Calculadora de precios de Azure Data Explorer
Azure Data Explorer proporciona una calculadora de precios para calcular el costo del clúster. La estimación se basa en especificaciones como la ingesta de datos estimada y la carga de trabajo del motor. A medida que realice cambios en la configuración, la estimación de precios también cambia para que pueda comprender las implicaciones de los costos de las opciones de configuración.
En este artículo se explica cada uno de los componentes de la calculadora y se proporcionan sugerencias a lo largo del proceso para ayudarle a tomar mejores decisiones sobre cómo configurar el clúster.
Funcionamiento
Establezca la región, el entorno y la ingesta de datos estimados del clúster. A continuación, la calculadora calcula un costo mensual basado en especificaciones seleccionadas automáticamente o seleccionadas manualmente en cada uno de los componentes siguientes:
- Instancias de motor
- Instancias de administración de datos
- Almacenamiento y transacciones
- Redes
- Margen de beneficio de Azure Data Explorer
En la parte inferior del formulario, las estimaciones de componentes individuales se agregan para crear una estimación mensual total. El componente calcula y la actualización total a medida que realiza cambios de configuración.
Introducción
- Vaya a la calculadora de precios.
- Desplácese hacia abajo hasta que vea una pestaña titulada Su estimación.
- Compruebe que Azure Data Explorer aparece en la pestaña . Si no es así, haga lo siguiente:
- Desplácese hacia atrás hasta la parte superior de la página.
- En el cuadro de búsqueda, escriba "Azure Data Explorer".
- Seleccione el widget azure Data Explorer .
- Inicie la configuración.
Las secciones de este artículo corresponden a los componentes de la calculadora y resaltan lo que necesita saber.
Región y entorno
La región y el entorno que elija para el clúster afectarán al costo de cada componente. Esto se debe a que las distintas regiones y entornos no proporcionan exactamente los mismos servicios o capacidad.
Seleccione la región deseada para el clúster.
Use la guía de decisión de regiones para encontrar la región adecuada. Su elección puede depender de requisitos como:
Elija el entorno del clúster.
Los clústeres de producción contienen dos o más nodos para el motor y la administración de datos y funcionan con el Acuerdo de Nivel de Servicio de Azure Data Explorer.
Los clústeres de desarrollo y pruebas son la opción de costo más bajo, lo que hace que sean excelentes para la evaluación del servicio, la realización de poC y validaciones de escenarios. Tienen un tamaño limitado y no pueden crecer más allá de un solo nodo. No hay ningún cargo de marcado de Azure Data Explorer ni acuerdo de nivel de servicio del producto para estos clústeres.
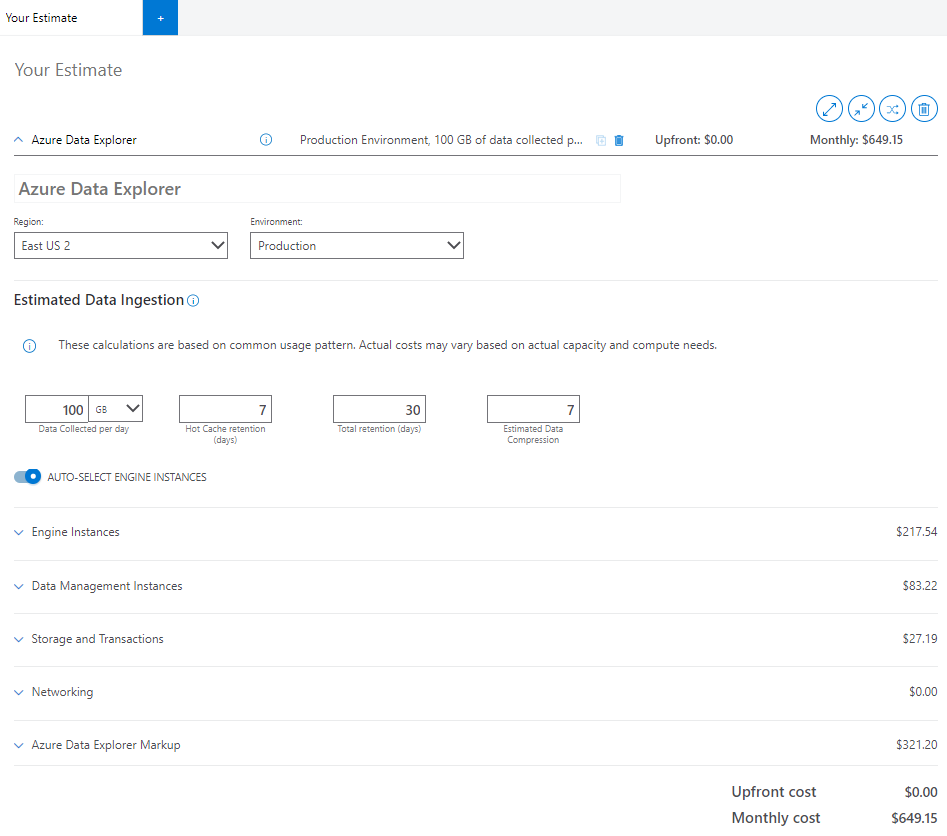
Ingesta de datos estimada
La información proporcionada en la sección Ingesta de datos estimados de la calculadora influye en el precio de todos los componentes del clúster.
