Copia y transformación de datos desde y hacia un punto de conexión de REST mediante Azure Data Factory
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. ¡Obtenga más información sobre cómo iniciar una nueva evaluación gratuita!
En este artículo se explica el uso de la actividad de copia de Azure Data Factory para copiar datos desde un punto de conexión de REST y hacia allí. El artículo se basa en Actividad de copia en Azure Data Factory, en el que se ofrece información general acerca de la actividad de copia.
Las diferencias entre este conector REST, el conector HTTP y el conector de tabla web son:
- El conector REST admite específicamente la copia de datos desde API de RESTful.
- El conector HTTP es genérico y puede recuperar datos desde cualquier punto de conexión HTTP, por ejemplo, para descargar archivos. Antes que este conector REST, puede usar el conector HTTP para copiar datos de API de RESTful, lo que se admite, pero es menos funcional en comparación con el conector REST.
- El conector de tabla web extrae contenido de la tabla de una página web HTML.
Funcionalidades admitidas
El conector REST es compatible con las siguientes funcionalidades:
| Funcionalidades admitidas | IR |
|---|---|
| Actividad de copia (origen/receptor) | ① ② |
| Flujo de datos de asignación (origen/receptor) | ① |
① Azure Integration Runtime ② Entorno de ejecución de integración autohospedado
Para obtener una lista de los almacenes de datos que se admiten como orígenes y receptores, consulte la tabla de almacenes de datos admitidos.
En concreto, este conector REST genérico admite lo siguiente:
- La copia de datos desde un punto de conexión de REST mediante los métodos GET o POST y la copia de datos hacia un punto de conexión de REST mediante los métodos POST, PUT o PATCH.
- Copia de datos mediante una de las siguientes autenticaciones: anónima, básica, entidad de servicio, credenciales de cliente OAuth2, identidad administrada asignada por el sistema e identidad administrada asignada por el usuario.
- Paginación en las API REST.
- En el caso de REST como origen, la copia de la respuesta JSON de REST tal cual o su análisis mediante la asignación de esquemas. Solo se admite la carga de respuesta en JSON.
Sugerencia
Para probar una solicitud REST para la recuperación de datos antes de configurar el conector REST en Data Factory, obtenga información sobre la especificación de API para los requisitos del cuerpo y del encabezado. Puede usar herramientas como Visual Studio, Invoke-RestMethod de PowerShell o un explorador web para validar.
Requisitos previos
Si el almacén de datos se encuentra en una red local, una red virtual de Azure o una nube privada virtual de Amazon, debe configurar un entorno de ejecución de integración autohospedado para conectarse a él.
Si el almacén de datos es un servicio de datos en la nube administrado, puede usar Azure Integration Runtime. Si el acceso está restringido a las direcciones IP que están aprobadas en las reglas de firewall, puede agregar direcciones IP de Azure Integration Runtime a la lista de permitidos.
También puede usar la característica del entorno de ejecución de integración de red virtual administrada de Azure Data Factory para acceder a la red local sin instalar ni configurar un entorno de ejecución de integración autohospedado.
Consulte Estrategias de acceso a datos para más información sobre los mecanismos de seguridad de red y las opciones que admite Data Factory.
Introducción
Para realizar la actividad de copia con una canalización, puede usar una de los siguientes herramientas o SDK:
- La herramienta Copiar datos
- Azure Portal
- El SDK de .NET
- El SDK de Python
- Azure PowerShell
- API REST
- La plantilla de Azure Resource Manager
Creación de un servicio vinculado REST mediante la interfaz de usuario
Siga estos pasos para crear un servicio vinculado REST en la interfaz de usuario de Azure Portal.
Vaya a la pestaña Administrar de su área de trabajo de Azure Data Factory o Synapse, y seleccione Servicios vinculados; a continuación, seleccione Nuevo:
Busque REST y seleccione el conector de REST.
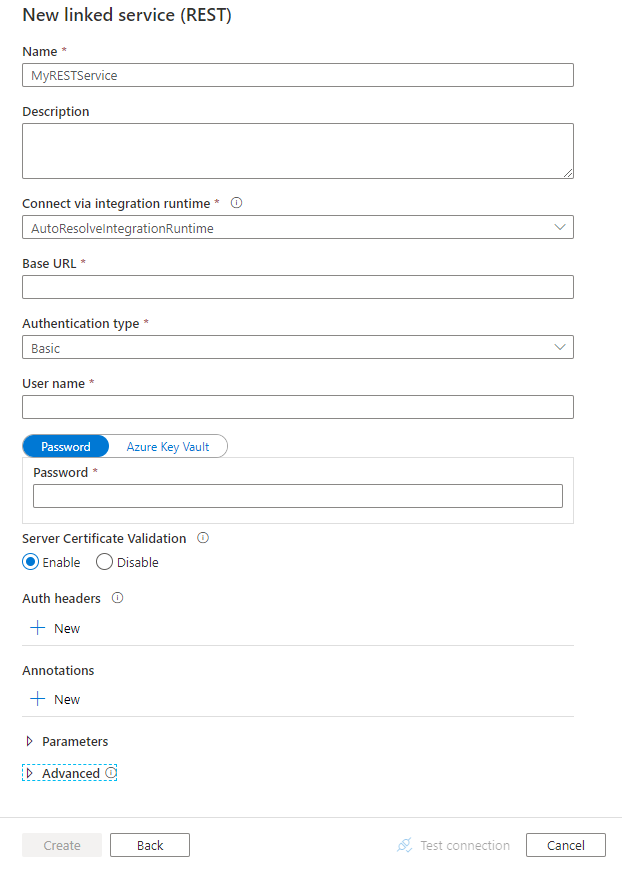
Configure los detalles del servicio, pruebe la conexión y cree el nuevo servicio vinculado.
