Conexión a Google Cloud Storage
En este artículo se describe cómo configurar una conexión desde Azure Databricks para leer y escribir tablas y datos almacenados en Google Cloud Storage (GCS).
Para leer o escribir desde un cubo de GCS, debe crear una cuenta de servicio adjunta y asociar el cubo a la cuenta de servicio. Conéctese al cubo directamente con una clave que genere para la cuenta de servicio.
Acceso a un cubo de GCS directamente con una clave de cuenta de servicio de Google Cloud
Para leer y escribir directamente en un cubo, configure una clave definida en la configuración de Spark.
Paso 1: Configurar una cuenta de servicio de Google Cloud mediante la Consola de Google Cloud
Debe crear una cuenta de servicio para el clúster de Azure Databricks. Databricks recomienda conceder a esta cuenta de servicio los privilegios mínimos necesarios para realizar sus tareas.
Haga clic en IAM y administración en el panel de navegación izquierdo.
Haga clic en Cuentas de servicio.
Haga clic en + CREAR CUENTA DE SERVICIO.
Escriba el nombre y la descripción de la cuenta de servicio.
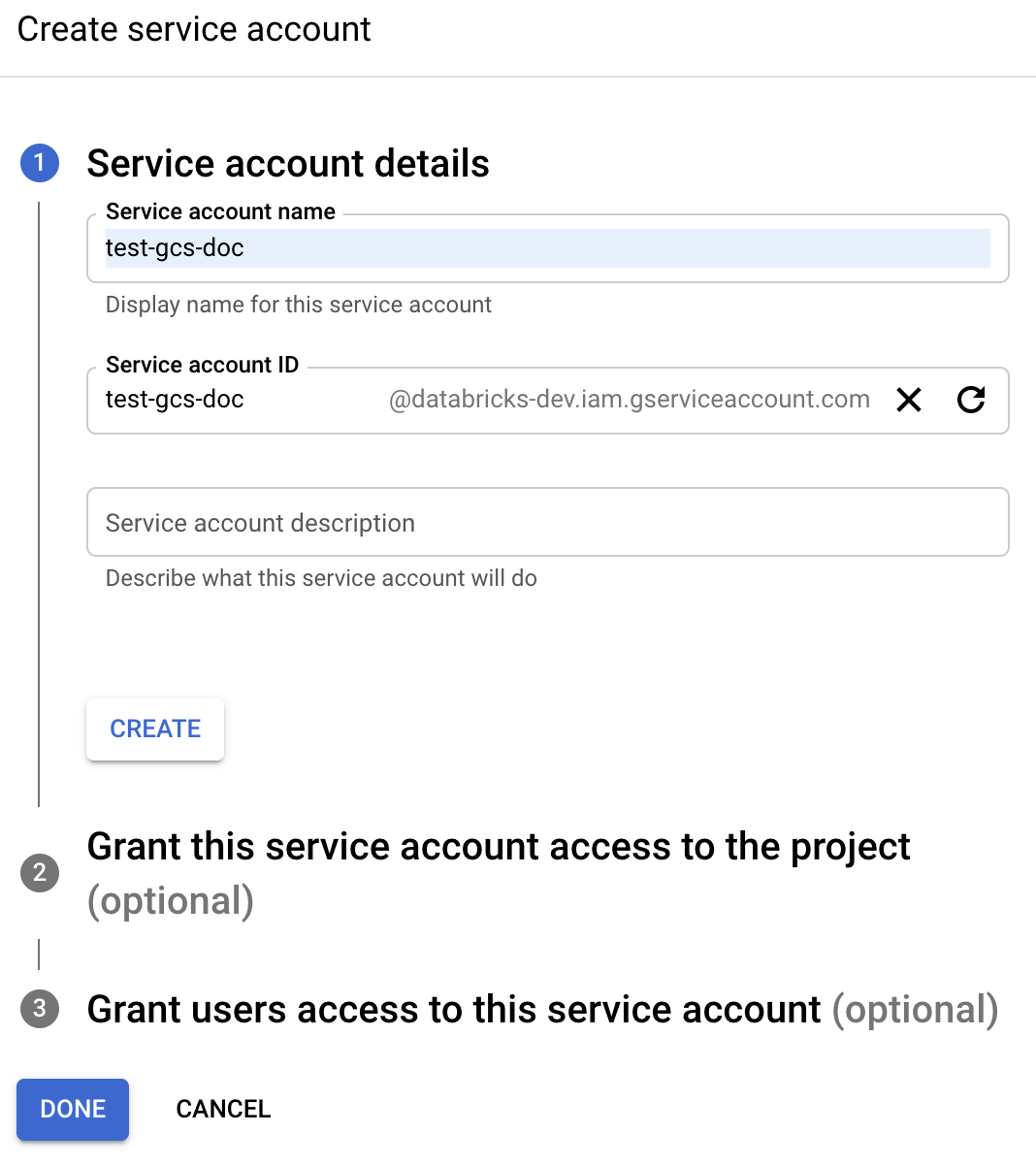
Haga clic en CREATE (Crear).
