Carga incremental de datos de Instancia administrada de Azure SQL a Azure Blob Storage mediante la captura de datos modificados (CDC)
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este tutorial, creará una factoría de datos de Azure con una canalización que carga en una instancia de Azure Blob Storage los datos diferenciales según la información de captura de datos modificados (CDC) de la base de datos de Instancia administrada de Azure SQL de origen.
En este tutorial, realizará los siguientes pasos:
- Preparación del almacenamiento de datos de origen
- Creación de una factoría de datos.
- Cree servicios vinculados.
- Creación de conjuntos de datos de origen y receptores.
- Creación, depuración y ejecución de la canalización para comprobar los datos modificados
- Modificación de los datos de la tabla de origen
- Creación, ejecución y supervisión de la canalización de copia incremental completa
Información general
La tecnología de captura de datos modificados compatible con los almacenes de datos, como Instancias administradas (MI) de Azure SQL y SQL Server, se puede usar para identificar los datos modificados. En este tutorial se describe cómo usar Azure Data Factory con la tecnología de captura de datos modificados de SQL para cargar de forma incremental los datos diferenciales de Instancia administrada de SQL en Azure Blob Storage. Para información más concreta sobre la tecnología de captura de datos modificados de SQL, consulte Acerca de la captura de datos modificados (SQL Server).
Flujo de trabajo de un extremo a otro
Estos son los pasos del flujo de trabajo típico de un extremo a otro para cargar datos de forma incremental mediante la tecnología de captura de datos modificados.
Nota
Tanto Instancia administrada de Azure SQL como SQL Server admiten la tecnología de captura de datos modificados. En este tutorial se usa Instancia administrada de Azure SQL como almacén de datos de origen. También puede usar un servidor local de SQL Server.
Solución de alto nivel
En este tutorial, creará una canalización que realiza las siguientes operaciones:
- Crea una actividad de búsqueda para contar el número de registros modificados en la tabla CDC de SQL Database y la pasa a una actividad de condición IF.
- Crea una condición If para comprobar si hay registros modificados y, en caso afirmativo, invoca la actividad de copia.
- Crea una actividad de copia para copiar los datos insertados, actualizados o eliminados entre la tabla CDC y Azure Blob Storage.
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Requisitos previos
- Azure SQL Managed Instance. La base de datos se usa como almacén de datos de origen. Si no tiene Azure SQL Managed Instance, consulte los pasos del artículo Creación de una instancia administrada de Azure SQL Database para crear una.
- Cuenta de Azure Storage. Blob Storage se usa como almacén de datos receptor. Si no tiene una cuenta de almacenamiento de Azure, consulte el artículo Crear una cuenta de almacenamiento para ver los pasos para su creación. Cree un contenedor llamado raw.
Creación de una tabla de origen de datos en Azure SQL Database
Inicie SQL Server Management Studio y conéctese al servidor de Instancias administradas de Azure SQL.
En el Explorador de servidores, haga clic con el botón derecho en la base de datos y elija la Nueva consulta.
Ejecute el siguiente comando SQL en su base de datos de Instancias administradas de Azure SQL para crear una tabla llamada
customerscomo almacén de origen de datos.create table customers ( customer_id int, first_name varchar(50), last_name varchar(50), email varchar(100), city varchar(50), CONSTRAINT "PK_Customers" PRIMARY KEY CLUSTERED ("customer_id") );Habilite el mecanismo Captura de datos modificados en la base de datos y la tabla de origen (customers) mediante la ejecución de la siguiente consulta SQL:
Nota
- Reemplace <el nombre del esquema de origen> por el esquema de Instancia administrada de Azure SQL que tiene la tabla customers.
- La captura de datos modificados no hace nada como parte de las transacciones que cambian la tabla de la que se realiza el seguimiento. En cambio, las operaciones de inserción, actualización y eliminación se escriben en el registro de transacciones. Los datos que se depositan en las tablas de cambios crecerán hasta llegar a ser incontrolables si no se reduce su número de forma periódica y sistemática. Para más información, consulte Habilitar la captura de datos modificados para una base de datos.
EXEC sys.sp_cdc_enable_db EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'customers', @role_name = NULL, @supports_net_changes = 1Inserte los datos en la tabla customers ejecutando el comando siguiente:
insert into customers (customer_id, first_name, last_name, email, city) values (1, 'Chevy', 'Leward', 'cleward0@mapy.cz', 'Reading'), (2, 'Sayre', 'Ateggart', 'sateggart1@nih.gov', 'Portsmouth'), (3, 'Nathalia', 'Seckom', 'nseckom2@blogger.com', 'Portsmouth');Nota
Antes de que se habilite la captura de datos modificados, no se capturan cambios históricos en la tabla.
Crear una factoría de datos
Siga los pasos del artículo Inicio rápido: Creación de una factoría de datos mediante Azure Portal para crear una factoría de datos si aún no tiene una con la que trabajar.
Crear servicios vinculados
Los servicios vinculados se crean en una factoría de datos para vincular los almacenes de datos y los servicios de proceso con la factoría de datos. En esta sección, creará servicios vinculados a la cuenta de Azure Storage e Instancia administrada de Azure SQL.
Creación de un servicio vinculado de Azure Storage
En este paso, vincula su cuenta de Azure Storage a la factoría de datos.
Haga clic en Connections (Conexiones) y en + New (+ Nuevo).
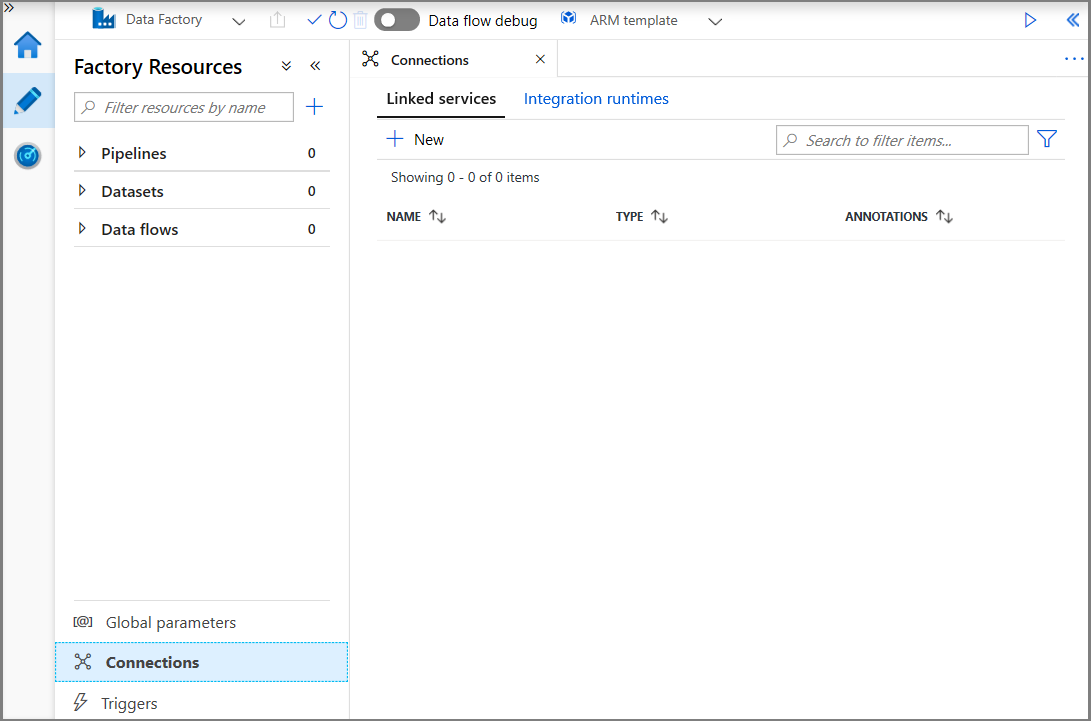
En la ventana New Linked Service (Nuevo servicio vinculado), seleccione Azure Blob Storage y haga clic en Continue (Continuar).
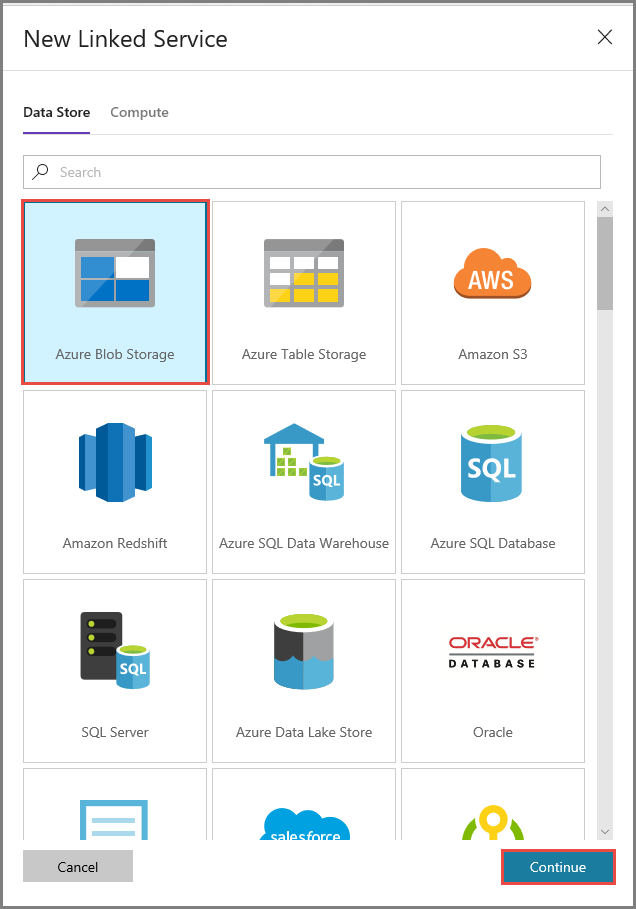
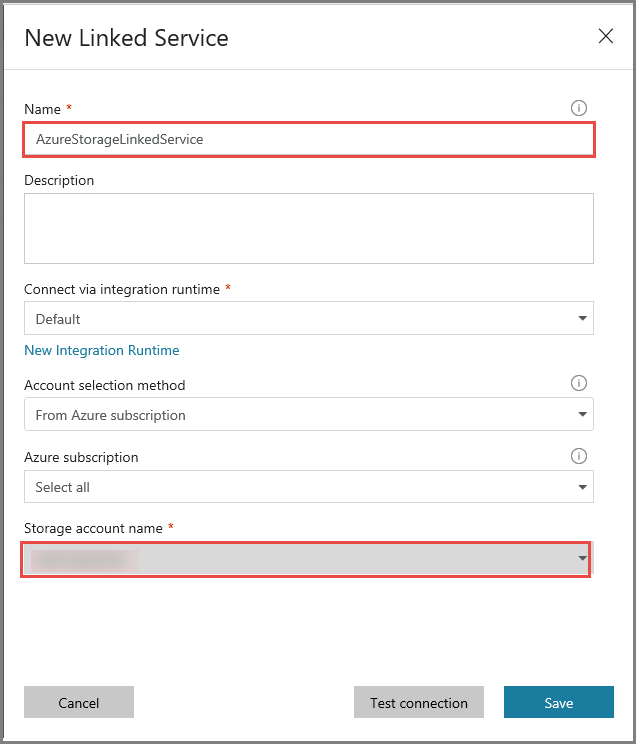
En la ventana New Linked Service (Nuevo servicio vinculado), realice los pasos siguientes:
- Escriba AzureStorageLinkedService en Name (Nombre).
