Copia masiva desde una base de datos con una tabla de control
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
Para copiar datos desde un almacenamiento de datos como Oracle Server, Netezza, Teradata o SQL Server en Azure Synapse Analytics, tiene que cargar enormes cantidades de datos de varias tablas. Normalmente, los datos se tienen que dividir aún más en cada tabla para poder cargar filas con varios subprocesos en paralelo desde una única tabla. En este artículo se describe una plantilla para utilizarla en estos escenarios.
Nota:
Si quiere copiar datos desde un número reducido de tablas con un volumen de datos relativamente pequeño en Azure Synapse Analytics, le resultará más eficaz usar la herramienta Copiar datos de Azure Data Factory. La plantilla que se describe en este artículo es más de lo que necesita para esa situación.
Acerca de esta plantilla de solución
Esta plantilla recupera una lista de particiones de la base de datos de origen para copiar desde una tabla de control externa. A continuación, recorre en iteración cada partición en la base de datos de origen y copia los datos en el destino.
La plantilla contiene tres actividades:
- Lookup recupera una lista de particiones de la base de datos de origen para copiar desde una tabla de control externa.
- ForEach obtiene la lista de particiones de la actividad Lookup y recorre en iteración cada partición para la actividad Copy.
- Copy copia cada partición del almacén de la base de datos de origen en el almacén de destino.
La plantilla define los parámetros siguientes:
- Control_Table_Name es la tabla de control externo, que almacena la lista de partición para la base de datos de origen.
- Control_Table_Schema_PartitionID es el nombre de columna en la tabla de control externa que almacena cada identificador de partición. Asegúrese de que el identificador de partición es único para cada partición en la base de datos de origen.
- Control_Table_Schema_SourceTableName es la tabla de control externa que almacena cada nombre de tabla desde la base de datos de origen.
- Control_Table_Schema_FilterQuery es el nombre de la columna en la tabla de control externa que almacena la consulta de filtro para obtener los datos de cada partición de la base de datos de origen. Por ejemplo, si hizo una partición de los datos por año, la consulta almacenada en cada fila podría ser similar a select * from datasource where LastModifytime >= ''2015-01-01 00:00:00'' and LastModifytime <= ''2015-12-31 23:59:59.999''.
- Data_Destination_Folder_Path es la ruta de acceso en que se copian los datos en el almacén de destino (aplicable cuando se selecciona "Sistema de archivos" o "Azure Data Lake Storage Gen1" como destino).
- Data_Destination_Container es la ruta de acceso de la carpeta raíz del lugar donde los datos se copian en el almacén de destino.
- Data_Destination_Directory es la ruta de acceso del directorio en la raíz donde los datos se copian en el almacén de destino.
Los tres últimos parámetros, que definen la ruta de acceso en el almacén de destino, solo están visibles si el destino que elige es almacenamiento basado en archivos. Si elige "Azure Synapse Analytics" como almacén de destino, estos parámetros no son necesarios. Pero los nombres de tabla y el esquema en Azure Synapse Analytics deben ser iguales que los de la base de datos de origen.
Uso de esta plantilla de solución
Cree una tabla de control en un servidor SQL Server o Azure SQL Database para almacenar la lista de particiones de la base de datos de origen para la copia masiva. En el ejemplo siguiente, hay cinco particiones en la base de datos de origen. Tres particiones son para datasource_table y dos para project_table. La columna LastModifytime se utiliza para dividir los datos de la tabla datasource_table desde la base de datos de origen. La consulta que se usa para leer la primera partición es select * from datasource_table where LastModifytime >= ''2015-01-01 00:00:00'' and LastModifytime <= ''2015-12-31 23:59:59.999''. Puede usar una consulta similar para leer datos de otras particiones.
