Obtener datos de Amazon S3
La ingesta de datos es el proceso que se usa para cargar datos de uno o varios orígenes en una tabla de Azure Data Explorer. Una vez que se ingieren, los datos están disponibles para su consulta. En este artículo, aprenderá a obtener datos de Amazon S3 en una tabla nueva o existente.
Para obtener más información sobre Amazon S3, consulte ¿Qué es Amazon S3?
Para obtener información general sobre la ingesta de datos, consulte Introducción a la ingesta de datos de Azure Data Explorer.
Requisitos previos
- Una cuenta de Microsoft o una identidad de usuario de Microsoft Entra. No se necesita una suscripción a Azure.
- Inicie sesión en la interfaz de usuario web de Azure Data Explorer.
- Un clúster y la base de datos de Azure Data Explorer. Cree un clúster y una base de datos.
Obtener datos
En el menú de la izquierda, seleccione Consulta.
Haga clic con el botón derecho en la base de datos donde desea ingerir los datos y, a continuación, seleccione Obtener datos.


Source
En la ventana Obtener datos, se selecciona la pestaña Origen.
Seleccione el origen de datos de la lista disponible. En este ejemplo, va a ingerir datos de Amazon S3.

Configurar
Seleccione una base de datos y una tabla de destino. Si desea ingerir datos en una nueva tabla, seleccione +Nueva tabla y escriba un nombre de tabla.
Nota:
Los nombres de tabla pueden tener hasta 1024 caracteres, entre los que se incluyen espacios, alfanuméricos, guiones y caracteres de subrayado. No se admiten caracteres especiales.
En el campo URI, pegue la cadena de conexión de un único cubo o un objeto individual en el formato siguiente.
Cubo:
https://BucketName.s3.RegionName.amazonaws.comObjeto: ObjectName
;AwsCredentials=AwsAccessID,AwsSecretKeyOpcionalmente, puede aplicar filtros de cubo para filtrar datos según una extensión de archivo específica.

Nota:
La ingesta admite un tamaño de archivo máximo de 6 GB. Se recomienda ingerir archivos de entre 100 MB y 1 GB.
Seleccione Siguiente.

Inspeccionar
La pestaña inspeccionar se abre con una vista previa de los datos.
Para completar el proceso de ingesta, seleccione Finalizar.

Opcionalmente:
- Seleccione Visor de comandos para ver y copiar los comandos automáticos generados a partir de los valores que haya introducido.
- Use la lista desplegable Archivo de definición de esquema para cambiar el archivo del que se deduce el esquema.
- Cambie el formato de datos inferido automáticamente seleccionando el formato deseado en la lista desplegable. Consulte Formatos de datos compatibles con Azure Data Explorer para la ingesta.
- Editar columnas.
- Explore las Opciones avanzadas basadas en el tipo de datos.
Editar columnas
Nota:
- En el caso de formatos tabulares (CSV, TSV, PSV), no se puede asignar una columna dos veces. Para asignar a una columna existente, elimine primero la nueva columna.
- No se puede cambiar un tipo de columna existente. Si intenta asignar a una columna con un formato diferente, puede acabar con columnas vacías.
Los cambios que pueda realizar a una tabla dependerán de los siguientes parámetros:
- El tipo de tabla es nuevo o existente
- El tipo de asignación es nuevo o existente
| Tipo de tabla. | Tipo de asignación | Ajustes disponibles |
|---|---|---|
| Tabla nueva | Asignación nueva | Cambio del nombre de columna, cambio del tipo de datos, cambio del origen de datos, la asignación de transformaciones, adición de columna, eliminación de columna |
| Tabla existente | Asignación nueva | Adición de columna (en la que puede cambiar el tipo de datos, cambiar el nombre y actualizar) |
| Tabla existente | Asignación existente | None |

Asignación de transformaciones
Algunas de las asignaciones de formato de datos (Parquet, JSON y Avro) admiten transformaciones sencillas en el momento de la ingesta. Para aplicar la asignación de transformaciones, cree o actualice una columna en la ventana Editar columnas.
La asignación de transformaciones se puede realizar en una columna de tipo string o datetime y un origen con un tipo de datos int o long. Las asignaciones de transformaciones que se admiten son:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Opciones avanzadas basadas en el tipo de datos
Tabular (CSV, TSV, PSV):
Si va a ingerir formatos tabulares en una tabla existente, puede seleccionar Advanced Keep current table schema (Mantener el esquema de tabla actual).> Los datos tabulares no incluyen necesariamente los nombres de columna que se usan para asignar datos de origen a las columnas existentes. Cuando se activa esta opción, la asignación se realiza por orden y el esquema de tabla es el mismo. Si esta opción está desactivada, se crean nuevas columnas para los datos entrantes, independientemente de la estructura de datos.
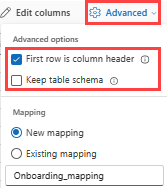
Para usar la primera fila como nombres de columna, seleccione Opciones avanzadas>La primera fila es el encabezado de la columna.
JSON:
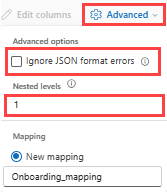
Para determinar la división de columnas de datos JSON, seleccione Opciones avanzadas>Niveles anidados, de 1 a 100.
Si selecciona Advanced Ignore data format errors (Omitir errores de formato de datos avanzados>), los datos se ingieren en formato JSON. Si no selecciona esta casilla, los datos se ingieren en formato de JSON múltiple.
Resumen
En la ventana Preparación de datos, los tres pasos se marcan con marcas de verificación verdes cuando la ingesta de datos se haya completado correctamente. Puede ver los comandos que se usaron para cada paso o seleccionar una tarjeta para consultar, visualizar o quitar los datos ingeridos.
