Configuración de proceso (antiguo)
Nota:
Estas son instrucciones para la interfaz de usuario de creación de clústeres heredada y solo se incluyen para obtener precisión histórica. Todos los clientes deben usar la interfaz de usuario de creación de clústeres actualizada.
En este artículo se explican las opciones de configuración disponibles al crear y editar clústeres de Azure Databricks. Se centra en la creación y edición de clústeres mediante la interfaz de usuario. Para otros métodos, consulte la CLI de Databricks, la API de clústeres y el proveedor de Terraform de Databricks.
Para obtener ayuda para decidir qué combinación de opciones de configuración se adapta mejor a sus necesidades, consulte Procedimientos recomendados de configuración de clústeres.
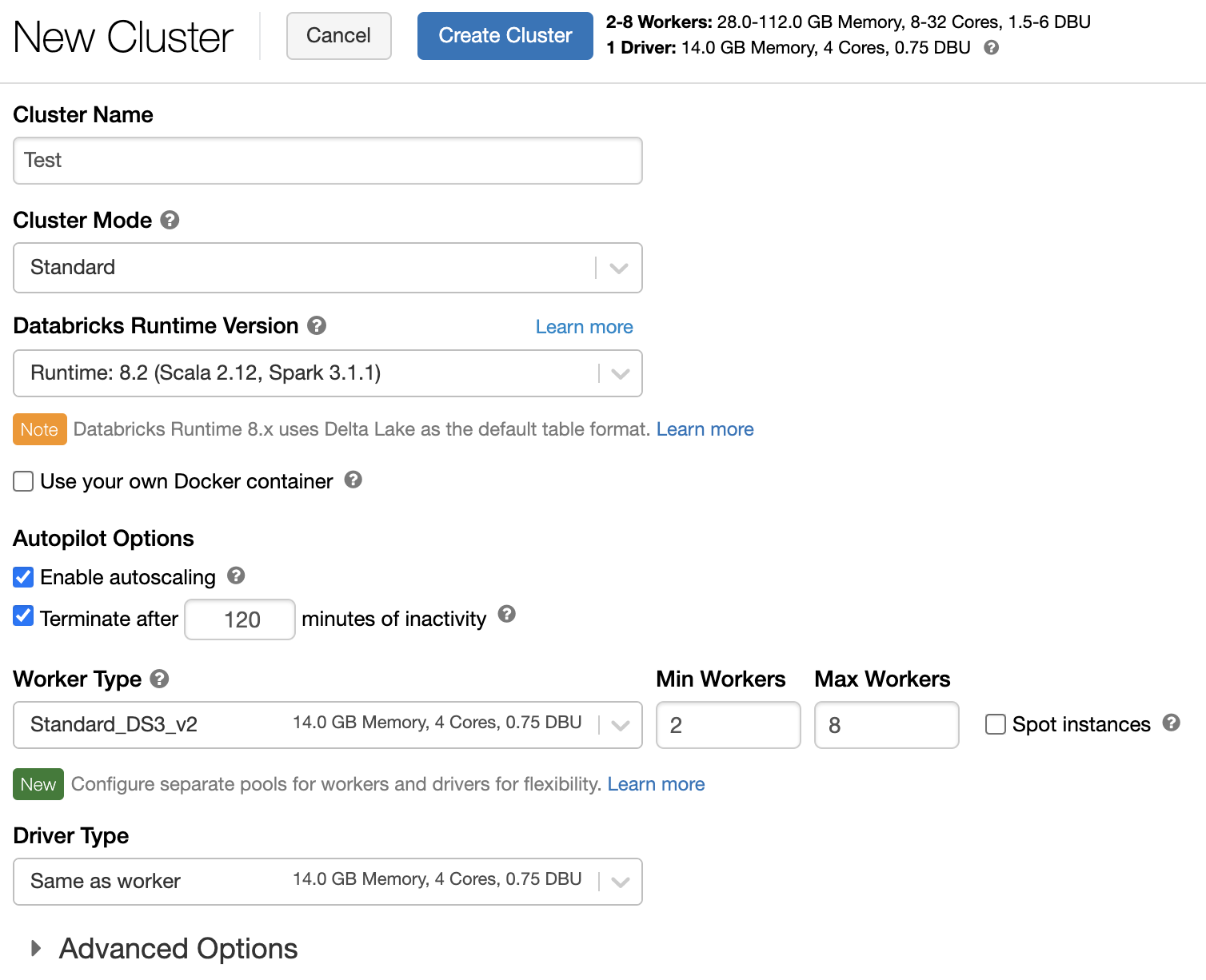
Directiva de clúster
Una directiva de clúster limita la capacidad de configurar clústeres en función de un conjunto de reglas. Las reglas de directiva limitan los atributos o los valores de atributo disponibles para la creación del clúster. Las directivas de clúster tienen ACL que limitan su uso a usuarios y grupos específicos y, por tanto, limitan las directivas que puede seleccionar al crear un clúster.
