Copia de datos desde Amazon RDS para SQL Server mediante Azure Data Factory o Azure Synapse Analytics
En este artículo se resume el uso de la actividad de copia en canalizaciones de Azure Data Factory y Azure Synapse para copiar datos de la base de datos de Amazon RDS for SQL Server. Para obtener más información, lea el artículo de introducción para Azure Data Factory o Azure Synapse Analytics.
Funcionalidades admitidas
Este conector de Amazon RDS for SQL Server es compatible con las funcionalidades siguientes:
| Funcionalidades admitidas | IR |
|---|---|
| Actividad de copia (origen/-) | ① ② |
| Actividad de búsqueda | ① ② |
| Actividad GetMetadata | ① ② |
| Actividad de procedimiento almacenado | ① ② |
① Azure Integration Runtime ② Entorno de ejecución de integración autohospedado
Consulte la tabla de almacenes de datos compatibles para ver una lista de almacenes de datos que la actividad de copia admite como orígenes o receptores.
En concreto, este conector de Amazon RDS for SQL Server admite:
- SQL Server versión 2005 y posteriores.
- La copia de datos con autenticación de SQL o Windows.
- Como origen, la recuperación de datos mediante una consulta SQL o un procedimiento almacenado. También puede optar por la copia en paralelo desde un origen de Amazon RDS for SQL Server. Consulte la sección Copia en paralelo desde una base de datos SQL para obtener detalles.
No se admite la base de datos local LocalDB de SQL Server Express.
Requisitos previos
Si el almacén de datos se encuentra en una red local, una red virtual de Azure o una nube privada virtual de Amazon, debe configurar un entorno de ejecución de integración autohospedado para conectarse a él.
Si el almacén de datos es un servicio de datos en la nube administrado, puede usar Azure Integration Runtime. Si el acceso está restringido a las direcciones IP que están aprobadas en las reglas de firewall, puede agregar direcciones IP de Azure Integration Runtime a la lista de permitidos.
También puede usar la característica del entorno de ejecución de integración de red virtual administrada de Azure Data Factory para acceder a la red local sin instalar ni configurar un entorno de ejecución de integración autohospedado.
Consulte Estrategias de acceso a datos para más información sobre los mecanismos de seguridad de red y las opciones que admite Data Factory.
Introducción
Para realizar la actividad de copia con una canalización, puede usar una de los siguientes herramientas o SDK:
- La herramienta Copiar datos
- Azure Portal
- El SDK de .NET
- El SDK de Python
- Azure PowerShell
- API REST
- La plantilla de Azure Resource Manager
Creación de un servicio vinculado de Amazon RDS for SQL Server mediante la interfaz de usuario
Siga estos pasos para crear un servicio vinculado de Amazon RDS for SQL Server en la interfaz de usuario de Azure Portal.
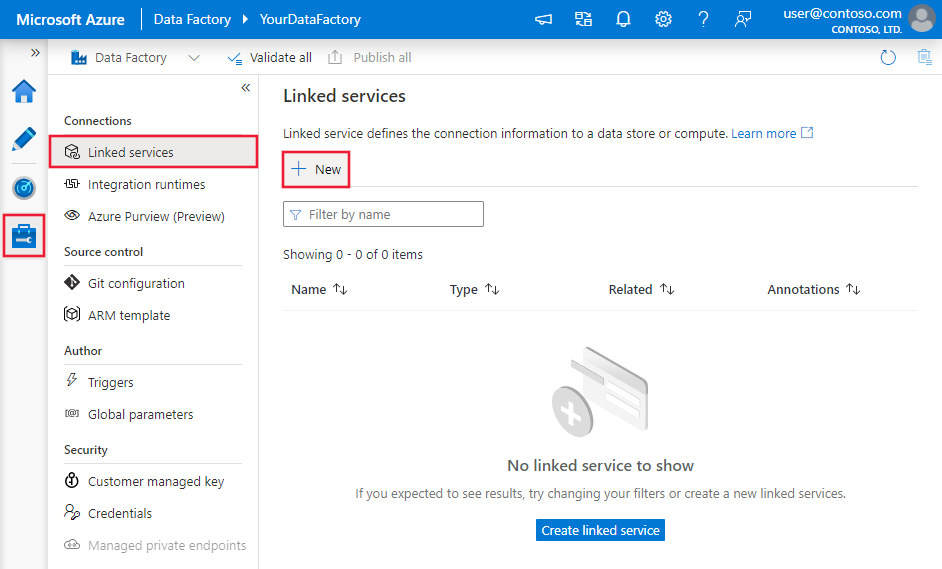
Vaya a la pestaña Administrar del área de trabajo de Azure Data Factory o Synapse y seleccione Servicios vinculados; luego haga clic en Nuevo:
Busque Amazon RDS para SQL Server y seleccione el conector de Amazon RDS for SQL Server.
