Administración de directivas de indexación en Azure Cosmos DB
En Azure Cosmos DB, para indexar los datos se usan las directivas de indexación que se definen para cada contenedor. La directiva de indexación predeterminada para los contenedores recién creados exige que se usen índices de intervalo para todas las cadenas o números. Puede invalidar esta directiva con su propia directiva de indexación personalizada.
Nota
El método de actualización de las directivas de indexación que se describe en este artículo solo se aplica a Azure Cosmos DB for NoSQL. Obtenga información sobre la indexación en Azure Cosmos DB for MongoDB e Indexación secundaria en Azure Cosmos DB for Apache Cassandra.
Ejemplos de directiva de indexación
Estos son algunos ejemplos de directivas de indexación que se muestran en formato JSON. Se exponen en Azure Portal en formato JSON. Los mismos parámetros se pueden establecer a través de la CLI de Azure o cualquier SDK.
Directiva de rechazo que excluye de forma selectiva algunas rutas de acceso de propiedades
{
"indexingMode": "consistent",
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/path/to/single/excluded/property/?"
},
{
"path": "/path/to/root/of/multiple/excluded/properties/*"
}
]
}
Directiva de participación que incluye de forma selectiva algunas rutas de acceso de propiedades
{
"indexingMode": "consistent",
"includedPaths": [
{
"path": "/path/to/included/property/?"
},
{
"path": "/path/to/root/of/multiple/included/properties/*"
}
],
"excludedPaths": [
{
"path": "/*"
}
]
}
Nota:
Por lo general, se recomienda usar una directiva de indexación de exclusión. Azure Cosmos DB indexa, de manera proactiva, todas las propiedades nuevas que se agregan a su modelo de datos.
Uso de un índice espacial en una ruta de acceso de una propiedad concreta solo
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/_etag/?"
}
],
"spatialIndexes": [
{
"path": "/path/to/geojson/property/?",
"types": [
"Point",
"Polygon",
"MultiPolygon",
"LineString"
]
}
]
}
Ejemplos de directivas de indexación de vectores
Además de incluir o excluir rutas de acceso para propiedades individuales, también puede especificar un índice de vector. En general, se deben especificar índices vectoriales cada vez que se usa la función del sistema VectorDistance para medir la similitud entre un vector de consulta y una propiedad vectorial.
Nota:
Antes de continuar, debe habilitar la indexación y búsqueda de vectores NoSQL de Azure Cosmos DB.
Importante
Una directiva de indexación de vectores debe estar en la misma ruta de acceso definida en la directiva de vectores del contenedor. Más información sobre las directivas de vectores de contenedor.
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/_etag/?"
},
{
"path": "/vector/*"
}
],
"vectorIndexes": [
{
"path": "/vector",
"type": "quantizedFlat"
}
]
}
Importante
Ruta de acceso vectorial agregada a la sección "excludedPaths" de la directiva de indexación para garantizar un rendimiento optimizado para la inserción. Si no se agrega la ruta de acceso vectorial a "excludedPaths", se producirá una mayor carga de RU y latencia para las inserciones vectoriales.
Importante
Actualmente, las directivas de vectores y los índices vectoriales son inmutables después de la creación. Para realizar cambios, cree una nueva colección.
Puede definir los siguientes tipos de directivas de índice vectorial:
| Tipo | Descripción | Dimensiones máximas |
|---|---|---|
flat |
Almacena vectores en el mismo índice que otras propiedades indexadas. | 505 |
quantizedFlat |
Cuantifica (comprime) vectores antes de almacenarlos en el índice. Esto puede mejorar la latencia y el rendimiento a costa de una pequeña cantidad de precisión. | 4096 |
diskANN |
Crea un índice basado en DiskANN para una búsqueda aproximada rápida y eficaz. | 4096 |
Los tipos de índice flat y quantizedFlat aprovechan el índice de Azure Cosmos DB para almacenar y leer cada vector al realizar un vector de búsqueda. El vector de búsqueda con un índice de flat son búsquedas por fuerza bruta y producen una precisión del 100 %. Sin embargo, hay una limitación de 505 dimensiones para vectores en un índice plano.