Haga clic en CONTINUE (Continuar).
Haga clic en LISTO.
Paso 2: Creación de una clave para acceder directamente al cubo de GCS
Advertencia
La clave JSON que se genera para la cuenta de servicio es una clave privada que solo se debe compartir con usuarios autorizados, ya que controla el acceso a conjuntos de datos y recursos de la cuenta de Google Cloud.
- En la Consola de Google Cloud, en la lista de cuentas de servicio, haga clic en la cuenta recientemente creada.
- En la sección Keys (Claves), haga clic en el botón ADD KEY > Create new key (AGREGAR CLAVE > Crear nueva clave).
- Acepte el tipo de clave JSON.
- Haga clic en CREATE (Crear). El archivo de clave se descarga en el equipo.
Paso 3: Configuración del cubo de GCS
Creación de un cubo
Si aún no tiene un cubo, cree uno:
Haga clic en Storage (Almacenamiento) en el panel de navegación izquierdo.
Haga clic en CREATE BUCKET (CREAR CUBO).
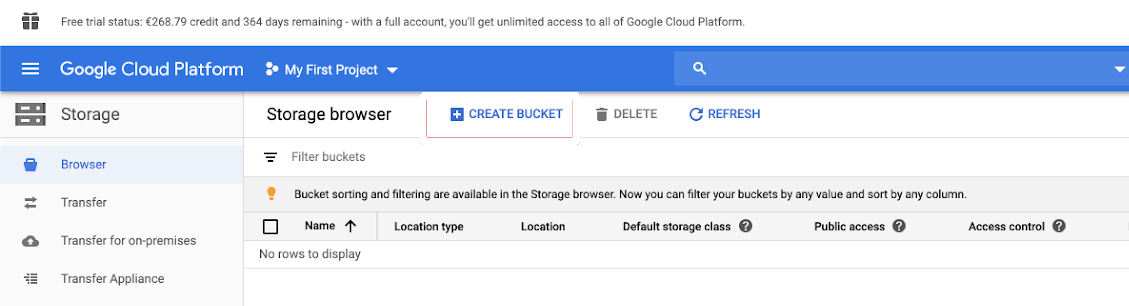
Haga clic en CREATE (Crear).
Configuración del cubo
Configure los detalles del cubo.
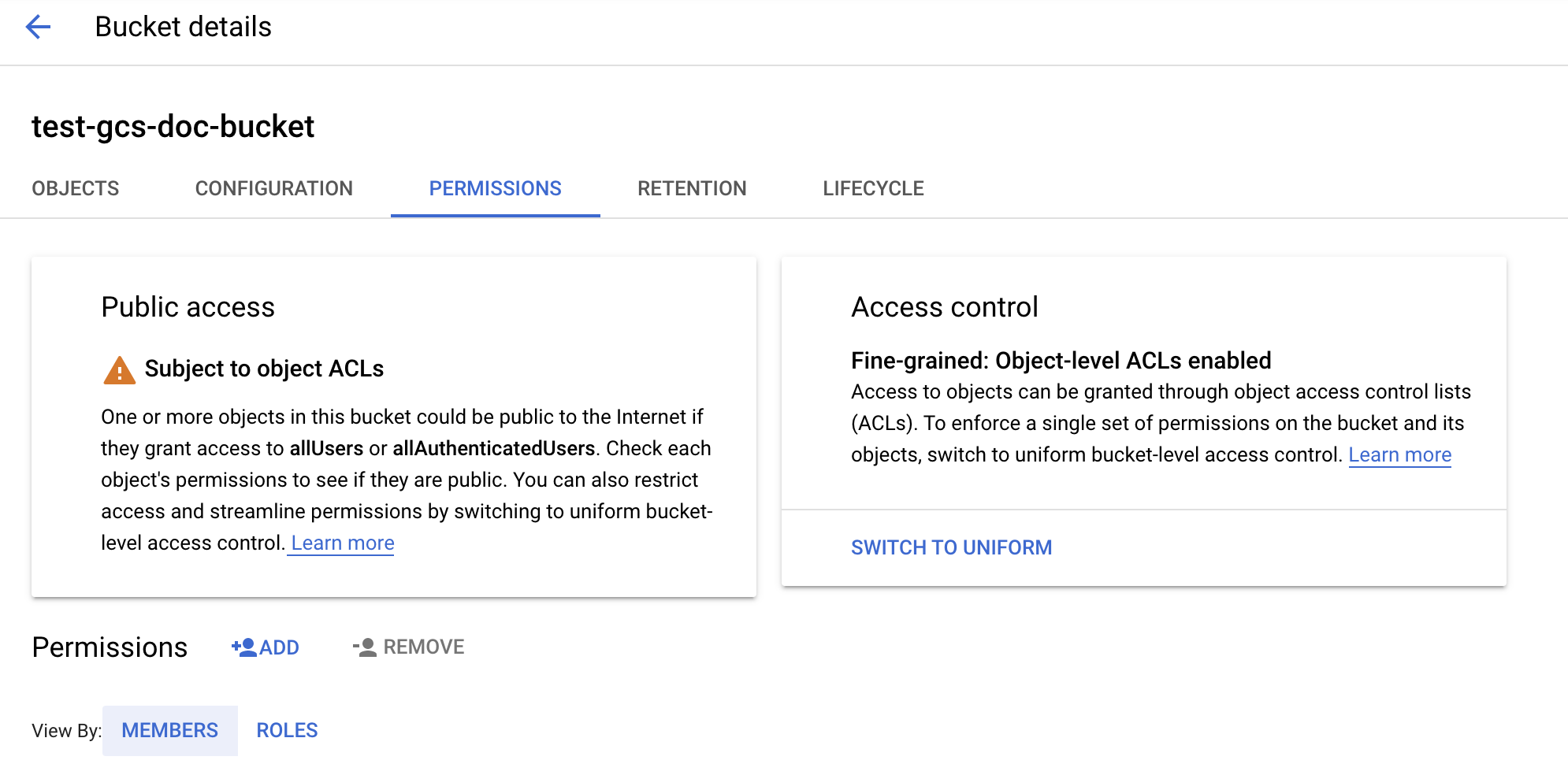
Haga clic en la pestaña Permisos.
Junto a la etiqueta Permissions (Permisos) , haga clic en ADD (AGREGAR).
Proporcione el permiso Administrador de Storage a la cuenta de servicio en el cubo de los roles de Cloud Storage.
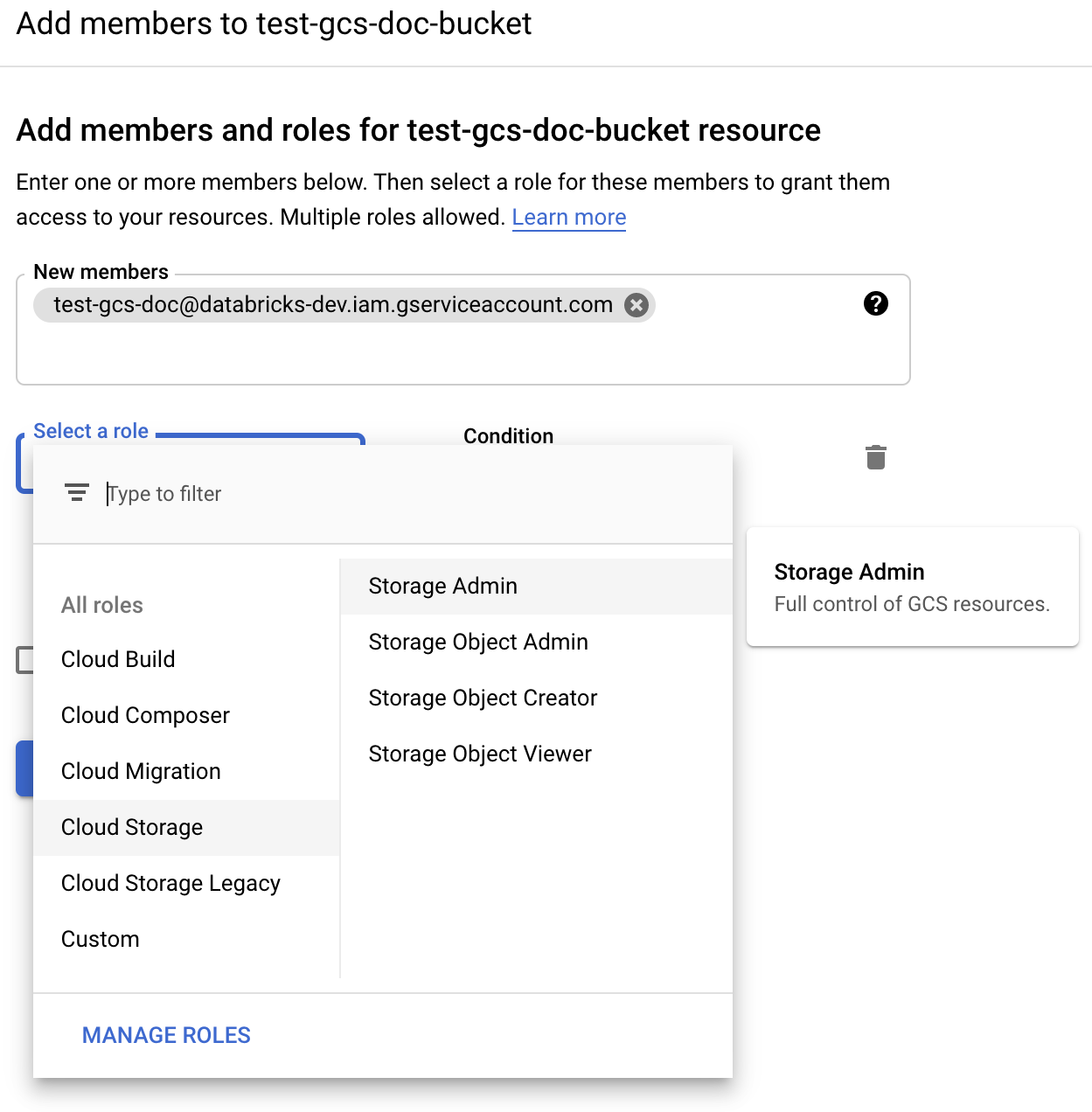
Haga clic en GUARDAR.
Paso 4: Colocación de la clave de cuenta de servicio en secretos de Databricks
