Recuperación ante desastres
Un patrón claro de recuperación ante desastres es fundamental para una plataforma de análisis de datos nativa de la nube, como es Azure Databricks. Es fundamental que los equipos de datos puedan usar la plataforma Azure Databricks incluso en el caso excepcional de una interrupción del proveedor de servicios en la nube en todo el servicio regional, ya sea causada por un desastre regional como un huracán, un terremoto u otras causas.
Azure Databricks suele ser una parte fundamental de un ecosistema de datos general que incluye muchos servicios, incluidos los servicios de ingesta de datos ascendentes (procesamiento por lotes y streaming), el almacenamiento nativo en la nube, como ADLS Gen2 (para áreas de trabajo creadas antes del 6 de marzo de 2023, Azure Blob Storage), herramientas y servicios de bajada, como aplicaciones de inteligencia empresarial y herramientas de orquestación. Algunos casos de uso pueden ser especialmente susceptibles a una interrupción en todo el servicio de la región.
En este artículo se describen los conceptos y los procedimientos recomendados para una solución de recuperación ante desastres entre regiones correcta para la plataforma Databricks.
Garantías de alta disponibilidad dentro de la región
Aunque el resto de este tema se centra en la implementación de la recuperación ante desastres entre regiones, es importante comprender las garantías de alta disponibilidad que Azure Databricks proporciona dentro de la única región. Las garantías de alta disponibilidad dentro de la región cubren los siguientes componentes:
Disponibilidad del plano de control de Azure Databricks
- La mayoría de los servicios del plano de control se ejecutan en clústeres de Kubernetes y controlarán la pérdida de máquinas virtuales en la instancia de AZ específica automáticamente.
- Los datos del área de trabajo se almacenan en bases de datos con almacenamiento premium, replicadas en toda la región. El almacenamiento de la base de datos (servidor único) no se replica en diferentes AZ o regiones. Si la interrupción de la zona afecta al almacenamiento de la base de datos, la base de datos se recupera mediante la incorporación de una nueva instancia de la copia de seguridad.
- Las cuentas de almacenamiento que se usan para atender imágenes de DBR también son redundantes dentro de la región y todas las regiones tienen cuentas de almacenamiento secundarias que se usan cuando la principal está inactiva. Consultar Regiones de Azure Databricks.
- En general, la funcionalidad del plano de control debe restaurarse en unos 15 minutos después de que se recupere la zona de disponibilidad.
Disponibilidad del plano de proceso
- La disponibilidad del área de trabajo depende de la disponibilidad del plano de control (como se ha descrito anteriormente).
- Los datos en la raíz de DBFS no se ven afectados si la cuenta de almacenamiento de la raíz de DBFS está configurada con ZRS o GZRS (el valor predeterminado es GRS).
- Los nodos de los clústeres se extraen de las distintas zonas de disponibilidad solicitando nodos del proveedor de proceso de Azure (suponiendo capacidad suficiente en las zonas restantes para satisfacer la solicitud). Si se pierde un nodo, el administrador de clústeres solicita nodos de reemplazo del proveedor de proceso de Azure, que los extrae de las AZ disponibles. La única excepción es cuando se pierde el nodo del controlador. En este caso, el administrador de trabajos o clústeres los reinicia.
Introducción a la recuperación ante desastres
La recuperación ante desastres implica un conjunto de directivas, herramientas y procedimientos que permiten la recuperación o continuación de sistemas e infraestructuras tecnológicos esenciales a consecuencia de desastres de origen humano. Un servicio en la nube de gran tamaño, como Azure, atiende a muchos clientes y tiene medidas de protección integradas en prevención de un único error. Por ejemplo, una región es un conjunto de edificios que están conectados a fuentes de alimentación diferentes para garantizar que un solo corte de energía no cause un apagado en toda la región. Sin embargo, pueden producirse errores en la región en la nube y la disrupción y el impacto puede variar en distintas medidas para la organización.
Antes de implementar un plan de recuperación ante desastres, es importante ver la diferencia entre la recuperación ante desastres (DR) y la alta disponibilidad (HA).
La alta disponibilidad es una característica de la resistencia de un sistema. La alta disponibilidad garantiza un nivel mínimo de rendimiento operacional que se suele definir en términos de tiempo de actividad coherente o porcentaje de tiempo de actividad. La alta disponibilidad se implementa en un lugar (en la misma región que el sistema principal) mediante el diseño de un sistema principal. Por ejemplo, los servicios en la nube como Azure tienen servicios de alta disponibilidad, como ADLS Gen2 (para las áreas de trabajo creadas antes del 6 de marzo de 2023, Azure Blob Storage). La alta disponibilidad no necesita una preparación explícita significativa del cliente de Azure Databricks.
Por el contrario, un plan de recuperación ante desastres requiere decisiones y soluciones que funcionen para que una organización específica controle una interrupción regional mayor de los sistemas imprescindibles. En este artículo se explica la terminología habitual relativa a la recuperación ante desastres, soluciones comunes y algunos de los procedimientos recomendados para los planes de recuperación ante desastres de Azure Databricks.
Terminología
Terminología de las regiones
En este artículo se usan las siguientes definiciones región:
Región primaria: la región geográfica en la cual los usuarios normalmente ejecutan a diario cargas de trabajo de análisis de datos automatizadas e interactivas.
Región secundaria: la región geográfica a la cual los equipos de TI mueven temporalmente las cargas de trabajo de análisis de datos durante una interrupción en la región primaria.
Almacenamiento con redundancia geográfica: Azure tiene un almacenamiento con redundancia geográfica entre regiones para el almacenamiento continuado mediante un proceso de replicación de almacenamiento asincrónico.