Detalles de configuración del conector
En las secciones siguientes se proporcionan detalles sobre las propiedades que puede usar para definir entidades de Data Factory específicas del conector REST.
Propiedades del servicio vinculado
Las siguientes propiedades son compatibles con el servicio vinculado de REST:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type debe establecerse en RestService. | Sí |
| url | La dirección URL base del servicio REST. | Sí |
| enableServerCertificateValidation | Si se debe validar el certificado TLS/SSL del lado servidor al conectarse al punto de conexión. | No (El valor predeterminado es: true) |
| authenticationType | El tipo de autenticación usado para conectarse al servicio REST. Los valores permitidos son Anonymous, Basic, AadServicePrincipal, OAuth2ClientCredential y ManagedServiceIdentity. Además, puede configurar encabezados de autenticación en la propiedad authHeaders. Haga referencia a las siguientes secciones correspondientes para obtener más información sobre propiedades y ejemplos, respectivamente. |
Sí |
| authHeaders | Encabezados de solicitud HTTP adicionales para la autenticación. Por ejemplo, para usar la autenticación de clave de API, puede seleccionar el tipo de autenticación "Anónima" y especificar la clave de API en el encabezado. |
No |
| connectVia | Instancia de Integration Runtime que se usará para conectarse al almacén de datos. Obtenga más información en la sección Requisitos previos. Si no se especifica, esta propiedad se usará Azure Integration Runtime. | No |
Para conocer los distintos tipos de autenticación, consulte las secciones correspondientes para ver los detalles.
- Autenticación básica
- Autenticación de la entidad de servicio
- Autenticación de credenciales de cliente de OAuth2
- Autenticación de identidad administrada asignada por el sistema
- Autenticación de identidad administrada asignada por el usuario
- Autenticación anónima
Uso de la autenticación básica
Establezca la propiedad authenticationType en Basic. Además de las propiedades genéricas descritas en las secciones anteriores, especifique las siguientes:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| userName | El nombre de usuario para acceder al punto de conexión REST. | Sí |
| password | Contraseña del usuario (valor userName). Marque este campo como de tipo SecureString para almacenarlo de forma segura en Data Factory. También puede hacer referencia a un secreto almacenado en Azure Key Vault. | Sí |
Ejemplo
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"authenticationType": "Basic",
"url" : "<REST endpoint>",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Uso de la autenticación de entidad de servicio
Establezca la propiedad authenticationType en AadServicePrincipal. Además de las propiedades genéricas descritas en las secciones anteriores, especifique las siguientes:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| servicePrincipalId | Especifique el ID de cliente de la aplicación Microsoft Entra. | Sí |
| servicePrincipalCredentialType | Especifique el tipo de credencial que se usará para la autenticación de entidad de servicio. Los valores permitidos son ServicePrincipalKey y ServicePrincipalCert. |
No |
| Para ServicePrincipalKey | ||
| servicePrincipalKey | Especifique la clave de la aplicación Microsoft Entra. Marque este campo como SecureString para almacenarlo de forma segura en Data Factory, o bien para hacer referencia a un secreto almacenado en Azure Key Vault. | No |
| Para ServicePrincipalCert | ||
| servicePrincipalEmbeddedCert | Especifique el certificado codificado en base64 de la aplicación registrada en Microsoft Entra ID y asegúrese de que el tipo de contenido del certificado es PKCS #12. Marque este campo como SecureString para almacenarlo de forma segura, o bien haga referencia a un secreto almacenado en Azure Key Vault. Vaya a esta sección para aprender a guardar el certificado en Azure Key Vault. | No |
| servicePrincipalEmbeddedCertPassword | Especifique la contraseña del certificado si el certificado está protegido por una. Marque este campo como SecureString para almacenarlo de forma segura, o bien haga referencia a un secreto almacenado en Azure Key Vault. | No |
| tenant | Especifique la información del inquilino (nombre de dominio o identificador de inquilino) en el que reside la aplicación. Para recuperarla, mantenga el puntero del mouse en la esquina superior derecha de Azure Portal. | Sí |
| aadResourceId | Especifique el recurso de Microsoft Entra para el que solicita autorización, por ejemplo, https://management.core.windows.net. |
Sí |
| azureCloudType | Para la autenticación de la entidad de servicio, especifique el tipo de entorno de nube de Azure en el que está registrada la aplicación de Microsoft Entra. Los valores permitidos son AzurePublic, AzureChina, AzureUsGovernment y AzureGermany. De forma predeterminada, se usa el entorno de nube de la factoría de datos. |
No |
Ejemplo 1: uso de la autenticación de claves de entidad de servicio
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "AadServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ejemplo 2: uso de la autenticación de certificados de entidad de servicio
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "AadServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalCert",
"servicePrincipalEmbeddedCert": {
"type": "SecureString",
"value": "<the base64 encoded certificate of your application registered in Microsoft Entra ID>"
},
"servicePrincipalEmbeddedCertPassword": {
"type": "SecureString",
"value": "<password of your certificate>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Guardar el certificado de entidad de servicio en Azure Key Vault
Tiene dos opciones para guardar el certificado de entidad de servicio en Azure Key Vault:
Opción 1
Convierta el certificado de entidad de servicio en una cadena base64. Más información en este artículo.
Guarde la cadena base64 como un secreto en Azure Key Vault.
