Carga de datos incremental de Azure SQL Database a Azure Blob Storage mediante Azure Portal
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este tutorial, creará una instancia de Azure Data Factory con una canalización que carga los datos diferenciales de una tabla de Azure SQL Database a una instancia de Azure Blob Storage.
En este tutorial, realizará los siguientes pasos:
- Preparación del almacén de datos para almacenar el valor de marca de agua
- Creación de una factoría de datos.
- Cree servicios vinculados.
- Creación de conjuntos de datos de marca de agua, de origen y de receptor.
- Creación de una canalización
- Ejecución de la canalización
- Supervisión de la ejecución de la canalización
- Revisión de los resultados
- Adición de más datos al origen
- Repetición de la ejecución de la canalización
- Supervisión de la segunda ejecución de la canalización
- Revisión de los resultados de la segunda ejecución
Información general
Este es el diagrama de solución de alto nivel:

Estos son los pasos importantes para crear esta solución:
Seleccione la columna de marca de agua. Seleccione una columna en el almacén de datos de origen, que pueda usarse para segmentar los registros nuevos o actualizados para cada ejecución. Normalmente, los datos de esta columna seleccionada (por ejemplo, last_modify_time o id.) siguen aumentando cuando se crean o se actualizan las filas. El valor máximo de esta columna se utiliza como una marca de agua.
Prepare el almacén de datos para almacenar el valor de marca de agua. En este tutorial, el valor de marca de agua se almacena en una base de datos SQL.
Cree una canalización con el siguiente flujo de trabajo:
La canalización de esta solución consta de las siguientes actividades:
- Cree dos actividades de búsqueda. Use la primera actividad de búsqueda para recuperar el último valor de marca de agua. y, la segunda actividad, para recuperar el nuevo valor de marca de agua. Estos valores de marca de agua se pasan a la actividad de copia.
- Cree una actividad de copia que copie filas del almacén de datos de origen con el valor de la columna de marca de agua que sea mayor que el valor anterior y menor que el nuevo. A continuación, copia los datos diferenciales del almacén de datos de origen en Blob Storage como un archivo nuevo.
- Cree un procedimiento almacenado que actualice el valor de marca de agua de la canalización que se ejecute la próxima vez.
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Requisitos previos
- Azure SQL Database. La base de datos se usa como almacén de datos de origen. Si no tiene ninguna base de datos de Azure SQL Database, consulte el artículo Creación de una base de datos en Azure SQL Database para ver los pasos y crear una.
- Azure Storage. Blob Storage se usa como almacén de datos receptor. Si no tiene una cuenta de almacenamiento, consulte la sección Crear una cuenta de almacenamiento para ver los pasos para su creación. Cree un contenedor denominado adftutorial.
Creación de una tabla de origen de datos en la base de datos SQL
Abra SQL Server Management Studio. En el Explorador de servidores, haga clic con el botón derecho en la base de datos y elija Nueva consulta.
Ejecute el siguiente comando SQL en la base de datos SQL para crear una tabla denominada
data_source_tablecomo el almacén de origen de datos:create table data_source_table ( PersonID int, Name varchar(255), LastModifytime datetime ); INSERT INTO data_source_table (PersonID, Name, LastModifytime) VALUES (1, 'aaaa','9/1/2017 12:56:00 AM'), (2, 'bbbb','9/2/2017 5:23:00 AM'), (3, 'cccc','9/3/2017 2:36:00 AM'), (4, 'dddd','9/4/2017 3:21:00 AM'), (5, 'eeee','9/5/2017 8:06:00 AM');En este tutorial, utilizará LastModifytime como columna de marca de agua. Los datos del almacén de origen de datos se muestran en la tabla siguiente:
PersonID | Name | LastModifytime -------- | ---- | -------------- 1 | aaaa | 2017-09-01 00:56:00.000 2 | bbbb | 2017-09-02 05:23:00.000 3 | cccc | 2017-09-03 02:36:00.000 4 | dddd | 2017-09-04 03:21:00.000 5 | eeee | 2017-09-05 08:06:00.000
Creación de otra tabla en la base de datos SQL para almacenar el valor de límite máximo
Ejecute el siguiente comando SQL en la base de datos SQL para crear una tabla denominada
watermarktabley almacenar el valor de marca de agua:create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Establezca el valor predeterminado de límite máximo con el nombre de la tabla del almacén de datos de origen. En este tutorial, el nombre de tabla es data_source_table.
