Migración de datos de Cassandra a una cuenta para Apache Cassandra de Azure Cosmos DB mediante Azure Databricks
SE APLICA A: ![]() Cassandra
Cassandra
API para Cassandra para Azure Cosmos DB se ha convertido en una excelente opción para cargas de trabajo empresariales que se ejecutan en Apache Cassandra por varios motivos:
No hay sobrecarga de administración y supervisión: evita la sobrecarga que supone administrar y supervisar las configuraciones en el sistema operativo y JVM, así como los archivos YAML y sus interacciones.
Importante ahorro de costos: puede ahorrar costos con Azure Cosmos DB, como en el costo de las máquinas virtuales, del ancho de banda y de las licencias aplicables. No tiene que administrar los centros de datos, los servidores, el almacenamiento en SSD, las redes y los costos de electricidad.
Posibilidad de usar código y herramientas existentes: Azure Cosmos DB proporciona compatibilidad de nivel de protocolo de conexión con SDK y herramientas existentes de Cassandra. Esta compatibilidad garantiza que pueda usar el código base existente para Apache Cassandra de Azure Cosmos DB con cambios triviales.
Hay varias maneras de migrar las cargas de trabajo de base de datos de una plataforma a otra. Azure Databricks es una oferta de plataforma como servicio (PaaS) para Apache Spark que proporciona una forma de realizar migraciones sin conexión a gran escala. En este artículo se describen los pasos necesarios para migrar datos de espacios de claves y tablas nativos de Apache Cassandra para Apache Cassandra de Azure Cosmos DB mediante Azure Databricks.
Prerrequisitos
Aprovisionamiento de una cuenta de Azure Cosmos DB para Apache Cassandra.
Consulte las características compatibles en Apache Cassandra de Azure Cosmos DB para garantizar la compatibilidad.
Asegúrese de que ya ha creado un espacio de claves y tablas sin contenido en la cuenta de Apache Cassandra de Azure Cosmos DB de destino.
Aprovisionar un clúster de Azure Databricks
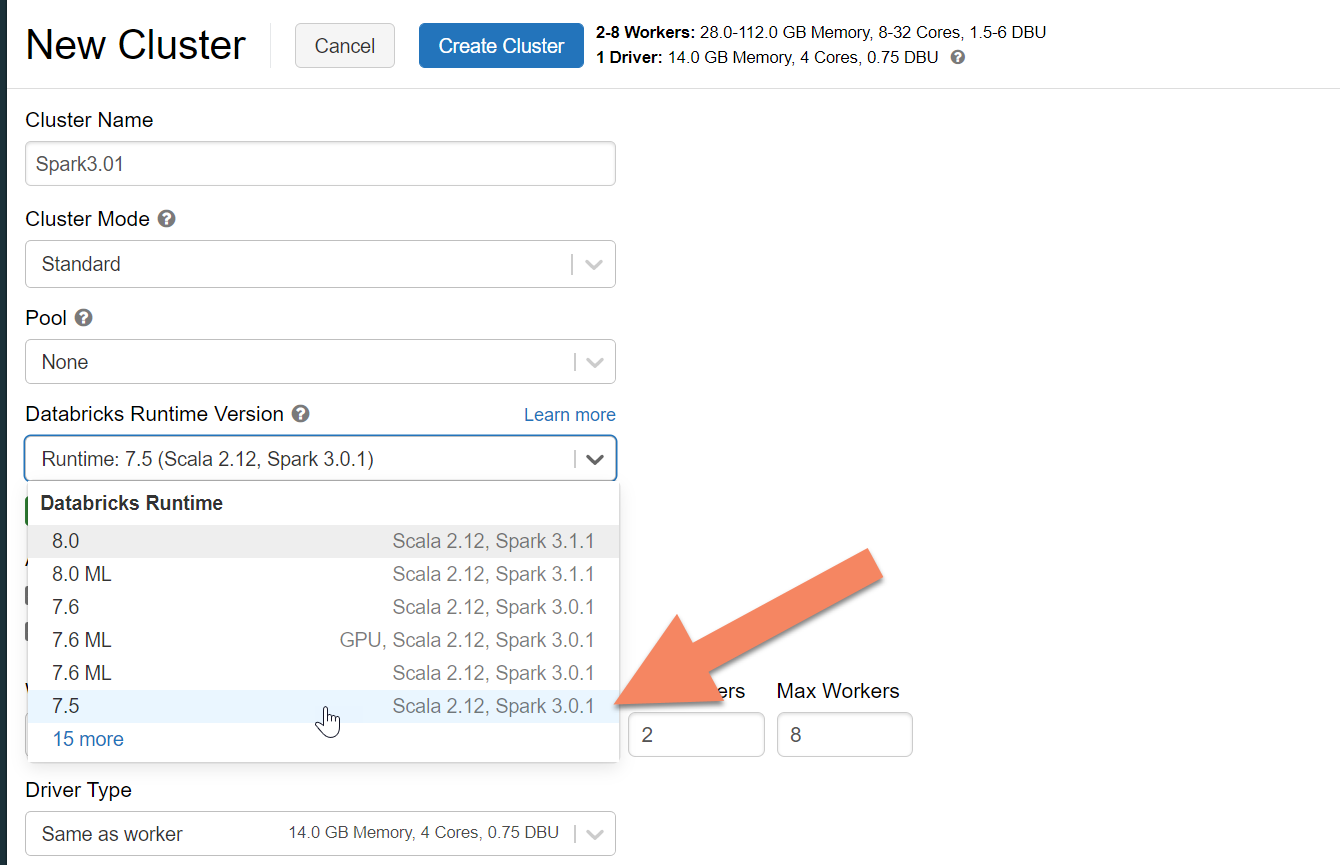
Puede seguir las instrucciones para aprovisionar un clúster de Azure Databricks. Se recomienda seleccionar el entorno de ejecución de Databricks Runtime versión 7.5, que admite Spark 3.0:
Adición de dependencias
Tiene que agregar la biblioteca de conectores de Cassandra de Apache Spark a su clúster para conectarse a los puntos de conexión nativos y de Cassandra de Azure Cosmos DB. En el clúster, seleccione Libraries>Install New>Maven (Bibliotecas > Instalar nueva > Maven) y, después, agregue com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 en las coordenadas de Maven.

