Modelo de compra vCore - Azure SQL Database
se aplica a:![]() de Azure SQL Database
de Azure SQL Database
En este artículo se revisa el modelo de compra de núcleo virtual para Azure SQL Database.
Visión general
Un núcleo virtual (núcleo virtual) representa una CPU lógica y le ofrece la opción de elegir las características físicas del hardware (por ejemplo, el número de núcleos, la memoria y el tamaño de almacenamiento). El modelo de compra basado en núcleo virtual ofrece flexibilidad, control, transparencia del consumo de recursos individuales y una manera sencilla de traducir los requisitos de carga de trabajo locales a la nube. Este modelo optimiza el precio y permite elegir los recursos de proceso, memoria y almacenamiento en función de las necesidades de la carga de trabajo.
En el modelo de compra basado en núcleo virtual, los costos dependen de la elección y el uso de:
- Nivel de servicio
- Configuración de hardware
- Recursos de proceso (el número de núcleos virtuales y la cantidad de memoria)
- Almacenamiento reservado de base de datos
- Almacenamiento de copia de seguridad real
Importante
Los recursos de proceso, la E/S y el almacenamiento de datos y de registro se cobran por base de datos o grupo elástico. El almacenamiento de copia de seguridad se cobra por cada base de datos. Para más información sobre los precios, consulte la página de precios de Azure SQL Database.
Comparación de los modelos de compra de vCore y DTU
El modelo de compra de núcleo virtual que usa Azure SQL Database proporciona varias ventajas con respecto al modelo de compra basado en DTU:
- Mayores límites de proceso, memoria, E/S y almacenamiento.
- Elección de la configuración de hardware para que coincida mejor con los requisitos de proceso y memoria de la carga de trabajo.
- Descuentos de precios para Ventaja híbrida de Azure (AHB).
- Mayor transparencia en los detalles de hardware que impulsan el proceso, lo que facilita la planeación de migraciones desde implementaciones locales.
- Los precios de las instancias reservadas solo están disponibles para el modelo de compra de núcleo virtual.
- Mayor granularidad de escalado con varios tamaños de proceso disponibles.
Para obtener ayuda para elegir entre los modelos de compra de vCore y DTU, consulte las diferencias entre los modelos de compra basados en vCore y DTU.
Calcular
El modelo de compra basado en núcleo virtual tiene un nivel de proceso aprovisionado y otro sin servidor. En el nivel de proceso aprovisionado, el costo de proceso refleja la capacidad total de proceso aprovisionada continuamente para la aplicación independientemente de la actividad de carga de trabajo. Elija la asignación de recursos que mejor se adapte a sus necesidades empresariales en función de los requisitos de núcleo virtual y memoria y, a continuación, escale y reduzca verticalmente los recursos según sea necesario para la carga de trabajo. En el nivel de proceso sin servidor para Azure SQL Database, los recursos de proceso se escalan automáticamente en función de la capacidad de carga de trabajo y se facturan por la cantidad de proceso que se usa, por segundo.
Para resumir:
- Aunque el nivel de proceso aprovisionado
proporciona una cantidad específica de recursos de proceso que se aprovisionan continuamente independientemente de la actividad de carga de trabajo, el nivel de proceso sin servidor escala automáticamente los recursos de proceso en función de la actividad de carga de trabajo. - Aunque el nivel de capacidad de proceso aprovisionada factura la cantidad de capacidad aprovisionada a un precio fijo por hora, el nivel de procesamiento sin servidor factura por la cantidad de proceso utilizado, por segundo.
Independientemente del nivel de proceso, se asignan automáticamente tres réplicas secundarias de alta disponibilidad adicionales en el nivel de servicio Crítico para la empresa para proporcionar alta resistencia a errores y conmutaciones por error rápidas. Estas réplicas adicionales hacen que el costo sea aproximadamente 2,7 veces mayor que en el nivel de servicio de Uso General. Del mismo modo, el mayor costo de almacenamiento por GB en el nivel de servicio Crítico para la empresa refleja los límites de E/S más altos y la menor latencia del almacenamiento SSD local.