INSERT INTO watermarktable VALUES ('data_source_table','1/1/2010 12:00:00 AM')Revise los datos de la tabla
watermarktable.Select * from watermarktableSalida:
TableName | WatermarkValue ---------- | -------------- data_source_table | 2010-01-01 00:00:00.000
Creación de un procedimiento almacenado en la base de datos SQL
Ejecute el siguiente comando para crear un procedimiento almacenado en la base de datos SQL:
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Crear una factoría de datos
Inicie el explorador web Microsoft Edge o Google Chrome. Actualmente, la interfaz de usuario de Data Factory solo se admite en los exploradores web Microsoft Edge y Google Chrome.
En el menú de la izquierda, seleccione Crear un recurso>Integración>Data Factory:
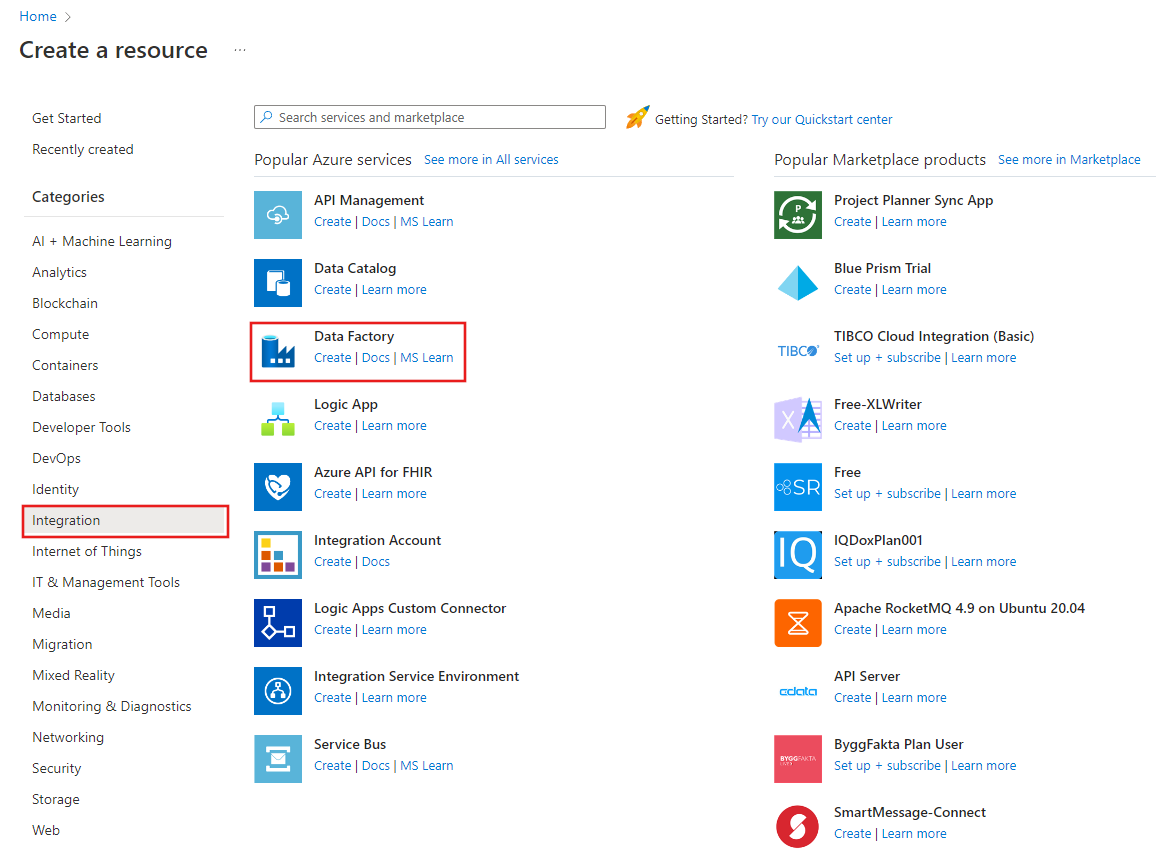
En la página Nueva factoría de datos, escriba ADFIncCopyTutorialDF para el nombre.
El nombre de la instancia de Azure Data Factory debe ser único globalmente. Si ve un signo de exclamación rojo con el siguiente error, cambie el nombre de la factoría de datos (por ejemplo, yournameADFIncCopyTutorialDF) e intente crearla de nuevo. Consulte el artículo Azure Data Factory: reglas de nomenclatura para conocer las reglas de nomenclatura de los artefactos de Data Factory.