Importante
Para los procesos de recuperación ante desastres, Databricks recomienda que no confíes en el almacenamiento con redundancia geográfica para la duplicación de datos entre regiones, como tu ADLS gen2 (para áreas de trabajo creadas antes del 6 de marzo de 2023, Azure Blob Storage) que Azure Databricks crea para cada área de trabajo. en tu suscripción de Azure. En general, use Clonación profunda para las tablas Delta y convierta datos al formato Delta para usar la clonación profunda si es posible para otros formatos de datos.
Terminología del estado de la implementación
En este artículo se define el estado de implementación de la siguiente manera:
Implementación activa: los usuarios pueden conectarse a una implementación activa de un área de trabajo de Azure Databricks y ejecutar cargas de trabajo. Los trabajos se programan periódicamente mediante el programador de Azure Databricks u otro mecanismo. Los flujos de datos también se pueden ejecutar en esta implementación. En algunos documentos la implementación activa puede aparecer como implementación en caliente.
Implementación pasiva: los procesos no se ejecutan en una implementación pasiva. Los equipos de IT pueden configurar los procedimientos automatizados para que implementen el código, la configuración y otros objetos de Azure Databricks en la implementación pasiva. Una implementación se convierte en activa únicamente si el proceso de implementación activa está fuera de servicio. En algunos documentos la implementación pasiva puede aparecer como implementación en frío.
Importante
Un proyecto puede incluir de forma opcional varias implementaciones pasivas en diferentes regiones para ofrecer opciones adicionales que resuelvan las interrupciones de la región.
Por lo general, un equipo solo tiene una implementación activa a la vez, en lo que se denomina una estrategia de recuperación ante desastres activa-pasiva. Existe una estrategia de solución de recuperación ante desastres menos habitual denominada activa-activa, en la que se dan simultáneamente dos implementaciones activas.
Terminología del sector de recuperación ante desastres
Hay dos términos importantes del sector que debe comprender y definir para el equipo:
Objetivo de punto de recuperación: Un objetivo de punto de recuperación (RPO) es el período máximo previsto en el que se pueden perder los datos (transacciones) desde un servicio de TI debido a un incidente grave. La implementación de Azure Databricks no almacena los datos principales del cliente. Se almacena en sistemas independientes, como ADLS Gen2 (para áreas de trabajo creadas antes del 6 de marzo de 2023, Azure Blob Storage) u otros orígenes de datos bajo tu control. El plano de control de Azure Databricks almacena algunos objectos en parte o en su totalidad, como trabajos y cuadernos. Para Azure Databricks, el RPO se define como el período máximo previsto en el cual se pueden perder objetos como cambios de cuaderno y trabajos. Además, eres responsable de definir el RPO para tus propios datos de cliente en ADLS Gen2 (para áreas de trabajo creadas antes del 6 de marzo de 2023, Azure Blob Storage) u otros orígenes de datos bajo tu control.
Objetivo de tiempo de recuperación: el objetivo de tiempo de recuperación (RTO) es la duración de tiempo prevista y un nivel de servicio en el que se debe restaurar un proceso empresarial después de un desastre.
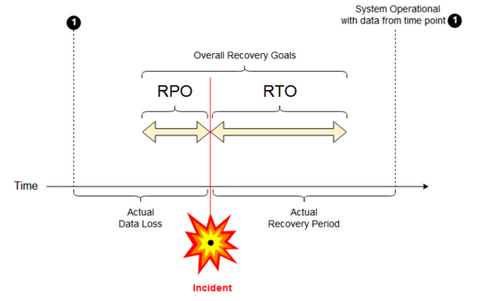
Recuperación ante desastres y datos dañados
Una solución de recuperación ante desastres no mitiga los daños en los datos. Los datos dañados de la región primaria se replican desde la región primaria a una región secundaria y están dañados en ambas. Hay otras maneras de mitigar este tipo de error, por ejemplo, el viaje en el tiempo de Delta.
Flujo de trabajo de recuperación habitual
Normalmente, un escenario de recuperación ante desastres de Azure Databricks se realiza de la siguiente manera:
Se produce un error en un servicio esencial que se usa en la región primaria. Puede tratarse de un servicio de origen de datos o una red que afecta a la implementación de Azure Databricks.
Usted investiga la situación del proveedor de nube.
Si determina que su empresa no puede esperar a que se solucione el problema en la región primaria, puede que decida que es necesaria una conmutación por error en una región secundaria.
Compruebe que el mismo problema no afecta a la región secundaria también.
Realice una conmutación por error a una región secundaria.
- Detenga todas las actividades del área de trabajo. Los usuarios deben detener las cargas de trabajo. Se indica a los usuarios o administradores que realicen una copia de seguridad de los cambios recientes si es posible. Los trabajos se cierran si no se han producido errores debido a la interrupción.
- Inicie el procedimiento de recuperación en la región secundaria. El procedimiento de recuperación actualiza el enrutamiento y el cambio de nombre de las conexiones y el tráfico de red a la región secundaria.
- Después de realizar las pruebas, declare operativa la región secundaria. Se podrán reanudar entonces las cargas de trabajo de producción. Los usuarios pueden iniciar sesión en la implementación que ya está activa. Puede volver a desencadenar los trabajos programados o retrasados.
Para obtener los pasos detallados en un contexto Azure Databricks, consulta conmutación por error de prueba.
En un momento determinado, el problema de la región primaria se mitiga y usted confirma este hecho.
Restaure (conmutación por recuperación) a la región primaria.
- Detenga todos los trabajos en la región secundaria.
- Inicie el procedimiento de recuperación en la región primaria. El procedimiento de recuperación controla el enrutamiento y el cambio de nombre de la conexión y el tráfico de red de vuelta a la región primaria.
