupo que se usará al leer desde Kafka. Utilícelo con precaución. De manera predeterminada, cada consulta genera un identificador de grupo único para leer datos. Esto garantiza que cada consulta tenga su propio grupo de consumidores que no se enfrenta a interferencias de ningún otro consumidor y, por tanto, pueda leer todas las particiones de sus temas suscritos. En algunos escenarios (por ejemplo, la autorización basada en grupos de Kafka), puede que desee usar identificadores de grupo autorizados específicos para leer datos. Opcionalmente, puede establecer el identificador de grupo. Sin embargo, haga esto con mucha precaución, ya que puede provocar un comportamiento inesperado. - Es probable que las consultas de ejecución simultánea (tanto por lotes como por streaming) con el mismo identificador de grupo interfieran entre sí, lo que hace que cada consulta solo lea una parte de los datos. - Esto también puede ocurrir cuando las consultas se inician o reinician en una sucesión rápida. Para minimizar estos problemas, establezca la configuración session.timeout.ms del consumidor de Kafka en un valor muy pequeño. |
| startingOffsets | más antigua, más reciente | latest | [Opcional] Punto inicial cuando se inicia una consulta, ya sea "más antigua", que procede de los desplazamientos más antiguos o bien una cadena JSON, que especifica un desplazamiento inicial para cada TopicPartition. En JSON, se puede usar -2 como compensación para referirse a la más antigua y -1 a la más reciente. Nota: en el caso de las consultas por lotes, no se permite la más reciente (ya sea implícitamente o mediante el uso de -1 en JSON). En el caso de las consultas de streaming, esto solo se aplica cuando se inicia una nueva consulta y esa reanudación siempre se retomará desde dónde se dejó la consulta. Las particiones recién detectadas durante una consulta se iniciarán al principio. |
Consulte Guía de integración de Kafka para streaming estructurado para ver otras configuraciones opcionales.
Esquema para registros de Kafka
El esquema de los registros de Kafka es:
| Columna | Tipo |
|---|---|
| key | binary |
| value | binary |
| topic | string |
| partición | int |
| offset | long |
| timestamp | long |
| timestampType | int |
key y value siempre se deserializan como matrices de bytes con ByteArrayDeserializer. Use operaciones de DataFrame (como cast("string")) para deserializar explícitamente las claves y los valores.
Escritura de datos en Kafka
A continuación se muestra un ejemplo de escritura de flujo a Kafka:
(df
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.start()
)
Azure Databricks también admite la semántica de escritura por lotes para receptores de datos de Kafka, como se muestra en el ejemplo siguiente:
(df
.write
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.save()
)
Configuración de escritor de Structured Streaming de Kafka
Importante
Databricks Runtime 13.3 LTS y versiones posteriores incluyen una versión más reciente de la biblioteca kafka-clients que permite escrituras idempotentes de manera predeterminada. Si un receptor de Kafka usa la versión 2.8.0, o cualquier otra versión inferior con las ACL configuradas, pero sin que IDEMPOTENT_WRITE esté habilitado, se producirá un error en la escritura con el mensaje org.apache.kafka.common.KafkaException: Cannot execute transactional method because we are in an error state.
Para resolver este error, actualice a Kafka versión 2.8.0 o posterior, o estableciendo .option(“kafka.enable.idempotence”, “false”) al configurar el sistema de escritura de Structured Streaming.
El esquema proporcionado a DataStreamWriter interactúa con el receptor de Kafka. Puede usar los campos siguientes:
| Nombre de la columna | Obligatorio u opcional | Tipo |
|---|---|---|
key |
opcional | STRING o BINARY |
value |
requerido | STRING o BINARY |
headers |
opcional | ARRAY |
topic |
opcional (se omite si topic se establece como opción de escritor) |
STRING |
partition |
opcional | INT |
A continuación se muestran las opciones comunes establecidas al escribir en Kafka:
| Opción | Value | Valor predeterminado | Descripción |
|---|---|---|---|
kafka.boostrap.servers |
Lista separada por comas de <host:port> |
None | [Obligatorio] Configuración bootstrap.servers de Kafka. |
topic |
STRING |
Sin establecer | [Opcional] Establece el tema para que se escriban todas las filas. Esta opción invalida cualquier columna de tema que exista en los datos. |
includeHeaders |
BOOLEAN |
false |
[Opcional] Si se van a incluir los encabezados de Kafka en la fila. |
Consulte Guía de integración de Kafka para streaming estructurado para ver otras configuraciones opcionales.