En Hiperescala, los clientes controlan el número de réplicas de alta disponibilidad adicionales de 0 a 4 para obtener el nivel de resistencia requerido por sus aplicaciones mientras controlan los costos.
Para más información sobre el proceso en Azure SQL Database, consulte Recursos de proceso (CPU y memoria).
Límites de recursos
En el caso de los límites de recursos de núcleo virtual, revise las configuraciones de hardware disponibles y, a continuación, revise los límites de recursos para:
Almacenamiento de datos y registros
Los siguientes factores afectan a la cantidad de almacenamiento que se usa para los archivos de datos y de registro y se aplican a los niveles De uso general y Crítico para la empresa.
- Cada tamaño de proceso admite un tamaño máximo de datos configurable, con un valor predeterminado de 32 GB.
- Al configurar el tamaño máximo de los datos, se agrega automáticamente un 30 % adicional de almacenamiento facturable para el archivo de registro.
- En el nivel de servicio De uso general,
tempdbusa almacenamiento SSD local y este costo de almacenamiento se incluye en el precio del núcleo virtual. - En el nivel de servicio Crítico para la empresa,
tempdbcomparte el almacenamiento local de SSD con datos y archivos de registro, y el costo de almacenamientotempdbse incluye en el precio del núcleo virtual. - En los niveles Uso general y Crítico para la empresa, se le cobra por el tamaño máximo de almacenamiento configurado para una base de datos o un grupo elástico.
- Para SQL Database, puede seleccionar cualquier tamaño máximo de datos entre 1 GB y el tamaño de almacenamiento máximo admitido, en incrementos de 1 GB.
Las siguientes consideraciones de almacenamiento se aplican a Hiperescala:
- El tamaño máximo de almacenamiento de datos se establece en 128 TB y no se puede configurar.
- Solo se le cobra por el almacenamiento de datos asignado, no por el almacenamiento de datos máximo.
- No se le cobrará por el almacenamiento de registros.
tempdbusa almacenamiento SSD local y su costo se incluye en el precio del núcleo virtual. Si desea supervisar el tamaño actual del almacenamiento de datos asignados y utilizados en SQL Database, use las métricas allocated_data_storage y storage de Azure Monitor, respectivamente.
Para supervisar el tamaño de almacenamiento asignado y usado actual de los archivos de registro y datos individuales de una base de datos mediante T-SQL, use la vista sys.database_files y la función FILEPROPERTY(... , "SpaceUsed").
Sugerencia
En algunas circunstancias, es posible que tenga que reducir una base de datos para reclamar espacio sin usar. Para más información, consulte Administración del espacio de archivos en Azure SQL Database.
Almacenamiento de copia de seguridad
El almacenamiento para las copias de seguridad de bases de datos se asigna para admitir las capacidades de restauración a un momento dado (PITR) y de retención a largo plazo (LTR) de la Base de Datos SQL. Este almacenamiento es independiente del almacenamiento de archivos de registro y de datos y se factura por separado.
- PITR: En los niveles De uso general y Crítico para la empresa, las copias de seguridad de base de datos individuales se copian en Azure Storage automáticamente. El tamaño de almacenamiento aumenta dinámicamente a medida que se crean nuevas copias de seguridad. El almacenamiento se utiliza para copias de seguridad completas, diferenciales y del registro de transacciones. El consumo de almacenamiento depende de la tasa de cambio de la base de datos y del período de retención configurado para las copias de seguridad. Puede configurar un período de retención independiente para cada base de datos entre 1 y 35 días para SQL Database. Se proporciona una cantidad de almacenamiento de copia de seguridad igual al tamaño máximo de datos configurado sin cargo adicional.
- LTR: también puede configurar la retención a largo plazo de copias de seguridad completas durante hasta 10 años. Si configura una directiva LTR, estas copias de seguridad se almacenan automáticamente en Azure Blob Storage, pero puede controlar la frecuencia con la que se copian las copias de seguridad. Para cumplir los distintos requisitos de cumplimiento, puede seleccionar diferentes períodos de retención para las copias de seguridad semanales, mensuales o anuales. La configuración que elija determina la cantidad de almacenamiento que se usa para las copias de seguridad de LTR. Para obtener más información, vea Retención de copias de seguridad a largo plazo.
