Tutorial: Configuración de grupos de disponibilidad para SQL Server en máquinas virtuales SLES en Azure
Se aplica a: ![]() SQL Server en máquina virtual de Azure
SQL Server en máquina virtual de Azure
Nota:
En este tutorial se usa SQL Server 2022 (16.x) con SUSE Linux Enterprise Server (SLES) v15, pero puede usar SQL Server 2019 (15.x) con SLES v12 o SLES v15 para configurar la alta disponibilidad.
En este tutorial, aprenderá a:
- Crear un nuevo grupo de recursos, un conjunto de disponibilidad y máquinas virtuales Linux
- Habilitar una alta disponibilidad
- Creación de un clúster de Pacemaker
- Configurar un agente de barrera mediante la creación de un dispositivo STONITH
- Instalar SQL Server y mssql-tools en SLES
- Configurar grupos de disponibilidad AlwaysOn de SQL Server
- Configurar recursos de grupo de disponibilidad en el clúster de Pacemaker
- Probar una conmutación por error y el agente de barrera
En este tutorial se utiliza la CLI de Azure para implementar los recursos en Azure.
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Requisitos previos
Use el entorno de Bash en Azure Cloud Shell. Para más información, consulte Inicio rápido para Bash en Azure Cloud Shell.

Si prefiere ejecutar comandos de referencia de la CLI localmente, instale la CLI de Azure. Si utiliza Windows o macOS, considere la posibilidad de ejecutar la CLI de Azure en un contenedor Docker. Para más información, vea Ejecución de la CLI de Azure en un contenedor de Docker.
Si usa una instalación local, inicie sesión en la CLI de Azure mediante el comando az login. Siga los pasos que se muestran en el terminal para completar el proceso de autenticación. Para ver otras opciones de inicio de sesión, consulte Inicio de sesión con la CLI de Azure.
En caso de que se le solicite, instale las extensiones de la CLI de Azure la primera vez que la use. Para más información sobre las extensiones, consulte Uso de extensiones con la CLI de Azure.
Ejecute az version para buscar cuál es la versión y las bibliotecas dependientes que están instaladas. Para realizar la actualización a la versión más reciente, ejecute az upgrade.
- En este artículo se necesita la versión 2.0.30 de la CLI de Azure, o cualquier versión posterior. Si usa Azure Cloud Shell, ya está instalada la versión más reciente.
Crear un grupo de recursos
Si tiene varias suscripciones, indique la suscripción en la que desea implementar estos recursos.
Use el siguiente comando para crear un grupo de recursos <resourceGroupName> en una región. Reemplace <resourceGroupName> por un nombre de su elección. En este tutorial se usa East US 2. Para más información, consulte el siguiente inicio rápido.
az group create --name <resourceGroupName> --location eastus2
Crear un conjunto de disponibilidad
El primer paso consiste en crear un conjunto de disponibilidad. Ejecute el siguiente comando en Azure Cloud Shell y reemplace <resourceGroupName> por el nombre del grupo de recursos. Elija un nombre para <availabilitySetName>.
az vm availability-set create \
--resource-group <resourceGroupName> \
--name <availabilitySetName> \
--platform-fault-domain-count 2 \
--platform-update-domain-count 2
Debería obtener los siguientes resultados cuando se complete el comando:
{
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/availabilitySets/<availabilitySetName>",
"location": "eastus2",
"name": "<availabilitySetName>",
"platformFaultDomainCount": 2,
"platformUpdateDomainCount": 2,
"proximityPlacementGroup": null,
"resourceGroup": "<resourceGroupName>",
"sku": {
"capacity": null,
"name": "Aligned",
"tier": null
},
"statuses": null,
"tags": {},
"type": "Microsoft.Compute/availabilitySets",
"virtualMachines": []
}
Creación de una red virtual y una subred
Cree una subred con nombre con un intervalo de direcciones IP asignado previamente. Reemplace estos valores en el siguiente comando:
<resourceGroupName><vNetName><subnetName>
az network vnet create \ --resource-group <resourceGroupName> \ --name <vNetName> \ --address-prefix 10.1.0.0/16 \ --subnet-name <subnetName> \ --subnet-prefix 10.1.1.0/24El comando anterior crea una red virtual y una subred que contiene un intervalo IP personalizado.
Creación de máquinas virtuales SLES en el conjunto de disponibilidad
Obtenga una lista de imágenes de máquina virtual que ofrecen SLES v15 SP4 con BYOS (traiga su propia suscripción). También puede usar la máquina virtual de aplicación de revisiones SUSE Enterprise Linux 15 SP4+ (
sles-15-sp4-basic).az vm image list --all --offer "sles-15-sp3-byos" # if you want to search the basic offers you could search using the command below az vm image list --all --offer "sles-15-sp3-basic"Debería ver los siguientes resultados al buscar imágenes BYOS:
[ { "offer": "sles-15-sp3-byos", "publisher": "SUSE", "sku": "gen1", "urn": "SUSE:sles-15-sp3-byos:gen1:2022.05.05", "version": "2022.05.05" }, { "offer": "sles-15-sp3-byos", "publisher": "SUSE", "sku": "gen1", "urn": "SUSE:sles-15-sp3-byos:gen1:2022.07.19", "version": "2022.07.19" }, { "offer": "sles-15-sp3-byos", "publisher": "SUSE", "sku": "gen1", "urn": "SUSE:sles-15-sp3-byos:gen1:2022.11.10", "version": "2022.11.10" }, { "offer": "sles-15-sp3-byos", "publisher": "SUSE", "sku": "gen2", "urn": "SUSE:sles-15-sp3-byos:gen2:2022.05.05", "version": "2022.05.05" }, { "offer": "sles-15-sp3-byos", "publisher": "SUSE", "sku": "gen2", "urn": "SUSE:sles-15-sp3-byos:gen2:2022.07.19", "version": "2022.07.19" }, { "offer": "sles-15-sp3-byos", "publisher": "SUSE", "sku": "gen2", "urn": "SUSE:sles-15-sp3-byos:gen2:2022.11.10", "version": "2022.11.10" } ]En este tutorial se usa
SUSE:sles-15-sp3-byos:gen1:2022.11.10.Importante
Los nombres de las máquinas deben tener menos de 15 caracteres para configurar un grupo de disponibilidad. Los nombres de usuario no pueden contener caracteres en mayúsculas y las contraseñas deben entre 12 y 72 caracteres.
