Generación aumentada de recuperación (RAG) con Azure Cosmos DB basado en núcleo virtual para MongoDB
En el ámbito de la inteligencia artificial generativa, los modelos de lenguaje grande (LLM) como GPT-3.5 han transformado el procesamiento del lenguaje natural. Sin embargo, una tendencia emergente en la inteligencia artificial es el uso de almacenes vectoriales, que desempeñan un papel fundamental en la mejora de las aplicaciones de inteligencia artificial.
En este tutorial se explora cómo usar Azure Cosmos DB for MongoDB (núcleo virtual), LangChain, y OpenAI para implementar la generación aumentada de recuperación (RAG) para mejorar el rendimiento de la inteligencia artificial junto con la discusión de los LLM y sus limitaciones. Exploramos el paradigma adoptado rápidamente de "generación aumentada de recuperación" (RAG) y analizamos brevemente el marco LangChain, los modelos de Azure OpenAI. Por último, integramos estos conceptos en una aplicación real. Al final, los lectores tendrán un conocimiento sólido de estos conceptos.
Descripción de los modelos de lenguaje grande (LLM) y sus limitaciones
Los modelos de lenguaje grande (LLM) son modelos avanzados de red neuronal profunda entrenados en conjuntos de datos de texto extensos, lo que les permite comprender y generar texto similar al humano. Aunque son revolucionarios en el procesamiento de lenguaje natural, los LLM tienen limitaciones inherentes:
- Alucinaciones: los LLM a veces generan información incorrecta o sin fundamento, lo que se conoce como "alucinaciones".
- Datos obsoletos: los LLM se entrenan en conjuntos de datos estáticos que podrían no incluir la información más reciente, lo que limita su relevancia actual.
- Sin acceso a los datos locales del usuario: los LLM no tienen acceso directo a los datos personales o localizados, lo que restringe su capacidad de proporcionar respuestas personalizadas.
- Límites de token: los LLM tienen un límite máximo de tokens por interacción, lo que restringe la cantidad de texto que pueden procesar a la vez. Por ejemplo, gpt-3.5-turbo de OpenAI tiene un límite de tokens de 4096.
Sacar provecho de la generación aumentada de recuperación (RAG)
La generación aumentada por recuperación (RAG) es una arquitectura diseñada para superar las limitaciones de los LLM. La RAG usa un vector de búsqueda para recuperar documentos relevantes en función de una consulta de entrada, proporcionando estos documentos como contexto al LLM para generar respuestas más precisas. En lugar de confiar únicamente en patrones entrenados previamente, la RAG mejora las respuestas mediante la incorporación de información relevante actualizada. Este enfoque ayuda a:
- Minimizar las alucinaciones: respuestas basadas en información objetiva.
- Garantizar la actualidad de la información: recuperar los datos más recientes para garantizar respuestas actualizadas.
- Utilizar bases de datos externas: aunque no concede acceso directo a los datos personales, la RAG permite la integración con bases de conocimiento externas específicas del usuario.
- Optimizar el uso de tokens: al centrarse en los documentos más relevantes, la RAG hace que el uso de tokens sea más eficaz.
En este tutorial se muestra cómo se puede implementar la RAG mediante Azure Cosmos DB for MongoDB (núcleo virtual) para crear una aplicación de respuesta a preguntas adaptada a los datos.