Para el almacenamiento de copia de seguridad en Hiperescala, consulte Copias de seguridad automatizadas para bases de datos de Hiperescala.
Niveles de servicio
Entre las opciones de nivel de servicio del modelo de compra de núcleo virtual se incluyen Uso general, Crítico para la empresa e Hiperescala. El nivel de servicio generalmente determina el tipo de almacenamiento y el rendimiento, las opciones de alta disponibilidad y recuperación ante desastres, y la disponibilidad de determinadas características, como In-Memory OLTP.
| Caso de uso | Uso general | crítico para la empresa | Hiperescala |
|---|---|---|---|
| Más adecuado para | La mayoría de las cargas de trabajo empresariales. Ofrece opciones de proceso y almacenamiento escalables, equilibradas y orientadas al presupuesto. | Ofrece a las aplicaciones empresariales la mayor resistencia a los errores mediante el uso de varias réplicas secundarias de alta disponibilidad y proporciona el mayor rendimiento de E/S. | La mayor variedad de cargas de trabajo, incluidas las que tienen requisitos de almacenamiento y de escalabilidad de lectura altamente escalables. Ofrece una mayor resistencia a los errores al permitir la configuración de más de una réplica secundaria de alta disponibilidad. |
| Tamaño de proceso | De 2 a 128 núcleos virtuales | De 2 a 128 núcleos virtuales | De 2 a 128 núcleos virtuales |
| tipo de almacenamiento | Almacenamiento remoto Premium (por instancia) | Almacenamiento SSD local super rápido (por instancia) | Almacenamiento desacoplado con caché de unidad de estado sólido local (por réplica de proceso) |
| tamaño de almacenamiento | 1 GB – 4 TB | 1 GB – 4 TB | 10 GB : 128 TB |
| IOPS | 320 IOPS por núcleo virtual con 16 000 IOPS máximas | 4000 IOPS por núcleo virtual con 327 680 IOPS máximas | 327 680 IOPS con SSD local máximo Hiperescala es una arquitectura de varios niveles con almacenamiento en caché en varios niveles. Las IOPS efectivas dependen de la carga de trabajo. |
| Memoria/núcleo virtual | 5,1 GB | 5,1 GB | 5,1 GB o 10,2 GB |
| Copias de seguridad | Una opción de almacenamiento de copia de seguridad con redundancia geográfica, con redundancia de zona o con redundancia local, retención de 1 a 35 días (7 días predeterminado) Retención a largo plazo disponible hasta 10 años |
Una opción de almacenamiento de copia de seguridad con redundancia geográfica, con redundancia de zona o con redundancia local, retención de 1 a 35 días (7 días predeterminado) Retención a largo plazo disponible hasta 10 años |
Una opción de almacenamiento con redundancia local (LRS), redundancia de zona (ZRS) o con redundancia geográfica (GRS) Retención de 1 a 35 días (7 días de forma predeterminada), con hasta 10 años de retención a largo plazo disponible |
| Disponibilidad | Una réplica, sin réplicas de escalado de lectura, alta disponibilidad (HA) con redundancia de zona |
Tres réplicas, una réplica de escalado de lectura, alta disponibilidad (HA) con redundancia de zona |
alta disponibilidad (HA) con redundancia de zona |
| precios y facturación | El núcleo virtual, el almacenamiento reservado y el almacenamiento de copia de seguridad se cobran. No se cobran IOPS. |
vCore, el almacenamiento reservado y el almacenamiento de copia de seguridad se cobran. No se cobran IOPS. |
Se cobran los núcleos virtuales de cada réplica y el almacenamiento usado. No se cobran IOPS. |
| Modelos de descuento | Instancias reservadas Beneficio Híbrido de Azure (no disponible en suscripciones de desarrollo y pruebas) Suscripciones de Enterprise y ofertas de desarrollo/pruebas de pago por uso |
Instancias reservadas beneficio híbrido de Azure (no disponible en las suscripciones de desarrollo y pruebas) Suscripciones de Enterprise y ofertas de desarrollo/pruebas de pago por uso |
ventaja híbrida de Azure (no disponible en suscripciones de desarrollo y pruebas) 1 Suscripciones de Enterprise y ofertas de desarrollo/pruebas de pago por uso |
| tablas OLTP en memoria | No | Sí | No |
1 Precios simplificados para SQL Database Hyperscale próximamente. Revise el blog de precios de Hiperescala para obtener más información.
