Introducción a los grupos de conmutación por error y procedimientos recomendados: Azure SQL Managed Instance
Se aplica a:![]() Azure SQL Managed Instance
Azure SQL Managed Instance
La característica de los grupos de conmutación por error permite administrar la replicación y la conmutación por error en otra región de Azure de todas las bases de datos de usuario de una instancia administrada. En este artículo se proporciona información general sobre la característica de grupo de conmutación por error con procedimientos recomendados y recomendaciones para usarlo con Azure SQL Managed Instance.
Para empezar a usar la característica, consulte Configuración de un grupo de conmutación por error para Azure SQL Managed Instance.
Información general
La característica de los grupos de conmutación por error permite administrar la replicación y la conmutación por error de bases de datos de usuario en una instancia administrada a una instancia administrada de otra región de Azure. Los grupos de conmutación por error están diseñados para simplificar la implementación y administración de bases de datos con replicación geográfica a escala.
Para más información, consulte Alta disponibilidad para Azure SQL Managed Instance. Para obtener información sobre RPO y RTO de la conmutación por error geográfica, consulta Introducción a la continuidad empresarial.
Redireccionamiento de punto de conexión
Los grupos de conmutación por error proporcionan puntos de conexión de agentes de escucha de lectura-escritura y de solo lectura que no se modifican durante las conmutaciones por error con replicación geográfica. No es necesario cambiar la cadena de conexión de la aplicación después de una conmutación por error geográfica, porque las conexiones se enrutan automáticamente a la región primaria actual. Una conmutación por error geográfica cambia todas las bases de datos secundarias del grupo al rol principal. Después de que la conmutación por error geográfica finaliza, el registro de DNS se actualiza automáticamente para redirigir los puntos de conexión a la nueva región.
Descarga de cargas de trabajo de solo lectura
Para reducir el tráfico a sus bases de datos principales, también puede utilizar las bases de datos secundarias de un grupo de conmutación por error para descargar cargas de trabajo de solo lectura. Utilice el cliente de escucha de solo lectura para dirigir el tráfico de solo lectura a una base de datos secundaria legible.
Recuperación de una aplicación
Para lograr una continuidad empresarial completa, agregar redundancia de base de datos regional es solo una parte de la solución. Para recuperar una aplicación (un servicio) de un extremo a otro tras un error catastrófico, es necesario recuperar todos los componentes que constituyen el servicio y cualquier servicio dependiente. Algunos ejemplos de estos componentes son el software cliente (por ejemplo, un explorador con JavaScript personalizado), los front-end web, el almacenamiento y DNS. Es fundamental que todos los componentes sean resistentes a los mismos errores y que estén disponibles en el plazo del objetivo de tiempo de recuperación (RTO) de la aplicación. Por lo tanto, debe identificar todos los servicios dependientes y comprender las garantías y capacidades que ofrecen. A continuación, debe seguir los pasos adecuados para asegurarse de que el servicio funcione durante la conmutación por error de los servicios de los que depende.
Directiva de conmutación por error
Los grupos de conmutación por error admiten dos directivas de conmutación por error:
- Administrada por el cliente (recomendado): los clientes pueden realizar una conmutación por error de un grupo cuando observen una interrupción inesperada que afecta a una o varias bases de datos del grupo de conmutación por error. Al usar herramientas de línea de comandos como PowerShell, la CLI de Azure o la API de REST, el valor de la directiva de conmutación por error administrada por el cliente es
manual. - Administrada por Microsoft: en caso de una interrupción generalizada que afecta a una región primaria, Microsoft inicia la conmutación por error de todos los grupos de conmutación por error afectados que tienen configurada su directiva de conmutación por error como administrada por Microsoft. La conmutación por error administrada por Microsoft no se iniciará para grupos de conmutación por error individuales ni para un subconjunto de grupos de conmutación por error de una región. Al usar herramientas de línea de comandos como PowerShell, la CLI de Azure o la API de REST, el valor de la directiva de conmutación por error administrada por Microsoft es
automatic.
Cada directiva de conmutación por error tiene un conjunto único de casos de uso y las expectativas correspondientes sobre el ámbito de conmutación por error y la pérdida de datos, como se resume en la tabla siguiente:
| Directiva de conmutación por error | Ámbito de la conmutación por error | Caso de uso | Posible pérdida de datos |
|---|---|---|---|
| Administrado por el cliente (Recomendado) |
Grupos de conmutación por error | Una o varias bases de datos de un grupo de conmutación por error se ven afectadas por una interrupción y dejan de estar disponibles. Puedes optar por conmutar por error. | Sí |
| Administrado por Microsoft | Todos los grupos de conmutación por error de la región | Una interrupción generalizada en un centro de datos, una zona de disponibilidad o una región provoca la falta de disponibilidad de las bases de datos y el equipo del servicio Microsoft Azure SQL decide desencadenar una conmutación por error forzada. Usa esta opción solo cuando desees delegar la responsabilidad de recuperación ante desastres en Microsoft y la aplicación es tolerante a RTO (tiempo de inactividad) de al menos una hora o más. |
Sí |
Administrado por el cliente
En raras ocasiones, la disponibilidad integrada o la alta disponibilidad no es suficiente para mitigar una interrupción y las bases de datos de un grupo de conmutación por error podrían no estar disponibles durante una duración que no es aceptable para el acuerdo de nivel de servicio (SLA) de las aplicaciones que usan las bases de datos. Las bases de datos pueden no estar disponibles debido a un problema localizado que afecta a solo unas pocas bases de datos o podrían estar en el centro de datos, la zona de disponibilidad o el nivel de región. En cualquiera de estos casos, para restaurar la continuidad empresarial, puedes iniciar una conmutación por error forzada.