Introducción a la arquitectura de aplicaciones
En el siguiente diagrama de arquitectura se muestran los componentes clave de nuestra implementación de la RAG:
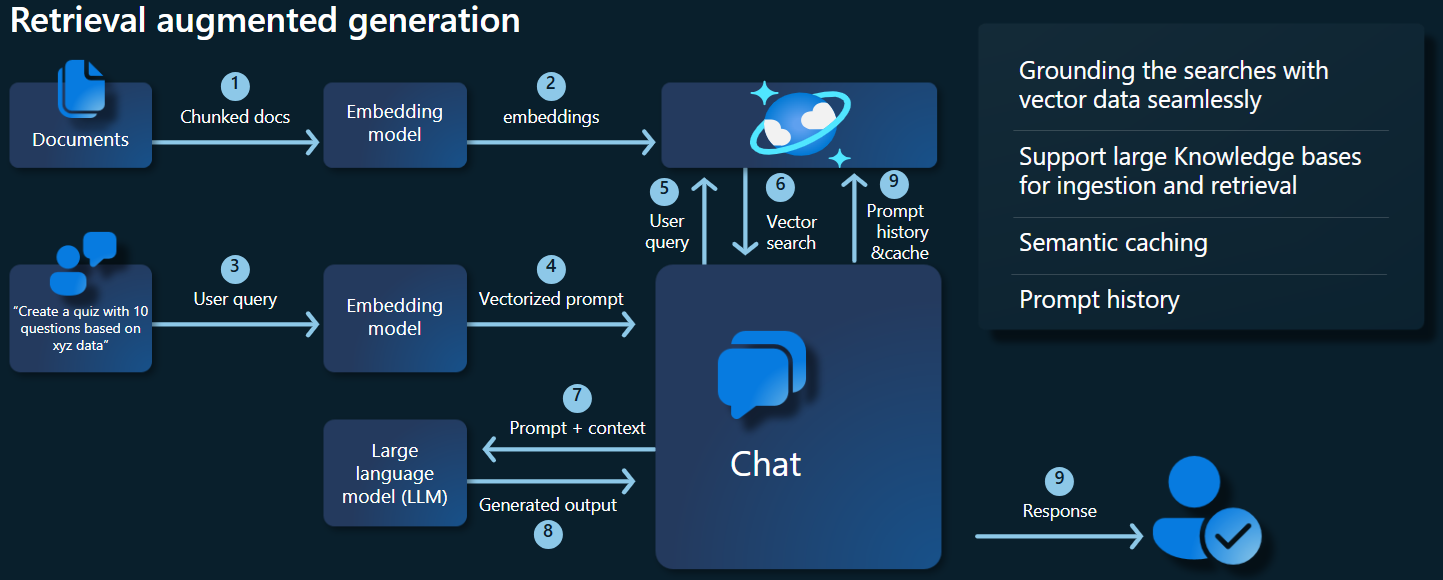
Componentes y marcos clave
Ahora analizaremos los distintos marcos, modelos y componentes usados en este tutorial, resaltando sus roles y matices.
Azure Cosmos DB for MongoDB (vCore)
Azure Cosmos DB for MongoDB (núcleo virtual) admite búsquedas de similitud semántica, esenciales para las aplicaciones con tecnología de inteligencia artificial. Permite representar datos en varios formatos como inserciones vectoriales, que se pueden almacenar junto con los datos de origen y los metadatos. Con un algoritmo de vecinos más cercano aproximado, como El mundo pequeño navegable jerárquico (HNSW), estas inserciones se pueden consultar para búsquedas rápidas de similitud semántica.
Marco de LangChain
LangChain simplifica la creación de aplicaciones de LLM proporcionando una interfaz estándar para cadenas, varias integraciones de herramientas y cadenas de un extremo a otro para tareas comunes. Permite a los desarrolladores de inteligencia artificial crear aplicaciones de LLM que aprovechan orígenes de datos externos.
Aspectos clave de LangChain:
- Cadenas: secuencias de componentes que resuelven tareas específicas.
- Componentes: módulos como contenedores de LLM, contenedores de almacén de vectores, plantillas de solicitud, cargadores de datos, divisores de texto y recuperadores.
- Modularidad: simplifica el desarrollo, la depuración y el mantenimiento.
- Popularidad: un proyecto de código abierto que obtiene rápidamente la adopción y evoluciona para satisfacer las necesidades del usuario.
Interfaz de Azure App Services
App Services proporciona una plataforma sólida para crear interfaces web fáciles de usar para aplicaciones de inteligencia artificial generativa. En este tutorial se usa Azure App Services para crear una interfaz web interactiva para la aplicación.
Modelos de OpenAI
OpenAI es líder en la investigación de inteligencia artificial, lo que proporciona varios modelos para la generación de lenguajes, la vectorización de texto, la creación de imágenes y la conversión de audio a texto. En este tutorial, usaremos los modelos de inserción y lenguaje de OpenAI, cruciales para comprender y generar aplicaciones basadas en lenguaje.
