Ajuste del rendimiento de aplicaciones y bases de datos en Azure SQL Managed Instance
Se aplica a: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Una vez identificado un problema de rendimiento que experimente con Azure SQL Managed Instance, este artículo le será de ayuda:
- Ajuste la aplicación y aplique algunas prácticas recomendadas que puedan mejorar el rendimiento.
- Ajuste la base de datos cambiando los índices y consultas para que funcionen de manera más eficiente con los datos.
En este artículo se da por supuesto que ha comprobado la información general sobre la supervisión y optimización y el rendimiento de la supervisión mediante el uso del Almacén de consultas. Además, en este artículo se supone que no tiene un problema de rendimiento relacionado con el uso de los recursos de CPU que se pueda resolver aumentando el tamaño de proceso o el nivel de servicio para proporcionar más recursos a la SQL Managed Instance.
Nota:
Para obtener instrucciones similares sobre Azure SQL Database, consulte Ajuste de aplicaciones y bases de datos para obtener un rendimiento en Azure SQL Database.
Optimización de la aplicación
En instancias de SQL Server locales tradicionales, el proceso de planeamiento inicial de la capacidad con frecuencia está separado del proceso de ejecución de una aplicación en producción. Primero se adquieren las licencias de hardware y productos y luego se ajusta el rendimiento. Cuando se usa Azure SQL, es una buena idea entrelazar el proceso de ejecutar una aplicación y ajustarla. Con el modelo de pago por capacidad a petición, puede ajustar su aplicación para que use el número mínimo de recursos necesarios, en lugar de aprovisionar en exceso el hardware en función de las estimaciones de planes de crecimiento futuro para una aplicación, que con frecuencia son incorrectas.
Algunos clientes pueden decidir no optimizar una aplicación y, en su lugar, eligen aprovisionar en exceso los recursos de hardware. Este enfoque puede ser una buena idea si no quiere cambiar una aplicación clave durante un período de ocupación. Sin embargo, la optimización de una aplicación puede minimizar los requisitos de recursos y reducir las facturas mensuales.
Procedimientos recomendados y antipatrones en el diseño de aplicaciones para Azure SQL Managed Instance
Aunque los niveles de servicio de Azure SQL Managed Instance están diseñados para mejorar la estabilidad del rendimiento y la previsibilidad de una aplicación, algunos procedimientos recomendados pueden ayudarle a optimizar la aplicación para un mejor aprovechamiento de los recursos en un tamaño de proceso. Aunque muchas aplicaciones tienen importantes ganancias de rendimiento con solo cambiar a un tamaño de proceso o un nivel de servicio superior, otras aplicaciones necesitan ajustes adicionales para beneficiarse de un nivel de servicio más alto.
Para aumentar el rendimiento, puede realizar ajustes adicionales en las aplicaciones para que tengan estas características:
Aplicaciones que tienen un rendimiento lento debido a un comportamiento "comunicativo"
Las aplicaciones comunicativas realizan excesivas operaciones de acceso a los datos que son sensibles a la latencia de red. Para reducir el número de operaciones de acceso a datos de la base de datos, puede que tenga que modificar estos tipos de aplicaciones. Por ejemplo, puede mejorar el rendimiento de la aplicación mediante técnicas como el procesamiento por lotes de consultas ad hoc o el movimiento de las consultas a procedimientos almacenados. Para más información, consulte Consultas por lotes.
Bases de datos con una carga de trabajo intensiva que no se admiten en una sola máquina
Las bases de datos que superen los recursos del tamaño de proceso Premium más podrían beneficiarse de escalar horizontalmente la carga de trabajo. Para más información, consulte Particionamiento entre bases de datos y Creación de particiones funcional.
Aplicaciones que tienen consultas subóptimas
Puede que las aplicaciones con consultas poco optimizadas no se beneficien de un proceso mayor. Esto incluye consultas que carecen de una cláusula WHERE, con índices que faltan o tienen estadísticas anticuadas. Estas aplicaciones se benefician de las técnicas de optimización del rendimiento de consultas estándar. Para más información, consulte Índices que faltan y Optimización de consultas y sugerencias.
