Replicación entre regiones en el núcleo virtual de Azure Cosmos DB for MongoDB
SE APLICA A: ![]() núcleo virtual de MongoDB
núcleo virtual de MongoDB
En este artículo se describe la recuperación ante desastres entre regiones (DR) para núcleo virtual de Azure Cosmos DB for MongoDB. También trata las funcionalidades de lectura de las réplicas de clúster en otras regiones para la escalabilidad de las operaciones de lectura.
La característica de replicación entre regiones permite replicar datos de un clúster en un clúster de solo lectura en otra región de Azure. Las réplicas se actualizan con tecnología de replicación asincrónica. Puede tener una réplica de clúster en otra región de elección para el clúster principal de núcleo virtual de Azure Cosmos DB for MongoDB. En un caso excepcional de interrupción de la región, puede promover la réplica de clúster en otra región para convertirse en el nuevo clúster de lectura y escritura para el funcionamiento continuo de la base de datos de MongoDB. Es posible que las aplicaciones sigan usando las mismas cadenas de conexión después de que la réplica del clúster de otra región se promueva para convertirse en el nuevo clúster principal.
Las réplicas son clústeres nuevos que se administran de forma similar a los clústeres normales. En cada réplica de lectura, se le cobra por el proceso aprovisionado en núcleos virtuales y el almacenamiento aprovisionado en GiB/mes. Los costos de proceso y almacenamiento de los clústeres de réplica tienen la misma estructura que los clústeres normales y los precios de la región de Azure donde se crean.
Recuperación ante desastres mediante réplicas de lectura de clúster
La replicación entre regiones es uno de los varios pilares importantes de la estrategia de continuidad empresarial y recuperación ante desastres (BCDR) de Azure. La replicación entre regiones replica de forma asincrónica las mismas aplicaciones y datos en otras regiones de Azure para la protección mediante la recuperación ante desastres. No todos los servicios de Azure replican automáticamente los datos ni se replican automáticamente desde una región con errores para la replicación cruzada en otra región habilitada. El núcleo virtual de Azure Cosmos DB for MongoDB proporciona una opción para crear una réplica de clúster en otra región y hacer que los datos escritos en el clúster principal se repliquen automáticamente en esa réplica. La reserva a la réplica del clúster si hay una interrupción en la región primaria debe iniciarse manualmente.
Cuando la replicación entre regiones está habilitada en un clúster de núcleo virtual de Azure Cosmos DB for MongoDB, cada partición se replica en otra región continuamente. Esta replicación mantiene una réplica de datos en la región seleccionada. Esta réplica está lista para usarse como parte del plan de recuperación ante desastres en un caso excepcional de interrupción de la región primaria. La replicación es asincrónica. Las operaciones de escritura en la partición del clúster principal no esperan a que se complete la replicación en la partición de la réplica correspondiente antes de enviar la confirmación de una escritura correcta. La replicación asincrónica ayuda a evitar mayores latencias para las operaciones de escritura en el clúster principal.
Escrituras continuas, operaciones de lectura en réplicas de clúster y cadenas de conexión
La cadena de conexión global de lectura y escritura en Azure Cosmos DB for MongoDB dirige constantemente las escrituras al clúster habilitado para escritura activa. Al iniciar una promoción de clúster de réplica, el clúster de réplicas de la región B cambia al modo de escritura, mientras que el clúster principal original de la región A pasa a solo lectura. Antes de la promoción, la cadena de conexión global de lectura y escritura tiene como destino el clúster principal de la región A y a continuación, se actualiza para que apunte a la región B a medida que asume las responsabilidades de escritura. En el caso de las aplicaciones que usan la cadena de conexión global de lectura y escritura, las operaciones de escritura continúan sin problemas durante el proceso de promoción, manteniendo un flujo de datos ininterrumpido.