- Seleccione la cuenta de Azure Storage en Storage account name (Nombre de la cuenta de Storage).
- Haga clic en Save(Guardar).
Cree un servicio vinculado de base de datos de Instancia administrada de Azure SQL.
En este paso, vinculará la base de datos de Instancia administrada de Azure SQL a la factoría de datos.
Nota
Para aquellos que usan Instancia administrada de SQL, consulte aquí para información sobre el acceso a través de un punto de conexión público frente a privado. Si usa un punto de conexión privado, tendría que ejecutar esta canalización mediante un entorno de ejecución de integración autohospedado. Lo mismo se aplica a los que ejecutan SQL Server en el entorno local, en una máquina virtual o en escenarios de red virtual.
Haga clic en Connections (Conexiones) y en + New (+ Nuevo).
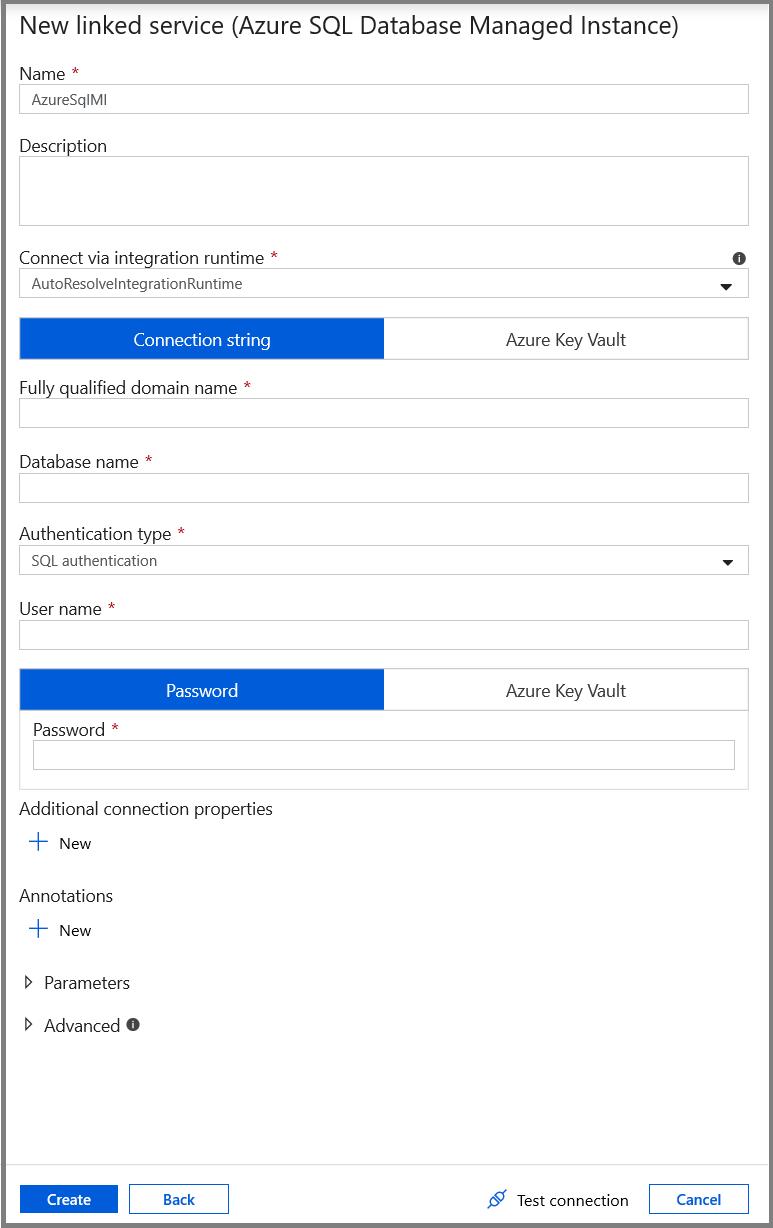
En la ventana New Linked Service (Nuevo servicio vinculado), seleccione Azure SQL Database Managed Instance (Instancia administrada de Azure SQL Database) y haga clic en Continue (Continuar).
En la ventana New Linked Service (Nuevo servicio vinculado), realice los pasos siguientes:
- Escriba AzureSqlMI1 en el campo Name (Nombre).
- Seleccione su servidor SQL en el campo Server name (Nombre del servidor).
- Seleccione la base de datos de SQL en el campo Database name (Nombre de la base de datos).
- Escriba el nombre del usuario en el campo User name (Nombre de usuario).
- Escriba la contraseña del usuario en el campo Password (Contraseña).
- Haga clic en Test connection (Prueba de conexión) para probar la conexión.
- Haga clic en Save (Guardar) para guardar el servicio vinculado.
Creación de conjuntos de datos
En este paso, creará conjuntos de datos para representar el origen y el destino de los datos.
Creación de un conjunto de datos que represente datos de origen
En este paso, creará conjuntos de datos para representar el origen de datos.
En la vista de árbol, haga clic en el signo + (más) y en Dataset (Conjunto de datos).
Seleccione Azure SQL Database Managed Instance (Instancia administrada de Azure SQL Database) y haga clic en Continue (Continuar).
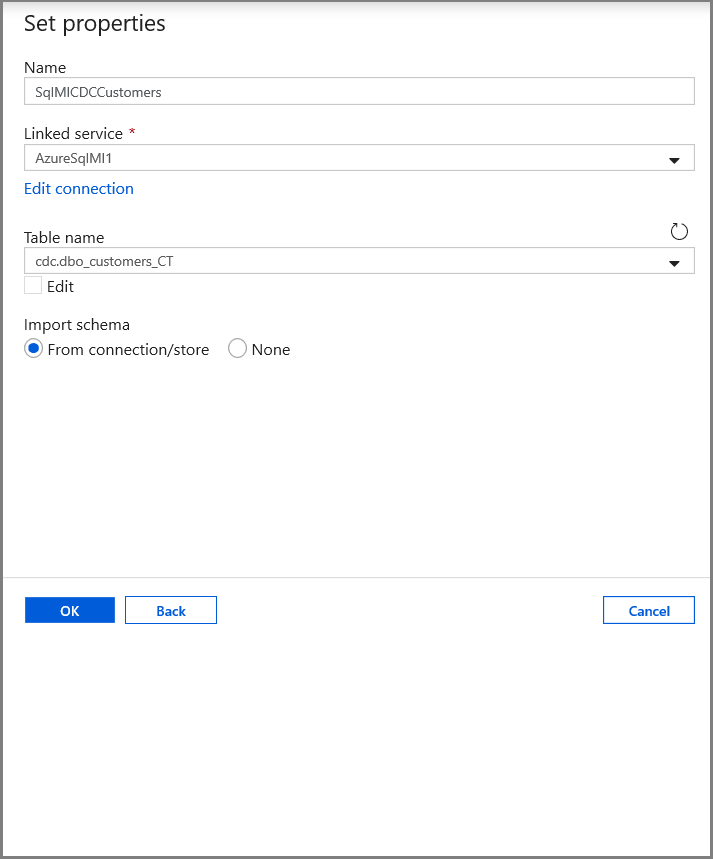
En la pestaña Set properties (Establecer propiedades), establezca la información de nombre y conexión del conjunto de datos:
- Seleccione AzureSqlMI1 en Linked service (Servicio vinculado).
- Seleccione [dbo].[dbo_customers_CT] en Table name (Nombre de la tabla). Nota: Esta tabla se creó automáticamente cuando se habilitó CDC en la tabla customers. Los datos modificados nunca se consultan en esta tabla directamente, sino que se extraen a través de las funciones CDC.
Creación de un conjunto de datos que represente los datos copiados en el almacén de datos receptor
En este paso, creará un conjunto de datos para representar los datos que se copian desde el almacén de datos de origen. Como parte de los requisitos previos, ha creado el contenedor de lago de datos en la instancia de Azure Blob Storage. Cree el contenedor si no existe (o) asígnele el nombre de uno existente. En este tutorial, el nombre del archivo de salida se genera dinámicamente mediante el desencadenador de hora, que se configurará más tarde.
En la vista de árbol, haga clic en el signo + (más) y en Dataset (Conjunto de datos).
Seleccione Azure Blob Storage y haga clic en Continue (Continuar).

Seleccione DelimitedText y haga clic en Continue (Continuar).