Para configurar una directiva de clúster, seleccione la directiva de clúster en la lista desplegable Directiva.
Nota:
Si no se ha creado ninguna directiva en el área de trabajo, la lista desplegable Directiva no se muestra.
Si tiene:
- Permiso de creación de clústeres, puede seleccionar la directiva Sin restricciones y crear clústeres totalmente configurables. La directiva Sin restricciones no limita los atributos de clúster ni los valores de atributo.
- Tanto con el permiso de creación de clústeres como con el acceso a las directivas de clúster, puede seleccionar la directiva Sin restricciones y las directivas a las que tiene acceso.
- Con acceso solo a las directivas de clúster, puede seleccionar las directivas a las que tiene acceso.
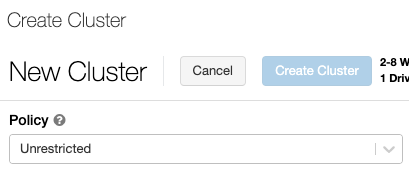
Modo de clúster
Nota:
En este artículo se describe la interfaz de usuario heredada de los clústeres. Para obtener información sobre la nueva interfaz de usuario de clústeres (en versión preliminar), vea Referencia de configuración de proceso. Esto incluye algunos cambios en la terminología de los modos y tipos de acceso del clúster. Para ver una comparación entre los tipos de clúster nuevos y los heredados, consulte Cambios en la interfaz de usuario de los clústeres y modos de acceso del clúster. En la interfaz de usuario en versión preliminar:
- Los clústeres en modo estándar ahora se denominan clústeres en modo de acceso compartido sin aislamiento.
- Los clústeres de alta simultaneidad con ACL de tabla ahora se denominan clústeres en modo de acceso compartido.
Azure Databricks es compatible con tres modos de clúster: estándar, de alta simultaneidad y de nodo único. El modo de clúster predeterminado es el estándar.
Importante
- Si el área de trabajo se ha asignado a un metastore del catálogo de Unity, los clústeres de alta simultaneidad no estarán disponibles. En su lugar, se usa el modo de acceso para garantizar la integridad de los controles de acceso y aplicar garantías de aislamiento sólidas. Consulte también Modos de acceso.
- No se puede cambiar el modo de clúster después de crear un clúster. Si desea un modo de clúster diferente, debe crear un nuevo clúster.
La configuración del clúster incluye una opción de configuración de terminación automática, cuyo valor predeterminado depende del modo de clúster:
- Los clústeres de nodo único y estándar finalizan automáticamente después de 120 minutos de forma predeterminada.
- Los clústeres de alta simultaneidad no finalizan automáticamente de forma predeterminada.
Clústeres estándar
Advertencia
Los clústeres en modo estándar (a veces denominados clústeres compartidos sin aislamiento) pueden compartirse entre varios usuarios, sin aislamiento entre los usuarios. Si usa el modo de clúster de alta simultaneidad sin opciones de seguridad adicionales, como las ACL de tabla o el acceso directo a credenciales, se usan las mismas opciones que en los clústeres en modo estándar. Los administradores de cuentas pueden impedir que se generen automáticamente credenciales internas para los administradores del área de trabajo de Databricks en estos tipos de clúster. Para unas opciones más seguras, Databricks recomienda alternativas como clústeres de alta simultaneidad con ACL de tabla.
Se recomienda un clúster estándar solo para usuarios únicos. Los clústeres estándar pueden ejecutar cargas de trabajo desarrolladas en Python, SQL, R y Scala.
