Uso de la actividad de comandos de Azure Data Factory para ejecutar comandos de administración de Azure Data Explorer
Azure Data Factory (ADF) es un servicio de integración de datos basado en la nube que le permite realizar una combinación de actividades sobre los datos. Use ADF para crear flujos trabajo controlados por datos y así orquestar y automatizar el movimiento y la transformación de los datos. La actividad Comando de Azure Data Explorer en Azure Data Factory permite ejecutar comandos de administración de Azure Data Explorer dentro de un flujo de trabajo de ADF. En este artículo se enseña cómo crear una canalización con una actividad de búsqueda y una actividad ForEach que contiene una actividad de comando de Azure Data Explorer.
Requisitos previos
- Suscripción a Azure. Cree una cuenta de Azure gratuita.
- Un clúster y la base de datos de Azure Data Explorer. Cree un clúster y una base de datos.
- Un origen de datos.
- Una factoría de datos. Debe crear una factoría de datos.
Creación de una canalización
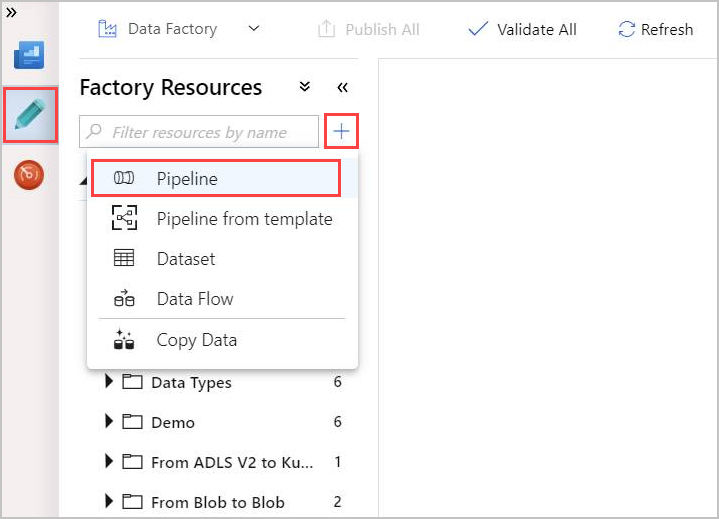
Seleccione la herramienta de lápiz Autor.
Para crear una canalización, seleccione + y, luego, Canalización en la lista desplegable.
Creación de una actividad de búsqueda
La actividad de búsqueda puede recuperar un conjunto de datos de cualquiera de los orígenes de datos compatibles con Azure Data Factory. La salida de la actividad de búsqueda se puede usar en una instrucción ForEach u otra actividad.
En el panel Actividades, en General, seleccione la actividad Búsqueda. Arrástrela y colóquela en el lienzo principal de la derecha.
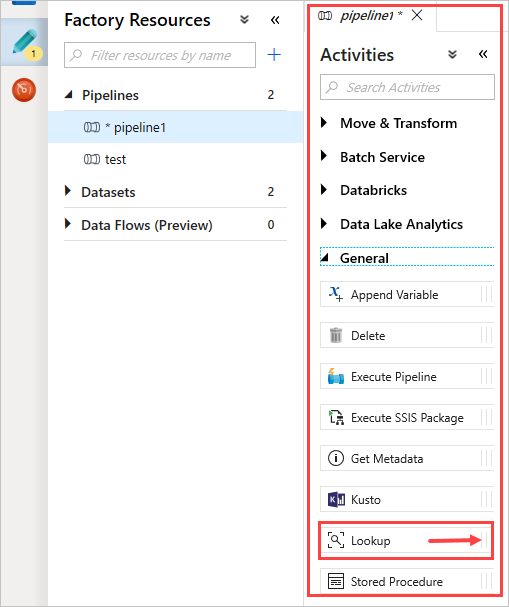
Ahora, el lienzo contiene la actividad de búsqueda que creó. Use las pestañas situadas debajo del lienzo para cambiar los parámetros pertinentes. En General, cambie el nombre de la actividad.
Sugerencia
Haga clic en el área del lienzo vacía para ver las propiedades de la canalización. Use la pestaña General para cambiar el nombre de la canalización. Nuestra canalización se denomina pipeline-4-docs.