El índice quantizedFlat almacena vectores cuantificados o comprimidos en el índice. El vector de búsqueda con quantizedFlat índice también son búsquedas por fuerza bruta, pero su precisión podría ser ligeramente inferior al 100 %, ya que los vectores se cuantifican antes de agregar al índice. Sin embargo, las búsquedas vectoriales con quantized flat deben tener una latencia menor, un mayor rendimiento y un menor costo de RU que el vector de búsqueda en un índice flat. Esta es una buena opción para escenarios en los que se usan filtros de consulta para restringir el vector de búsqueda a un conjunto relativamente pequeño de vectores.
El diskANN índice es un índice independiente definido específicamente para vectores que aprovechan DiskANN, un conjunto de algoritmos de indexación de vectores de alto rendimiento desarrollados por Microsoft Research. Los índices DiskANN pueden ofrecer algunas de las consultas de menor latencia, la consulta por segundo (QPS) más alta y las consultas de costo de RU más bajas con alta precisión. Sin embargo, dado que DiskANN es un índice aproximado de vecinos más cercanos (ANN), la precisión puede ser menor que quantizedFlat o flat.
Los índices diskANN y quantizedFlat pueden adoptar parámetros de compilación de índices opcionales que se pueden usar para ajustar la precisión frente a la desventaja de latencia que se aplica a todos los índices vectoriales vecinos más cercanos aproximados.
quantizationByteSize: establece el tamaño (en bytes) para la cuantificación del producto. Mínimo=1, Valor predeterminado=dinámico (lo decide el sistema), Máximo=512. Establecer este valor de forma superior puede dar lugar a vectores de búsquedas de mayor precisión en base a un mayor costo de RU y una mayor latencia. Esto se aplica a los tipos de índicequantizedFlatyDiskANN.indexingSearchListSize: establece cuántos vectores se van a buscar durante la construcción de la compilación del índice. Mínimo=10, Valor predeterminado=100, Máximo=500. Establecer este valor de forma superior puede dar lugar a vectores de búsquedas de mayor precisión en base a tiempos de compilación de índices más largos y latencias de ingesta de vectores más altas. Esto solo se aplica a los índices deDiskANN.
Ejemplos de directivas de indexación de tupla
En este ejemplo de directiva de indexación se define un índice de tupla en events.name y events.category
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{"path":"/*"},
{"path":"/events/[]/{name,category}/?"}
],
"excludedPaths":[],
"compositeIndexes":[]
}
El índice anterior se usa para la consulta siguiente.
SELECT *
FROM root r
WHERE
EXISTS (SELECT VALUE 1 FROM ev IN r.events
WHERE ev.name = ‘M&M’ AND ev.category = ‘Candy’)
Ejemplos de la directiva de índice compuesto
Además de incluir o excluir rutas de acceso para las propiedades individuales, también puede especificar un índice compuesto. Para realizar una consulta que tenga una cláusula ORDER BY para varias propiedades, se necesita un índice compuesto en esas propiedades. Si la consulta incluye filtros junto con la ordenación en varias propiedades, es posible que necesite más de un índice compuesto.
Los índices compuestos tienen también una ventaja de rendimiento para las consultas con varios filtros, o bien, con un filtro y una cláusula ORDER BY.
Nota:
Las rutas de acceso compuestas tienen un carácter /? implícito, ya que solo se indexa el valor escalar de esa ruta de acceso. El carácter comodín /* no se admite en las rutas de acceso compuestas. No debe especificar /? ni /* en las rutas de acceso compuestas. Las rutas de acceso compuestas también distinguen mayúsculas de minúsculas.
Índice compuesto definido para (name asc, age desc)
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"descending"
}
]
]
}
El índice compuesto en name y age es necesario para las siguientes consultas:
Consulta 1:
SELECT *
FROM c
ORDER BY c.name ASC, c.age DESC
Consulta 2:
SELECT *
FROM c
ORDER BY c.name DESC, c.age ASC
Este índice compuesto beneficia a las siguientes consultas y optimiza los filtros:
Consulta #3:
SELECT *
FROM c
WHERE c.name = "Tim"
ORDER BY c.name DESC, c.age ASC
Consulta #4:
SELECT *
FROM c
WHERE c.name = "Tim" AND c.age > 18
Índice compuesto definido para (name ASC, age ASC) y (name ASC, age DESC)
Puede definir varios índices compuestos dentro de la misma directiva de índice.
