Transformación Combinación en el flujo de datos de asignación
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
Los flujos de datos están disponibles en las canalizaciones Azure Data Factory y Azure Synapse. Este artículo se aplica a los flujos de datos de asignación. Si carece de experiencia con las transformaciones, consulte el artículo de introducción Transformación de datos mediante flujos de datos de asignación.
Use la transformación Combinación para combinar datos de dos orígenes o flujos en un mismo flujo de datos de asignación. El flujo de salida incluirá todas las columnas de ambos orígenes que coincidan con una condición de combinación.
Tipos de combinación
La asignación de flujos de datos admite actualmente cinco tipos de combinación diferentes.
Combinación interna
La combinación interna solo genera filas que tienen valores coincidentes en ambas tablas.
Externa izquierda
La combinación externa izquierda devuelve todas las filas del flujo izquierdo y los registros coincidentes del flujo derecho. Si una fila del flujo izquierdo no tiene ninguna coincidencia, las columnas de salida del flujo derecho se establecen en NULL. La salida constará de las filas devueltas por una combinación interna más las filas sin coincidencias del flujo izquierdo.
Nota
En ocasiones, el motor de Spark que los flujos de datos usan puede no funcionar debido a posibles productos cartesianos en las condiciones de combinación. Si esto sucede, puede cambiar a una combinación cruzada personalizada y escribir manualmente la condición de combinación. Esto puede dar lugar a un rendimiento más lento en los flujos de datos, ya que es posible que el motor de ejecución tenga que calcular todas las filas de ambos lados de la relación y luego filtrarlas.
Externa derecha
La combinación externa derecha devuelve todas las filas del flujo derecho y los registros coincidentes del flujo izquierdo. Si una fila del flujo derecho no tiene ninguna coincidencia, las columnas de salida del flujo izquierdo se establecen en NULL. La salida constará de las filas devueltas por una combinación interna más las filas sin coincidencias del flujo derecho.
Externa completa
La combinación externa completa devuelve todas las columnas y filas de ambos lados con valores NULL para las columnas que no coinciden.
Combinación cruzada personalizada
La combinación cruzada genera el producto cruzado de los dos flujos en función de una condición. Si utiliza una condición que no es de igualdad, debe especificar una expresión personalizada como condición de combinación cruzada. El flujo de salida constará de todas las filas que cumplan la condición de combinación.
Puede usar este tipo de combinación para combinaciones no equivalentes y condiciones OR.
Si quiere generar explícitamente un producto cartesiano completo, utilice la transformación Columna derivada en cada uno de los dos flujos independientes antes de la combinación para crear una clave sintética en la que buscar coincidencias. Por ejemplo, cree una columna en la columna derivada de cada flujo denominada SyntheticKey y establézcala como igual a 1. A continuación, use a.SyntheticKey == b.SyntheticKey como expresión de combinación personalizada.
Nota
Asegúrese de incluir al menos una columna a cada lado de la relación izquierda y derecha de una combinación cruzada personalizada. La ejecución de combinaciones cruzadas con valores estáticos en lugar de columnas a cada lado produce exámenes completos de todo el conjunto de datos, lo que provoca que el flujo de datos se realice de manera deficiente.
Combinación aproximada
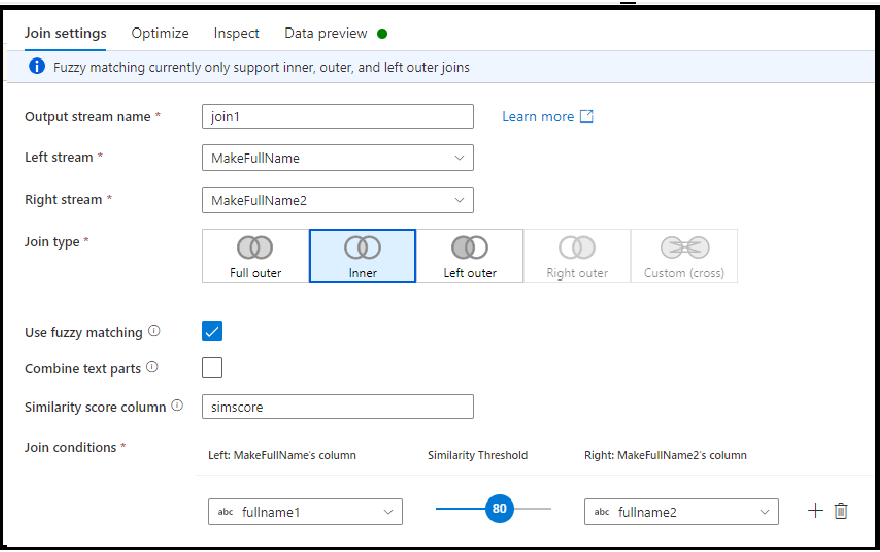
Puede optar por unirse en función de la lógica de combinación aproximada en lugar de la coincidencia exacta de valores de columna activando la opción de casilla "Usar coincidencia aproximada".
