Optimización de transformaciones
Use las estrategias siguientes para optimizar el rendimiento de las transformaciones en los flujos de datos de asignación en las canalizaciones de Azure Data Factory y Azure Synapse Analytics.
Optimización de transformaciones de tipo Combinación, Existe y Búsqueda
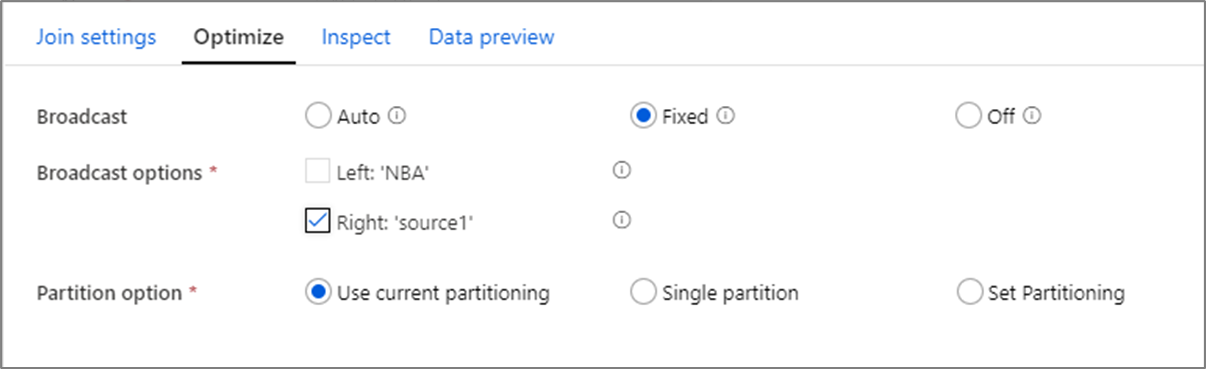
Difusión
En las transformaciones de tipo Combinación, Búsqueda y Existe, cuando uno o ambos flujos de datos son lo suficientemente pequeños como para caber en la memoria del nodo de trabajo, puede optimizar el rendimiento si habilita la opción Broadcast (Difusión). La difusión consiste en enviar tramas de datos pequeñas a todos los nodos del clúster. Esto permite que el motor de Spark realice una combinación sin reordenar los datos del flujo grande. De forma predeterminada, el motor de Spark decide automáticamente si difundir o no un lado de una combinación. Si está familiarizado con los datos de entrada y sabe que un flujo es menor que el otro, puede seleccionar la opción de difusión Fixed (Fija). La difusión fija fuerza a Spark a difundir el flujo seleccionado.
Si el tamaño de los datos difundidos es demasiado grande para el nodo de Spark, puede aparecer un error de memoria insuficiente. Para evitar estos errores, utilice los clústeres optimizados para memoria. Si hay tiempos de espera de difusión durante las ejecuciones de flujo de datos, puede desactivar la optimización de difusión. Sin embargo, esto da lugar a flujos de datos con un rendimiento más lento.
Al trabajar con orígenes de datos que pueden tardar más tiempo en consultarse, como las consultas de bases de datos grandes, se recomienda desactivar la transmisión para las combinaciones. Los orígenes con tiempos de consulta largos pueden hacer que se agoten los tiempos de espera de Spark cuando el clúster intenta transmitir a nodos de proceso. También es una buena opción desactivar la transmisión cuando tiene una transmisión en el flujo de datos que agrega valores para usarlos en una transformación de búsqueda más adelante. Este patrón puede confundir al optimizador de Spark y hacer que se agoten los tiempos de espera.
Combinaciones cruzadas
Si usa valores literales en las condiciones de combinación o tiene varias coincidencias en ambos lados de una combinación, Spark ejecuta la combinación como una combinación cruzada. Una combinación cruzada es un producto cartesiano completo que, a continuación, filtra los valores combinados. Es más lenta que otros tipos de combinación. Asegúrese de que tiene referencias de columna en ambos lados de las condiciones de combinación para evitar que afecte al rendimiento.
Ordenación antes de las combinaciones
A diferencia de la unión de combinación en herramientas como SSIS, la transformación Combinación no es una operación de unión de combinación obligatoria. Las claves de combinación no requieren que se ordene antes de la transformación. No se recomienda usar transformaciones de ordenación en flujos de datos de asignación.
Rendimiento de la transformación de ventana
La Transformación Ventana en el flujo de datos de asignación divide los datos por valor en las columnas que se seleccionan como parte de la cláusula over() de la configuración de la transformación. Hay una serie de funciones de agregado y análisis muy populares que se exponen en la transformación de ventanas. Sin embargo, si el caso de uso es generar una ventana sobre todo el conjunto de filas para clasificar rank() o el número de fila rowNumber(), se recomienda que utilice en su lugar la transformación de clasificación y la transformación de clave suplente. Esas transformaciones funcionan mejor con las operaciones de conjunto de datos completos que usan esas funciones.
Creación de nuevas particiones de datos asimétricos
Ciertas transformaciones, como las combinaciones y los agregados, reordenan las particiones de datos y en ocasiones pueden provocar datos asimétricos. Los datos asimétricos son aquellos que no se distribuyen uniformemente entre las particiones. Los datos muy asimétricos pueden dar lugar a transformaciones y escrituras de receptor de nivel inferior más lentas. Puede comprobar la asimetría de los datos en cualquier momento de una ejecución de flujo de datos haciendo clic en la transformación en la pantalla de supervisión.
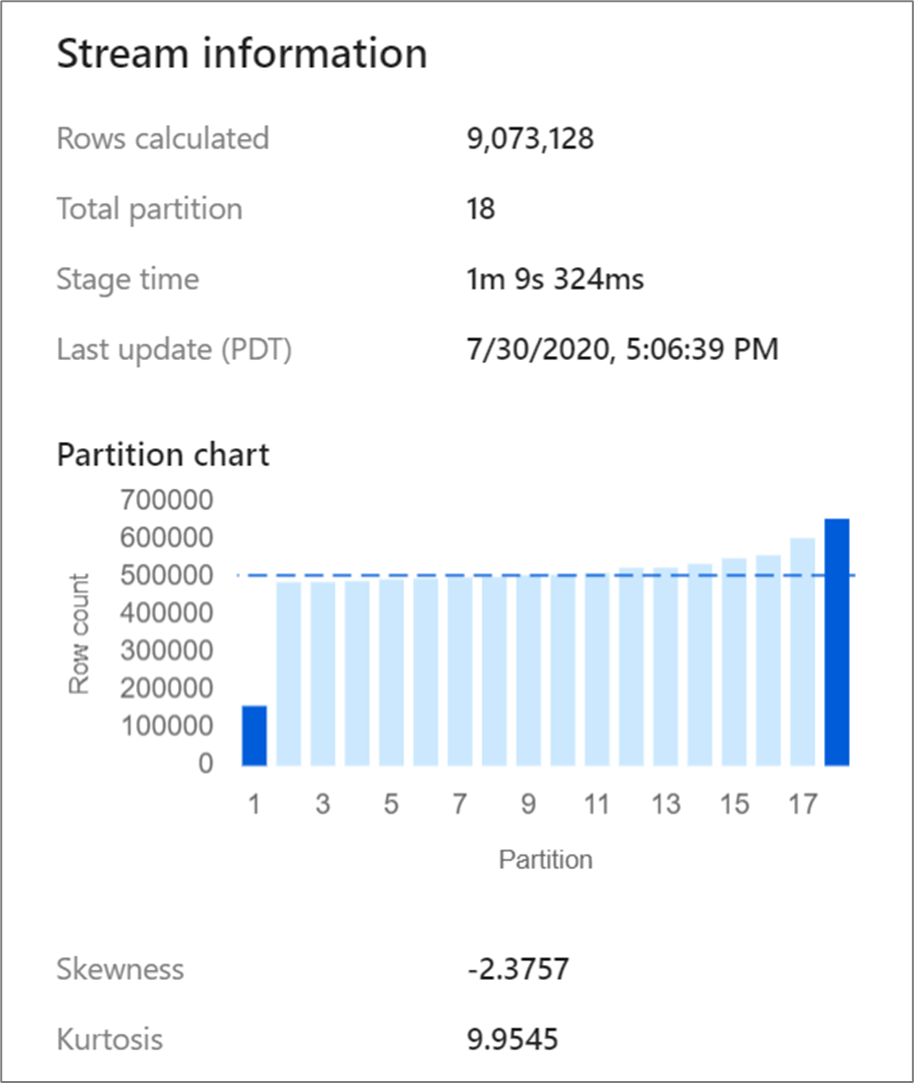
La pantalla de supervisión muestra cómo se distribuyen los datos en cada partición, junto con dos métricas, asimetría y curtosis. El valor Skewness (Asimetría) es una medida del grado de asimetría que tienen los datos; puede tener un valor positivo, cero, negativo o indefinido. Una asimetría negativa significa que la cola izquierda es más larga que la derecha. El valor Kurtosis (Curtosis) es la medida que indica si los datos son de cola pesada o de cola ligera. No son deseables valores altos de curtosis. Los intervalos ideales de asimetría se encuentran entre -3 y 3 y los de curtosis son menores que 10. Una manera fácil de interpretar estos números es examinar el gráfico de particiones y ver si una barra es mayor que el resto.
Si los datos no quedan distribuidos uniformemente en las particiones después de una transformación, puede usar la pestaña Optimize (Optimizar) para volver a crear las particiones. La reordenación de los datos tarda tiempo y puede que no mejore el rendimiento del flujo de datos.
Sugerencia
Si vuelve a crear particiones de los datos, pero tiene transformaciones de nivel inferior que reordenan los datos, utilice la creación de particiones por hash en una columna utilizada como clave de combinación.
Nota
Las transformaciones dentro del flujo de datos (a excepción de la transformación de receptor) no modifican la creación de particiones de archivos y carpetas de los datos en reposo. La creación de particiones en cada transformación reparticiona los datos dentro de los marcos de datos del clúster de Spark sin servidor temporal que ADF administra para cada una de las ejecuciones de flujo de datos.
Contenido relacionado
- Introducción al rendimiento del flujo de datos
- Optimización de orígenes
- Optimización de receptores
- Uso de flujos de datos en canalizaciones
Vea el resto de artículos sobre Data Flow relacionados con el rendimiento: