Modelado de datos en Azure Cosmos DB
SE APLICA A: ![]() NoSQL
NoSQL
Mientras que las bases de datos sin esquemas, como Azure Cosmos DB, facilitan notablemente almacenar y consultar datos no estructurados y semiestructurados, debe dedicar algún tiempo a reflexionar sobre qué modelos de datos usar para sacar el máximo partido al servicio en cuanto a rendimiento, escalabilidad y menor costo.
¿Cómo se van a almacenar los datos? ¿Cómo la aplicación va a recuperar y consultar los datos? ¿La aplicación realiza muchas operaciones de lectura o escritura?
Después de leer este artículo, podrá responder a las preguntas siguientes:
- ¿Qué es el modelado de datos y por qué tendría que importarme?
- ¿Por qué es el modelado de datos en Azure Cosmos DB distinto a en una base de datos relacional?
- ¿Cómo expreso relaciones de datos en una base de datos no relacional?
- ¿Cuándo se incrustan datos y cuándo realizo vinculaciones a los datos?
Números en el lenguaje JSON
Azure Cosmos DB guarda los documentos en formato JSON. Por este motivo, es necesario determinar cuidadosamente si los números deben o no deben convertirse en cadenas antes de almacenarlos en formato JSON. Preferiblemente, todos los números deben convertirse en String si existe cualquier posibilidad de que estos no respeten los límites de los números de doble precisión según IEEE 754 binary64. La especificación JSON señala las razones por las que utilizar números que no respeten este límite constituye un procedimiento generalmente incorrecto con JSON, ya que esto puede desencadenar en probables problemas de interoperabilidad. Estos problemas son especialmente pertinentes para la columna de clave de partición, ya que es inmutable y requiere la migración de datos para cambiarla más adelante.
Inserción de datos
Al comenzar a modelar datos en Azure Cosmos DB, intente tratar las entidades como elementos independientes representados como documentos JSON.
Para la comparación, veamos primero cómo podríamos modelar datos en una base de datos relacional. En el ejemplo siguiente se muestra puede almacenarse una persona en una base de datos relacional.
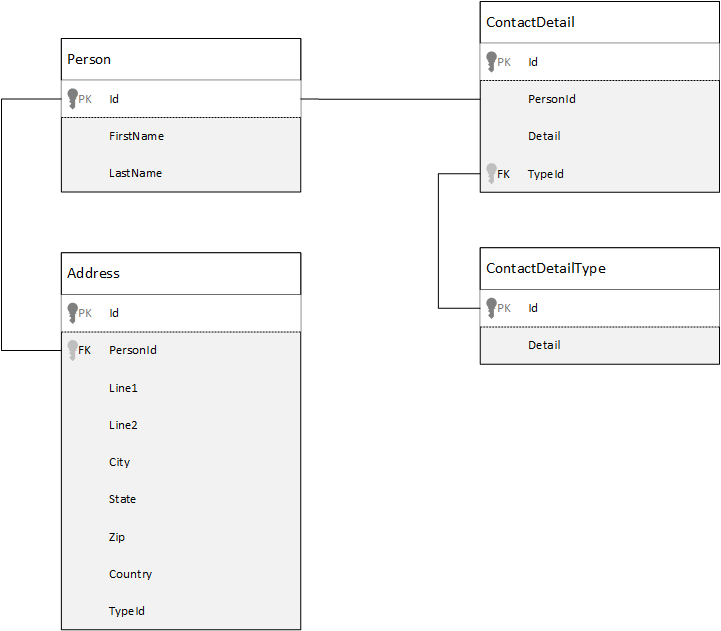
Cuando se trabaja con bases de datos relacionales, la estrategia es normalizar todos los datos. La normalización de los datos implica normalmente tomar una entidad, como una persona, y dividirla en componentes discretos. En el ejemplo anterior, una persona puede tener varios registros de información de contacto, así como varios registros de dirección. Los detalles de contacto pueden desglosarse más si se extraen todavía más campos comunes, como un tipo. Lo mismo se aplica a la dirección, cada registro puede ser de tipo Home o Business.