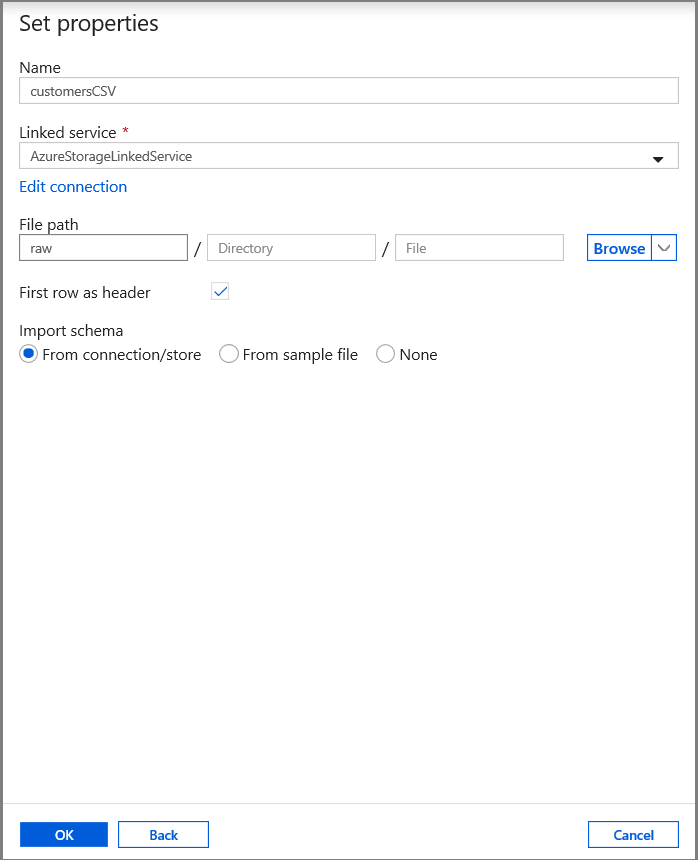
En la pestaña Set properties (Establecer propiedades), establezca la información de nombre y conexión del conjunto de datos:
- Seleccione AzureStorageLinkedService en Linked service (Servicio vinculado).
- Escriba raw (sin procesar) para la parte de container (contenedor) de filePath.
- Habilite First row as header (Primera fila como encabezado).
- Haga clic en Aceptar.
Creación de una canalización para copiar los datos modificados
En este paso, creará una canalización, que primero comprueba el número de registros modificados presentes en la tabla de cambios mediante una actividad de búsqueda. Una actividad de condición IF comprueba si el número de registros modificados es mayor que cero y ejecuta una actividad de copia para copiar los datos insertados, actualizados o eliminados de Azure SQL Database a Azure Blob Storage. Por último, se configura un desencadenador de ventana de saltos de tamaño constante y las horas de inicio y de finalización se pasarán a las actividades como parámetros de la ventana de inicio y de finalización.
En la interfaz de usuario de Data Factory, cambie a la pestaña Edit (Editar). Haga clic en el signo + (más) en el panel izquierdo y en Pipeline (Canalización).
Verá una nueva pestaña para configurar la canalización. También verá la canalización en la vista de árbol. En la ventana Properties (Propiedades), cambie el nombre de la canalización a IncrementalCopyPipeline.
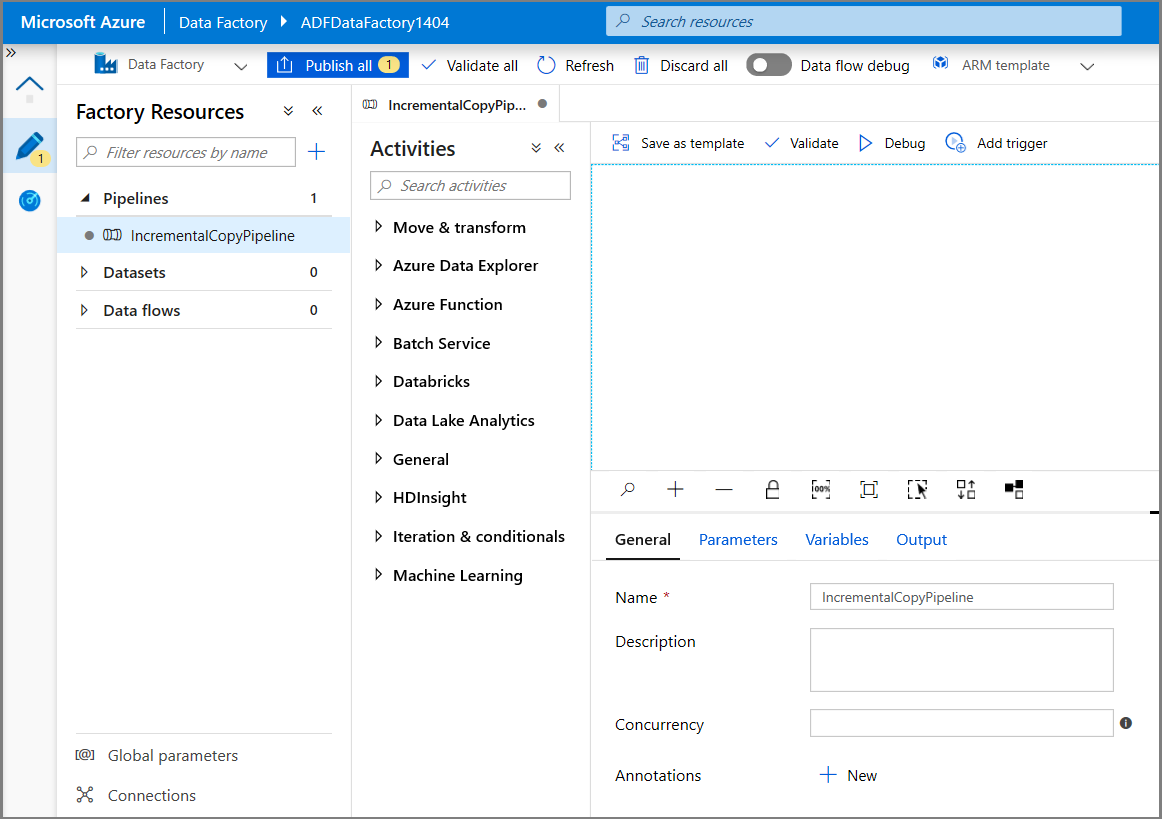
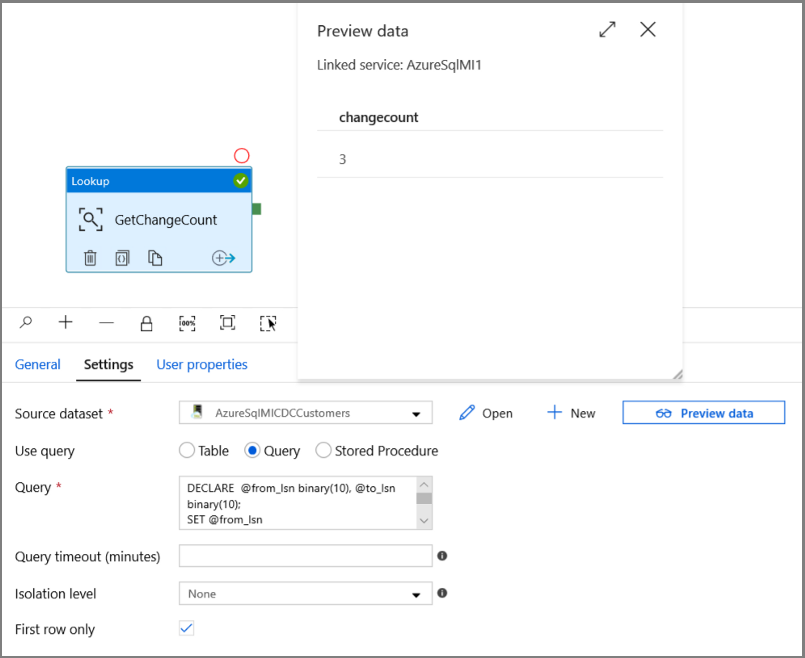
En el cuadro de herramientas Activities (Actividades), expanda General (General), arrastre la actividad Lookup (Búsqueda) y colóquela en la superficie del diseñador de canalizaciones. Establezca el nombre de la actividad en GetChangeCount. Esta actividad obtiene el número de registros de la tabla de cambios durante un período de tiempo determinado.
Cambie a la pestaña Settings (Configuración) de la ventana Properties (Propiedades):
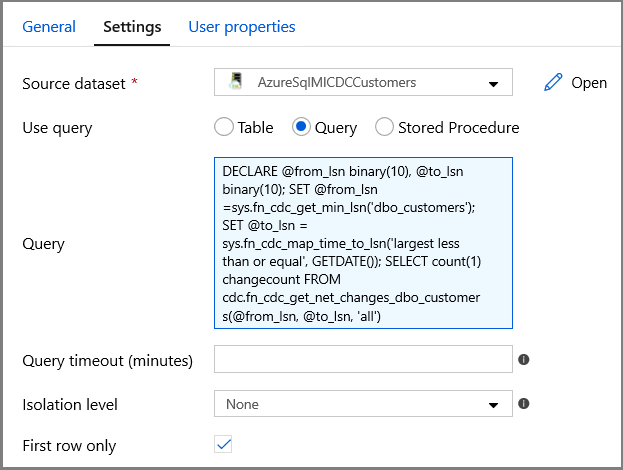
Especifique el nombre del conjunto de datos de Instancia administrada de SQL en el campo Source Dataset (Conjunto de datos de origen).
Seleccione la opción de consulta y escriba lo siguiente en el cuadro de consulta:
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')- Habilite First row only (Solo primera fila).
Haga clic en el botón Preview data (Vista previa de datos) para asegurarse de que la actividad de búsqueda obtiene una salida válida.
Expanda Iteration & conditionals (Iteración y condicionales) en el cuadro de herramientas Activities (Actividades) y arrastre y coloque la actividad If Condition (Condición If) en la superficie del diseñador de canalizaciones. Establezca el nombre de la actividad en HasChangedRows.