Recuperación de métricas de Kafka
Puede obtener el promedio, el mínimo y el máximo del número de desplazamientos que la consulta de streaming está detrás del desplazamiento disponible más reciente entre todos los temas suscritos con las métricas avgOffsetsBehindLatest, maxOffsetsBehindLatest y minOffsetsBehindLatest. Consulte Lectura interactiva de métricas.
Nota:
Disponible en Databricks Runtime 9.1 y versiones posteriores.
Obtenga el número total estimado de bytes de los temas suscritos que el proceso de consulta no haya consumido mediante una examinación del valor del elemento estimatedTotalBytesBehindLatest. Esta estimación se basa en los lotes procesados en los últimos 300 segundos. El período de tiempo en el que se basa la estimación se puede cambiar estableciendo la opción bytesEstimateWindowLength en otro valor. Por ejemplo, para establecerla en 10 minutos:
df = (spark.readStream
.format("kafka")
.option("bytesEstimateWindowLength", "10m") # m for minutes, you can also use "600s" for 600 seconds
)
Si ejecuta el flujo en un cuaderno, puede ver estas métricas en la pestaña Datos sin procesar en el panel de progreso de la consulta de transmisión:
{
"sources" : [ {
"description" : "KafkaV2[Subscribe[topic]]",
"metrics" : {
"avgOffsetsBehindLatest" : "4.0",
"maxOffsetsBehindLatest" : "4",
"minOffsetsBehindLatest" : "4",
"estimatedTotalBytesBehindLatest" : "80.0"
},
} ]
}
Uso de SSL para conectar Azure Databricks a Kafka
Para habilitar las conexiones SSL a Kafka, siga las instrucciones que se indican en Cifrado y autenticación con SSL de la documentación de Confluent. Puede proporcionar las configuraciones descritas allí, con el prefijo kafka., como opciones. Por ejemplo, especifique la ubicación del almacén de confianza en la propiedad kafka.ssl.truststore.location.
Databricks recomienda que:
- Almacene los certificados en el almacenamiento de objetos en la nube. Puede restringir el acceso a los certificados solo a los clústeres que puedan acceder a Kafka. Consulte Gobernanza de datos con Unity Catalog.
- Almacene las contraseñas de certificado como secretos en un ámbito de secretos.
En el ejemplo siguiente se usan ubicaciones de almacenamiento de objetos y secretos de Databricks para habilitar una conexión SSL:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", ...)
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.ssl.truststore.location", <truststore-location>)
.option("kafka.ssl.keystore.location", <keystore-location>)
.option("kafka.ssl.keystore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<keystore-password-key-name>))
.option("kafka.ssl.truststore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<truststore-password-key-name>))
)
Conexión de Kafka en HDInsight a Azure Databricks
Cree un clúster de Kafka de HDInsight.
Consulte Conexión con Apache Kafka en HDInsight mediante una instancia de Azure Virtual Network para obtener instrucciones.
Configure los agentes de Kafka para que anuncien la dirección correcta.
Siga las instrucciones que se indican en Configuración de Kafka para anunciar direcciones IP. Si administra Kafka usted mismo en Azure Virtual Machines, asegúrese de que la configuración
advertised.listenersde los agentes esté establecida en la dirección IP interna de los hosts.Cree un clúster de Azure Databricks.
Empareje el clúster de Kafka con el clúster de Azure Databricks.
Siga las instrucciones que se indican en Emparejamiento de redes virtuales.
Autenticación de entidad de servicio con Microsoft Entra ID y Azure Event Hubs
Azure Databricks admite la autenticación de trabajos de Spark con servicios de Event Hubs. Esta autenticación se realiza mediante OAuth con Microsoft Entra ID.