Configure los detalles del servicio, pruebe la conexión y cree el nuevo servicio vinculado.

Detalles de configuración del conector
En las secciones siguientes se proporcionan detalles sobre las propiedades que se usan para definir entidades de canalizaciones de Data Factory y Synapse específicas del conector de la base de datos de Amazon RDS for SQL Server.
Propiedades del servicio vinculado
La versión recomendada del conector de Amazon RDS para SQL Server admite TLS 1.3. Consulte esta sección para actualizar la versión del conector de Amazon RDS para SQL Server desde el heredado. Para obtener los detalles de la propiedad, consulte las secciones correspondientes.
Nota:
La característica Always Encrypted de Amazon RDS for SQL Server no se admite en el flujo de datos.
Sugerencia
Si recibió un error con el código de error "UserErrorFailedToConnectToSqlServer" y un mensaje parecido a "The session limit for the database is XXX and has been reached" (El límite de sesión de la base de datos es XXX y ya se ha alcanzado), agregue Pooling=false a la cadena de conexión e inténtelo de nuevo.
Versión recomendada
Estas propiedades genéricas son compatibles con un servicio vinculado de Amazon RDS para SQL Server cuando se aplica la versión recomendada:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type debe establecerse en AmazonRdsForSqlServer. | Sí |
| server | Nombre o dirección de red de la instancia de SQL Server a la que desea conectarse. | Sí |
| database | El nombre de la base de datos. | Sí |
| authenticationType | Tipo usado para la autenticación. Los valores permitidos son SQL (valor predeterminado), Windows. Ve a la sección de autenticación pertinente sobre propiedades y requisitos previos específicos. | Sí |
| alwaysEncryptedSettings | Especifique la información alwaysencryptedsettings necesaria para permitir que Always Encrypted proteja los datos confidenciales almacenados en Amazon RDS for SQL Server mediante una identidad administrada o una entidad de servicio. Para obtener más información, vea el ejemplo de JSON debajo de la tabla y consulte la sección Uso de Always Encrypted. Si no se especifica, la configuración predeterminada Always Encrypted está deshabilitada. | No |
| encrypt | Indica si se requiere cifrado TLS para todos los datos enviados entre el cliente y el servidor. Opciones: obligatorio (para true, valor predeterminado)/opcional (para falso)/restringido. | No |
| trustServerCertificate | Indique si el canal se cifrará al pasar la cadena de certificados para validar la confianza. | No |
| hostNameInCertificate | Nombre de host que se va a usar al validar el certificado de servidor para la conexión. Cuando no se especifica, el nombre del servidor se usa para la validación de certificados. | No |
| connectVia | Este entorno de ejecución de integración se usa para conectarse al almacén de datos. Obtenga más información en la sección Requisitos previos. Si no se especifica, se usa el valor predeterminado de Azure Integration Runtime. | No |
Para obtener más propiedades de conexión, consulte la tabla siguiente:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| applicationIntent | Tipo de carga de trabajo de aplicación al conectarse a un servidor. Los valores permitidos son ReadOnly y ReadWrite. |
No |
| connectTimeout | El período de tiempo (en segundos) que se espera a una conexión al servidor antes de finalizar el intento y generar un error. | No |
| connectRetryCount | Número de reconexión intentadas después de identificar un error de conexión inactiva. El valor debe ser un número entero entre 0 y 255. | No |
| connectRetryInterval | Cantidad de tiempo (en segundos) entre cada intento de reconexión después de identificar un error de conexión inactiva. El valor debe ser un entero entre 1 y 60. | No |
| loadBalanceTimeout | Tiempo mínimo (en segundos) para que la conexión resida en el grupo de conexiones antes de que se destruya la conexión. | No |
| commandTimeout | Tiempo de espera predeterminado (en segundos) antes de terminar el intento de ejecutar un comando y generar un error. | No |