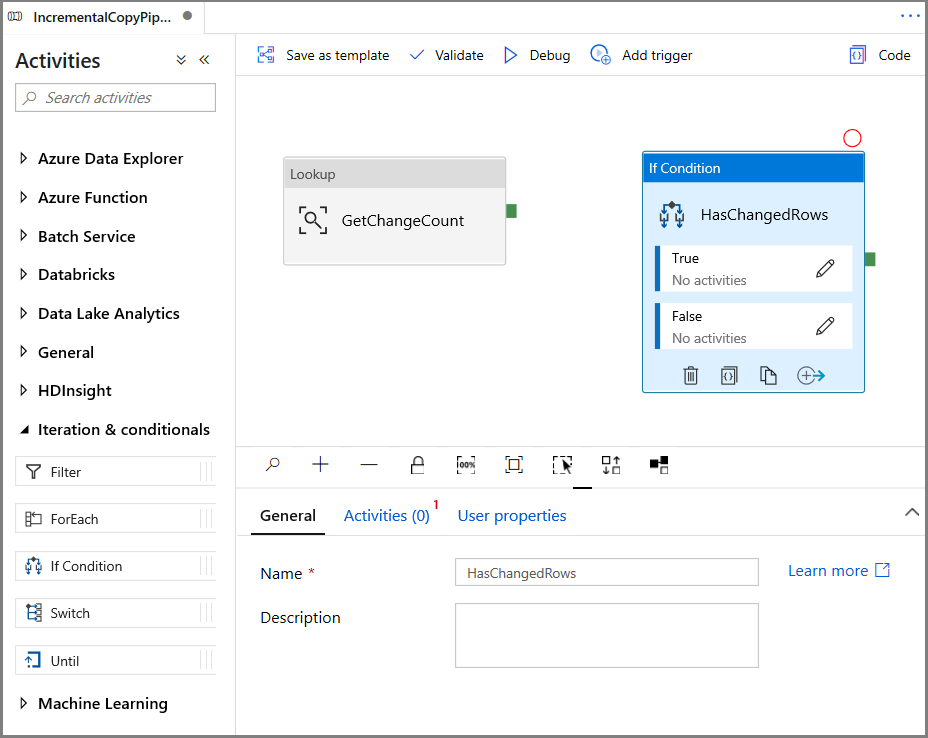
Cambie a Activities (Actividades) en la ventana Properties (Propiedades):
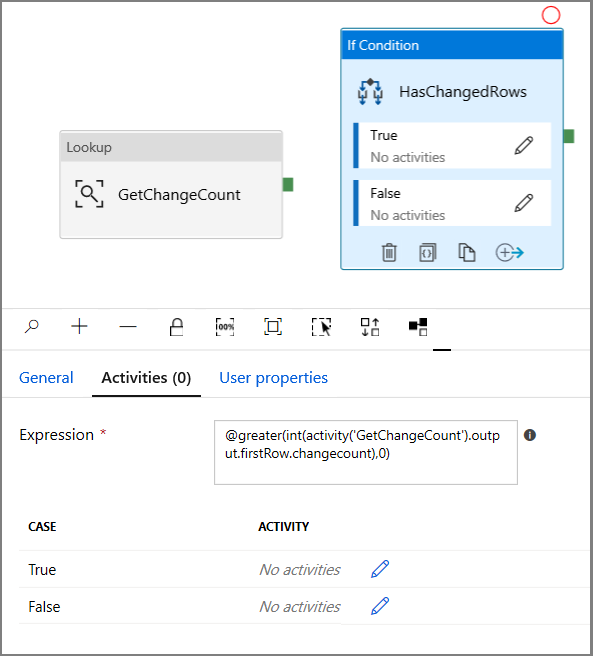
- Escriba la siguiente expresión.
@greater(int(activity('GetChangeCount').output.firstRow.changecount),0)- Haga clic en el icono de lápiz para editar la condición True.
- En el cuadro de herramientas Activities (Actividades), expanda General (General), arrastre la actividad Wait (Espera) y colóquela en la superficie del diseñador de canalizaciones. Esta es una actividad temporal para depurar la condición If y se modificará más adelante en el tutorial.
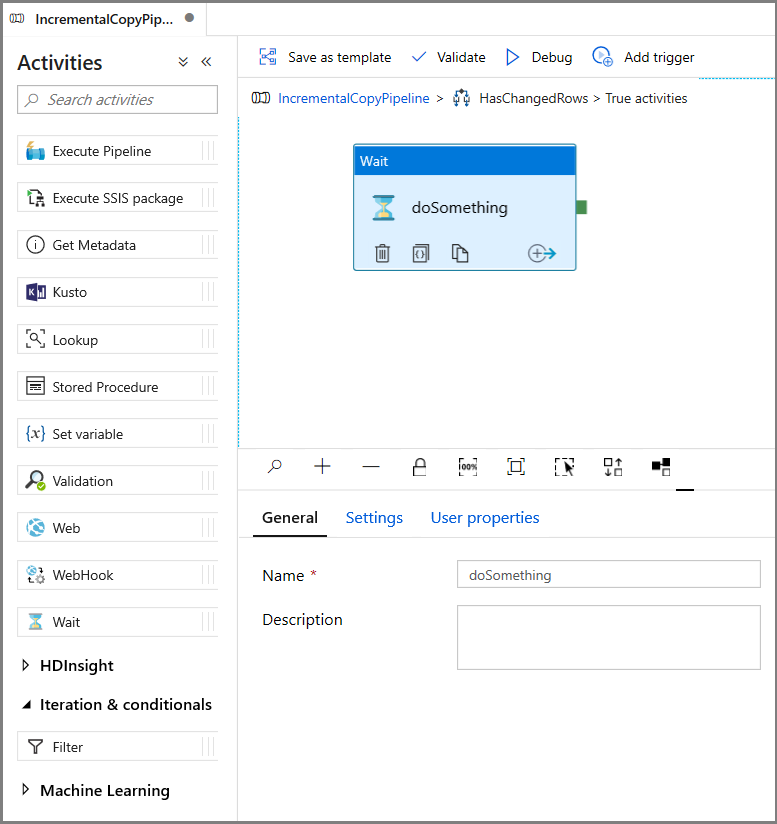
- Haga clic en la ruta de navegación de IncrementalCopyPipeline para volver a la canalización principal.
Ejecute la canalización en modo Debug (Depurar) para comprobar que se ejecuta correctamente.
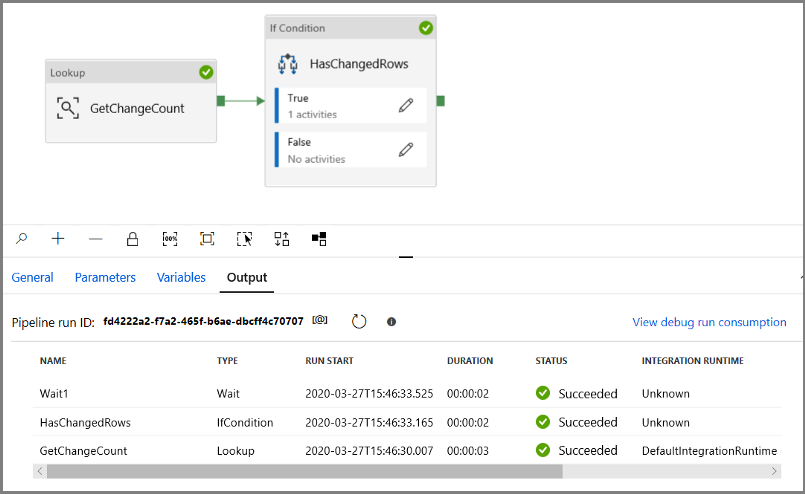
A continuación, vuelva al paso de condición True y elimine la actividad Wait (Espera). En el cuadro de herramientas Activities (Actividades), expanda Move & transform (Mover y transformar), arrastre la actividad Copy (Copia) y colóquela en la superficie del diseñador de canalizaciones. Establezca el nombre de la actividad en IncrementalCopyActivity.
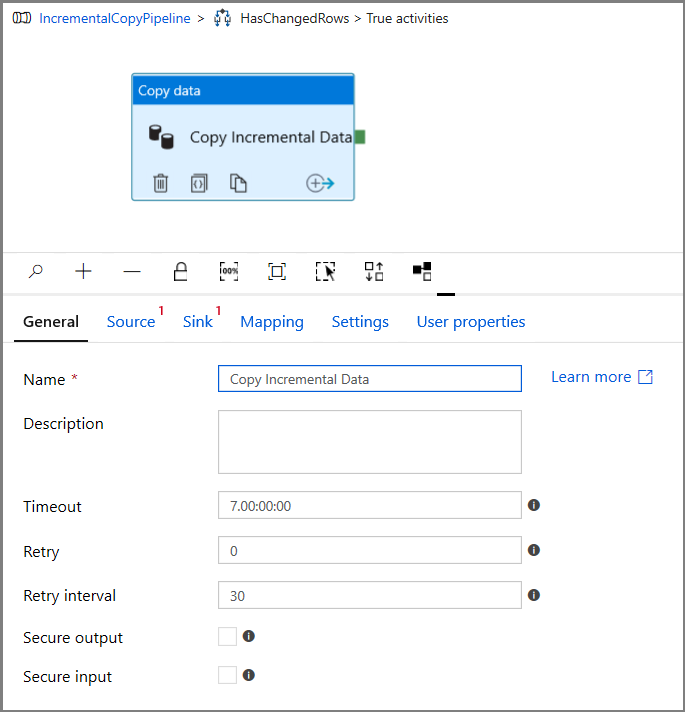
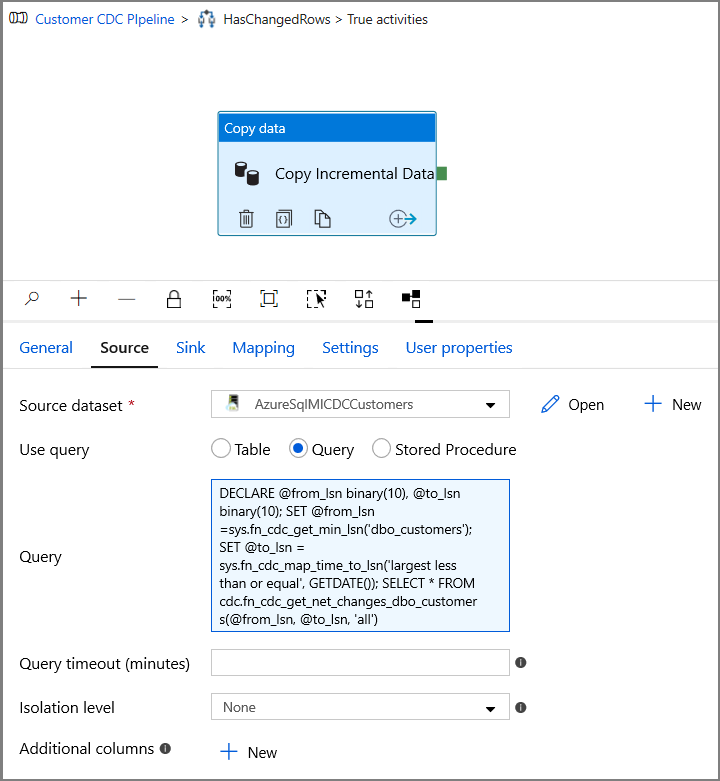
Cambie a la pestaña Source (Origen) de la ventana Properties (Propiedades) y realice los pasos siguientes:
Especifique el nombre del conjunto de datos de Instancia administrada de SQL en el campo Source Dataset (Conjunto de datos de origen).