Cree tres máquinas virtuales en el conjunto de disponibilidad. Reemplace estos valores en el siguiente comando:
<resourceGroupName><VM-basename><availabilitySetName><VM-Size>: un ejemplo sería "Standard_D16s_v3".<username><adminPassword><vNetName><subnetName>
for i in `seq 1 3`; do az vm create \ --resource-group <resourceGroupName> \ --name <VM-basename>$i \ --availability-set <availabilitySetName> \ --size "<VM-Size>" \ --os-disk-size-gb 128 \ --image "SUSE:sles-15-sp3-byos:gen1:2022.11.10" \ --admin-username "<username>" \ --admin-password "<adminPassword>" \ --authentication-type all \ --generate-ssh-keys \ --vnet-name "<vNetName>" \ --subnet "<subnetName>" \ --public-ip-sku Standard \ --public-ip-address "" done
El comando anterior crea las máquinas virtuales usando la red virtual definida anteriormente. Para más información sobre las distintas configuraciones, consulte el artículo az vm create.
El comando también incluye el parámetro --os-disk-size-gb para crear un tamaño de unidad de sistema operativo personalizado de 128 GB. Si aumenta este tamaño más adelante, expanda los volúmenes de carpetas adecuados para acomodar la instalación. Configure el Administrador de volúmenes lógicos (LVM).
Debe obtener resultados similares a los siguientes una vez que el comando se complete para cada máquina virtual:
{
"fqdns": "",
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/virtualMachines/sles1",
"location": "westus",
"macAddress": "<Some MAC address>",
"powerState": "VM running",
"privateIpAddress": "<IP1>",
"resourceGroup": "<resourceGroupName>",
"zones": ""
}
Prueba de la conexión a las máquinas virtuales creadas
Conéctese a cada máquina virtual con el siguiente comando en Azure Cloud Shell. Si no encuentra las direcciones IP de las máquinas virtuales, siga las indicaciones que se proporcionan en Inicio rápido para Azure Cloud Shell.
ssh <username>@<publicIPAddress>
Si la conexión se realiza correctamente, verá la siguiente salida que representa el terminal de Linux:
[<username>@sles1 ~]$
Escriba exit para salir de la sesión de SSH.
Registro en SUSEConnect e instalación de paquetes de alta disponibilidad
Para completar este tutorial, las máquinas virtuales deben registrarse en SUSEConnect para recibir actualizaciones y soporte técnico. Después, puede instalar la extensión de alta disponibilidad, o patrón, que es un conjunto de paquetes que habilita la alta disponibilidad.
Es más fácil abrir una sesión de SSH en cada una de las máquinas virtuales (nodos) simultáneamente, ya que se deben ejecutar los mismos comandos en cada máquina virtual a lo largo del artículo.
Si va a copiar y pegar varios comandos sudo y se le pide una contraseña, los comandos adicionales no se ejecutan. Ejecute cada comando por separado.
Conéctese a cada nodo de máquina virtual para ejecutar los siguientes pasos.
Registro de la máquina virtual en SUSEConnect
Para registrar el nodo de máquina virtual en SUSEConnect, reemplace estos valores en el siguiente comando, en todos los nodos:
<subscriptionEmailAddress><registrationCode>
sudo SUSEConnect
--url=https://scc.suse.com
-e <subscriptionEmailAddress> \
-r <registrationCode>
Instalación de la extensión de alta disponibilidad
Para instalar la extensión de alta disponibilidad, ejecute el siguiente comando en todos los nodos:
sudo SUSEConnect -p sle-ha/15.3/x86_64 -r <registration code for Partner Subscription for High Availability Extension>
Configuración del acceso SSH sin contraseña entre nodos
El acceso SSH sin contraseña permite que las máquinas virtuales se comuniquen entre sí mediante claves públicas SSH. Debe configurar claves SSH en cada nodo y copiar esas claves en todos los nodos.
Generación de claves SSH nuevas
El tamaño de clave SSH necesario es de 4096 bits. En cada máquina virtual, cambie a la carpeta /root/.ssh y ejecute el siguiente comando:
ssh-keygen -t rsa -b 4096
Durante este paso, es posible que se le pida que sobrescriba un archivo SSH. Debe aceptar esta petición. No tiene que escribir ninguna frase de contraseña.
Copia de las claves SSH públicas
En cada máquina virtual, debe copiar la clave pública del nodo que acaba de crear con el comando ssh-copy-id. Si desea especificar un directorio de la máquina virtual de destino, puede usar el parámetro -i.
En el siguiente comando, la cuenta <username> puede ser la misma que configuró para cada nodo cuando creó la máquina virtual. También puede usar la root cuenta, pero no se recomienda en un entorno de producción.
sudo ssh-copy-id <username>@sles1
sudo ssh-copy-id <username>@sles2
sudo ssh-copy-id <username>@sles3
Comprobación del acceso sin contraseña desde cada nodo
Para confirmar que la clave pública SSH se ha copiado en todos los nodos, use el comando ssh desde cada nodo. Si copió correctamente las claves, no se le pedirá una contraseña y la conexión se realizará correctamente.