Create table ControlTableForTemplate ( PartitionID int, SourceTableName varchar(255), FilterQuery varchar(255) ); INSERT INTO ControlTableForTemplate (PartitionID, SourceTableName, FilterQuery) VALUES (1, 'datasource_table','select * from datasource_table where LastModifytime >= ''2015-01-01 00:00:00'' and LastModifytime <= ''2015-12-31 23:59:59.999'''), (2, 'datasource_table','select * from datasource_table where LastModifytime >= ''2016-01-01 00:00:00'' and LastModifytime <= ''2016-12-31 23:59:59.999'''), (3, 'datasource_table','select * from datasource_table where LastModifytime >= ''2017-01-01 00:00:00'' and LastModifytime <= ''2017-12-31 23:59:59.999'''), (4, 'project_table','select * from project_table where ID >= 0 and ID < 1000'), (5, 'project_table','select * from project_table where ID >= 1000 and ID < 2000');Vaya a la plantilla Copia masiva desde base de datos. Crear una conexión nueva a la tabla de control externo que ha creado en el paso 1.
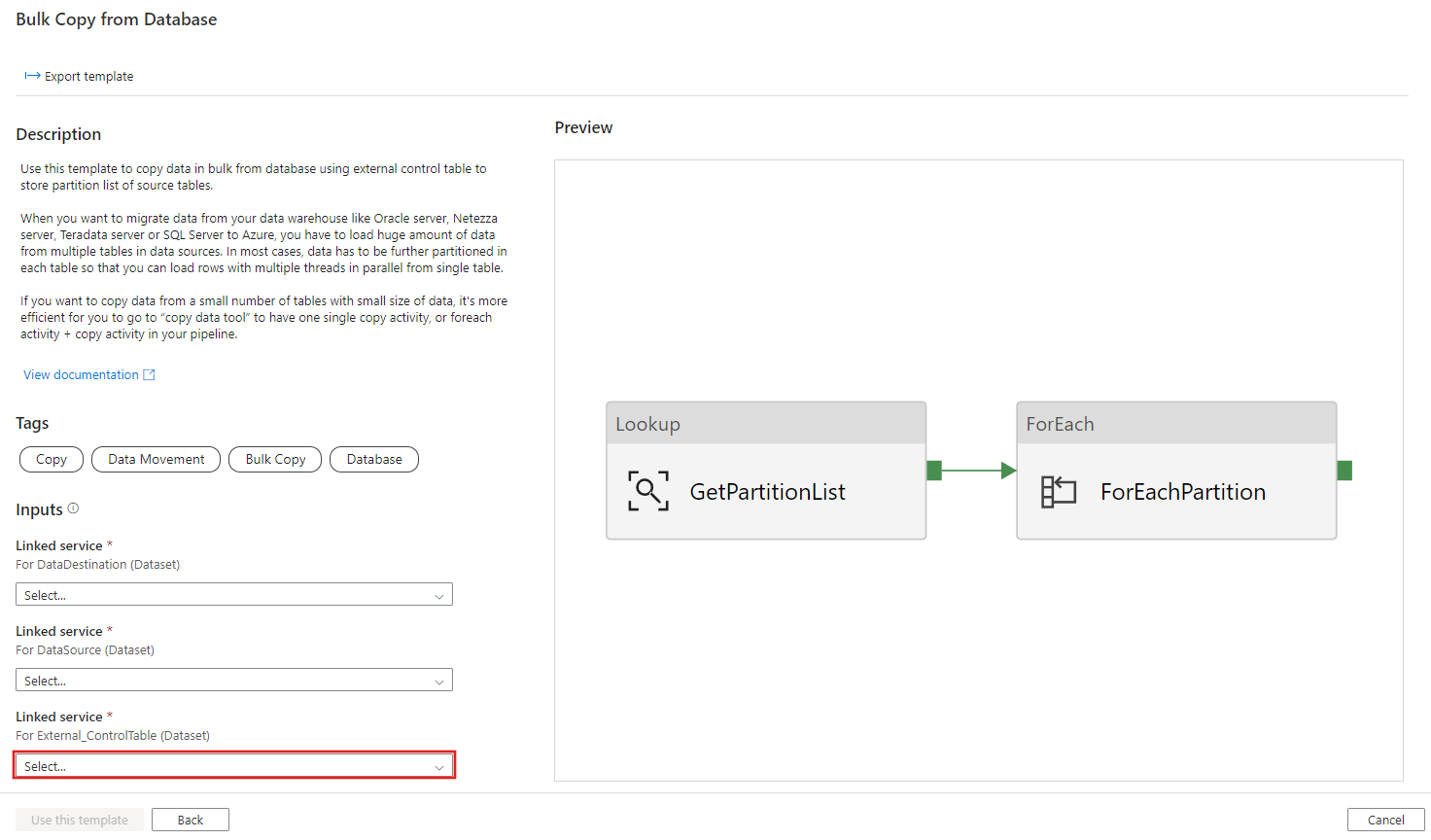
Creación de una nueva conexión a la base de datos de origen desde la que está copiando datos.