Seleccione Install (Instalar) y asegúrese de reiniciar el clúster cuando se complete la instalación.
Nota
Asegúrese de reiniciar el clúster de Databricks después de que se haya instalado la biblioteca de conectores de Cassandra.
Advertencia
Los ejemplos que se muestran en este artículo se han probado con Spark versión 3.0.1 y el conector de Cassandra Spark com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 correspondiente. Es posible que las versiones posteriores de Spark o del conector de Cassandra no funcionen según lo previsto.
Creación de un cuaderno de Scala para la migración
Cree un cuaderno de Scala en Databricks. Reemplace las configuraciones de Cassandra de origen y de destino con las credenciales correspondientes, así como los espacios de claves y las tablas de origen y destino. Después, ejecute el código siguiente:
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val nativeCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "false",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val cosmosCassandra = Map(
"spark.cassandra.connection.host" -> "<USERNAME>.cassandra.cosmos.azure.com",
"spark.cassandra.connection.port" -> "10350",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
//"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "1", // Spark 3.x
"spark.cassandra.connection.connections_per_executor_max"-> "1", // Spark 2.x
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//Read from native Cassandra
val DFfromNativeCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(nativeCassandra)
.load
//Write to CosmosCassandra
DFfromNativeCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(cosmosCassandra)
.mode(SaveMode.Append) // only required for Spark 3.x
.save
Nota
Los valores spark.cassandra.output.batch.size.rowsspark.cassandra.output.concurrent.writes y el número de trabajos del clúster de Spark son configuraciones importantes para optimizar con el fin de evitar la limitación de velocidad. La limitación de velocidad se produce cuando las solicitudes de Azure Cosmos DB superan el rendimiento aprovisionado o las unidades de solicitud (RU). Es posible que tenga que ajustar esta configuración en función del número de ejecutores del clúster de Spark y, potencialmente, del tamaño (y, por consiguiente, el costo de unidad de solicitud) de cada registro que se escribe en las tablas de destino.
Solución de problemas
Limitación de frecuencia (error 429)
Es posible que vea un código de error 429 o un error de tipo "La tasa de solicitudes es grande", incluso si ha reducido la configuración a sus valores mínimos. Los siguientes escenarios pueden provocar la limitación de velocidad:
El rendimiento asignado a la tabla es inferior a 6000 unidades de solicitud . Incluso con una configuración mínima, Spark podrá ejecutar escrituras a una velocidad de alrededor de 6000 unidades de solicitud o más. Si ha aprovisionado una tabla en un espacio de claves con un rendimiento compartido, es posible que esta tabla tenga menos de 6000 RU disponibles en tiempo de ejecución.
Asegúrese de que la tabla a la que va a migrar tenga al menos 6000 RU disponibles al ejecutar la migración. Si es necesario, asigne unidades de solicitud dedicadas a esa tabla.
Asimetría de datos excesiva con grandes volúmenes de datos. Si tiene una gran cantidad de datos para migrar a una tabla determinada, pero tiene una asimetría significativa en los datos (es decir, un gran número de registros que se escriben para el mismo valor de clave de partición), es posible que experimente una limitación de velocidad aunque tenga varias unidades de solicitud aprovisionadas en la tabla. Las unidades de solicitud se dividen equitativamente entre las particiones físicas y, una asimetría de datos intensiva puede causar un cuello de botella de las solicitudes en una única partición.
En este escenario, reduzca a la configuración de rendimiento mínima en Spark y fuerce la ejecución lenta de la migración. Este escenario puede ser más común al migrar las tablas de referencia o de control, donde el acceso es menos frecuente, pero la asimetría puede ser alta. Sin embargo, si hay una asimetría significativa en cualquier otro tipo de tabla, puede querer revisar el modelo de datos para evitar problemas de partición frecuentes para la carga de trabajo durante las operaciones de estado estable.