Clústeres de alta simultaneidad
Un clúster de alta simultaneidad es un recurso en la nube administrado. Las principales ventajas de los clústeres de alta simultaneidad son que proporcionan un uso compartido específico para maximizar el uso de recursos y latencias de consulta mínimas.
Los clústeres de alta simultaneidad pueden ejecutar cargas de trabajo desarrolladas SQL, Python y R. El rendimiento y la seguridad de los clústeres de alta simultaneidad se proporcionan mediante la ejecución de código de usuario en procesos independientes, lo que no es posible en Scala.
Además, solo los clústeres de alta simultaneidad admiten el control de acceso a tablas.
Para crear un clúster de alta simultaneidad, establezca Modo de clúster en Alta simultaneidad.
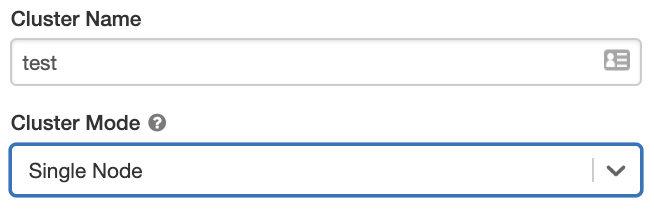
Clústeres de nodo único
Un clúster de nodo único no tiene trabajos y ejecuta trabajos de Spark en el nodo del controlador.
En cambio, un clúster estándar requiere al menos un nodo de trabajo de Spark además del nodo de controlador para ejecutar trabajos de Spark.
Para crear un clúster de nodo único, establezca Modo de clúster en Nodo único.
Para más información sobre cómo trabajar con clústeres de nodo único, vea proceso de un solo nodo o de varios nodos.
Grupos
Para reducir la hora de inicio del clúster, puede asociar un clúster a un grupo predefinido de instancias inactivas para los nodos de controlador y de trabajo. El clúster se crea mediante instancias en los grupos. Si el grupo no tiene suficientes recursos inactivos para crear los nodos de controlador o de trabajo solicitados, el grupo se expande mediante la asignación de nuevas instancias del proveedor de instancias. Cuando finaliza un clúster asociado, las instancias que ha usado se devuelven a los grupos y otro clúster puede reutilizarlas.
Si selecciona un grupo para los nodos de trabajo, pero no para el nodo de controlador, el nodo de controlador hereda el grupo de la configuración del nodo de trabajo.
Importante
Si intenta seleccionar un grupo para el nodo de controlador, pero no para los nodos de trabajo, se produce un error y no se crea el clúster. Este requisito evita una situación en la que el nodo de controlador tiene que esperar a que se creen nodo de trabajo, o viceversa.
Vea Referencia de configuración de grupo para más información sobre cómo trabajar con grupos en Azure Databricks.
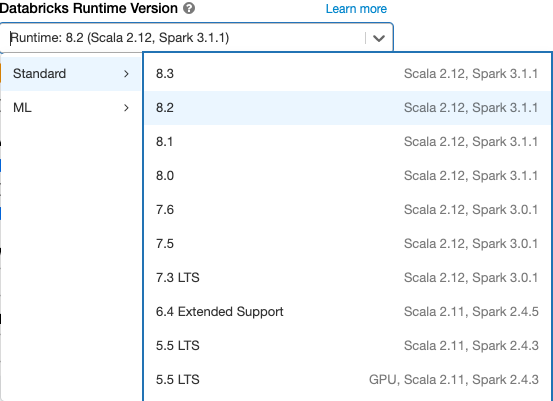
Databricks Runtime
Las instancias de Databricks Runtime son el conjunto de componentes principales que se ejecutan en sus clústeres. Todas las instancias de Databricks Runtime incluyen Apache Spark y agregan componentes y actualizaciones que mejoran la facilidad de uso, el rendimiento y la seguridad. Para obtener más detalles, vea las notas de la versión de Databricks Runtime y compatibilidad.
Azure Databricks ofrece varios tipos de entornos de ejecución y varias versiones de dichos tipos en la lista desplegable Versión de Databricks Runtime al crear o editar un clúster.
Aceleración de Photon
Photon está disponible para clústeres que ejecutan Databricks Runtime 9.1 LTS y versiones posteirores.
Para habilitar la aceleración de Photon, active la casilla Usar aceleración de Photon.