Se recomienda encarecidamente establecer la directiva de conmutación por error como administrada por el cliente, ya que mantienes el control de cuándo iniciar una conmutación por error y restaurar la continuidad empresarial. Puedes iniciar una conmutación por error cuando observe una interrupción inesperada que afecte a una o varias bases de datos del grupo de conmutación por error.
Administrado por Microsoft
Con una directiva de conmutación por error administrada por Microsoft, la responsabilidad de recuperación ante desastres se delega al servicio Azure SQL. Para que el servicio Azure SQL inicie una conmutación por error forzada, se deben cumplir las siguientes condiciones:
- Interrupción del nivel de centro de datos, zona de disponibilidad o región causada por un evento de desastre natural, cambios en la configuración, errores de software o errores de componentes de hardware y muchas bases de datos de la región afectadas.
- El período de gracia ha expirado. Dado que la comprobación de la escala de la interrupción y la rapidez con que se puede mitigar conllevan acciones humanas, el período de gracia no se puede establecer por debajo de una hora.
Cuando se cumplen estas condiciones, el servicio Azure SQL inicia conmutaciones por error forzadas para todos los grupos de conmutación por error de la región que tienen la directiva de conmutación por error establecida en Administrada por Microsoft.
Importante
Use la directiva de conmutación por error administrada por el cliente para probar e implementar el plan de recuperación ante desastres. No confíe en la conmutación por error administrada por Microsoft, que solo ejecutaría Microsoft en circunstancias extremas. Se iniciaría una conmutación por error administrada por Microsoft para todos los grupos de conmutación por error de la región que tienen la directiva de conmutación por error establecida en administrado por Microsoft. No se puede iniciar para un grupo de conmutación por error individual. Si necesita la capacidad de conmutar por error de forma selectiva el grupo de conmutación por error, use la directiva de conmutación por error administrada por el cliente.
Establece la directiva de conmutación por error en Administrada por Microsoft solo cuando:
- Quieras delegar la responsabilidad de recuperación ante desastres en el servicio Azure SQL.
- La aplicación es tolerante a que la base de datos no esté disponible durante al menos una hora o más.
- Es aceptable desencadenar conmutaciones por error forzadas algún tiempo después de que expire el período de gracia, ya que el tiempo real de la conmutación por error forzada puede variar significativamente.
- Es aceptable que todas las bases de datos del grupo de conmutación por error conmuten por error, independientemente de su configuración de redundancia de zona o estado de disponibilidad. Aunque las bases de datos configuradas para la redundancia de zona son resistentes a errores zonales y podrían no verse afectadas por una interrupción, seguirán conmutando por error si forman parte de un grupo de conmutación por error con una directiva de conmutación por error Administrada por Microsoft.
- Es aceptable tener conmutaciones por error forzadas de bases de datos en el grupo de conmutación por error sin tener en cuenta la dependencia de la aplicación en otros servicios o componentes de Azure usados por la aplicación, lo que puede provocar una degradación del rendimiento o una falta de disponibilidad de la aplicación.
- Es aceptable incurrir en una cantidad desconocida de pérdida de datos, ya que el tiempo exacto de la conmutación por error forzada no se puede controlar y omite el estado de sincronización de las bases de datos secundarias.
- Todas las bases de datos principales y secundarias del grupo de conmutación por error, y cualquier relación de replicación geográfica, tienen el mismo nivel de servicio, nivel de proceso (aprovisionado o sin servidor) y tamaño de proceso (DTU o núcleos virtuales). Si el objetivo de nivel de servicio (SLO) de todas las bases de datos no coincide, la directiva de conmutación por error se actualizará finalmente de administrada por Microsoft a administrada por el cliente mediante el servicio Azure SQL.
Cuando Microsoft desencadena una conmutación por error, se agrega una entrada para el nombre de operación de Conmutación por error del grupo de conmutación por error de Azure SQL al registro de actividad de Azure Monitor. La entrada incluye el nombre del grupo de conmutación por error en Recurso y Evento iniciado por muestra un solo guión (-) para indicar que Microsoft inició la conmutación por error. Esta información también se puede encontrar en la página Registro de actividad del nuevo servidor principal o instancia de Azure Portal.
