Tutorial: Configuración de grupos de disponibilidad para SQL Server en máquinas virtuales de Ubuntu en Azure
En este tutorial, aprenderá a:
- Cree máquinas virtuales y colóquelas en un conjunto de disponibilidad
- Habilitar una alta disponibilidad
- Creación de un clúster de Pacemaker
- Configurar un agente de barrera mediante la creación de un dispositivo STONITH
- Instalación de SQL Server y mssql-tools en Ubuntu
- Configurar grupos de disponibilidad AlwaysOn de SQL Server
- Configurar recursos de grupo de disponibilidad en el clúster de Pacemaker
- Probar una conmutación por error y el agente de barrera
Nota:
Comunicación sin prejuicios
Este artículo contiene referencias al término esclavo, que Microsoft considera ofensivo cuando se usa en este contexto. El término aparece en este artículo porque actualmente aparece en el software. Cuando se quite el término del software, se quitará también del artículo.
En este tutorial se utiliza la CLI de Azure para implementar los recursos en Azure.
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Requisitos previos
Use el entorno de Bash en Azure Cloud Shell. Para más información, consulte Inicio rápido para Bash en Azure Cloud Shell.

Si prefiere ejecutar comandos de referencia de la CLI localmente, instale la CLI de Azure. Si utiliza Windows o macOS, considere la posibilidad de ejecutar la CLI de Azure en un contenedor Docker. Para más información, vea Ejecución de la CLI de Azure en un contenedor de Docker.
Si usa una instalación local, inicie sesión en la CLI de Azure mediante el comando az login. Siga los pasos que se muestran en el terminal para completar el proceso de autenticación. Para ver otras opciones de inicio de sesión, consulte Inicio de sesión con la CLI de Azure.
En caso de que se le solicite, instale las extensiones de la CLI de Azure la primera vez que la use. Para más información sobre las extensiones, consulte Uso de extensiones con la CLI de Azure.
Ejecute az version para buscar cuál es la versión y las bibliotecas dependientes que están instaladas. Para realizar la actualización a la versión más reciente, ejecute az upgrade.
- En este artículo se necesita la versión 2.0.30 de la CLI de Azure, o cualquier versión posterior. Si usa Azure Cloud Shell, ya está instalada la versión más reciente.
Crear un grupo de recursos
Si tiene varias suscripciones, establezca la suscripción en la que desea implementar estos recursos.
Use el siguiente comando para crear un grupo de recursos <resourceGroupName> en una región. Reemplace <resourceGroupName> por un nombre de su elección. En este tutorial se usa East US 2. Para más información, consulte el siguiente inicio rápido.
az group create --name <resourceGroupName> --location eastus2
Crear un conjunto de disponibilidad
El primer paso consiste en crear un conjunto de disponibilidad. Ejecute el siguiente comando en Azure Cloud Shell y reemplace <resourceGroupName> por el nombre del grupo de recursos. Elija un nombre para <availabilitySetName>.
az vm availability-set create \
--resource-group <resourceGroupName> \
--name <availabilitySetName> \
--platform-fault-domain-count 2 \
--platform-update-domain-count 2
Debería obtener los siguientes resultados cuando se complete el comando:
{
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/availabilitySets/<availabilitySetName>",
"location": "eastus2",
"name": "<availabilitySetName>",
"platformFaultDomainCount": 2,
"platformUpdateDomainCount": 2,
"proximityPlacementGroup": null,
"resourceGroup": "<resourceGroupName>",
"sku": {
"capacity": null,
"name": "Aligned",
"tier": null
},
"statuses": null,
"tags": {},
"type": "Microsoft.Compute/availabilitySets",
"virtualMachines": []
}
Creación de una red virtual y una subred
Cree una subred con nombre con un intervalo de direcciones IP asignado previamente. Reemplace estos valores en el siguiente comando:
<resourceGroupName><vNetName><subnetName>
az network vnet create \ --resource-group <resourceGroupName> \ --name <vNetName> \ --address-prefix 10.1.0.0/16 \ --subnet-name <subnetName> \ --subnet-prefix 10.1.1.0/24El comando anterior crea una red virtual y una subred que contiene un intervalo IP personalizado.