Aplicaciones que tienen un diseño de acceso a datos subóptimo
Puede que las aplicaciones que tienen problemas inherentes de simultaneidad del acceso a los datos, por ejemplo, interbloqueos, no se beneficien de un tamaño de proceso más alto. Considere la posibilidad de reducir los recorridos de ida y vuelta a la base de datos almacenando en caché los datos del lado cliente con el Servicio de almacenamiento en caché de Azure u otra tecnología de almacenamiento en caché. Consulte Almacenamiento en caché de la capa de aplicación.
Para evitar los interbloqueos en Azure SQL Managed Instance, consulte las herramientas de interbloqueo de la guía de interbloqueos.
Ajuste de la base de datos
En esta sección, examinamos algunas técnicas que puede usar para ajustar la base de datos para obtener el mejor rendimiento de la aplicación y ejecutarla con el menor tamaño de proceso posible. Algunas de estas técnicas coinciden con los procedimientos recomendados de optimización tradicionales de SQL Server, pero otras son específicas de Azure SQL Managed Instance. En algunos casos, puede examinar los recursos consumidos en una base de datos para encontrar áreas de mejora adicional y ampliar las técnicas de SQL Server tradicionales para trabajar en Azure SQL Managed Instance.
Identificación e incorporación de índices que faltan
Un problema común del rendimiento de las bases de datos OLTP está relacionado con el diseño físico de la base de datos. A menudo, los esquemas de base de datos se diseñan y se entregan sin realizar pruebas a escala (ya sea en la carga o en el volumen de datos). Lamentablemente, el rendimiento de un plan de consultas puede ser aceptable a pequeña escala, pero se puede degradar sustancialmente cuando se enfrenta a los volúmenes de datos del nivel de producción. El origen más común de este problema es la falta de índices adecuados para satisfacer los filtros u otras restricciones en una consulta. A menudo, la falta de índices se manifiesta como un recorrido de tabla cuando podría ser suficiente una búsqueda de índice.
En este ejemplo, el plan de consulta seleccionado usa una exploración cuando bastaría con una búsqueda:
DROP TABLE dbo.missingindex;
CREATE TABLE dbo.missingindex (col1 INT IDENTITY PRIMARY KEY, col2 INT);
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO dbo.missingindex(col2) VALUES (@a);
SET @a += 1;
END
COMMIT TRANSACTION;
GO
SELECT m1.col1
FROM dbo.missingindex m1 INNER JOIN dbo.missingindex m2 ON(m1.col1=m2.col1)
WHERE m1.col2 = 4;
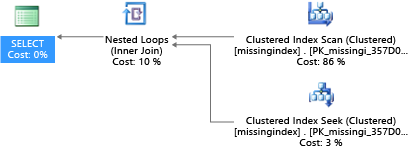
Las DMV que se crean en SQL Server desde 2005 examinan compilaciones de consultas en las que un índice reduciría considerablemente el costo estimado de ejecutar una consulta. Durante la ejecución de las consultas, el motor de base de datos hace un seguimiento de la frecuencia con que se ejecuta cada plan de consulta, así como de la diferencia estimada entre el plan de consulta en ejecución y el imaginario en el que existía ese índice. Estas DMV se pueden usar para realizar suposiciones rápidas sobre qué cambios en el diseño de la base de datos física podrían mejorar el costo de la carga de trabajo general de una base de datos y su carga de trabajo real.
