Referencia de las tablas del sistema de trabajos
Nota:
El esquema lakeflow se conocía anteriormente como workflow. El contenido de ambos esquemas es idéntico. Para que el esquema lakeflow sea visible, debe habilitarlo por separado.
Este artículo es una referencia sobre cómo usar las tablas del sistema de lakeflow para supervisar los trabajos en tu cuenta. Estas tablas incluyen registros de todas las áreas de trabajo de la cuenta implementadas en la misma región de nube. Para ver los registros de otra región, debe ver las tablas de un área de trabajo implementada en esa región.
Requisitos
- Un administrador de cuenta debe habilitar el esquema
system.lakeflow. Consulte Habilitar esquemas de tablas del sistema. - Para acceder a estas tablas del sistema, los usuarios deben:
- Ser un administrador de metastore y un administrador de cuenta, o
- Tener permisos
USEySELECTen los esquemas del sistema. Consulte Conceder acceso a las tablas del sistema.
Tablas de trabajos disponibles
Todas las tablas del sistema relacionadas con trabajos residen en el esquema system.lakeflow. Actualmente, el esquema hospeda cuatro tablas:
| Tabla | Descripción | Admite streaming | Período de retención libre | Incluye datos globales o regionales |
|---|---|---|---|---|
| trabajos (versión preliminar pública) | Realiza un seguimiento de todos los trabajos creados en la cuenta | Sí | 365 días | Regional |
| job_tasks (versión preliminar pública) | Realiza un seguimiento de todas las tareas de trabajo que se ejecutan en la cuenta | Sí | 365 días | Regional |
| job_run_timeline (versión preliminar pública) | Realiza un seguimiento de las ejecuciones del trabajo y los metadatos relacionados | Sí | 365 días | Regional |
| job_task_run_timeline (versión preliminar pública) | Realiza un seguimiento de las ejecuciones de tareas de trabajo y los metadatos relacionados | Sí | 365 días | Regional |
Referencia detallada del esquema
En las secciones siguientes se proporcionan referencias de esquema para cada una de las tablas del sistema relacionadas con los trabajos.
Esquema de tabla de trabajos
La tabla jobs es una tabla de dimensiones que cambia lentamente (SCD2). Cuando cambia una fila, se emite una nueva fila, reemplazando lógicamente a la anterior.
ruta de acceso de tabla: system.lakeflow.jobs
| Nombre de la columna | Tipo de datos | Descripción | Notas |
|---|---|---|---|
account_id |
string | El identificador de la cuenta a la que pertenece este trabajo | |
workspace_id |
string | El identificador del área de trabajo a la que pertenece este trabajo | |
job_id |
string | Identificador del trabajo | Solo único dentro de un único área de trabajo |
name |
string | Nombre del trabajo proporcionado por el usuario | |
description |
string | Descripción proporcionada por el usuario del trabajo | Este campo está vacío si tiene claves administradas por cliente configuradas. No rellenado para las filas emitidas antes de finales de agosto de 2024 |
creator_id |
string | Identificador de la entidad de seguridad que creó el trabajo | |
tags |
string | Etiquetas personalizadas proporcionadas por el usuario asociadas a este trabajo | |
change_time |
timestamp | Hora a la que se modificó por última vez el trabajo | Zona horaria registrada como +00:00 (UTC) |
delete_time |
timestamp | Hora a la que el usuario eliminó el trabajo | Zona horaria registrada como +00:00 (UTC) |
run_as |
string | El identificador del usuario o la entidad de servicio cuyos permisos se usan para la ejecución del trabajo |
Ejemplo de consulta
-- Get the most recent version of a job
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
Esquema de tabla de tareas de trabajo
La tabla de tareas de trabajo es una tabla de dimensiones que cambia lentamente (SCD2). Cuando cambia una fila, se emite una nueva fila, reemplazando lógicamente a la anterior.