En este ejemplo, nos conectamos a los nodos segundo y tercero desde la primera máquina virtual (sles1). Una vez más, la cuenta <username> puede ser la misma que configuró para cada nodo cuando creó la máquina virtual.
ssh <username>@sles2
ssh <username>@sles3
Repita este proceso desde los tres nodos para que cada nodo pueda comunicarse con los demás sin necesidad de contraseñas.
Configuración de la resolución de nombres
Puede configurar la resolución de nombres mediante DNS o editando manualmente el archivo etc/hosts en cada nodo.
Para obtener más información sobre DNS y Active Directory, consulte Unión de SQL Server en un host de Linux a un dominio de Active Directory.
Importante
Se recomienda usar la dirección IP privada del ejemplo anterior. El uso de la dirección IP pública en esta configuración producirá un error en la configuración y expondrá la máquina virtual a redes externas.
Las máquinas virtuales y las direcciones IP usadas en este ejemplo se enumeran de la siguiente manera:
sles1: 10.0.0.85sles2: 10.0.0.86sles3: 10.0.0.87
Configuración del clúster
En este tutorial, la primera máquina virtual (sles1) es el nodo 1, la segunda máquina virtual (sles2) es el nodo 2 y la tercera máquina virtual (sles3) es el nodo 3. Para obtener más información sobre la instalación de clústeres, consulte Configuración de Pacemaker en SUSE Linux Enterprise Server en Azure.
Instalación del clúster
Ejecute el siguiente comando para instalar el paquete
ha-cluster-bootstrapen el nodo 1 y reinicie el nodo. En este ejemplo, es la máquina virtualsles1.sudo zypper install ha-cluster-bootstrapUna vez reiniciado el nodo, ejecute el siguiente comando para implementar el clúster:
sudo crm cluster init --name sqlclusterVerá un resultado similar al del siguiente ejemplo:
Do you want to continue anyway (y/n)? y Generating SSH key for root The user 'hacluster' will have the login shell configuration changed to /bin/bash Continue (y/n)? y Generating SSH key for hacluster Configuring csync2 Generating csync2 shared key (this may take a while)...done csync2 checking files...done Detected cloud platform: microsoft-azure Configure Corosync (unicast): This will configure the cluster messaging layer. You will need to specify a network address over which to communicate (default is eth0's network, but you can use the network address of any active interface). Address for ring0 [10.0.0.85] Port for ring0 [5405] Configure SBD: If you have shared storage, for example a SAN or iSCSI target, you can use it avoid split-brain scenarios by configuring SBD. This requires a 1 MB partition, accessible to all nodes in the cluster. The device path must be persistent and consistent across all nodes in the cluster, so /dev/disk/by-id/* devices are a good choice. Note that all data on the partition you specify here will be destroyed. Do you wish to use SBD (y/n)? n WARNING: Not configuring SBD - STONITH will be disabled. Hawk cluster interface is now running. To see cluster status, open: https://10.0.0.85:7630/ Log in with username 'hacluster', password 'linux' WARNING: You should change the hacluster password to something more secure! Waiting for cluster..............done Loading initial cluster configuration Configure Administration IP Address: Optionally configure an administration virtual IP address. The purpose of this IP address is to provide a single IP that can be used to interact with the cluster, rather than using the IP address of any specific cluster node. Do you wish to configure a virtual IP address (y/n)? y Virtual IP []10.0.0.89 Configuring virtual IP (10.0.0.89)....done Configure Qdevice/Qnetd: QDevice participates in quorum decisions. With the assistance of a third-party arbitrator Qnetd, it provides votes so that a cluster is able to sustain more node failures than standard quorum rules allow. It is recommended for clusters with an even number of nodes and highly recommended for 2 node clusters. Do you want to configure QDevice (y/n)? n Done (log saved to /var/log/crmsh/ha-cluster-bootstrap.log)Compruebe el estado del clúster en el nodo 1 con el siguiente comando:
sudo crm statusLa salida debe incluir el siguiente texto si se ejecuta correctamente:
1 node configured 1 resource instance configuredEn todos los nodos, cambie la contraseña de
haclustera algo más seguro con el siguiente comando. También debe cambiar la contraseña de usuario deroot:sudo passwd haclustersudo passwd rootEjecute el siguiente comando en el nodo 2 y el nodo 3 para instalar primero el paquete
crmsh:sudo zypper install crmshAhora, ejecute el comando para unirse al clúster:
sudo crm cluster joinEstas son algunas de las interacciones que deben tener lugar:
Join This Node to Cluster: You will be asked for the IP address of an existing node, from which configuration will be copied. If you have not already configured passwordless ssh between nodes, you will be prompted for the root password of the existing node. IP address or hostname of existing node (e.g.: 192.168.1.1) []10.0.0.85 Configuring SSH passwordless with root@10.0.0.85 root@10.0.0.85's password: Configuring SSH passwordless with hacluster@10.0.0.85 Configuring csync2...done Merging known_hosts WARNING: scp to sles2 failed (Exited with error code 1, Error output: The authenticity of host 'sles2 (10.1.1.5)' can't be established. ECDSA key fingerprint is SHA256:UI0iyfL5N6X1ZahxntrScxyiamtzsDZ9Ftmeg8rSBFI. Are you sure you want to continue connecting (yes/no/[fingerprint])? lost connection ), known_hosts update may be incomplete Probing for new partitions...done Address for ring0 [10.0.0.86] Hawk cluster interface is now running. To see cluster status, open: https://10.0.0.86:7630/ Log in with username 'hacluster', password 'linux' WARNING: You should change the hacluster password to something more secure! Waiting for cluster.....done Reloading cluster configuration...done Done (log saved to /var/log/crmsh/ha-cluster-bootstrap.log)Una vez que haya unido todas las máquinas al clúster, compruebe el recurso para ver si todas las máquinas virtuales están en línea:
sudo crm statusDebería ver los siguientes resultados:
Stack: corosync Current DC: sles1 (version 2.0.5+20201202.ba59be712-150300.4.30.3-2.0.5+20201202.ba59be712) - partition with quorum Last updated: Mon Mar 6 18:01:17 2023 Last change: Mon Mar 6 17:10:09 2023 by root via cibadmin on sles1 3 nodes configured 1 resource instance configured Online: [ sles1 sles2 sles3 ] Full list of resources: admin-ip (ocf::heartbeat:IPaddr2): Started sles1Instale el componente de recursos del clúster. Ejecute el siguiente comando en todos los nodos.
sudo zypper in socatInstale el componente
azure-lb. Ejecute el siguiente comando en todos los nodos.sudo zypper in resource-agentsConfigurar el sistema operativo. Siga estos pasos en todos los nodos.