Esta consulta se puede usar para evaluar los posibles índices que falten:
SELECT
CONVERT (varchar, getdate(), 126) AS runtime
, mig.index_group_handle
, mid.index_handle
, CONVERT (decimal (28,1), migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans)) AS improvement_measure
, 'CREATE INDEX missing_index_' + CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' + mid.statement + '
(' + ISNULL (mid.equality_columns,'')
+ CASE WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL
THEN ',' ELSE '' END + ISNULL (mid.inequality_columns, '') + ')'
+ ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
, migs.*
, mid.database_id
, mid.[object_id]
FROM sys.dm_db_missing_index_groups AS mig
INNER JOIN sys.dm_db_missing_index_group_stats AS migs
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid
ON mig.index_handle = mid.index_handle
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC
En este ejemplo, la consulta ha dado como resultado esta sugerencia:
CREATE INDEX missing_index_5006_5005 ON [dbo].[missingindex] ([col2])
Después de crearla, esa misma instrucción SELECT elige un plan diferente, que usa una búsqueda en lugar de una exploración y, luego, ejecuta el plan de forma más eficaz:
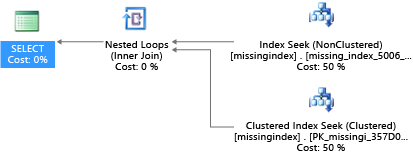
El principal dato es que la capacidad de E/S de un sistema compartido es más limitada que la de una máquina servidor dedicada. Es de especial valor minimizar la E/S innecesaria para sacar el máximo partido del sistema dentro de los recursos de cada tamaño de proceso de los niveles de servicio. La elección adecuada de las opciones de diseño de bases de datos físicas puede mejorar considerablemente la latencia de las consultas individuales y la capacidad de procesamiento de solicitudes simultáneas que puede realizar por unidad de escalado, así como minimizar los costos necesarios para satisfacer la consulta.
Para obtener más información sobre cómo optimizar los índices mediante solicitudes de índice que faltan, consulte Optimización de índices no agrupados con sugerencias de índice que faltan.
Optimización de consultas y sugerencias
El optimizador de consultas de Azure SQL Managed Instance es similar al optimizador de consultas tradicional de SQL Server. La mayoría de los procedimientos recomendados para optimizar consultas y entender las limitaciones del modelo de razonamiento para el optimizador de consultas se aplican también a Azure SQL Managed Instance. Si optimiza las consultas en Azure SQL Managed Instance, puede obtener el beneficio adicional de reducir las demandas de recursos agregados. La aplicación podría ejecutarse con un menor costo que una equivalente sin optimizar porque se puede ejecutar con un tamaño de proceso menor.
Un ejemplo común en SQL Server y que también se aplica a Azure SQL Managed Instance es cómo el optimizador de consultas examina los parámetros. Durante la compilación, el optimizador de consultas evalúa el valor actual de un parámetro para determinar si puede generar un plan de consulta más óptimo. Aunque con frecuencia esta estrategia puede conducir a un plan de consultas bastante más rápido que un plan compilado sin valores de parámetros conocidos, actualmente no funciona muy bien en Azure SQL Managed Instance. (Una nueva función de rendimiento de consulta inteligente introducida con SQL Server 2022 denominada Optimización del plan de sensibilidad de parámetros aborda el escenario en el que un único plan almacenado en caché para una consulta con parámetros no es óptimo para todos los posibles valores de parámetros entrantes. Actualmente, Parameter Sensitivity Plan Optimization no está disponible en Azure SQL Managed Instance).
A veces el parámetro no se examina y otras veces sí, pero el plan generado es poco óptimo para el conjunto completo de valores de parámetros de una carga de trabajo. Microsoft incluye sugerencias de consulta (directivas) para que pueda especificar más deliberadamente la intención y reemplazar el comportamiento predeterminado de examen de parámetros. Puede optar por recurrir a sugerencias cuando el comportamiento predeterminado es imperfecto para la carga de trabajo de un cliente específico.