La premisa principal cuando se normalizan datos es la de evitar el almacenamiento de datos redundantes en cada registro y, en su lugar, hacer referencia a los datos. En este ejemplo, para leer a una persona, con toda su información de contacto y direcciones, tendrá que usar CONEXIONES para volver a componer (o desnormalizar) de forma eficaz los datos en tiempo de ejecución.
SELECT p.FirstName, p.LastName, a.City, cd.Detail
FROM Person p
JOIN ContactDetail cd ON cd.PersonId = p.Id
JOIN ContactDetailType cdt ON cdt.Id = cd.TypeId
JOIN Address a ON a.PersonId = p.Id
Se necesitan operaciones de escritura en muchas tablas individuales para actualizar los detalles y las direcciones de contacto de una sola persona.
Ahora veamos cómo modelamos los mismos datos como una entidad independiente en Azure Cosmos DB.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"addresses": [
{
"line1": "100 Some Street",
"line2": "Unit 1",
"city": "Seattle",
"state": "WA",
"zip": 98012
}
],
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555", "extension": 5555}
]
}
Mediante este enfoque, hemos desnormalizado el registro de la persona insertando toda la información relacionada con ella, como su información de contacto y direcciones, en un documento único JSON. Además, puesto que no estamos limitados a un esquema fijo, contamos con la flexibilidad para hacer cosas como tener información de contacto de formas diferentes por completo.
Recuperar un registro de persona completa de la base de datos es ahora una única operación de lectura frente a un contenedor único y para un elemento único. La actualización de los datos de contacto y las direcciones del registro de una persona es también una operación de escritura única en un elemento único.
Mediante la desnormalización de datos, es posible que la aplicación tenga que emitir menos consultas y actualizaciones para completar operaciones comunes.
Cuándo se debe realizar la incrustación
Por lo general, use los modelos de datos de incrustación cuando:
- Existen relaciones contenidas entre entidades.
- Existen relaciones de uno a algunos entre entidades.
- Existen datos incrustados que cambian con poca frecuencia.
- Existen datos insertados que no crecerán sin límites.
- Hay datos incrustados que se consultan con frecuencia juntos.
Nota
Los modelos de datos desnormalizados normalmente proporcionan un mejor rendimiento de lectura .
Cuándo no se debe incrustar
Puesto que la regla general en Azure Cosmos DB es desnormalizarlo todo e incrustar todos los datos en un único elemento, es posible que se produzcan situaciones que se deben evitar.
Seleccione este fragmento JSON.
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"comments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
…
{"id": 100001, "author": "jane", "comment": "and on we go ..."},
…
{"id": 1000000001, "author": "angry", "comment": "blah angry blah angry"},
…
{"id": ∞ + 1, "author": "bored", "comment": "oh man, will this ever end?"},
]
}
Este podría el aspecto de una entidad de publicación con comentarios incrustados si se ha modelado un sistema, CMS o blog normales. El problema con este ejemplo es que la matriz de comentarios no está limitada, lo que significa que no hay ningún límite (práctico) para el número de comentarios que puede tener cualquier publicación única. Esto puede constituir un problema, ya que el tamaño del elemento podría crecer hasta el infinito, por lo que es un diseño que debería evitar.
Puesto que el tamaño del elemento aumenta la capacidad de transmisión de los datos a través de la conexión, así como la lectura y actualización del elemento, a gran escala, se verán afectados.
En este caso sería mejor tener en cuenta el siguiente modelo de datos.
Post item:
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"recentComments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
{"id": 3, "author": "jane", "comment": "....."}
]
}
Comment items:
[
{"id": 4, "postId": "1", "author": "anon", "comment": "more goodness"},
{"id": 5, "postId": "1", "author": "bob", "comment": "tails from the field"},
...
{"id": 99, "postId": "1", "author": "angry", "comment": "blah angry blah angry"},
{"id": 100, "postId": "2", "author": "anon", "comment": "yet more"},
...