- Combinar partes de texto: use esta opción para buscar coincidencias quitando espacio entre palabras. Por ejemplo, Data Factory coincide con DataFactory si esta opción está habilitada.
- Columna de puntuación de similitud: opcionalmente, puede elegir almacenar la puntuación coincidente para cada fila de una columna escribiendo un nuevo nombre de columna aquí para almacenar ese valor.
- Umbral de similitud: elija un valor entre 60 y 100 como coincidencia porcentual entre los valores de las columnas que ha seleccionado.
Nota:
La coincidencia aproximada actualmente solo funciona con tipos de columnas de cadena y con tipos de combinación interna, externa izquierda y externa completa. Debe desactivar la optimización de difusión al usar combinaciones coincidentes aproximadas.
Configuración
- Elija el flujo de datos que va a combinar en la lista desplegable Right stream (Flujo derecho).
- Seleccione el tipo de combinación
- Elija las columnas clave con las que desea hacer coincidir su condición de combinación. De forma predeterminada, el flujo de datos busca la igualdad entre una columna de cada flujo. Para comparar a través de un valor de proceso, mantenga el mouse sobre la lista desplegable y seleccione Columna calculada.
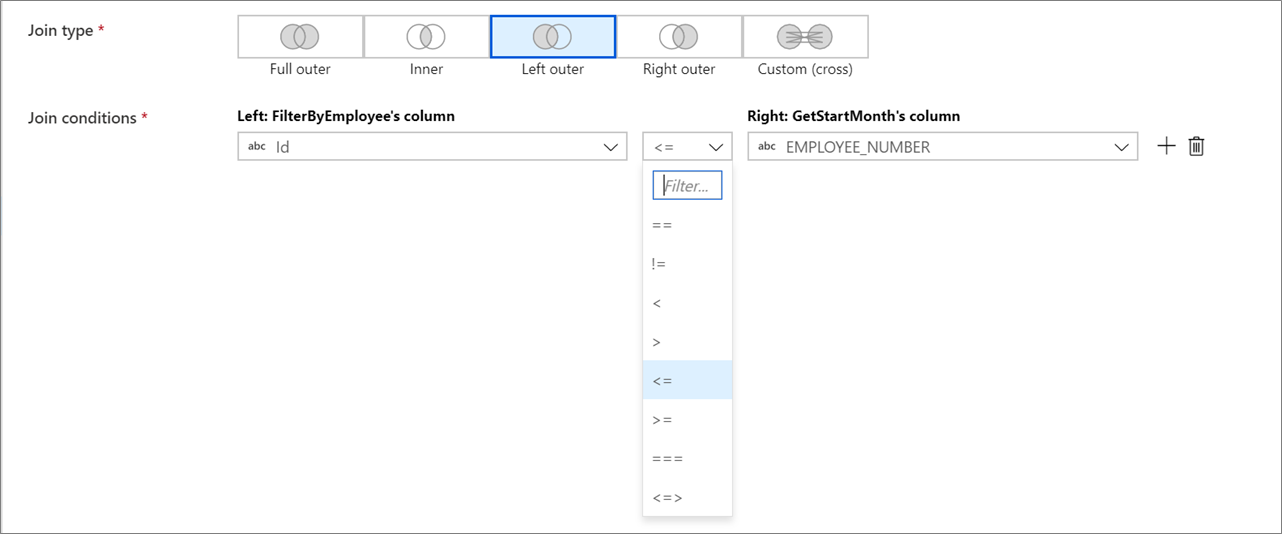
Combinaciones no equivalentes
Para usar un operador condicional, por ejemplo, no es igual a (! =) o mayor que (>) en las condiciones de combinación, cambie la lista desplegable de operadores entre las dos columnas. Las combinaciones no equivalentes requieren que al menos uno de los dos flujos se difundan mediante la retransmisión fija en la pestaña Optimizar.