ruta de acceso de tabla: system.lakeflow.job_tasks
| Nombre de la columna | Tipo de datos | Descripción | Notas |
|---|---|---|---|
account_id |
string | El identificador de la cuenta a la que pertenece este trabajo | |
workspace_id |
string | El identificador del área de trabajo a la que pertenece este trabajo | |
job_id |
string | ID del trabajo | Solo único dentro de un único área de trabajo |
task_key |
string | Clave de referencia de una tarea en un trabajo | Solo único dentro de un único trabajo |
depends_on_keys |
array | Claves de tarea de todas las dependencias ascendentes de esta tarea | |
change_time |
timestamp | Hora a la que se modificó por última vez la tarea | Zona horaria registrada como +00:00 (UTC) |
delete_time |
timestamp | Hora en que el usuario eliminó una tarea | Zona horaria registrada como +00:00 (UTC) |
Ejemplo de consulta
-- Get the most recent version of a job task
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.job_tasks QUALIFY rn=1
Esquema de tabla de escala de tiempo de ejecución de trabajo
La tabla de escala de tiempo de ejecución del trabajo es inmutable y se completa en el momento en que se genera.
ruta de acceso a la tabla: system.lakeflow.job_run_timeline
| Nombre de la columna | Tipo de datos | Descripción | Notas |
|---|---|---|---|
account_id |
string | El identificador de la cuenta a la que pertenece este trabajo | |
workspace_id |
string | El identificador del área de trabajo a la que pertenece este trabajo | |
job_id |
string | Identificador del trabajo | Esta clave solo es única dentro de un único área de trabajo. |
run_id |
string | Identificador de la ejecución del trabajo | |
period_start_time |
timestamp | Hora de inicio de la ejecución o durante el período de tiempo | La información de zona horaria se registra al final del valor con +00:00 que representan UTC |
period_end_time |
timestamp | Hora de finalización de la ejecución o durante el período de tiempo | La información de zona horaria se registra al final del valor con +00:00 que representan UTC |
trigger_type |
string | Tipo de desencadenador que puede desencadenar una ejecución | Para conocer los valores posibles, consulte Valores de tipo de desencadenador. |
run_type |
string | Tipo de ejecución de trabajo | Para ver los valores posibles, consulte Ejecutar valores de tipo |
run_name |
string | Nombre de ejecución proporcionado por el usuario asociado a esta ejecución de trabajo | |
compute_ids |
array | Matriz que contiene los identificadores de proceso del trabajo para la ejecución del trabajo primario | Use para identificar el clúster de trabajos usado por WORKFLOW_RUN tipos de ejecución. Para obtener otra información de proceso, consulte la job_task_run_timeline tabla .No rellenado para las filas emitidas antes de finales de agosto de 2024 |
result_state |
string | Resultado de la ejecución del trabajo | Para consultar los posibles valores, vea Valores del estado de resultado |
termination_code |
string | Código de finalización de la ejecución del trabajo | Para conocer los valores posibles, consulte Valores de código de finalización. No rellenado para las filas emitidas antes de finales de agosto de 2024 |
job_parameters |
map | Parámetros de nivel de trabajo usados en la ejecución del trabajo | Las configuraciones en desuso de notebook_params no se incluyen en este campo. No rellenado para las filas emitidas antes de finales de agosto de 2024 |
Ejemplo de consulta
-- This query gets the daily job count for a workspace for the last 7 days:
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
-- This query returns the daily job count for a workspace for the last 7 days, distributed by the outcome of the job run.
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
result_state,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
AND result_state IS NOT NULL
GROUP BY ALL
-- This query returns the average time of job runs, measured in seconds. The records are organized by job. A top 90 and a 95 percentile column show the average lengths of the job's longest runs.
with job_run_duration as (
SELECT
workspace_id,
job_id,
run_id,
CAST(SUM(period_end_time - period_start_time) AS LONG) as duration
FROM
system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
)
SELECT
t1.workspace_id,
t1.job_id,
COUNT(DISTINCT t1.run_id) as runs,
MEAN(t1.duration) as mean_seconds,
AVG(t1.duration) as avg_seconds,
PERCENTILE(t1.duration, 0.9) as p90_seconds,
PERCENTILE(t1.duration, 0.95) as p95_seconds
FROM
job_run_duration t1
GROUP BY ALL
ORDER BY mean_seconds DESC
LIMIT 100
-- This query provides a historical runtime for a specific job based on the `run_name` parameter. For the query to work, you must set the `run_name`.
