Aprovisionamiento del análisis a escala de la nube
Proceso de implementación de la zona de aterrizaje de administración de datos
El equipo de operaciones de la plataforma de datos es responsable de implementar una zona de aterrizaje de administración de datos. La zona de aterrizaje de administración de datos debe tener su propio repositorio mantenido por el equipo de operaciones de la plataforma de datos.
Cautela
Cree e implemente una zona de aterrizaje de administración de datos antes de implementar cualquier zona de aterrizaje de datos.
Proceso de implementación de zona de aterrizaje de datos
Teams puede usar plantillas proporcionadas por el equipo de operaciones de la plataforma de datos para evitar empezar desde cero para cada recurso. Se recomienda un patrón de bifurcación para automatizar la implementación de una nueva zona de aterrizaje.
Por ejemplo, un equipo de operaciones de zona de aterrizaje de datos solicita una nueva zona de aterrizaje de datos mediante una herramienta de administración de TI o Power Apps. Tras la aprobación de la solicitud, inicie el siguiente flujo de trabajo mediante parámetros de la solicitud:
- Implemente una nueva suscripción para la nueva zona de aterrizaje de datos.
- Bifurque la rama principal de la plantilla de zona de aterrizaje de datos para crear un nuevo repositorio.
- Cree una conexión de servicio en el nuevo repositorio.
- Actualice los parámetros del nuevo repositorio en función de los parámetros de la solicitud.
- Cree una canalización de implementación para implementar los servicios, desencadenada por el registro de los parámetros actualizados.
- Notifique al equipo de operaciones de la zona de aterrizaje de datos que la nueva zona de aterrizaje está disponible.