Los clústeres de réplica también están disponibles para lecturas. Ayuda a descargar operaciones de lectura intensivas del clúster principal o a ofrecer una latencia reducida para las operaciones de lectura a los clientes que se encuentran más cerca de la región de replicación. Cuando la replicación entre regiones está habilitada, las aplicaciones pueden usar la cadena de conexión de autoservicio del clúster de réplica para realizar lecturas de la réplica del clúster. El clúster principal está disponible para las operaciones de lectura y escritura mediante su propia cadena de conexión.
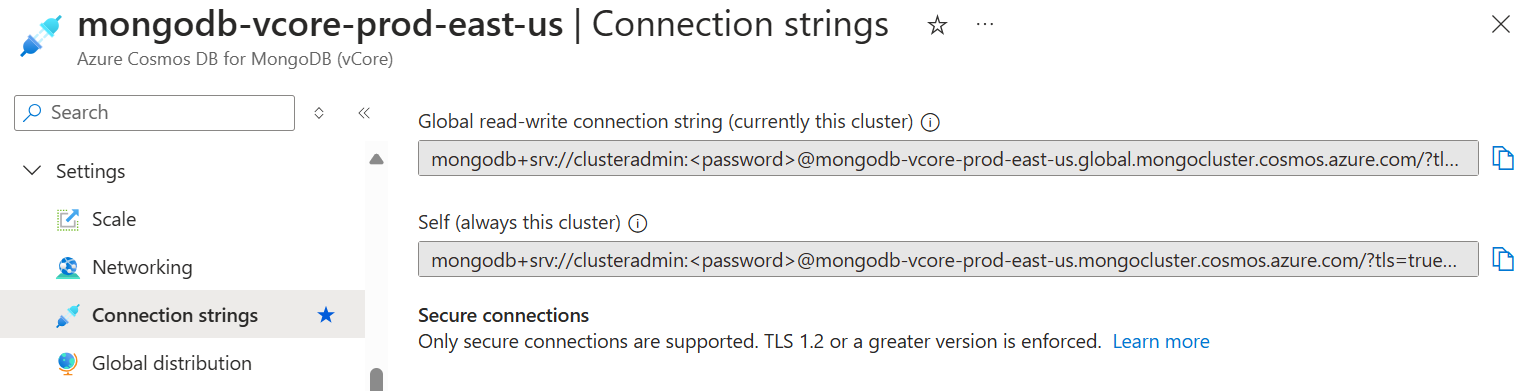
Al crear una réplica habilitando la replicación entre regiones, no hereda la configuración de red, como las reglas de firewall del clúster principal. Esta configuración debe establecerse de forma independiente para la réplica. La réplica hereda la cuenta de administrador del clúster principal. Las cuentas de usuario deben administrarse en el clúster principal. Puede conectarse al clúster principal y a su clúster de réplica mediante las mismas cuentas de usuario.
Promoción del clúster de réplica
Si se produce una interrupción de una región, puede realizar una operación de recuperación ante desastres si promueve la réplica del clúster en otra región para que esté disponible para las escrituras. Durante la operación de promoción de réplicas, se realizan estos pasos:
- Las escrituras en la réplica de la región B están habilitadas además de lecturas. La réplica anterior se convierte en un nuevo clúster de lectura y escritura.
- El clúster de réplica promocionado de la región B acepta escrituras mediante su cadena de conexión y la cadena de conexión global de lectura y escritura.
- El clúster de la región A se establece en de solo lectura y mantiene su cadena de conexión.
Importante
Dado que la replicación es asincrónica, es posible que algunos datos del clúster de la región A no se repliquen en la región B cuando se promueve la réplica del clúster en la región B. Si este es el caso, la promoción daría lugar a que los datos no replicados no estuvieran presentes en ambos clústeres.
Contenido relacionado
- Aprenda a habilitar la replicación entre regiones y a promover el clúster de réplicas
- Consulte límites y limitaciones de replicación entre regiones
- Para resolver un problema con la replicación entre regiones, consulte esta guía de solución de problemas.
- Obtenga más información sobre la confiabilidad en núcleo virtual de Azure Cosmos DB for MongoDB