En el ejemplo siguiente se muestra cómo el procesador de consultas puede generar un plan poco óptimo para los requisitos de rendimiento y recursos. Este ejemplo también muestra que si usa una sugerencia de consulta, puede reducir los requisitos de recursos y el tiempo de ejecución de consultas de su base de datos:
DROP TABLE psptest1;
CREATE TABLE psptest1(col1 int primary key identity, col2 int, col3 binary(200));
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO psptest1(col2) values (1);
INSERT INTO psptest1(col2) values (@a);
SET @a += 1;
END
COMMIT TRANSACTION
CREATE INDEX i1 on psptest1(col2);
GO
CREATE PROCEDURE psp1 (@param1 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1
WHERE col2 = @param1
ORDER BY col2;
END
GO
CREATE PROCEDURE psp2 (@param2 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1 WHERE col2 = @param2
ORDER BY col2
OPTION (OPTIMIZE FOR (@param2 UNKNOWN))
END
GO
CREATE TABLE t1 (col1 int primary key, col2 int, col3 binary(200));
GO
El código de instalación crea una tabla que tiene datos distribuidos irregularmente en la tabla t1. El plan de consulta óptimo varía en función del parámetro que seleccione. Desafortunadamente, el comportamiento de almacenar en caché el plan no siempre recompila la consulta según el valor de parámetro más común. Por lo tanto, se puede almacenar en caché un plan poco óptimo y usarse para muchos valores, aunque un plan diferente podría ser una mejor opción por término medio. A continuación, el plan de consulta crea dos procedimientos almacenados que son idénticos, salvo que uno tiene una sugerencia de consulta especial.
-- Prime Procedure Cache with scan plan
EXEC psp1 @param1=1;
TRUNCATE TABLE t1;
-- Iterate multiple times to show the performance difference
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp1 @param1=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
Se recomienda esperar al menos 10 minutos para empezar la parte 2 del ejemplo, con el fin de que los resultados sean distintos en los datos de telemetría resultantes.
EXEC psp2 @param2=1;
TRUNCATE TABLE t1;
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp2 @param2=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
Cada parte de este ejemplo intenta ejecutar 1000 veces una instrucción insert parametrizada (para generar una carga suficiente para usarla como un conjunto de datos de prueba). Al ejecutar los procedimientos almacenados, el procesador de consultas examina el valor de los parámetros pasados al procedimiento durante su primera compilación (lo que se conoce como examinar parámetros). El procesador almacena en caché el plan resultante y se usa para invocaciones posteriores, aunque el valor del parámetro sea diferente. El plan óptimo no podría utilizarse en todos los casos. En ocasiones, es necesario guiar al optimizador para que seleccione un plan que sea mejor para el caso medio en lugar de para el caso específico de cuando la consulta se compila por primera vez. En este ejemplo, el plan inicial genera un plan de "exploración" que lee todas las filas para encontrar todos los valores que coinciden con el parámetro.

Como el procedimiento se ejecutó con el valor 1, el plan resultante era óptimo para 1, pero poco óptimo para todos los demás valores de la tabla. Es probable que el resultado no sea lo que esperaría si seleccionara cada plan de manera aleatoria, dado que el plan se ejecuta más despacio y usa menos recursos.
Si ejecuta la prueba con SET STATISTICS IO establecido en ON, el trabajo de exploración lógica en este ejemplo se realiza en segundo plano. Puede ver que hay 1148 lecturas que realiza el plan (lo que es ineficaz, si el caso medio es devolver solo una fila):

La segunda parte del ejemplo usa una sugerencia de consulta para indicar al optimizador que use un valor específico durante el proceso de compilación. En este caso, obliga al procesador de consultas a omitir el valor que se pasa como parámetro, y en su lugar a asumir UNKNOWN. Este valor hace referencia a un valor que tiene la frecuencia media en la tabla (omitiendo el sesgo). El plan resultante está basado en búsquedas, es más rápido y usa menos recursos, como términos medio, que el plan de la parte 1 de este ejemplo:

Puede ver el efecto en la vista de catálogo del sistema sys.server_resource_stats. Los datos se recopilan, se agregan y se actualizan en intervalos de 5 a 10 minutos. Hay una fila por cada 15 segundos de informes. Por ejemplo:
SELECT TOP 1000 *
FROM sys.server_resource_stats
ORDER BY start_time DESC
Puede examinar sys.server_resource_stats para determinar si el recurso de una prueba usa más o menos recursos que otra prueba. Al comparar los datos, separe el tiempo de pruebas para que no se encuentren en el mismo período de 5 minutos en la vista sys.server_resource_stats. El objetivo del ejercicio es minimizar la cantidad total de recursos usados, no minimizar los recursos máximos. Por lo general, al optimizar la latencia de un fragmento de código, también se reduce el consumo de recursos. Asegúrese de que los cambios realizados en una aplicación sean necesarios y que no afecten negativamente a la experiencia del cliente para alguien que podría estar usando sugerencias de consulta en la aplicación.