Para obtener más información, revise los límites de recursos para servidor lógico, bases de datos únicasy bases de datos agrupadas.
Nota
Para más información sobre el Acuerdo de Nivel de Servicio (SLA), consulte SLA for Azure SQL Database
Uso general
El modelo de arquitectura para el nivel de servicio De uso general se basa en una separación de proceso y almacenamiento. Este modelo de arquitectura se basa en la alta disponibilidad y confiabilidad de Azure Blob Storage que replica de forma transparente los archivos de base de datos y garantiza ninguna pérdida de datos si se produce un error de infraestructura subyacente.
En la ilustración siguiente se muestran cuatro nodos en el modelo de arquitectura estándar con las capas de proceso y almacenamiento separadas.
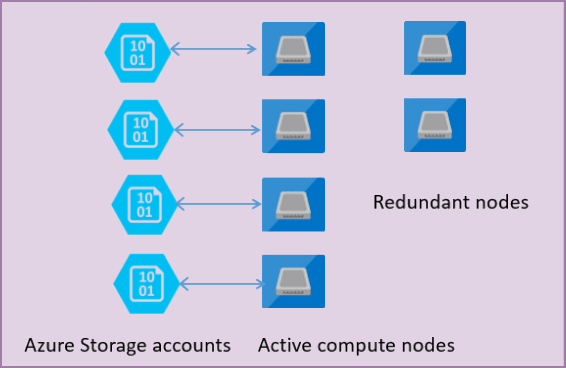
En el modelo de arquitectura del nivel de servicio De uso general, hay dos capas:
- Una capa de proceso sin estado que ejecuta el proceso de
sqlservr.exey solo contiene datos transitorios y almacenados en caché (por ejemplo, caché de planes, grupo de búferes, grupo de almacén de columnas). Este nodo sin estado lo opera Azure Service Fabric, que inicializa el proceso, controla el estado del nodo y realiza la conmutación por error en otro lugar si es necesario. - Una capa de datos con estado con archivos de base de datos (.mdf o .ldf) que se almacenan en Azure Blob Storage. Azure Blob Storage garantiza que no se pierda ningún registro que se coloque en ningún archivo de base de datos. Azure Storage tiene una disponibilidad o redundancia de datos integrada que garantiza que todos los registros del archivo de registro o la página del archivo de datos se conserven incluso si el proceso se bloquea.
Cada vez que se actualiza el motor de base de datos o el sistema operativo, se produce un error en alguna parte de la infraestructura subyacente o si se detecta algún problema crítico en el proceso de sqlservr.exe, Azure Service Fabric mueve el proceso sin estado a otro nodo de proceso sin estado. Hay un conjunto de nodos de reserva que están listos para ejecutar un nuevo servicio de computación si se produce una conmutación por error del nodo principal para minimizar el tiempo de falla. Los datos de la capa de almacenamiento de Azure no se ven afectados y los archivos de datos/registro se adjuntan al proceso recién inicializado. Este proceso garantiza una disponibilidad del 99.99% de forma predeterminada y una disponibilidad del 99.995% cuando se habilita la redundancia de zona . Es posible que haya algunos impactos en el rendimiento en cargas de trabajo intensivas que están en vuelo debido al tiempo de transición y al hecho de que el nuevo nodo comience con caché fría.
Cuándo elegir este nivel de servicio
El nivel de servicio De uso general es el nivel de servicio predeterminado en Azure SQL Database diseñado para la mayoría de las cargas de trabajo genéricas. Si necesita un motor de base de datos totalmente administrado con un Acuerdo de Nivel de Servicio y una latencia de almacenamiento predeterminados entre 5 ms y 10 ms, el nivel De uso general es la opción para usted.