Edite el archivo de configuración:
sudo vi /etc/systemd/system.confCambie el valor de
DefaultTasksMaxa4096:#DefaultTasksMax=512 DefaultTasksMax=4096Guarde los cambios y salga del editor vi.
Para activar esta configuración, ejecute el siguiente comando:
sudo systemctl daemon-reloadCompruebe si el cambio se ha realizado correctamente:
sudo systemctl --no-pager show | grep DefaultTasksMax
Reduzca el tamaño de la caché de datos incorrectos. Siga estos pasos en todos los nodos.
Edite el archivo de configuración del control del sistema:
sudo vi /etc/sysctl.confAgregue las dos líneas siguientes al archivo:
vm.dirty_bytes = 629145600 vm.dirty_background_bytes = 314572800Guarde los cambios y salga del editor vi.
Instale el SDK de Python de Azure en todos los nodos con los siguientes comandos:
sudo zypper install fence-agents # Install the Azure Python SDK on SLES 15 or later: # You might need to activate the public cloud extension first. In this example, the SUSEConnect command is for SLES 15 SP1 SUSEConnect -p sle-module-public-cloud/15.1/x86_64 sudo zypper install python3-azure-mgmt-compute sudo zypper install python3-azure-identity
Configuración del agente de barrera
Un dispositivo STONITH proporciona un agente de barrera. Las instrucciones siguientes se han modificado para este tutorial. Para obtener más información, consulte Configuración de Pacemaker en SUSE Linux Enterprise Server en Azure.
Compruebe la versión del agente de barrera de Azure para asegurarse de que está actualizado. Use el comando siguiente:
sudo zypper info resource-agents
Debería ver una salida similar a la del ejemplo siguiente.
Information for package resource-agents:
----------------------------------------
Repository : SLE-Product-HA15-SP3-Updates
Name : resource-agents
Version : 4.8.0+git30.d0077df0-150300.8.37.1
Arch : x86_64
Vendor : SUSE LLC <https://www.suse.com/>
Support Level : Level 3
Installed Size : 2.5 MiB
Installed : Yes (automatically)
Status : up-to-date
Source package : resource-agents-4.8.0+git30.d0077df0-150300.8.37.1.src
Upstream URL : http://linux-ha.org/
Summary : HA Reusable Cluster Resource Scripts
Description : A set of scripts to interface with several services
to operate in a High Availability environment for both
Pacemaker and rgmanager service managers.
Registro de una nueva aplicación en Microsoft Entra ID
Para registrar una nueva aplicación en Microsoft Entra ID (antes llamado Azure Active Directory), siga estos pasos:
- Ir a https://portal.azure.com.
- Abra el panel de Propiedades de Microsoft Entra ID y anote el
Tenant ID. - Seleccione App registrations (Registros de aplicaciones).
- Seleccione Nuevo registro.
- Escriba un nombre, por ejemplo,
<resourceGroupName>-app. En Tipos de cuenta admitidos, seleccione Solo cuentas de este directorio organizativo (solo de Microsoft - Cuenta empresarial única). - Seleccione Web para URI de redirección y escriba una dirección URL (por ejemplo, http://localhost)) y seleccione Agregar. La dirección URL de inicio de sesión puede ser cualquier dirección URL válida. Una vez hecho esto, seleccione Registrar.
- Elija Certificados y secretos para el nuevo registro de aplicación y haga clic en Nuevo secreto de cliente.
- Escriba una descripción para la nueva clave (secreto de cliente), y seleccione Agregar.
- Anote el valor del secreto. Se usa como contraseña para la entidad de servicio.
- Seleccione Información general. Anote el identificador de la aplicación. Se utiliza como nombre de usuario (identificador de inicio de sesión en los pasos siguientes) de la entidad de servicio.
Creación de un rol personalizado para el agente de barrera
Siga el tutorial para crear un rol personalizado de Azure con la CLI de Azure.
El archivo JSON debe tener un aspecto similar al del ejemplo siguiente.
- Reemplace
<username>por el nombre que prefiera. Esto se hace para evitar la duplicación al crear esta definición de roles. - Reemplace
<subscriptionId>con la identificación de su suscripción de Azure.