Si una carga de trabajo contiene un conjunto de consultas repetidas, con frecuencia tiene sentido capturar y validar la idoneidad de esas elecciones del plan, ya que controlarán la unidad de tamaño mínima de los recursos necesaria para hospedar la base de datos. Después de comprobarlo, vuelva a examinar de vez en cuando los planes para asegurarse de que no se han degradado. Puede aprender más sobre las sugerencias de consulta (Transact-SQL).
Procedimientos recomendados para arquitecturas de base de datos de gran tamaño en Azure SQL Managed Instance
En las dos secciones siguientes se describen dos opciones para solucionar problemas de bases de datos de gran tamaño en Azure SQL Managed Instance.
Particionamiento entre bases de datos
Como Azure SQL Managed Instance se ejecutan en hardware estándar, los límites de capacidad para una base de datos individual son inferiores a los de una instalación local de SQL Server tradicional. Algunos clientes usan técnicas de particionamiento para repartir las operaciones de base de datos entre varias bases de datos cuando las operaciones no entran en los límites de una base de datos individual en Azure SQL Managed Instance. La mayoría de los clientes que usan técnicas de particionamiento en Azure SQL Managed Instance dividen sus datos en una única dimensión entre varias bases de datos. En este enfoque, debe comprender que las aplicaciones OLTP a menudo realizan transacciones que se aplican a una sola fila o a un pequeño grupo de filas del esquema.
Por ejemplo, si una base de datos tiene el nombre del cliente, el pedido y los detalles del pedido (como la base de datos AdventureWorks), podría dividir estos datos en varias bases de datos mediante la agrupación de un cliente con el pedido relacionado y la información detallada del pedido. Puede garantizar que los datos del cliente permanezcan en una base de datos individual. La aplicación dividiría los distintos clientes entre las bases de datos, repartiendo la carga eficazmente entre varias bases de datos. El particionamiento no solo permite que los clientes eviten el límite de tamaño máximo de la base de datos, sino también que Azure SQL Managed Instance puedan procesar cargas de trabajo que sean mucho mayores que los límites de los distintos tamaños de proceso, siempre y cuando cada base de datos se ajuste a sus límites de nivel de servicio.
Aunque el particionamiento de base de datos no reduce la capacidad de recursos agregados para una solución, es muy eficaz a la hora de admitir soluciones muy grandes que se distribuyen entre varias bases de datos. Cada base de datos se puede ejecutar con un tamaño de proceso diferente para admitir bases de datos "eficaces" muy grandes con requisitos elevados de recursos.
Creación de particiones funcional
Los usuarios suelen combinar varias funciones en una base de datos individual. Por ejemplo, si una aplicación contiene lógica para administrar el inventario de un almacén, esa base de datos podría contener lógica asociada con el inventario, el seguimiento de los pedidos de compra, los procedimientos almacenados y las vistas indizadas o materializadas que administran los informes de fin de me. Esta técnica facilita la administración de la base de datos para operaciones como la copia de seguridad, pero también requiere ajustar el tamaño del hardware para administrar la carga máxima en todas las funciones de una aplicación.