Creación de un conjunto de datos de Azure Data Explorer en la actividad de búsqueda
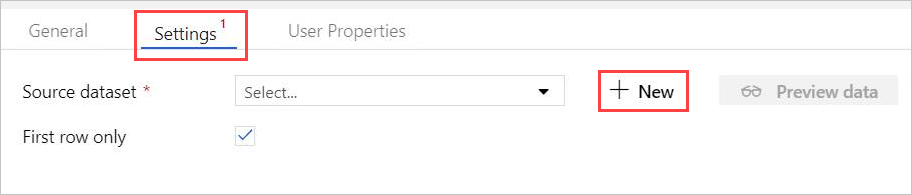
En Settings (Configuración), seleccione el conjunto de datos de Azure Data Explorer creado previamente o seleccione + New (+ Nuevo) para crear un conjunto de datos.
Seleccione el conjunto de datos Azure Data Explorer (Kusto) en la ventana New Dataset (Nuevo conjunto de datos). Seleccione Continue (Continuar) para agregar el nuevo conjunto de datos.
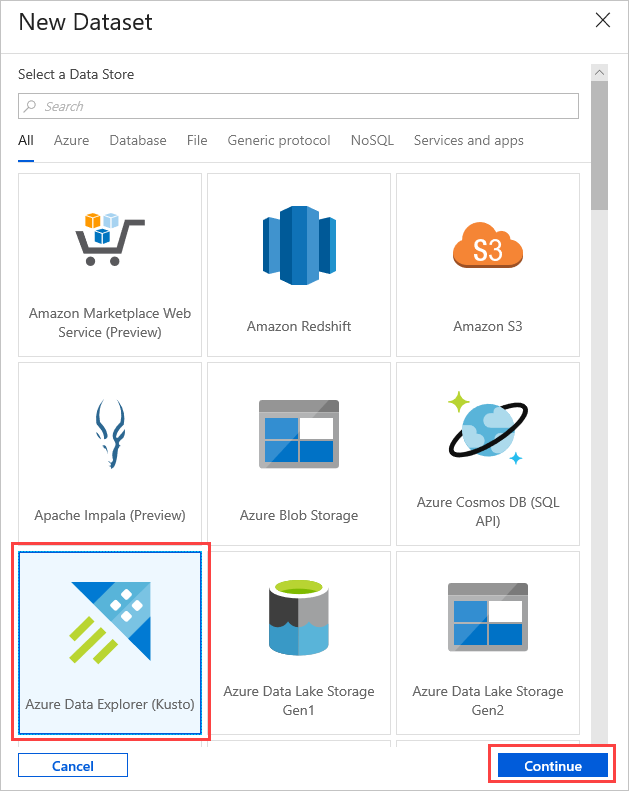
Los nuevos parámetros del conjunto de datos de Azure Data Explorer son visibles en Settings (Configuración). Para actualizar los parámetros, seleccione Edit (Editar).
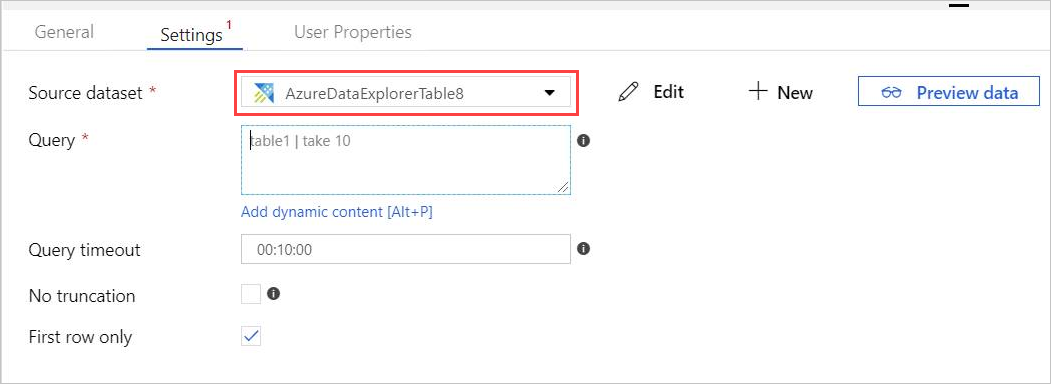
Se abrirá la nueva pestaña AzureDataExplorerTable en el lienzo principal.