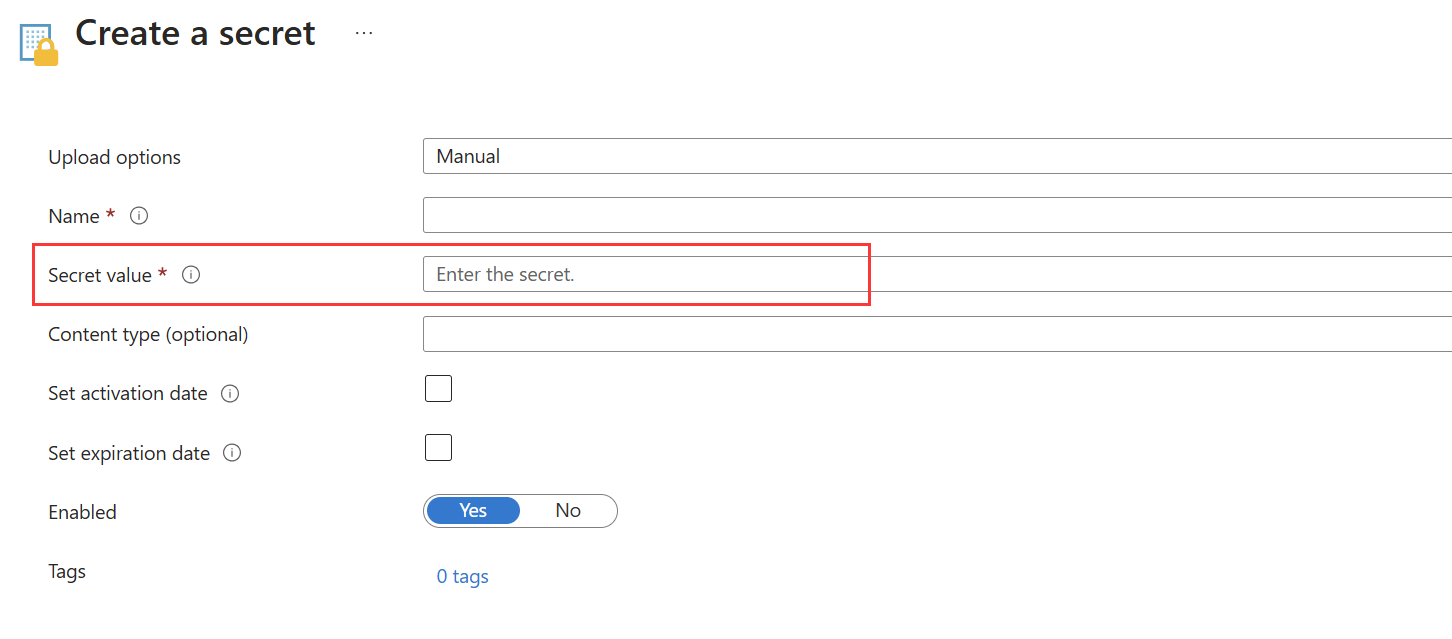
Opción 2
Si no puede descargar el certificado de Azure Key Vault, puede usar esta plantilla para guardar el certificado de entidad de servicio convertido como secreto en Azure Key Vault.

Uso de la autenticación de credenciales de cliente de OAuth2
Establezca la propiedad authenticationType en OAuth2ClientCredential. Además de las propiedades genéricas descritas en las secciones anteriores, especifique las siguientes:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| tokenEndpoint | Punto de conexión de token del servidor de autorización para adquirir el token de acceso. | Sí |
| clientId | Identificador de cliente asociado a la aplicación. | Sí |
| clientSecret | Secreto de cliente asociado a la aplicación. Marque este campo como de tipo SecureString para almacenarlo de forma segura en Data Factory. También puede hacer referencia a un secreto almacenado en Azure Key Vault. | Sí |
| scope | Ámbito del acceso necesario. Describe qué tipo de acceso se solicitará. | No |
| resource | Servicio o recurso de destino al que se solicitará el acceso. | No |
Ejemplo
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"enableServerCertificateValidation": true,
"authenticationType": "OAuth2ClientCredential",
"clientId": "<client ID>",
"clientSecret": {
"type": "SecureString",
"value": "<client secret>"
},
"tokenEndpoint": "<token endpoint>",
"scope": "<scope>",
"resource": "<resource>"
}
}
}
Uso de la autenticación de identidad administrada asignada por el sistema
Establezca la propiedad authenticationType en ManagedServiceIdentity. Además de las propiedades genéricas descritas en las secciones anteriores, especifique las siguientes:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| aadResourceId | Especifique el recurso de Microsoft Entra para el que solicita autorización, por ejemplo, https://management.core.windows.net. |
Sí |
Ejemplo
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "ManagedServiceIdentity",
"aadResourceId": "<AAD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Uso de la autenticación de identidad administrada asignada por el usuario
Establezca la propiedad authenticationType en ManagedServiceIdentity. Además de las propiedades genéricas descritas en las secciones anteriores, especifique las siguientes:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| aadResourceId | Especifique el recurso de Microsoft Entra para el que solicita autorización, por ejemplo, https://management.core.windows.net. |
Sí |
| credentials | Especifique la identidad administrada asignada por el usuario como objeto de credencial. | Sí |
Ejemplo
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "ManagedServiceIdentity",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Uso de los encabezados de autenticación
Además, puede configurar los encabezados de solicitud para realizar la autenticación, junto con los tipos de autenticación integrados.
Ejemplo: uso de la autenticación mediante clave de API
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint>",
"authenticationType": "Anonymous",
"authHeaders": {
"x-api-key": {
"type": "SecureString",
"value": "<API key>"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propiedades del conjunto de datos
En esta sección se proporciona una lista de las propiedades que admite el conjunto de datos de REST.
Para ver una lista completa de las secciones y propiedades disponibles para definir conjuntos de datos, consulte Conjuntos de datos y servicios vinculados.