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"ascending"
}
],
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"descending"
}
]
]
}
Índice compuesto definido para (name ASC, age ASC)
Si quiere, puede especificar el orden. Si no lo especifica, el orden es ascendente.
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name"
},
{
"path":"/age"
}
]
]
}
Excluir las rutas de acceso de todas las propiedades, pero mantener la indexación activa
Puede usar esta directiva en las situaciones en que la característica Período de vida (TTL) esté activa, pero no se necesite ningún otro índice para usar Azure Cosmos DB como almacén de pares clave-valor puro.
{
"indexingMode": "consistent",
"includedPaths": [],
"excludedPaths": [{
"path": "/*"
}]
}
Sin indexación
Esta directiva desactiva la indexación. Si indexingMode está establecido en none, no puede establecer un TTL en el contenedor.
{
"indexingMode": "none"
}
Actualización de la directiva de indexación
En Azure Cosmos DB, la directiva de indexación se puede actualizar mediante cualquiera de los métodos siguientes:
- Desde Azure Portal
- Uso de la CLI de Azure
- Usar PowerShell
- Con uno de los SDK
Las actualizaciones de las directivas de indexación desencadenan transformaciones de índices. También se puede realizar un seguimiento del progreso de esta transformación desde los SDK.
Nota:
Al actualizar la directiva de indexación, las escrituras en Azure Cosmos DB no se interrumpen. Obtenga más información sobre las transformaciones de indexación.
Importante
La eliminación de un índice tiene efecto inmediato, mientras que la adición de un nuevo índice lleva cierto tiempo, ya que requiere una transformación de indexación. Al reemplazar un índice por otro (por ejemplo, reemplazar un solo índice de propiedad por un índice compuesto), asegúrese de agregar primero el nuevo índice y, a continuación, esperar a que se complete la transformación del índice antes de quitar el índice anterior de la directiva de indexación. De lo contrario, esto afectará negativamente a la capacidad de consultar el índice anterior y podría interrumpir las cargas de trabajo activas que hagan referencia al índice anterior.
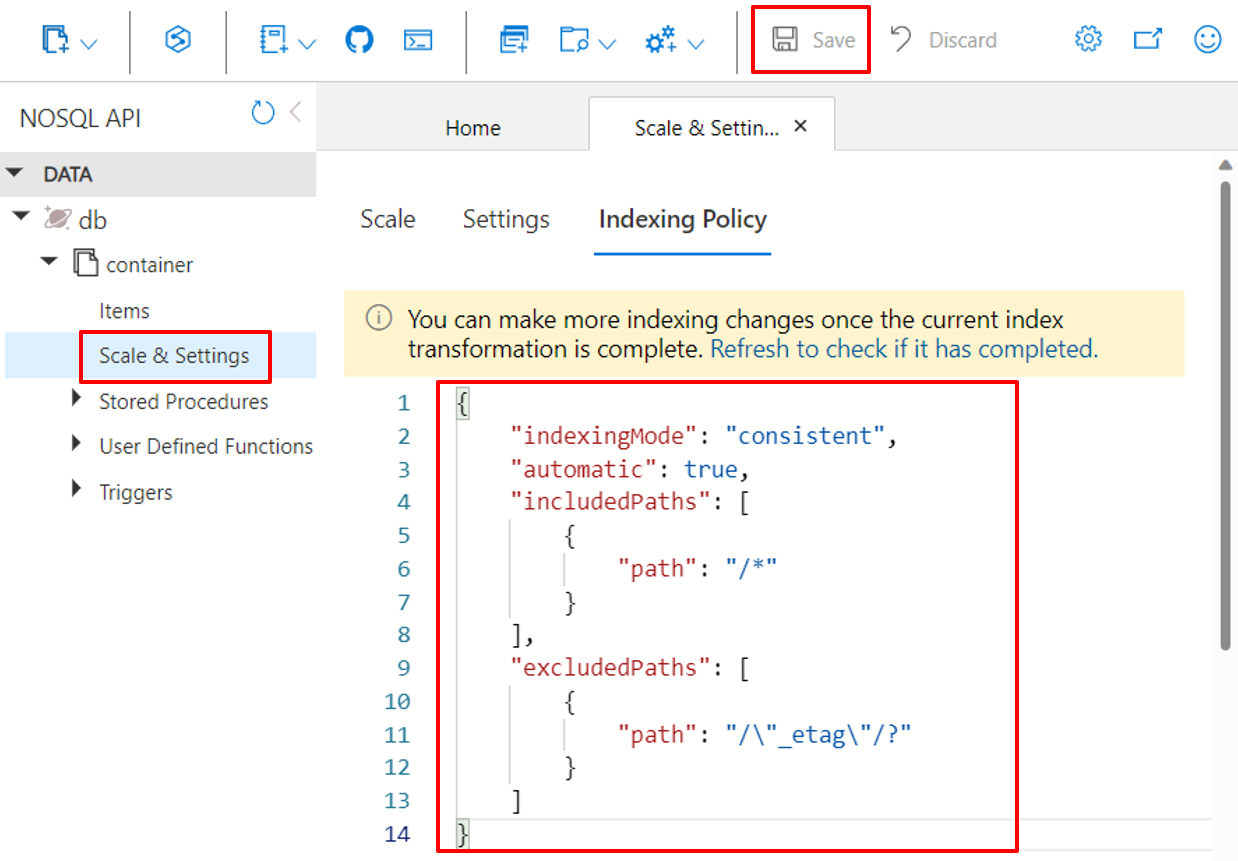
Uso de Azure Portal
Los contenedores de Azure Cosmos DB almacenan su directiva de indexación en forma de documento JSON que Azure Portal permite editar directamente.
Inicie sesión en Azure Portal.