El equipo de Databricks recomienda que se usen ámbitos secretos para almacenar todas las credenciales. Puede colocar la clave privada y el identificador de clave privada del archivo JSON de clave en ámbitos secretos de Databricks. Puede otorgar a los usuarios, entidades de servicio y grupos de su área de trabajo acceso para leer el ámbito secreto. Esto protege la clave de la cuenta de servicio, al tiempo que permite a los usuarios acceder a GCS. Para crear un ámbito de secreto, consulte Administración de secretos.
Paso 5: Configuración de un clúster de Azure Databricks
En la pestaña Configuración de Spark, defina una configuración global o una configuración por cubo. En los ejemplos siguientes se establecen las claves mediante valores almacenados como secretos de Databricks.
Nota:
Use el control de acceso del clúster y el control de acceso de cuadernos juntos para proteger el acceso a la cuenta de servicio y a los datos del cubo de GCS. Consulte Permisos de proceso y Colaborar mediante cuadernos de Databricks.
Configuración global
Utilice esta configuración si se deben utilizar las credenciales proporcionadas para acceder a todos los cubos.
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id {{secrets/scope/gsa_private_key_id}}
Reemplace <client-email> y <project-id> por los valores de esos nombres de campo exactos del archivo JSON de clave.
Configuración por cubo
Utilice esta configuración si debe configurar las credenciales para depósitos específicos. La sintaxis de la configuración por cubo anexa el nombre del cubo al final de cada configuración, como en el ejemplo siguiente.
Importante
Las configuraciones por cubo se pueden utilizar además de las configuraciones globales. Cuando se especifica, las configuraciones por cubo superponen las configuraciones globales.
spark.hadoop.google.cloud.auth.service.account.enable.<bucket-name> true
spark.hadoop.fs.gs.auth.service.account.email.<bucket-name> <client-email>
spark.hadoop.fs.gs.project.id.<bucket-name> <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key.<bucket-name> {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id.<bucket-name> {{secrets/scope/gsa_private_key_id}}
Reemplace <client-email> y <project-id> por los valores de esos nombres de campo exactos del archivo JSON de clave.
Paso 6: Lectura de GCS
Para leer desde el cubo de GCS, use un comando de lectura de Spark en cualquier formato compatible como, por ejemplo:
df = spark.read.format("parquet").load("gs://<bucket-name>/<path>")
Para escribir en el cubo de GCS, use un comando de escritura de Spark en cualquier formato compatible como, por ejemplo:
df.write.mode("<mode>").save("gs://<bucket-name>/<path>")
Reemplace <bucket-name> por el nombre del cubo que ha creado en el Paso 3: Configuración del cubo de GCS.