Si lo desea, puede especificar el tipo de instancia en la lista desplegable Tipo de trabajo y Tipo de controlador.
Databricks recomienda los siguientes tipos de instancia para obtener un precio y un rendimiento óptimos:
- Standard_E4ds_v4
- Standard_E8ds_v4
- Standard_E16ds_v4
Puede ver la actividad de Photon en la interfaz de usuario de Spark. En la captura de pantalla siguiente se muestra el DAG de detalles de la consulta. Hay dos indicaciones de Photon en el DAG. En primer lugar, los operadores de Photon comienzan con "Photon", por ejemplo, PhotonGroupingAgg. En segundo lugar, en el DAG, los operadores y las fases de Photon son de color melocotón, mientras que el resto son azules.

Imágenes de Docker
Para algunas versiones de Databricks Runtime, puede especificar una imagen de Docker al crear un clúster. Entre los casos de uso de ejemplo se incluyen la personalización de la biblioteca, un entorno de contenedor modelo que no cambia y la integración de CI/CD de Docker.
También puede usar imágenes de Docker para crear entornos de aprendizaje profundo personalizados en clústeres con dispositivos GPU.
Para obtener instrucciones, consulte Personalización de contenedores con el servicio de contenedor de Databricks y Servicios de contenedor de Databricks en procesos de GPU.
Tipo de nodo de clúster
Un clúster consta de un nodo de controlador y ninguno o varios nodos de trabajo.
Puede elegir tipos de instancia de proveedor de nube independientes para los nodos de controlador y de trabajo, aunque de forma predeterminada el nodo de controlador usa el mismo tipo de instancia que el nodo de trabajo. Las distintas familias de tipos de instancia se ajustan a distintos casos de uso, como cargas de trabajo con un uso intensivo de memoria o de proceso intensivo.
Nota:
Si los requisitos de seguridad incluyen aislamiento de proceso, seleccione una instancia Standard_F72s_V2 como tipo de trabajo. Estos tipos de instancia representan máquinas virtuales aisladas que consumen todo el host físico y proporcionan el nivel de aislamiento necesario para admitir, por ejemplo, las cargas de trabajo de nivel de impacto 5 (IL5) del Departamento de Defensa de Estados Unidos.
Nodo de controlador
El nodo de controlador mantiene la información de estado de todos los cuadernos asociados al clúster. El nodo de controlador también mantiene SparkContext e interpreta todos los comandos que se ejecutan desde un cuaderno o una biblioteca en el clúster, y ejecuta el maestro de Apache Spark que se coordina con los ejecutores de Spark.
El valor predeterminado del tipo de nodo de controlador es el mismo que el tipo de nodo de trabajo. Puede elegir un tipo de nodo de controlador mayor con más memoria si planea collect() una gran cantidad de datos de los trabajadores de Spark y analizarlos en el cuaderno.
Sugerencia
Puesto que el nodo de controlador mantiene toda la información de estado de los cuadernos asociados, asegúrese de desasociar los cuadernos no utilizados del nodo de controlador.
Nodo de trabajo
Los nodos de trabajo de Azure Databricks ejecutan los ejecutores de Spark y otros servicios necesarios para el correcto funcionamiento de los clústeres. Al distribuir la carga de trabajo con Spark, todo el procesamiento distribuido se produce en los nodos de trabajo. Azure Databricks ejecuta un ejecutor por nodo de trabajo; por lo tanto, los términos ejecutor y trabajador se usan indistintamente en el contexto de la arquitectura de Azure Databricks.
Sugerencia
Para ejecutar un trabajo de Spark, necesita al menos un rol de trabajo. Si un clúster no tiene ningún trabajo, puede ejecutar comandos que no son de Spark en el nodo de controlador, pero se producirá un error en los comandos de Spark.
Tipos de instancia de GPU
Para tareas computacionalmente complejas que exigen un alto rendimiento, como las asociadas al aprendizaje profundo, Azure Databricks admite clústeres acelerados con unidades de procesamiento de gráficos (GPU). Para más información, consulte Procesos habilitados para GPU.
Instancias de acceso puntual
Para ahorrar costos, puede optar por usar instancias de Spot, también conocidas como VM de Azure Spot. Para ello, active la casilla Instancias de Spot.