SELECT
workspace_id,
run_id,
SUM(period_end_time - period_start_time) as run_time
FROM system.lakeflow.job_run_timeline
WHERE
run_type="SUBMIT_RUN"
AND run_name = :run_name
AND period_start_time > CURRENT_TIMESTAMP() - INTERVAL 60 DAYS
GROUP BY ALL
-- This query collects a list of retried job runs with the number of retries for each run.
with repaired_runs as (
SELECT
workspace_id, job_id, run_id, COUNT(*) - 1 as retries_count
FROM system.lakeflow.job_run_timeline
WHERE result_state IS NOT NULL
GROUP BY ALL
HAVING retries_count > 0
)
SELECT
*
FROM repaired_runs
ORDER BY retries_count DESC
LIMIT 10;
Esquema de tabla de escala de tiempo de ejecución de tareas de trabajo
La tabla de escala de tiempo de ejecución de la tarea de trabajo es inmutable y completa en el momento en que se genera.
ruta de acceso de tabla: system.lakeflow.job_task_run_timeline
| Nombre de la columna | Tipo de datos | Descripción | Notas |
|---|---|---|---|
account_id |
string | El identificador de la cuenta a la que pertenece este trabajo | |
workspace_id |
string | El identificador del área de trabajo a la que pertenece este trabajo | |
job_id |
string | Identificador del trabajo | Solo único dentro de un único área de trabajo |
run_id |
string | Identificador de la ejecución de la tarea | |
job_run_id |
string | Identificador de la ejecución del trabajo | No rellenado para las filas emitidas antes de finales de agosto de 2024 |
parent_run_id |
string | Identificador de la ejecución primaria | No rellenado para las filas emitidas antes de finales de agosto de 2024 |
period_start_time |
timestamp | Hora de inicio de la tarea o del período de tiempo | La información de zona horaria se registra al final del valor con +00:00 que representan UTC |
period_end_time |
timestamp | Hora de finalización de la tarea o del período de tiempo | La información de zona horaria se registra al final del valor con +00:00 que representan UTC |
task_key |
string | Clave de referencia de una tarea en un trabajo | Esta clave solo es única dentro de un único trabajo. |
compute_ids |
array | La matriz compute_ids contiene identificadores de clústeres de trabajos, clústeres interactivos y almacenes de SQL usados por la tarea de trabajo. | |
result_state |
string | Resultado de la ejecución de la tarea de trabajo | Para ver los valores posibles, consulte Valores de estado de resultado |
termination_code |
string | Código de finalización de la ejecución de la tarea | Para conocer los valores posibles, consulte Valores de código de finalización. No rellenado para las filas emitidas antes de finales de agosto de 2024 |
Patrones de Combinación Comunes
En las secciones siguientes se proporcionan consultas de ejemplo que resaltan los patrones de combinación usados habitualmente para las tablas del sistema de trabajos.
Combinar los trabajos y las tablas de escala de tiempo de ejecución de trabajos
Enriquecer la ejecución del trabajo con un nombre de trabajo
with jobs as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM system.lakeflow.jobs QUALIFY rn=1
)
SELECT
job_run_timeline.*
jobs.name
FROM system.lakeflow.job_run_timeline
LEFT JOIN jobs USING (workspace_id, job_id)
Unir la escala de tiempo de ejecución del trabajo y las tablas de uso
Enriquecer cada registro de facturación con metadatos de ejecución de trabajos
SELECT
t1.*,
t2.*
FROM system.billing.usage t1
LEFT JOIN system.lakeflow.job_run_timeline t2
ON t1.workspace_id = t2.workspace_id
AND t1.usage_metadata.job_id = t2.job_id
AND t1.usage_metadata.job_run_id = t2.run_id
AND t1.usage_start_time >= date_trunc("Hour", t2.period_start_time)
AND t1.usage_start_time < date_trunc("Hour", t2.period_end_time) + INTERVAL 1 HOUR
WHERE
billing_origin_product="JOBS"
Calcular el costo por ejecución de un trabajo
Esta consulta se combina con la tabla del sistema billing.usage para calcular un costo por ejecución de trabajo.