Inserción de modelos frente a Generación de lenguaje
| Categoría | Modelo de inserción de texto | Modelo de lenguaje |
|---|---|---|
| Propósito | Conversión de texto en inserciones vectoriales. | Comprensión y generación de lenguaje natural. |
| Función | Transforma los datos textuales en matrices multidimensionales de números, capturando el significado semántico del texto. | Comprende y genera texto similar al humano en función de una entrada determinada. |
| Salida | Matriz de números (inserciones vectoriales). | Texto, respuestas, traducciones, código, etc. |
| Salida de ejemplo | Cada inserción representa el significado semántico del texto en forma numérica, con una dimensionalidad determinada por el modelo. Por ejemplo, text-embedding-ada-002 genera vectores con 1536 dimensiones. |
Texto contextualmente relevante y coherente generado en función de la entrada proporcionada. Por ejemplo, gpt-3.5-turbo puede generar respuestas a preguntas, traducir texto, escribir código, etc. |
| Casos de uso típicos | - Búsqueda semántica | - Bots de chat |
| - Sistemas de recomendaciones | - Creación automatizada de contenido | |
| - Agrupación en clústeres y clasificación de datos de texto | - Traducción de idiomas | |
| - Recuperación de información | - Resumen | |
| Representación de datos | Representación numérica (inserciones) | Texto de lenguaje natural |
| Dimensionalidad | La longitud de la matriz corresponde al número de dimensiones del espacio de inserción, por ejemplo, 1536 dimensiones. | Normalmente se representa como una secuencia de tokens, con el contexto que determina la longitud. |
Componentes principales de la aplicación
- Núcleo virtual de Azure Cosmos DB for MongoDB: almacenamiento y consulta de inserciones de vectores.
- LangChain: construcción del flujo de trabajo de LLM de la aplicación. Utiliza herramientas como:
- Cargador de documentos: para cargar y procesar documentos desde un directorio.
- Integración del almacén de vectores: para almacenar y consultar inserciones de vectores en Azure Cosmos DB.
- AzureCosmosDBVectorSearch: contenedor alrededor del vector de búsqueda de Cosmos DB
- Azure App Services: creación de la interfaz de usuario para la aplicación Cosmic Food.
- Azure OpenAI: para proporcionar LLM y modelos de inserción, entre los que se incluyen:
- text-embedding-ada-002: un modelo de inserción de texto que convierte texto en inserciones vectoriales con 1536 dimensiones.
- gpt-3.5-turbo: un modelo de lenguaje para comprender y generar lenguaje natural.
Configuración del entorno
Para empezar a optimizar la generación aumentada por recuperación (RAG) mediante Azure Cosmos DB for MongoDB (núcleo virtual), siga estos pasos:
- Cree los siguientes recursos en Microsoft Azure:
- clúster de núcleo virtual de Azure Cosmos DB for MongoDB: consulte la guía de inicio rápido aquí.
- Recurso de Azure OpenAI con:
- Implementación de modelo de inserción (por ejemplo,
text-embedding-ada-002). - Implementación de modelo de chat (por ejemplo,
gpt-35-turbo).
- Implementación de modelo de inserción (por ejemplo,
Documentos de ejemplo
En este tutorial, se cargará un único archivo de texto mediante Documento. Estos archivos deben guardarse en un directorio denominado data en la carpeta src. Su contenido es el siguiente:
food_items.json
{
"category": "Cold Dishes",
"name": "Hamachi Fig",
"description": "Hamachi sashimi lightly tossed in a fig sauce with rum raisins, and serrano peppers then topped with fried lotus root.",
"price": "16.0 USD"
},
Carga de documentos
Establezca la cadena de conexión de Cosmos DB for MongoDB (núcleo virtual), el nombre de la base de datos, el nombre de la colección y el índice:
mongo_client = MongoClient(mongo_connection_string) database_name = "Contoso" db = mongo_client[database_name] collection_name = "ContosoCollection" index_name = "ContosoIndex" collection = db[collection_name]Inicialice el cliente de inserción.
from langchain_openai import AzureOpenAIEmbeddings openai_embeddings_model = os.getenv("AZURE_OPENAI_EMBEDDINGS_MODEL_NAME", "text-embedding-ada-002") openai_embeddings_deployment = os.getenv("AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME", "text-embedding") azure_openai_embeddings: AzureOpenAIEmbeddings = AzureOpenAIEmbeddings( model=openai_embeddings_model, azure_deployment=openai_embeddings_deployment, )Cree inserciones a partir de los datos, guarde en la base de datos y devuelva una conexión al almacén de vectores, Cosmos DB for MongoDB (núcleo virtual).
