Desduplicación de filas y búsqueda de valores NULL mediante fragmentos de código de flujo de datos
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. ¡Obtenga más información sobre cómo iniciar una nueva evaluación gratuita!
Si utiliza fragmentos de código en los flujos de datos de asignación, puede realizar de manera muy sencilla tareas comunes, como la desduplicación de datos y el filtrado de valores NULL. En este artículo se explica cómo agregar fácilmente esas funciones a las canalizaciones mediante fragmentos de scripts de flujo de datos.
Crear una canalización
Seleccione Nueva canalización.
Agregue una actividad de flujo de datos.
Seleccione la pestaña Configuración de origen, agregue una transformación de origen y conéctela a uno de los conjuntos de datos.
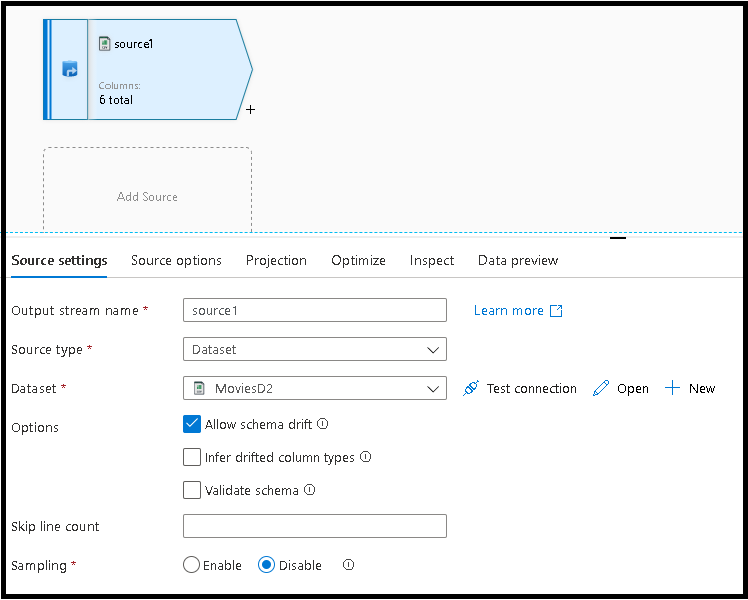
Los fragmentos de código de desduplicación y comprobación de valores NULL emplean patrones genéricos que aprovechan las ventajas del desplazamiento del esquema de flujo de datos. Los fragmentos de código funcionan con cualquier esquema del conjunto de datos o con conjuntos de datos que no tienen ningún esquema predefinido.
En la sección "Fila DISTINCT que utiliza todas las columnas" de Script de flujo de datos (DFS), copie el fragmento de código de DistinctRows.
-
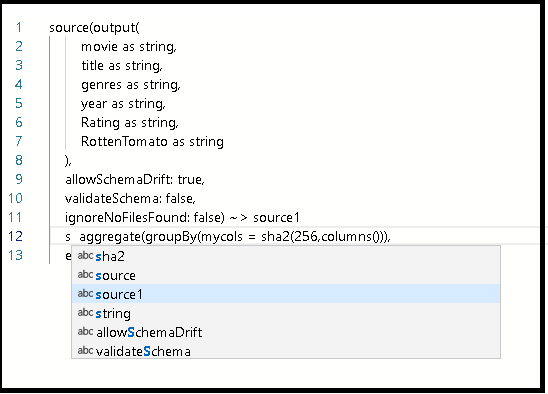
En el script, después de la definición de
source1, presione Entrar y, luego, pegue el fragmento de código.Realice cualquiera de las siguientes acciones:
Conecte este fragmento de código pegado a la transformación de origen que creó anteriormente en el gráfico escribiendo source1 delante.
También puede conectar la transformación nueva en el diseñador seleccionando la secuencia entrante del nuevo nodo de transformación en el gráfico.
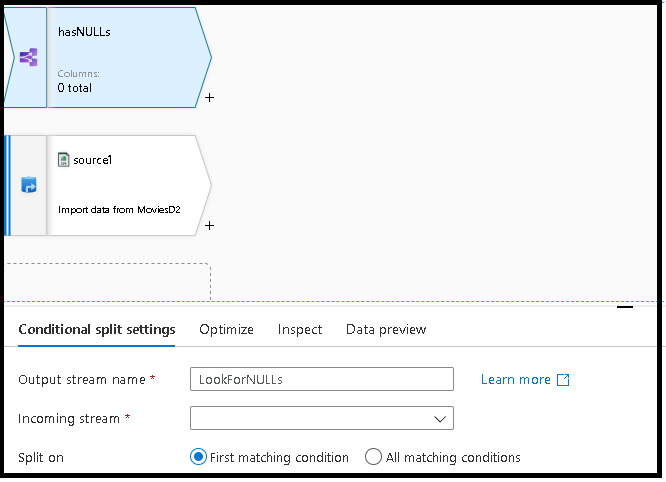
Ahora, el flujo de datos quitará las filas duplicadas del origen mediante la transformación de agregados, que agrupa todas las filas usando un hash general en todos los valores de columna.
Agregue un fragmento de código para dividir los datos en un flujo que contenga filas con valores NULL y otro flujo sin valores NULL. Para ello:
-
b. En el diseñador de flujos de datos, seleccione Script de nuevo y, luego, pegue este nuevo código de transformación en la parte inferior. Esta acción conecta el script a la transformación anterior al colocar el nombre de esa transformación delante del fragmento de código pegado.
El gráfico de flujo de datos debería tener ahora un aspecto similar al siguiente:
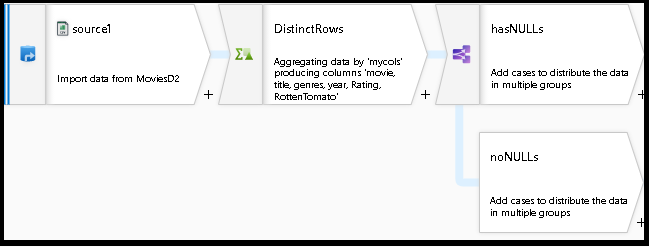
Ahora ha creado un flujo de datos funcional con desduplicación y comprobación de valores NULL genéricos, para lo cual ha tomado fragmentos de código existentes de la biblioteca de scripts de flujo de datos y los ha agregado al diseño existente.
Contenido relacionado
- Compile el resto de la lógica del flujo de datos mediante transformaciones de flujos de datos de asignación.