with jobs_usage AS (
SELECT
*,
usage_metadata.job_id,
usage_metadata.job_run_id as run_id,
identity_metadata.run_as as run_as
FROM system.billing.usage
WHERE billing_origin_product="JOBS"
),
jobs_usage_with_usd AS (
SELECT
jobs_usage.*,
usage_quantity * pricing.default as usage_usd
FROM jobs_usage
LEFT JOIN system.billing.list_prices pricing ON
jobs_usage.sku_name = pricing.sku_name
AND pricing.price_start_time <= jobs_usage.usage_start_time
AND (pricing.price_end_time >= jobs_usage.usage_start_time OR pricing.price_end_time IS NULL)
AND pricing.currency_code="USD"
),
jobs_usage_aggregated AS (
SELECT
workspace_id,
job_id,
run_id,
FIRST(run_as, TRUE) as run_as,
sku_name,
SUM(usage_usd) as usage_usd,
SUM(usage_quantity) as usage_quantity
FROM jobs_usage_with_usd
GROUP BY ALL
)
SELECT
t1.*,
MIN(period_start_time) as run_start_time,
MAX(period_end_time) as run_end_time,
FIRST(result_state, TRUE) as result_state
FROM jobs_usage_aggregated t1
LEFT JOIN system.lakeflow.job_run_timeline t2 USING (workspace_id, job_id, run_id)
GROUP BY ALL
ORDER BY usage_usd DESC
LIMIT 100
Obtener registros de uso para trabajos de SUBMIT_RUN
SELECT
*
FROM system.billing.usage
WHERE
EXISTS (
SELECT 1
FROM system.lakeflow.job_run_timeline
WHERE
job_run_timeline.job_id = usage_metadata.job_id
AND run_name = :run_name
AND workspace_id = :workspace_id
)
Unir el cronograma de ejecución de tareas y las tablas de clústeres
Enriquecer las ejecuciones de tareas de trabajo con metadatos de clústeres
with clusters as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters QUALIFY rn=1
),
exploded_task_runs AS (
SELECT
*,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE array_size(compute_ids) > 0
)
SELECT
exploded_task_runs.*,
clusters.*
FROM exploded_task_runs t1
LEFT JOIN clusters t2
USING (workspace_id, cluster_id)
Buscar trabajos que se ejecutan en un proceso de uso completo
Esta consulta se une a la de la tabla del sistema compute.clusters para devolver los trabajos recientes que se ejecutan en proceso multiuso en lugar de proceso de trabajos.
with clusters AS (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters
WHERE cluster_source="UI" OR cluster_source="API"
QUALIFY rn=1
),
job_tasks_exploded AS (
SELECT
workspace_id,
job_id,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE period_start_time >= CURRENT_DATE() - INTERVAL 30 DAY
),
all_purpose_cluster_jobs AS (
SELECT
t1.*,
t2.cluster_name,
t2.owned_by,
t2.dbr_version
FROM job_tasks_exploded t1
INNER JOIN clusters t2 USING (workspace_id, cluster_id)
)
SELECT * FROM all_purpose_cluster_jobs LIMIT 10;
Panel de supervisión de trabajos
En el panel siguiente se usan tablas del sistema para ayudarle a empezar a supervisar los trabajos y el estado operativo. Incluye casos de uso comunes, como el seguimiento del rendimiento del trabajo, la supervisión de errores y el uso de recursos.