- Seleccione General y edite el nombre del conjunto de datos.
- Seleccione Connection (Conexión) para editar las propiedades del conjunto de datos.
- Seleccione Linked service (Servicio vinculado) en la lista desplegable o seleccione + New (+ Nuevo) para crear un servicio vinculado.
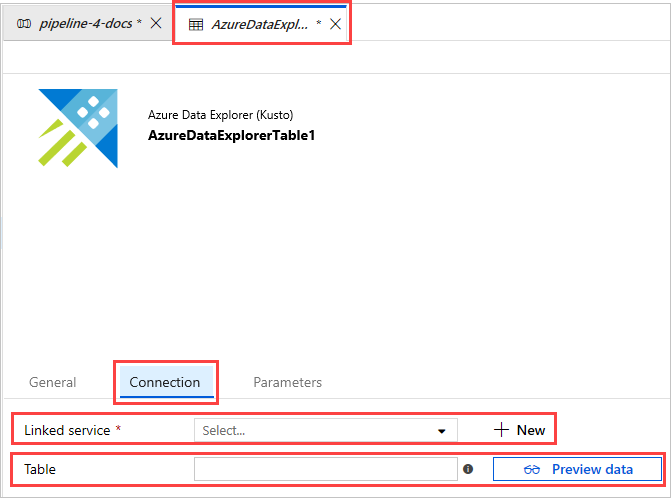
Al crear un servicio vinculado, se abre la página New Linked Service (Azure Data Explorer) (Nuevo servicio vinculado [Azure Data Explorer]):
- Seleccione Nombre para el servicio vinculado de Azure Data Explorer. En Description (Descripción), agregue una descripción si es necesario.
- En Connect via integration runtime (Conectar mediante el entorno de ejecución de integración), cambie la configuración actual, si es necesario.
- En Método de selección de cuenta, seleccione el clúster con uno de los dos métodos:
- Seleccione el botón de radio Desde suscripción de Azure y seleccione su cuenta de suscripción de Azure. A continuación, seleccione el clúster. Tenga en cuenta que la lista desplegable mostrará solo los clústeres que pertenecen al usuario.
- También puede seleccionar el botón de radio de Enter manually (Escribir manualmente) y especifique su punto de conexión (dirección URL del clúster).
- Especifique el inquilino.
- Escriba el Id. de entidad de servicio. Este valor se puede encontrar en Azure Portal en App Registrations Overview Application (client) ID (Id. de aplicación de información general>de registros>de aplicaciones [cliente]). La entidad de seguridad debe tener los permisos adecuados, según el nivel de permiso requerido por el comando que se está usando.
- Seleccione el botón Clave de entidad de servicio y especifique Clave de entidad de servicio.
- Seleccione la base de datos en el menú desplegable. También puede activar la casilla Editar y especificar el nombre de su base de datos.
- Seleccione Probar conexión para probar la conexión de servicio vinculado que creó. Si puede conectarse a la configuración, aparecerá una marca verde de conexión correcta.
- Seleccione Finalizar para completar la creación del servicio vinculado.
Cuando haya configurado un servicio vinculado, en AzureDataExplorerTable>Connection (Conexión), agregue el nombre Table (Tabla). Seleccione Preview data (Vista previa de datos), para asegurarse de que los datos se presentan correctamente.
El conjunto de datos ya está listo y puede seguir editando la canalización.