{"id": 199, "postId": "2", "author": "bored", "comment": "will this ever end?"}
]
Este modelo cuenta con un documento para cada comentario con una propiedad que contiene el identificador de la publicación. Así, las publicaciones pueden contener cualquier cantidad de comentarios y aumentar de manera eficiente. Los usuarios que quieran ver algo más que los comentarios más recientes deberán consultar este contenedor pasando el valor de postId, que debería ser la clave de partición del contenedor de comentarios.
Otro caso en el que la incrustación de datos no es una buena opción es cuando los datos incrustados se utilizan a menudo en elementos y cambian con frecuencia.
Seleccione este fragmento JSON.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{
"numberHeld": 100,
"stock": { "symbol": "zbzb", "open": 1, "high": 2, "low": 0.5 }
},
{
"numberHeld": 50,
"stock": { "symbol": "xcxc", "open": 89, "high": 93.24, "low": 88.87 }
}
]
}
Esto podría representar la cartera de acciones de una persona. Hemos elegido insertar la información de las acciones en cada documento de la cartera. En un entorno donde los datos relacionados cambian con frecuencia, como una aplicación de comercio bursátil, la incrustación de datos que cambian con frecuencia significará que está actualizando constantemente cada documento de la cartera cada vez que se negocia una acción.
Es posible negociar con la acción zbzb cientos de veces en un solo día y miles de usuarios pueden tener zbzb en su cartera. Con un modelo de datos como el del ejemplo, tendríamos que actualizar miles de documentos de cartera varias veces al día, por lo que daría lugar a un escalado del sistema nada bueno.
Datos de referencia
La incrustación de datos funciona bien en muchos casos, pero hay escenarios en los que la desnormalización de los datos provoca más problemas que ventajas. ¿Qué hacemos ahora?
Las bases de datos relacionales no son el único lugar donde puede crear relaciones entre entidades. En una base de datos de documentos, puede tener información en un documento que se relacione con los datos en otros documentos. No se recomienda crear sistemas que podrían ser más adecuados para una base de datos relacional en Azure Cosmos DB o cualquier otra base de datos de documentos, ya que las relaciones simples son correctas y pueden ser útiles.
En el JSON hemos optado por utilizar el ejemplo de una cartera de acciones anteriores, pero esta vez hacemos referencia al artículo en existencias en la cartera en lugar de incrustarlo. De esa forma, cuando el artículo comercial cambia frecuentemente a lo largo del día, el único documento que tiene que actualizarse es el documento de acciones único.
Person document:
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{ "numberHeld": 100, "stockId": 1},
{ "numberHeld": 50, "stockId": 2}
]
}
Stock documents:
{
"id": "1",
"symbol": "zbzb",
"open": 1,
"high": 2,
"low": 0.5,
"vol": 11970000,
"mkt-cap": 42000000,
"pe": 5.89
},
{
"id": "2",
"symbol": "xcxc",
"open": 89,
"high": 93.24,
"low": 88.87,
"vol": 2970200,
"mkt-cap": 1005000,
"pe": 75.82
}
Sin embargo, una desventaja de este enfoque inmediato es si la aplicación es necesaria para mostrar información sobre cada acción que se mantiene al mostrar la cartera de una persona; en este caso necesitaría realizar varios viajes a la base de datos para cargar la información de cada documento de acciones. Aquí hemos tomado una decisión de mejorar la eficacia de las operaciones de escritura, que se producen con frecuencia a lo largo del día, pero a su vez, se comprometen las operaciones de lectura que potencialmente tienen un menor impacto en el rendimiento de este sistema en particular.
Nota
Los modelos de datos normalizados pueden requerir varios viajes de ida y vuelta al servidor.
¿Qué sucede con las claves externas?
Puesto que actualmente no hay ningún concepto de restricción, clave externa o de otra índole, las relaciones entre documentos que tienen en los documentos son efectivamente "puntos débiles" y la base de datos no los comprobará. Si desea asegurarse de que los datos a los que hace referencia un documento existen realmente, debe hacerlo en la aplicación o mediante desencadenadores de servidor o procedimientos almacenados en Azure Cosmos DB.
Cuándo se debe establecer referencias
Por lo general, se deben utilizar modelos de datos normalizados cuando:
- Se realiza una representación de relaciones de uno a varios .