- Replique los datos en la región primaria cuando sea necesario. Para reducir la complejidad, quizás minimice la cantidad de datos que se necesite replicar. Por ejemplo, si algunos trabajos son de solo lectura al ejecutarse en la implementación secundaria, es posible que no tenga que replicarlos en la implementación principal en la región primaria. Sin embargo, es posible que haya un trabajo de producción que necesite ejecutarse y posiblemente deban replicarse los datos en la región primaria.
- Pruebe la implementación en la región primaria.
- Declare operativa la región primaria y que es su implementación activa. Reanude las cargas de trabajo de producción.
Para obtener más información sobre cómo restaurar en la región primaria, consulte Restauración de prueba (conmutación por recuperación).
Importante
Puede producirse una pérdida de datos al completarse estos pasos. La organización debe definir hasta qué punto puede producirse una pérdida de datos y lo que se puede hacer para mitigarla.
Paso 1: reconocimiento de las necesidades empresariales
El primer paso consiste en definir y comprender las necesidades de la empresa. Defina qué servicios de datos son esenciales y cuáles son sus objetivo de punto de recuperación (RPO) y RTO previstos.
Investigue sobre la tolerancia real de cada sistema y tenga en cuenta que la conmutación por error y la conmutación por recuperación de recuperación ante desastres pueden ser costosas y conllevan otros riesgos. Entre otros riesgos se incluyen datos dañados, datos duplicados si se escribe en la ubicación de almacenamiento equivocada y los usuarios que acceden realizan cambios en lugares equivocados.
Asigne todos los puntos de integración de Azure Databricks que afectan a la empresa:
- ¿La solución de la recuperación ante desastres necesita adaptarse a procesos interactivos, procesos automatizados o a ambos?
- ¿Qué servicios de datos usa? Algunos pueden ser locales.
- ¿Cómo llegan los datos de entrada a la nube?
- ¿Quién consume estos datos? ¿Qué procesos los consumen de bajada?
- ¿Existen integraciones de terceros que necesiten tener en cuenta los cambios de recuperación ante desastres?
Determine las herramientas o estrategias de comunicación que pueden proporcionar asistencia en el plan de recuperación ante desastres:
- ¿Qué herramientas va a usar para modificar rápidamente las configuraciones de red?
- ¿Puede predefinir la configuración y convertirla en modular para dar cabida a soluciones de recuperación ante desastres de una manera natural y sostenible?
- ¿Qué canales y herramientas de comunicación notifican a los equipos internos y a terceros (integraciones, consumidores de nivel inferior) los cambios de conmutación por error y conmutación por recuperación ante desastres? ¿Cómo va a confirmar su reconocimiento?
- ¿Qué herramientas o soporte técnico especial se necesitan?
- ¿Qué servicios, en caso de haberlos, se apagarán hasta que se haya puesto en marcha la recuperación al completo?
Paso 2: elección de un proceso que satisfaga las necesidades empresariales
La solución debe replicar los datos correctos en el plano de control, el plano de proceso y los orígenes de datos. Las áreas de trabajo redundantes para la recuperación ante desastres deben asignarse a distintos planos de control en otras regiones. Los datos deben sincronizarse periódicamente mediante una solución basada en scripts, una herramienta de sincronización o un flujo de trabajo CI/CD. No es necesario sincronizar datos desde dentro de la propia red del plano de proceso, como desde los trabajos de Databricks Runtime.
Si usa la característica de inserción en red virtual (no disponible con todas las suscripciones ni tipos de implementación), puede implementar estas redes coherentemente mediante herramientas basadas en una plantilla como Terraform.
Además, es necesario asegurarse de que se replican los orígenes de datos cuando sea necesario en todas las regiones.
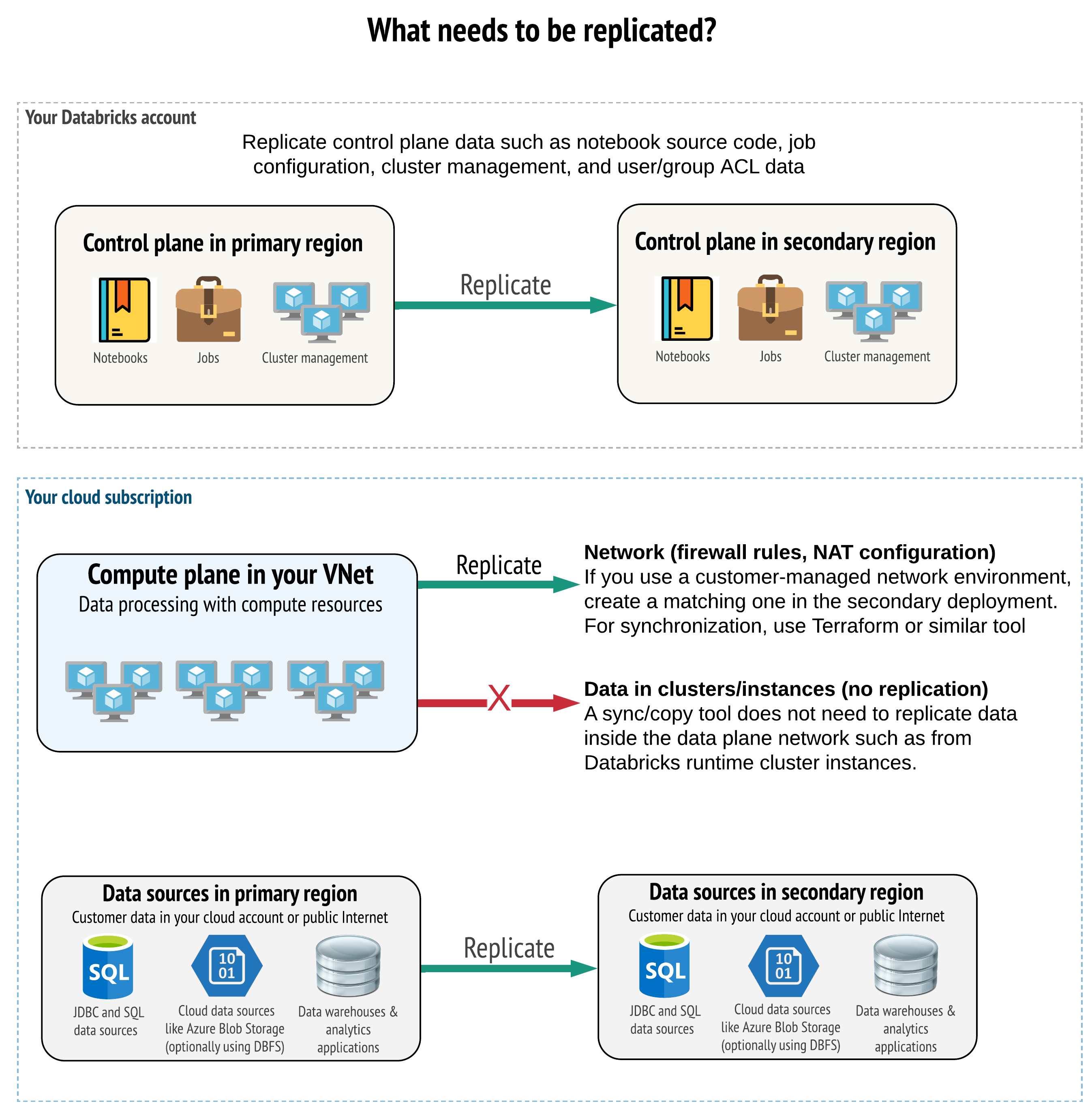