Para copiar datos de REST, se admiten las siguientes propiedades:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del conjunto de datos debe establecerse en RestResource. | Sí |
| relativeUrl | Dirección URL relativa al recurso que contiene los datos. Cuando no se especifica la propiedad, solo se usa la dirección URL especificada en la definición del servicio vinculado. El conector HTTP copia los datos de la dirección URL combinada: [URL specified in linked service]/[relative URL specified in dataset]. |
No |
Si ha configurado requestMethod, additionalHeaders, requestBody y paginationRules en el conjunto de datos, todavía se admite tal cual, aunque se aconseja usar en el futuro el nuevo modelo en la actividad.
Ejemplo:
{
"name": "RESTDataset",
"properties": {
"type": "RestResource",
"typeProperties": {
"relativeUrl": "<relative url>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<REST linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propiedades de la actividad de copia
En esta sección se proporciona una lista de las propiedades compatibles con REST como origen y receptor.
Para ver una lista completa de las secciones y propiedades que hay disponibles para definir actividades, consulte Canalizaciones.
REST como origen
Se admiten las siguientes propiedades en la sección source de la actividad de copia:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del origen de la actividad de copia debe establecerse en RestSource. | Sí |
| requestMethod | Método HTTP. Los valores permitidos son GET (valor predeterminado) y POST. | No |
| additionalHeaders | Encabezados de solicitud HTTP adicionales. | No |
| requestBody | Cuerpo de la solicitud HTTP. | No |
| paginationRules | Las reglas de paginación para componer las solicitudes de página siguiente. Vea la sección Compatibilidad con la paginación para obtener más información. | No |
| httpRequestTimeout | El tiempo de espera (el valor TimeSpan) para que la solicitud HTTP obtenga una respuesta. Este valor es el tiempo de espera para obtener una respuesta, no para leer los datos de la respuesta. El valor predeterminado es 00:01:40. | No |
| requestInterval | El tiempo de espera antes de enviar la solicitud de página siguiente. El valor predeterminado es 00:00:01 | No |
Nota
El conector REST ignora cualquier encabezado "Accept" que se especifique en additionalHeaders. Como el conector REST solo admite la respuesta en JSON, generará automáticamente un encabezado de Accept: application/json.
La matriz de objetos como cuerpo de respuesta no se admite en la paginación.
Ejemplo 1: Mediante el método Get con la paginación
"activities":[
{
"name": "CopyFromREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<REST input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "RestSource",
"additionalHeaders": {
"x-user-defined": "helloworld"
},
"paginationRules": {
"AbsoluteUrl": "$.paging.next"
},
"httpRequestTimeout": "00:01:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Ejemplo 2: Uso del método POST
"activities":[
{
"name": "CopyFromREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<REST input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "RestSource",
"requestMethod": "Post",
"requestBody": "<body for POST REST request>",
"httpRequestTimeout": "00:01:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
REST como receptor
Se admiten las siguientes propiedades en la sección sink de la actividad de copia:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del receptor de la actividad de copia debe establecerse en RestSink. | Sí |
| requestMethod | Método HTTP. Los valores permitidos son POST (valor predeterminado), PUT y PATCH. | No |
| additionalHeaders | Encabezados de solicitud HTTP adicionales. | No |
| httpRequestTimeout | El tiempo de espera (el valor TimeSpan) para que la solicitud HTTP obtenga una respuesta. Este valor es el tiempo de espera para obtener una respuesta, no para escribir los datos. El valor predeterminado es 00:01:40. | No |
| requestInterval | El intervalo de tiempo entre diferentes solicitudes en milisegundos. El valor del intervalo de solicitudes debe ser un número entre [10, 60000]. | No |
| httpCompressionType | Tipo de compresión HTTP que se va a usar al enviar datos con un nivel de compresión óptimo. Los valores permitidos son ninguno y gzip. | No |
| writeBatchSize | Número de registros que se van a escribir en el receptor de REST por lote. El valor predeterminado es 10000. | No |
El conector de REST como receptor funciona con las API REST que aceptan JSON. Los datos se enviarán en JSON con el siguiente patrón. Según sea necesario, puede usar la asignación de esquemas de la actividad de copia para cambiar la forma de los datos de origen de modo que se ajusten a la carga esperada por la API REST.
[
{ <data object> },
{ <data object> },
...
]
Ejemplo:
"activities":[
{
"name": "CopyToREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<REST output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "RestSink",
"requestMethod": "POST",
"httpRequestTimeout": "00:01:40",
"requestInterval": 10,
"writeBatchSize": 10000,
"httpCompressionType": "none",
},
}
}
]
Propiedades de Asignación de instancias de Data Flow
REST se admite en flujos de datos de conjuntos de datos de integración y conjuntos de datos en línea.