Cree una nueva cuenta de Azure Cosmos DB o seleccione una existente.
Abra el panel Data Explorer y seleccione el contenedor en el que quiere trabajar.
Seleccione Escala y Configuración.
Modifique el documento JSON de la directiva de indexación, como se muestra en estos ejemplos.
Cuando haya terminado, haga clic en Guardar.
Uso de la CLI de Azure
Para crear un contenedor con una directiva de indexación personalizada, consulte Creación de un contenedor con una directiva de indexación personalizada mediante la CLI.
Uso de PowerShell
Para crear un contenedor con una directiva de indexación personalizada, consulte Creación de un contenedor con una directiva de indexación personalizada mediante PowerShell.
Uso del SDK de .NET
El objeto ContainerProperties del SDK de .NET v3 expone una propiedad IndexingPolicy que permite cambiar IndexingMode y agregar o quitar IncludedPaths y ExcludedPaths. Para más información, consulte Inicio rápido: Biblioteca cliente de Azure Cosmos DB for NoSQL para .NET.
// Retrieve the container's details
ContainerResponse containerResponse = await client.GetContainer("database", "container").ReadContainerAsync();
// Set the indexing mode to consistent
containerResponse.Resource.IndexingPolicy.IndexingMode = IndexingMode.Consistent;
// Add an included path
containerResponse.Resource.IndexingPolicy.IncludedPaths.Add(new IncludedPath { Path = "/*" });
// Add an excluded path
containerResponse.Resource.IndexingPolicy.ExcludedPaths.Add(new ExcludedPath { Path = "/name/*" });
// Add a spatial index
SpatialPath spatialPath = new SpatialPath
{
Path = "/locations/*"
};
spatialPath.SpatialTypes.Add(SpatialType.Point);
containerResponse.Resource.IndexingPolicy.SpatialIndexes.Add(spatialPath);
// Add a composite index
containerResponse.Resource.IndexingPolicy.CompositeIndexes.Add(new Collection<CompositePath> { new CompositePath() { Path = "/name", Order = CompositePathSortOrder.Ascending }, new CompositePath() { Path = "/age", Order = CompositePathSortOrder.Descending } });
// Update container with changes
await client.GetContainer("database", "container").ReplaceContainerAsync(containerResponse.Resource);
Para realizar un seguimiento del progreso de transformación del índice, utilice un objeto RequestOptions que establezca la propiedad PopulateQuotaInfo en true. Recupere el valor del encabezado de respuesta x-ms-documentdb-collection-index-transformation-progress.