Terminología y funcionalidades
Grupo de conmutación por error (FOG)
Un grupo de conmutación por error permite que todas las bases de datos de usuario de una instancia administrada conmuten por error como una unidad en otra región de Azure en caso de que la instancia administrada principal deje de estar disponible debido a una interrupción de la región primaria. Como los grupos de conmutación por error automática para SQL Managed Instance contiene todas las bases de datos de usuario de la instancia, solo se puede configurar un grupo de conmutación por error en una instancia.
Importante
El nombre del grupo de conmutación por error debe ser único globalmente en el dominio
.database.windows.net.Principal
Instancia administrada que hospeda las bases de datos principales del grupo de conmutación por error.
Secundario
Instancia administrada que hospeda las bases de datos secundarias del grupo de conmutación por error. La base de datos secundaria no puede estar en la misma región de Azure que la principal.
Importante
Si una base de datos contiene objetos OLTP en memoria, la instancia principal y la de réplica geográfica secundaria de destino deben tener niveles de servicio coincidentes, ya que los objetos OLTP en memoria residen en memoria. Un nivel de servicio inferior en la instancia de réplica geográfica puede dar lugar a problemas de memoria insuficiente. Si esto ocurre, es posible que la réplica secundaria no pueda recuperar la base de datos, lo que provoca una falta de disponibilidad de la base de datos secundaria junto con objetos OLTP en memoria en la base de datos geográfica secundaria. Esto, a su vez, podría hacer que las conmutaciones por error también sean incorrectas. Para evitarlo, asegúrate de que el nivel de servicio de la instancia secundaria geográfica coincide con el de la base de datos principal. Las actualizaciones de nivel de servicio pueden ser operaciones de tamaño de datos y es posible que tarden en finalizar.
Conmutación por error (sin pérdida de datos)
La conmutación por error realiza una sincronización de datos completa entre las bases de datos principales y secundarias antes de que el rol principal pase a la secundaria. De esta manera se garantiza que no hay pérdida de datos. La conmutación por error solo es posible cuando se puede acceder a la principal. La conmutación por error se usa en los siguientes escenarios:
- Realizar simulacros de recuperación ante desastres (DR) en producción cuando no es aceptable la pérdida de datos
- Reubicar la carga de trabajo a una región diferente
- Devolver la carga de trabajo a la región primaria después de que se ha corregido la interrupción (conmutación por recuperación)
Conmutación por error forzada (posible pérdida de datos)
La conmutación por error forzada cambia inmediatamente el rol secundario al rol primario sin tener que esperar a que los cambios recientes se propaguen desde el rol primario. Esta operación puede dar lugar a una potencial pérdida de datos. La conmutación por error forzada se usa como método de recuperación durante las interrupciones cuando no es posible acceder a la base de datos principal. Cuando se mitiga la interrupción, la base de datos principal anterior se vuelve a conectar automáticamente y se convierte en una nueva base de datos secundaria. Asimismo, se puede ejecutar una conmutación por error para realizar una conmutación por recuperación y devolver las réplicas a sus roles principal y secundario originales.
Período de gracia con pérdida de datos
Dado que los datos se replican en la base de datos secundaria mediante la replicación asincrónica, la conmutación por error forzada de grupos con directivas de conmutación por error administradas por Microsoft puede provocar la pérdida de datos. Puedes personalizar la directiva de conmutación por error para que refleje la tolerancia de la aplicación a la pérdida de datos. Si configuras
GracePeriodWithDataLossHours, puedes controlar durante cuánto tiempo espera el servicio Azure SQL antes de iniciar la conmutación por error forzada, aunque es probable que genere una pérdida de datos.
Zona DNS
Identificador único que se genera automáticamente cuando se crea una Instancia administrada de SQL. Se aprovisiona un certificado de varios dominios (SAN) para esta instancia a fin de autenticar las conexiones de cliente a cualquier instancia de la misma zona DNS. Las dos instancias administradas en el mismo grupo de conmutación por error deben compartir la zona DNS.