El nombre "ADFIncCopyTutorialDF" de factoría de datos no está disponible.
Seleccione la suscripción de Azure donde desea crear la factoría de datos.
Para el grupo de recursos, realice uno de los siguientes pasos:
Seleccione en primer lugar Usar existentey después un grupo de recursos de la lista desplegable.
Seleccione Crear nuevoy escriba el nombre de un grupo de recursos.
Para obtener más información sobre los grupos de recursos, consulte Uso de grupos de recursos para administrar los recursos de Azure.
Seleccione V2 para la versión.
Seleccione la ubicación de Data Factory. En la lista desplegable solo se muestran las ubicaciones que se admiten. Los almacenes de datos (Azure Storage, Azure SQL Database, Instancia administrada de Azure SQL, etc.) y los procesos (HDInsight, etc.) que usa la factoría de datos pueden encontrarse en otras regiones.
Haga clic en Crear.
Una vez completada la creación, verá la página Data Factory tal como se muestra en la imagen.

Seleccione Abrir en el icono Abrir Azure Data Factory Studio para iniciar la aplicación de interfaz de usuario (IU) de Azure Data Factory en una pestaña independiente.
Crear una canalización
En este tutorial, creará una canalización con dos actividades de búsqueda, una actividad de copia y un procedimiento almacenado encadenada en una canalización.
En la página principal de la interfaz de usuario de Data Factory, haga clic en el icono Orquestar.
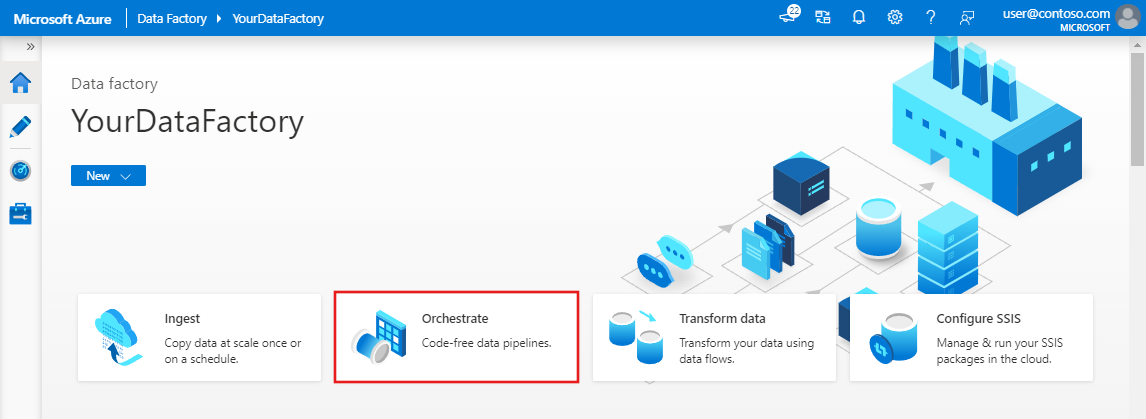
En el panel General, en Propiedades, especifique IncrementalCopyPipeline en Nombre. A continuación, contraiga el panel; para ello, haga clic en el icono Propiedades en la esquina superior derecha.
Agreguemos la primera actividad de búsqueda para recuperar el valor de marca de agua anterior. En el cuadro de herramientas Activities (Actividades), expanda General (General), arrastre la actividad Lookup (Búsqueda) y colóquela en la superficie del diseñador de canalizaciones. Cambie el nombre de la actividad a LookupOldWaterMarkActivity.
