Copia de datos de Cassandra con Azure Data Factory o Synapse Analytics
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. ¡Obtenga más información sobre cómo iniciar una nueva evaluación gratuita!
En este artículo se describe el uso de la actividad de copia en una canalización de Azure Data Factory o Synapse Analytics para copiar datos de Cassandra. El documento se basa en el artículo de introducción a la actividad de copia que describe información general de la actividad de copia.
Funcionalidades admitidas
Este conector Cassandra es compatible con las siguientes capacidades:
| Funcionalidades admitidas | IR |
|---|---|
| Actividad de copia (origen/-) | ① ② |
| Actividad de búsqueda | ① ② |
① Azure Integration Runtime ② Entorno de ejecución de integración autohospedado
Para obtener una lista de los almacenes de datos que se admiten como orígenes y receptores, consulte la tabla de almacenes de datos admitidos.
En concreto, este conector Cassandra admite lo siguiente:
- Las versiones 2.X y 3.x de Cassandra.
- Copiar datos mediante la autenticación Básica o Anónima.
Nota
Para la actividad que se ejecuta en Integration Runtime (autohospedado), Cassandra 3.x es compatible a partir de IR 3.7 y versiones posteriores.
Prerrequisitos
Si el almacén de datos se encuentra en una red local, una red virtual de Azure o una nube privada virtual de Amazon, debe configurar un entorno de ejecución de integración autohospedado para conectarse a él.
Si el almacén de datos es un servicio de datos en la nube administrado, puede usar Azure Integration Runtime. Si el acceso está restringido a las direcciones IP que están aprobadas en las reglas de firewall, puede agregar direcciones IP de Azure Integration Runtime a la lista de permitidos.
También puede usar la característica del entorno de ejecución de integración de red virtual administrada de Azure Data Factory para acceder a la red local sin instalar ni configurar un entorno de ejecución de integración autohospedado.
Consulte Estrategias de acceso a datos para más información sobre los mecanismos de seguridad de red y las opciones que admite Data Factory.
El entorno Integration Runtime proporciona un controlador de Cassandra integrado, por lo tanto, no es necesario instalar manualmente los controladores cuando se copian datos desde Cassandra.
Introducción
Para realizar la actividad de copia con una canalización, puede usar una de los siguientes herramientas o SDK:
- La herramienta Copiar datos
- Azure Portal
- El SDK de .NET
- El SDK de Python
- Azure PowerShell
- API REST
- La plantilla de Azure Resource Manager
Creación de un servicio vinculado a Cassandra mediante la interfaz de usuario
Siga estos pasos para crear un servicio vinculado a Cassandra en la interfaz de usuario de Azure Portal.
Vaya a la pestaña Administrar del área de trabajo de Azure Data Factory o Synapse y seleccione Servicios vinculados; luego haga clic en Nuevo:
Busque Cassandra y seleccione el conector de Cassandra.
Configure los detalles del servicio, pruebe la conexión y cree el nuevo servicio vinculado.
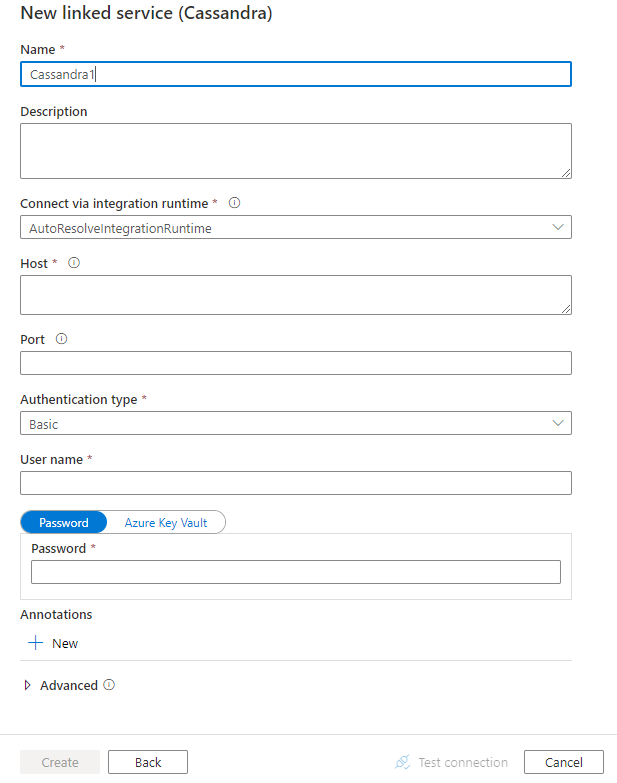
Detalles de configuración del conector
Las secciones siguientes proporcionan detalles sobre las propiedades que se usan para definir entidades de Data Factory específicas del conector Cassandra.