Creación de máquinas virtuales de Ubuntu en el conjunto de disponibilidad
Obtenga una lista de imágenes de máquinas virtuales que ofrecen un sistema operativo basado en Ubuntu en Azure.
az vm image list --all --offer "sql2022-ubuntupro2004"Debería ver los siguientes resultados al buscar imágenes BYOS:
[ { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.230808", "version": "16.0.230808" } ]En este tutorial se usa
Ubuntu 20.04.Importante
Los nombres de las máquinas deben tener menos de 15 caracteres para configurar un grupo de disponibilidad. Los nombres de usuario no pueden contener caracteres en mayúsculas y las contraseñas deben entre 12 y 72 caracteres.
Cree tres máquinas virtuales en el conjunto de disponibilidad. Reemplace estos valores en el siguiente comando:
<resourceGroupName><VM-basename><availabilitySetName><VM-Size>: un ejemplo sería "Standard_D16s_v3".<username><adminPassword><vNetName><subnetName>
for i in `seq 1 3`; do az vm create \ --resource-group <resourceGroupName> \ --name <VM-basename>$i \ --availability-set <availabilitySetName> \ --size "<VM-Size>" \ --os-disk-size-gb 128 \ --image "Canonical:0001-com-ubuntu-server-jammy:20_04-lts-gen2:latest" \ --admin-username "<username>" \ --admin-password "<adminPassword>" \ --authentication-type all \ --generate-ssh-keys \ --vnet-name "<vNetName>" \ --subnet "<subnetName>" \ --public-ip-sku Standard \ --public-ip-address "" done
El comando anterior crea las máquinas virtuales usando la red virtual definida anteriormente. Para más información sobre las distintas configuraciones, consulte el artículo az vm create.
El comando también incluye el parámetro --os-disk-size-gb para crear un tamaño de unidad de sistema operativo personalizado de 128 GB. Si aumenta este tamaño más adelante, expanda los volúmenes de carpetas adecuados para acomodar la instalación. Configure el Administrador de volúmenes lógicos (LVM).
Debe obtener resultados similares a los siguientes una vez que el comando se complete para cada máquina virtual:
{
"fqdns": "",
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/virtualMachines/ubuntu1",
"location": "westus",
"macAddress": "<Some MAC address>",
"powerState": "VM running",
"privateIpAddress": "<IP1>",
"resourceGroup": "<resourceGroupName>",
"zones": ""
}
Prueba de la conexión a las máquinas virtuales creadas
Conéctese a cada máquina virtual con el siguiente comando en Azure Cloud Shell. Si no encuentra las direcciones IP de las máquinas virtuales, siga las indicaciones que se proporcionan en Inicio rápido para Azure Cloud Shell.
ssh <username>@<publicIPAddress>
Si la conexión se realiza correctamente, verá la siguiente salida que representa el terminal de Linux:
[<username>@ubuntu1 ~]$
Escriba exit para salir de la sesión de SSH.
Configuración del acceso SSH sin contraseña entre nodos
El acceso SSH sin contraseña permite que las máquinas virtuales se comuniquen entre sí mediante claves públicas SSH. Debe configurar claves SSH en cada nodo y copiar esas claves en todos los nodos.
Generación de claves SSH nuevas
El tamaño de clave SSH necesario es de 4096 bits. En cada máquina virtual, cambie a la carpeta /root/.ssh y ejecute el siguiente comando:
ssh-keygen -t rsa -b 4096
Durante este paso, es posible que se le pida que sobrescriba un archivo SSH. Debe aceptar esta petición. No tiene que escribir ninguna frase de contraseña.