| integratedSecurity | Los valores permitidos son true o false. Al especificar false, indique si userName y contraseña se especifican en la conexión. Al especificar true, indica si las credenciales actuales de la cuenta de Windows se usan para la autenticación. |
No |
| failoverPartner | Nombre o dirección del servidor asociado al que se va a conectar si el servidor principal está inactivo. | No |
| maxPoolSize | Número máximo de conexiones permitidas en el grupo de conexiones para la conexión específica. | No |
| minPoolSize | Número mínimo de conexiones permitidas en el grupo de conexiones para la conexión específica. | No |
| multipleActiveResultSets | Los valores permitidos son true o false. Al especificar true, una aplicación puede mantener conjunto de resultados activo múltiple (MARS). Al especificar false, una aplicación debe procesar o cancelar todos los conjuntos de resultados de un lote para poder ejecutar cualquier otro lote en esa conexión. |
No |
| multiSubnetFailover | Los valores permitidos son true o false. Si la aplicación se conecta a un grupo de disponibilidad AlwaysOn (AG) en subredes diferentes, establecer esta propiedad en true proporciona una detección y conexión más rápidas con el servidor activo actualmente. |
No |
| packetSize | Tamaño en bytes de los paquetes de red usados para comunicarse con una instancia de servidor. | No |
| pooling | Los valores permitidos son true o false. Al especificar true, la conexión se agrupará. Al especificar false, la conexión se abrirá explícitamente cada vez que se solicite la conexión. |
No |
Autenticación SQL
Para usar la autenticación de SQL, además de las propiedades genéricas que se describen en la sección anterior, especifique las siguientes propiedades:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| userName | Nombre de usuario usado para conectarse al servidor. | Sí |
| password | Contraseña del nombre de usuario. Marque este campo como SecureString para almacenarlo de forma segura. O bien puede hacer referencia a un secreto almacenado en Azure Key Vault. | Sí |
Ejemplo: Uso de la autenticación de SQL
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ejemplo 2: Uso de la autenticación de SQL con una contraseña en Azure Key Vault
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ejemplo: Use Always Encrypted
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticación de Windows
Para usar autenticación de Windows, además de las propiedades genéricas que se describen en la sección anterior, especifica las siguientes propiedades:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| userName | Especifique un nombre de usuario. Un ejemplo es domainname\username. | Sí |
| password | Especifique la contraseña de la cuenta de usuario que se especificó para el nombre de usuario. Marque este campo como SecureString para almacenarlo de forma segura. O bien puede hacer referencia a un secreto almacenado en Azure Key Vault. | Sí |
Ejemplo: Use la autenticación de Windows
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "Windows",
"userName": "<domain\\username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Versión heredada
Estas propiedades genéricas son compatibles con un servicio vinculado de Amazon RDS para SQL Server cuando se aplica la versión heredada:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type debe establecerse en AmazonRdsForSqlServer. | Sí |
| alwaysEncryptedSettings | Especifique la información alwaysencryptedsettings necesaria para permitir que Always Encrypted proteja los datos confidenciales almacenados en Amazon RDS for SQL Server mediante una identidad administrada o una entidad de servicio. Para más información, consulte la sección Uso de Always Encrypted. Si no se especifica, la configuración predeterminada Always Encrypted está deshabilitada. | No |
| connectVia | Este entorno de ejecución de integración se usa para conectarse al almacén de datos. Obtenga más información en la sección Requisitos previos. Si no se especifica, se usa el valor predeterminado de Azure Integration Runtime. | No |
Este conector Amazon RDS para SQL Server admite los siguientes tipos de autenticación. Consulte las secciones correspondientes para más información.