Agente de escucha de lectura-escritura de grupo de conmutación por error
Un registro CNAME de DNS que apunta a la base de datos principal actual. Se crea automáticamente cuando se crea el grupo de conmutación por error y permite que la carga de trabajo de lectura y escritura se vuelva a conectar de forma transparente a la principal cuando esta cambia después de la conmutación por error. Cuando se crea el grupo de conmutación por error en Instancia administrada de SQL, el registro CNAME de DNS para la dirección URL del cliente de escucha tiene el formato
<fog-name>.<zone_id>.database.windows.net.Agente de escucha de solo lectura de grupo de conmutación por error
Un registro CNAME de DNS que apunta a la base de datos secundaria actual. Se crea automáticamente cuando se crea el grupo de conmutación por error y permite que la carga de trabajo de SQL de solo lectura se vuelva a conectar de forma transparente a la secundaria cuando la secundaria cambia después de la conmutación por error. Cuando se crea el grupo de conmutación por error en Instancia administrada de SQL, el registro CNAME de DNS para la dirección URL del cliente de escucha tiene el formato
<fog-name>.secondary.<zone_id>.database.windows.net. De forma predeterminada, la conmutación por error del agente de escucha de solo lectura está deshabilitada, ya que garantiza que el rendimiento de la principal no se vea afectado cuando la base de datos secundaria esté sin conexión. En cambio, también significa que las sesiones de solo lectura no podrán conectarse hasta que se recupere la base de datos secundaria. Si no puedes tolerar tiempo de inactividad en las sesiones de solo lectura pero sí, usar la base de datos principal para el tráfico de solo lectura y el de lectura y escritura a costa de la posible degradación del rendimiento de esta, puedes habilitar la conmutación por error para el agente de escucha de solo lectura mediante la configuración de la propiedadAllowReadOnlyFailoverToPrimary. En ese caso, el tráfico de solo lectura se redirige automáticamente a la base de datos principal si la secundaria no está disponible.Nota:
La propiedad
AllowReadOnlyFailoverToPrimarysolo surte efecto si la directiva de conmutación por error administrada por Microsoft está habilitada y si se ha desencadenado una conmutación por error forzada. En ese caso, si la propiedad se establece en true, la nueva base de datos principal atenderá a las sesiones de lectura y escritura, y de solo lectura.
Arquitectura del grupo de conmutación por error
El grupo de conmutación por error debe estar configurado en la instancia principal y se conectará a la instancia secundaria de una región de Azure diferente. Todas las bases de datos de usuario de la instancia se replicarán en la instancia secundaria. Las bases de datos del sistema como master y msdb no se replicarán.
En el diagrama siguiente se ilustra una configuración típica de una aplicación en la nube con redundancia geográfica con instancia administrada y un grupo de conmutación por error:
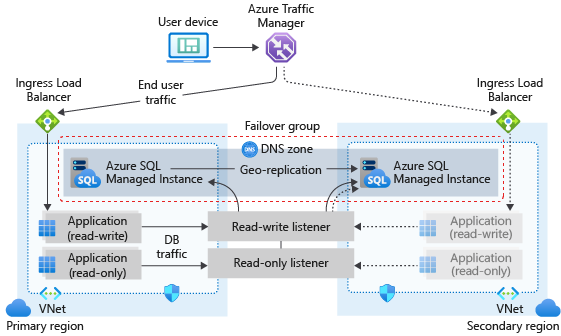
Si la aplicación utiliza SQL Managed Instance como la capa de datos, siga las directrices generales y los procedimientos recomendados que se describen en este artículo al realizar el diseño para la continuidad empresarial.
Creación de la instancia de ubicación geográfica secundaria
Para garantizar la conectividad sin interrupciones a la Instancia administrada de SQL principal después de la conmutación por error, las instancias principales y secundarias deben estar en la misma zona DNS. Esto garantiza que se pueda usar el mismo certificado de varios dominios (SAN) para autenticar las conexiones de cliente a cualquiera de las dos instancias del grupo de conmutación por error. Cuando la aplicación esté lista para la implementación en producción, cree una Instancia administrada de SQL secundaria en una región distinta y asegúrese de que comparte la zona DNS con la Instancia administrada de SQL principal. Puede hacerlo al especificar un parámetro opcional durante la creación. Si usa PowerShell o la API REST, el nombre del parámetro opcional es DNSZonePartner. El nombre del campo opcional correspondiente en Azure Portal es Primary Managed Instance (Instancia administrada principal).
Importante
La primera Instancia administrada creada en la subred determina la zona DNS de todas las instancias posteriores de la misma subred. Esto significa que dos instancias de la misma subred no pueden pertenecer a zonas DNS diferentes.
Para obtener más información sobre cómo crear la SQL Managed Instance secundaria en la misma zona DNS que la instancia principal, consulta Configurar un grupo de conmutación por error para Azure SQL Managed Instance.
Uso de regiones emparejadas
De cara al rendimiento, implemente ambas instancias administradas en regiones emparejadas. Los grupos de conmutación por error de SQL Managed Instance en regiones emparejadas tienen un mejor rendimiento en comparación con las regiones no emparejadas.
Azure SQL Managed Instance sigue una práctica de implementación segura en la que las regiones emparejadas de Azure no se suelen implementar al mismo tiempo. Sin embargo, no es posible predecir qué región se actualizará primero, por lo que no se garantiza el orden de implementación. A veces, la instancia principal se actualiza primero y, a veces, la instancia secundaria se actualiza primero.
En situaciones en las que Azure SQL Managed Instance forma parte de un grupo de conmutación por error y las instancias del grupo no están en regiones emparejadas de Azure, selecciona diferentes programaciones de ventana de mantenimiento para la base de datos principal y secundaria. Por ejemplo, seleccione una ventana de mantenimiento Día de la semana para la base de datos secundaria geográfica y una ventana de mantenimiento Fin de semana para la base de datos principal geográfica.