- Se realiza una representación de las relaciones de muchos a muchos .
- Los datos relacionados cambian con frecuencia.
- Puede cancelarse el límitede los datos de referencia.
Nota
Normalmente, la normalización proporciona un mejor rendimiento de escritura .
¿Dónde coloco la relación?
El crecimiento de la relación ayuda a determinar en qué documento almacenar la referencia.
Si observamos el JSON que sirve como modelo para los editores y los libros.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press",
"books": [ 1, 2, 3, ..., 100, ..., 1000]
}
Book documents:
{"id": "1", "name": "Azure Cosmos DB 101" }
{"id": "2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "3", "name": "Taking over the world one JSON doc at a time" }
...
{"id": "100", "name": "Learn about Azure Cosmos DB" }
...
{"id": "1000", "name": "Deep Dive into Azure Cosmos DB" }
Si el número de libros por publicador es reducido con un crecimiento limitado, almacenar la referencia del libro dentro del documento del editor puede ser útil. Sin embargo, si el número de libros por editor no tiene un límite, este modelo de datos provocaría matrices crecientes y mutables como ocurre en el documento de editor del ejemplo.
Cambiar las cosas un poco provocaría la creación de un modelo que seguiría representando los mismos datos, pero que evitaría esas grandes colecciones mutables.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press"
}
Book documents:
{"id": "1","name": "Azure Cosmos DB 101", "pub-id": "mspress"}
{"id": "2","name": "Azure Cosmos DB for RDBMS Users", "pub-id": "mspress"}
{"id": "3","name": "Taking over the world one JSON doc at a time", "pub-id": "mspress"}
...
{"id": "100","name": "Learn about Azure Cosmos DB", "pub-id": "mspress"}
...
{"id": "1000","name": "Deep Dive into Azure Cosmos DB", "pub-id": "mspress"}
En este ejemplo, hemos eliminado la colección ilimitada en el documento del editor. En su lugar, solo tenemos una referencia al publicador en cada documento del libro.
Cómo modelar relaciones de varios a varios
En una base de datos relacional, las relaciones varios a varios se modelan con frecuencia con tablas de unión, que simplemente unen registros de otras tablas.
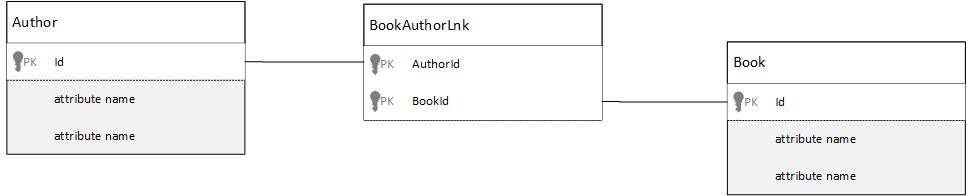
Podría verse tentado a replicar lo mismo con documentos y producir un modelo de datos que tenga un aspecto similar al siguiente.
Author documents:
{"id": "a1", "name": "Thomas Andersen" }
{"id": "a2", "name": "William Wakefield" }
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101" }
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "b3", "name": "Taking over the world one JSON doc at a time" }
{"id": "b4", "name": "Learn about Azure Cosmos DB" }
{"id": "b5", "name": "Deep Dive into Azure Cosmos DB" }
Joining documents:
{"authorId": "a1", "bookId": "b1" }
{"authorId": "a2", "bookId": "b1" }
{"authorId": "a1", "bookId": "b2" }
{"authorId": "a1", "bookId": "b3" }
Esto funcionaría. Sin embargo, cargar un autor con sus libros o cargar un libro con su autor siempre requeriría al menos dos consultas adicionales en la base de datos. Una consulta para el documento de unión y, a continuación, otra consulta para capturar el documento real que se está uniendo.
Si esta combinación lo único que hace es pegar entre sí dos datos, ¿por qué no quitarla completamente? Tenga en cuenta el siguiente ejemplo.