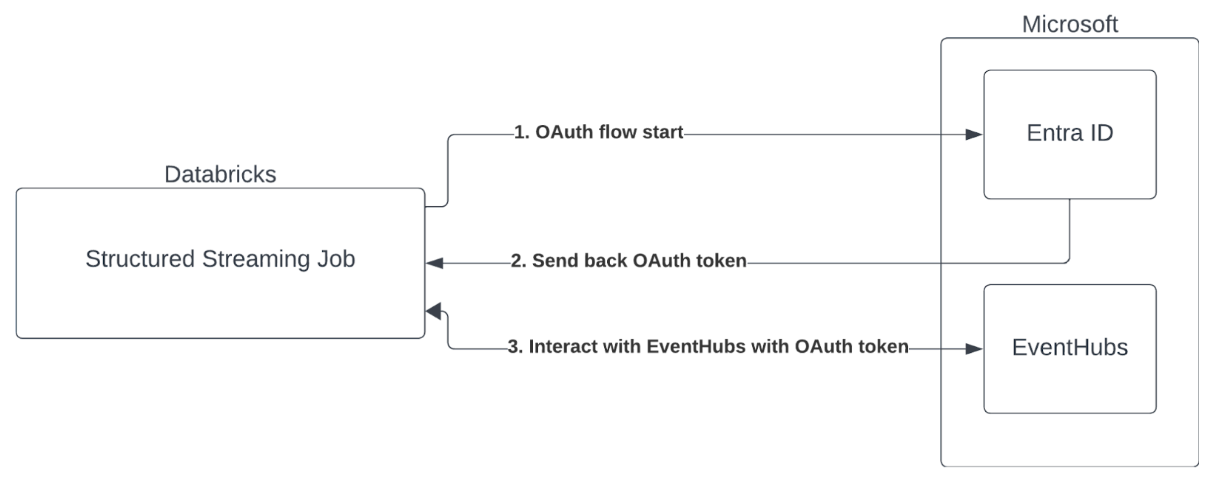
Azure Databricks admite la autenticación de Microsoft Entra ID con un identificador de cliente y un secreto en los siguientes entornos de proceso:
- Databricks Runtime 12.2 LTS y versiones posteriores en el proceso configurado con el modo de acceso de usuario único.
- Databricks Runtime 14.3 LTS y versiones posteriores en el proceso configurado con el modo de acceso compartido.
- Canalizaciones de Delta Live Tables configuradas sin Unity Catalog.
Azure Databricks no admite la autenticación de Microsoft Entra ID con un certificado en cualquier entorno de proceso o en canalizaciones de Delta Live Tables configuradas con Unity Catalog.
Esta autenticación no funciona en clústeres compartidos ni en tablas dinámicas delta de Unity Catalog.
Configuración del conector de Kafka de Structured Streaming
Para realizar la autenticación con Microsoft Entra ID, necesitará los siguientes valores:
Un id. de inquilino. Puede encontrarlo en la pestaña Servicios de Microsoft Entra ID.
Un clientID (también conocido como Application ID).
Un secreto de cliente. Una vez que lo tenga, debe agregarlo como secreto al área de trabajo de Databricks. Para agregar este secreto, consulte Administración de secretos.
Un tema de EventHubs. Puede encontrar una lista de temas en la sección Event Hubs en la sección Entidades de una página específica de espacio de nombres de Event Hubs. Para trabajar con varios temas, puede establecer el rol IAM en el nivel de Event Hubs.
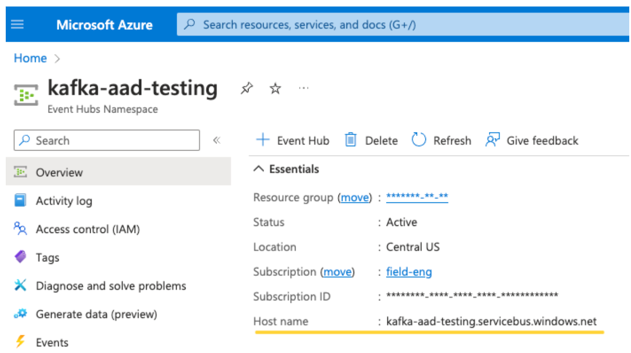
Un servidor de EventHubs. Puede encontrarlo en la página de información general del espacio de nombres de Event Hubs específico:
Además, para usar Entra ID, es necesario indicar a Kafka que use el mecanismo SASL de OAuth (SASL es un protocolo genérico y OAuth es un tipo de "mecanismo" de SASL):
kafka.security.protocoltiene que serSASL_SSLkafka.sasl.mechanismtiene que serOAUTHBEARERkafka.sasl.login.callback.handler.classdebe ser un nombre completo de la clase Java con un valor dekafkashadedpara el controlador de devolución de llamada de inicio de sesión de nuestra clase Kafka sombreada. Consulte el siguiente ejemplo para ver la clase exacta.
Ejemplo
Ahora echemos un vistazo a un ejemplo en ejecución:
Python
# This is the only section you need to modify for auth purposes!
# ------------------------------
tenant_id = "..."
client_id = "..."
client_secret = dbutils.secrets.get("your-scope", "your-secret-name")
event_hubs_server = "..."
event_hubs_topic = "..."