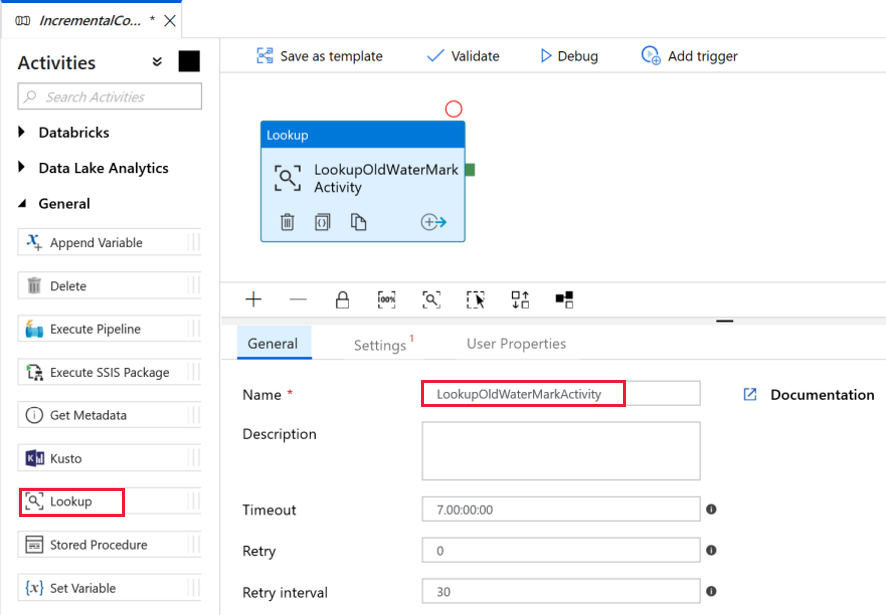
Cambie a la pestaña Settings (Configuración) y haga clic en + New (+ Nuevo) para Source Dataset (Conjunto de datos de origen). En este paso, creará conjuntos de datos que representarán los datos de watermarktable. Esta tabla contiene la marca de agua que se utilizó anteriormente en la operación de copia anterior.
En la ventana New Dataset (Nuevo conjunto de datos), seleccione Azure SQL Database y haga clic en Continue (Continuar). Verá que se abre una nueva ventana para el conjunto de datos.
En la ventana Set properties (Establecer propiedades) para el conjunto de datos, escriba WatermarkDataset en Name (Nombre).
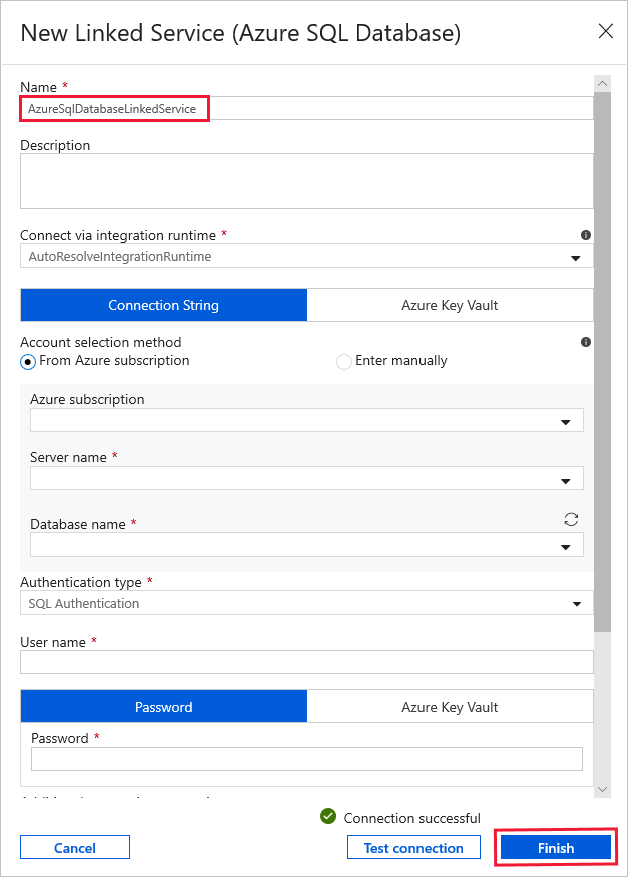
En Linked Service (Servicio vinculado), seleccione New (Nuevo) y siga estos pasos:
Escriba AzureSqlDatabaseLinkedService en Name (Nombre).
Seleccione su servidor en Server name (Nombre del servidor).
Seleccione el nombre de la base de datos en el menú desplegable.
Escriba su nombre de usuario y contraseña.
Para probar la conexión a la base de datos de SQL, haga clic en Test connection (Prueba de conexión).
Haga clic en Finalizar
Confirme que AzureSqlDatabaseLinkedService está seleccionado en Linked service (Servicio vinculado).
Seleccione Finalizar.
En la pestaña Connection (Conexión), seleccione [dbo].[watermarktable] en Table (Tabla). Si desea una vista previa de los datos de la tabla, haga clic en Preview data (Vista previa de los datos).