Author documents:
{"id": "a1", "name": "Thomas Andersen", "books": ["b1", "b2", "b3"]}
{"id": "a2", "name": "William Wakefield", "books": ["b1", "b4"]}
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101", "authors": ["a1", "a2"]}
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users", "authors": ["a1"]}
{"id": "b3", "name": "Learn about Azure Cosmos DB", "authors": ["a1"]}
{"id": "b4", "name": "Deep Dive into Azure Cosmos DB", "authors": ["a2"]}
Ahora, si tuviera un autor, sabría de inmediato qué libros ha escrito y, a la inversa, si tuviera un documento del libro cargado sabría los identificadores de los autores. Esto ahorra la consulta intermedia de la tabla de unión, por lo que se reduce el número de viajes de ida y vuelta al servidor que tiene que realizar la aplicación.
Modelos de datos híbridos
Ahora se ha visto cómo insertar datos (desnormalizar) y hacer referencia a ellos (normalizar). Cada enfoque tiene sus inconvenientes y riesgos.
No siempre tiene que ser lo uno o lo otro, no tenga miedo de mezclar un poco las cosas.
En función de las cargas de trabajo y los diseños de uso específico de la aplicación, es posible que existan casos en los que mezclar los datos de referencia e incrustados tenga sentido y puede generar una lógica de aplicación más simple con menos viajes de ida y vuelta de servidor a la vez que se sigue manteniendo un buen nivel de rendimiento.
Considere el siguiente JSON.
Author documents:
{
"id": "a1",
"firstName": "Thomas",
"lastName": "Andersen",
"countOfBooks": 3,
"books": ["b1", "b2", "b3"],
"images": [
{"thumbnail": "https://....png"}
{"profile": "https://....png"}
{"large": "https://....png"}
]
},
{
"id": "a2",
"firstName": "William",
"lastName": "Wakefield",
"countOfBooks": 1,
"books": ["b1"],
"images": [
{"thumbnail": "https://....png"}
]
}
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
{"id": "a2", "name": "William Wakefield", "thumbnailUrl": "https://....png"}
]
},
{
"id": "b2",
"name": "Azure Cosmos DB for RDBMS Users",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
]
}
Aquí hemos seguido principalmente el modelo de incrustación, donde los datos de otras entidades se incrustan en el documento de nivel superior, pero se establece la referencia en otros datos.
Si observa el documento del libro, podemos ver algunos campos interesantes cuando nos centramos en la matriz de autores. Hay un campo id que es el campo que se usa para volver a hacer referencia a un documento de autor, una práctica estándar en un modelo normalizado, pero también tenemos name y thumbnailUrl. Podríamos habernos parado en id y dejar la aplicación para obtener información adicional que necesita a partir del documento de autor correspondiente mediante el "vínculo", pero como nuestra aplicación muestra el nombre del autor y una imagen en miniatura con cada libro mostrado, podemos ahorrar un viaje de ida y vuelta al servidor por libro en una lista mediante la desnormalización de algunos datos del autor.
Por supuesto, si cambia el nombre del autor o se desea actualizar la foto, tendríamos que realizar una actualización de cada libro publicado, pero para nuestra aplicación, que se basa en la suposición de que los autores no cambian de nombre a menudo, se trata de una decisión de diseño aceptable.
En el ejemplo hay valores de agregados calculados previamente para ahorrar un procesamiento costoso en una operación de lectura. En el ejemplo, algunos de los datos incrustados en el documento del autor son datos que se calculan en tiempo de ejecución. Cada vez que se publica un nuevo libro, se crea un documento de libro y el campo countOfBooks se establece en un valor calculado en función del número de documentos de libro que existen para un autor concreto. Esta optimización sería adecuada en sistemas en los que se realizan muchas operaciones de lectura, donde podemos permitirnos hacer cálculos en las escrituras para optimizarlas.
La capacidad de tener un modelo con campos calculados previamente es posible porque Azure Cosmos DB admite transacciones de varios documentos. Muchos almacenes NoSQL no pueden realizar transacciones en documentos y, por lo tanto, recomiendan las decisiones de diseño, por ejemplo, "siempre incrustar todo", debido a esa limitación. Con Azure Cosmos DB, puede utilizar los desencadenadores de servidor o los procedimientos almacenados que insertan los libros y actualizan los autores dentro de una transacción ACID. Ahora no tiene que insertar todo en un documento para asegurarse de que los datos sigan siendo coherentes.