Seleccione Query (Consulta) en Use Query (Usar consulta).
En Query (Consulta), escriba lo siguiente.
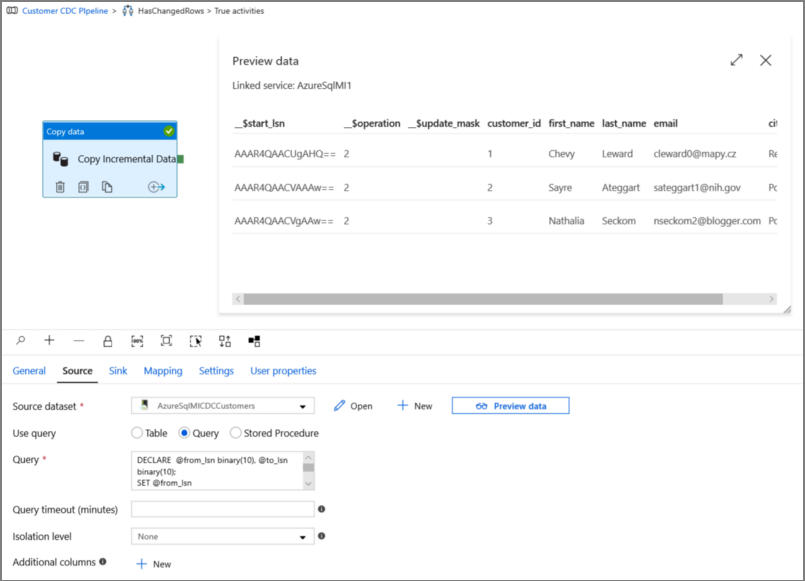
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')
Haga clic en Preview (Vista previa) para comprobar que la consulta devuelve las filas modificadas correctamente.
Cambie a la pestaña Sink (Receptor) y especifique el conjunto de datos de Azure Storage en el campo Sink Dataset (Conjunto de datos de receptor).

Haga clic de nuevo en el lienzo de la canalización principal y conecte la actividad Lookup (Búsqueda) a la actividad If Condition (Condición If) una a una. Arrastre el botón verde asociado a la actividad Lookup (Búsqueda) a la actividad If Condition (Condición If).
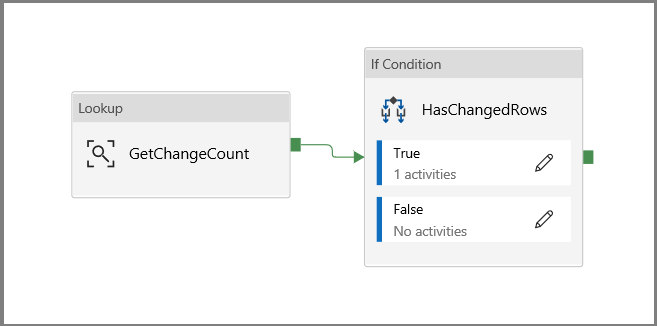
Haga clic en Validate (Comprobar) en la barra de herramientas. Confirme que no haya errores de comprobación. Para cerrar la ventana Pipeline Validation Report (Informe de comprobación de la canalización), haga clic en >>.
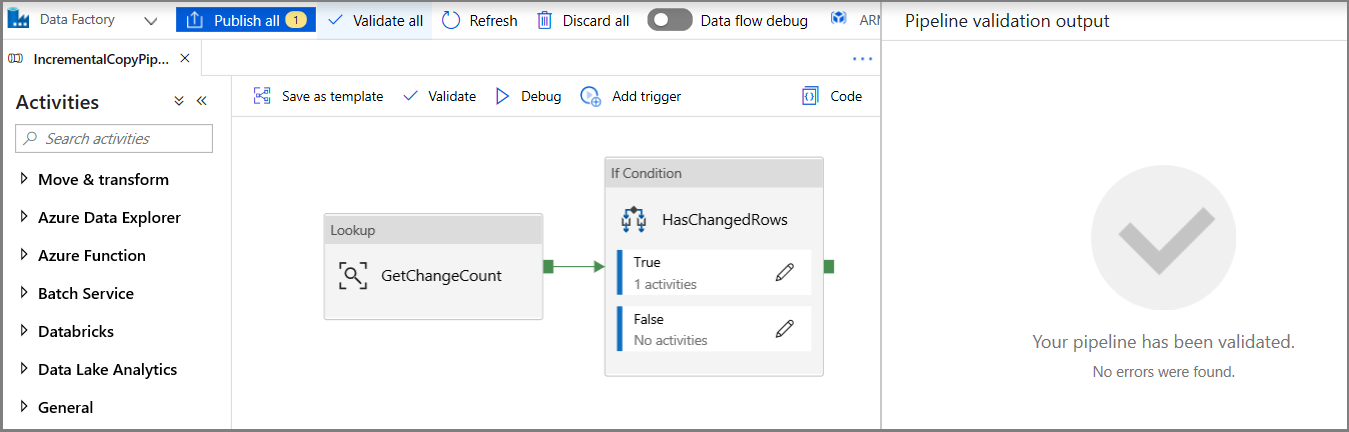
Haga clic en Debug (Depurar) para probar la canalización y comprobar que se genera un archivo en la ubicación de almacenamiento.
Para publicar entidades (servicios vinculados, conjuntos de datos y canalizaciones) en el servicio Data Factory, haga clic en el botón Publicar todo. Espere hasta ver el mensaje Publishing succeeded (Publicación correcta).
Configuración del desencadenador de ventana de saltos de tamaño constante y de los parámetros de la ventana CDC
En este paso, creará un desencadenador de ventana de saltos de tamaño constante para ejecutar el trabajo según una programación frecuente. Usará las variables del sistema WindowStart y WindowEnd del desencadenador de ventana de saltos de tamaño constante y las pasará como parámetros a la canalización que se usará en la consulta CDC.
Vaya a la pestaña Parameters (Parámetros) de la canalización IncrementalCopyPipeline y, con el botón + New (+ Nuevo), agregue dos parámetros (triggerStartTime y triggerEndTime) a la canalización, que representan la hora de inicio y de finalización de la ventana de saltos de tamaño constante. Con fines de depuración, agregue valores predeterminados con el formato AAAA-MM-DD HH24:MI:SS.FFF, pero asegúrese de que triggerStartTime no sea anterior a la CDC que se habilita en la tabla o se producirá un error.