Crítico para la empresa
El modelo de nivel de servicio Crítico para la empresa se basa en un clúster de procesos del motor de base de datos. Este modelo de arquitectura se basa en un cuórum de nodos del motor de base de datos para minimizar los impactos en el rendimiento de la carga de trabajo, incluso durante las actividades de mantenimiento. Las actualizaciones y revisiones del sistema operativo subyacente, los controladores y el motor de base de datos se producen de forma transparente, con un tiempo de inactividad mínimo para los usuarios finales.
En el modelo crítico para la empresa, el proceso y el almacenamiento se integran en cada nodo. La replicación de datos entre los procesos del motor de base de datos en cada nodo de un clúster de cuatro nodos alcanza una alta disponibilidad, y cada nodo utiliza un SSD conectado localmente como almacenamiento de datos. En el siguiente diagrama se muestra cómo el nivel de servicio Crítico para el negocio organiza un clúster de nodos del motor de bases de datos en réplicas de grupo de disponibilidad.

Tanto el proceso del motor de base de datos como los archivos .mdf/.ldf subyacentes se colocan en el mismo nodo con almacenamiento SSD conectado localmente, lo que proporciona baja latencia a la carga de trabajo. La alta disponibilidad se implementa mediante tecnología similar a SQL Server grupos de disponibilidad AlwaysOn. Cada base de datos es un clúster de nodos de base de datos con una réplica principal que es accesible para las cargas de trabajo del cliente y tres réplicas secundarias que contienen copias de datos. La réplica principal inserta constantemente los cambios en las réplicas secundarias para asegurarse de que los datos están disponibles en las réplicas secundarias si se produce un error en la principal por cualquier motivo. Service Fabric y el motor de base de datos controlan la conmutación por error: una réplica secundaria se convierte en la principal y se crea una réplica secundaria para garantizar que hay suficientes nodos en el clúster. La carga de trabajo se redirige automáticamente a la nueva réplica principal.
Además, el clúster Crítico para la empresa tiene una capacidad Escalado horizontal de lectura integrada, que proporciona una réplica de solo lectura gratuita usada para ejecutar consultas de solo lectura (por ejemplo, informes) que no afectarán al rendimiento de la carga de trabajo en la réplica principal.
Cuándo elegir este nivel de servicio
El nivel de servicio Crítico para la empresa está diseñado para aplicaciones que requieren respuestas de baja latencia del almacenamiento SSD subyacente (de 1 a 2 ms en promedio), una recuperación más rápida si se produce un error en la infraestructura subyacente o necesita desactivar la carga de informes, análisis y consultas de solo lectura a la réplica secundaria legible de cargo de la base de datos principal.
Las principales razones por las que debe elegir el nivel de servicio Crítico para la empresa en lugar del nivel de uso general son:
- requisitos de latencia de E/S baja: las cargas de trabajo que necesitan una respuesta rápida coherente de la capa de almacenamiento (de 1 a 2 milisegundos en promedio) deben usar el nivel Crítico para la empresa.
- Carga de trabajo con informes y consultas analíticas donde basta con una única réplica secundaria gratuita de solo lectura.
- mayor resistencia y recuperación más rápida frente a errores. En caso de que se produzca un error del sistema, la base de datos en la instancia principal está deshabilitada y una de las réplicas secundarias se convierte inmediatamente en la nueva base de datos principal de lectura y escritura, lista para procesar las consultas.
- protección avanzada contra daños en los datos. Dado que el nivel Crítico para la empresa usa réplicas de bases de datos en segundo plano, el servicio usa la reparación automática de páginas que hay disponible con la creación de reflejo y los grupos de disponibilidad para ayudar a mitigar los datos dañados. Si una réplica no puede leer una página debido a un problema de integridad de datos, se recupera una copia nueva de la página de otra réplica, reemplazando la página no legible sin pérdida de datos ni tiempo de inactividad del cliente. Esta funcionalidad está disponible en el nivel De uso general si la base de datos tiene réplica secundaria geográfica.