Transformación de origen
| Propiedad | Descripción | Requerido |
|---|---|---|
| requestMethod | Método HTTP. Los valores permitidos son GET y POST. | Sí |
| relativeUrl | Dirección URL relativa al recurso que contiene los datos. Cuando no se especifica la propiedad, solo se usa la dirección URL especificada en la definición del servicio vinculado. El conector HTTP copia los datos de la dirección URL combinada: [URL specified in linked service]/[relative URL specified in dataset]. |
No |
| additionalHeaders | Encabezados de solicitud HTTP adicionales. | No |
| httpRequestTimeout | El tiempo de espera (el valor TimeSpan) para que la solicitud HTTP obtenga una respuesta. Este valor es el tiempo de espera para obtener una respuesta, no para escribir los datos. El valor predeterminado es 00:01:40. | No |
| requestInterval | El intervalo de tiempo entre diferentes solicitudes en milisegundos. El valor del intervalo de solicitudes debe ser un número entre [10, 60000]. | No |
| QueryParameters.request_query_parameter O QueryParameters["request_query_parameter"] | El usuario define "request_query_parameter", que hace referencia a un nombre de parámetro de consulta en la siguiente dirección URL de solicitud HTTP. | No |
Transformación de receptor
| Propiedad | Descripción | Requerido |
|---|---|---|
| additionalHeaders | Encabezados de solicitud HTTP adicionales. | No |
| httpRequestTimeout | El tiempo de espera (el valor TimeSpan) para que la solicitud HTTP obtenga una respuesta. Este valor es el tiempo de espera para obtener una respuesta, no para escribir los datos. El valor predeterminado es 00:01:40. | No |
| requestInterval | El intervalo de tiempo entre diferentes solicitudes en milisegundos. El valor del intervalo de solicitudes debe ser un número entre [10, 60000]. | No |
| httpCompressionType | Tipo de compresión HTTP que se va a usar al enviar datos con un nivel de compresión óptimo. Los valores permitidos son ninguno y gzip. | No |
| writeBatchSize | Número de registros que se van a escribir en el receptor de REST por lote. El valor predeterminado es 10000. | No |
Puede establecer los métodos delete, insert, update y upsert, así como los datos de fila relativos que se van a enviar al receptor REST para las operaciones CRUD.
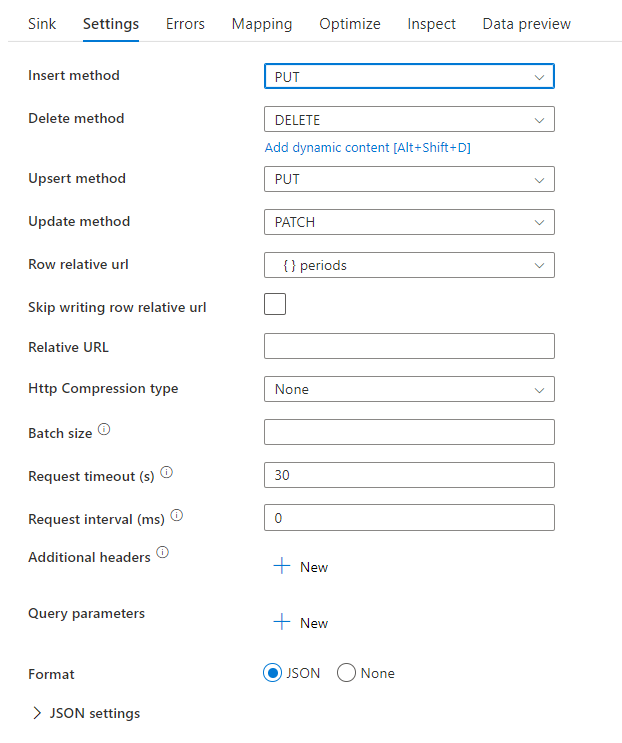
Script de flujo de datos de ejemplo
Observe el uso de una transformación alter row antes del receptor para indicar a ADF qué tipo de acción realizar con el receptor REST. Es decir, insert, update, upsert, delete.
AlterRow1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
rowRelativeUrl: 'periods',
insertHttpMethod: 'PUT',
deleteHttpMethod: 'DELETE',
upsertHttpMethod: 'PUT',
updateHttpMethod: 'PATCH',
timeout: 30,
requestFormat: ['type' -> 'json'],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
Compatibilidad con la paginación
Al copiar datos de las API de REST, por lo general, la API de REST limita su tamaño de carga de respuesta de una única solicitud a un número razonable; mientras que, para devolver una gran cantidad de datos, divide el resultado en varias páginas y exige que los autores de la llamada envíen solicitudes consecutivas para obtener la página siguiente del resultado. Por lo general, la solicitud para una página es dinámica y está compuesta por la información devuelta de la respuesta de página anterior.
Este conector REST genérico admite los siguientes patrones de paginación:
- Dirección URL absoluta o relativa de la siguiente solicitud = valor de propiedad en el cuerpo de la respuesta actual
- Dirección URL absoluta o relativa de la siguiente solicitud = valor de encabezado en los encabezados de la respuesta actual
- Parámetro de consulta de la siguiente solicitud = valor de propiedad en el cuerpo de la respuesta actual
- Parámetro de consulta de la siguiente solicitud = valor de encabezado en los encabezados de la respuesta actual
- Encabezado de la siguiente solicitud = valor de propiedad en el cuerpo de la respuesta actual
- Encabezado de la siguiente solicitud = valor de encabezado en los encabezados de la respuesta actual
Las reglas de paginación se definen como un diccionario en el conjunto de datos que contiene uno o más pares clave-valor que distinguen mayúsculas de minúsculas. La configuración se usará para generar la solicitud a partir de la segunda página. El conector detendrá la iteración cuando obtenga el código de estado HTTP 204 (sin contenido) o cualquiera de las expresiones JSONPath en "paginationRules" devuelva NULL.