Si usa una arquitectura de escalado horizontal en Azure SQL Managed Instance, es una buena idea repartir las distintas funciones de una aplicación en diferentes bases de datos. Mediante esta técnica, cada aplicación se escala de forma independiente. A medida que una aplicación realiza una actividad mayor (y aumenta la carga en la base de datos), el administrador puede elegir tamaños de proceso independientes para cada función de la aplicación. En el límite, una aplicación con esta arquitectura puede ser más grande de lo que puede controlar una única máquina estándar por lo que la carga se reparte entre varias máquinas.
Consultas por lotes
Para las aplicaciones que acceden a datos mediante consultas ad hoc frecuentes de gran volumen, una parte sustancial del tiempo de respuesta se dedica a la comunicación de red entre la capa de aplicación y la de la base de datos. Incluso si la aplicación y la base de datos residen en el mismo centro de datos, la latencia de red entre ambas podría verse aumentada por un número elevado de operaciones de acceso a datos. Para reducir los recorridos de ida y vuelta de red en las operaciones de acceso a datos, puede usar la opción para procesar por lotes todas las consultas ad hoc o para compilarlas como procedimientos almacenados. Si procesa por lotes las consultas ad hoc, puede enviar varias consultas como un lote grande en un solo recorrido a la base de datos. Si compila las consultas ad hoc en un procedimiento almacenado, podría lograr el mismo resultado que si las procesa por lotes. El uso de un procedimiento almacenado también ofrece la ventaja de aumentar la probabilidad de almacenar en caché los planes de consulta en la base de datos de modo que pueda usar de nuevo el procedimiento almacenado.
Algunas aplicaciones requieren operaciones de escritura intensivas. En ocasiones se puede reducir la carga total de E/S en una base de datos si se considera cómo procesar por lotes las escrituras juntas. Con frecuencia es tan sencillo como usar transacciones explícitas en lugar de transacciones de confirmación automática dentro de los procedimientos almacenados y lotes ad hoc. Para ver una evaluación de las distintas técnicas que se pueden usar, consulte Técnicas de procesamiento por lotes para aplicaciones de base de datos en Azure. Experimente con su propia carga de trabajo para encontrar el modelo adecuado de procesamiento por lotes. Asegúrese de entender que un modelo puede tener garantías de coherencia transaccional ligeramente diferentes. Para encontrar la carga de trabajo adecuada que minimiza el uso de recursos, es necesario encontrar la combinación correcta de coherencia y rendimiento.
Almacenamiento en caché de la capa de aplicación
Algunas aplicaciones de base de datos tienen cargas de trabajo con operaciones de lectura intensivas. El almacenamiento en caché de las capas podría reducir la carga en la base de datos y también, posiblemente, el tamaño de proceso necesario para admitir una base de datos con Azure SQL Managed Instance. Con Azure Cache for Redis, si tiene una carga de trabajo con muchas operaciones de lectura, puede leer los datos una vez (o quizás una vez por máquina del nivel de aplicación, según cómo esté configurada) y luego almacenar esos datos fuera de la base de datos. Se trata de una forma de reducir la carga de la base de datos (CPU y E/S de lectura), pero tiene efectos sobre la coherencia transaccional, porque los datos que se leen de la caché podrían no estar sincronizados con respecto a los datos de la base de datos. Aunque en muchas aplicaciones algún nivel de incoherencia es aceptable, esto no se aplica a todas las cargas de trabajo. Debería comprender totalmente los requisitos de una aplicación antes de emplear una estrategia de almacenamiento en caché de la capa de aplicación.
Contenido relacionado
- Modelo de compra de núcleo virtual: Azure SQL Managed Instance
- Configure las opciones de tempdb de Azure SQL Managed Instance
- Supervisión del rendimiento de las instancias administradas de Microsoft Azure SQL mediante vistas de gestión dinámicas
- Ajuste de índices no agrupados con sugerencias de índices que faltan
- Supervisión de Azure SQL Managed Instance con Azure Monitor