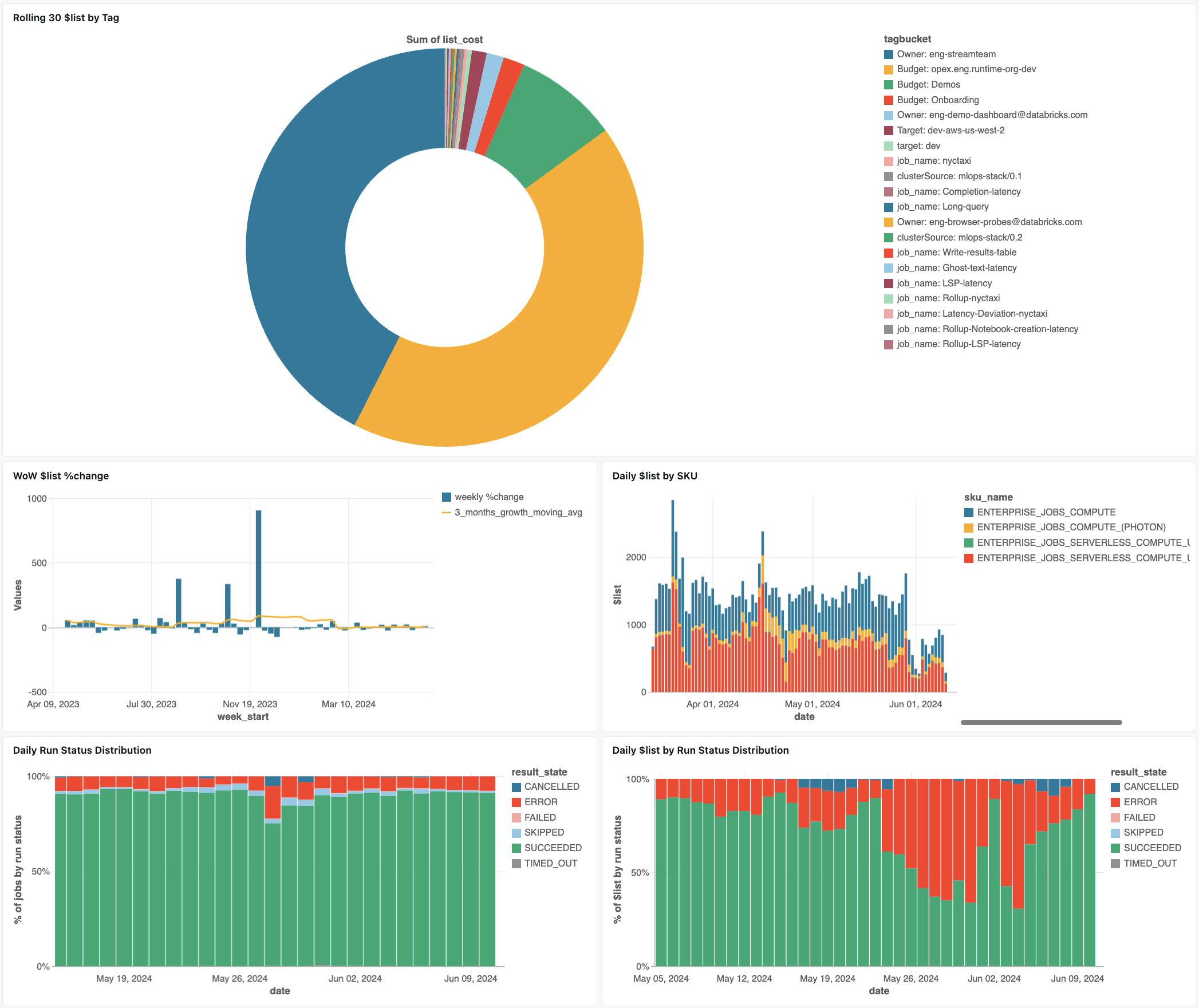
Para obtener información sobre cómo descargar el panel, consulte Supervisión de costes y rendimiento de trabajos con tablas del sistema
Solución de problemas
La tarea no está registrada en la tabla lakeflow.jobs
Si un trabajo no está visible en las tablas del sistema:
- El trabajo no se modificó en los últimos 365 días
- Modifique cualquiera de los campos del trabajo presentes en el esquema para emitir un nuevo registro.