Claves admitidas en las reglas de paginación:
| Clave | Descripción |
|---|---|
| AbsoluteUrl | Indica la dirección URL para emitir la siguiente solicitud. Puede ser una dirección URL absoluta o relativa. |
| QueryParameters.request_query_parameter O QueryParameters["request_query_parameter"] | El usuario define "request_query_parameter", que hace referencia a un nombre de parámetro de consulta en la siguiente dirección URL de solicitud HTTP. |
| Headers.request_header O Headers["request_header"] | El usuario define "request_header", que hace referencia a un nombre de encabezado en la siguiente solicitud HTTP. |
| EndCondition:end_condition | "end_condition" la define el usuario, e indica la condición que hará finalizar el bucle de paginación en la siguiente solicitud HTTP. |
| MaxRequestNumber | Indica el número máximo de solicitudes de paginación. Si lo deja vacío significa que no hay límite. |
| SupportRFC5988 | De forma predeterminada, se establece en true si no se define ninguna regla de paginación. Puede deshabilitar esta regla estableciendo supportRFC5988 en false o quitando esta propiedad del script. |
Valores admitidos en las reglas de paginación:
| Value | Descripción |
|---|---|
| Headers.response_header O Headers["response_header"] | El usuario define "response_header", que hace referencia a un nombre de encabezado en la respuesta HTTP actual, el valor que se usará para emitir la solicitud siguiente. |
| Una expresión JSONPath que empieza por "$" (que representa la raíz del cuerpo de respuesta) | El cuerpo de la respuesta debe contener solo un objeto JSON y la matriz del objeto, ya que no se admite el cuerpo de la respuesta. La expresión JSONPath debe devolver un único valor primitivo, que se usará para emitir la solicitud siguiente. |
Nota:
Las reglas de paginación de los flujos de datos de asignación son diferentes de las de la actividad de copia en los aspectos siguientes:
- El intervalo no se admite en los flujos de datos de asignación.
['']no se admite en los flujos de datos de asignación. En su lugar, use{}para incluir el carácter especial en el escape. Por ejemplo,body.{@odata.nextLink}, cuyo nodo JSON@odata.nextLinkcontiene el carácter especial..- La condición final se admite en los flujos de datos de asignación, pero la sintaxis de la condición es diferente de ella en la actividad de copia.
bodyse usa para indicar el cuerpo de la respuesta en lugar de$.headerse usa para indicar el encabezado de respuesta en lugar deheaders. Estos son dos ejemplos que muestran esta diferencia:- Ejemplo 1:
Actividad de copia: "EndCondition:$.data": "Empty"
Flujos de datos de asignación: "EndCondition:body.data": "Empty" - Ejemplo 2:
Actividad de copia: "EndCondition:headers.complete": "Exist"
Flujos de datos de asignación: "EndCondition:header.complete": "Exist"
- Ejemplo 1:
Ejemplos de reglas de paginación
En esta sección se proporciona una lista de ejemplos para la configuración de reglas de paginación.
Ejemplo 1: Variables en QueryParameters
En este ejemplo se proporcionan los pasos de configuración para enviar varias solicitudes cuyas variables se encuentran en QueryParameters.
Varias solicitudes:
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=0,
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=1000,
......
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=10000
Paso 1: Escriba sysparm_offset={offset} en URL base o URL relativa como se muestra en las siguientes capturas de pantalla:
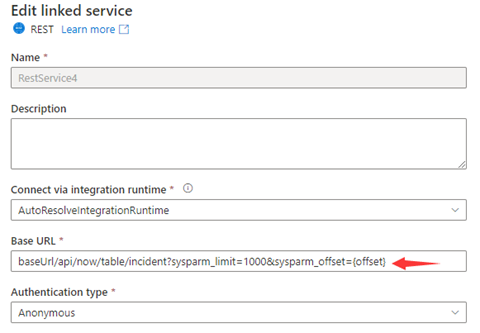
or
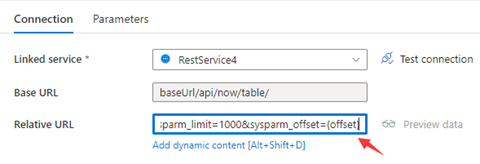
Paso 2: Establezca las reglas de paginación como opción 1 u opción 2:
Option1: "QueryParameters.{offset}" : "RANGE:0:10000:1000"
Option2: "AbsoluteUrl.{offset}" : "RANGE:0:10000:1000"
Ejemplo 2:Variables en AbsoluteUrl
En este ejemplo se proporcionan los pasos de configuración para enviar varias solicitudes cuyas variables se encuentran en AbsoluteUrl.
Varias solicitudes:
BaseUrl/api/now/table/t1
BaseUrl/api/now/table/t2
......
BaseUrl/api/now/table/t100
Paso 1: Escriba {id} en la URL base en la página de configuración del servicio vinculado o la URL relativa en el panel de conexión del conjunto de datos.

or
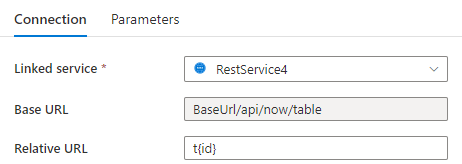
Paso 2: Establezca las reglas de paginación como "AbsoluteUrl.{id}" :"RANGE:1:100:1".
Ejemplo 3: Variables en encabezados
En este ejemplo se proporcionan los pasos de configuración para enviar varias solicitudes cuyas variables se encuentran en encabezados.
Varias solicitudes:
RequestUrl: https://example/table
Solicitud 1: Header(id->0)
Solicitud 2: Header(id->10)
......
Solicitud 100: Header(id->100)
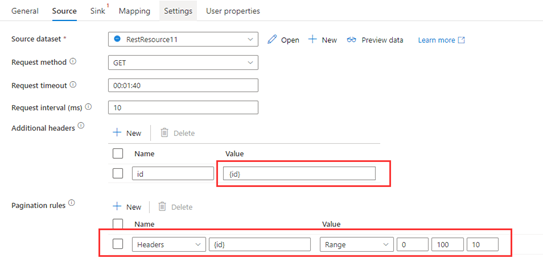
Paso 1: Escriba {id} en los encabezados adicionales.
Paso 2: Establezca las reglas de paginación como "Headers.{id}" : "RANGE:0:100:10".
Ejemplo 4: Las variables están en AbsoluteUrl/QueryParameters/Headers, la variable final no está predefinida y la condición final se basa en la respuesta.
En este ejemplo se proporcionan pasos de configuración para enviar varias solicitudes cuyas variables están en AbsoluteUrl/QueryParameters/Headers, pero la variable final no está definida. Para respuestas diferentes, se muestra una configuración de regla de condición final diferente en el ejemplo 4.1-4.6.