Procedimientos recomendados generales
Entre los procedimientos recomendados generales para un plan de recuperación ante desastres satisfactorio se incluyen:
Reconocer qué procesos son fundamentales para la empresa y tienen que ejecutarse en la recuperación ante desastres.
Identificar con claridad qué servicios están implicados, qué datos se están procesando, cuál es el flujo de datos y dónde se almacenan
Aislar todo lo posible los servicios y los datos. Por ejemplo, cree un contenedor especial de almacenamiento en la nube para los datos que cubra la recuperación ante desastres o mueva los objetos de Azure Databricks necesarios durante un desastre a un área de trabajo independiente.
Es su responsabilidad mantener la integridad de las implementaciones principal y secundaria para otros objetos que no están almacenados en el plano de control de Databricks.
Advertencia
Es un procedimiento recomendado no almacenar ningún dato en el ADLS gen2 raíz (para áreas de trabajo creadas antes del 6 de marzo de 2023, Azure Blob Storage) que se usa para el acceso raíz de DBFS para el área de trabajo. Ese almacenamiento raíz de DBFS no es compatible con los datos del cliente de producción. Databricks también recomienda no almacenar bibliotecas, archivos de configuración ni scripts de inicialización en esta ubicación.
En el caso de los orígenes de datos, siempre que sea posible, se recomienda usar herramientas nativas de Azure para la replicación y redundancia con el objeto de replicar datos en las regiones de recuperación ante desastres.
Elección de una estrategia de solución de recuperación
Las soluciones de recuperación ante desastres habituales implican dos (o posiblemente más) áreas de trabajo. Se puede elegir entre distintas estrategias. Tenga en cuenta la posible duración de la interrupción (horas o puede que incluso un día), el esfuerzo para garantizar que el área de trabajo esté totalmente operativa y el esfuerzo para realizar la restauración (conmutación por recuperación) en la región primaria.
Estrategia de solución activa-pasiva
En este artículo se aborda la solución activa-pasiva, que es el tipo de solución más común y sencillo. Una solución activa-pasiva sincroniza los cambios de datos y objetos desde la implementación activa a la implementación pasiva. Si lo prefiere, podría tener varias implementaciones pasivas en distintas regiones, pero este artículo se centra en el enfoque de implementación pasiva única. Durante un evento de recuperación ante desastres, la implementación pasiva en la región secundaria se convierte en la implementación activa.
Existen dos variantes principales de esta estrategia:
- Una solución unificada (empresarial): exactamente un conjunto de implementaciones activas y pasivas que proporcionan soporte a toda la organización.
- Una solución por departamento o proyecto: cada departamento o dominio de proyecto mantiene una solución de recuperación ante desastres independiente. Algunas organizaciones buscan desacoplar los detalles de recuperación ante desastres entre departamentos y, para ello, usan diferentes regiones primarias y secundarias para cada equipo en función de sus necesidades específicas.
Existen otras variantes, como usar una implementación pasiva para casos de uso de solo lectura. Las cargas de trabajo de solo lectura, por ejemplo, las consultas de usuario, pueden ejecutarse en una solución pasiva en cualquier momento si no modifican datos ni objetos de Azure Databricks, como cuadernos o trabajos.
Estrategia de solución activa-activa
En una solución activa-activa, se ejecutan todos los procesos de datos en ambas regiones o en paralelo. El equipo de operaciones debe asegurarse de que solo se marca como completo un proceso de datos, como puede ser un trabajo, cuando se finaliza correctamente en ambas regiones. Los objetos no se pueden cambiar en producción y deben seguir una promoción estricta de CI/CD de desarrollo/almacenamiento provisional a producción.