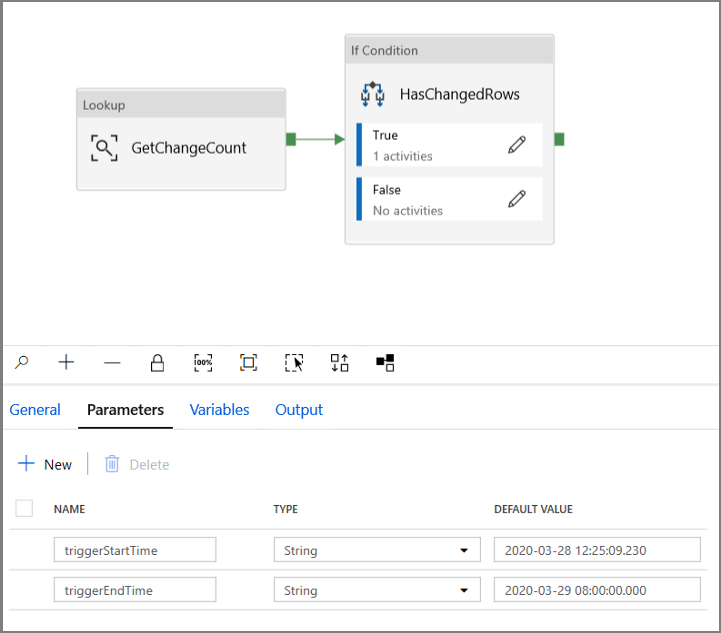
Haga clic en la pestaña de configuración de la actividad Lookup (Búsqueda) y configure la consulta para usar los parámetros de inicio y de finalización. Copie lo siguiente en la consulta:
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')Vaya a la actividad Copy (Copia) en el caso True de la actividad If Condition (Condición if) y haga clic en la pestaña Source (Origen). Copie lo siguiente en la consulta:
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')Haga clic en la pestaña Sink (Receptor) de la actividad Copy (Copia) y haga clic en Open (Abrir) para editar los parámetros del conjunto de datos. Haga clic en la pestaña Parameters (Parámetros) y agregue un nuevo parámetro denominado triggerStart
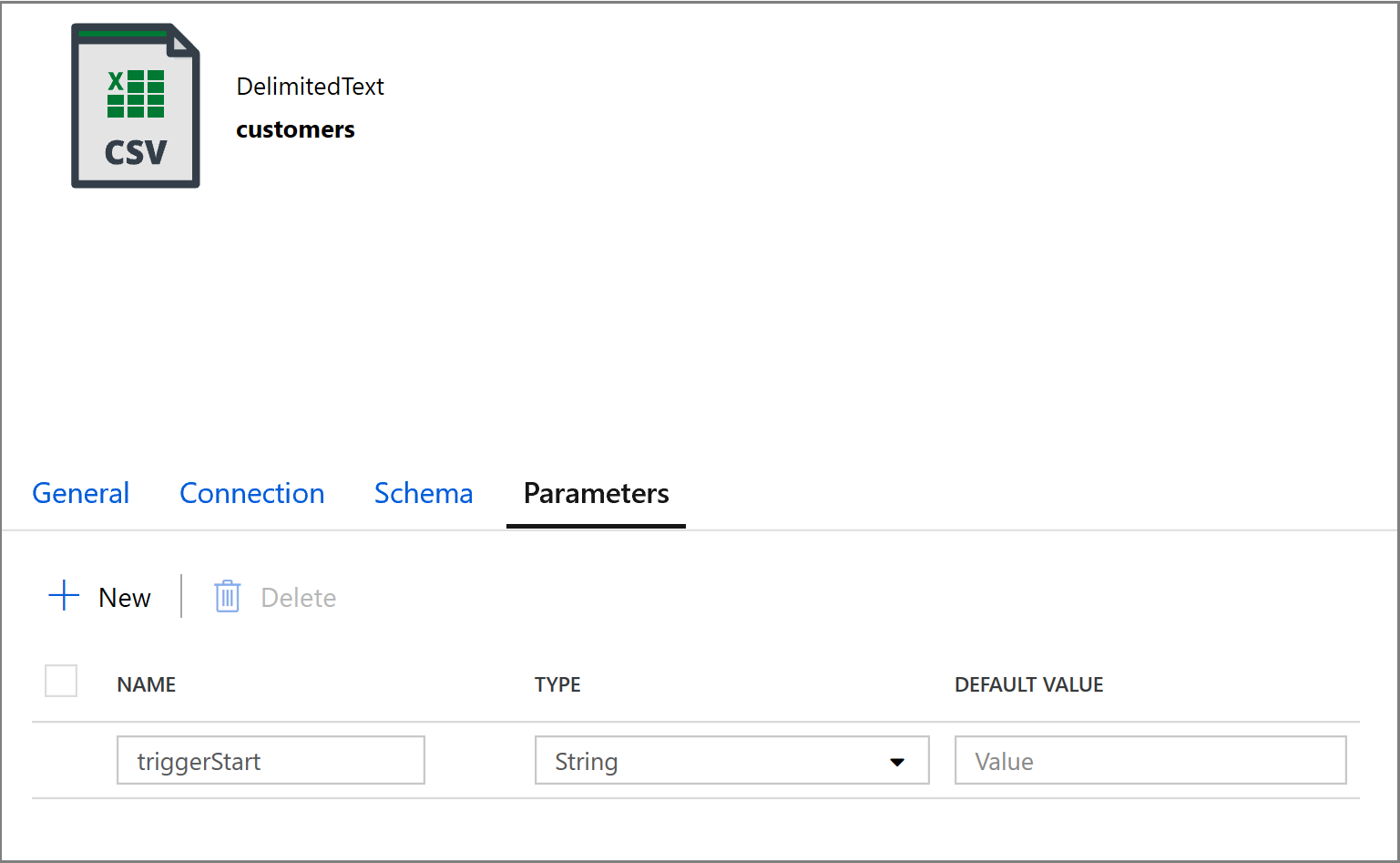
A continuación, configure las propiedades del conjunto de datos para almacenar los datos en el subdirectorio clientes/incremental con particiones basadas en fechas.
Haga clic en la pestaña Connection (Conexión) de las propiedades del conjunto de datos y agregue contenido dinámico en las secciones Directory (Directorio) y File (Archivo).
Escriba la siguiente expresión en la sección Directory (Directorio); para ello, haga clic en el vínculo de contenido dinámico en el cuadro de texto:
@concat('customers/incremental/',formatDateTime(dataset().triggerStart,'yyyy/MM/dd'))Escriba la siguiente expresión en la sección File (Archivo). Se crean nombres de archivo basados en la fecha y la hora de inicio del desencadenador, con el sufijo de la extensión csv:
@concat(formatDateTime(dataset().triggerStart,'yyyyMMddHHmmssfff'),'.csv')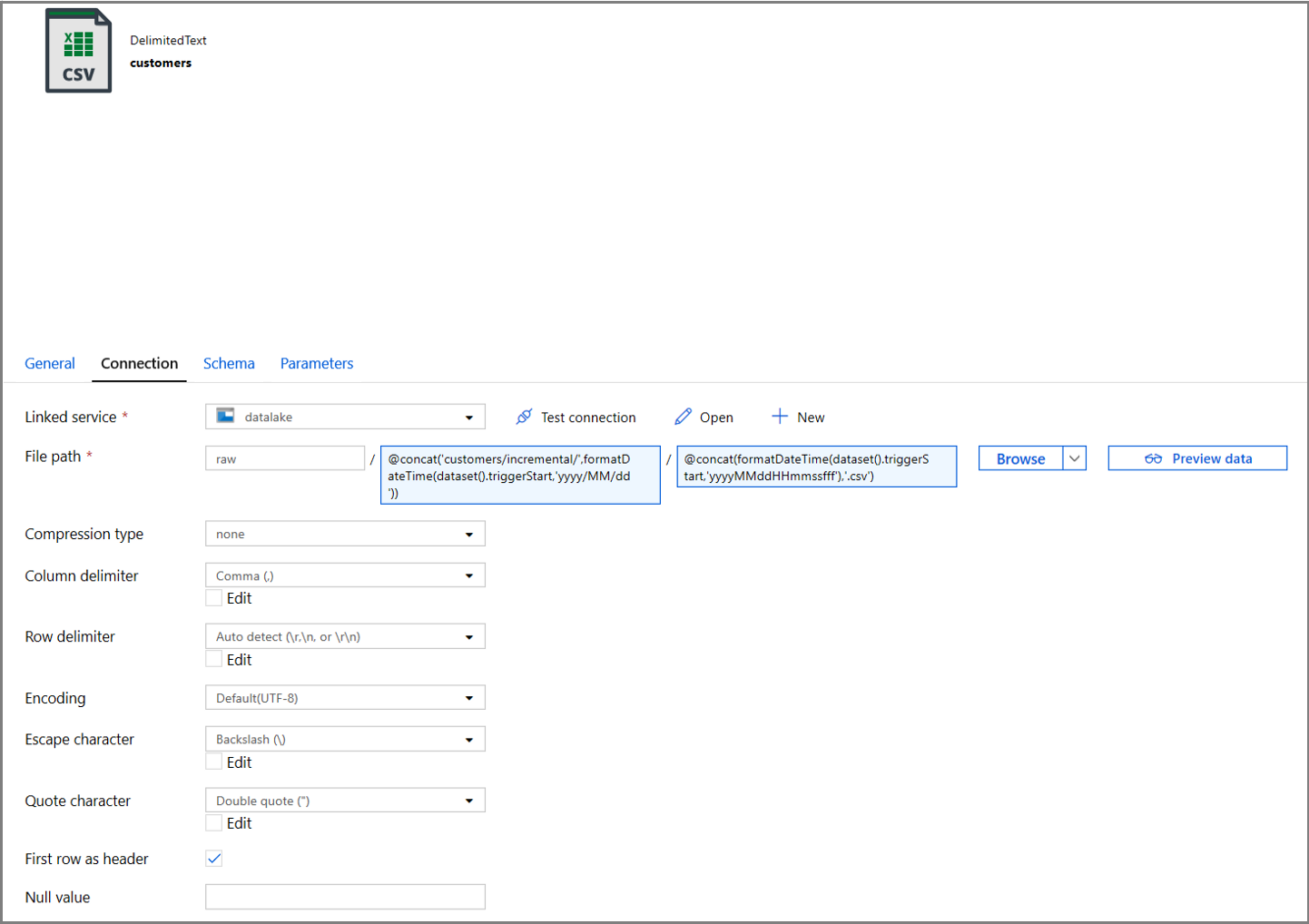
Vuelva a la configuración de Sink (Receptor) de la actividad Copy (Copia) haciendo clic en la pestaña IncrementalCopyPipeline.