Autenticación de SQL para la versión heredada
Para usar autenticación SQL, además de las propiedades genéricas que se describen en la sección anterior, especifica las siguientes propiedades:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| connectionString | Especifique la información de connectionString necesaria para conectarse a la base de datos de Amazon RDS para SQL Server. Especifique un nombre de inicio de sesión como nombre de usuario y asegúrese de que la base de datos que desea conectar está asignada a este inicio de sesión. | Sí |
| password | Si quiere establecer una contraseña en Azure Key Vault, extraiga la configuración de password de la cadena de conexión. Para obtener más información, consulte Almacenamiento de credenciales en Azure Key Vault. |
No |
Autenticación de Windows para la versión heredada
Para usar autenticación de Windows, además de las propiedades genéricas que se describen en la sección anterior, especifica las siguientes propiedades:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| connectionString | Especifique la información de connectionString necesaria para conectarse a la base de datos de Amazon RDS para SQL Server. | Sí |
| userName | Especifique un nombre de usuario. Un ejemplo es domainname\username. | Sí |
| password | Especifique la contraseña de la cuenta de usuario que se especificó para el nombre de usuario. Marque este campo como SecureString para almacenarlo de forma segura. O bien puede hacer referencia a un secreto almacenado en Azure Key Vault. | Sí |
Propiedades del conjunto de datos
Si desea ver una lista completa de las secciones y propiedades disponibles para definir conjuntos de datos, consulte el artículo sobre conjuntos de datos. En esta sección se proporciona una lista de las propiedades que admite el conjunto de datos de Amazon RDS for SQL Server.
Las siguientes propiedades son compatibles para copiar datos desde una base de datos de Amazon RDS for SQL Server:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del conjunto de datos se debe establecer en AmazonRdsForSqlServerTable. | Sí |
| esquema | Nombre del esquema. | No |
| table | Nombre de la tabla o vista. | No |
| tableName | Nombre de la tabla o vista con el esquema. Esta propiedad permite la compatibilidad con versiones anteriores. Para la nueva carga de trabajo use schema y table. |
No |
Ejemplo
{
"name": "AmazonRdsForSQLServerDataset",
"properties":
{
"type": "AmazonRdsForSqlServerTable",
"linkedServiceName": {
"referenceName": "<Amazon RDS for SQL Server linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Propiedades de la actividad de copia
Si desea ver una lista completa de las secciones y propiedades disponibles para definir actividades, vea el artículo sobre canalizaciones. En esta sección se proporciona una lista de las propiedades que admite el origen de Amazon RDS for SQL Server.
Amazon RDS for SQL Server como origen
Sugerencia
Para cargar datos desde Amazon RDS for SQL Server de manera eficaz mediante la creación de particiones de datos, consulte Copia en paralelo desde una base de datos SQL.
Para copiar datos desde Amazon RDS for SQL Server, establezca el tipo de origen de la actividad de copia en AmazonRdsForSqlServerSource. En la sección source de la actividad de copia se admiten las siguientes propiedades:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del origen de la actividad de copia debe establecerse en: AmazonRdsForSqlServerSource. | Sí |
| sqlReaderQuery | Use la consulta SQL personalizada para leer los datos. Un ejemplo es select * from MyTable. |
No |
| sqlReaderStoredProcedureName | Esta propiedad es el nombre del procedimiento almacenado que lee datos de la tabla de origen. La última instrucción SQL debe ser una instrucción SELECT del procedimiento almacenado. | No |
| storedProcedureParameters | Estos parámetros son para el procedimiento almacenado. Los valores permitidos son pares de nombre o valor. Los nombres y las mayúsculas y minúsculas de los parámetros tienen que coincidir con las mismas características de los parámetros de procedimiento almacenado. |
No |
| isolationLevel | Especifica el comportamiento de bloqueo de transacción para el origen de SQL. Los valores permitidos son: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable y Snapshot. Si no se especifica, se utiliza el nivel de aislamiento predeterminado de la base de datos. Vea este documento para obtener más detalles. | No |