El equipo de operaciones de la zona de aterrizaje de datos ahora puede cambiar o agregar plantillas de Azure Resource Manager.
Este flujo de trabajo se puede automatizar mediante varios conjuntos de servicios en la plataforma Azure. Gestione algunos de los pasos, como cambiar el nombre de los parámetros en los archivos de parámetros, mediante canalizaciones de CI/CD. Otros pasos se pueden ejecutar mediante otras herramientas de orquestación de flujo de trabajo, como Logic Apps.
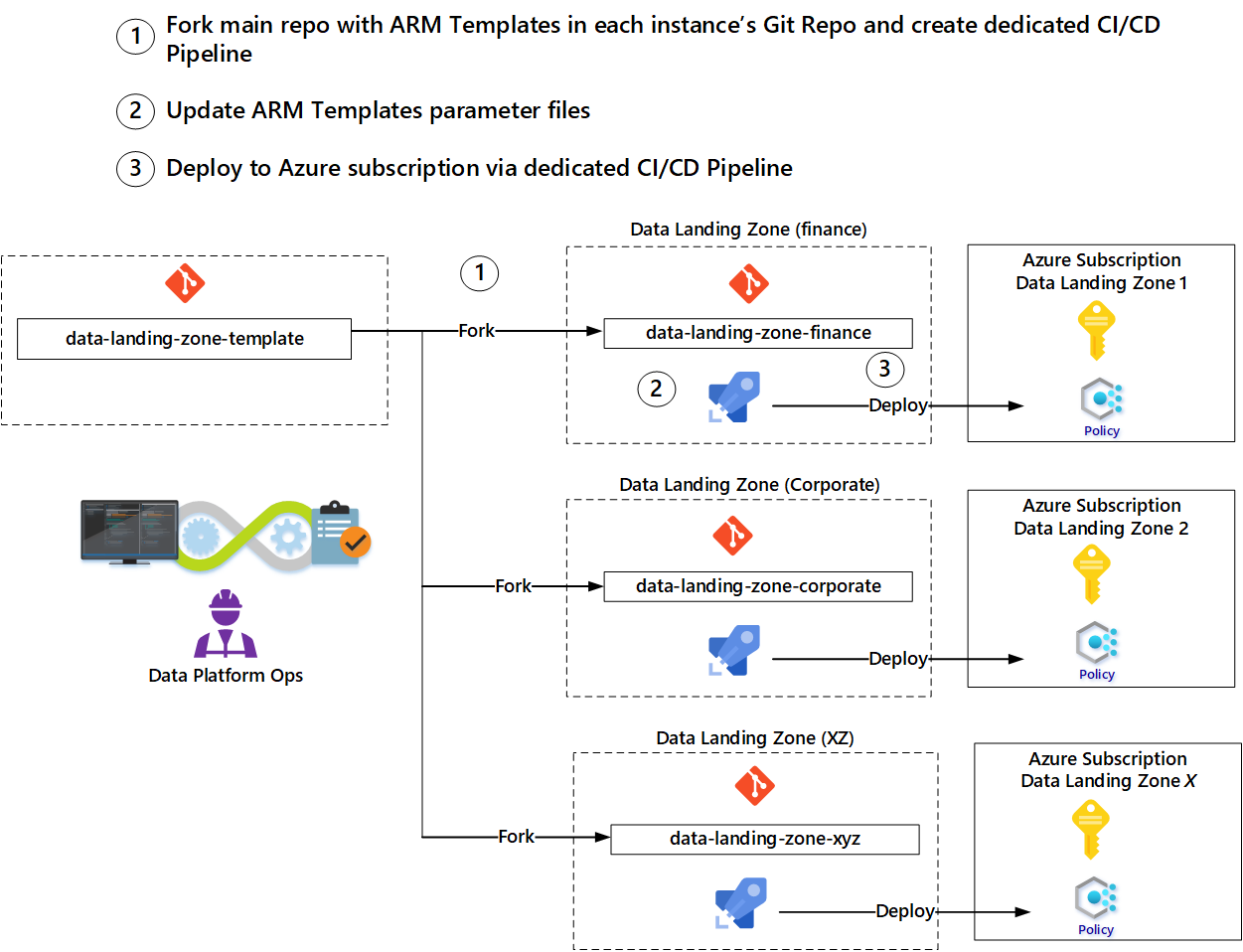
El patrón de bifurcación permite a los equipos actualizar sus plantillas a partir de las plantillas originales usadas para bifurcarlas. Además, si se implementan mejoras o nuevas características en los repositorios de plantillas, los equipos de operaciones pueden extraerlas en su bifurcación.
Adopte procedimientos recomendados para repositorios, como:
- Proteja la rama principal.
- Use ramas para cambios, actualizaciones y mejoras.
- Defina los responsables de código que aprueban los pull requests antes de integrar los cambios en la rama principal.
- Valide las ramas mediante pruebas automatizadas.
- Limite el número de acciones y personas del equipo, como quién puede desencadenar canalizaciones de compilación y versión.
Sugerencia
Coordinar las actividades entre equipos para asegurarse de que las mejoras o las nuevas características de las plantillas originales se replican en todas las instancias de zona de aterrizaje de datos. Los equipos de operaciones pueden extraer los cambios de plantilla originales en su bifurcación.
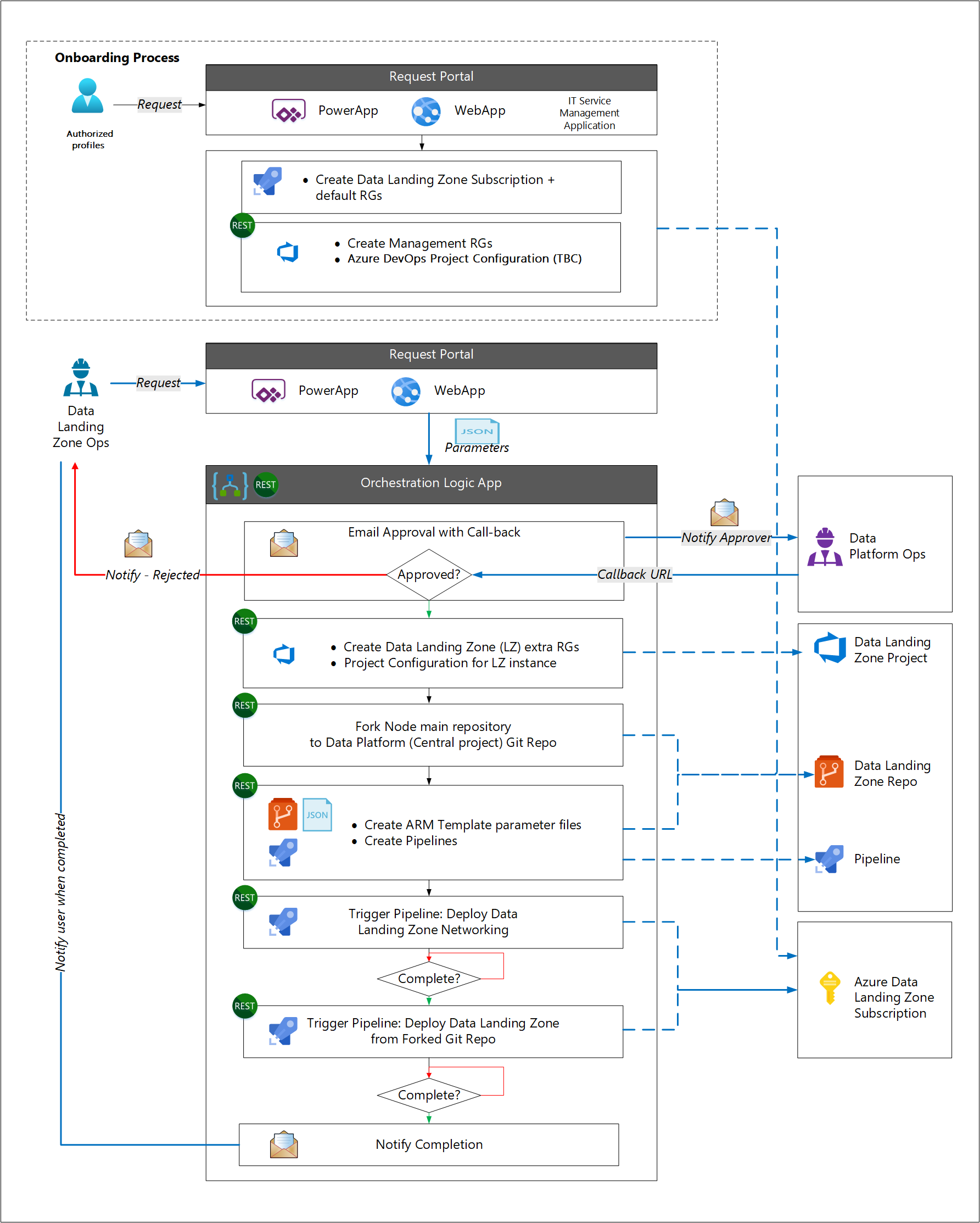