Optimización del rendimiento de combinación
A diferencia de la unión de combinación en herramientas como SSIS, la transformación Combinación no es una operación de unión de combinación obligatoria. No es necesario ordenar las claves de combinación. La operación de combinación se realiza en función de la operación de combinación óptima en Spark, ya sea una combinación de difusión o del lado de la asignación.
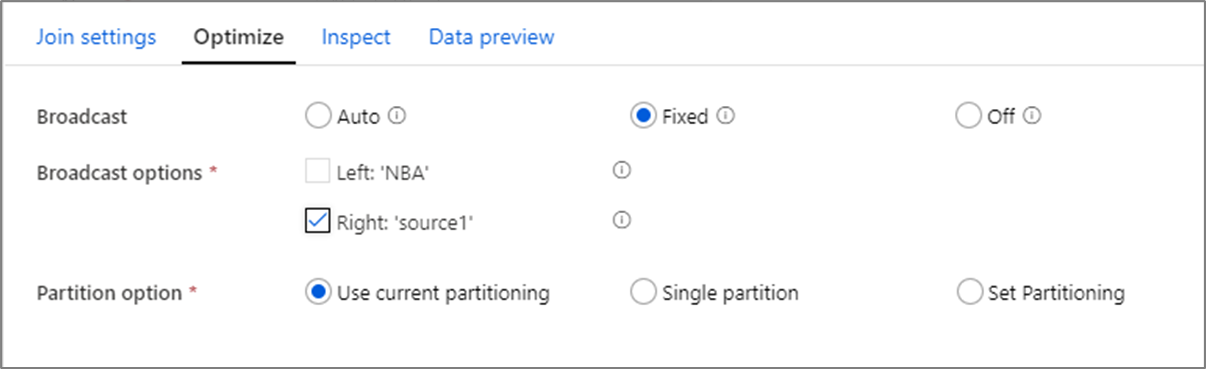
En las combinaciones, búsquedas y transformaciones Existe, si uno o ambos flujos de datos caben en la memoria del nodo de trabajo, puede optimizar el rendimiento al habilitar la opción Difusión. De forma predeterminada, el motor de Spark decidirá automáticamente si difundir o no una parte. Para elegir manualmente la parte que se va a difundir, seleccione Fijo.
No se recomienda deshabilitar la difusión a través de la opción Desactivado a menos que las combinaciones experimenten errores de tiempo de espera.
Autocombinación
Para autocombinar un flujo de datos consigo mismo, asigne un alias a un flujo existente mediante una transformación Selección. Para crear una nueva rama, haga clic en el icono de signo más junto a una transformación y seleccione Nueva rama. Agregue una transformación Selección para asignar un alias al flujo original. Agregue una transformación Combinación y elija el flujo original como Left stream (flujo izquierdo) y la transformación Selección como el Right stream (flujo derecho).
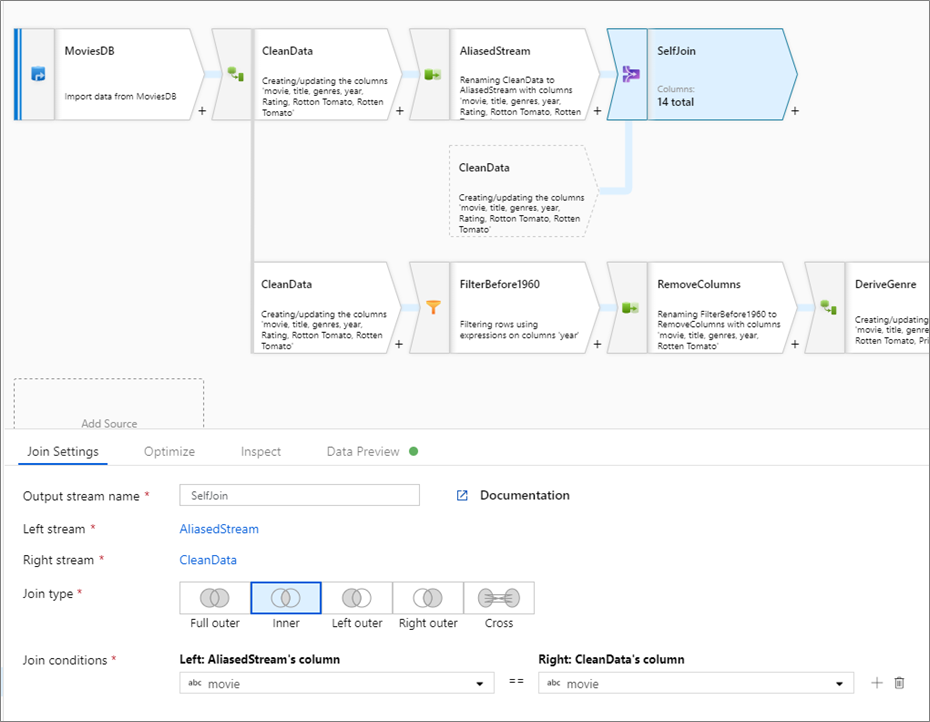
Condiciones de combinación de pruebas
Cuando pruebe las transformaciones Combinación con la vista previa de datos en modo de depuración, use un conjunto pequeño de datos conocidos. Cuando se realiza un muestreo de filas de un conjunto de filas grande, no se puede predecir qué filas y claves se leerán para las pruebas. El resultado es no determinista, lo que significa que las condiciones de combinación pueden no devolver ninguna coincidencia.