| partitionOptions | Especifica las opciones de creación de particiones de datos que se usan para cargar datos desde Amazon RDS for SQL Server. Los valores permitidos son: None (valor predeterminado), PhysicalPartitionsOfTable y DynamicRange. Cuando se habilita una opción de partición (es decir, el valor no es None), el grado de paralelismo para cargar datos de manera simultánea desde Amazon RDS for SQL Server se controla mediante la opción parallelCopies en la actividad de copia. |
No |
| partitionSettings | Especifique el grupo de configuración para la creación de particiones de datos. Se aplica si la opción de partición no es None. |
No |
En partitionSettings: |
||
| partitionColumnName | Especifique el nombre de la columna de origen de tipo entero o date/datetime (int, smallint, bigint, date, smalldatetime, datetime, datetime2 o datetimeoffset) que se va a usar en la creación de particiones por rangos para la copia en paralelo. Si no se especifica, el índice o la clave primaria de la tabla se detectan automáticamente y se usan como columna de partición.Se aplica si la opción de partición es DynamicRange. Si usa una consulta para recuperar datos de origen, enlace ?DfDynamicRangePartitionCondition en la cláusula WHERE. Para obtener un ejemplo, vea la sección Copia en paralelo desde una base de datos SQL. |
No |
| partitionUpperBound | Valor máximo de la columna de partición para la división del rango de partición. Este valor se usa para decidir el intervalo de particiones, no para filtrar las filas de la tabla. Se crean particiones de todas las filas de la tabla o el resultado de la consulta y se copian. Si no se especifica, la actividad de copia detecta automáticamente el valor. Se aplica si la opción de partición es DynamicRange. Para obtener un ejemplo, vea la sección Copia en paralelo desde una base de datos SQL. |
No |
| partitionLowerBound | Valor mínimo de la columna de partición para la división del rango de partición. Este valor se usa para decidir el intervalo de particiones, no para filtrar las filas de la tabla. Se crean particiones de todas las filas de la tabla o el resultado de la consulta y se copian. Si no se especifica, la actividad de copia detecta automáticamente el valor. Se aplica si la opción de partición es DynamicRange. Para obtener un ejemplo, vea la sección Copia en paralelo desde una base de datos SQL. |
No |
Tenga en cuenta los siguientes puntos:
- Si se especifica sqlReaderQuery para AmazonRdsForSqlServerSource, la actividad de copia ejecuta la consulta en el origen de Amazon RDS for SQL Server a fin de obtener los datos. También puede indicar un procedimiento almacenado mediante la definición de sqlReaderStoredProcedureName y storedProcedureParameters si el procedimiento almacenado adopta parámetros.
- Al usar el procedimiento almacenado del origen para recuperar datos, tenga en cuenta que si está diseñado para devolver otro esquema cuando se pasa un valor de parámetro diferente, es posible que encuentre un error o vea un resultado inesperado al importar el esquema desde la interfaz de usuario, o bien al copiar datos en la base de datos SQL con la creación automática de tablas.
Ejemplo: Uso de la consulta SQL
"activities":[
{
"name": "CopyFromAmazonRdsForSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForSqlServerSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Ejemplo: Uso de un procedimiento almacenado
"activities":[
{
"name": "CopyFromAmazonRdsForSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForSqlServerSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Definición del procedimiento almacenado
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Copia en paralelo desde una base de datos SQL
En la actividad de copia, el conector de Amazon RDS for SQL Server proporciona una creación de particiones de datos integrada para copiar los datos en paralelo. Puede encontrar las opciones de creación de particiones de datos en la pestaña Origen de la actividad de copia.
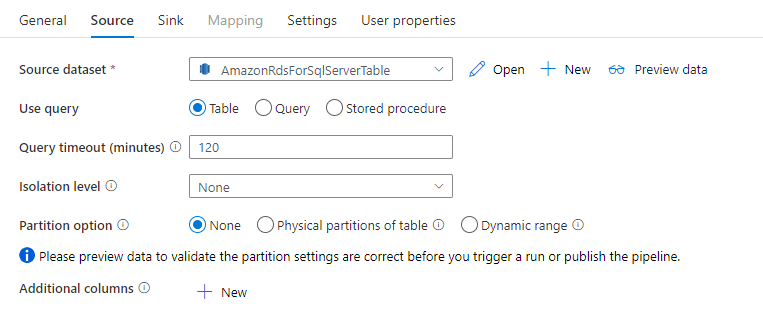
Al habilitar la copia con particiones, la actividad de copia ejecuta consultas en paralelo en el origen de Amazon RDS for SQL Server a fin de cargar los datos por particiones. El grado en paralelo se controla mediante el valor parallelCopies de la actividad de copia. Por ejemplo, si establece parallelCopies en cuatro, el servicio genera y ejecuta al mismo tiempo cuatro consultas de acuerdo con la configuración y la opción de partición que ha especificado, y cada consulta recupera una porción de datos de Amazon RDS for SQL Server.