La estrategia más complicada es la activa-activa y dado que se ejecutan trabajos en ambas regiones se incurre en costes adicionales.
Al igual que la estrategia activa-pasiva, se puede implementar como una solución para toda la organización o por departamento.
Puede que no sea necesaria un área de trabajo equivalente en el sistema secundario para todas las áreas de trabajo, en función del flujo de trabajo. Por ejemplo, es posible que no haya que duplicar un desarrollo o un área de trabajo provisional. Con una canalización de desarrollo correctamente diseñada, es posible que las áreas de trabajo puedan reconstruirse de ser necesario.
Elige las herramientas
Existen dos enfoques principales para que las herramientas mantengan los datos lo más parecido posible entre las áreas de trabajo de las regiones primaria y secundaria:
- Cliente de sincronización que copia de la primaria a la secundaria: un cliente de sincronización inserta los recursos y datos de producción de la región primaria a la secundaria. Se suele ejecutar de forma programada.
- Herramientas de CI/CD para la implementación en paralelo: para los recursos y el código de producción, use herramientas de CI/CD que insertan simultáneamente cambios a los sistemas de producción en las dos regiones. Por ejemplo, al insertar código y recursos del ensayo o desarrollo en la producción, un sistema de CI/CD lo pone a disposición en ambas regiones al mismo tiempo. La idea principal es tratar todos los artefactos de un área de trabajo de Azure Databricks como infraestructura como código. La mayoría de los artefactos se pueden implementar de forma conjunta en las áreas de trabajo principal y secundaria, mientras que es posible que otros tengan que implementarse solo después de un evento de recuperación ante desastres. Para ver las herramientas, consulte Scripts, ejemplos y prototipos de Automation.
En el siguiente diagrama se contraponen los dos enfoques.
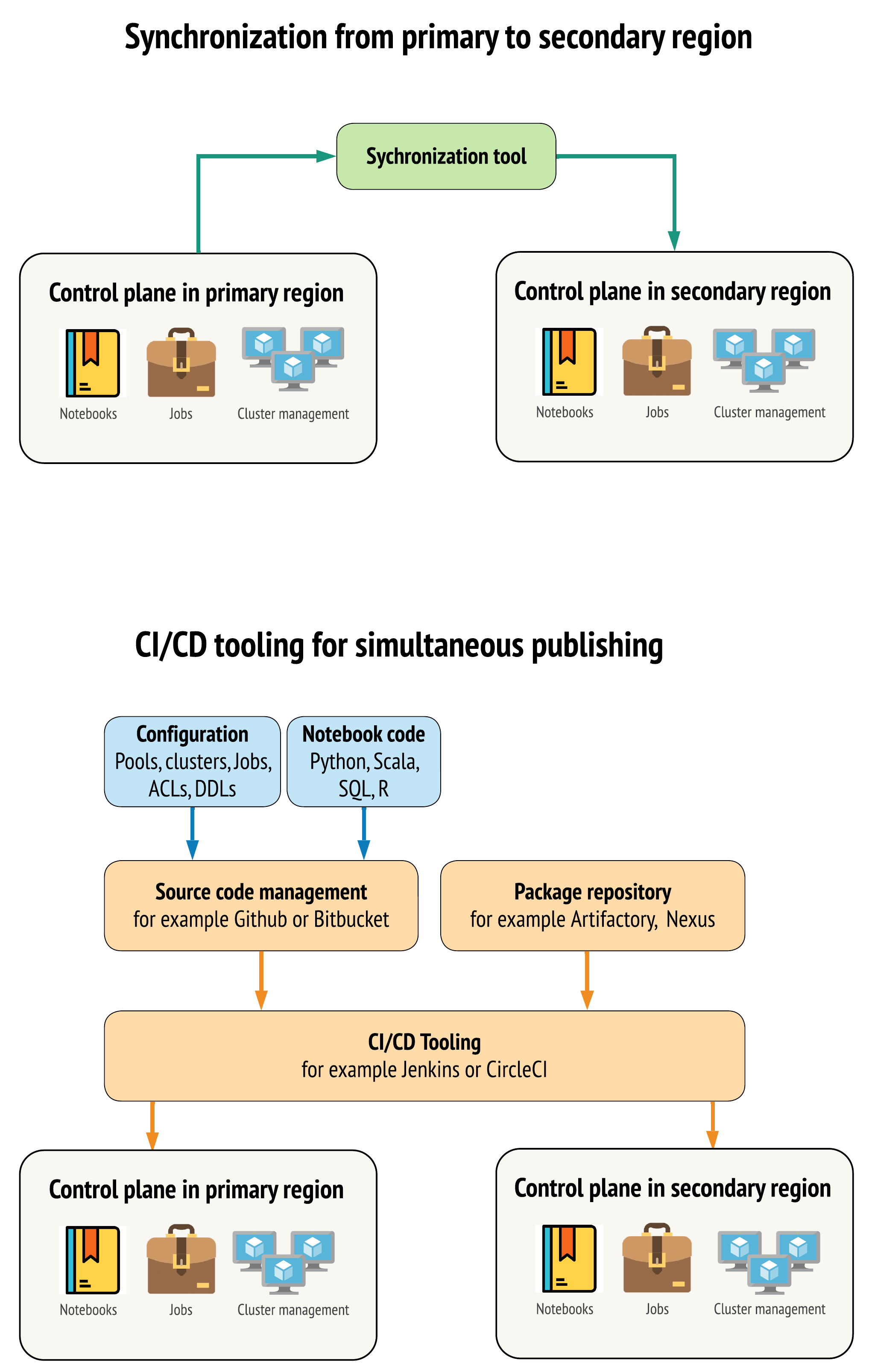
En función de las necesidades específicas, se pueden combinar ambos enfoques. Por ejemplo, se puede usar CI/CD para el código fuente del cuaderno, pero utilizar la sincronización para la configuración, como grupos y controles de acceso.