{
"Name": "Linux Fence Agent Role-<username>",
"Id": null,
"IsCustom": true,
"Description": "Allows to power-off and start virtual machines",
"Actions": [
"Microsoft.Compute/*/read",
"Microsoft.Compute/virtualMachines/powerOff/action",
"Microsoft.Compute/virtualMachines/start/action"
],
"NotActions": [
],
"AssignableScopes": [
"/subscriptions/<subscriptionId>"
]
}
Para agregar el rol, ejecute el siguiente comando:
- Reemplace
<filename>por el nombre del archivo. - Si va a ejecutar el comando desde una ruta de acceso distinta a la de la carpeta en la que se guarda el archivo, incluya la ruta de acceso de la carpeta del archivo en el comando.
az role definition create --role-definition "<filename>.json"
Debería ver los siguientes resultados:
{
"assignableScopes": [
"/subscriptions/<subscriptionId>"
],
"description": "Allows to power-off and start virtual machines",
"id": "/subscriptions/<subscriptionId>/providers/Microsoft.Authorization/roleDefinitions/<roleNameId>",
"name": "<roleNameId>",
"permissions": [
{
"actions": [
"Microsoft.Compute/*/read",
"Microsoft.Compute/virtualMachines/powerOff/action",
"Microsoft.Compute/virtualMachines/start/action"
],
"dataActions": [],
"notActions": [],
"notDataActions": []
}
],
"roleName": "Linux Fence Agent Role-<username>",
"roleType": "CustomRole",
"type": "Microsoft.Authorization/roleDefinitions"
}
Asignación del rol personalizado a la entidad de servicio
Asigne a la entidad de servicio el rol personalizado Linux Fence Agent Role-<username> que ha creado en el último paso. Repita estos pasos en todos los nodos.
Advertencia
No use el rol Propietario a partir de ahora.
- Vaya a https://portal.azure.com.
- Abra el panel Todos los recursos.
- Seleccione la máquina virtual del primer nodo de clúster.
- Seleccione Access Control (IAM)
- Seleccione Agregar asignación de roles.
- Seleccione el rol
Linux Fence Agent Role-<username>de la lista Rol - Deje Asignar acceso a con el valor predeterminado
Users, group, or service principal. - En la lista Seleccionar, escriba el nombre de la aplicación que creó antes; por ejemplo,
<resourceGroupName>-app. - Seleccione Guardar.
Creación de los dispositivos STONITH
Ejecute los siguientes comandos en el nodo 1:
- Reemplace
<ApplicationID>por el valor del identificador del registro de aplicación. - Reemplace
<servicePrincipalPassword>por el valor del secreto de cliente. - Reemplace
<resourceGroupName>por el grupo de recursos de la suscripción que se usa para este tutorial. - Reemplace los valores de
<tenantID>y<subscriptionId>de su suscripción de Azure.
- Reemplace
Ejecute
crm configurepara abrir el símbolo del sistema de crm:sudo crm configureEn el símbolo del sistema de crm, ejecute el siguiente comando para configurar las propiedades del recurso, con lo que se crea el recurso
rsc_st_azure, como se muestra en el ejemplo siguiente:primitive rsc_st_azure stonith:fence_azure_arm params subscriptionId="subscriptionID" resourceGroup="ResourceGroup_Name" tenantId="TenantID" login="ApplicationID" passwd="servicePrincipalPassword" pcmk_monitor_retries=4 pcmk_action_limit=3 power_timeout=240 pcmk_reboot_timeout=900 pcmk_host_map="sles1:sles1;sles2:sles2;sles3:sles3" op monitor interval=3600 timeout=120 commit quitEjecute los comandos siguientes para configurar el agente de barrera:
sudo crm configure property stonith-timeout=900 sudo crm configure property stonith-enabled=true sudo crm configure property concurrent-fencing=trueCompruebe el estado del clúster para ver que STONITH se ha habilitado:
sudo crm statusDebería ver un resultado similar al texto siguiente:
Stack: corosync Current DC: sles1 (version 2.0.5+20201202.ba59be712-150300.4.30.3-2.0.5+20201202.ba59be712) - partition with quorum Last updated: Mon Mar 6 18:20:17 2023 Last change: Mon Mar 6 18:10:09 2023 by root via cibadmin on sles1 3 nodes configured 2 resource instances configured Online: [ sles1 sles2 sles3 ] Full list of resources: admin-ip (ocf::heartbeat:IPaddr2): Started sles1 rsc_st_azure (stonith:fence_azure_arm): Started sles2
Instalación de SQL Server y mssql-tools
Use la sección siguiente para instalar SQL Server y mssql-tools. Para obtener más información, consulte Inicio rápido: Instalación de SQL Server y creación de una base de datos en SUSE Linux Enterprise Server.
Realice estos pasos en todos los nodos de esta sección.
Instalación de SQL Server en las máquinas virtuales
Utilice los comandos siguientes para instalar SQL Server:
Descargue el archivo de configuración del repositorio de SLES de Microsoft SQL Server 2019:
sudo zypper addrepo -fc https://packages.microsoft.com/config/sles/15/mssql-server-2022.repoActualice los repositorios.
sudo zypper --gpg-auto-import-keys refreshPara asegurarse de que la clave de firma de paquetes de Microsoft está instalada en el sistema, use el siguiente comando para importar la clave:
sudo rpm --import https://packages.microsoft.com/keys/microsoft.ascEjecute los comandos siguientes para instalar SQL Server:
sudo zypper install -y mssql-serverCuando finalice la instalación del paquete, ejecute
mssql-conf setupy siga las indicaciones para establecer la contraseña de administrador del sistema y elegir la edición.sudo /opt/mssql/bin/mssql-conf setupNota
Asegúrese de especificar una contraseña segura para la cuenta del administrador del sistema (longitud mínima de 8 caracteres, incluidas mayúsculas y minúsculas, dígitos en base 10 o símbolos no alfanuméricos).
Cuando finalice la configuración, compruebe que el servicio se esté ejecutando:
systemctl status mssql-server
Instalación de las herramientas de la línea de comandos de SQL Server
En los siguientes pasos, se instalan las herramientas de la línea de comandos de SQL Server sqlcmd y bcp.