- Mayor disponibilidad - El nivel de Empresa Crítica en una configuración de zona de disponibilidad múltiple proporciona resistencia a errores zonales y un Acuerdo de Nivel de Servicio de mayor disponibilidad.
- Recuperación geográfica rápida: cuando se configura la replicación geográfica activa, el nivel Crítico para la empresa tiene un Objetivo de punto de recuperación (RPO) garantizado de 5 segundos y un Objetivo de tiempo de recuperación (RTO) de 30 segundos durante el 100 % de las horas implementadas.
Hiperescala
El nivel de servicio Hiperescala es adecuado para todos los tipos de carga de trabajo. Su arquitectura nativa en la nube proporciona un proceso y almacenamiento escalables de forma independiente para admitir la amplia variedad de aplicaciones tradicionales y modernas. Los recursos de proceso y almacenamiento en Hiperescala superan considerablemente los recursos disponibles en los niveles De uso general y Crítico para la empresa.
Para obtener más información, revise Nivel de servicio Hiperescala para Azure SQL Database.
Cuándo elegir este nivel de servicio
El nivel de servicio Hiperescala quita muchos de los límites prácticos que tradicionalmente se ven en las bases de datos en la nube. Cuando la mayoría de las demás bases de datos están limitadas por los recursos disponibles en un solo nodo, las bases de datos del nivel de servicio Hiperescala no tienen estos límites. Con su arquitectura de almacenamiento flexible, una base de datos de Hiperescala crece según sea necesario y solo se le factura la capacidad de almacenamiento que use.
Además de sus funcionalidades de escalado avanzadas, Hiperescala es una excelente opción para cualquier carga de trabajo, no solo para bases de datos grandes. Con Hiperescala, puede hacer lo siguiente:
- Lograr una alta resistencia y recuperación rápida de errores a la vez que se controla el costo, al elegir el número de réplicas de alta disponibilidad de 0 a 4.
- Mejore la alta disponibilidad de habilitando la redundancia de zona para el cálculo y el almacenamiento.
- Lograr una baja latencia de E/S de (de 1 a 2 milisegundos en promedio) para la parte de la base de datos que se accede con frecuencia. En el caso de las bases de datos más pequeñas, esto puede aplicarse a toda la base de datos.
- Implementar una gran variedad de escenarios de escalado horizontal de lectura con réplicas con nombre.
- Aproveche el rápido escalado de a, sin esperar a que los datos se copien en el almacenamiento local en los nuevos nodos.
- Disfrutar de la copia de seguridad continua de la base de datos con impacto cero y la restauración rápida.
- Disponer de compatibilidad con los requisitos de continuidad empresarial mediante grupos de conmutación por error y replicación geográfica.
Configuración de hardware
Entre las configuraciones de hardware comunes del modelo de núcleo virtual se incluyen la serie estándar (Gen5), la serie Fsv2 y la serie DC. Hiperescala también proporciona una opción para la serie premium y para el hardware optimizado para memoria de la serie premium. La configuración de hardware define los límites de proceso y memoria y otras características que afectan al rendimiento de la carga de trabajo.
Algunas configuraciones de hardware como la serie estándar (Gen5) pueden usar más de un tipo de procesador (CPU), como se describe en Recursos de proceso (CPU y memoria). Aunque una base de datos determinada o un grupo elástico tiende a permanecer en el hardware con el mismo tipo de CPU durante mucho tiempo (normalmente durante varios meses), hay determinados eventos que pueden hacer que una base de datos o un grupo se muevan al hardware que usa un tipo de CPU diferente.
Se puede mover una base de datos o un grupo para una variedad de escenarios, entre los que se incluyen, entre otros:
- Se cambia el objetivo de servicio.
- La infraestructura actual de un centro de datos se está aproximando a los límites de capacidad.
- El hardware usado actualmente se está retirando debido a su fin de vida
- La configuración con redundancia de zona está habilitada, pasando a otro hardware debido a la capacidad disponible.