El proceso de incorporación es independiente del proceso de implementación de la zona de aterrizaje de datos. Esta separación se basa en la suposición de que la mayoría de las organizaciones tienen un proceso de implementación de suscripción de Azure estándar como parte de su modelo operativo en la nube. El proceso de incorporación implementa componentes corporativos estándar (como una herramienta de administración de servicios de TI de terceros). Los componentes específicos de la zona de aterrizaje de datos se implementan a continuación.
No hay api de Git disponibles para clonar, actualizar, confirmar o insertar en la solución de automatización propuesta. Por lo tanto, nuestro enfoque consiste en usar una cuenta de Automatización de Azure que contenga libros de ejecución de PowerShell que:
- Configuración de una zona de aterrizaje de datos
- Bifurcar el repositorio principal en un repositorio de Git de plataforma de datos
- Configuración de las configuraciones de subred para la zona de aterrizaje de datos
- Configuración de Microsoft Entra ID
Los runbooks usan funciones de Git del módulo de PowerShell de GitAutomation para trabajar con repositorios de Git. Al instalar este módulo dentro de una cuenta de Azure Automation, los usuarios pueden crear, clonar, consultar, insertar, extraer y confirmar operaciones en repositorios de Git. En la imagen siguiente se muestra el módulo GitAutomation instalado dentro de una cuenta de Azure Automation:

Use la función Copy-GitRepository del módulo GitAutomation para clonar el repositorio de Git principal desde la dirección URL especificada por URL a la ruta de acceso de Git de la plataforma de datos especificada por DestinationPath.