Agregue el repositorio de Microsoft SQL Server en Zypper.
sudo zypper addrepo -fc https://packages.microsoft.com/config/sles/15/prod.repoActualice los repositorios.
sudo zypper --gpg-auto-import-keys refreshInstale mssql-tools con el paquete de desarrollo
unixODBC. Para más información, consulte Instalación de Microsoft ODBC Driver for SQL Server (Linux).sudo zypper install -y mssql-tools unixODBC-devel
Por comodidad, puede agregar /opt/mssql-tools/bin/ a la variable de entorno PATH. De este modo, podrá ejecutar las herramientas sin especificar la ruta de acceso completa. Ejecute los comandos siguientes para modificar la variable PATH, tanto para las sesiones de inicio de sesión como para las sesiones interactivas o sin inicio de sesión:
echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bash_profile
echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bashrc
source ~/.bashrc
Instalación del agente de alta disponibilidad de SQL Server
Ejecute el siguiente comando en todos los nodos para instalar el paquete del agente de alta disponibilidad de SQL Server:
sudo zypper install mssql-server-ha
Apertura de puertos para servicios de alta disponibilidad
Puede abrir los siguientes puertos de firewall en todos los nodos para los servicios de alta disponibilidad y SQL Server: 1433, 2224, 3121, 5022, 5405, 21064.
sudo firewall-cmd --zone=public --add-port=1433/tcp --add-port=2224/tcp --add-port=3121/tcp --add-port=5022/tcp --add-port=5405/tcp --add-port=21064 --permanent sudo firewall-cmd --reload
Configuración de un grupo de disponibilidad
Utilice los siguientes pasos para configurar un grupo de disponibilidad AlwaysOn de SQL Server para las máquinas virtuales. Para más información, consulte Configuración de un grupo de disponibilidad AlwaysOn de SQL Server para alta disponibilidad en Linux
Habilitación de grupos de disponibilidad y reinicio de SQL Server
Habilite grupos de disponibilidad en cada nodo donde se hospede una instancia de SQL Server. A continuación, reinicie el servicio mssql-server. Ejecute los siguientes comandos en cada nodo:
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
sudo systemctl restart mssql-server
Crear un certificado
Microsoft no admite la autenticación de Active Directory en el punto de conexión del grupo de disponibilidad. Por tanto, debe usar un certificado para el cifrado del punto de conexión del grupo de disponibilidad.
Conéctese a todos los nodos por medio de SQL Server Management Studio (SSMS) o sqlcmd. Ejecute los siguientes comandos para habilitar la sesión de AlwaysOn_health y crear una clave maestra:
Importante
Si se conecta de forma remota a la instancia de SQL Server, deberá tener el puerto 1433 abierto en el firewall. También tendrá que permitir conexiones entrantes al puerto 1433 en el grupo de seguridad de red de cada máquina virtual. Para más información, consulte Creación de una regla de seguridad para crear una regla de seguridad de entrada.
- Reemplace
<MasterKeyPassword>por su propia contraseña.
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE = ON); GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<MasterKeyPassword>'; GO- Reemplace
Conéctese a la réplica principal por medio de SSMS o sqlcmd. Los comandos siguientes crean un certificado en
/var/opt/mssql/data/dbm_certificate.cery una clave privada envar/opt/mssql/data/dbm_certificate.pvken la réplica principal de SQL Server:- Reemplace
<PrivateKeyPassword>por su propia contraseña.
CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; GO BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<PrivateKeyPassword>' ); GO- Reemplace
Salga de la sesión de sqlcmd ejecutando el comando exit y vuelva a la sesión de SSH.
Copia del certificado en las réplicas secundarias y creación de los certificados en el servidor
Copie los dos archivos que se crearon en la misma ubicación en todos los servidores que hospedarán las réplicas de disponibilidad.
En el servidor principal, ejecute el siguiente comando
scppara copiar el certificado en los servidores de destino:- Reemplace
<username>ysles2por el nombre de usuario y el nombre de la máquina virtual de destino que está usando. - Ejecute este comando para todas las réplicas secundarias.
Nota:
No tiene que ejecutar
sudo -i, lo que le proporciona el entorno raíz. En su lugar, puede ejecutar el comandosudodelante de cada comando.# The below command allows you to run commands in the root environment sudo -iscp /var/opt/mssql/data/dbm_certificate.* <username>@sles2:/home/<username>- Reemplace
En el servidor de destino, ejecute el siguiente comando:
- Reemplace
<username>por el nombre de usuario. - El comando
mvmueve los archivos o directorios de un lugar a otro. - El comando
chownse usa para cambiar el propietario y el grupo de archivos, directorios o vínculos. - Ejecute estos comandos para todas las réplicas secundarias.
sudo -i mv /home/<username>/dbm_certificate.* /var/opt/mssql/data/ cd /var/opt/mssql/data chown mssql:mssql dbm_certificate.*- Reemplace
El script de Transact-SQL siguiente crea un certificado a partir de la copia de seguridad creada en la réplica principal de SQL Server. Actualice el script con contraseñas seguras. La contraseña de descifrado es la misma que se usó para crear el archivo .pvk en el paso anterior. Para crear el certificado, ejecute el siguiente script con sqlcmd o SSMS en todos los servidores secundarios:
CREATE CERTIFICATE dbm_certificate FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<PrivateKeyPassword>' ); GO
Crear los puntos de conexión de creación de reflejo de la base de datos en todas las réplicas
Ejecute el siguiente script en todas las instancias de SQL Server por medio de sqlcmd o SSMS:
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
GO
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
GO
Crear el grupo de disponibilidad
Conéctese a la instancia de SQL Server que hospeda la réplica principal con sqlcmd o SSMS. Ejecute el siguiente comando para crear el grupo de disponibilidad:
- Reemplace
ag1por el nombre del grupo de disponibilidad que desee. - Reemplace los valores
sles1,sles2ysles3con los nombres de las instancias de SQL Server que hospedan las réplicas.