Expanda las propiedades del conjunto de datos y escriba contenido dinámico en el valor del parámetro triggerStart con la siguiente expresión:
@pipeline().parameters.triggerStartTime
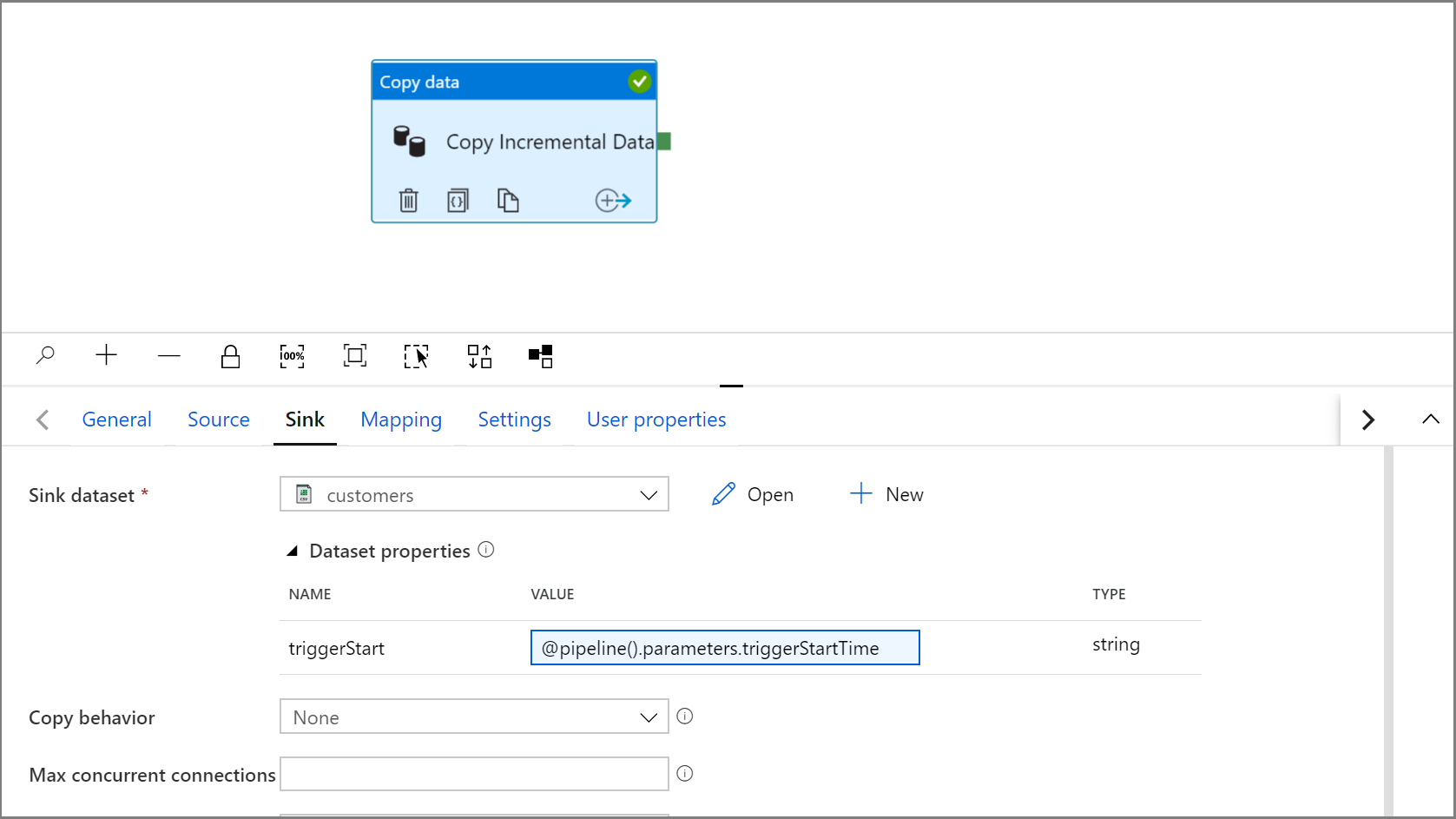
Haga clic en Debug (Depurar) para probar la canalización y asegurarse de que la estructura de carpetas y el archivo de salida se generan según lo previsto. Descargue y abra el archivo para comprobar el contenido.
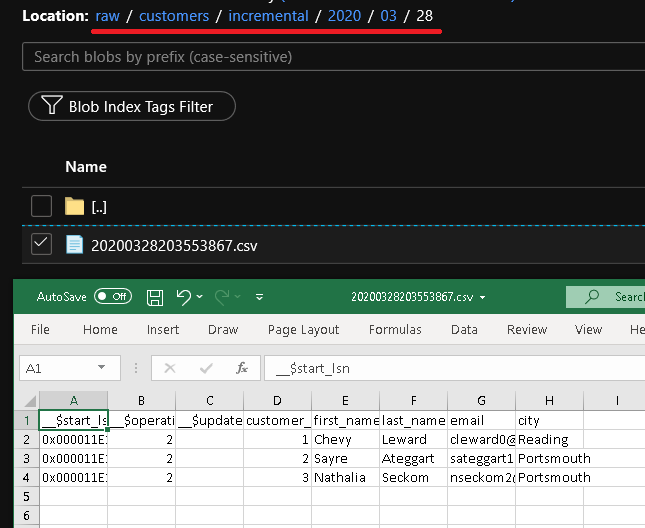
Asegúrese de que los parámetros se inserten en la consulta, para lo cual debe revisar los parámetros de entrada de la ejecución de canalización.
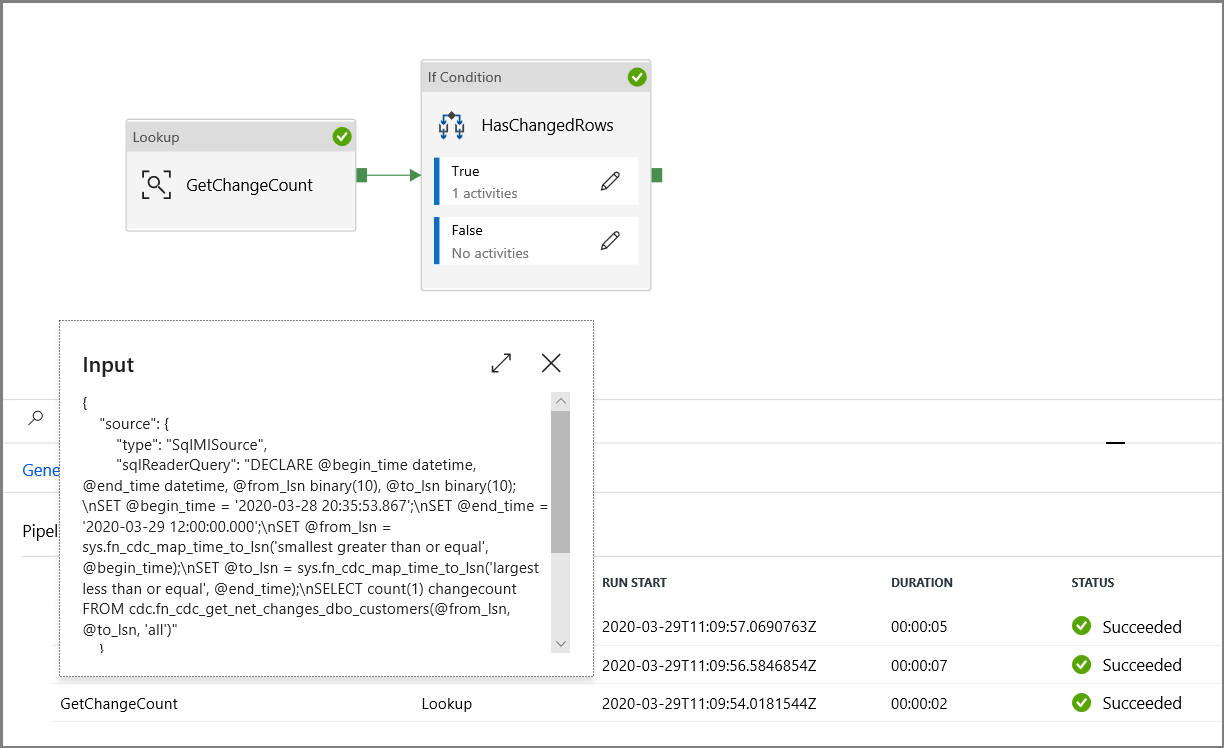
Para publicar entidades (servicios vinculados, conjuntos de datos y canalizaciones) en el servicio Data Factory, haga clic en el botón Publicar todo. Espere hasta ver el mensaje Publishing succeeded (Publicación correcta).
Por último, configure un desencadenador de ventana de saltos de tamaño constante para ejecutar la canalización a intervalos regulares y establecer los parámetros de hora de inicio y de finalización.
- Haga clic en el botón Add trigger (Agregar desencadenador) y seleccione New/Edit (Nuevo/Editar).
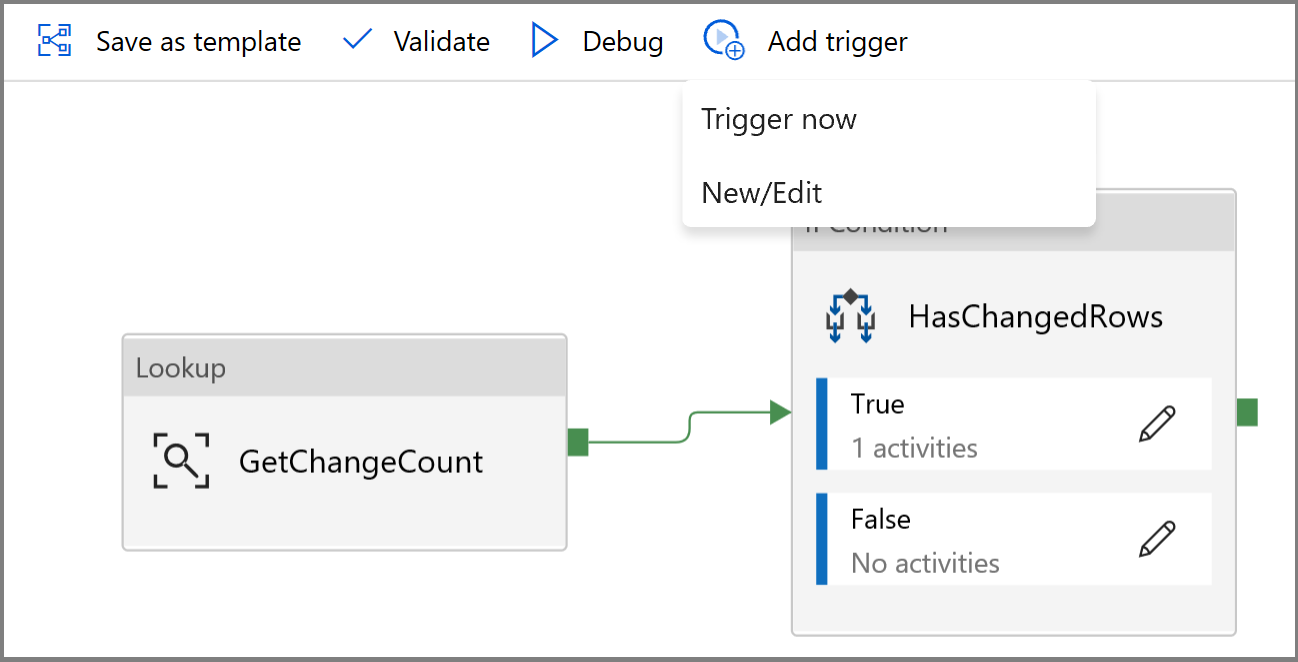
- Escriba un nombre de desencadenador y especifique una hora de inicio, que es igual a la hora de finalización de la ventana de depuración anterior.