En la siguiente tabla se describe cómo controlar diferentes tipos de datos con cada opción de herramientas.
| Descripción | Cómo controlar las herramientas de CI/CD | Cómo controlar con la herramienta de sincronización |
|---|---|---|
| Código fuente: exportaciones de origen de cuadernos y código fuente para bibliotecas empaquetadas | Implemente de forma conjunta en el sistema principal y secundario. | Sincronice el código fuente del sistema principal al secundario. |
| Usuarios y grupos | Administre los metadatos como la configuración en Git. También puede usar el mismo proveedor de identidades (IdP) para ambas áreas de trabajo. Implemente de forma conjunta los datos de usuario y grupo en las implementaciones principal y secundaria. | Use SCIM u otra automatización para ambas regiones. No se recomienda la creación manual, pero si se usa debe realizarse al mismo tiempo en ambas. Si usa una configuración manual, cree un proceso automatizado programado para comparar la lista de usuarios y grupos entre las dos implementaciones. |
| Configuraciones de grupo | Pueden ser plantillas de Git. Implemente de forma conjunta en los sistemas principal y secundario. Sin embargo, min_idle_instances en el sistema secundario debe ser cero hasta el evento de recuperación ante desastres. |
Grupos creados con cualquiera min_idle_instances al sincronizarse con el área de trabajo secundaria mediante la API o la CLI. |
| Configuraciones del trabajo | Pueden ser plantillas de Git. En la implementación principal, implemente la definición del trabajo tal y como está. En la implementación secundaria, implemente el trabajo y establezca las concurrencias en cero. Se deshabilita, así, el trabajo en esta implementación y se impiden ejecuciones adicionales. Cambie el valor de simultaneidad después de que se active la implementación secundaria. | Si los trabajos, por algún motivo, se ejecutan en <interactive> clústeres existentes, el cliente de sincronización debe asignarlos al correspondiente cluster_id en el área de trabajo secundaria. |
| Listas de control de acceso (ACL) | Pueden ser plantillas de Git. Implementación de forma conjunta en las implementaciones principal y secundaria para cuadernos, carpetas y clústeres. Sin embargo, retenga los datos de los trabajos hasta el evento de recuperación ante desastres. | La Permissions API puede establecer controles de acceso para los clústeres, conjuntos, cuadernos y carpetas. Un cliente de sincronización debe asignar a los ID de objeto correspondientes cada objeto del área de trabajo secundaria. Databricks recomienda crear una asignación de los ID de objeto del área de trabajo principal a la secundaria mientras se sincronizan esos objetos antes de replicar los controles de acceso. |
| Bibliotecas | Inclúyalas en el código fuente y plantillas del clúster o el trabajo. | Sincronice las bibliotecas personalizadas desde repositorios centralizados, DBFS o almacenamiento en la nube (se puede montar). |
| Scripts de inicialización de clúster | Inclúyalos en el código fuente si lo prefiere. | Para llevar a cabo una sincronización más sencilla, almacene los scripts de inicialización en el área de trabajo principal de una carpeta común o en un pequeño conjunto de carpetas, si es posible. |
| Puntos de montaje | Inclúyalos en el código fuente si solo se crean a través de trabajos basados en cuadernos o la API de comandos. | Use trabajos que puedan ejecutarse como actividades (ADF) de Azure Data Factory. Tenga en cuenta que los puntos de conexión del almacenamiento pueden cambiar, dado que las áreas de trabajo estarían en regiones diferentes. También depende en gran medida de la estrategia de recuperación ante desastres en los datos. |
| Metadatos de tabla | Inclúyalos con código fuente si solo se crean a través de trabajos basados en cuadernos o API de comandos. Esto se aplica tanto al metastore interno de Azure Databricks como al metastore configurado de forma externa. | Compare las definiciones de metadatos entre los metastore de metadatos mediante la API del catálogo de Spark o Show Create Table a través de un cuaderno o scripts. Tenga en cuenta que las tablas de almacenamiento subyacente pueden basarse en regiones y serán diferentes entre las instancias de metastore. |
| Secretos | Inclúyalos en el código fuente si solo se crearon por medio de una API de comandos. Tenga en cuenta que posiblemente se necesite cambiar contenido de secretos entre el sistema principal y secundario. | Los secretos se crean en las dos áreas de trabajo por medio de la API. Tenga en cuenta que posiblemente se necesite cambiar contenido de secretos entre el sistema principal y secundario. |
| Configuraciones de clústeres | Pueden ser plantillas de Git. Implemente de forma conjunta en las implementaciones principal y secundaria, aunque las de la implementación secundaria deben finalizarse hasta el evento de recuperación ante desastres. | Los clústeres se crean después de sincronizarse con el área de trabajo secundaria mediante la API o la CLI. Se pueden finalizar explícitamente si lo desea, en función de la configuración de finalización automática. |
| Permisos de cuaderno, trabajo y carpeta | Pueden ser plantillas de Git. Implemente de forma conjunta en las implementaciones principal y secundaria. | Replique mediante la Permissions API. |
Elija regiones y varias áreas de trabajo secundarias
Necesita un control absoluto del desencadenador de recuperación ante desastres. Puede decidir desencadenarlo en cualquier momento o por cualquier motivo. Debe asumir la responsabilidad de la estabilización de la recuperación ante desastres antes de poder reiniciar el modo de conmutación por recuperación de la operación (producción normal). Normalmente, esto significa que es necesario crear varias áreas de trabajo de Azure Databricks para satisfacer las necesidades de recuperación ante desastres y de producción y elegir la región de conmutación por error.