Habilitación y optimización del flujo de tráfico de replicación geográfica entre las instancias
Se debe establecer y mantener la conectividad entre las subredes de red virtual que hospedan la instancia principal y la secundaria para el flujo de tráfico de replicación geográfica ininterrumpido. Hay varias maneras de proporcionar conectividad entre las instancias para elegir en función de la topología de red y las directivas:
- Emparejamiento global de redes virtuales
- Puertas de enlace de VPN
- Información técnica de ExpressRoute
El emparejamiento global de redes virtuales (emparejamiento VNet) es la manera recomendada de establecer la conectividad entre dos instancias de un grupo de conmutación por error. Proporciona una conexión privada de ancho de banda alto y baja latencia entre las redes virtuales emparejadas mediante la infraestructura troncal de Microsoft. No se requiere ninguna red pública de Internet, puertas de enlace ni cifrado adicional en la comunicación entre las redes virtuales emparejadas.
Propagación inicial
Al establecer un grupo de conmutación por error entre instancias administradas, hay una fase de propagación inicial antes de que se inicie la replicación de datos. Esta fase de propagación inicial es la operación más larga y costosa de la operación. Una vez completada, se sincronizan los datos y solo se replican los cambios de datos posteriores. El tiempo que se tarda en completarse la propagación inicial depende del tamaño de los datos, el número de bases de datos replicadas, la intensidad de la carga de trabajo en las bases de datos principales y la velocidad del vínculo entre las redes virtuales que hospedan la instancia principal y secundaria, que depende principalmente de la forma en que se establece la conectividad. En circunstancias normales, y cuando se establece la conectividad mediante el emparejamiento global de redes virtuales recomendado, la velocidad de propagación es de hasta 360 GB por hora para SQL Managed Instance. La propagación se realiza para un lote de bases de datos de usuario en paralelo, y no necesariamente para todas las bases de datos al mismo tiempo. Es posible que se necesiten varios lotes si hay muchas bases de datos hospedadas en la instancia.
Si la velocidad del vínculo entre las dos instancias es más lenta de lo necesario, es probable que el tiempo de inicialización resulte muy afectado. Puede usar la velocidad de propagación indicada, el número de bases de datos, el tamaño total de los datos y la velocidad del vínculo para calcular cuánto tardará la fase de propagación inicial antes de que se inicie la replicación de los datos. Por ejemplo, en el caso de una sola base de datos de 100 GB, la fase de inicialización inicial tardaría aproximadamente 1,2 horas si el vínculo es capaz de insertar 84 GB por hora y si no hay otras bases de datos que se vayan a inicializar. Si el vínculo solo puede transferir 10 GB por hora, la propagación de una base de datos de 100 GB tardará aproximadamente 10 horas. Si hay que replicar varias bases de datos, la propagación se ejecutará en paralelo y, cuando se combina con una velocidad de vínculo baja, la fase de propagación inicial puede tardar mucho más tiempo, en especial si la propagación paralela de los datos de todas las bases de datos supera el ancho de banda de vínculo disponible.
Importante
En caso de que un vínculo vaya a una velocidad extremadamente baja o esté ocupado, lo que provoca que la fase de propagación inicial tarde días en realizarse, la creación de un grupo de conmutación por error puede agotar el tiempo de espera. El proceso de creación se cancelará automáticamente después de 6 días.
Administración de la conmutación por error geográfica en una instancia secundaria geográfica
El grupo de conmutación por error administra la conmutación por error geográfica de todas las bases de datos de la instancia administrada principal. Cuando se crea un grupo, cada base de datos de la instancia se replicará geográficamente de manera automática a la instancia secundaria geográfica. No se pueden usar grupos de conmutación por error para iniciar una conmutación por error parcial de un subconjunto de bases de datos.
Importante
Si se coloca una base de datos en la instancia administrada principal, también se colocará automáticamente en la instancia administrada secundaria de replicación geográfica.
Uso del cliente de escucha de lectura y escritura (MI principal)
Para cargas de trabajo de lectura y escritura, use <fog-name>.zone_id.database.windows.net como nombre del servidor. Las conexiones se dirigen automáticamente a la principal. Este nombre no cambia después de la conmutación por error. La conmutación por error geográfica implica actualizar el registro DNS para que las conexiones de cliente nuevas se enruten a la nueva base de datos principal cuando la caché DNS del cliente se haya actualizado. Dado que la instancia secundaria comparte la zona DNS con la principal, la aplicación cliente podrá volver a conectarse a ella con el mismo certificado de SAN del lado del servidor. Las conexiones de cliente existentes deben finalizarse y volver a crearse para que se enruten a la nueva principal. No se puede acceder al cliente de escucha de lectura y escritura, ni al cliente de escucha de solo lectura, mediante el punto de conexión público de la instancia administrada.