Script de flujo de datos
Sintaxis
<leftStream>, <rightStream>
join(
<conditionalExpression>,
joinType: { 'inner'> | 'outer' | 'left_outer' | 'right_outer' | 'cross' }
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <joinTransformationName>
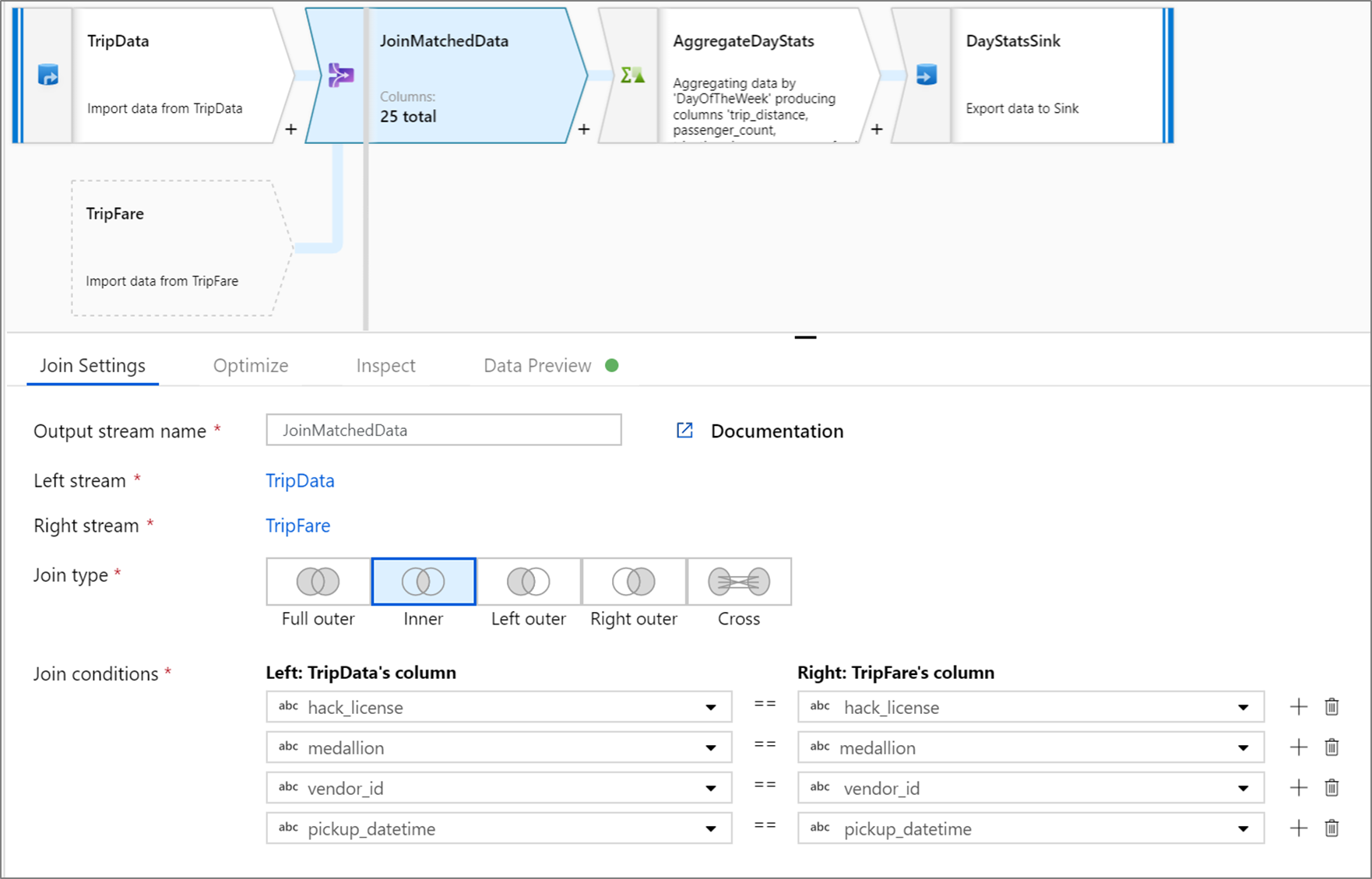
Ejemplo de combinación interna
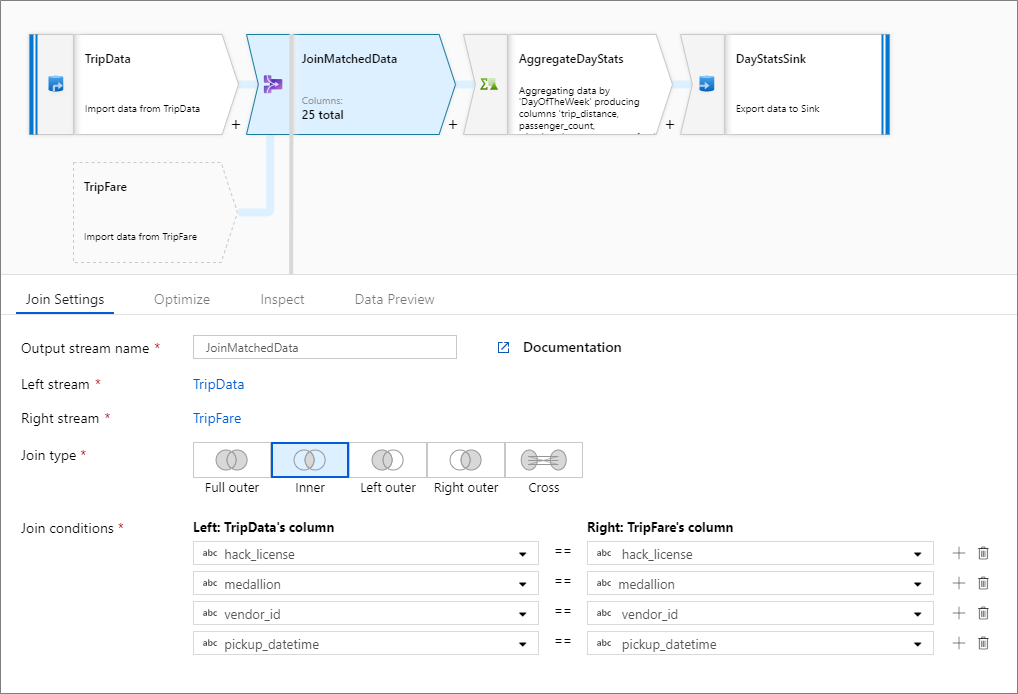
El ejemplo siguiente es una transformación Combinación denominada JoinMatchedData que toma el flujo izquierdo TripData y el flujo derecho TripFare. La condición de combinación es la expresión hack_license == { hack_license} && TripData@medallion == TripFare@medallion && vendor_id == { vendor_id} && pickup_datetime == { pickup_datetime} que devuelve true si coinciden las columnas hack_license, medallion, vendor_id y pickup_datetime de cada flujo. El valor de joinType es 'inner'. Vamos a habilitar la difusión solo en el flujo izquierdo, por lo que broadcast tiene el valor 'left'.