- El trabajo se creó en otra región
- Creación reciente de trabajos (retrasos en los datos)
No se puede encontrar un trabajo visto en la tabla job_run_timeline
No todas las ejecuciones de trabajos están visibles en todas partes. Aunque las entradas de JOB_RUN aparecen en todas las tablas relacionadas con el trabajo, WORKFLOW_RUN (ejecuciones de flujo de trabajo del cuaderno) solo se registran en job_run_timeline y SUBMIT_RUN (ejecuciones enviadas una sola vez) se registran únicamente en ambas tablas de cronología. Estas ejecuciones no se rellenan en otras tablas del sistema de trabajo, como jobs o job_tasks.
Consulte la tabla Tipos de ejecución siguiente para obtener un desglose detallado de dónde está visible y accesible cada tipo de ejecución.
Ejecución de trabajo no visible en la tabla billing.usage
En system.billing.usage, el usage_metadata.job_id solo se rellena para los trabajos que se ejecutan en computación en trabajos o computación sin servidor.
Además, los trabajos de WORKFLOW_RUN no tienen una atribución propia de usage_metadata.job_id o de usage_metadata.job_run_id en system.billing.usage.
En su lugar, su uso de computación se atribuye al notebook principal que los activó.
Esto significa que cuando un notebook inicia la ejecución de un flujo de trabajo, todos los costos de proceso aparecen en el uso del notebook principal, no como un trabajo de flujo de trabajo independiente.
Consulte referencia de metadatos de uso para obtener más información.
Calcular el costo de un trabajo que se ejecuta en una computación de propósito general
El cálculo preciso del costo para los trabajos que se ejecutan en recursos de cómputo dedicados no es posible con una precisión de 100%. Cuando un trabajo se ejecuta en un proceso interactivo (de uso completo), varias cargas de trabajo como cuadernos, consultas SQL u otros trabajos a menudo se ejecutan simultáneamente en ese mismo recurso de proceso. Dado que los recursos del clúster se comparten, no hay ninguna asignación directa de 1:1 entre los costos informáticos y las ejecuciones de trabajos individuales.
Para un seguimiento preciso del costo del trabajo, Databricks recomienda ejecutar trabajos en computación dedicada para trabajos o computación sin servidor, donde usage_metadata.job_id y usage_metadata.job_run_id permiten una atribución precisa de costos.
Si debe usar la computación de propósito general, puede hacer lo siguiente:
- Supervise el uso general del clúster y los costes en
system.billing.usageen función deusage_metadata.cluster_id. - Realice un seguimiento de las métricas del tiempo de ejecución del trabajo por separado.
- Tenga en cuenta que cualquier estimación de costos será aproximada debido a los recursos compartidos.
Consulte referencia de metadatos de uso para obtener más información sobre la atribución de costes.
Valores de referencia
En la sección siguiente se incluyen referencias para seleccionar columnas en tablas relacionadas con trabajos.