Distinguir entre diferentes tipos de documentos
En algunos escenarios, es posible que quiera mezclar distintos tipos de documentos en la misma colección; esto suele suceder cuando quiere que varios documentos relacionados se encuentren en la misma partición. Por ejemplo, podría colocar los libros y las reseñas en la misma colección de libros y dividirla por bookId. En este caso, es probable que quiera agregar a los documentos un campo que los identifique y le ayude a diferenciarlos.
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"bookId": "b1",
"type": "book"
}
Review documents:
{
"id": "r1",
"content": "This book is awesome",
"bookId": "b1",
"type": "review"
},
{
"id": "r2",
"content": "Best book ever!",
"bookId": "b1",
"type": "review"
}
Modelado de datos para Azure Synapse Link y el almacén analítico de Azure Cosmos DB
Azure Synapse Link para Azure Cosmos DB es una funcionalidad de procesamiento analítico y transaccional híbrido (HTAP) nativo de nube que permite ejecutar análisis casi en tiempo real de datos operativos en Azure Cosmos DB. Azure Synapse Link crea una integración perfecta y sin contratiempos entre Azure Cosmos DB y Azure Synapse Analytics.
Esta integración se produce a través del almacén analítico de Azure Cosmos DB, una representación en columnas de los datos transaccionales que permite análisis a gran escala sin ningún impacto en las cargas de trabajo transaccionales. Este almacén analítico es adecuado para consultas rápidas y rentables en conjuntos de datos operativos de gran tamaño, sin necesidad de copiar los datos ni de afectar al rendimiento de las cargas de trabajo transaccionales. Al crear un contenedor con el almacén analítico habilitado, o al habilitar el almacén analítico en un contenedor existente, todas las inserciones transaccionales, actualizaciones y eliminaciones se sincronizan con el almacén analítico casi en tiempo real, no se requiere Change Feed o trabajos ETL.
Con Azure Synapse Link, ahora puede conectarse directamente a los contenedores de Azure Cosmos DB desde Azure Synapse Analytics y acceder al almacén analítico sin costo por unidad de solicitud (RU). Azure Synapse Analytics admite actualmente Azure Synapse Link con Apache Spark en Synapse y grupos de SQL sin servidor. Si tiene una cuenta de Azure Cosmos DB distribuida de forma global, después de habilitar el almacén analítico para un contenedor, estará disponible en todas las regiones de esa cuenta.
Inferencia automática del esquema del almacén analítico
Aunque el almacén transaccional de Azure Cosmos DB se considera datos semiestructurados orientados a filas, el almacén analítico tiene un formato de columnas y estructurado. Esta conversión se realiza automáticamente para los clientes, con las reglas de inferencia de esquema del almacén analítico. Hay límites en el proceso de conversión: número máximo de niveles anidados, número máximo de propiedades, tipos de datos no admitidos y mucho más.
Nota
En el contexto del almacén analítico, consideramos las siguientes estructuras como propiedad:
- "Elementos" JSON" o "pares cadena-valor separados por
:". - Objetos JSON, delimitados por
{y}. - Matrices JSON, delimitadas por
[y].
Puede minimizar el impacto de las conversiones de inferencia de esquema y maximizar sus capacidades analíticas mediante las técnicas siguientes.
Normalización
La normalización no tiene sentido, ya que con Azure Synapse Link puede combinar sus contenedores con T-SQL o Spark SQL. Las ventajas esperadas de la normalización son:
- Menor huella de datos en el almacén transaccional y analítico.
- Transacciones más pequeñas.
- Menos propiedades por documento.
- Estructuras de datos con menos niveles anidados.
Estos dos últimos factores, menos propiedades y menos niveles, ayudan al rendimiento de las consultas analíticas, y además disminuyen las posibilidades de que partes de los datos no se representen en el almacén analítico. Tal y como se describe en el artículo sobre reglas de inferencia automática de esquema, hay límites en el número de niveles y propiedades que se representan en el almacén analítico.