En Azure, compruebe la replicación de datos, así como la disponibilidad de los tipos de producto y máquina virtual.
Paso 3: preparación de áreas de trabajo y realización de una copia de un solo uso
Si un área de trabajo ya está en proceso de producción, suele ejecutarse una operación decopia de un solo uso para sincronizar la implementación pasiva con la activa. Esta copia de un solo uso controla lo siguiente:
- Replicación de datos: los replica mediante una solución de replicación en la nube o una clonación profunda Delta.
- Generación de token: se usa la generación de token para automatizar la replicación y carga de trabajo futuras.
- Replicación del área de trabajo: se usa la replicación del área de trabajo mediante los métodos que se describen en el Paso 4: preparación de los orígenes de datos.
- Validación del área de trabajo: - se realiza una prueba para asegurarse de que el área de trabajo y el proceso pueden ejecutar satisfactoriamente y proporcionar los resultados deseados.
Después de realizar la copia de un solo uso, se agilizan las acciones de sincronización y copias posteriores. Todos los registros desde las herramientas constituyen un registro de qué y cuándo se han cambiado.
Paso 4: preparación de los orígenes de datos
Azure Databricks puede procesar una amplia variedad de orígenes de datos mediante el procesamiento por lotes o los flujos de datos.
Procesamiento por lotes de orígenes de datos
Al procesarse los datos por lotes, suelen residir en un origen de datos que puede replicarse con facilidad o entregarse en otra región.
Por ejemplo, es posible que los datos se carguen periódicamente en una ubicación de almacenamiento en la nube. En el modo de recuperación ante desastres de la región secundaria, es necesario asegurarse de que los archivos se cargan en el almacenamiento de la región secundaria. Las cargas de trabajo deben leer el almacenamiento de la región secundaria y escribir en el mismo.
Flujos de datos
El procesamiento de un flujo de datos supone un desafío mayor. Los flujos de datos se pueden ingerir desde varios orígenes, así como procesarse y enviarse a una solución de secuencias:
- Cola de mensajes como Kafka
- Flujo de captura de datos de cambio de base de datos
- Procesamiento continuo basado en archivos
- Procesamiento programado basado en archivos, llamado también desencadenador de un uso
En todos estos casos, se deben configurar los orígenes de datos para controlar el modo de recuperación ante desastres y para usar la implementación secundaria en la región secundaria.
Un sistema de escritura de secuencias almacena un punto de control con información sobre los datos que se han procesado. En este punto de comprobación puede haber una ubicación de datos (generalmente un almacenamiento en la nube) que tuvo que cambiarse a una nueva ubicación para garantizar un reinicio de la transmisión adecuada. Por ejemplo, la source subcarpeta en el punto de control podría almacenar la carpeta en la nube basada en archivos.
El punto de comprobación se debe replicar de forma oportuna. Conviene considerar la posibilidad de sincronizar el intervalo del punto de comprobación con cualquier nueva solución de replicación en la nube.
La actualización del punto de comprobación es una función del objeto de escritura y, por tanto, se aplica a la ingesta o procesamiento de los flujos de datos y al almacenamiento en otro origen de transmisión.
En el caso de las cargas de trabajo de flujos, asegúrese de que los puntos de control están configurados en el almacenamiento administrado por el cliente para que se puedan replicar en la región secundaria para la reanudación de la carga de trabajo desde el momento del último error. También se puede optar por ejecutar el proceso de transmisión secundario en paralelo al proceso principal.
Paso 5: implementación y realización de la prueba de la solución
Pruebe periódicamente la configuración de recuperación ante desastres para asegurarse de que funciona correctamente. No resulta útil mantener una solución de recuperación ante desastres si no se puede usar cuando se necesita. Algunas empresas cambian de región cada pocos meses. Al cambiar de región siguiendo una programación periódica, se prueban las suposiciones y procesos, además de garantizarse que se satisfacen las necesidades específicas de recuperación. Esto también garantiza que la organización se familiarice con las directivas y los procedimientos en caso de emergencia.
Importante
Pruebe periódicamente la solución de recuperación ante desastres en condiciones reales.
En caso de que le falte un objeto o plantilla y todavía dependa de la información almacenada en el área de trabajo principal, modifique el plan para salvar estos obstáculos, replicar esta información en el sistema secundario o hacer que esté disponible de otro modo.
Pruebe todos cambios organizativos necesarios de los procesos y en la configuración en general. El plan de recuperación ante desastres afecta a la canalización de implementación y es importante que el equipo sepa qué debe mantenerse sincronizado. Después de configurar las áreas de trabajo de recuperación ante desastres, asegúrese de que la infraestructura (manual o de código), los trabajos, los cuadernos, las bibliotecas y otros objetos de área de trabajo están disponibles en la región secundaria.
Hable con el equipo sobre cómo expandir los procesos de trabajo estándar y las canalizaciones de la configuración para poder implementar cambios en todas la áreas de trabajo. Administre las identidades de usuario en todas las áreas de trabajo. No olvide configurar las herramientas como la automatización de trabajos y la supervisión de nuevas áreas de trabajo.
Planee y pruebe los cambios en las herramientas de configuración:
- Ingesta: se debe comprender dónde están los orígenes de datos y dónde obtienen los datos. Siempre que sea posible, parametrice el origen y asegúrese de que existen una plantilla de configuración independiente para trabajar con las implementaciones y regiones secundarias. Prepara un plan para la conmutación por error y pruebe todas las suposiciones.