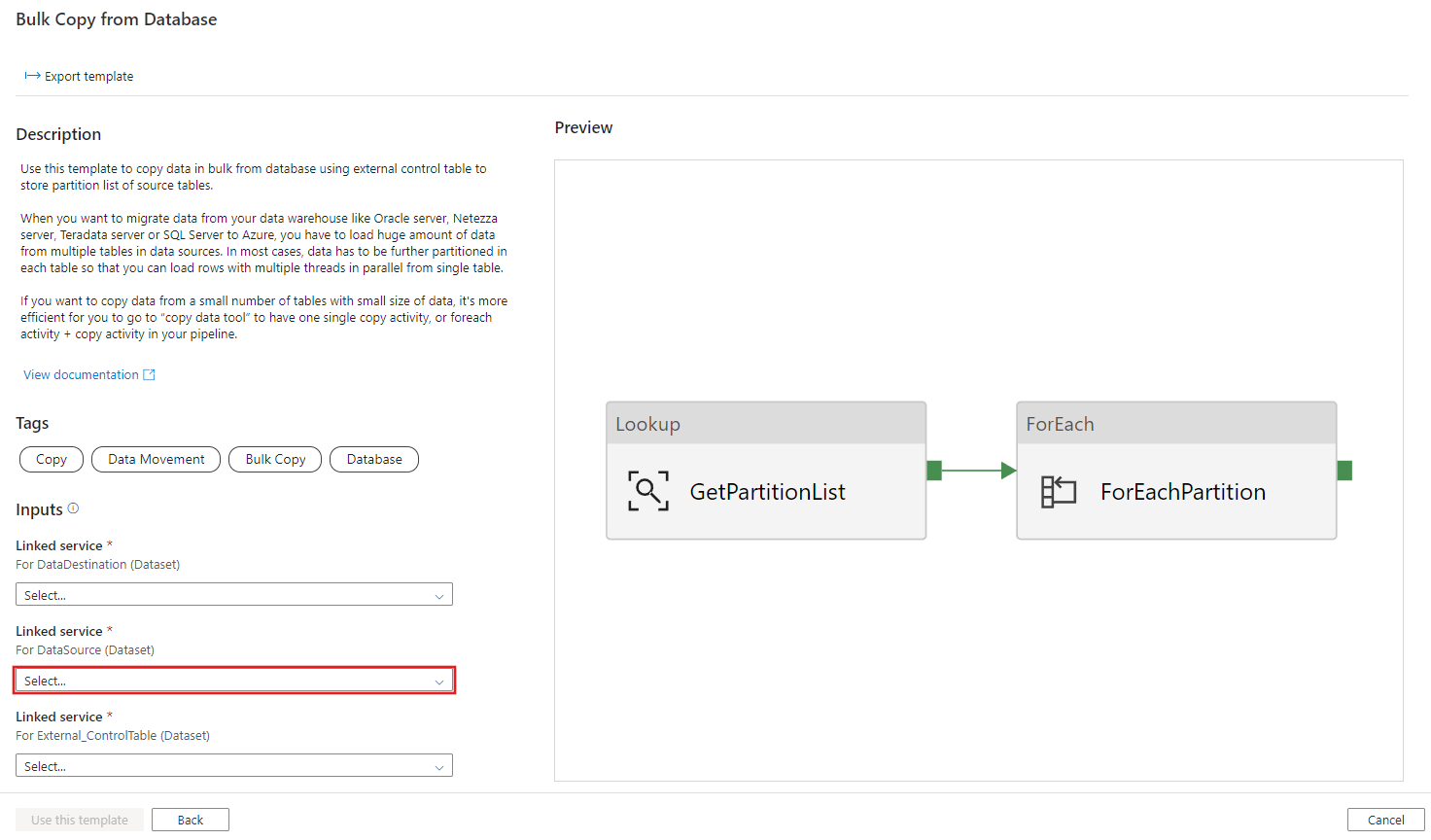
Cree una conexión nueva al almacén de datos de destino en el que está copiando datos.