Otro factor importante para la normalización es que los grupos de SQL sin servidor de Azure Synapse admiten conjuntos de resultados con hasta 1000 columnas y exponer columnas anidadas también cuenta para ese límite. En otras palabras, tanto el almacén analítico como los grupos sin servidores de Synapse SQL tienen un límite de 1000 propiedades.
Pero ¿qué hacer puesto que la desnormalización es una técnica importante de modelado de datos para Azure Cosmos DB? La respuesta es que debe encontrar el equilibrio adecuado para sus cargas de trabajo transaccionales y analíticas.
Partition Key
La clave de partición (PK) de Azure Cosmos DB no se usa en el almacén analítico. Y ahora puede usar la creación de particiones personalizadas del almacén analítico en copias del almacén analítico con cualquier PK que desee. Debido a este aislamiento, puede elegir una PK para los datos transaccionales con el foco en la ingesta de datos y las lecturas puntuales, mientras que las consultas entre particiones se pueden realizar con Azure Synapse Link. Veamos un ejemplo:
En un escenario hipotético de IoT global, device id es un buena PK, ya que todos los dispositivos tienen un volumen de datos similar y con eso no tendrá un problema de partición activa. Pero si desea analizar los datos de más de un dispositivo, como "todos los datos de ayer" o "totales por ciudad", es posible que tenga problemas, ya que son consultas entre particiones. Esas consultas pueden dañar el rendimiento transaccional, ya que usan parte del rendimiento en unidades de solicitud para ejecutarse. Sin embargo, con Azure Synapse Link, puede ejecutar estas consultas analíticas sin costos por unidad de solicitud. El formato de columnas del almacén analítico está optimizado para consultas analíticas y Azure Synapse Link aplica esta característica para permitir un gran rendimiento con los entornos de ejecución de Azure Synapse Analytics.
Nombres de propiedades y tipos de datos
En el artículo reglas de inferencia automática de esquema se enumeran los tipos de datos admitidos. Mientras que los tipos de datos no admitidos bloquean la representación en el almacén analítico, los tipos de datos admitidos pueden ser procesados de forma diferente por los entornos de ejecución de Azure Synapse. Un ejemplo es: Al usar cadenas DateTime que siguen la norma UTC ISO 8601, los grupos de Spark de Azure Synapse representarán estas columnas como cadenas y los grupos de SQL sin servidor en Azure Synapse representarán estas columnas como varchar(8000).
Otro reto es que Azure Synapse Spark no acepta todos los caracteres. Aunque se aceptan espacios en blanco, caracteres como dos puntos, acento grave y coma no lo son. Supongamos que el documento tiene una propiedad denominada "Nombre, apellidos". Esta propiedad se representa en el almacén analítico y el grupo sin servidor de Synapse SQL puede leerla sin ningún problema. Sin embargo, como se encuentra en un almacén analítico, Azure Synapse Spark no puede leer ningún dato del almacén analítico, incluidas todas las demás propiedades. Al final del día, no puede usar Azure Synapse Spark cuando tiene una propiedad con los caracteres no admitidos en sus nombres.
Aplanamiento de datos
Todas las propiedades del nivel raíz de los datos de Azure Cosmos DB se representarán en el almacén analítico como una columna y todo lo demás que se encuentra en niveles más profundos del modelo de datos del documento se representará como JSON, también en estructuras anidadas. Las estructuras anidadas exigen un procesamiento adicional de los entornos de ejecución de Azure Synapse para aplanar los datos en formato estructurado, lo que puede ser un reto en escenarios de macrodatos.
El documento siguiente solo tendrá dos columnas en el almacén analítico, id y contactDetails. Todos los demás datos, email y phone, requerirán procesamiento adicional a través de funciones de SQL para que se lean individualmente.
{
"id": "1",
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555"}
]
}
El documento tendrá tres columnas en el almacén analítico, id, email y phone. Todos los datos son accesibles directamente como columnas.
{
"id": "1",
"email": "thomas@andersen.com",
"phone": "+1 555 555-5555"
}
Organización de los datos en capas
Azure Synapse Link le permite reducir los costos desde las siguientes perspectivas:
- Menos consultas que se ejecutan en la base de datos transaccional.