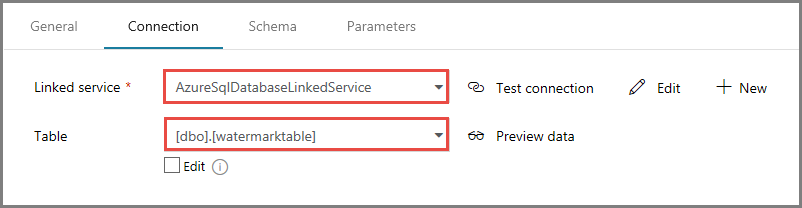
Cambie al editor de canalización; para ello, haga clic en la pestaña de la canalización de la parte superior o en el nombre de esta de la vista de árbol de la izquierda. En la ventana de propiedades de la actividad de búsqueda, confirme que WatermarkDataset está seleccionado en el campo Source Dataset (Conjunto de datos de origen).
En el cuadro de herramientas Activities (Actividades), expanda General (General), y arrastre otra actividad Lookup (Búsqueda) y colóquela en la superficie del diseñador de canalizaciones; después, establezca el nombre en LookupNewWaterMarkActivity en la pestaña General (General) de la ventana de propiedades. Esta actividad de búsqueda obtiene el nuevo valor de marca de agua de la tabla y copia los datos de origen en el destino.
En la ventana de propiedades de la segunda actividad de búsqueda, cambie a la pestaña Settings (Configuración) y haga clic en New (Nuevo). Creará un conjunto de datos que apuntará a la tabla de origen con el nuevo valor de marca de agua (valor máximo de LastModifyTime).
En la ventana New Dataset (Nuevo conjunto de datos), seleccione Azure SQL Database y haga clic en Continue (Continuar).
En la ventana Set Properties (Establecer propiedades), escriba SourceDataset (Conjunto de datos de origen) en Name (Nombre). Seleccione AzureSqlDatabaseLinkedService como Linked service (Servicio vinculado).
Seleccione [dbo].[data_source_table] en Table (Tabla). Más adelante en este tutorial especificará una consulta en este conjunto de datos. La consulta tiene prioridad sobre la tabla que se especifica en este paso.
Seleccione Finalizar.
Cambie al editor de canalización; para ello, haga clic en la pestaña de la canalización de la parte superior o en el nombre de esta de la vista de árbol de la izquierda. En la ventana de propiedades de la actividad de búsqueda, confirme que SourceDataset está seleccionado en el campo Source Dataset (Conjunto de datos de origen).
Seleccione Query (Consulta) en el campo Use Query (Usar consulta) y escriba la siguiente consulta: solo se selecciona el valor máximo de LastModifytime de data_source_table. Asegúrese de haber activado también First row only (Solo la primera fila).
select MAX(LastModifytime) as NewWatermarkvalue from data_source_table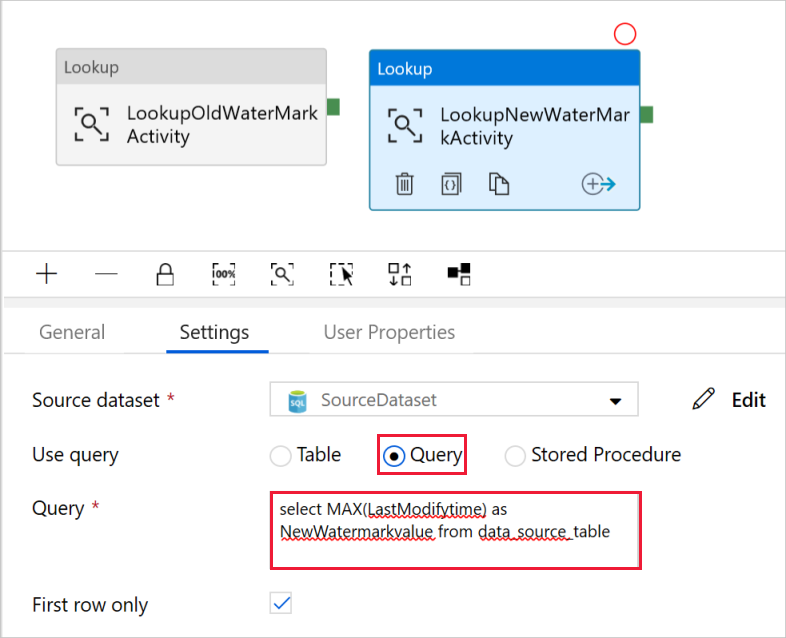
En el cuadro de herramientas Activities (Actividades), expanda Move & Transform (Mover y transformar) y arrastre la actividad Copy (Copiar) del cuadro de herramientas Activities (Actividades); después, establezca el nombre en IncrementalCopyActivity.