En la interfaz de usuario, esta transformación es similar a la siguiente imagen:
En el siguiente fragmento de código se muestra el script del flujo de datos para esta transformación:
TripData, TripFare
join(
hack_license == { hack_license}
&& TripData@medallion == TripFare@medallion
&& vendor_id == { vendor_id}
&& pickup_datetime == { pickup_datetime},
joinType:'inner',
broadcast: 'left'
)~> JoinMatchedData
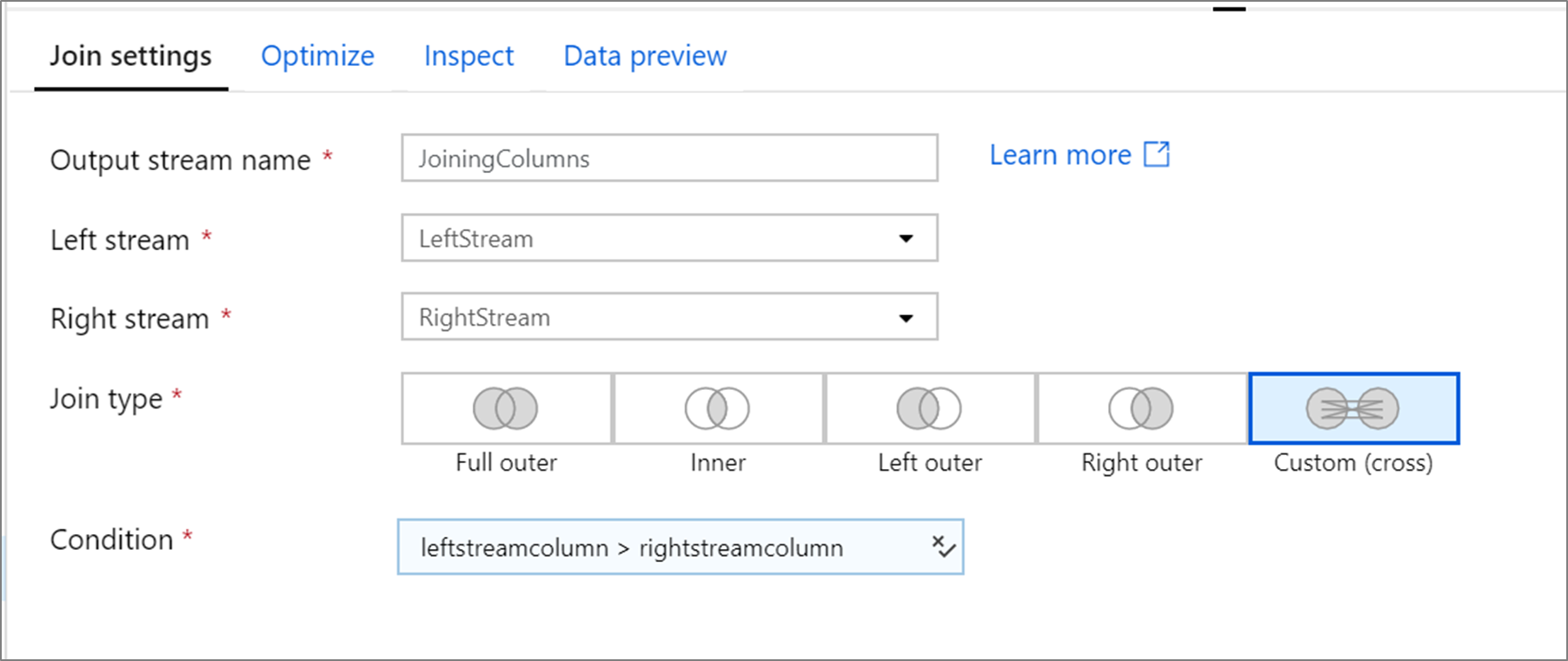
Ejemplo de combinación cruzada personalizada
El ejemplo siguiente es una transformación Combinación denominada JoiningColumns que toma el flujo izquierdo LeftStream y el flujo derecho RightStream. Esta transformación toma dos flujos y combina todas las filas en las que la columna leftstreamcolumn es mayor que la columna rightstreamcolumn. El valor de joinType es cross. La difusión no está habilitada, broadcast tiene el valor 'none'.
En la interfaz de usuario, esta transformación es similar a la siguiente imagen:
En el siguiente fragmento de código se muestra el script del flujo de datos para esta transformación:
LeftStream, RightStream
join(
leftstreamcolumn > rightstreamcolumn,
joinType:'cross',
broadcast: 'none'
)~> JoiningColumns
Contenido relacionado
Después de combinar los datos, puede crear una columna derivada y recibir sus datos en un almacén de datos de destino.