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_documents( json_data, azure_openai_embeddings, collection=collection, index_name=index_name, )Cree el siguiente índice de vector HNSW en la colección (tenga en cuenta que el nombre del índice es el mismo que el anterior).
num_lists = 100 dimensions = 1536 similarity_algorithm = CosmosDBSimilarityType.COS kind = CosmosDBVectorSearchType.VECTOR_HNSW m = 16 ef_construction = 64 vector_store.create_index( num_lists, dimensions, similarity_algorithm, kind, m, ef_construction )
Realice el vector de búsqueda mediante Cosmos DB for MongoDB (núcleo virtual)
Conéctese al almacén de vectores.
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_connection_string( connection_string=mongo_connection_string, namespace=f"{database_name}.{collection_name}", embedding=azure_openai_embeddings, )Defina una función que realice una búsqueda de similitud semántica mediante el vector de búsqueda de Cosmos DB en una consulta (tenga en cuenta que este fragmento de código es simplemente una función de prueba).
query = "beef dishes" docs = vector_store.similarity_search(query) print(docs[0].page_content)Inicialice el cliente de chat para implementar una función de RAG.
azure_openai_chat: AzureChatOpenAI = AzureChatOpenAI( model=openai_chat_model, azure_deployment=openai_chat_deployment, )Cree una función de RAG.
history_prompt = ChatPromptTemplate.from_messages( [ MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ( "user", """Given the above conversation, generate a search query to look up to get information relevant to the conversation""", ), ] ) context_prompt = ChatPromptTemplate.from_messages( [ ("system", "Answer the user's questions based on the below context:\n\n{context}"), MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ] )Convierte el almacén de vectores en un recuperador, que puede buscar documentos pertinentes en función de los parámetros especificados.
vector_store_retriever = vector_store.as_retriever( search_type=search_type, search_kwargs={"k": limit, "score_threshold": score_threshold} )Cree una cadena de recuperadores que conozca el historial de conversaciones, garantizando la recuperación de documentos contextualmente relevante mediante el modelo de azure_openai_chat y vector_store_retriever.
retriever_chain = create_history_aware_retriever(azure_openai_chat, vector_store_retriever, history_prompt)Cree una cadena que combine documentos recuperados en una respuesta coherente mediante el modelo de lenguaje (azure_openai_chat) y un símbolo del sistema especificado (context_prompt).
context_chain = create_stuff_documents_chain(llm=azure_openai_chat, prompt=context_prompt)Cree una cadena que controle todo el proceso de recuperación, integrando la cadena del recuperador compatible con el historial y la cadena de combinación de documentos. Esta cadena de RAG se puede ejecutar para recuperar y generar respuestas contextualmente precisas.
rag_chain: Runnable = create_retrieval_chain( retriever=retriever_chain, combine_docs_chain=context_chain, )
Salidas de ejemplo
En el siguiente recorte de pantalla se muestran las salidas de varias preguntas. Una búsqueda de similitud semántica devuelve el texto sin formato de los documentos de origen, mientras que la aplicación de respuesta a preguntas mediante la arquitectura de RAG genera respuestas precisas y personalizadas combinando el contenido del documento recuperado con el modelo de lenguaje.