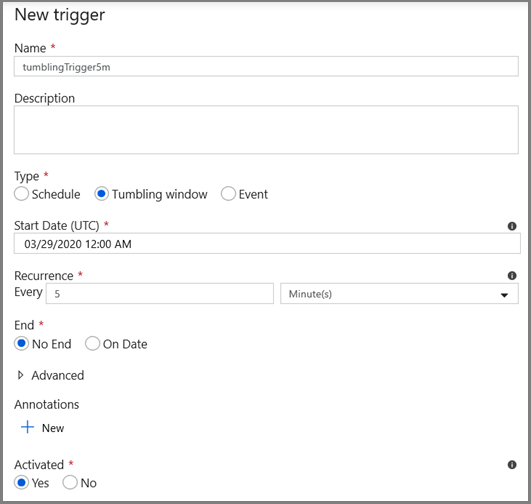
En la siguiente pantalla, especifique los siguientes valores para los parámetros de inicio y de finalización, respectivamente.
@formatDateTime(trigger().outputs.windowStartTime,'yyyy-MM-dd HH:mm:ss.fff') @formatDateTime(trigger().outputs.windowEndTime,'yyyy-MM-dd HH:mm:ss.fff')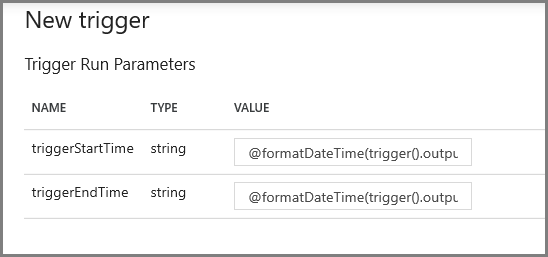
Nota
El desencadenador solo se ejecuta una vez que se ha publicado. Además, el comportamiento esperado de la ventana de saltos de tamaño constante es ejecutar todos los intervalos históricos desde la fecha de inicio hasta ahora. Puede encontrar más información sobre los desencadenadores de ventana de saltos de tamaño constante aquí.
Con SQL Server Management Studio realice cambios adicionales en la tabla customers mediante la ejecución del siguiente código SQL:
insert into customers (customer_id, first_name, last_name, email, city) values (4, 'Farlie', 'Hadigate', 'fhadigate3@zdnet.com', 'Reading'); insert into customers (customer_id, first_name, last_name, email, city) values (5, 'Anet', 'MacColm', 'amaccolm4@yellowbook.com', 'Portsmouth'); insert into customers (customer_id, first_name, last_name, email, city) values (6, 'Elonore', 'Bearham', 'ebearham5@ebay.co.uk', 'Portsmouth'); update customers set first_name='Elon' where customer_id=6; delete from customers where customer_id=5;Haga clic en el botón Publicar todo. Espere hasta ver el mensaje Publishing succeeded (Publicación correcta).
Al cabo de unos minutos, se habrá desencadenado la canalización y se habrá cargado un nuevo archivo en Azure Storage.
Supervisión de la canalización de la copia incremental
Haga clic en la pestaña Monitor (Supervisar) de la izquierda. Verá la ejecución de la canalización en la lista y su estado. Haga clic en Refresh (Actualizar) para actualizar la lista. Mantenga el puntero cerca del nombre de la canalización para acceder a la acción Rerun (Volver a ejecutar) y al informe de consumo.
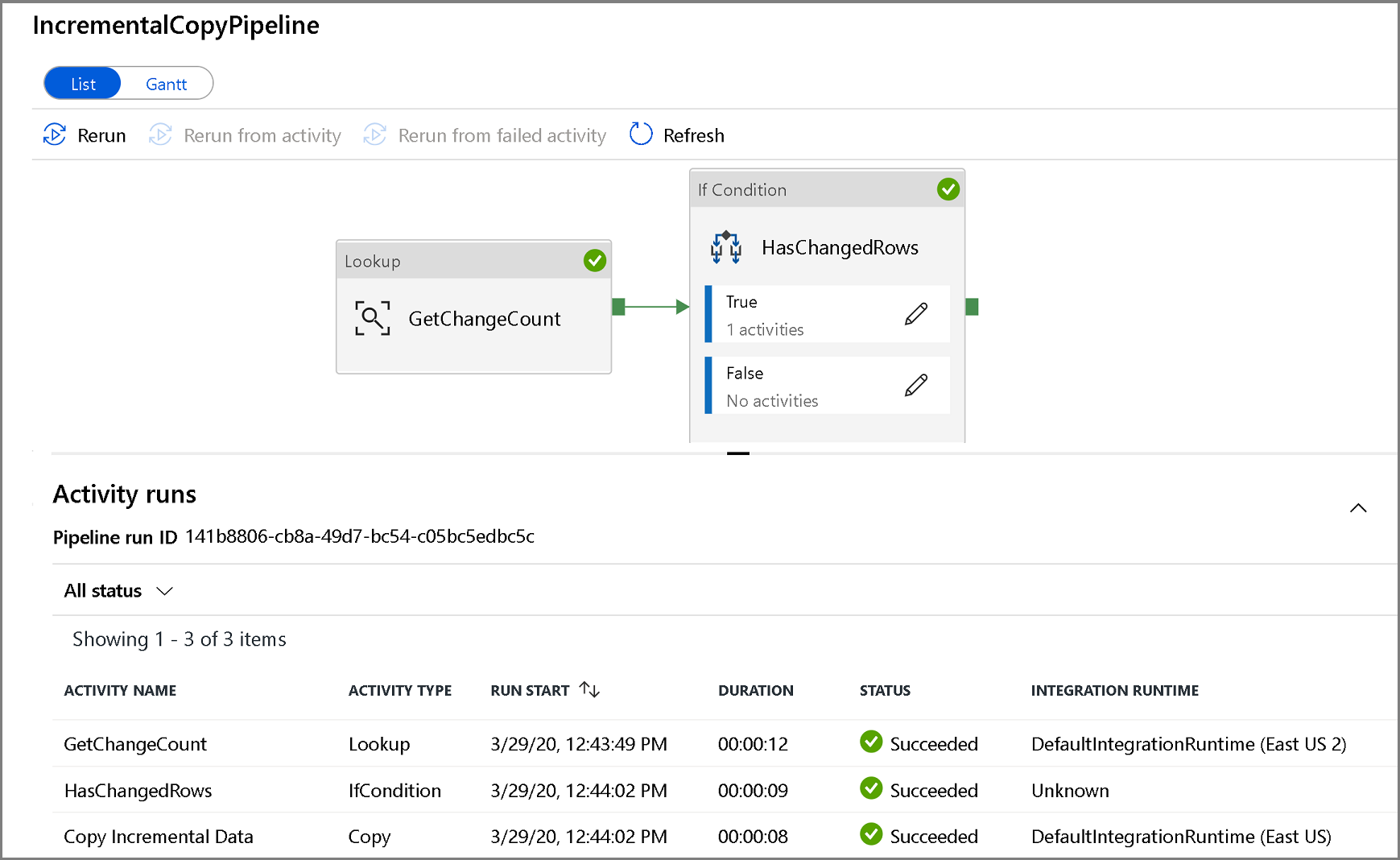
Para ver las ejecuciones de actividad asociadas a la ejecución de la canalización, haga clic en el nombre de la canalización. Si se han detectado datos modificados, habrá tres actividades, incluida la actividad de copia; de lo contrario, solo habrá dos entradas en la lista. Para volver a la vista Pipeline Runs (Ejecuciones de canalización), haga clic en el vínculo All Pipelines (Todas las canalizaciones) de la parte superior.
Revisión del resultado
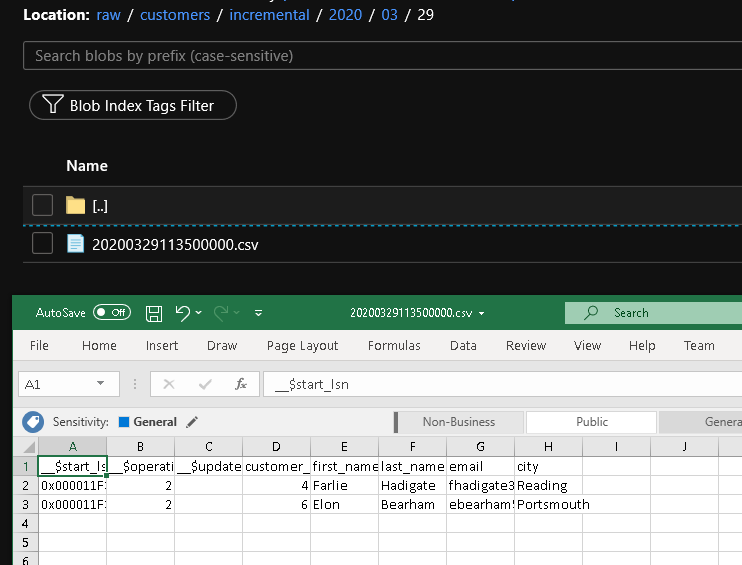
Verá el segundo archivo customers/incremental/YYYY/MM/DD en la carpeta raw del contenedor.
Contenido relacionado
Pase al tutorial siguiente para obtener información acerca de cómo copiar archivos nuevos y modificados solo según el valor de LastModifiedDate: