Conector de Azure Data Explorer para Apache Spark
Apache Spark es un motor de análisis unificado para el procesamiento de datos a gran escala. Azure Data Explorer es un servicio de análisis de datos rápido y totalmente administrado que permite analizar grandes volúmenes de datos en tiempo real.
El conector de Kusto para Spark es un proyecto de código abierto que se puede ejecutar en cualquier clúster de Spark. Implementa el origen y el receptor de datos para mover datos entre los clústeres de Azure Data Explorer y de Spark. Con Azure Data Explorer y Apache Spark, puede compilar aplicaciones rápidas y escalables orientadas a escenarios controlados por datos. Por ejemplo, aprendizaje automático (ML), extracción, transformación y carga de datos (ETL) y Log Analytics. Gracias al conector, Azure Data Explorer se convierte en un almacén de datos válido para las operaciones estándar de origen y receptor de Spark, como escritura, lectura y writeStream.
Puede escribir en Azure Data Explorer a través de la ingesta en cola o la ingesta de streaming. La lectura desde Azure Data Explorer admite la eliminación de columnas y la aplicación del predicado, lo que filtra los datos en Azure Data Explorer, reduciendo el volumen de datos transferidos.
Nota:
Para más información sobre cómo trabajar con el conector de Synapse Spark para Azure Data Explorer, consulte Conexión a Azure Data Explorer con Apache Spark para Azure Synapse Analytics.
En este tema se describe cómo instalar y configurar el conector de Azure Data Explorer para Spark y cómo trasladar los datos entre los clústeres de Azure Data Explorer y de Apache Spark.
Nota:
Aunque algunos de los ejemplos siguientes se refieren a un clúster de Spark de Azure Databricks, el conector de Spark de Azure Data Explorer no tiene dependencias directas en Databricks ni en ninguna otra distribución de Spark.
Requisitos previos
- Suscripción a Azure. Cree una cuenta de Azure gratuita.
- Un clúster y la base de datos de Azure Data Explorer. Cree un clúster y una base de datos.
- Un clúster de Spark.
- Instalación de la biblioteca del conector:
- Bibliotecas pregeneradas para Spark 2.4 + Scala 2.11 o Spark 3 + Scala 2.12
- Repositorio de Maven
- Maven 3.x instalado
Sugerencia
Las versiones 2.3.x de Spark también se admiten, pero pueden requerir algunos cambios en las dependencias pom.xml.
Cómo crear el conector de Spark
A partir de la versión 2.3.0 se introducen nuevos identificadores de artefacto que reemplazan a spark-kusto-connector: kusto-spark_3.0_2.12 con para Spark 3.x y Scala 2.12.
Nota:
Las versiones anteriores a la versión 2.5.1 ya no funcionan para la ingesta en una tabla existente. Realice la actualización a una versión posterior. Este paso es opcional. Si usa bibliotecas predefinidas, como por ejemplo, Maven, consulte Instalación del clúster de Spark.
Requisitos previos de compilación
Consulte este origen para crear el conector de Spark.
Para aplicaciones de Scala o Java que usan definiciones de proyecto de Maven, vincule su aplicación con el artefacto más reciente. Busque el artefacto más reciente en Maven Central.
For more information, see [https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12](https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12).Si no usa bibliotecas pregeneradas, debe instalar las bibliotecas enumeradas en las dependencias, lo que incluye las bibliotecas del SDK de Java de Kusto siguientes. Para encontrar la versión correcta que se va a instalar, busque en el archivo pom de la versión pertinente:
Para compilar el archivo jar y ejecutar todas las pruebas:
mvn clean package -DskipTestsPara compilar el archivo jar, ejecute todas las pruebas e instale jar en el repositorio de Maven local:
mvn clean install -DskipTests
Para obtener más información, consulte Uso de conectores.
Instalación del clúster de Spark
Nota:
Se recomienda usar la última versión del conector de Kusto para Spark al realizar los pasos a continuación.
Establezca la siguiente configuración del clúster de Spark, basado en el clúster de Azure Databricks Spark 3.0.1 y Scala 2.12:
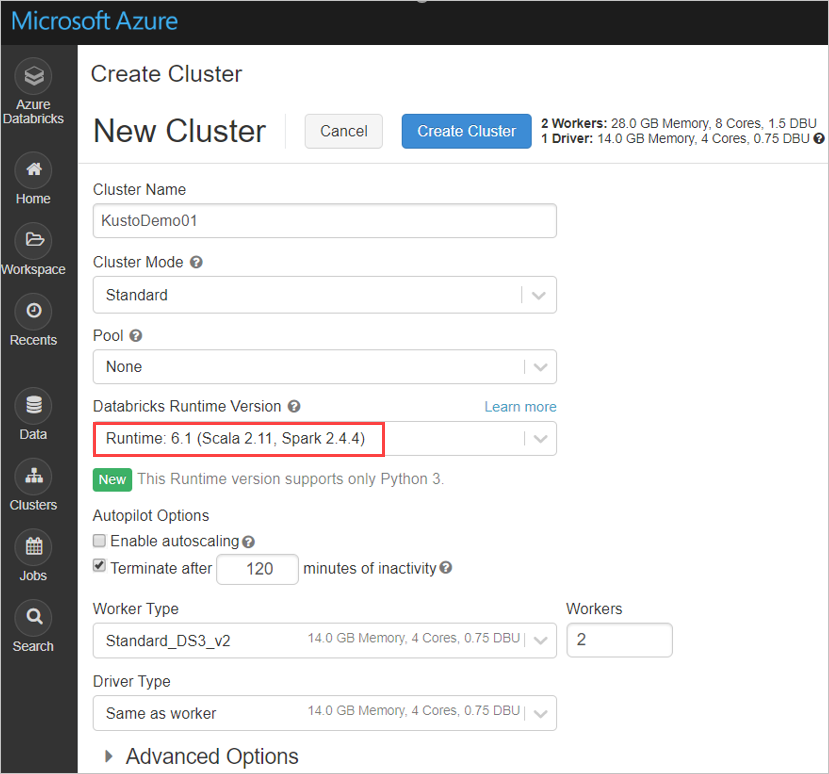
Instale la biblioteca spark-kusto-connector más reciente de Maven:
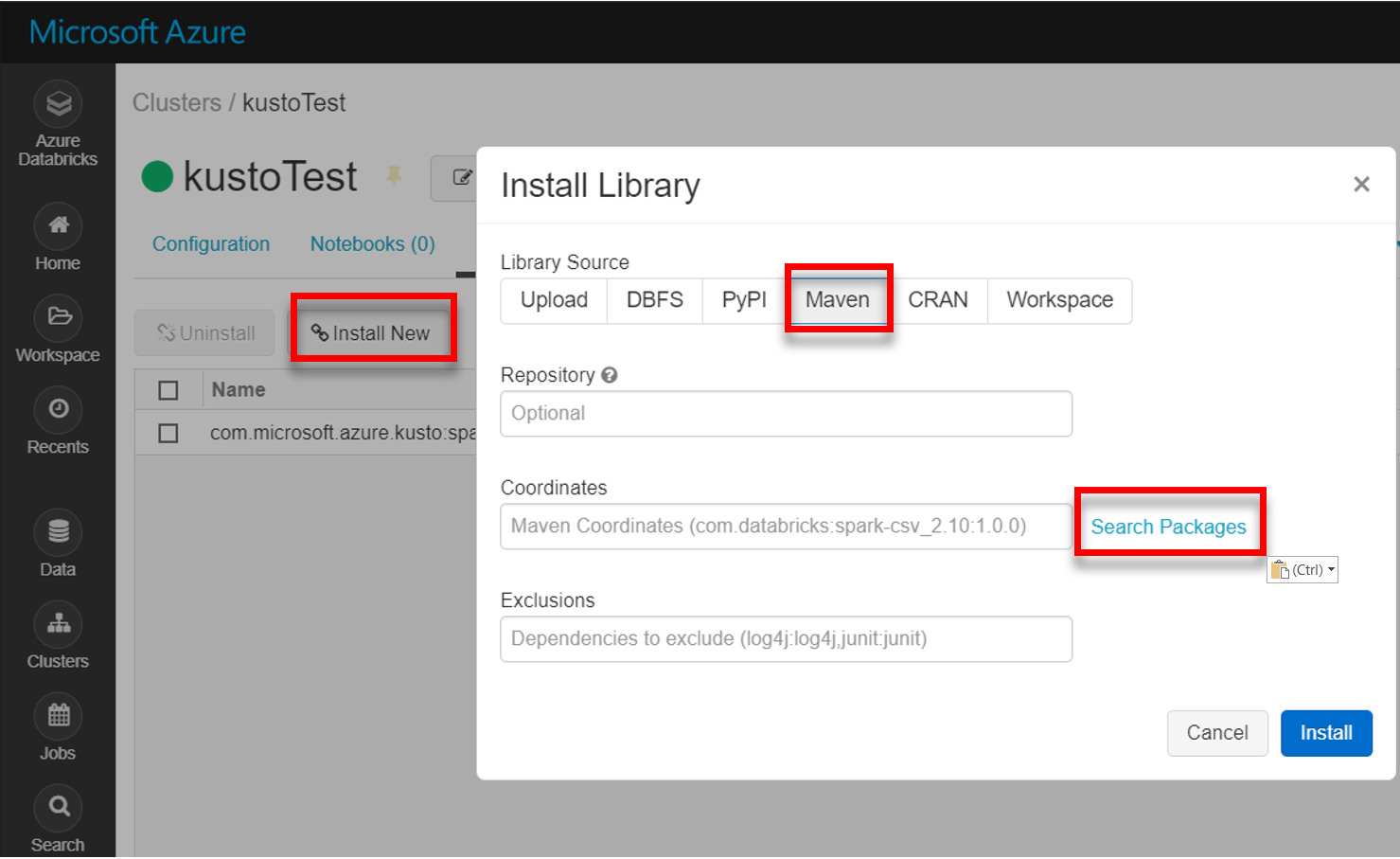
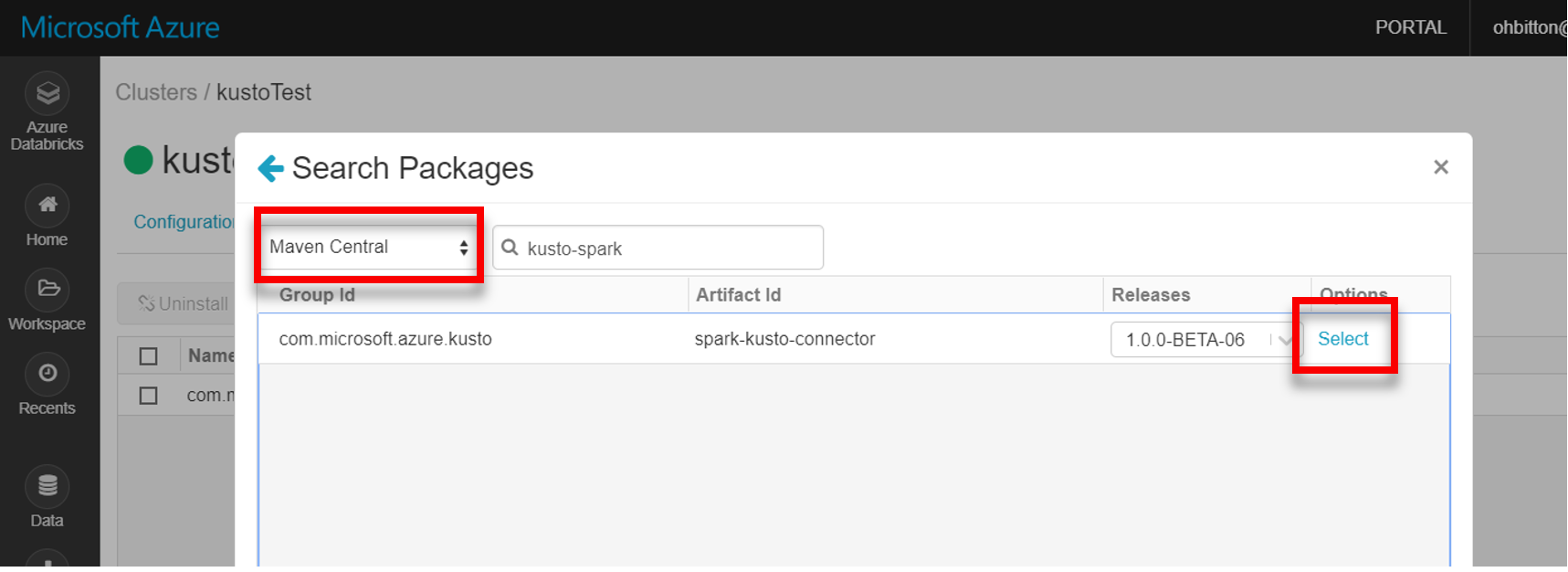
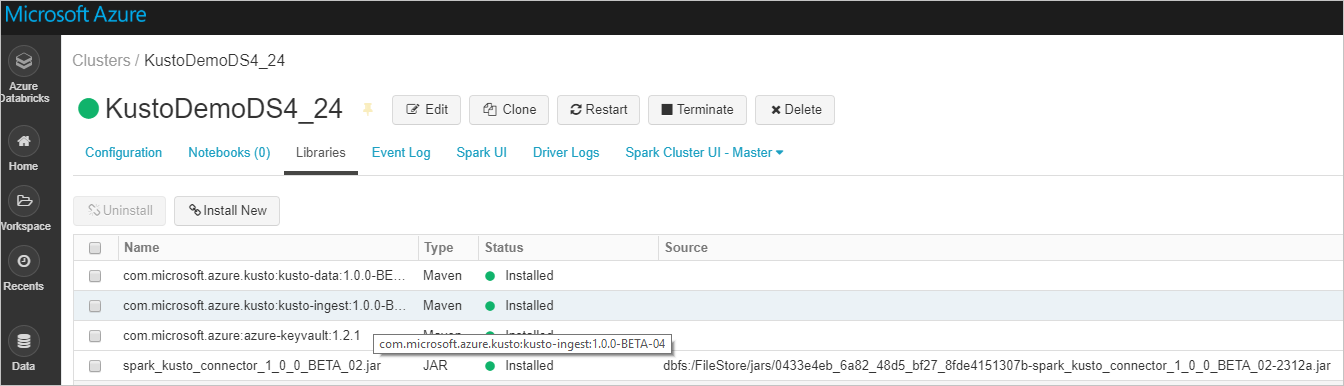
Compruebe que están instaladas todas las bibliotecas necesarias:
Para realizar la instalación con un archivo JAR, compruebe que se instalaron dependencias adicionales:
Autenticación
El conector de Spark de Kusto le permite autenticarse con Microsoft Entra ID mediante uno de los métodos siguientes:
- Una aplicación Microsoft Entra
- Un token de acceso de Microsoft Entra
- Autenticación de dispositivos (para escenarios que no sean de producción)
- Una instancia de Azure Key Vault. Para acceder al recurso de Key Vault, instale el paquete azure-keyvault y proporcione las credenciales de aplicación.
Autenticación de aplicaciones de Microsoft Entra
La autenticación de aplicaciones de Microsoft Entra es el método de autenticación más sencillo y más común y se recomienda para el conector Spark de Kusto.
Inicie sesión en su suscripción de Azure a través de la CLI de Azure. A continuación, realice la autenticación en el explorador.
az loginElija la suscripción para hospedar la entidad de servicio. Este paso es necesario si tiene varias suscripciones.
az account set --subscription YOUR_SUBSCRIPTION_GUIDCree la entidad de servicio. En este ejemplo, la entidad de servicio se llama
my-service-principal.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}En los datos JSON devueltos, copie los valores
appId,passwordytenantpara usarlos posteriormente.{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
Ha creado una aplicación de Microsoft Entra y una entidad de servicio.
El conector de Spark usa las siguientes propiedades de la aplicación Entra para la autenticación:
| Propiedades | Cadena de opción | Descripción |
|---|---|---|
| KUSTO_AAD_APP_ID | kustoAadAppId | Identificador de la aplicación Microsoft Entra (cliente). |
| KUSTO_AAD_AUTHORITY_ID | kustoAadAuthorityID | Autoridad de autenticación de Microsoft Entra. Identificador de Microsoft Entra Directory (inquilino). Opcional: por valor predeterminado microsoft.com. Para obtener más información, consulte autoridad de Microsoft Entra. |
| KUSTO_AAD_APP_SECRET | kustoAadAppSecret | Clave de aplicación de Microsoft Entra para el cliente. |
| KUSTO_ACCESS_TOKEN | kustoAccessToken | Si ya tiene un token de acceso (accessToken) creado con acceso a Kusto, se puede usar pasándolo al conector también para la autenticación. |
Nota:
Las versiones anteriores de la API (anteriores a la versión 2.0.0) tienen la siguiente nomenclatura: "kustoAADClientID", "kustoClientAADClientPassword", "kustoAADAuthorityID"
Privilegios de Kusto
Conceda los siguientes privilegios en el lado de Kusto en función de la operación de Spark que quiera realizar.
| Operación de Spark | Privilegios |
|---|---|
| Lectura: modo único | Lector |
| Lectura: forzar modo distribuido | Lector |
| Escritura: modo en cola con la opción de creación de tabla CreateTableIfNotExist | Administración |
| Escritura: modo en cola con la opción de creación de tabla FailIfNotExist | Agente de ingesta |
| Escritura: TransactionalMode | Administración |
Para más información sobre los roles principales, véase Control de acceso basado en roles. Para administrar los roles de seguridad, consulte Administración de los roles de seguridad.
Receptor de Spark: escribir en Kusto
Configuración de los parámetros del receptor:
val KustoSparkTestAppId = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppId") val KustoSparkTestAppKey = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppKey") val appId = KustoSparkTestAppId val appKey = KustoSparkTestAppKey val authorityId = "72f988bf-86f1-41af-91ab-2d7cd011db47" // Optional - defaults to microsoft.com val cluster = "Sparktest.eastus2" val database = "TestDb" val table = "StringAndIntTable"Escriba Spark DataFrame en el clúster de Kusto como lote:
import com.microsoft.kusto.spark.datasink.KustoSinkOptions import org.apache.spark.sql.{SaveMode, SparkSession} df.write .format("com.microsoft.kusto.spark.datasource") .option(KustoSinkOptions.KUSTO_CLUSTER, cluster) .option(KustoSinkOptions.KUSTO_DATABASE, database) .option(KustoSinkOptions.KUSTO_TABLE, "Demo3_spark") .option(KustoSinkOptions.KUSTO_AAD_APP_ID, appId) .option(KustoSinkOptions.KUSTO_AAD_APP_SECRET, appKey) .option(KustoSinkOptions.KUSTO_AAD_AUTHORITY_ID, authorityId) .option(KustoSinkOptions.KUSTO_TABLE_CREATE_OPTIONS, "CreateIfNotExist") .mode(SaveMode.Append) .save()O bien, use la sintaxis simplificada:
import com.microsoft.kusto.spark.datasink.SparkIngestionProperties import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val sparkIngestionProperties = Some(new SparkIngestionProperties()) // Optional, use None if not needed df.write.kusto(cluster, database, table, conf, sparkIngestionProperties)Escriba datos de streaming:
import org.apache.spark.sql.streaming.Trigger import java.util.concurrent.TimeUnit import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.Trigger // Set up a checkpoint and disable codeGen. spark.conf.set("spark.sql.streaming.checkpointLocation", "/FileStore/temp/checkpoint") // Write to a Kusto table from a streaming source val kustoQ = df .writeStream .format("com.microsoft.kusto.spark.datasink.KustoSinkProvider") .options(conf) .trigger(Trigger.ProcessingTime(TimeUnit.SECONDS.toMillis(10))) // Sync this with the ingestionBatching policy of the database .start()
Origen de Spark: lectura de Kusto
Al leer pequeñas cantidades de datos, defina la consulta de datos:
import com.microsoft.kusto.spark.datasource.KustoSourceOptions import org.apache.spark.SparkConf import org.apache.spark.sql._ import com.microsoft.azure.kusto.data.ClientRequestProperties val query = s"$table | where (ColB % 1000 == 0) | distinct ColA" val conf: Map[String, String] = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey ) val df = spark.read.format("com.microsoft.kusto.spark.datasource"). options(conf). option(KustoSourceOptions.KUSTO_QUERY, query). option(KustoSourceOptions.KUSTO_DATABASE, database). option(KustoSourceOptions.KUSTO_CLUSTER, cluster). load() // Simplified syntax flavor import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val cpr: Option[ClientRequestProperties] = None // Optional val df2 = spark.read.kusto(cluster, database, query, conf, cpr) display(df2)Opcional: si es usted (y no Kusto) quien proporciona el almacenamiento de blobs transitorio, la responsabilidad de la creación de los blobs es del autor de la llamada. Esto incluye el aprovisionamiento del almacenamiento, la rotación de claves de acceso y la eliminación de artefactos transitorios. El módulo KustoBlobStorageUtils contiene funciones de asistente para eliminar blobs en función tanto de las coordenadas de cuenta y del contenedor como de las credenciales de cuenta, o de una dirección URL de SAS completa con permisos de escritura, lectura y lista. Cuando ya no se necesita el RDD correspondiente, cada transacción almacena artefactos de blob transitorios en un directorio independiente. Este directorio se captura como parte de los registros de información de transacciones de lectura que se notifica en el nodo del controlador de Spark.
// Use either container/account-key/account name, or container SaS val container = dbutils.secrets.get(scope = "KustoDemos", key = "blobContainer") val storageAccountKey = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountKey") val storageAccountName = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountName") // val storageSas = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageSasUrl")En el ejemplo anterior, no se accede a Key Vault mediante la interfaz del conector; se usa un método más sencillo con los secretos de Databricks.
Leer de Kusto.
Si usted proporciona el almacenamiento de blobs transitorio, leer de Kusto de la siguiente manera:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey KustoSourceOptions.KUSTO_BLOB_STORAGE_SAS_URL -> storageSas) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)Si Kusto proporciona el almacenamiento de blobs transitorios, leer de Kusto de la siguiente manera:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_CLIENT_ID -> appId, KustoSourceOptions.KUSTO_AAD_CLIENT_PASSWORD -> appKey) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)