Copia de las claves SSH públicas
En cada máquina virtual, debe copiar la clave pública del nodo que acaba de crear con el comando ssh-copy-id. Si desea especificar un directorio de la máquina virtual de destino, puede usar el parámetro -i.
En el siguiente comando, la cuenta <username> puede ser la misma que configuró para cada nodo cuando creó la máquina virtual. También puede usar la root cuenta, pero esta opción no se recomienda en un entorno de producción.
sudo ssh-copy-id <username>@ubuntu1
sudo ssh-copy-id <username>@ubuntu2
sudo ssh-copy-id <username>@ubuntu3
Comprobación del acceso sin contraseña desde cada nodo
Para confirmar que la clave pública SSH se ha copiado en todos los nodos, use el comando ssh desde cada nodo. Si copió correctamente las claves, no se le pide una contraseña y la conexión se realiza correctamente.
En este ejemplo, nos conectamos a los nodos segundo y tercero desde la primera máquina virtual (ubuntu1). Una vez más, la cuenta <username> puede ser la misma que configuró para cada nodo cuando creó la máquina virtual.
ssh <username>@ubuntu2
ssh <username>@ubuntu3
Repita este proceso desde los tres nodos para que cada nodo pueda comunicarse con los demás sin necesidad de contraseñas.
Configuración de la resolución de nombres
Puede configurar la resolución de nombres mediante DNS o editando manualmente el archivo etc/hosts en cada nodo.
Para obtener más información sobre DNS y Active Directory, consulte Unión de SQL Server en un host de Linux a un dominio de Active Directory.
Importante
Se recomienda usar la dirección IP privada del ejemplo anterior. El uso de la dirección IP pública en esta configuración producirá un error en la configuración y expondrá la máquina virtual a redes externas.
Las máquinas virtuales y las direcciones IP usadas en este ejemplo se enumeran de la siguiente manera:
ubuntu1: 10.0.0.85ubuntu2: 10.0.0.86ubuntu3: 10.0.0.87
Habilitación de la alta disponibilidad
Use ssh para conectarse a cada una de las 3 máquinas virtuales y, una vez conectado, ejecute los siguientes comandos para habilitar la alta disponibilidad.
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
sudo systemctl restart mssql-server
Instalar y configurar el clúster de Pacemaker
Para empezar a configurar el clúster de Pacemaker, debe instalar los paquetes necesarios y los agentes de recursos. Ejecute los siguientes comandos en cada una de las máquinas virtuales:
sudo apt-get install -y pacemaker pacemaker-cli-utils crmsh resource-agents fence-agents csync2 python3-azure
Ahora, continúe con la creación de la clave de autenticación en el servidor principal:
sudo corosync-keygen
La clave de autenticación se genera en la ubicación /etc/corosync/authkey. Copie la clave de autenticación en los servidores secundarios de esta ubicación: /etc/corosync/authkey
sudo scp /etc/corosync/authkey username@ubuntu2:~
sudo scp /etc/corosync/authkey username@ubuntu3:~
Mueva la clave de autenticación del directorio principal a /etc/corosync.
sudo mv authkey /etc/corosync/authkey
Proceda a crear el clúster mediante los siguientes comandos:
cd /etc/corosync/
sudo vi corosync.conf
Edite el archivo Corosync para representar contenidos de la siguiente manera:
totem {
version: 2
secauth: off
cluster_name: demo
transport: udpu
}
nodelist {
node {
ring0_addr: 10.0.0.85
name: ubuntu1
nodeid: 1
}
node {
ring0_addr: 10.0.0.86
name: ubuntu2
nodeid: 2
}
node {
ring0_addr: 10.0.0.87
name: ubuntu3
nodeid: 3
}
}
quorum {
provider: corosync_votequorum
two_node: 0
}
qb {
ipc_type: native
}
logging {
fileline: on
to_stderr: on
to_logfile: yes
logfile: /var/log/corosync/corosync.log
to_syslog: no
debug: off
}
Copie el archivo corosync.conf en otros nodos en /etc/corosync/corosync.conf:
sudo scp /etc/corosync/corosync.conf username@ubuntu2:~
sudo scp /etc/corosync/corosync.conf username@ubuntu3:~
sudo mv corosync.conf /etc/corosync/
Reinicie Pacemaker y Corosync y confirme el estado:
sudo systemctl restart pacemaker corosync
sudo crm status
El resultado es similar al ejemplo siguiente:
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by hacluster via crmd on ubuntu1
* 3 nodes configured
* 0 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* No resources
Configuración del agente de barrera
Configure la barrera en el clúster. La barrera es el aislamiento del nodo con errores en un clúster. Reinicie el nodo con errores, lo que deja que se apague, restablezca y vuelva a ponerse en marcha y vuelva a unir el clúster.