CREATE AVAILABILITY
GROUP [ag1]
WITH (
DB_FAILOVER = ON,
CLUSTER_TYPE = EXTERNAL
)
FOR REPLICA
ON N'sles1'
WITH (
ENDPOINT_URL = N'tcp://sles1:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'sles2'
WITH (
ENDPOINT_URL = N'tcp://sles2:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'sles3'
WITH (
ENDPOINT_URL = N'tcp://sles3:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
);
GO
ALTER AVAILABILITY GROUP [ag1]
GRANT CREATE ANY DATABASE;
GO
Crear un inicio de sesión de SQL Server para Pacemaker
En todas las instancias de SQL Server, cree un inicio de sesión de SQL Server para Pacemaker. La siguiente instrucción Transact-SQL crea un inicio de sesión.
- Reemplace
<password>por una contraseña propia compleja.
USE [master]
GO
CREATE LOGIN [pacemakerLogin]
WITH PASSWORD = N'<password>';
GO
ALTER SERVER ROLE [sysadmin]
ADD MEMBER [pacemakerLogin];
GO
En todas las instancias de SQL Server, guarde las credenciales usadas para el inicio de sesión de SQL Server.
Cree el archivo:
sudo vi /var/opt/mssql/secrets/passwdAgregue las dos líneas siguientes al archivo:
pacemakerLogin <password>Para salir del editor de vi, primero presione la tecla Esc y, a continuación, escriba el comando
:wqpara escribir en el archivo y salir.Haga que solo el usuario raíz pueda leer el archivo:
sudo chown root:root /var/opt/mssql/secrets/passwd sudo chmod 400 /var/opt/mssql/secrets/passwd
Conexión de las réplicas secundarias al grupo de disponibilidad
En las réplicas secundarias, ejecute los siguientes comandos para conectarlas al grupo de disponibilidad:
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOEjecute el script de Transact-SQL siguiente en la réplica principal y en cada una de las réplicas secundarias:
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::ag1 TO pacemakerLogin; GO GRANT VIEW SERVER STATE TO pacemakerLogin; GOUna vez que se conectan las réplicas secundarias, puede verlas en el Explorador de objetos de SSMS expandiendo el nodo de alta disponibilidad de Always On:
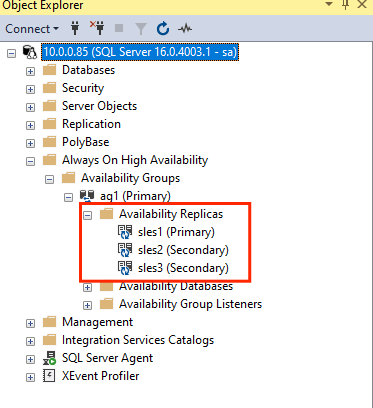
Agregar una base de datos al grupo de disponibilidad
En esta sección se sigue el artículo para agregar una base de datos a un grupo de disponibilidad.
Se utilizan los siguientes comandos de Transact-SQL en este paso. Ejecute estos comandos en la réplica principal:
CREATE DATABASE [db1]; -- creates a database named db1
GO
ALTER DATABASE [db1] SET RECOVERY FULL; -- set the database in full recovery model
GO
BACKUP DATABASE [db1] -- backs up the database to disk
TO DISK = N'/var/opt/mssql/data/db1.bak';
GO
ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [db1]; -- adds the database db1 to the AG
GO
Compruebe que la base de datos se crea en los servidores secundarios.
En todas las réplicas secundarias de SQL Server, ejecute la consulta siguiente para ver si se ha creado la base de datos db1 y su estado es SINCRONIZADO:
SELECT * FROM sys.databases
WHERE name = 'db1';
GO
SELECT DB_NAME(database_id) AS 'database',
synchronization_state_desc
FROM sys.dm_hadr_database_replica_states;
GO
Si synchronization_state_desc muestra SINCRONIZADO para db1, esto significa que las réplicas están sincronizadas. En las secundarias aparece db1 en la réplica principal.
Creación de recursos de grupo de disponibilidad en el clúster de Pacemaker
Nota
Comunicación sin prejuicios
Este artículo contiene referencias al término esclavo, que Microsoft considera ofensivo cuando se usa en este contexto. El término aparece en este artículo porque actualmente aparece en el software. Cuando se quite el término del software, se quitará también del artículo.
En este artículo se hace referencia a la guía para crear los recursos del grupo de disponibilidad en un clúster de Pacemaker.
Habilitar Pacemaker
Habilite Pacemaker para que se inicie automáticamente.
Ejecute el siguiente comando en todos los nodos del clúster.