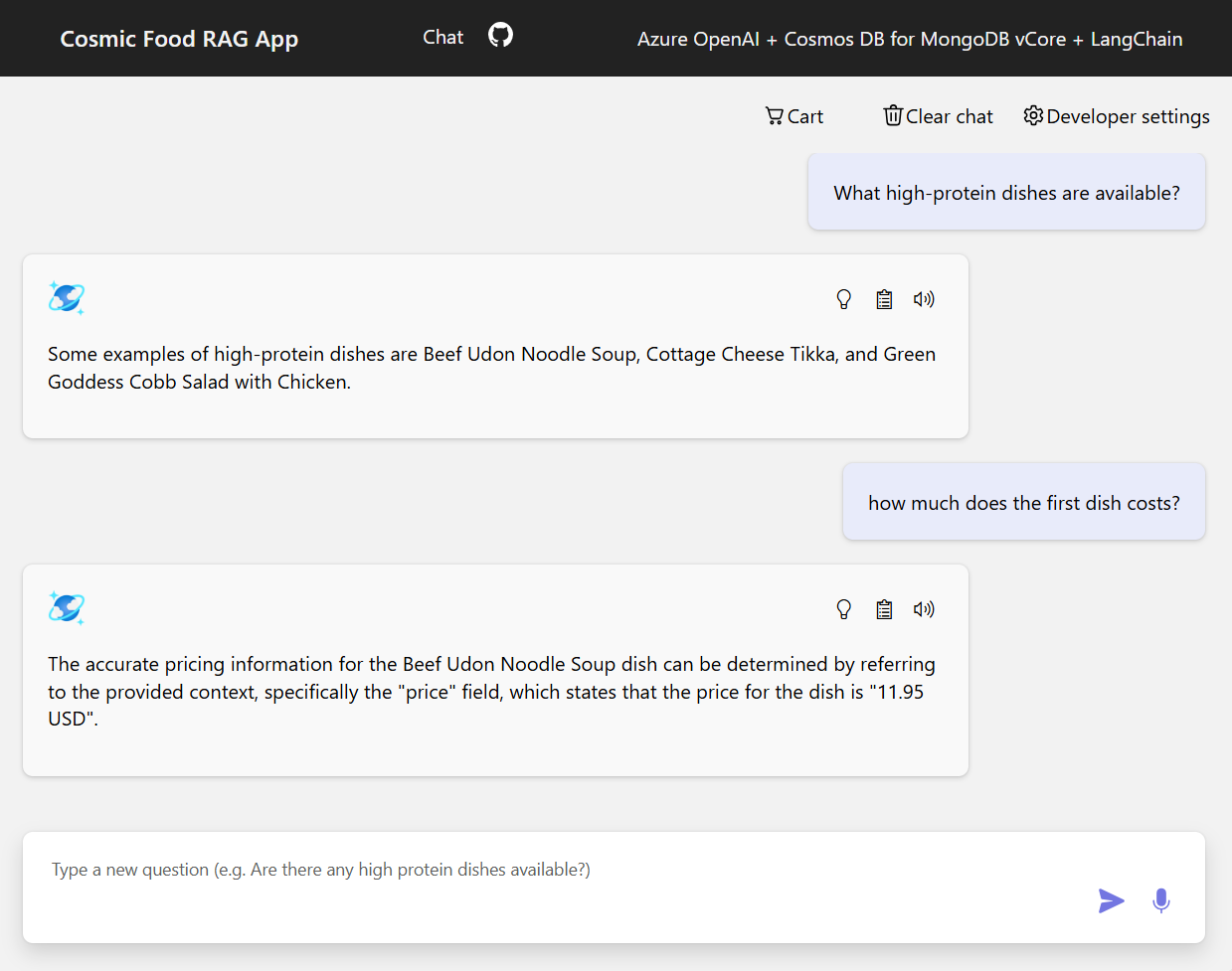
Conclusión
En este tutorial, se ha explorado cómo crear una aplicación de respuesta a preguntas que interactúe con los datos privados mediante Cosmos DB como almacén de vectores. Al aprovechar la arquitectura de generación aumentada de recuperación (RAG) con LangChain y Azure OpenAI, hemos demostrado cómo los almacenes de vectores son esenciales para las aplicaciones de LLM.
La RAG es un avance significativo en la inteligencia artificial, especialmente en el procesamiento de lenguaje natural, y la combinación de estas tecnologías permite la creación de aplicaciones eficaces controladas por inteligencia artificial para varios casos de uso.