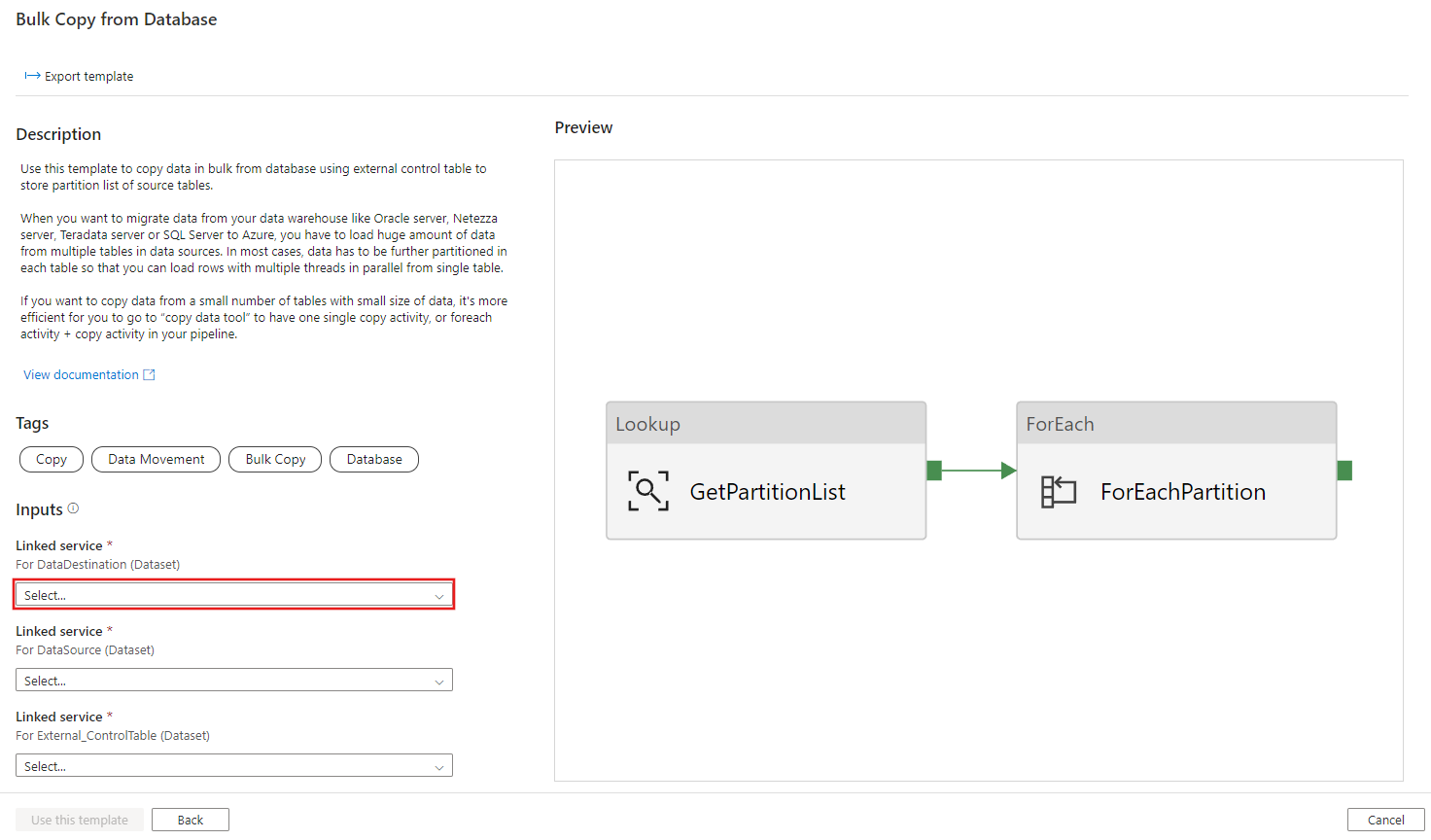
Seleccione Usar esta plantilla.