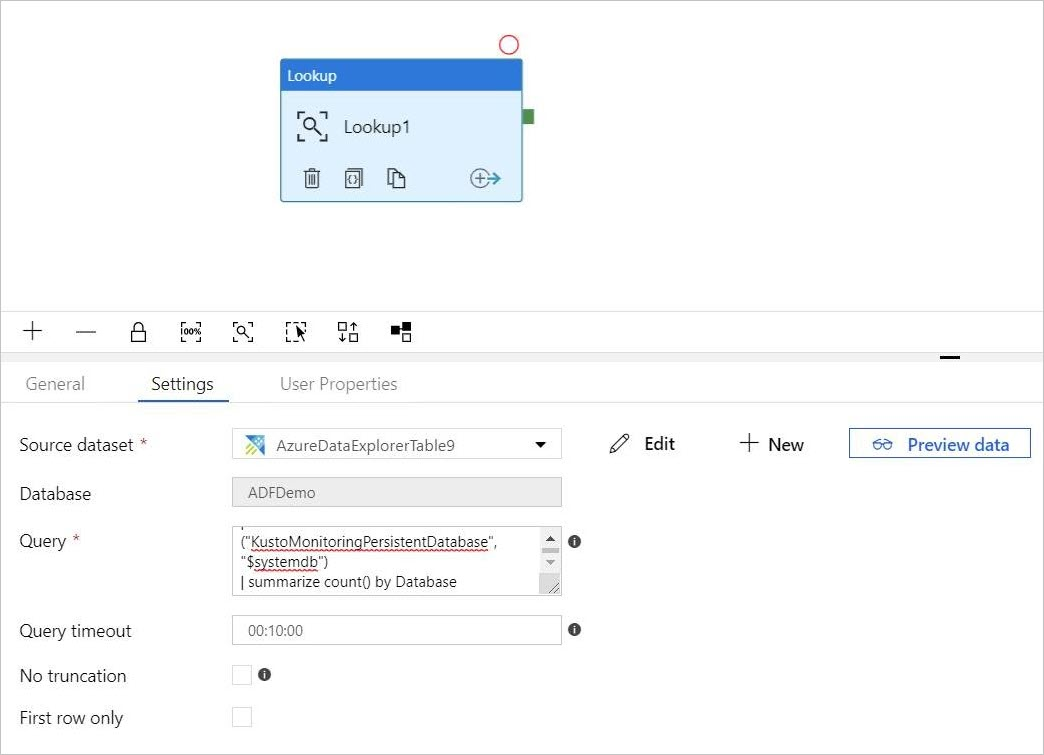
Adición de una consulta a la actividad de búsqueda
En pipeline-4-docs>Settings (Configuración), agregue una consulta en el cuadro de texto Query (Consulta), por ejemplo:
ClusterQueries | where Database !in ("KustoMonitoringPersistentDatabase", "$systemdb") | summarize count() by DatabaseCambie las propiedades Query timeout (Tiempo de espera de consulta), No truncation (Sin truncamiento) y First row only (Solo la primera fila), según sea necesario. En este flujo, se mantiene el valor predeterminado de Query timeout (Tiempo de espera de la consulta) y se desactivan las casillas.
Creación de una actividad ForEach
La actividad For-Each se usa para iterar una colección y ejecuta las actividades especificadas en un bucle.
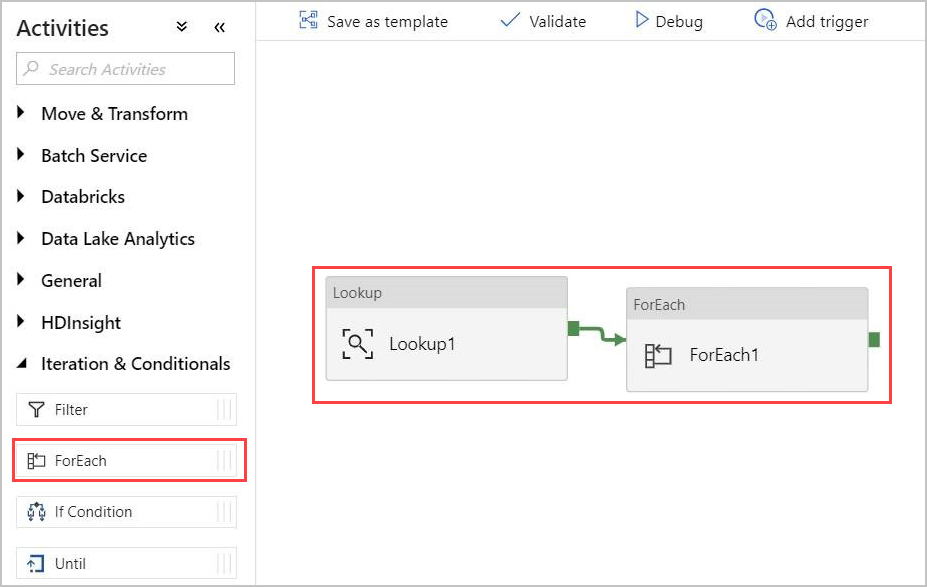
A continuación, agregará una actividad For-Each a la canalización. Esta actividad procesará los datos devueltos por la actividad de búsqueda.