Para configurar barreras, realice las siguientes acciones:
- Registre una aplicación con Microsoft Entra ID y cree un secreto
- Cree un rol personalizado a partir de un archivo JSON en powershell o la CLI
- Asigne el rol y la aplicación a las máquinas virtuales del clúster
- Establezca las propiedades del agente de barrera
Registre una aplicación con Microsoft Entra ID y cree un secreto
- Vaya a Microsoft Entra ID en el portal y anote el identificador de inquilino.
- En el menú de la izquierda, seleccione Registros de aplicaciones y luego Nuevo registro.
- Escriba un nombre y seleccione Solo las cuentas de este directorio organizativo.
- En Tipo de aplicación, seleccione Web, escriba
http://localhostcomo dirección URL de inicio de sesión y, a continuación, seleccione Registrar. - En el menú de la izquierda, seleccione Certificados y secretos y, después, Nuevo secreto de cliente.
- Escriba una descripción y seleccione un tiempo de expiración.
- Anote el valor del secreto, se usa como la contraseña siguiente y el ID del secreto, que se usa como nombre de usuario siguiente.
- Seleccione "Información general" y anote el ID de la aplicación. Se usa como el siguiente inicio de sesión.
Cree un archivo JSON llamado fence-agent-role.json y agregue lo siguiente (agregando el ID de suscripción):
{
"Name": "Linux Fence Agent Role-ap-server-01-fence-agent",
"Id": null,
"IsCustom": true,
"Description": "Allows to power-off and start virtual machines",
"Actions": [
"Microsoft.Compute/*/read",
"Microsoft.Compute/virtualMachines/powerOff/action",
"Microsoft.Compute/virtualMachines/start/action"
],
"NotActions": [],
"AssignableScopes": [
"/subscriptions/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX"
]
}
Creación de un rol personalizado a partir de un archivo JSON en PowerShell o la CLI
az role definition create --role-definition fence-agent-role.json
Asigne el rol y la aplicación a las máquinas virtuales del clúster
- Para cada una de las máquinas virtuales del clúster, seleccione Control de acceso (IAM) en el menú lateral.
- Seleccione Agregar una asignación de roles (use la experiencia clásica).
- Seleccione el rol creado anteriormente.
- En la lista Seleccionar, escriba el nombre de la aplicación que creó anteriormente.