// retrieve the container's details
ContainerResponse containerResponse = await client.GetContainer("database", "container").ReadContainerAsync(new ContainerRequestOptions { PopulateQuotaInfo = true });
// retrieve the index transformation progress from the result
long indexTransformationProgress = long.Parse(containerResponse.Headers["x-ms-documentdb-collection-index-transformation-progress"]);
Al definir una directiva de indexación personalizada durante la creación de un nuevo contenedor, la API fluida del SDK v3 le permite escribir esta definición de una manera concisa y eficaz:
await client.GetDatabase("database").DefineContainer(name: "container", partitionKeyPath: "/myPartitionKey")
.WithIndexingPolicy()
.WithIncludedPaths()
.Path("/*")
.Attach()
.WithExcludedPaths()
.Path("/name/*")
.Attach()
.WithSpatialIndex()
.Path("/locations/*", SpatialType.Point)
.Attach()
.WithCompositeIndex()
.Path("/name", CompositePathSortOrder.Ascending)
.Path("/age", CompositePathSortOrder.Descending)
.Attach()
.Attach()
.CreateIfNotExistsAsync();
Uso del SDK de Java
El objeto DocumentCollection del SDK de Java expone los métodos getIndexingPolicy() y setIndexingPolicy(). El objeto IndexingPolicy que manipulan permite cambiar el modo de indexación y agregar o quitar las rutas de acceso incluidas y excluidas. Para más información, consulte Inicio rápido: Compilación de una aplicación Java para administrar los datos de Azure Cosmos DB for NoSQL.
// Retrieve the container's details
Observable<ResourceResponse<DocumentCollection>> containerResponse = client.readCollection(String.format("/dbs/%s/colls/%s", "database", "container"), null);
containerResponse.subscribe(result -> {
DocumentCollection container = result.getResource();
IndexingPolicy indexingPolicy = container.getIndexingPolicy();
// Set the indexing mode to consistent
indexingPolicy.setIndexingMode(IndexingMode.Consistent);
// Add an included path
Collection<IncludedPath> includedPaths = new ArrayList<>();
IncludedPath includedPath = new IncludedPath();
includedPath.setPath("/*");
includedPaths.add(includedPath);
indexingPolicy.setIncludedPaths(includedPaths);
// Add an excluded path
Collection<ExcludedPath> excludedPaths = new ArrayList<>();
ExcludedPath excludedPath = new ExcludedPath();
excludedPath.setPath("/name/*");
excludedPaths.add(excludedPath);
indexingPolicy.setExcludedPaths(excludedPaths);
// Add a spatial index
Collection<SpatialSpec> spatialIndexes = new ArrayList<SpatialSpec>();
Collection<SpatialType> collectionOfSpatialTypes = new ArrayList<SpatialType>();
SpatialSpec spec = new SpatialSpec();
spec.setPath("/locations/*");
collectionOfSpatialTypes.add(SpatialType.Point);
spec.setSpatialTypes(collectionOfSpatialTypes);
spatialIndexes.add(spec);
indexingPolicy.setSpatialIndexes(spatialIndexes);
// Add a composite index
Collection<ArrayList<CompositePath>> compositeIndexes = new ArrayList<>();
ArrayList<CompositePath> compositePaths = new ArrayList<>();
CompositePath nameCompositePath = new CompositePath();
nameCompositePath.setPath("/name");
nameCompositePath.setOrder(CompositePathSortOrder.Ascending);
CompositePath ageCompositePath = new CompositePath();
ageCompositePath.setPath("/age");
ageCompositePath.setOrder(CompositePathSortOrder.Descending);
compositePaths.add(ageCompositePath);
compositePaths.add(nameCompositePath);
compositeIndexes.add(compositePaths);
indexingPolicy.setCompositeIndexes(compositeIndexes);
// Update the container with changes
client.replaceCollection(container, null);
});
Para realizar un seguimiento del progreso de transformación del índice en un contenedor, utilice un objeto RequestOptions que solicite la información de cuota que se debe rellenar. Recupere el valor del encabezado de respuesta x-ms-documentdb-collection-index-transformation-progress.