Uso del cliente de escucha de solo lectura (MI secundaria)
Si tiene cargas de trabajo de solo lectura aisladas lógicamente que son tolerantes a la latencia de datos, puede ejecutarlas en la base de datos secundaria geográfica. Para conectarse directamente a la base de datos secundaria geográfica, use <fog-name>.secondary.<zone_id>.database.windows.net como nombre del servidor.
En el nivel Crítico para la empresa, SQL Managed Instance admite el uso de réplicas de solo lectura para descargar cargas de trabajo de consulta de solo lectura, mediante el parámetro ApplicationIntent=ReadOnly de la cadena de conexión. Cuando se configuró una base de datos secundaria con replicación geográfica, se puede usar esta funcionalidad para conectarse a una réplica de solo lectura de la ubicación principal o de la ubicación con replicación geográfica:
- Para conectarse a una réplica de solo lectura en la ubicación principal, use
ApplicationIntent=ReadOnlyy<fog-name>.<zone_id>.database.windows.net. - Para conectarse a una réplica de solo lectura en la ubicación secundaria, use
ApplicationIntent=ReadOnlyy<fog-name>.secondary.<zone_id>.database.windows.net.
No se puede acceder al cliente de escucha de lectura y escritura, ni al cliente de escucha de solo lectura, mediante el punto de conexión público de la instancia administrada.
Posible degradación del rendimiento después de la conmutación por error
Una aplicación de Azure típica usa varios servicios de Azure y consta de varios componentes. La conmutación por error geográfica del grupo de conmutación por error se desencadena en función del estado de los componentes de Azure SQL. Es posible que otros servicios de Azure de la región primaria no se vean afectados por la interrupción y que sus componentes sigan estando disponibles en esa región. Una vez que las bases de datos principales cambien a la región secundaria, la latencia entre los componentes dependientes puede aumentar. Para evitar que la mayor latencia entre regiones afecte al rendimiento de la aplicación, garantiza la redundancia de todos los componentes de la aplicación en la región secundaria y realiza la conmutación por error de los componentes junto con la de la base de datos.
Posible pérdida de datos después de la conmutación por error forzada
Si se produce una interrupción en la región primaria, es posible que las transacciones recientes no se hayan replicado en la base de datos secundaria geográfica y que se produzca una pérdida de datos si se realiza una conmutación por error forzada.
Actualización de DNS
La actualización de DNS del agente de escucha de lectura y escritura sucederá inmediatamente después de que se inicie la conmutación por error. Esta operación no ocasionará la pérdida de datos. Sin embargo, el proceso de conmutación de roles de base de datos puede tardar hasta 5 minutos en condiciones normales. Hasta que se complete, algunas bases de datos de la nueva instancia principal seguirán siendo de solo lectura. Si se inicia una conmutación por error mediante PowerShell, la operación para cambiar el rol de la réplica principal es sincrónica. Si se inicia mediante Azure Portal, la interfaz de usuario indica el estado de finalización. Si se inicia mediante la API REST, use el mecanismo de sondeo estándar de Azure Resource Manager para supervisar la finalización.
Importante
Use la conmutación por error planeada manual para volver a transferir la principal a la ubicación original una vez mitigada la interrupción que provocó la conmutación por error geográfica.
Ahorro de costos con una réplica de recuperación ante desastres sin licencia
Puede ahorrar en los costos de licencia de SQL Server mediante la configuración de la instancia administrada secundaria que se usará solo para la recuperación ante desastres (DR). Para configurarlo, consulte Configuración de una réplica en espera sin licencia para Azure SQL Managed Instance.
Siempre que la instancia secundaria no se use para cargas de trabajo de lectura, Microsoft le proporciona un número gratuito de núcleos virtuales para que coincidan con la instancia principal. Todavía se le cobra por el proceso y el almacenamiento que usa la instancia secundaria. Los grupos de conmutación por error solo admiten una réplica: la réplica debe ser legible o designarse como solo de recuperación ante desastres.
Habilitación de escenarios que dependen de objetos de las bases de datos del sistema
Las bases de datos del sistema no se replican en la instancia secundaria de un grupo de conmutación por error. Para habilitar escenarios que dependen de los objetos de las bases de datos del sistema, asegúrese de crear los mismos objetos en la instancia secundaria y mantenerlos sincronizados con la instancia principal.
Por ejemplo, si tiene previsto utilizar los mismos inicios de sesión en la instancia secundaria, asegúrese de crearlos con el SID idéntico.
-- Code to create login on the secondary instance
CREATE LOGIN foo WITH PASSWORD = '<enterStrongPasswordHere>', SID = <login_sid>;
Para más información, consulte el artículo sobre la replicación de inicios de sesión y trabajos de agente.
Sincronización de las propiedades de instancia y las instancias de directivas de retención
Las instancias de un grupo de conmutación por error siguen siendo recursos de Azure independientes y ningún cambio que se haga en la configuración de la instancia principal se replicará automáticamente en la instancia secundaria. Por ello, asegúrese de realizar todos los cambios relevantes tanto en la instancia principal como en la secundaria. Por ejemplo, si cambia la redundancia del almacenamiento de copia de seguridad o la directiva de retención de copias de seguridad a largo plazo en la instancia principal, asegúrese de cambiarla también en la instancia secundaria.