En algunas cargas de trabajo, un cambio a otro tipo de CPU puede cambiar el rendimiento. SQL Database configura el hardware con el objetivo de proporcionar un rendimiento predecible de la carga de trabajo incluso si cambia el tipo de CPU, manteniendo los cambios de rendimiento dentro de una banda estrecha. Sin embargo, en todo el amplio espectro de cargas de trabajo de clientes de SQL Database y a medida que haya nuevos tipos de CPU disponibles, en ocasiones es posible ver cambios más notables en el rendimiento, si una base de datos o un grupo se mueve a un tipo de CPU diferente.
Independientemente del tipo de CPU usado, los límites de recursos de una base de datos o un grupo elástico (como el número de núcleos, la memoria, el número máximo de IOPS de datos, la tasa máxima de registro y el número máximo de trabajos simultáneos) seguirán siendo los mismos que la base de datos permanece en el mismo objetivo de servicio.
Recursos de proceso (CPU y memoria)
En la tabla siguiente se comparan los recursos de proceso en diferentes configuraciones de hardware y niveles de proceso:
| Configuración de hardware | Unidad Central de Procesamiento (CPU) | Memoria |
|---|---|---|
| Serie estándar (Gen5) | Proceso aprovisionado - Procesadores Intel® E5-2673 v4 (Broadwell) de 2,3 GHz, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2,5 GHz*, Intel® Xeon® Platinum 8370C (Ice Lake)*, AMD EPYC 7763v (Milán) - Aprovisionamiento de hasta 128 núcleos virtuales (Hyper-Threaded) Computación sin servidor - Procesadores Intel® E5-2673 v4 (Broadwell) de 2,3 GHz, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2,5 GHz*, Intel® Xeon® Platinum 8370C (Ice Lake)*, AMD EPYC 7763v (Milán) - Escalabilidad automática de hasta 80 núcleos virtuales (Hyper-Threaded) - La proporción de memoria a núcleo virtual se adapta dinámicamente al uso de memoria y CPU en función de la demanda de cargas de trabajo y puede ser tan alto como 24 GB por núcleo virtual. Por ejemplo, en un momento dado, una carga de trabajo podría usar y facturarse por memoria de 240 GB y solo 10 núcleos virtuales. |
Proceso aprovisionado - 5,1 GB por núcleo virtual - Aprovisionamiento de hasta 625 GB Cómputo sin servidor - Escalabilidad automática de hasta 24 GB por núcleo virtual - Escalado automático de hasta 240 GB máximo |
| Serie Fsv2 | - Procesadores Intel® 8168 (Skylake) - Con una velocidad de reloj turbo sostenida de todos los núcleos de 3,4 GHz y una velocidad máxima de reloj turbo de un solo núcleo de 3,7 GHz. - Aprovisionamiento de hasta 72 núcleos virtuales (Hyper-Threaded) |
- 1,9 GB por núcleo virtual - Aprovisionamiento de hasta 136 GB |
| Serie DC | - Procesadores Intel® Xeon® E-2288G - Con la extensión Intel Software Guard (Intel SGX) - Aprovisionamiento de hasta 8 núcleos virtuales (físicos) |
4,5 GB por núcleo virtual |
* En la vista de administración dinámica sys.dm_user_db_resource_governance, la generación de hardware para bases de datos que usan procesadores Intel® SP-8160 (Skylake) aparece como Gen6, la generación de hardware para bases de datos que usan Intel® 8272CL (Cascade Lake) aparece como Gen7 y la generación de hardware para bases de datos que usan Intel® Xeon® Platinum 8370C (Ice Lake) o AMD® EPYC® 7763v (Milán) aparecen como Gen8. Para una configuración de hardware y tamaño de proceso determinado, los límites de recursos son los mismos independientemente del tipo de CPU (Intel Broadwell, Skylake, Ice Lake, Cascade Lake o AMD Milan).
Para obtener más información, consulte Límites de recursos para bases de datos únicas y grupos elásticos .
Para obtener información sobre los recursos de computación y la especificación de la base de datos de Hiperescala, consulte recursos de computación de Hiperescala.