Este enfoque para la implementación de la zona de aterrizaje de datos es flexible, a la vez que garantiza que las acciones son compatibles con los requisitos de la organización. La administración del ciclo de vida se habilita aplicando nuevas características o optimizaciones de las plantillas originales.
Proceso de implementación de aplicaciones de datos
Una vez creada una zona de aterrizaje de datos, la incorporación puede iniciarse para los equipos de aplicaciones de datos. Los equipos de operaciones de la plataforma de datos o de la zona de aterrizaje de datos otorgan la aprobación para la implementación.
La implementación se realiza directamente mediante herramientas de DevOps o mediante canalizaciones o flujos de trabajo expuestos como APIs. De forma similar a la zona de recepción de datos, la implementación comienza con la creación de una copia derivada del repositorio de aplicaciones de datos original.
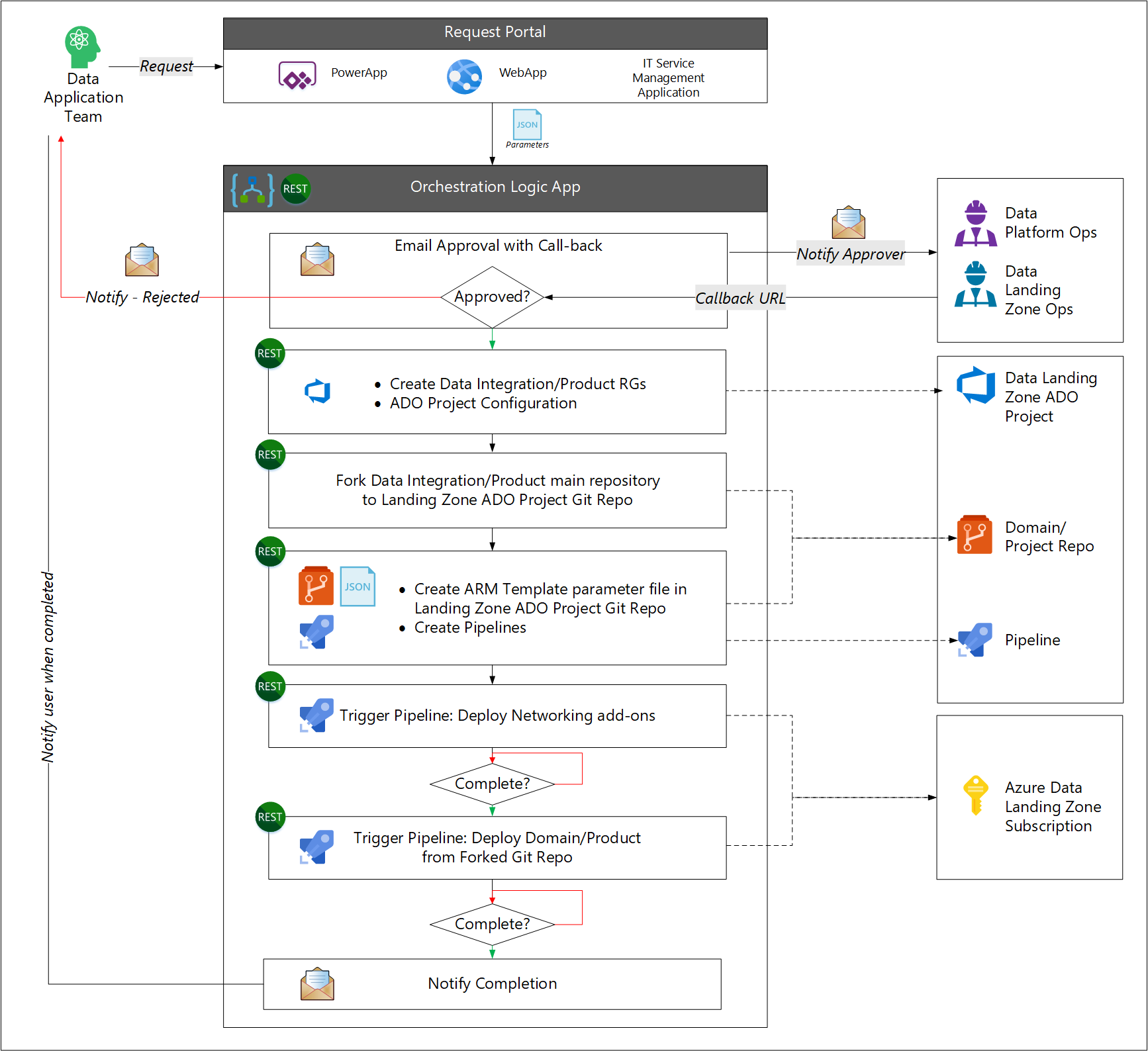
- El usuario realiza una solicitud de nuevos servicios de aplicación de datos.