// set the RequestOptions object
RequestOptions requestOptions = new RequestOptions();
requestOptions.setPopulateQuotaInfo(true);
// retrieve the container's details
Observable<ResourceResponse<DocumentCollection>> containerResponse = client.readCollection(String.format("/dbs/%s/colls/%s", "database", "container"), requestOptions);
containerResponse.subscribe(result -> {
// retrieve the index transformation progress from the response headers
String indexTransformationProgress = result.getResponseHeaders().get("x-ms-documentdb-collection-index-transformation-progress");
});
Uso del SDK de Node.js
La interfaz ContainerDefinition del SDK de Node.js expone una propiedad indexingPolicy que le permite cambiar el indexingMode y agregar o quitar includedPaths y excludedPaths. Para más información, consulte Inicio rápido: Biblioteca cliente de Azure Cosmos DB for NoSQL para Node.js.
Recuperar los detalles del contenedor:
const containerResponse = await client.database('database').container('container').read();
Establecer el modo de indexación en coherente:
containerResponse.body.indexingPolicy.indexingMode = "consistent";
Agregar una ruta de acceso incluida con un índice espacial:
containerResponse.body.indexingPolicy.includedPaths.push({
includedPaths: [
{
path: "/age/*",
indexes: [
{
kind: cosmos.DocumentBase.IndexKind.Range,
dataType: cosmos.DocumentBase.DataType.String
},
{
kind: cosmos.DocumentBase.IndexKind.Range,
dataType: cosmos.DocumentBase.DataType.Number
}
]
},
{
path: "/locations/*",
indexes: [
{
kind: cosmos.DocumentBase.IndexKind.Spatial,
dataType: cosmos.DocumentBase.DataType.Point
}
]
}
]
});
Agregar una ruta de acceso excluida:
containerResponse.body.indexingPolicy.excludedPaths.push({ path: '/name/*' });
Actualizar el contenedor con cambios:
const replaceResponse = await client.database('database').container('container').replace(containerResponse.body);
Para realizar un seguimiento del progreso de transformación del índice en un contenedor, utilice un objeto RequestOptions que establezca la propiedad populateQuotaInfo en true. Recupere el valor del encabezado de respuesta x-ms-documentdb-collection-index-transformation-progress.
// retrieve the container's details
const containerResponse = await client.database('database').container('container').read({
populateQuotaInfo: true
});
// retrieve the index transformation progress from the response headers
const indexTransformationProgress = replaceResponse.headers['x-ms-documentdb-collection-index-transformation-progress'];
Agregar un índice compuesto:
console.log("create container with composite indexes");
const containerDefWithCompositeIndexes = {
id: "containerWithCompositeIndexingPolicy",
indexingPolicy: {
automatic: true,
indexingMode: IndexingMode.consistent,
includedPaths: [
{
path: "/*",
},
],
excludedPaths: [
{
path: '/"systemMetadata"/*',
},
],
compositeIndexes: [
[
{ path: "/field", order: "ascending" },
{ path: "/key", order: "ascending" },
],
],
},
};
const containerWithCompositeIndexes = (
await database.containers.create(containerDefWithCompositeIndexes)
).container;
Uso del SDK de Python
Cuando se usa el SDK de Python v3, la configuración del contenedor se administra como un diccionario. Desde este diccionario, puede acceder a la directiva de indexación y a todos sus atributos. Para más información, consulte Inicio rápido: Biblioteca cliente de Azure Cosmos DB for NoSQL para Python.
Recuperar los detalles del contenedor:
containerPath = 'dbs/database/colls/collection'
container = client.ReadContainer(containerPath)
Establecer el modo de indexación en coherente:
container['indexingPolicy']['indexingMode'] = 'consistent'
Definir una directiva de indexación con una ruta de acceso incluida y un índice espacial:
container["indexingPolicy"] = {
"indexingMode":"consistent",
"spatialIndexes":[
{"path":"/location/*","types":["Point"]}
],
"includedPaths":[{"path":"/age/*","indexes":[]}],
"excludedPaths":[{"path":"/*"}]
}
Definir una directiva de indexación con una ruta de acceso excluida:
container["indexingPolicy"] = {
"indexingMode":"consistent",
"includedPaths":[{"path":"/*","indexes":[]}],
"excludedPaths":[{"path":"/name/*"}]
}
Agregar un índice compuesto:
container['indexingPolicy']['compositeIndexes'] = [
[
{
"path": "/name",
"order": "ascending"
},
{
"path": "/age",
"order": "descending"
}
]
]
Actualizar el contenedor con cambios:
response = client.ReplaceContainer(containerPath, container)