Varias solicitudes:
Request 1: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=0,
Request 2: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=1000,
Request 3: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=2000,
......
Dos respuestas encontradas en este ejemplo:
Respuesta 1:
{
Data: [
{key1: val1, key2: val2
},
{key1: val3, key2: val4
}
]
}
Respuesta 2:
{
Data: [
{key1: val5, key2: val6
},
{key1: val7, key2: val8
}
]
}
Paso 1: Establezca el intervalo de reglas de paginación como el Ejemplo 1 y deje el final del intervalo vacío como "AbsoluteUrl.{offset}": "RANGE:0::1000".
Paso 2: Establezca distintas reglas de condición final según las últimas respuestas diferentes. Vea los siguientes ejemplos:
Ejemplo 4.1: La paginación finaliza cuando el valor del nodo específico en respuesta está vacío.
La API REST devuelve la última respuesta en la estructura siguiente:
{ Data: [] }Establezca la regla de condición final como "EndCondition:$.data": "Empty" para finalizar la paginación cuando el valor del nodo específico en respuesta esté vacío.

Ejemplo 4.2: La paginación finaliza cuando el valor del nodo específico en respuesta no existe.
La API REST devuelve la última respuesta en la estructura siguiente:
{}Establezca la regla de condición final como "EndCondition:$.data": "NonExist" para finalizar la paginación cuando el valor del nodo específico en respuesta no exista.

Ejemplo 4.3: La paginación finaliza cuando el valor del nodo específico en respuesta existe.
La API REST devuelve la última respuesta en la estructura siguiente:
{ Data: [ {key1: val991, key2: val992 }, {key1: val993, key2: val994 } ], Complete: true }Establezca la regla de condición final como "EndCondition:$.Complete": "Exist" para finalizar la paginación cuando el valor del nodo específico en respuesta exista.

Ejemplo 4.4: La paginación finaliza cuando el valor del nodo específico en respuesta es un valor const definido por el usuario.
La API REST devuelve la respuesta en la estructura siguiente:
{ Data: [ {key1: val1, key2: val2 }, {key1: val3, key2: val4 } ], Complete: false }......
Y la última respuesta está en la estructura siguiente:
{ Data: [ {key1: val991, key2: val992 }, {key1: val993, key2: val994 } ], Complete: true }Establezca la regla de condición final como "EndCondition:$.Complete": "Const:true" para finalizar la paginación cuando el valor del nodo específico en respuesta sea un valor const definido por el usuario.

Ejemplo 4.5: La paginación finaliza cuando el valor de la clave de encabezado en respuesta es igual a un valor const definido por el usuario.
Las claves de encabezado en las respuestas de la API REST se muestran en la estructura siguiente:
Encabezado de respuesta 1:
header(Complete->0)
......
Encabezado de última respuesta:header(Complete->1)Establezca la regla de condición final como "EndCondition:headers.Complete": "Const:1" para finalizar la paginación cuando el valor de la clave de encabezado en respuesta sea igual al valor const definido por el usuario.

Ejemplo 4.6: La paginación finaliza cuando la clave existe en el encabezado de respuesta.
Las claves de encabezado en las respuestas de la API REST se muestran en la estructura siguiente:
Encabezado de respuesta 1:
header()
......
Encabezado de última respuesta:header(CompleteTime->20220920)Establezca la regla de condición final como "EndCondition:headers.CompleteTime": "Exist" para finalizar la paginación cuando la clave exista en el encabezado de respuesta.

Ejemplo 5: Establezca la condición de finalización para evitar solicitudes infinitas cuando no se define la regla de intervalo.
En este ejemplo se proporcionan los pasos de configuración para enviar varias solicitudes cuando no se use la regla de intervalo. La condición final se puede establecer según el ejemplo 4.1-4.6 para evitar solicitudes infinitas. La API REST devuelve la respuesta en la siguiente estructura, en cuyo caso la dirección URL de la siguiente página se representa en paging.next.
{
"data": [
{
"created_time": "2017-12-12T14:12:20+0000",
"name": "album1",
"id": "1809938745705498_1809939942372045"
},
{
"created_time": "2017-12-12T14:14:03+0000",
"name": "album2",
"id": "1809938745705498_1809941802371859"
},
{
"created_time": "2017-12-12T14:14:11+0000",
"name": "album3",
"id": "1809938745705498_1809941879038518"
}
],
"paging": {
"cursors": {
"after": "MTAxNTExOTQ1MjAwNzI5NDE=",
"before": "NDMyNzQyODI3OTQw"
},
"previous": "https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw",
"next": "https://graph.facebook.com/me/albums?limit=25&after=MTAxNTExOTQ1MjAwNzI5NDE="
}
}
...
La última respuesta es:
{
"data": [],
"paging": {
"cursors": {
"after": "MTAxNTExOTQ1MjAwNzI5NDE=",
"before": "NDMyNzQyODI3OTQw"
},
"previous": "https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw",
"next": "Same with Last Request URL"
}
}
Paso 1: Establezca las reglas de paginación como "AbsoluteUrl": "$.paging.next".
Paso 2: Si next en la última respuesta es siempre igual a la última dirección URL de solicitud y no está vacía, se enviarán infinitas solicitudes. La condición final se puede usar para evitar solicitudes infinitas. Por lo tanto, para establecer la regla de condición final, consulte el ejemplo 4.1-4.6.
Ejemplo 6: Establezca el número máximo de solicitudes para evitar solicitudes infinitas.
Establezca MaxRequestNumber para evitar solicitudes infinitas, como se muestra en la captura de pantalla siguiente:

Ejemplo 7: La regla de paginación RFC 5988 es compatible de forma predeterminada.