En el panel Activities (Actividades), en Iteration & Conditionals (Iteración y condicionales), seleccione la actividad ForEach y arrástrela y suéltela en el lienzo.
Dibuje una línea entre la salida de la actividad de búsqueda y la entrada de la actividad ForEach en el lienzo para conectarlas.
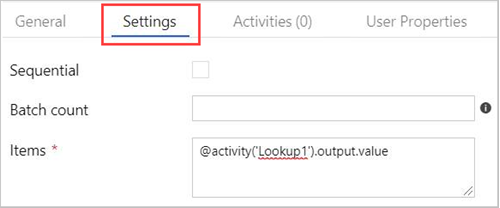
Seleccione la actividad ForEach en el lienzo. En la pestaña Settings (Configuración):
Active la casilla Sequential (Secuencial) para el procesamiento secuencial de los resultados de búsqueda, o déjela desactivada para crear procesamiento paralelo.
Establezca el valor de Batch count (Número de lotes).
En Items (Elementos), proporcione la siguiente referencia al valor de salida: @activity('Lookup1').output.value.
Creación de una actividad de comando de Azure Data Explorer dentro de la actividad ForEach
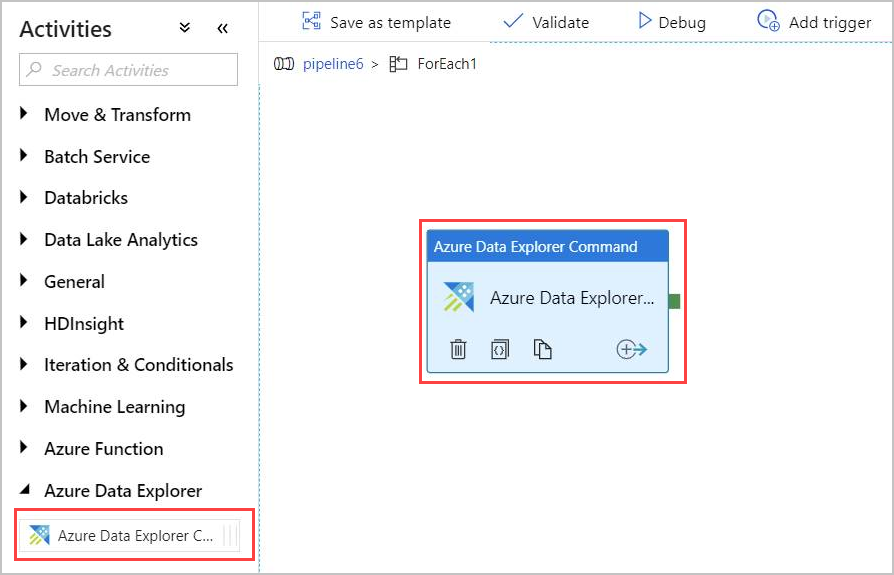
Haga doble clic en la actividad ForEach en el lienzo para abrirla en un nuevo lienzo y especificar las actividades dentro de ForEach.
En el panel Activities (Actividades), en Azure Data Explorer, seleccione la actividad Azure Data Explorer Command (Comando de Azure Data Explorer) y arrástrela y suéltela en el lienzo.
En la pestaña Connection (Conexión), seleccione el mismo servicio vinculado creado anteriormente.
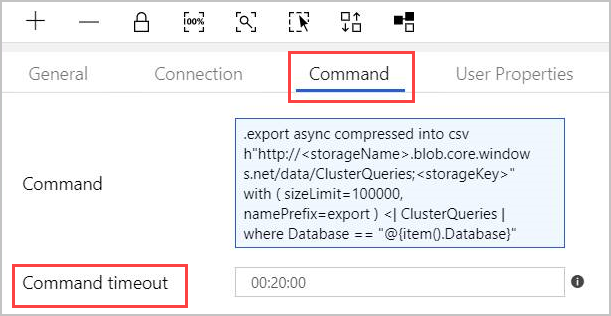
En la pestaña Command (Comando), proporcione el siguiente comando:
.export async compressed into csv h"http://<storageName>.blob.core.windows.net/data/ClusterQueries;<storageKey>" with ( sizeLimit=100000, namePrefix=export ) <| ClusterQueries | where Database == "@{item().Database}"El comando indica a Azure Data Explorer que exporte los resultados de una consulta dada a Blob Storage, en formato comprimido. Se ejecuta de forma asincrónica (mediante el modificador async). La consulta dirige la columna de base de datos de cada fila en el resultado de la actividad de búsqueda. El tiempo de espera del comando se puede dejar como está.