Instancias de escalado
Puede escalar verticalmente o reducir verticalmente la instancia principal o secundaria a un tamaño de proceso diferente en el mismo nivel de servicio. Cuando se escala verticalmente dentro del mismo nivel de servicio, se recomienda escalar verticalmente primero la secundaria geográfica y, después, escalar verticalmente la principal. Al reducir verticalmente dentro del mismo nivel de servicio, invierta el orden: primero escale verticalmente la principal y, a continuación, escale verticalmente la secundaria. Cuando se escala la instancia a un nivel de servicio diferente, se aplica esta recomendación. La secuencia de operaciones se aplica al escalar el nivel de servicio y los núcleos virtuales, así como el almacenamiento.
La secuencia se recomienda específicamente para evitar que la base de datos secundaria geográfica de una SKU inferior se sobrecargue y deba reinicializarse durante un proceso de actualización o degradación.
Importante
- Para las instancias dentro de un grupo de conmutación por error, no se admite el cambio del nivel de servicio a, o desde, el nivel de uso general de próxima generación. Primero debe eliminar el grupo de conmutación por error antes de modificar cualquiera de las réplicas y, a continuación, volver a crear el grupo de conmutación por error después de que el cambio surta efecto.
- Hay un problema conocido que puede afectar a la accesibilidad de la instancia que se escala mediante el agente de escucha del grupo de migración tras error asociado.
Evitación la pérdida de datos críticos
Debido a la elevada latencia de las redes de área extensa, la replicación geográfica usa un mecanismo de replicación asincrónica. La replicación asincrónica hace que la posibilidad de perder datos sea inevitable si se produce un error en la principal. Para proteger las transacciones críticas contra la pérdida de datos, un desarrollador de aplicaciones puede llamar al procedimiento almacenado sp_wait_for_database_copy_sync inmediatamente después de confirmar la transacción. La llamada a sp_wait_for_database_copy_sync bloquea el subproceso de llamada hasta que se transmite y protege la última transacción confirmada en el registro de transacciones de la base de datos secundaria. Pero no espera a que las transacciones transmitidas se reproduzcan (vuelvan a hacerse) en la secundaria. sp_wait_for_database_copy_sync está limitado a un vínculo de replicación geográfica específico. Cualquier usuario con derechos de conexión para la base de datos principal puede llamar a este procedimiento.
Para evitar la pérdida de datos durante la conmutación por error geográfica planeada iniciada por el usuario, la replicación cambia automática y temporalmente a replicación sincrónica y, a continuación, realiza una conmutación por error. Después, la replicación vuelve al modo asincrónico una vez completada la conmutación por error geográfica.
Nota:
sp_wait_for_database_copy_sync evita la pérdida de datos después de la conmutación por error geográfica para transacciones específicas, pero no garantiza la sincronización completa para el acceso de lectura. El retraso provocado por una llamada al procedimiento sp_wait_for_database_copy_sync puede ser considerable y depende del tamaño del registro de transacciones que todavía no se transmiten en la principal en el momento de la llamada.
Estado del grupo de conmutación por error
El grupo de conmutación por error informa de su estado describiendo el estado actual de la replicación de datos:
- Inicialización: la inicialización inicial tiene lugar después de la creación del grupo de conmutación por error, hasta que todas las bases de datos de usuario se inicializan en la instancia secundaria. No se puede iniciar el proceso de conmutación por error mientras el grupo de conmutación por error se encuentra en estado de inicialización, ya que las bases de datos de usuario aún no se copian en la instancia secundaria.
- Sincronización: el estado habitual del grupo de conmutación por error. Esto significa que los cambios de datos de la instancia principal se replican de forma asincrónica en la instancia secundaria. Este estado no garantiza que los datos estén totalmente sincronizados en cada momento. Puede haber cambios en los datos del servidor principal que todavía se va a replicar en la base de datos secundaria debido a la naturaleza asincrónica del proceso de replicación entre instancias del grupo de conmutación por error. Tanto las conmutaciones por error automáticas como las manuales se pueden iniciar mientras el grupo de conmutación por error se encuentra en estado de sincronización.
- Conmutación por error en curso: este estado indica que el proceso de conmutación por error iniciado de forma automática o manual está en curso. No se pueden iniciar cambios en el grupo de conmutación por error ni conmutaciones por error adicionales mientras el grupo de conmutación por error se encuentra en este estado.
Conmutación por recuperación
Cuando los grupos de conmutación por error se configuran con una directiva de conmutación por error administrada por Microsoft, la conmutación por error al servidor geográfico secundario se inicia durante un escenario de desastre según el período de gracia que se definió. La conmutación por recuperación al servidor principal anterior debe iniciarse manualmente.
Interoperabilidad de las características
Copias de seguridad
En los escenarios siguientes se realiza una copia de seguridad completa:
- Antes de que se inicie la propagación inicial al crear un grupo de migración tras error.
- Después de una migración tras error.
Una copia de seguridad completa es un tamaño de operación de datos que no se puede omitir ni aplazar, y puede tardar algún tiempo en completarse. El tiempo necesario para completarse depende del tamaño de los datos, del número de bases de datos y de la intensidad de la carga de trabajo en las bases de datos principales. Una copia de seguridad completa puede retrasar considerablemente la propagación inicial y puede retrasar o evitar una operación de migración tras error en una nueva instancia poco después de una migración tras error.
Servicio de reproducción de registros
Las bases de datos migradas a Azure SQL Managed Instance mediante el Servicio de reproducción de registros (LRS) no se pueden agregar a un grupo de migración tras error hasta que se ejecute el paso de transición. Una base de datos migrada con LRS está en un estado de restauración hasta la migración, y las bases de datos en un estado de restauración no se pueden agregar a un grupo de migración tras error. Al intentar crear un grupo de migración tras error con una base de datos en un estado de restauración, se retrasa la creación del grupo de migración tras error hasta que se complete la restauración de la base de datos.
Replicación transaccional
Se admite el uso de la replicación transaccional con instancias que se encuentran en un grupo de conmutación por error. Sin embargo, si configura la replicación antes de agregar una instancia administrada de SQL a un grupo de conmutación por error, la replicación se detiene temporalmente cuando empiece a crear el grupo de conmutación por error y el monitor de replicación muestra el estado Replicated transactions are waiting for the next log backup or for mirroring partner to catch up. La replicación se reanuda una vez que el grupo de conmutación por error se crea correctamente.
Si una instancia administrada de SQL de un publicador o distribuidor se encuentra en un grupo de conmutación por error, el administrador de la instancia administrada de SQL debe limpiar todas las publicaciones de la instancia principal anterior y volver a configurarlas en la nueva instancia principal después de una conmutación por error. Revise la guía de replicación transaccional para conocer el paso de las actividades necesarias en este escenario.
Permisos y limitaciones
Revise una lista de permisos y limitaciones antes de configurar un grupo de migración tras error.
Administración mediante programación de grupos de conmutación por error
Los grupos de conmutación por error también se pueden administrar mediante programación con Azure PowerShell, la CLI de Azure y la API de REST. Para obtener más información, consulta Configuración del grupo de conmutación por error.
Maniobras de recuperación ante desastres
La manera recomendada de realizar un simulacro de recuperación ante desastres es usar la conmutación por error planeada manual, según el siguiente tutorial: Prueba de conmutación por error.
No se recomienda realizar un simulacro mediante la conmutación por error forzada, ya que esta operación no proporciona límites de protección contra la pérdida de datos. Sin embargo, es posible lograr la conmutación por error forzada sin pérdida de datos asegurándose de que se cumplen las siguientes condiciones antes de iniciar la conmutación por error forzada:
- La carga de trabajo se detiene en la instancia administrada principal.
- Todas las transacciones de larga duración se han completado.
- Todas las conexiones de cliente a la instancia administrada principal se han desconectado.
- El estado del grupo de conmutación por error es "Sincronizar".
Asegúrese de que las dos instancias administradas tienen roles modificados y que el estado del grupo de conmutación por error ha cambiado de "Conmutación por error en curso" a "Sincronización" antes de establecer opcionalmente las conexiones a la nueva instancia administrada principal e iniciar la carga de trabajo de lectura y escritura.
Para realizar una conmutación por recuperación sin pérdida de datos en los roles de instancia administrada original, se recomienda encarecidamente usar la conmutación por error planeada manual en lugar de la conmutación por error forzada. Si se usa la conmutación por recuperación forzada:
- Siga los mismos pasos que para la conmutación por error sin pérdida de datos.
- Se espera un tiempo de ejecución de conmutación por recuperación más largo si la conmutación por recuperación forzada se ejecuta poco después de que se complete la conmutación por error forzada inicial, ya que tiene que esperar a que se completen las operaciones de copia de seguridad automática pendientes en la instancia administrada principal anterior.
- Las operaciones pendientes de copia de seguridad automática en la instancia administrada que realicen la transición del rol principal al secundario afectarán a la disponibilidad de la base de datos en esta instancia.
- Utilice el estado del grupo de conmutación por error para determinar si ambas instancias han cambiado correctamente sus roles y están listas para aceptar conexiones de cliente.
Contenido relacionado
- Configuración de un grupo de conmutación por error
- Uso de PowerShell para agregar una instancia administrada a un grupo de conmutación por error
- Configuración de una réplica en espera sin licencia para Azure SQL Managed Instance
- Introducción a la continuidad del negocio con Azure SQL Managed Instance
- Copias de seguridad automatizadas en Azure SQL Managed Instance
- Restauración de una base de datos desde una copia de seguridad en Azure SQL Managed Instance