Conecte las dos actividades Lookup (Búsqueda) a la actividad Copy (Copiar) ; para ello, arrastre el botón verde de las actividades de búsqueda a la actividad de copia. Suelte el botón del mouse cuando vea el color del borde de la actividad de copia cambiar a azul.
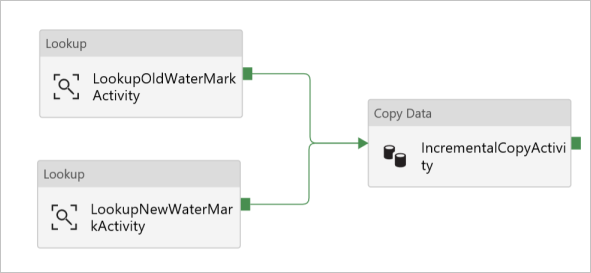
Seleccione la actividad de copia y confirme que ve sus propiedades en la ventana Properties (Propiedades).
Cambie a la pestaña Source (Origen) de la ventana Properties (Propiedades) y realice los pasos siguientes:
Seleccione SourceDataset en el campo Source Dataset (Conjunto de datos de origen).
Seleccione Query (Consulta) en el campo Use Query (Usar consulta).
Escriba la siguiente consulta SQL en el campo Query (Consulta).
select * from data_source_table where LastModifytime > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and LastModifytime <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'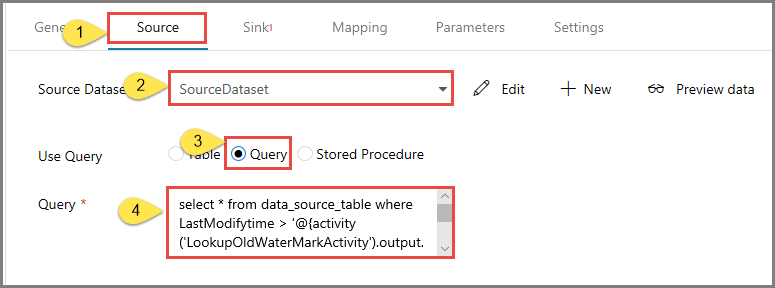
Cambie a la pestaña Sink (Receptor) y haga clic en + New (+ Nuevo) en el campo Sink Dataset (Conjunto de datos receptor).
En este tutorial, el almacén de datos receptor es de tipo Azure Blob Storage. Por lo tanto, seleccione Azure Blob Storage y haga clic en Continue (Continuar) en la ventana New Dataset (Nuevo conjunto de datos).
En la página Select Format (Seleccionar formato), elija el tipo de formato de los datos y, después, seleccione Continue (Continuar).
En la ventana Set Properties (Establecer propiedades), escriba SinkDataset (Conjunto de datos de receptor) en Name (Nombre). En Linked Service (Servicio vinculado), seleccione + New (+ Nuevo). En este paso se crea una conexión (servicio vinculado) y su instancia de Azure Blob Storage.
En la ventana New Linked Service (Azure Blob Storage) [Nuevo servicio vinculado (Azure Blob Storage)], realice los siguientes pasos:
- Escriba AzureStorageLinkedService en Name (Nombre).
- Seleccione la cuenta de Azure Storage en Storage account name (Nombre de la cuenta de Storage).
- Pruebe la conexión y, a continuación, haga clic en Finalizar.
En la ventana Set Properties (Establecer propiedades), confirme que AzureStorageLinkedService está seleccionado para Linked service (Servicio vinculado). Después, seleccione Finalizar.
Vaya a la pestaña Connection (Conexión) de SinkDataset y realice los pasos siguientes:
- En el campo File path (Ruta de acceso de archivo), escriba adftutorial/incrementalcopy. adftutorial es el nombre del contenedor de blobs; incrementalcopy, el de la carpeta. Con este fragmento de código se da por supuesto que tiene un contenedor de blob denominado adftutorial en Blob Storage. Cree el contenedor si no existe o asígnele el nombre de uno existente. Si no existe, Azure Data Factory crea automáticamente la carpeta de salida incrementalcopy. También puede usar el botón Browse (Examinar) para ir a una carpeta del contenedor de blobs mediante la ruta de acceso del archivo.