Ahora podemos crear el recurso del agente de barrera mediante los valores anteriores y el identificador de suscripción:
sudo crm configure primitive fence-vm stonith:fence_azure_arm \
params \
action=reboot \
resourceGroup="resourcegroupname" \
resourceGroup="$resourceGroup" \
username="$secretId" \
login="$applicationId" \
passwd="$password" \
tenantId="$tenantId" \
subscriptionId="$subscriptionId" \
pcmk_reboot_timeout=900 \
power_timeout=60 \
op monitor \
interval=3600 \
timeout=120
Establezca las propiedades del agente de barrera
Ejecute los comandos siguientes para configurar las propiedades del agente de barrera:
sudo crm configure property cluster-recheck-interval=2min
sudo crm configure property start-failure-is-fatal=true
sudo crm configure property stonith-timeout=900
sudo crm configure property concurrent-fencing=true
sudo crm configure property stonith-enabled=true
Y confirme el estado del clúster:
sudo crm status
El resultado es similar al ejemplo siguiente:
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 1 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* fence-vm (stonith:fence_azure_arm): Started ubuntu1
Instalación de SQL Server y mssql-tools
Utilice los comandos siguientes para instalar SQL Server:
Importe las claves de GPG del repositorio público:
curl https://packages.microsoft.com/keys/microsoft.asc | sudo tee /etc/apt/trusted.gpg.d/microsoft.ascRegistre el repositorio de Ubuntu:
sudo add-apt-repository "$(wget -qO- https://packages.microsoft.com/config/ubuntu/20.04/mssql-server-2022.list)"Ejecute los comandos siguientes para instalar SQL Server:
sudo apt-get update sudo apt-get install -y mssql-serverCuando finalice la instalación del paquete, ejecute
mssql-conf setupy siga las indicaciones para establecer la contraseña de administrador del sistema y elegir la edición. Como recordatorio, las siguientes ediciones tienen licencia gratuita: Evaluation, Developer y Express.sudo /opt/mssql/bin/mssql-conf setupCuando finalice la configuración, compruebe que el servicio se esté ejecutando:
systemctl status mssql-server --no-pagerInstalación de las herramientas de línea de comandos de SQL Server
Para crear una base de datos, necesita conectarse con una herramienta que pueda ejecutar instrucciones Transact-SQL en SQL Server. En los pasos siguientes, se instalan las herramientas de línea de comandos de SQL Server sqlcmd y bcp.
Siga estos pasos para instalar mssql-tools18 en Ubuntu.
Nota:
- Ubuntu 18.04 se admite a partir de SQL Server 2019 CU 3.
- Ubuntu 20.04 se admite a partir de SQL Server 2019 CU 10.
- Ubuntu 22.04 se admite a partir de SQL Server 2022 CU 10.
Acceda al modo de superusuario.
sudo suImporte las claves de GPG del repositorio público.
curl https://packages.microsoft.com/keys/microsoft.asc | sudo tee /etc/apt/trusted.gpg.d/microsoft.ascRegistre el repositorio de Ubuntu de Microsoft.
Para Ubuntu 22.04, utilice el siguiente comando:
curl https://packages.microsoft.com/config/ubuntu/22.04/prod.list > /etc/apt/sources.list.d/mssql-release.listPara Ubuntu 20.04, utilice el siguiente comando:
curl https://packages.microsoft.com/config/ubuntu/20.04/prod.list > /etc/apt/sources.list.d/mssql-release.listPara Ubuntu 18.04, utilice el siguiente comando:
curl https://packages.microsoft.com/config/ubuntu/18.04/prod.list > /etc/apt/sources.list.d/mssql-release.listPara Ubuntu 16.04, utilice el siguiente comando:
curl https://packages.microsoft.com/config/ubuntu/16.04/prod.list > /etc/apt/sources.list.d/mssql-release.list
Salga del modo de superusuario.
exitActualice la lista de orígenes y ejecute el comando de instalación con el paquete para desarrolladores de unixODBC.
sudo apt-get update sudo apt-get install mssql-tools18 unixodbc-devNota:
Para actualizar a la versión más reciente de mssql-tools, ejecute los siguientes comandos:
sudo apt-get update sudo apt-get install mssql-tools18Opcional: agregue
/opt/mssql-tools18/bin/a la variable de entornoPATHen un shell de Bash.Para que sqlcmd y bcp sean accesibles desde el shell de Bash para inicios de sesión, modifique la variable
PATHen el archivo~/.bash_profilecon el comando siguiente:echo 'export PATH="$PATH:/opt/mssql-tools18/bin"' >> ~/.bash_profilePara que sqlcmd y bcp sean accesibles desde el intérprete de comandos bash para sesiones interactivas/no de inicio de sesión, modifica el
PATHen el archivo~/.bashrccon el siguiente comando:echo 'export PATH="$PATH:/opt/mssql-tools18/bin"' >> ~/.bashrc source ~/.bashrc
Instalación del agente de alta disponibilidad de SQL Server
Ejecute el siguiente comando en todos los nodos para instalar el paquete del agente de alta disponibilidad de SQL Server:
sudo apt-get install mssql-server-ha
Configuración de un grupo de disponibilidad
Utilice los siguientes pasos para configurar un grupo de disponibilidad AlwaysOn de SQL Server para las máquinas virtuales. Para más información, consulte Configuración de un grupo de disponibilidad AlwaysOn de SQL Server para alta disponibilidad en Linux.