- El proceso de flujo de trabajo solicita la aprobación del equipo de operaciones de la plataforma de datos o de la zona de aterrizaje de datos.
- El flujo de trabajo llama a la API de administración de servicios de TI para crear grupos de recursos necesarios y crear una conexión de servicio de Azure DevOps. El flujo de trabajo asigna un equipo al proyecto de Azure DevOps.
- El flujo de trabajo clona el repositorio de la aplicación de datos original para crear el proyecto de destino en Azure DevOps.
- El flujo de trabajo crea un archivo de parámetros de plantilla para Azure Resource Manager y las canalizaciones.
- A continuación, el flujo de trabajo inicia una canalización de Azure para crear los requisitos de red y otra canalización de Azure para implementar los servicios de aplicación de datos.
- El flujo de trabajo notifica al usuario al finalizar.
Sugerencia
Si es nuevo en DataOps, revise el laboratorio práctico DataOps para el almacenamiento de datos moderno en el Centro de arquitectura de Azure. El escenario del laboratorio describe una oficina ficticia de planificación urbana que puede usar esta solución de implementación. La solución de implementación proporciona una canalización de datos de un extremo a otro que sigue el patrón de arquitectura del almacenamiento de datos moderno, junto con los procesos correspondientes de DevOps y DataOps, para evaluar el uso del estacionamiento y tomar decisiones empresariales informadas.
Resumen
Los patrones anteriores proporcionan control, agilidad, autoservicio y administración del ciclo de vida de las directivas.
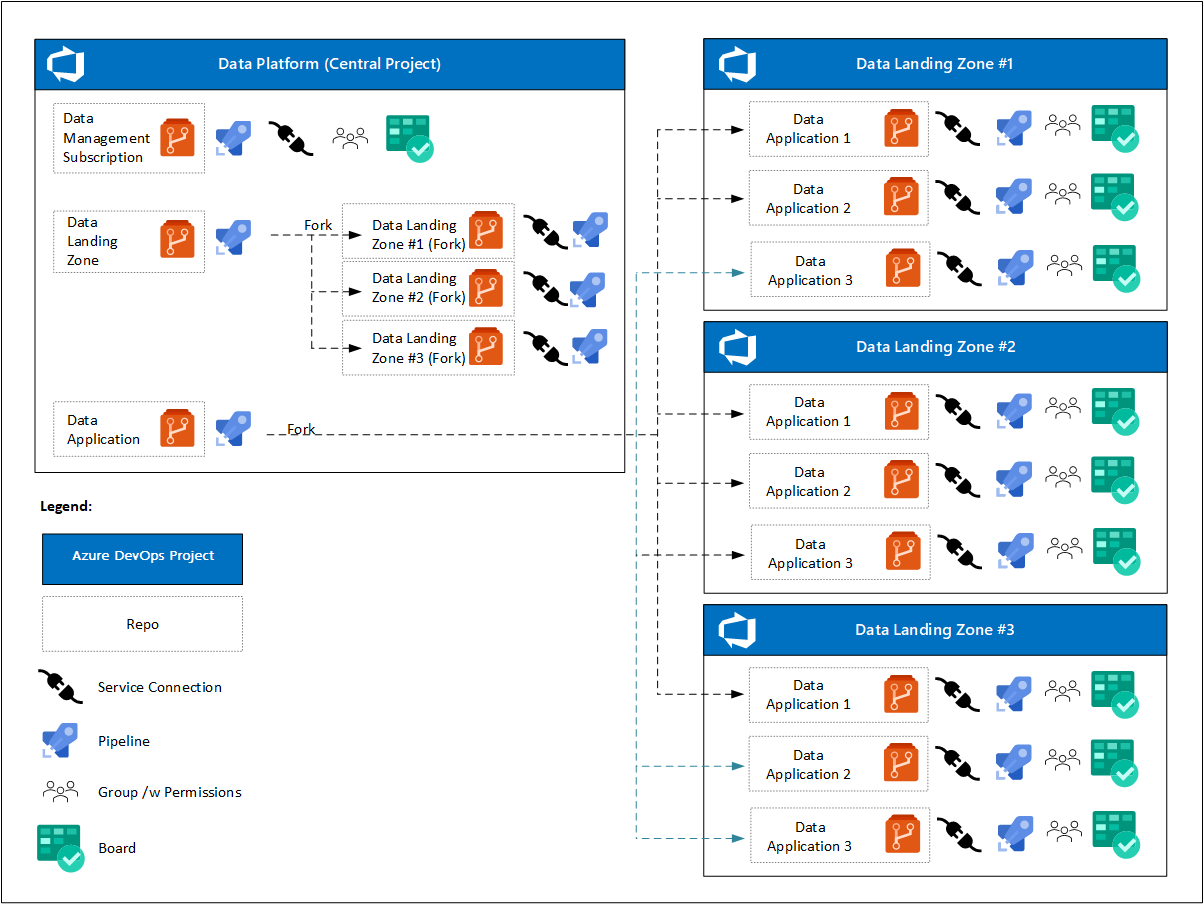
Al principio del proyecto, la plataforma de datos tiene un proyecto de Azure DevOps con una o varias instancias de Azure Boards. Los equipos individuales de DevOps se centran en:
- Un repositorio para la zona de aterrizaje de administración de datos, las canalizaciones y una conexión de servicio al entorno en la nube.