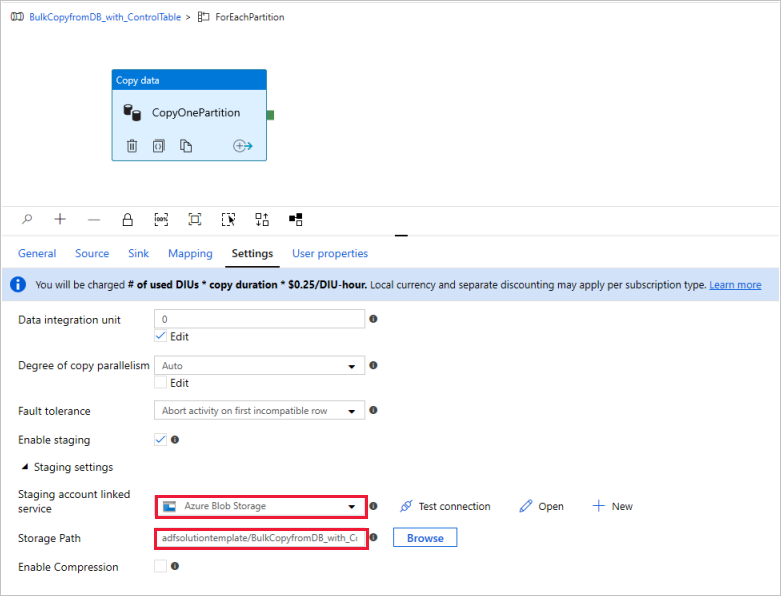
Ve la canalización, como se muestra en el ejemplo siguiente:
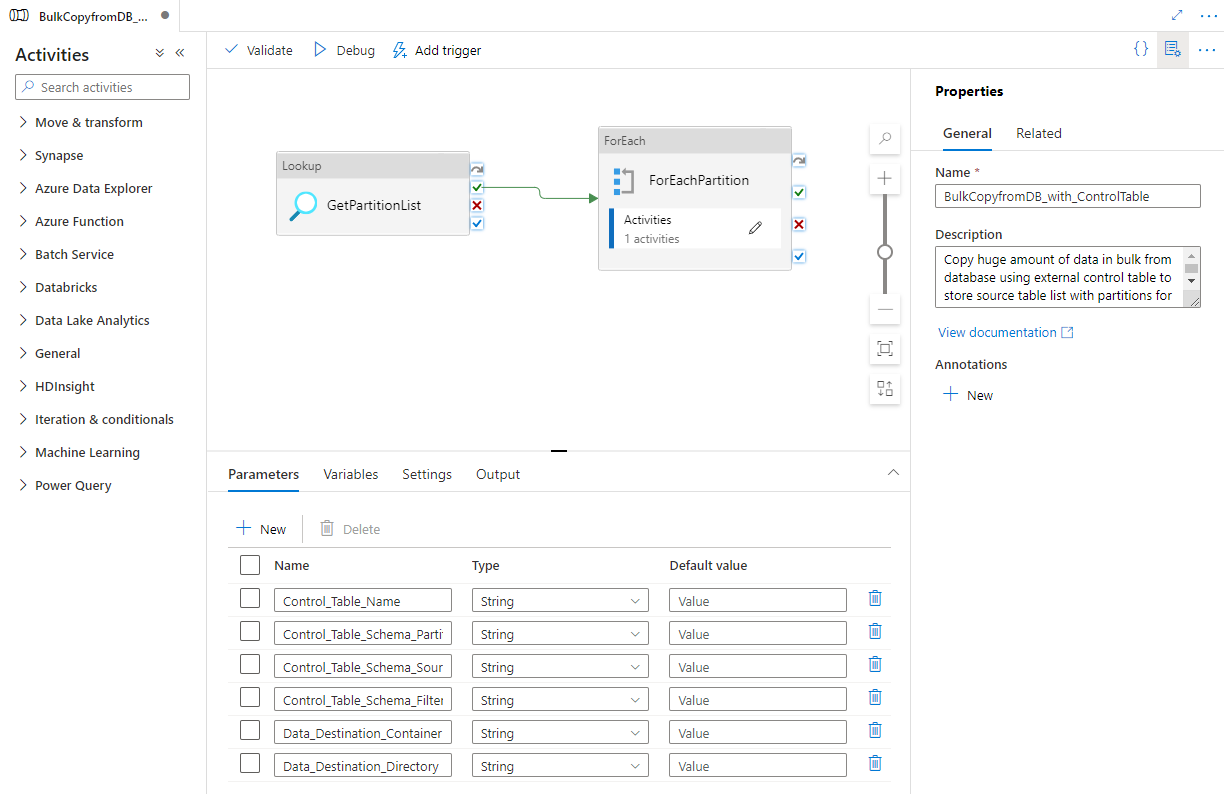
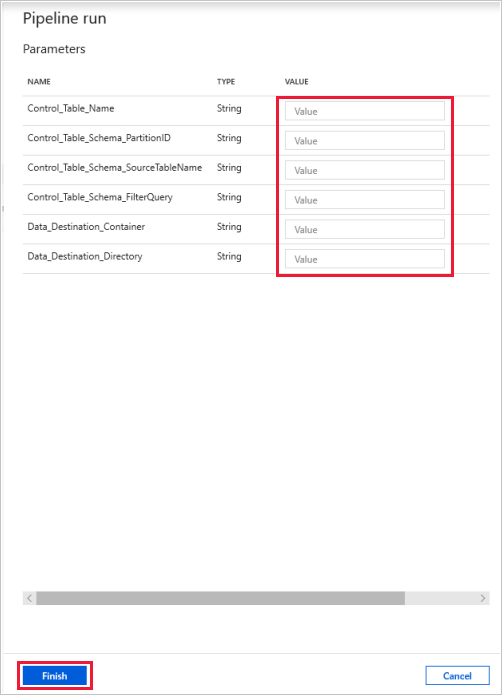
Seleccione Depurar, escriba los parámetros y, a continuación, seleccione Finalizar.
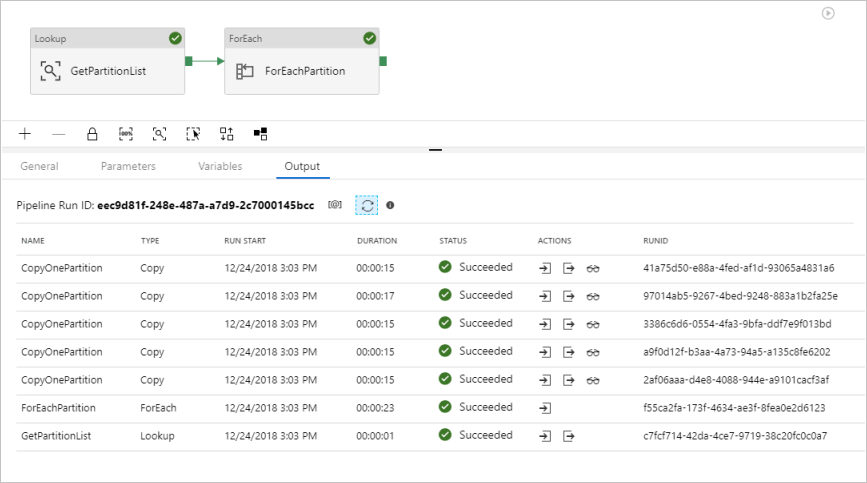
Ve resultados similares al ejemplo siguiente:
(Opcional) Si elige "Azure Synapse Analytics" como destino de datos, debe especificar una conexión a una instancia de Azure Blob Storage como almacenamiento provisional, porque así lo requiere PolyBase de Azure Synapse Analytics. La plantilla generará automáticamente una ruta de acceso de contenedor para Blob Storage. Consulte si el contenedor se ha creado después de la ejecución de la canalización.