# -------------------------------
sasl_config = f'kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="{client_id}" clientSecret="{client_secret}" scope="https://{event_hubs_server}/.default" ssl.protocol="SSL";'
kafka_options = {
# Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers": f"{event_hubs_server}:9093",
"kafka.sasl.jaas.config": sasl_config,
"kafka.sasl.oauthbearer.token.endpoint.url": f"https://login.microsoft.com/{tenant_id}/oauth2/v2.0/token",
"subscribe": event_hubs_topic,
# You should not need to modify these
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class": "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
}
df = spark.readStream.format("kafka").options(**kafka_options)
display(df)
Scala
// This is the only section you need to modify for auth purposes!
// -------------------------------
val tenantId = "..."
val clientId = "..."
val clientSecret = dbutils.secrets.get("your-scope", "your-secret-name")
val eventHubsServer = "..."
val eventHubsTopic = "..."
// -------------------------------
val saslConfig = s"""kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="$clientId" clientSecret="$clientSecret" scope="https://$eventHubsServer/.default" ssl.protocol="SSL";"""
val kafkaOptions = Map(
// Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers" -> s"$eventHubsServer:9093",
"kafka.sasl.jaas.config" -> saslConfig,
"kafka.sasl.oauthbearer.token.endpoint.url" -> s"https://login.microsoft.com/$tenantId/oauth2/v2.0/token",
"subscribe" -> eventHubsTopic,
// You should not need to modify these
"kafka.security.protocol" -> "SASL_SSL",
"kafka.sasl.mechanism" -> "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class" -> "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
)
val scalaDF = spark.readStream
.format("kafka")
.options(kafkaOptions)
.load()
display(scalaDF)
Control de posibles errores
Las opciones de streaming no se admiten.
Si intenta usar este mecanismo de autenticación en una canalización de Delta Live Tables configurada con Unity Catalog, puede recibir el siguiente error:
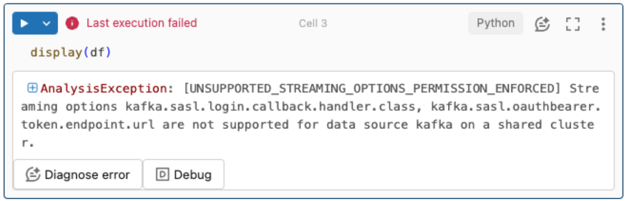
Para resolver este error, use una configuración de proceso compatible. Consulte Autenticación de entidad de servicio con Microsoft Entra ID y Azure Event Hubs.
No se pudo crear un nuevo
KafkaAdminClient.Este es un error interno que Kafka produce si alguna de las siguientes opciones de autenticación es incorrecta:
- Id. de cliente (también conocido como id. de aplicación)
- Id. de inquilino
- Servidor de EventHubs
Para resolver el error, compruebe que los valores son correctos para estas opciones.
Además, es posible que vea este error si modifica las opciones de configuración proporcionadas de forma predeterminada en el ejemplo (que se le pidió que no modifique), como
kafka.security.protocol.No se devuelven registros
Si está intentando mostrar o procesar el DataFrame, pero no obtiene resultados, verá lo siguiente en la interfaz de usuario.
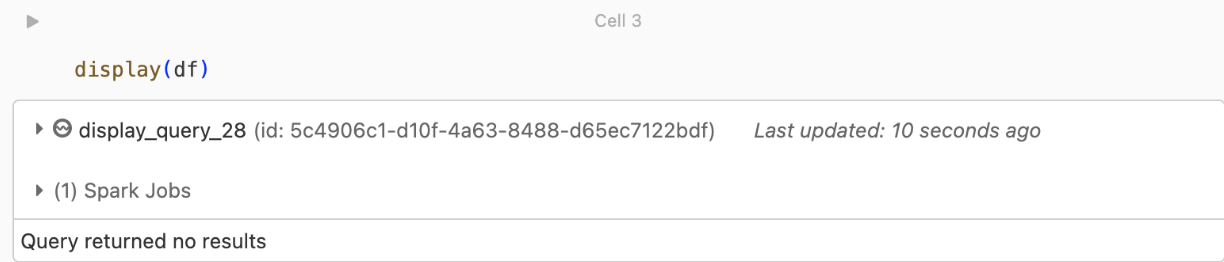
Este mensaje significa que la autenticación se realizó correctamente, pero EventHubs no devolvió ningún dato. Algunas razones posibles (aunque no exhaustivas) son:
- Ha especificado el tema de EventHubs incorrecto.
- La opción de configuración predeterminada de Kafka para
startingOffsetseslatesty, actualmente, no recibe ningún dato a través del tema. Puede establecerstartingOffsetstoearliestpara empezar a leer datos a partir de los desplazamientos más antiguos de Kafka.