En la calculadora, escriba estimaciones para los campos siguientes:
Datos recopilados por día (GB/TB): datos que planea ingerir sin compresión en el clúster de Azure Data Explorer todos los días. Calcule esta estimación en función del número de archivos y del tamaño medio de un archivo que se ingiere. Si transmite los datos mediante mensajes, revise el tamaño medio de un solo mensaje y cuántos mensajes va a ingerir.
Retención de caché activa (días): período durante el que los datos se almacenan en la memoria caché para el acceso rápido a las consultas. Datos ingeridos almacenados en caché según nuestra directiva de caché en la SSD local del servicio Motor. El requisito de rendimiento de las consultas determina la cantidad de nodos de proceso y el almacenamiento SSD local necesario.
Retención total (días): período durante el que se almacenan los datos y están disponibles para la consulta. Después de la ventana de retención, los datos se quitarán automáticamente. Elija la ventana de retención de datos en función del cumplimiento u otros requisitos normativos. Aplique la funcionalidad de ventana activa para activar los datos en función del período de tiempo para realizar consultas más rápidas.
Compresión de datos estimada: relación entre el tamaño de los datos sin comprimir y el tamaño comprimido. La compresión de datos varía en función de la cardinalidad de los valores y su estructura. Por ejemplo, los datos de registros ingeridos en columnas estructuradas tienen una compresión mayor en comparación con las columnas dinámicas o guid. Todos los datos ingeridos se comprimen de forma predeterminada.
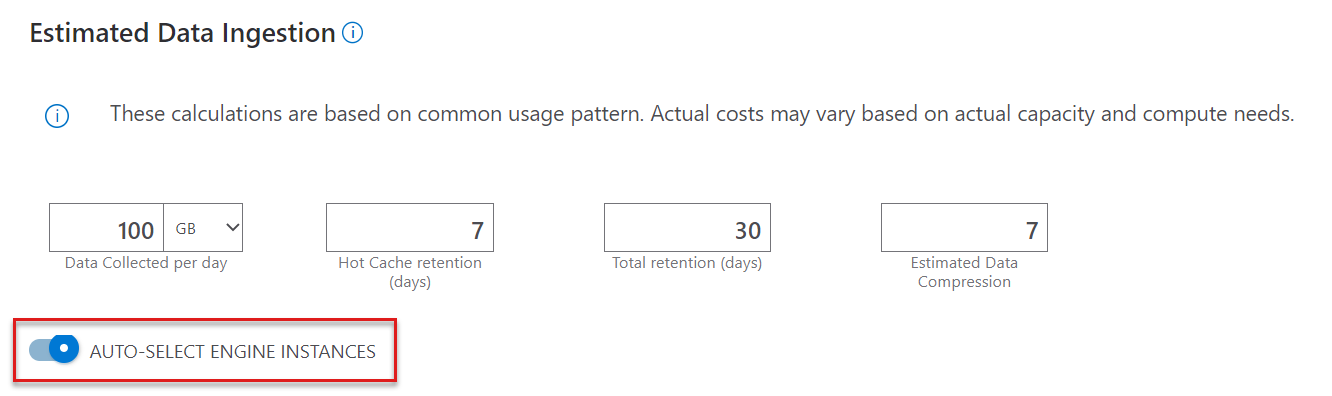
Selección automática de instancias del motor
Si desea configurar individualmente los componentes restantes, desactive LAS INSTANCIAS DEL MOTOR DE SELECCIÓN AUTOMÁTICA. Cuando se activa, la calculadora selecciona la SKU más óptima en función de las entradas de ingesta.
Instancias de motor
Las instancias del motor son responsables de indexar, almacenar en caché datos en ssd locales, premium storage como discos administrados y atender consultas. El servicio de motor requiere un mínimo de dos instancias de proceso.
Opciones de carga de trabajo
A continuación se muestran las opciones de carga de trabajo del motor:
- Todo: selecciona automáticamente la SKU óptima en función de la entrada que proporcione.
- SKU optimizadas para proceso:
- Proporciona núcleos altos a la proporción de caché activa.
- Adecuado para altas tasas de consulta
- SSD local para E/S de baja latencia
- SKU optimizadas para almacenamiento:
- Proporciona opciones de almacenamiento más grandes de 1 TB a 4 TB por nodo de motor
- Adecuado para cargas de trabajo que requieren almacenamiento en caché de grandes tamaños de datos
- En algunas SKU, el almacenamiento en disco administrado premium está conectado al nodo del motor en lugar de SSD local para el almacenamiento de datos frecuente.
Para obtener una estimación de las instancias del motor:
- Elija entre las opciones de carga de trabajo. La instancia del motor se ajustará en consecuencia. Si desactivó LAS INSTANCIAS DE MOTOR DE SELECCIÓN AUTOMÁTICA, elija la instancia de motor específica y la serie de máquinas virtuales.