Habilitación de grupos de disponibilidad y reinicio de SQL Server
Habilite grupos de disponibilidad en cada nodo donde se hospede una instancia de SQL Server. A continuación, reinicie el servicio mssql-server. Ejecute los siguientes comandos en cada nodo:
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
sudo systemctl restart mssql-server
Crear un certificado
Microsoft no admite la autenticación de Active Directory en el punto de conexión del grupo de disponibilidad. Por tanto, debe usar un certificado para el cifrado del punto de conexión del grupo de disponibilidad.
Conéctese a todos los nodos por medio de SQL Server Management Studio (SSMS) o sqlcmd. Ejecute los siguientes comandos para habilitar la sesión de AlwaysOn_health y crear una clave maestra:
Importante
Si se conecta de forma remota a la instancia de SQL Server, deberá tener el puerto 1433 abierto en el firewall. También tendrá que permitir conexiones entrantes al puerto 1433 en el grupo de seguridad de red de cada máquina virtual. Para más información, consulte Creación de una regla de seguridad para crear una regla de seguridad de entrada.
- Reemplace
<MasterKeyPassword>por su propia contraseña.
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE = ON); GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<MasterKeyPassword>'; GO- Reemplace
Conéctese a la réplica principal por medio de SSMS o sqlcmd. Los comandos siguientes crean un certificado en
/var/opt/mssql/data/dbm_certificate.cery una clave privada envar/opt/mssql/data/dbm_certificate.pvken la réplica principal de SQL Server:- Reemplace
<PrivateKeyPassword>por su propia contraseña.
CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; GO BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<PrivateKeyPassword>' ); GO- Reemplace
Salga de la sesión de sqlcmd ejecutando el comando exit y vuelva a la sesión de SSH.
Copia del certificado en las réplicas secundarias y creación de los certificados en el servidor
Copie los dos archivos que se crearon en la misma ubicación en todos los servidores que hospedarán las réplicas de disponibilidad.
En el servidor principal, ejecute el siguiente comando
scppara copiar el certificado en los servidores de destino:- Reemplace
<username>ysles2por el nombre de usuario y el nombre de la máquina virtual de destino que está usando. - Ejecute este comando para todas las réplicas secundarias.
Nota:
No tiene que ejecutar
sudo -i, lo que le proporciona el entorno raíz. En su lugar, puede ejecutar el comandosudodelante de cada comando.# The below command allows you to run commands in the root environment sudo -iscp /var/opt/mssql/data/dbm_certificate.* <username>@sles2:/home/<username>- Reemplace
En el servidor de destino, ejecute el siguiente comando:
- Reemplace
<username>por el nombre de usuario. - El comando
mvmueve los archivos o directorios de un lugar a otro. - El comando
chownse usa para cambiar el propietario y el grupo de archivos, directorios o vínculos. - Ejecute estos comandos para todas las réplicas secundarias.