- Un repositorio de plantillas para la zona de aterrizaje de datos, canalizaciones para implementar una instancia de zona de aterrizaje de datos y conexiones de servicio a entornos en la nube.
- Un repositorio de plantillas para servicios de productos de datos, canalizaciones para implementar una instancia de producto de datos y conexiones de servicio a entornos en la nube. Estas conexiones se bifurcan desde la zona de aterrizaje de Azure DevOps Projects.
Una vez implementadas las zonas de aterrizaje de datos, el análisis a escala de la nube prescribe lo siguiente:
- Cada zona de aterrizaje de datos tendrá su propio proyecto de Azure DevOps con una o varias instancias de Azure Boards.
- Para cada aplicación de datos, su bifurcación del proyecto de Azure DevOps de la zona de aterrizaje de datos se crea después de la aprobación de la solicitud.
- Cada aplicación de datos incluye:
- Una conexión de servicio.
- Una canalización registrada.
- Un equipo de DevOps con acceso a su panel y repositorio de Azure.
- Un conjunto diferente de directivas para el repositorio bifurcado.
Para controlar la implementación de aplicaciones de datos, siga estos procedimientos:
- El equipo de operaciones de la zona de recepción de datos posee y protege la rama del repositorio principal.
- Solo se usa la rama principal para implementar en entornos de prueba y producción.
- Las ramas de funcionalidades pueden implementarse en entornos de desarrollo.
- Las ramas funcionales son propiedad de los equipos de DataOps. Se usan para probar características nuevas o modificadas.
- Los equipos de DataOps pueden combinar ramas de funciones en otras ramas de funciones sin aprobación.
- Los equipos de DataOps crean una solicitud de incorporación de cambios para combinar ramas de características en la rama principal y el equipo de operaciones de la zona de aterrizaje de datos proporciona aprobación.
- Las nuevas características o mejoras de las plantillas originales se combinan en el repositorio bifurcado para mantenerlo actualizado.