Nota:
La actividad de comando tiene los siguientes límites:
- Límite de tamaño: tamaño de respuesta de 1 MB
- Límite de tiempo: 20 minutos (valor predeterminado), 1 hora (máximo).
- Si es necesario, puede anexar una consulta al resultado mediante AdminThenQuery para reducir el tamaño y la hora resultantes.
Ahora la canalización está lista. Para volver a la vista de canalización principal, haga clic en el nombre de la canalización.

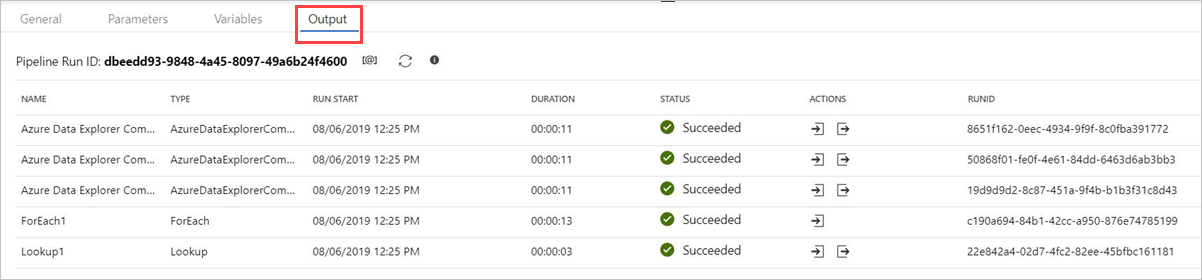
Seleccione Debug (Depurar) antes de publicar la canalización. El progreso de la canalización se puede supervisar en la pestaña Output (Salida).
Puede usar las opciones Publish All (Publicar todo) y, luego, Add trigger (Agregar desencadenador) para ejecutar la canalización.
Salidas del comando de administración
A continuación se detalla la estructura de la salida de la actividad de comando. Esta salida se puede usar con la siguiente actividad de la canalización.
Valor devuelto de un comando de administración no asincrónico
En un comando de administración no asincrónico, la estructura del valor devuelto es similar a la estructura del resultado de la actividad Lookup. El campo count indica el número de registros devueltos. Un campo de matriz fijo value contiene una lista de registros.
{
"count": "2",
"value": [
{
"ExtentId": "1b9977fe-e6cf-4cda-84f3-4a7c61f28ecd",
"ExtentSize": 1214.0,
"CompressedSize": 520.0
},
{
"ExtentId": "b897f5a3-62b0-441d-95ca-bf7a88952974",
"ExtentSize": 1114.0,
"CompressedSize": 504.0
}
]
}
Valor devuelto de un comando de administración asincrónica
En un comando de administración asincrónica, la actividad sondea la tabla de operaciones en segundo plano, hasta que la operación asincrónica se completa o agota el tiempo de espera. Por lo tanto, el valor devuelto contendrá el resultado de .show operations OperationId para esa propiedad OperationId dada. Compruebe los valores de las propiedades de estado para comprobar que la operación se ha realizado correctamente.
{
"count": "1",
"value": [
{
"OperationId": "910deeae-dd79-44a4-a3a2-087a90d4bb42",
"Operation": "TableSetOrAppend",
"NodeId": "",
"StartedOn": "2019-06-23T10:12:44.0371419Z",
"LastUpdatedOn": "2019-06-23T10:12:46.7871468Z",
"Duration": "00:00:02.7500049",
"State": "Completed",
"Status": "",
"RootActivityId": "f7c5aaaf-197b-4593-8ba0-e864c94c3c6f",
"ShouldRetry": false,
"Database": "MyDatabase",
"Principal": "<some principal id>",
"User": "<some User id>"
}
]
}