Se sugiere habilitar la copia en paralelo con la creación de particiones de datos, especialmente si se cargan grandes cantidades de datos de Amazon RDS for SQL Server. Estas son algunas configuraciones sugeridas para diferentes escenarios. Cuando se copian datos en un almacén de datos basado en archivos, se recomienda escribirlos en una carpeta como varios archivos (solo especifique el nombre de la carpeta), en cuyo caso el rendimiento es mejor que escribirlos en un único archivo.
| Escenario | Configuración sugerida |
|---|---|
| Carga completa de una tabla grande con particiones físicas. | Opción de partición: particiones físicas de la tabla. Durante la ejecución, el servicio detecta automáticamente las particiones físicas y copia los datos por particiones. Para comprobar si la tabla tiene una partición física o no, puede hacer referencia a esta consulta. |
| Carga completa de una tabla grande, sin particiones físicas, aunque con una columna de tipo entero o datetime para la creación de particiones de datos. | Opciones de partición: partición por rangos dinámica. Columna de partición (opcional): especifique la columna usada para crear la partición de datos. Si no se especifica, se usa la columna de clave principal. Límite de partición superior y límite de partición inferior (opcional): especifique si quiere determinar el intervalo de la partición. No es para filtrar las filas de la tabla, se crean particiones de todas las filas de la tabla y se copian. Si no se especifica, la actividad de copia detecta automáticamente los valores y puede tardar mucho tiempo en función de los valores MIN y MAX. Se recomienda proporcionar límite superior e inferior. Por ejemplo, si la columna de partición "ID" tiene valores que van de 1 a 100 y establece el límite inferior en 20 y el superior en 80, con la copia en paralelo establecida en 4, el servicio recupera los datos en 4 particiones: identificadores del rango <=20, del rango [21, 50], del rango [51, 80] y del rango >=81, respectivamente. |
| Carga de grandes cantidades de datos mediante una consulta personalizada, sin particiones físicas, aunque con una columna de tipo entero o date/datetime para la creación de particiones de datos. | Opciones de partición: partición por rangos dinámica. Consulta: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Columna de partición: especifique la columna usada para crear la partición de datos. Límite de partición superior y límite de partición inferior (opcional): especifique si quiere determinar el intervalo de la partición. No es para filtrar las filas de la tabla, se crean particiones de todas las filas del resultado de la consulta y se copian. Si no se especifica, la actividad de copia detecta automáticamente el valor. Por ejemplo, si la columna de partición "ID" tiene valores que van de 1 a 100 y establece el límite inferior en 20 y el superior en 80, con la copia en paralelo establecida en 4, el servicio recupera los datos en 4 particiones: identificadores del rango <=20, del rango [21, 50], del rango [51, 80] y del rango >=81, respectivamente. A continuación se muestran más consultas de ejemplo para distintos escenarios: 1. Consulta de la tabla completa: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Consulta de una tabla con selección de columnas y filtros adicionales de la cláusula where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Consulta con subconsultas: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Consulta con partición en subconsulta: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Procedimientos recomendados para cargar datos con la opción de partición:
- Seleccione una columna distintiva como columna de partición (como clave principal o clave única) para evitar la asimetría de datos.
- Si la tabla tiene una partición integrada, use la opción de partición "Particiones físicas de tabla" para obtener un mejor rendimiento.
- Si usa Azure Integration Runtime para copiar datos, puede establecer "unidades de integración de datos (DIU)" mayores (>4) para usar más recursos de cálculo. Compruebe los escenarios aplicables allí.
- "Grado de paralelismo de copia" controla los números de partición. Si se establece en un número demasiado grande, puede resentirse el rendimiento, así que se recomienda establecerlo como (DIU o número de nodos de IR autohospedados) * (2 a 4).
Ejemplo: carga completa de una tabla grande con particiones físicas
"source": {
"type": "AmazonRdsForSqlServerSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Ejemplo: consulta con partición por rangos dinámica
"source": {
"type": "AmazonRdsForSqlServerSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Consulta de ejemplo para comprobar la partición física
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Si la tabla tiene una partición física, verá "HasPartition" como "yes" como en el caso siguiente.

Propiedades de la actividad de búsqueda
Para obtener información detallada sobre las propiedades, consulte Actividad de búsqueda.