Valores de tipo de desencadenador
Los valores posibles para la columna trigger_type son:
CONTINUOUSCRONFILE_ARRIVALONETIMEONETIME_RETRY
Valores de tipo de ejecución
Los valores posibles para la columna run_type son:
| Tipo | Descripción | Ubicación de la interfaz de usuario | Punto de conexión de API | Tablas del sistema |
|---|---|---|---|---|
JOB_RUN |
Ejecución de trabajos estándar | Interfaz de usuario de trabajos y ejecuciones de trabajos | /jobs y /jobs/runs endpoints | jobs, job_tasks, job_run_timeline, job_task_run_timeline |
SUBMIT_RUN |
Ejecución única a través de POST /jobs/runs/submit | Solo la interfaz de usuario de ejecuciones de trabajos | /jobs/runs endpoints only | job_run_timeline, job_task_run_timeline |
WORKFLOW_RUN |
Ejecución iniciada desde flujo de trabajo del cuaderno | No visible | No es accesible | cronograma_de_ejecución_de_tareas |
Valores de estado del resultado
Los valores posibles para la columna result_state son:
| Estado | Descripción |
|---|---|
SUCCEEDED |
La ejecución se completó correctamente |
FAILED |
La ejecución se completó con un error |
SKIPPED |
La ejecución nunca se realizó porque no se cumplió una condición |
CANCELLED |
La ejecución se canceló a petición del usuario. |
TIMED_OUT |
La ejecución se detuvo después de agotar el tiempo de espera |
ERROR |
La ejecución se completó con un error |
BLOCKED |
La ejecución se bloqueó en una dependencia ascendente |
Valores de código de finalización
Los valores posibles para la columna termination_code son:
| Código de terminación | Descripción |
|---|---|
SUCCESS |
La ejecución se completó correctamente |
CANCELLED |
La ejecución fue cancelada durante la ejecución por la plataforma de Databricks; por ejemplo, si se superó la duración máxima de la ejecución |
SKIPPED |
La ejecución nunca se llevó a cabo, por ejemplo, si se produjo un error en la ejecución de la tarea previa, no se cumplió la condición del tipo de dependencia o no había tareas pendientes para ejecutar. |
DRIVER_ERROR |
La ejecución encontró un error al comunicarse con el controlador de Spark. |
CLUSTER_ERROR |
Error en la ejecución debido a un error de clúster |
REPOSITORY_CHECKOUT_FAILED |
No se pudo completar el pago debido a un error al comunicarse con el servicio de terceros. |
INVALID_CLUSTER_REQUEST |
Error en la ejecución porque emitió una solicitud no válida para iniciar el clúster |
WORKSPACE_RUN_LIMIT_EXCEEDED |
El espacio de trabajo ha alcanzado la cuota del número máximo de ejecuciones activas simultáneas. Considere la posibilidad de programar las ejecuciones en un período de tiempo mayor |
FEATURE_DISABLED |
Error en la ejecución porque intentó acceder a una característica no disponible para el área de trabajo |
CLUSTER_REQUEST_LIMIT_EXCEEDED |
El número de solicitudes de creación, inicio y tamaño del clúster ha superado el límite de velocidad asignado. Considere la posibilidad de distribuir la ejecución en un periodo de tiempo mayor. |
STORAGE_ACCESS_ERROR |
Error en la ejecución debido a un error al acceder al almacenamiento de blobs del cliente |
RUN_EXECUTION_ERROR |
La ejecución se completó con errores de tarea |
UNAUTHORIZED_ERROR |
Error en la ejecución debido a un problema de permiso al acceder a un recurso |
LIBRARY_INSTALLATION_ERROR |
Error en la ejecución al instalar la biblioteca solicitada por el usuario. Las causas pueden incluir, pero no se limitan a: La biblioteca proporcionada no es válida, no hay permisos suficientes para instalar la biblioteca, etc. |
MAX_CONCURRENT_RUNS_EXCEEDED |
La ejecución programada supera el límite de ejecuciones simultáneas máximas establecidas para el trabajo. |
MAX_SPARK_CONTEXTS_EXCEEDED |
La ejecución se programa en un clúster que ya ha alcanzado el número máximo de contextos que está configurado para crear. |
RESOURCE_NOT_FOUND |
No existe un recurso necesario para la ejecución de la ejecución |
INVALID_RUN_CONFIGURATION |
Error en la ejecución debido a una configuración no válida |
CLOUD_FAILURE |
Error en la ejecución debido a un problema de proveedor de nube |
MAX_JOB_QUEUE_SIZE_EXCEEDED |
Se omitió la ejecución debido a que se alcanzó el límite de tamaño del nivel de la cola de trabajo |