La primera instancia siempre será a petición (el nodo de controlador siempre es a petición) y las instancias posteriores serán instancias de Spot. Si las instancias de Spot se expulsan debido a la falta de disponibilidad, las instancias a petición se implementarán para reemplazar las instancias expulsadas.
Tamaño del clúster y escalado automático
Al crear un clúster de Azure Databricks, puede proporcionar un número fijo de roles de trabajo o bien, las cantidades mínima y máxima de roles de trabajo para el clúster.
Si proporciona un clúster de tamaño fijo, Azure Databricks garantiza que el clúster tiene el número especificado de trabajos. Si proporciona un intervalo para el número de trabajos, Databricks elige el número adecuado de trabajos necesarios para ejecutar el trabajo. Esto se conoce como escalado automático.
Con el escalado automático, Azure Databricks reasigna de forma dinámica los trabajos para que tengan en cuenta las características de su trabajo. Algunas partes de la canalización pueden ser más exigentes computacionalmente que otras, y Databricks agrega automáticamente trabajos adicionales durante estas fases del trabajo (y los quita cuando ya no son necesarios).
El escalado automático hace que sea más fácil lograr un uso del clúster elevado, ya que no es necesario aprovisionar ese clúster para que coincida con una carga de trabajo. Esto se aplica especialmente a las cargas de trabajo cuyos requisitos cambian con el tiempo (como explorar un conjunto de datos en el transcurso de un día), pero también se puede aplicar a una carga de trabajo única más corta cuyos requisitos de aprovisionamiento se desconocen. Por lo tanto, el escalado automático ofrece dos ventajas:
- Las cargas de trabajo se pueden ejecutar más rápido en comparación con un clúster de tamaño constante infraaprovisionado.
- El escalado automático de clústeres puede reducir los costos generales en comparación con un clúster de tamaño estático.
En función del tamaño constante del clúster y la carga de trabajo, el escalado automático le ofrece una o ambas ventajas al mismo tiempo. El tamaño del clúster puede estar por debajo del número mínimo de trabajos seleccionados cuando el proveedor de nube finaliza las instancias. En este caso, Azure Databricks reintenta de forma continua volver a aprovisionar instancias con el fin de mantener el número mínimo de trabajos.
Nota:
El escalado automático no está disponible para los trabajos de spark-submit.
Cómo se comporta el escalado automático
- Permite el escalado vertical de mínimo o máximo en dos pasos.
- Puede realizar la reducción vertical aunque el clúster no esté inactivo si observa el estado de archivo aleatorio.
- Realiza la reducción vertical en función de un porcentaje de los nodos actuales.
- En los clústeres de trabajos, realiza la reducción vertical si el clúster se ha infrautilizado en los últimos 40 segundos.
- En los clústeres multiuso, realiza la reducción vertical si el clúster se ha infrautilizado en los últimos 150 segundos.
- La propiedad
spark.databricks.aggressiveWindowDownSde configuración de Spark especifica en segundos la frecuencia con la que un clúster toma decisiones de reducción vertical. Al aumentar el valor, la reducción vertical de un clúster se realiza más lentamente. El valor máximo es 600.
Habilitación y configuración del escalado automático
Para permitir que Azure Databricks cambie el tamaño del clúster automáticamente, habilite el escalado automático para el clúster y proporcione el intervalo mínimo y máximo de trabajos.
Habilite el escalado automático.
Clúster multiuso: en la página Crear clúster, active la casilla Habilitar escalado automático en el cuadro Opciones de Autopilot:

Clúster de trabajos: en la página Configurar clúster, active la casilla Habilitar escalado automático en el cuadro Opciones de Autopilot:

Configure los trabajos mínimo y máximo.

Cuando se ejecuta el clúster, la página de detalles del clúster muestra el número de trabajos asignados. Puede comparar el número de trabajos asignados con la configuración de trabajo y realizar ajustes según sea necesario.
Importante
Si usa un grupo de instancias:
- Asegúrese de que el tamaño del clúster solicitado es menor o igual que el número mínimo de instancias inactivas del grupo. Si es mayor, el tiempo de inicio del clúster será equivalente a un clúster que no use un grupo.
- Asegúrese de que el tamaño máximo del clúster sea menor o igual que la capacidad máxima del grupo. Si es mayor, se producirá un error en la creación del clúster.