Propiedades del servicio vinculado
Las siguientes propiedades son compatibles con el servicio vinculado de Cassandra:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type debe establecerse en: Cassandra | Sí |
| host | Una o varias direcciones IP o nombres de host de los servidores de Cassandra. Especifica una lista de direcciones IP o nombres de host separada por comas para conectar con todos los servidores a la vez. |
Sí |
| port | Puerto TCP que el servidor de Cassandra utiliza para escuchar las conexiones del cliente. | No (el valor predeterminado es 9042). |
| authenticationType | El tipo de autenticación que se utiliza para conectarse a la base de datos Cassandra. Los valores permitidos son: Basic (básica) y Anonymous (anónima). |
Sí |
| username | Especifique el nombre de usuario de la cuenta de usuario. | Sí, si el valor de authenticationType es Basic. |
| password | Especifique la contraseña para la cuenta de usuario. Marque este campo como SecureString para almacenarlo de forma segura, o bien haga referencia a un secreto almacenado en Azure Key Vault. | Sí, si el valor de authenticationType es Basic. |
| connectVia | El entorno Integration Runtime que se usará para conectarse al almacén de datos. Obtenga más información en la sección Requisitos previos. Si no se especifica, se usará Azure Integration Runtime. | No |
Nota
Actualmente no se admite la conexión a Cassandra mediante TLS.
Ejemplo:
{
"name": "CassandraLinkedService",
"properties": {
"type": "Cassandra",
"typeProperties": {
"host": "<host>",
"authenticationType": "Basic",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propiedades del conjunto de datos
Si desea ver una lista completa de las secciones y propiedades disponibles para definir conjuntos de datos, consulte el artículo sobre conjuntos de datos. En esta sección se proporciona una lista de las propiedades que admite el conjunto de datos de Cassandra.
Para copiar datos desde Cassandra, establezca la propiedad type del conjunto de datos en CassandraTable. Se admiten las siguientes propiedades:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del conjunto de datos debe establecerse en: CassandraTable | Sí |
| keyspace | Nombre del espacio de claves o esquema de la base de datos de Cassandra. | Sí (si no hay especificada ninguna "consulta" para "CassandraSource") |
| tableName | Nombre de la tabla de la base de datos de Cassandra. | Sí (si no hay especificada ninguna "consulta" para "CassandraSource") |
Ejemplo:
{
"name": "CassandraDataset",
"properties": {
"type": "CassandraTable",
"typeProperties": {
"keySpace": "<keyspace name>",
"tableName": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Cassandra linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propiedades de la actividad de copia
Si desea ver una lista completa de las secciones y propiedades disponibles para definir actividades, consulte el artículo sobre canalizaciones. En esta sección se proporciona una lista de las propiedades que admite el origen Cassandra.
Cassandra como origen
Para copiar datos desde Cassandra, establezca el tipo de origen de la actividad de copia en CassandraSource. Se admiten las siguientes propiedades en la sección source de la actividad de copia:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del origen de la actividad de copia debe establecerse en: CassandraSource | Sí |
| Query | Utilice la consulta personalizada para leer los datos. Consulta SQL-92 o consulta CQL. Vea la CQL reference(referencia de CQL). Cuando utilice una consulta SQL, especifique nombre de espacio de claves.nombre de tabla para representar la tabla que quiere consultar. |
No (si "tableName" y "keyspace" en el conjunto de datos están especificados) |
| consistencyLevel | El nivel de coherencia establece el número de réplicas que deben responder a una solicitud de lectura antes de que se devuelvan datos a la aplicación cliente. Cassandra comprueba el número de réplicas especificado para que los datos satisfagan la solicitud de lectura. Para más información, consulte Configuring data consistency (Configuración de la coherencia de datos). Los valores permitidos son: ONE, TWO, THREE, QUORUM, ALL, LOCAL_QUORUM, EACH_QUORUM y LOCAL_ONE. |
No (el valor predeterminado es ONE) |
Ejemplo:
"activities":[
{
"name": "CopyFromCassandra",
"type": "Copy",
"inputs": [
{
"referenceName": "<Cassandra input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "CassandraSource",
"query": "select id, firstname, lastname from mykeyspace.mytable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Asignación de tipos de Cassandra
Al copiar datos de Cassandra, se utilizan las siguientes asignaciones de tipos de datos de Cassandra en los tipos de datos provisionales usados internamente dentro del servicio. Consulte el artículo sobre asignaciones de tipos de datos y esquema para información sobre cómo la actividad de copia asigna el tipo de datos y el esquema de origen al receptor.