sudo -i mv /home/<username>/dbm_certificate.* /var/opt/mssql/data/ cd /var/opt/mssql/data chown mssql:mssql dbm_certificate.*- Reemplace
El script de Transact-SQL siguiente crea un certificado a partir de la copia de seguridad creada en la réplica principal de SQL Server. Actualice el script con contraseñas seguras. La contraseña de descifrado es la misma que se usó para crear el archivo .pvk en el paso anterior. Para crear el certificado, ejecute el siguiente script con sqlcmd o SSMS en todos los servidores secundarios:
CREATE CERTIFICATE dbm_certificate FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<PrivateKeyPassword>' ); GO
Crear los puntos de conexión de creación de reflejo de la base de datos en todas las réplicas
Ejecute el siguiente script en todas las instancias de SQL Server por medio de sqlcmd o SSMS:
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
GO
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
GO
Crear el grupo de disponibilidad
Conéctese a la instancia de SQL Server que hospeda la réplica principal con sqlcmd o SSMS. Ejecute el siguiente comando para crear el grupo de disponibilidad:
- Reemplace
ag1por el nombre del grupo de disponibilidad que desee. - Reemplace los valores
ubuntu1,ubuntu2yubuntu3con los nombres de las instancias de SQL Server que hospedan las réplicas.
CREATE AVAILABILITY
GROUP [ag1]
WITH (
DB_FAILOVER = ON,
CLUSTER_TYPE = EXTERNAL
)
FOR REPLICA
ON N'ubuntu1'
WITH (
ENDPOINT_URL = N'tcp://ubuntu1:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'ubuntu2'
WITH (
ENDPOINT_URL = N'tcp://ubuntu2:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'ubuntu3'
WITH (
ENDPOINT_URL = N'tcp://ubuntu3:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
);
GO
ALTER AVAILABILITY GROUP [ag1]
GRANT CREATE ANY DATABASE;
GO
Crear un inicio de sesión de SQL Server para Pacemaker
En todas las instancias de SQL Server, cree un inicio de sesión de SQL Server para Pacemaker. La siguiente instrucción Transact-SQL crea un inicio de sesión.
- Reemplace
<password>por una contraseña propia compleja.
USE [master]
GO
CREATE LOGIN [pacemakerLogin]
WITH PASSWORD = N'<password>';
GO
ALTER SERVER ROLE [sysadmin]
ADD MEMBER [pacemakerLogin];
GO
En todas las instancias de SQL Server, guarde las credenciales usadas para el inicio de sesión de SQL Server.
Cree el archivo:
sudo vi /var/opt/mssql/secrets/passwdAgregue las dos líneas siguientes al archivo:
pacemakerLogin <password>Para salir del editor de vi, primero presione la tecla Esc y, a continuación, escriba el comando
:wqpara escribir en el archivo y salir.Haga que solo el usuario raíz pueda leer el archivo:
sudo chown root:root /var/opt/mssql/secrets/passwd sudo chmod 400 /var/opt/mssql/secrets/passwd
Conexión de las réplicas secundarias al grupo de disponibilidad
En las réplicas secundarias, ejecute los siguientes comandos para conectarlas al grupo de disponibilidad:
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOEjecute el script de Transact-SQL siguiente en la réplica principal y en cada una de las réplicas secundarias:
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::ag1 TO pacemakerLogin; GO GRANT VIEW SERVER STATE TO pacemakerLogin; GOUna vez que se conectan las réplicas secundarias, puede verlas en el Explorador de objetos de SSMS expandiendo el nodo de alta disponibilidad de Always On:
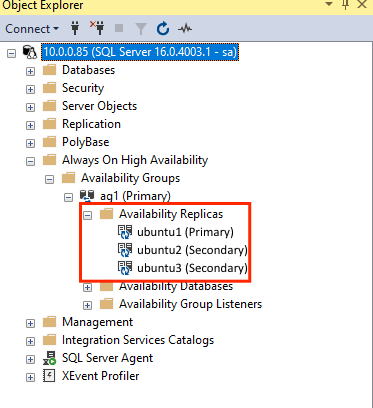
Agregar una base de datos al grupo de disponibilidad
En esta sección se sigue el artículo para agregar una base de datos a un grupo de disponibilidad.