Ejemplo de escalado automático
Si vuelve a configurar un clúster estático para que sea un clúster de escalado automático, Azure Databricks cambia inmediatamente el tamaño del clúster dentro de los límites mínimo y máximo y, a continuación, inicia el escalado automático. Por ejemplo, en la tabla siguiente se muestra lo que sucede con los clústeres con un tamaño inicial determinado si se vuelve a configurar un clúster para escalar automáticamente entre 5 y 10 nodos.
| Tamaño inicial | Tamaño después de la reconfiguración |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
Escalado automático del almacenamiento local
A menudo puede ser difícil calcular cuánto espacio en disco necesitará un trabajo determinado. Para evitar tener que calcular cuántos gigabytes de disco administrado se deben asociar al clúster en el momento de su creación, Azure Databricks habilita automáticamente el escalado automático del almacenamiento local en todos los clústeres de Azure Databricks.
Con el escalado automático del almacenamiento local, Azure Databricks supervisa la cantidad de espacio libre en disco disponible en los trabajos de Spark del clúster. Si un trabajo comienza a ejecutarse con demasiado poco espacio en el disco, Databricks asocia automáticamente un nuevo disco administrado al trabajo antes de que se agote el espacio en disco. Los discos tienen asociado un límite de hasta 5 TB de espacio total en disco por máquina virtual (incluido el almacenamiento local inicial de la máquina virtual).
Los discos administrados conectados a una máquina virtual solo se desasocian cuando la máquina virtual se devuelve a Azure. Es decir, los discos administrados nunca se desasocian de una máquina virtual, siempre que formen parte de un clúster en ejecución. Para reducir verticalmente el uso del disco administrado, Azure Databricks recomienda usar esta característica en un clúster configurado con tamaño del clúster y escalado automático o terminación inesperada.
Cifrado de discos locales
Importante
Esta característica está en versión preliminar pública.
Algunos tipos de instancia que se usan para ejecutar clústeres pueden tener discos conectados localmente. Azure Databricks puede almacenar datos aleatorios o datos efímeros en estos discos conectados localmente. Para asegurarse de que todos los datos en reposo se cifran para todos los tipos de almacenamiento, incluidos los datos aleatorios que se almacenan temporalmente en los discos locales del clúster, puede habilitar el cifrado de disco local.
Importante
Las cargas de trabajo pueden ejecutarse más lentamente debido al impacto en el rendimiento de la lectura y escritura de datos cifrados hacia y desde los volúmenes locales.
Cuando el cifrado de disco local está habilitado, Azure Databricks genera una clave de cifrado localmente que es única para cada nodo del clúster y que se usa para cifrar todos los datos almacenados en discos locales. El ámbito de la clave es local para cada nodo del clúster y se destruye junto con el propio nodo del clúster. Durante su vigencia, la clave reside en la memoria para el cifrado y el descifrado, y se almacena cifrada en el disco.
Para habilitar el cifrado de disco local, debe usar la API de clústeres. Durante la creación o edición del clúster, establezca:
{
"enable_local_disk_encryption": true
}
Consulte la API de clústeres para ver ejemplos de cómo invocar estas API.
Este es un ejemplo de una llamada de creación de clúster que habilita el cifrado de disco local:
{
"cluster_name": "my-cluster",
"spark_version": "7.3.x-scala2.12",
"node_type_id": "Standard_D3_v2",
"enable_local_disk_encryption": true,
"spark_conf": {
"spark.speculation": true
},
"num_workers": 25
}
Modo de seguridad
Si el área de trabajo está asignada a un metastore del catálogo de Unity, use el modo de seguridad en lugar del modo de clústeres de alta simultaneidad para garantizar la integridad de los controles de acceso y aplicar garantías de aislamiento sólidas. El modo de clúster de alta simultaneidad no está disponible con Unity Catalog.
En Opciones avanzadas, seleccione entre los siguientes modos de seguridad de clúster:
- None (Ninguno): sin aislamiento. No aplica el control de acceso a la tabla local del área de trabajo ni credenciales transferidas. No se puede acceder a los datos de Unity Catalog.