- Especifique el número de horas, días o meses que desea ejecutar el motor.
- (Opcional) Seleccione un plan de opciones de ahorro.
El componente Disco administrado Premium se basa en la SKU seleccionada.
Nota:
No todas las series de máquinas virtuales se ofrecen en cada región. Si busca una SKU que no aparece en la región seleccionada, elija otra región.
Instancias de administración de datos
El servicio de administración de datos (DM) es responsable de la ingesta de datos de canalizaciones de datos administradas, como Azure Blob Storage, Event Hubs, IoT Hub y otros servicios como Azure Data Factory, Azure Stream Analytics y Kafka. El servicio requiere un mínimo de dos instancias de proceso que se configuran y administran automáticamente en función del tamaño de la instancia del motor.
Para obtener una estimación de las instancias de Administración de datos:
- Especifique el número de horas, días o meses que desea ejecutar la instancia.
- (Opcional) Seleccione un plan de opciones de ahorro.
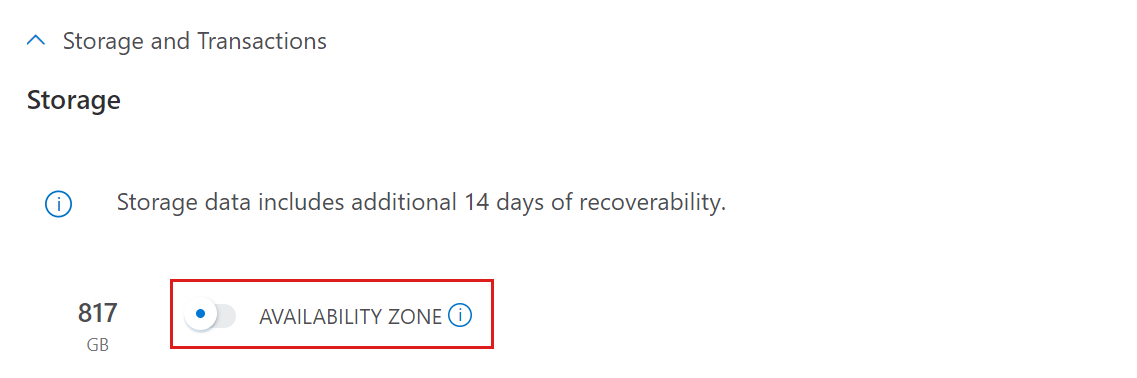
Almacenamiento y transacciones
El componente de almacenamiento es la capa persistente donde se almacenan todos los datos comprimidos y se facturan como LRS estándar o como ZRS estándar. El almacenamiento se calcula en función de la cantidad de datos recopilados, los días de retención totales y la compresión de datos estimada.
Para obtener una estimación de Storage y transacciones:
- Si necesita compatibilidad con zonas de disponibilidad, active AVAILABILITY ZONE. Cuando se activa, el almacenamiento se implementará como ZRS. De lo contrario, el almacenamiento se implementará como LRS.
Redes
Este componente se configura mediante el servicio de ancho de banda.
Para obtener una estimación del servicio de ancho de banda:
- Desplácese hasta la parte superior de la página.
- En el cuadro de búsqueda, escriba "ancho de banda".
- Seleccione el widget de producto Ancho de banda.
- Desplácese hacia abajo hasta el componente Ancho de banda de la estimación.
- Selección de un tipo de transferencia de datos
- Selección de una región de origen
- Selección de una región de destino
- Escriba la cantidad estimada de datos salientes en GB.
Nota:
Seleccione la misma región donde se generan los registros para evitar el costo entre regiones y reducir la latencia. No hay ningún costo de transferencia de datos entre los servicios de Azure implementados en la misma región.
Margen de beneficio de Azure Data Explorer
El marcado de Azure Data Explorer se cobra por la opción de soporte técnico Premium proporcionada con los clústeres de motor y ingesta de datos. Se factura en función del número de vCPU del motor en el clúster y no se cobra por los clústeres de desarrollo. Los costos cambian en función del número de horas, días o meses configurados en el componente de instancias del motor. Opcionalmente, seleccione un plan de opciones de ahorro. Para más información, consulte Precios de Azure Data Explorer: preguntas más frecuentes.
Soporte técnico
Elija un plan de soporte técnico:
Desarrollador: seleccione esta opción al configurar Azure Data Explorer en un entorno que no sea de producción o para evaluación y evaluación. Para más información, consulte la página Soporte técnico de Azure: Desarrollador .
Estándar: seleccione esta opción al configurar Azure Data Explorer cuando necesite una dependencia mínima crítica para la empresa. Para más información, consulte la página Soporte técnico de Azure: Estándar .
Professional Direct: seleccione esta opción cuando necesite un uso importante para la empresa de Azure Data Explorer. Para más información, consulte la página Soporte técnico de Azure: Professional Direct .
Qué hacer con la estimación
- Exportación de la estimación a Excel
- Guardar la estimación para referencia futura
- Compartir la estimación: se requiere el inicio de sesión