- En la parte File (Archivo) del campo File path (Ruta de acceso de archivo), seleccione Add dynamic content [ALT+P] y, después, escriba
@CONCAT('Incremental-', pipeline().RunId, '.txt')en la ventana abierta. Después, seleccione Finalizar. El nombre de archivo se genera dinámicamente mediante la expresión. Cada ejecución de canalización tiene un identificador único. La actividad de copia usa el identificador de ejecución para generar el nombre de archivo.
Cambie al editor de canalización; para ello, haga clic en la pestaña de la canalización de la parte superior o en el nombre de esta de la vista de árbol de la izquierda.
En el cuadro de herramientas Activities (Actividades), expanda General (General), arrastre la actividad Stored Procedure (Procedimiento almacenado) del cuadro de herramientas Actividades para colocarla en la superficie del diseñador de canalizaciones. Conecte el resultado verde (correcto) de la actividad Copy (Copiar) con la actividad Stored Procedure (Procedimiento almacenado).
Seleccione Stored Procedure Activity (Actividad Procedimiento almacenado) en el diseñador de canalizaciones y cambie el nombre a StoredProceduretoWriteWatermarkActivity.
Cambie a la pestaña SQL Account (Cuenta de SQL) y seleccione AzureSqlDatabaseLinkedService en Linked service (Servicio vinculado).
Cambie a la pestaña Stored Procedure (Procedimiento almacenado) y realice los pasos siguientes:
En Stored procedure name (Nombre del procedimiento almacenado), seleccione usp_write_watermark.
Para especificar valores para los parámetros del procedimiento almacenado, haga clic en Import parameter (Importar parámetro) y escriba los valores siguientes:
Nombre Tipo Value LastModifiedtime DateTime @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue} TableName String @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName} 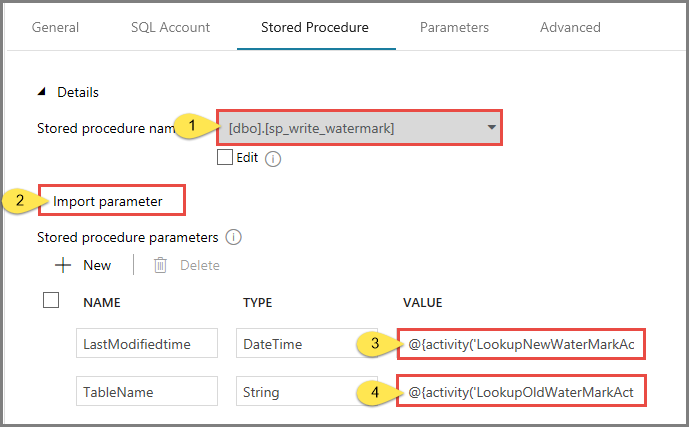
Para validar la configuración de canalización, haga clic en Validate (Validar) en la barra de herramientas. Confirme que no haya errores de comprobación. Para cerrar la ventana Pipeline Validation Report (Informe de validación de la canalización), haga clic en >>.
Para publicar entidades (servicios vinculados, conjuntos de datos y canalizaciones) en el servicio Azure Data Factory, seleccione el botón Publish All (Publicar todo). Espere hasta que vea un mensaje de que la publicación se completó correctamente.
Desencadenamiento de una ejecución de la canalización
Haga clic en Add Trigger (Agregar desencadenar) en la barra de herramientas y en Trigger Now (Desencadenar ahora).
En la ventana Pipeline Run (Ejecución de canalización), seleccione Finish (Finalizar).
Supervisión de la ejecución de la canalización
Cambie a la pestaña Monitor (Supervisar) de la izquierda. Verá el estado de ejecución de la canalización desencadenada por un desencadenador manual. Puede usar los vínculos de la columna NOMBRE DE CANALIZACIÓN para ver los detalles de la ejecución y volver a ejecutar la canalización.
Para ver las ejecuciones de actividad asociadas a la ejecución de la canalización, seleccione el vínculo en la columna NOMBRE DE CANALIZACIÓN. Para más información sobre las ejecuciones de actividad, seleccione el vínculo Detalles (icono de gafas) en la columna NOMBRE DE ACTIVIDAD. Para volver a la vista Ejecuciones de canalización, seleccione All pipeline runs (Todas las ejecuciones de canalización) en la parte superior. Para actualizar la vista, seleccione Refresh (Actualizar).