- Single User (Usuario único): solo lo puede utilizar un usuario (de forma predeterminada, el usuario que creó el clúster). Otros usuarios no se pueden conectar al clúster. Al acceder a una vista desde un clúster con el modo de seguridad Single User (Usuario único), la vista se ejecuta con los permisos del usuario. Los clústeres de usuario único admiten cargas de trabajo con scripts de Python, Scala y R. Init, instalación de biblioteca y montajes dbFS se admiten en clústeres de usuario único. Los trabajos automatizados deben usar clústeres de usuario único.
- User Isolation (Aislamiento de usuarios): se puede compartir con varios usuarios. Solo se admiten cargas de trabajo de SQL. La instalación de bibliotecas, los scripts de inicialización y los montajes de DBFS están deshabilitados para aplicar un aislamiento estricto entre los usuarios del clúster.
- Table ACL only (Legacy) [Solo ACL de tabla (heredado)]: aplica el control de acceso a la tabla local del área de trabajo, pero no puede acceder a los datos de Unity Catalog.
- Passthrough only (Legacy) [Solo credenciales transferidas (heredado)]: aplica el uso de credenciales transferidas del área de trabajo local, pero no puede acceder a los datos de Unity Catalog.
Los únicos modos de seguridad admitidos para las cargas de trabajo de Unity Catalog son Single User (Usuario único) y User Isolation (Aislamiento de usuarios).
Para obtener más información, vea Modos de acceso.
Configuración de Spark
Para ajustar los trabajos de Spark, puede proporcionar propiedades de configuración de Spark personalizadas en una configuración de clúster.
En la página de configuración del clúster, haga clic en el botón de alternancia Opciones avanzadas.
Haga clic en la pestaña Spark.
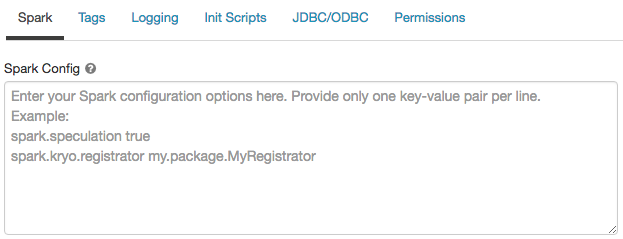
En Configuración de Spark, escriba las propiedades de configuración como un par clave-valor por línea.
Cuando configure un clúster mediante la API de clúster, establezca las propiedades de Spark en el campo spark_conf de la API Crear nuevo clúster de API o Actualizar la API de configuración del clúster.
Databricks no recomienda usar scripts de inicialización globales.
Para establecer las propiedades de Spark para todos los clústeres, cree un script init global:
dbutils.fs.put("dbfs:/databricks/init/set_spark_params.sh","""
|#!/bin/bash
|
|cat << 'EOF' > /databricks/driver/conf/00-custom-spark-driver-defaults.conf
|[driver] {
| "spark.sql.sources.partitionOverwriteMode" = "DYNAMIC"
|}
|EOF
""".stripMargin, true)
Recuperación de una propiedad de configuración de Spark de un secreto
Databricks recomienda almacenar información confidencial, como contraseñas, en un secreto en lugar de almacenarla como texto no cifrado. Para hacer referencia a un secreto en la configuración de Spark, use la sintaxis siguiente:
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
Por ejemplo, para establecer una propiedad de configuración de Spark llamada password en el valor del secreto almacenado en secrets/acme_app/password:
spark.password {{secrets/acme-app/password}}
Para obtener más información, consulte Administración de secretos.
Variables de entorno
Puede configurar variables de entorno personalizadas a las que pueda acceder desde scripts de inicialización que se ejecutan en un clúster. Databricks también ofrece variables de entorno predefinidas que se pueden usar en los scripts de inicialización. No puede invalidar estas variables de entorno predefinidas.
En la página de configuración del clúster, haga clic en el botón de alternancia Opciones avanzadas.
Haga clic en la pestaña Spark.
Establezca las variables de entorno en el campo Variables de entorno.
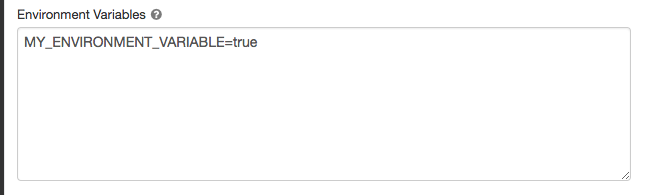
También puede establecer variables de entorno mediante el campo spark_env_vars de la API de creación de nuevos clústeres o la API de actualización de la configuración de clústeres.