Se utilizan los siguientes comandos de Transact-SQL en este paso. Ejecute estos comandos en la réplica principal:
CREATE DATABASE [db1]; -- creates a database named db1
GO
ALTER DATABASE [db1] SET RECOVERY FULL; -- set the database in full recovery mode
GO
BACKUP DATABASE [db1] -- backs up the database to disk
TO DISK = N'/var/opt/mssql/data/db1.bak';
GO
ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [db1]; -- adds the database db1 to the AG
GO
Compruebe que la base de datos se crea en los servidores secundarios.
En todas las réplicas secundarias de SQL Server, ejecute la consulta siguiente para ver si se ha creado la base de datos db1 y su estado es SINCRONIZADO:
SELECT * FROM sys.databases
WHERE name = 'db1';
GO
SELECT DB_NAME(database_id) AS 'database',
synchronization_state_desc
FROM sys.dm_hadr_database_replica_states;
GO
Si synchronization_state_desc muestra SINCRONIZADO para db1, esto significa que las réplicas están sincronizadas. En las secundarias aparece db1 en la réplica principal.
Creación de recursos de grupo de disponibilidad en el clúster de Pacemaker
Para crear el recurso de grupo de disponibilidad en Pacemaker, ejecute los siguientes comandos:
sudo crm
configure
primitive ag1_cluster \
ocf:mssql:ag \
params ag_name="ag1" \
meta failure-timeout=60s \
op start timeout=60s \
op stop timeout=60s \
op promote timeout=60s \
op demote timeout=10s \
op monitor timeout=60s interval=10s \
op monitor timeout=60s on-fail=demote interval=11s role="Master" \
op monitor timeout=60s interval=12s role="Slave" \
op notify timeout=60s
ms ms-ag1 ag1_cluster \
meta master-max="1" master-node-max="1" clone-max="3" \
clone-node-max="1" notify="true"
commit
Este comando anterior crea el recurso ag1_cluster, es decir, el recurso de grupo de disponibilidad. A continuación, crea el recurso ms-ag1 (recurso principal o secundario en Pacemaker y, a continuación, agrega el recurso de grupo de disponibilidad a él. Esto garantiza que el recurso de grupo de disponibilidad se ejecute en los tres nodos del clúster, pero solo uno de esos nodos es principal).
Para ver el recurso de grupo de grupo de disponibilidad y comprobar el estado del clúster:
sudo crm resource status ms-ag1
sudo crm status
El resultado es similar al ejemplo siguiente:
resource ms-ag1 is running on: ubuntu1 Master
resource ms-ag1 is running on: ubuntu3
resource ms-ag1 is running on: ubuntu2
La salida es similar a la del siguiente ejemplo. Para agregar restricciones de ubicación y promoción, consulte Tutorial: Configuración de un agente de escucha de grupo de disponibilidad en máquinas virtuales Linux.
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 4 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* Clone Set: ms-ag1 [ag1_cluster] (promotable):
* Masters: [ ubuntu1 ]
* Slaves : [ ubuntu2 ubuntu3 ]
* fence-vm (stonith:fence_azure_arm): Started ubuntu1
Ejecute el siguiente comando para crear un recurso de grupo, de modo que las restricciones de ubicación y promoción aplicadas al agente de escucha y el equilibrador de carga no tengan que aplicarse individualmente.
sudo crm configure group virtualip-group azure-load-balancer virtualip
El resultado de crm status será similar al siguiente ejemplo:
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 6 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* Clone Set: ms-ag1 [ag1_cluster] (promotable):
* Masters: [ ubuntu1 ]
* Slaves : [ ubuntu2 ubuntu3 ]
* Resource Group: virtual ip-group:
* azure-load-balancer (ocf :: heartbeat:azure-lb): Started ubuntu1
* virtualip (ocf :: heartbeat: IPaddr2): Started ubuntu1
* fence-vm (stonith:fence_azure_arm): Started ubuntu1