- Cambios de ejecución: si hay un programador para desencadenar trabajos u otras acciones, es posible que sea necesario configurar un programador independiente que funcione con la implementación secundaria o sus orígenes de datos. Prepara un plan para la conmutación por error y pruebe todas las suposiciones.
- Conectividad interactiva: se debe tener en cuenta cómo la configuración, la autenticación y las conexiones de red podrían verse afectadas por interrupciones regionales por cualquier uso de las API REST, las herramientas de la CLI u otros servicios como JDBC/ODBC. Prepara un plan para la conmutación por error y pruebe todas las suposiciones.
- Cambios de automatización: para todas las herramientas de automatización, se necesita un plan para la conmutación por error y pruebe todas las suposiciones.
- Salidas: para cualquier herramienta que genere datos de salida o registros, prepare un plan para la conmutación por error y pruebe todas las suposiciones.
Conmutación por error de prueba
La recuperación ante desastres se puede desencadenar en muchos escenarios diferentes. Puede deberse a una interrupción inesperada. Es posible que algunas funcionalidades centrales no se puedan usar, incluida la red en la nube, el almacenamiento en la nube u otro servicio. No se puede apagar el sistema correctamente y se debe intentar la recuperación. No obstante, un apagado o una interrupción planeada puede desencadenar el proceso, o incluso una conmutación periódica de las implementaciones activas entre las dos regiones.
Al probar la conmutación por error, conéctese al sistema y ejecute el proceso de apagado. Asegúrese de que se completaron todos los trabajos y se terminaron los clústeres.
Un cliente de sincronización (o herramientas de CI/CD) puede replicar objetos de Azure Databricks y recursos pertinentes en el área de trabajo secundaria. Para activar el área de trabajo secundaria, el proceso debe incluir lo siguiente, en parte o en su totalidad:
- Ejecución de pruebas para confirmar que la plataforma está actualizada.
- Deshabilite los grupos y los clústeres en la región primaria para que, si el servicio con errores vuelve a estar en línea, la región primaria no empiece a procesar nuevos datos.
- Proceso de recuperación:
- Compruebe la fecha de los datos sincronizados más recientes. Más información en Terminología del sector de recuperación ante desastres. Los detalles de este paso pueden variar en función de cómo sincronice los datos y sus necesidades empresariales específicas.
- Estabilice los orígenes de datos y asegurarse de que todos están disponibles. Incluya todos los orígenes de datos externos, como Azure Cloud SQL, así como los archivos de Delta Lake, Parquet u otros.
- Busque el punto de recuperación de secuencias. Configure el reinicio desde allí y tenga el proceso listo para identificar y eliminar posibles duplicados (Delta Lake facilita esta tarea).
- Complete el proceso de flujo de datos e informe a los usuarios.
- Inicie los grupos pertinentes (o aumentar
min_idle_instancesal número pertinente). - Inicie los clústeres pertinentes (si no están finalizados).
- Cambie la ejecución simultánea de los trabajos y ejecute los trabajos pertinentes. Podrían tratarse de ejecuciones de una sola vez o periódicas.
- Para una herramienta externa que use una dirección URL o un nombre de dominio para el área de trabajo de Azure Databricks, actualice las configuraciones para el nuevo plano de control. Por ejemplo, puede actualizar las direcciones URL de las API de REST y las conexiones JDBC/ODBC. La dirección URL orientada al cliente de la aplicación web de Azure Databricks cambia cuando lo hace el plano de control, así que informe sobre la nueva dirección URL a los usuarios de la organización.
Restauración de prueba (conmutación por recuperación)
La conmutación por recuperación es más sencilla de controlar y puede hacerse en una ventana de mantenimiento. Este plan puede incluir lo siguiente, en parte o en su totalidad:
- Obtenga confirmación de que se ha restaurado la región primaria.
- Deshabilite los grupos y los clústeres de la región secundaria para que no empiece a procesar nuevos datos.
- Sincronice todos los recursos nuevos o modificados en el área de trabajo secundaria en la implementación principal. En función del diseño de los scripts de conmutación por error, tal vez pueda ejecutar los mismos para sincronizar los objetos de la región secundaria (recuperación ante desastres) con la región primaria (de producción).
- Sincronice todas las actualizaciones de nuevos datos en la implementación principal. Puede usar las pistas de auditoría de los registros y las tablas Delta para garantizar que no se pierdan datos.
- Apague todas las áreas de trabajo en la región de recuperación ante desastres.
- Cambie las direcciones URL de usuarios y los trabajos en la región primaria.
- Ejecución de pruebas para confirmar que la plataforma está actualizada.
- Inicie los grupos pertinentes (o aumente
min_idle_instancesen un número pertinente). - Inicie los clústeres pertinentes (si no están finalizados).
- Cambie la ejecución simultánea de los trabajos y ejecute los trabajos pertinentes. Podrían tratarse de ejecuciones de una sola vez o periódicas.
- Según sea necesario, vuelva a configurar la región secundaria para la recuperación ante desastres futuros.
Prototipos, ejemplos y scripts de Automation
Los scripts de Automatización que se deben tener en cuenta en los proyectos de recuperación ante desastres:
- Databricks recomienda Proveedor Databricks Terraform para desarrollar procesos de sincronización propios.
- En Herramientas de migración del área de trabajo de Databricks se pueden consultar scripts de ejemplo y prototipos. Además de los objetos de Azure Databricks, replique las canalizaciones de Azure Data Factory pertinentes para que se refieran a un servicio vinculado que está asignado al área de trabajo secundaria.
- El proyecto Databricks Sync (DBSync) es una herramienta de sincronización de objeto que hace copias de seguridad, restaura y sincroniza las área de trabajo de Databricks.