| Tipo de datos de Cassandra | Tipo de datos de servicio provisional |
|---|---|
| ASCII | String |
| bigint | Int64 |
| BLOB | Byte[] |
| BOOLEAN | Boolean |
| DECIMAL | Decimal |
| DOUBLE | Double |
| FLOAT | Single |
| INET | String |
| INT | Int32 |
| TEXT | String |
| TIMESTAMP | DateTime |
| TIMEUUID | Guid |
| UUID | Guid |
| VARCHAR | String |
| VARINT | Decimal |
Nota
Par más información sobre tipos de colecciones (map, set, list, etc.), consulte la sección Uso de colecciones con tablas virtuales .
No se admiten tipos definidos por el usuario.
La longitud de la columna binaria y la columna de cadena no puede ser superior a 4000.
Uso de colecciones con tablas virtuales
El servicio utiliza un controlador ODBC integrado para conectarse a una base de datos de Cassandra y copiar datos de ella. En el caso de los tipos de colección (como map, set y list), el controlador volverá a normalizar los datos en las tablas virtuales correspondientes. En concreto, si una tabla contiene columnas de colecciones, el controlador generará las siguientes tablas virtuales:
- Una tabla base, que contiene los mismos datos que la tabla real, salvo las columnas de colecciones. La tabla base utiliza el mismo nombre que la tabla real a la que representa.
- Una tabla virtual para cada columna de la colección, que ampliará los datos anidados. Para asignar un nombre a las tablas virtuales que representan colecciones, se utiliza el nombre de la tabla real, un separador "vt" y el nombre de la columna.
Las tablas virtuales hacen referencia a los datos de la tabla real, lo que permite al controlador acceder a los datos no normalizados. Consulte la sección de ejemplo para más información. Para acceder al contenido de las colecciones de Cassandra, puede crear consultas y combinar las tablas virtuales.
Ejemplo
Por ejemplo, el siguiente "ExampleTable" es una tabla de una base de datos de Cassandra que contiene una columna de clave principal de enteros denominada “pk_int”, una columna de texto denominada "value", una columna List, una columna Map y una columna Set (denominada "StringSet").
| pk_int | Value | List | Map | StringSet |
|---|---|---|---|---|
| 1 | "valor de ejemplo 1" | ["1", "2", "3"] | {"S1": "a", "S2": "b"} | {"A", "B", "C"} |
| 3 | "valor de ejemplo 3" | ["100", "101", "102", "105"] | {"S1": "t"} | {"A", "E"} |
El controlador generará varias tablas virtuales que representan a esta tabla. Las columnas de clave externa de las tablas virtuales hacen referencia a las columnas de clave principal de la tabla real e indican qué fila de la tabla real se corresponde con la fila de la tabla virtual.
La primera tabla virtual es la tabla base y se denomina "ExampleTable", tal y como se muestra en la siguiente tabla:
| pk_int | Value |
|---|---|
| 1 | "valor de ejemplo 1" |
| 3 | "valor de ejemplo 3" |
La tabla base contiene los mismos datos que la tabla de base de datos original a excepción de las colecciones, que no aparecen en esta tabla, sino que se amplían en otras tablas virtuales.
Las tablas siguientes representan las tablas virtuales que normalizan de nuevo los datos de las columnas List, Map y StringSet. Las columnas cuyos nombres terminan en "_index" o "_key" indican la posición de los datos en la columna List o Map original. Las columnas cuyos nombres terminan en "_value" contienen los datos ampliados de la colección.
Tabla "ExampleTable_vt_List":
| pk_int | List_index | List_value |
|---|---|---|
| 1 | 0 | 1 |
| 1 | 1 | 2 |
| 1 | 2 | 3 |
| 3 | 0 | 100 |
| 3 | 1 | 101 |
| 3 | 2 | 102 |
| 3 | 3 | 103 |
Tabla "ExampleTable_vt_Map":
| pk_int | Map_key | Map_value |
|---|---|---|
| 1 | S1 | Un |
| 1 | S2 | b |
| 3 | S1 | t |
Tabla "ExampleTable_vt_StringSet":
| pk_int | StringSet_value |
|---|---|
| 1 | A |
| 1 | B |
| 1 | C |
| 3 | Un |
| 3 | E |
Propiedades de la actividad de búsqueda
Para obtener información detallada sobre las propiedades, consulte Actividad de búsqueda.
Contenido relacionado
Para obtener una lista de almacenes de datos que la actividad de copia admite como orígenes y receptores, vea Almacenes de datos que se admiten.