El back-end obtendrá automáticamente la siguiente dirección URL en función de los vínculos de estilo RFC 5988 del encabezado.

Sugerencia
Si no desea habilitar esta regla de paginación predeterminada, puede establecer supportRFC5988 en false o simplemente eliminarla en el script.
Ejemplo 8a: La siguiente dirección URL de solicitud del cuerpo de la respuesta cuando se utiliza la paginación en los flujos de datos de asignación
En este ejemplo se indica cómo establecer la regla de paginación y la regla de condición final en los flujos de datos de asignación cuando la siguiente dirección URL de solicitud es del cuerpo de la respuesta.
A continuación se muestra el esquema de respuesta:
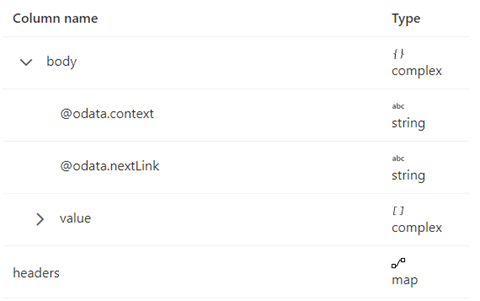
Las reglas de paginación deben establecerse como la captura de pantalla siguiente:

De forma predeterminada, la paginación se detendrá cuando body.{@odata.nextLink}** sea nulo o esté vacío.
Pero si el valor de @odata.nextLink en el cuerpo de la última respuesta es igual a la última dirección URL de solicitud, se producirá un bucle infinito. Para evitar esta condición, defina reglas de condición final.
Si Valor en la última respuesta es Vacío, la regla de condición final puede establecerse como se indica a continuación:

Si el valor de la clave completa en el encabezado de respuesta es igual a true e indica el final de la paginación, la regla de la condición de finalización se puede establecer como se indica a continuación:
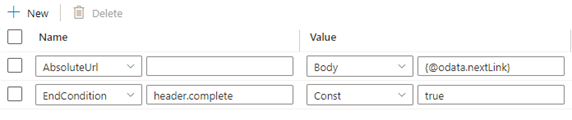
Ejemplo 8b: La siguiente dirección URL de solicitud del cuerpo de la respuesta cuando se utiliza la paginación en la actividad de copia
En este ejemplo se muestra cómo establecer la regla de paginación en una actividad de copia cuando la siguiente dirección URL de solicitud se encuentra dentro del cuerpo de la respuesta.
A continuación se muestra el esquema de respuesta:
Las reglas de paginación deben establecerse tal y como se muestra en la captura de pantalla siguiente:

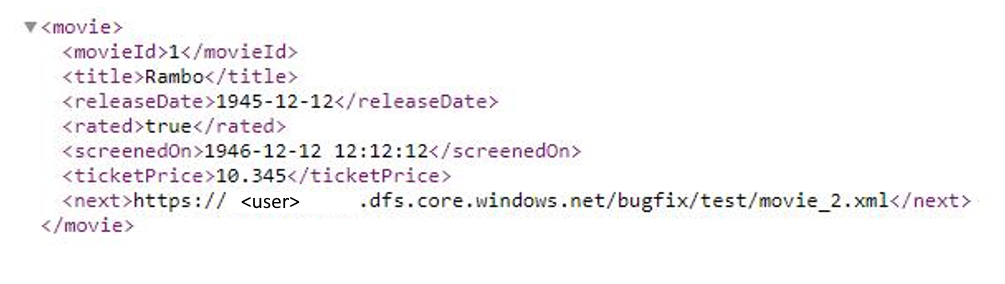
Ejemplo 9: El formato de la respuesta es XML y la siguiente dirección URL de solicitud es del cuerpo de la respuesta cuando se utiliza la paginación en los flujos de datos de asignación.
En este ejemplo se indica cómo establecer la regla de paginación en los flujos de datos de asignación cuando el formato de respuesta es XML y la siguiente dirección URL de solicitud es del cuerpo de la respuesta. Como se muestra en la captura de pantalla siguiente, la primera dirección URL es https://<user>.dfs.core.windows.NET/bugfix/test/movie_1.xml
A continuación se muestra el esquema de respuesta:
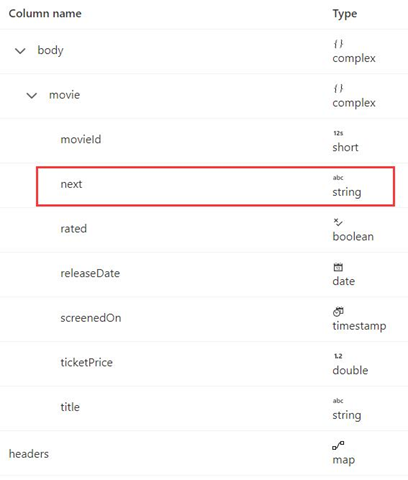
La sintaxis de la regla de paginación es la misma que en el ejemplo 8 y debe establecerse como se indica a continuación en este ejemplo:

Exportación de la respuesta JSON tal cual
Puede usar este conector REST para exportar la respuesta de JSON de la API REST tal cual a varios almacenes basados en archivos. Para lograr esa copia independiente del esquema, omita la sección “structure” (estructura, también denominada schema) en el conjunto de datos y la asignación de esquemas en la actividad de copia.
Asignación de esquemas
Para copiar datos desde el punto de conexión de REST en un receptor tabular, vea asignación de esquemas.
Contenido relacionado
Para ver una lista de los almacenes de datos que la actividad de copia admite como orígenes y receptores en Azure Data Factory, consulte los Almacenes de datos y formatos que se admiten.