sudo systemctl enable pacemaker
Creación de un recurso de clúster del grupo de disponibilidad
Ejecute
crm configurepara abrir el símbolo del sistema de crm:sudo crm configureEn el símbolo del sistema de crm, ejecute el siguiente comando para configurar las propiedades del recurso. Los siguientes comandos crean el recurso
ag_clusteren el grupo de disponibilidadag1.primitive ag_cluster ocf:mssql:ag params ag_name="ag1" meta failure-timeout=60s op start timeout=60s op stop timeout=60s op promote timeout=60s op demote timeout=10s op monitor timeout=60s interval=10s op monitor timeout=60s interval=11s role="Master" op monitor timeout=60s interval=12s role="Slave" op notify timeout=60s ms ms-ag_cluster ag_cluster meta master-max="1" master-node-max="1" clone-max="3" clone-node-max="1" notify="true" commit quitSugerencia
Escriba
quitpara salir del símbolo del sistema de crm.Establezca la restricción de coubicación para la IP virtual, para que se ejecute en el mismo nodo que el nodo principal:
sudo crm configure colocation vip_on_master inf: admin-ip ms-ag_cluster: Master commit quitAgregue la restricción de ordenación para evitar que la dirección IP apunte temporalmente al nodo con la réplica secundaria previa a la conmutación por error. Ejecute el siguiente comando para crear una restricción de ordenación:
sudo crm configure order ag_first inf: ms-ag_cluster:promote admin-ip:start commit quitCompruebe el estado del clúster con este comando:
sudo crm statusLa salida debe ser similar a la del siguiente ejemplo:
Cluster Summary: * Stack: corosync * Current DC: sles1 (version 2.0.5+20201202.ba59be712-150300.4.30.3-2.0.5+20201202.ba59be712) - partition with quorum * Last updated: Mon Mar 6 18:38:17 2023 * Last change: Mon Mar 6 18:38:09 2023 by root via cibadmin on sles1 * 3 nodes configured * 5 resource instances configured Node List: * Online: [ sles1 sles2 sles3 ] Full List of Resources: * admin-ip (ocf::heartbeat:IPaddr2): Started sles1 * rsc_st_azure (stonith:fence_azure_arm): Started sles2 * Clone Set: ms-ag_cluster [ag_cluster] (promotable): * Masters: [ sles1 ] * Slaves: [ sles2 sles3 ]Ejecute el siguiente comando para revisar las restricciones:
sudo crm configure showLa salida debe ser similar a la del siguiente ejemplo:
node 1: sles1 node 2: sles2 node 3: sles3 primitive admin-ip IPaddr2 \ params ip=10.0.0.93 \ op monitor interval=10 timeout=20 primitive ag_cluster ocf:mssql:ag \ params ag_name=ag1 \ meta failure-timeout=60s \ op start timeout=60s interval=0 \ op stop timeout=60s interval=0 \ op promote timeout=60s interval=0 \ op demote timeout=10s interval=0 \ op monitor timeout=60s interval=10s \ op monitor timeout=60s interval=11s role=Master \ op monitor timeout=60s interval=12s role=Slave \ op notify timeout=60s interval=0 primitive rsc_st_azure stonith:fence_azure_arm \ params subscriptionId=xxxxxxx resourceGroup=amvindomain tenantId=xxxxxxx login=xxxxxxx passwd="******" cmk_monitor_retries=4 pcmk_action_limit=3 power_timeout=240 pcmk_reboot_timeout=900 pcmk_host_map="sles1:sles1;les2:sles2;sles3:sles3" \ op monitor interval=3600 timeout=120 ms ms-ag_cluster ag_cluster \ meta master-max=1 master-node-max=1 clone-max=3 clone-node-max=1 notify=true order ag_first Mandatory: ms-ag_cluster:promote admin-ip:start colocation vip_on_master inf: admin-ip ms-ag_cluster:Master property cib-bootstrap-options: \ have-watchdog=false \ dc-version="2.0.5+20201202.ba59be712-150300.4.30.3-2.0.5+20201202.ba59be712" \ cluster-infrastructure=corosync \ cluster-name=sqlcluster \ stonith-enabled=true \ concurrent-fencing=true \ stonith-timeout=900 rsc_defaults rsc-options: \ resource-stickiness=1 \ migration-threshold=3 op_defaults op-options: \ timeout=600 \ record-pending=true
Conmutación por error de prueba
Para asegurarse de que la configuración se ha realizado correctamente, pruebe una conmutación por error. Para más información, consulte Conmutación por error del grupo de disponibilidad Always On en Linux.
Ejecute el siguiente comando para realizar manualmente la conmutación por error de la réplica principal en
sles2. Reemplacesles2por el valor del nombre del servidor.sudo crm resource move ag_cluster sles2La salida debe ser similar a la del siguiente ejemplo:
INFO: Move constraint created for ms-ag_cluster to sles2 INFO: Use `crm resource clear ms-ag_cluster` to remove this constraintCompruebe el estado del clúster:
sudo crm statusLa salida debe ser similar a la del siguiente ejemplo:
Cluster Summary: * Stack: corosync * Current DC: sles1 (version 2.0.5+20201202.ba59be712-150300.4.30.3-2.0.5+20201202.ba59be712) - partition with quorum * Last updated: Mon Mar 6 18:40:02 2023 * Last change: Mon Mar 6 18:39:53 2023 by root via crm_resource on sles1 * 3 nodes configured * 5 resource instances configured Node List: * Online: [ sles1 sles2 sles3 ] Full List of Resources: * admin-ip (ocf::heartbeat:IPaddr2): Stopped * rsc_st_azure (stonith:fence_azure_arm): Started sles2 * Clone Set: ms-ag_cluster [ag_cluster] (promotable): * Slaves: [ sles1 sles2 sles3 ]Después de algún tiempo, la máquina virtual
sles2es ahora la principal y las otras dos máquinas virtuales son secundarias. Vuelva a ejecutarsudo crm statusy revise la salida, que es similar a la del siguiente ejemplo:Cluster Summary: * Stack: corosync * Current DC: sles1 (version 2.0.5+20201202.ba59be712-150300.4.30.3-2.0.5+20201202.ba59be712) - partition with quorum * Last updated: Tue Mar 6 22:00:44 2023 * Last change: Mon Mar 6 18:42:59 2023 by root via cibadmin on sles1 * 3 nodes configured * 5 resource instances configured Node List: * Online: [ sles1 sles2 sles3 ] Full List of Resources: * admin-ip (ocf::heartbeat:IPaddr2): Started sles2 * rsc_st_azure (stonith:fence_azure_arm): Started sles2 * Clone Set: ms-ag_cluster [ag_cluster] (promotable): * Masters: [ sles2 ] * Slaves: [ sles1 sles3 ]Vuelva a comprobar las restricciones con
crm config show. Observe que se ha agregado otra restricción debido a la conmutación por error manual.Quite la restricción con el id.
cli-prefer-ag_clustercon el siguiente comando:crm configure delete cli-prefer-ms-ag_cluster commit
Prueba de las barreras
Puede probar STONITH. Para ello, ejecute el siguiente comando. Intente ejecutar el comando siguiente desde sles1 para sles3.
sudo crm node fence sles3