Propiedades de la actividad GetMetadata
Para información detallada sobre las propiedades, consulte Actividad de obtención de metadatos.
Uso de Always Encrypted
Al copiar datos desde o hacia Amazon RDS for SQL Server con Always Encrypted, siga estos pasos:
Almacene la clave maestra de columna (CMK) en una instancia de Azure Key Vault. Obtenga más información acerca de la configuración de Always Encrypted con Azure Key Vault
Asegúrese de conceder acceso al almacén de claves donde se almacena la clave maestra de columna (CMK). Consulte este artículo para obtener información acerca de los permisos necesarios.
Cree un servicio vinculado para conectarse a la base de datos SQL y habilitar la función "Always Encrypted" mediante una identidad administrada o una entidad de servicio.
Solución de problemas de conexión
Configure la instancia de Amazon RDS for SQL Server para que acepte conexiones remotas. Inicie Amazon RDS for SQL Server Management Studio, haga clic con el botón derecho en servidor y seleccione Propiedades. Seleccione Conexiones en la lista y marque la casilla Permitir conexiones remotas con este servidor.
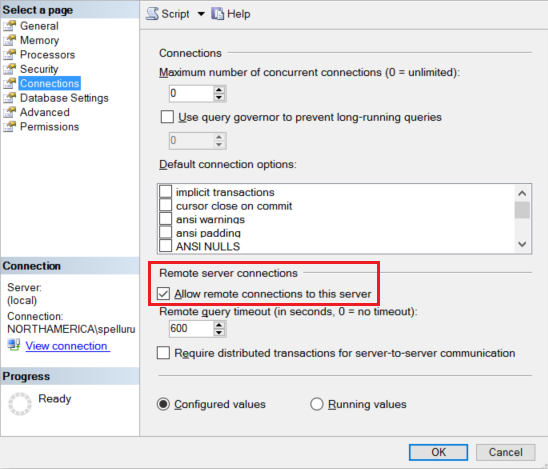
Consulte los pasos detallados en el artículo Configurar la opción de configuración del servidor Acceso remoto.
Inicie Amazon RDS for SQL Server Configuration Manager. Expanda la configuración de la red de Amazon RDS for SQL Server para la instancia que desee y seleccione Protocolos para MSSQLSERVER. Los protocolos aparecen en el panel derecho. Para habilitar TCP/IP, haga clic con el botón derecho en TCP/IP y seleccione Habilitar.
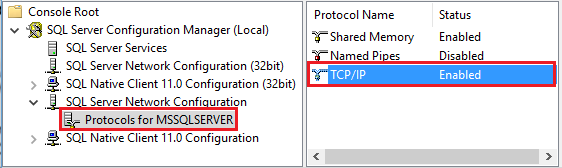
Para obtener más información y maneras alternativas de habilitar el protocolo TCP/IP, consulte Habilitar o deshabilitar un protocolo de red de servidor.
En la misma ventana, haga doble clic en TCP/IP para abrir la ventana TCP/IP Properties (Propiedades de TCP/IP).
Cambie a la pestaña Direcciones IP . Desplácese hacia abajo hasta la sección IPAll. Escriba el puerto TCP. El valor predeterminado es 1433.
Cree una regla del Firewall de Windows en la máquina para permitir el tráfico entrante a través de este puerto.
Compruebe la conexión: use Amazon RDS for SQL Server Management Studio en una máquina diferente para conectarse a Amazon RDS for SQL Server con un nombre completo. Un ejemplo es
"<machine>.<domain>.corp.<company>.com,1433".
Actualización de la versión de Amazon RDS para SQL Server
Para actualizar a la versión de Amazon RDS para SQL Server, en la página Editar servicio vinculado, seleccione Recomendado en Versión y configure el servicio vinculado haciendo referencia a las propiedades del servicio vinculado para la versión recomendada.
Diferencias entre la versión recomendada y heredada
En la tabla siguiente se muestran las diferencias entre el RDS de Amazon para SQL Server con la versión recomendada y heredada.
| Versión recomendada | Versión heredada |
|---|---|
Admite TLS 1.3 a través de encrypt como strict. |
No se admite TLS 1.3. |
Contenido relacionado
Para obtener una lista de almacenes de datos que la actividad de copia admite como orígenes y receptores, vea Almacenes de datos que se admiten.