Etiquetas del clúster
Las etiquetas de clúster permiten supervisar fácilmente el costo de los recursos en la nube que usan los diferentes grupos de la organización. Puede especificar etiquetas como pares clave-valor al crear un clúster, y Azure Databricks aplica estas etiquetas a recursos en la nube, como VM y volúmenes de disco, así como a informes de uso de DBU.
En el caso de los clústeres iniciados desde grupos, las etiquetas de clúster personalizadas solo se aplican a los informes de uso de DBU y no se propagan a los recursos en la nube.
Para obtener información detallada sobre cómo funcionan conjuntamente los tipos de etiquetas de grupo y clúster, consulte Uso de atributos mediante etiquetas.
Por comodidad, Azure Databricks aplica cuatro etiquetas predeterminadas a cada clúster: Vendor, Creator, ClusterName y ClusterId.
Además, en los clústeres de trabajos, Azure Databricks aplica dos etiquetas predeterminadas: RunName y JobId.
En los recursos usados por Databricks SQL, Azure Databricks aplica también la etiqueta predeterminada SqlWarehouseId.
Advertencia
No asigne una etiqueta personalizada con la clave Name a un clúster. Cada clúster tiene una etiqueta Name con el valor establecido por Azure Databricks. Si cambia el valor asociado a la clave Name, Azure Databricks ya no puede realizar el seguimiento del clúster. Como consecuencia, es posible que el clúster no finalice después de quedarse inactivo y que siga incurriendo en costos de uso.
Puede agregar etiquetas personalizadas al crear un clúster. Para configurar etiquetas de clúster:
En la página de configuración del clúster, haga clic en el botón de alternancia Opciones avanzadas.
En la parte inferior de la página, haga clic en la pestaña Etiquetas.

Agregue un par clave-valor para cada etiqueta personalizada. Puede agregar hasta 43 etiquetas personalizadas.
Acceso SSH a los clústeres
Por motivos de seguridad, el puerto SSH está cerrado de forma predeterminada en Azure Databricks. Si desea habilitar el acceso SSH a los clústeres de Spark, póngase en contacto con el soporte técnico de Azure Databricks.
Nota:
Tenga en cuenta que SSH solo se puede habilitar si el área de trabajo está implementada en su propia red virtual de Azure.
Entrega de registros del clúster
Al crear un clúster, puede especificar una ubicación para entregar los registros del nodo de controlador de Spark, los nodos de trabajo y los eventos. Los registros se entregan cada cinco minutos al destino elegido. Cuando finaliza un clúster, Azure Databricks garantiza la entrega de todos los registros generados hasta la finalización del clúster.
El destino de los registros depende del identificador del clúster. Si el destino especificado es dbfs:/cluster-log-delivery, los registros del clúster para 0630-191345-leap375 se entregan a dbfs:/cluster-log-delivery/0630-191345-leap375.
Para configurar la ubicación de entrega del registro:
En la página de configuración del clúster, haga clic en el botón de alternancia Opciones avanzadas.
Haga clic en la pestaña Registro.
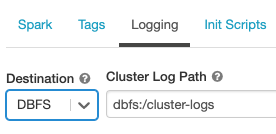
Seleccione un tipo de destino.
Escriba la ruta de acceso del registro del clúster.
Nota:
Esta característica también está disponible en la API de REST. Consulte la API de clústeres.
Scripts de inicialización
Un script de inicialización de nodo de clúster (o init) es un script de shell que se ejecuta durante el inicio de cada nodo del clúster antes de que se inicie la JVM del trabajo o el controlador de Spark. Puede usar scripts de init para instalar paquetes y bibliotecas no incluidos en Databricks Runtime, modificar la ruta de clase del sistema de la JVM, establecer las propiedades del sistema y las variables de entorno usadas por la JVM o modificar los parámetros de configuración de Spark, entre otras tareas de configuración.
Puede adjuntar scripts init a un clúster si expande la sección Opciones avanzadas y hace clic en la pestaña Scripts init.
Para obtener instrucciones detalladas, consulte ¿Qué son los scripts de inicialización?.