Revisión del resultado
Puede conectarse a su cuenta de Azure Storage mediante herramientas como el Explorador de Azure Storage. Compruebe que se crea un archivo de salida en la carpeta incrementalcopy del contenedor adftutorial.

Abra el archivo de salida y observe que todos los datos se hayan copiado de data_source_table en el archivo de blobs.
1,aaaa,2017-09-01 00:56:00.0000000 2,bbbb,2017-09-02 05:23:00.0000000 3,cccc,2017-09-03 02:36:00.0000000 4,dddd,2017-09-04 03:21:00.0000000 5,eeee,2017-09-05 08:06:00.0000000Compruebe el valor más reciente de
watermarktable. Verá que se ha actualizado el valor de marca de agua.Select * from watermarktableEste es el resultado:
| TableName | WatermarkValue | | --------- | -------------- | | data_source_table | 2017-09-05 8:06:00.000 |
Incorporación de más datos al origen
Inserte nuevos datos en la base de datos (almacén de origen de datos).
INSERT INTO data_source_table
VALUES (6, 'newdata','9/6/2017 2:23:00 AM')
INSERT INTO data_source_table
VALUES (7, 'newdata','9/7/2017 9:01:00 AM')
Los datos actualizados de la base de datos son los siguientes:
PersonID | Name | LastModifytime
-------- | ---- | --------------
1 | aaaa | 2017-09-01 00:56:00.000
2 | bbbb | 2017-09-02 05:23:00.000
3 | cccc | 2017-09-03 02:36:00.000
4 | dddd | 2017-09-04 03:21:00.000
5 | eeee | 2017-09-05 08:06:00.000
6 | newdata | 2017-09-06 02:23:00.000
7 | newdata | 2017-09-07 09:01:00.000
Desencadenamiento de otra ejecución de canalización
Cambie a la pestaña Edit (Editar). Si no está abierta en el diseñador, haga clic en la canalización en la vista de árbol.
Haga clic en Add Trigger (Agregar desencadenar) en la barra de herramientas y en Trigger Now (Desencadenar ahora).
Supervisión de la segunda ejecución de la canalización
Cambie a la pestaña Monitor (Supervisar) de la izquierda. Verá el estado de ejecución de la canalización desencadenada por un desencadenador manual. Puede usar los vínculos de la columna PIPELINE NAME (Nombre de la canalización) para ver los detalles de la actividad y volver a ejecutar la canalización.
Para ver las ejecuciones de actividad asociadas a la ejecución de la canalización, seleccione el vínculo en la columna NOMBRE DE CANALIZACIÓN. Para más información sobre las ejecuciones de actividad, seleccione el vínculo Detalles (icono de gafas) en la columna NOMBRE DE ACTIVIDAD. Para volver a la vista Ejecuciones de canalización, seleccione All pipeline runs (Todas las ejecuciones de canalización) en la parte superior. Para actualizar la vista, seleccione Refresh (Actualizar).
Comprobación de la segunda salida
En la instancia de Blob Storage, verá que se ha creado otro archivo. En este tutorial, el nombre de archivo nuevo es
Incremental-<GUID>.txt. Abra ese archivo y verá que contiene dos filas de registros.6,newdata,2017-09-06 02:23:00.0000000 7,newdata,2017-09-07 09:01:00.0000000Compruebe el valor más reciente de
watermarktable. Verá que se ha vuelto a actualizar el valor de marca de agua.Select * from watermarktableSalida del ejemplo:
| TableName | WatermarkValue | | --------- | -------------- | | data_source_table | 2017-09-07 09:01:00.000 |
Contenido relacionado
En este tutorial, realizó los pasos siguientes:
- Preparación del almacén de datos para almacenar el valor de marca de agua
- Creación de una factoría de datos.
- Cree servicios vinculados.
- Creación de conjuntos de datos de marca de agua, de origen y de receptor.
- Creación de una canalización
- Ejecución de la canalización
- Supervisión de la ejecución de la canalización
- Revisión de los resultados
- Adición de más datos al origen
- Repetición de la ejecución de la canalización
- Supervisión de la segunda ejecución de la canalización
- Revisión de los resultados de la segunda ejecución
En este tutorial, la canalización copió datos de una única tabla de SQL Database a Blob Storage. Avance al tutorial siguiente para aprender a copiar datos de varias tablas de una base de datos de SQL Server en SQL Database.