- Una PK optimizada para la ingesta de datos y las lecturas puntuales, lo que reduce la huella de datos, los escenarios de particiones activas y las divisiones de particiones.
- Organización de los datos en capas, porque el TTL analítico (ATTL) es independiente del TTL transaccional (TTTL). Puede mantener los datos transaccionales en el almacén transaccional durante unos días, semanas o meses, y mantener los datos en el almacén analítico durante años o para siempre. El formato por columnas del almacén analítico proporciona una compresión natural de los datos, del 50 % al 90 %. Y su costo por GB es aproximadamente un 10 % del precio real del almacén transaccional. Para más información sobre las limitaciones de copia de seguridad actuales, consulte Introducción al almacén analítico.
- No hay trabajos de ETL que se ejecuten en el entorno, lo que significa que no es necesario aprovisionar unidades de solicitud para ellos.
Redundancia controlada
Esta es una gran alternativa para situaciones en las que ya existe un modelo de datos y no se puede cambiar. Y cuando el modelo de datos existente no cabe bien en el almacén analítico debido a reglas de inferencia automática de esquema, como el límite de niveles anidados o el número máximo de propiedades. Si este es su caso, puede usar Azure Cosmos DB Change Feed para replicar los datos en otro contenedor, aplicando las transformaciones necesarias para un modelo de datos descriptivo de Azure Synapse Link. Veamos un ejemplo:
Escenario
El contenedor CustomersOrdersAndItems se usa para almacenar pedidos en línea, incluidos los detalles del cliente y de los artículos: dirección de facturación, dirección de entrega, método de entrega, estado de entrega, precio de los artículos, etc. Solo se representan las primeras 1000 propiedades y la información clave no se incluye en el almacén analítico, lo que bloquea el uso de Azure Synapse Link. El contenedor tiene PB de registros y no es posible cambiar la aplicación ni remodelar los datos.
Otra perspectiva del problema es el volumen de los macrodatos. El departamento de análisis usa miles de millones de filas constantemente, lo que les impide usar TTTL para la eliminación de datos antiguos. Mantener todo el historial de datos en la base de datos transaccional debido a las necesidades analíticas les obliga a aumentar constantemente el aprovisionamiento de unidades de solicitud, lo que afecta a los costos. Las cargas de trabajo transaccionales y analíticas compiten por los mismos recursos al mismo tiempo.
¿Qué debe hacer?
Solución con Change Feed
- El equipo de ingeniería decidió usar Change Feed para rellenar tres nuevos contenedores:
Customers,OrdersyItems. Con Change Feed, se están normalizando y aplanando los datos. La información innecesaria se quita del modelo de datos y cada contenedor tiene cerca de 100 propiedades, lo que evita la pérdida de datos debido a los límites de inferencia automática del esquema. - Estos nuevos contenedores tienen el almacén analítico habilitado y ahora el departamento de análisis usa Synapse Analytics para leer los datos, lo que reduce el uso de unidades de solicitud, ya que las consultas analíticas se están produciendo en Synapse Apache Spark y en grupos de SQL sin servidor.
- El contenedor
CustomersOrdersAndItemsahora tiene un conjunto de TTTL para conservar los datos solo durante seis meses, lo que permite otra reducción del uso de unidades de solicitud, ya que hay un mínimo de una unidad de solicitud por GB en Azure Cosmos DB. Menos datos, menos unidades de solicitud.
Puntos clave
Lo más importante de este artículo es comprender que el modelado de datos en un mundo sin esquemas es más importante que nunca.
Como no hay ninguna manera única de representar un elemento de datos en una pantalla, no hay una única forma de modelar los datos. Necesita comprender la aplicación y saber cómo produce, consume y procesa los datos. A continuación, mediante la aplicación de algunas directrices presentadas aquí, puede crear un modelo que aborde las necesidades inmediatas de la aplicación. Cuando las aplicaciones necesitan cambiar, puede usar la flexibilidad de una base de datos sin esquemas para adoptar ese cambio y que el modelo de datos evolucione con facilidad.