Serie estándar (Gen5)
- El hardware de la serie estándar (Gen5) proporciona recursos de proceso y memoria equilibrados y es adecuado para la mayoría de las cargas de trabajo de base de datos.
El hardware de la serie estándar (Gen5) está disponible en todas las regiones públicas de todo el mundo.
Serie Premium de Hipercale
- Las opciones de hardware de la serie Premium usan la tecnología de CPU y memoria más reciente de Intel y AMD. La serie Premium proporciona un aumento del rendimiento de proceso en relación con el hardware de la serie estándar.
- La opción de la serie Premium ofrece un rendimiento de CPU más rápido en comparación con la serie Estándar y un mayor número de núcleos virtuales máximos.
- La opción optimizada para memoria de la serie Premium ofrece el doble de memoria relativa a la serie Estándar.
- La serie estándar, la serie prémium y la serie prémium optimizada para memoria están disponibles para grupos elásticos de Hiperescala.
Para más información, consulte el anuncio del blog de la serie premium de Hiperescala.
Para ver las regiones disponibles, consulte Disponibilidad de la serie Premium de Hiperescala.
Serie Fsv2
- La serie Fsv2 es una configuración de hardware optimizada para proceso que ofrece baja latencia de CPU y alta velocidad de reloj para las cargas de trabajo más exigentes de CPU. De forma similar a las configuraciones de hardware de la serie Premium de Hiperescala, la serie Fsv2 cuenta con la tecnología más reciente de CPU y memoria de Intel y AMD, lo que permite a los clientes aprovechar el hardware más reciente al usar bases de datos y grupos elásticos en el nivel de servicio De uso general.
- En función de la carga de trabajo, la serie Fsv2 puede ofrecer más rendimiento de CPU por núcleo virtual que otros tipos de hardware. Por ejemplo, el tamaño de proceso de Fsv2 de 72 núcleos virtuales puede proporcionar más rendimiento de CPU que 80 núcleos virtuales en la serie estándar (Gen5), a un costo menor.
- Fsv2 proporciona menos memoria y
tempdbpor núcleo virtual que otro hardware, por lo que las cargas de trabajo sensibles a esos límites podrían funcionar mejor en la serie estándar (Gen5).
La serie Fsv2 solo se admite en el nivel De uso general. Para las regiones en las que está disponible la serie Fsv2, consulte la disponibilidad de la serie Fsv2.
Serie DC
- El hardware de la serie DC usa procesadores Intel con tecnología de Extensiones de Protección de Software (Intel SGX).
- La serie DC es necesaria para Always Encrypted con enclaves seguros en cargas de trabajo que requieren una mayor protección de seguridad de los enclaves de hardware, en comparación con los enclaves de seguridad basados en virtualización (VBS).
- La serie DC está diseñada para cargas de trabajo que procesan datos confidenciales y exigen funcionalidades de procesamiento de consultas confidenciales, proporcionadas por Always Encrypted con enclaves seguros.
- El hardware de la serie DC proporciona recursos de proceso y memoria equilibrados.
La serie DC solo se admite para cómputo aprovisionado (no se admite sin servidor) y no ofrece soporte para redundancia de zona. Para ver las regiones en las que la serie DC está disponible, consulte la disponibilidad de la serie DC.
Tipos de ofertas de Azure compatibles con la serie DC
Para crear bases de datos o grupos elásticos en hardware de la serie DC, la suscripción debe ser un tipo de oferta de pago, como Pago por uso o Contrato Enterprise (EA). Para obtener una lista completa de los tipos de ofertas de Azure compatibles con la serie DC, consulte ofertas actuales sin límites de gasto.
Selección de la configuración de hardware
Puede seleccionar la configuración de hardware de una base de datos o un grupo elástico en SQL Database en el momento de la creación. También puede cambiar la configuración de hardware de una base de datos o un grupo elástico existente.
Para seleccionar una configuración de hardware al crear una base de datos SQL o un grupo
Para obtener información detallada, consulte Crear una SQL Database.
En la pestaña

Seleccione la configuración de hardware deseada:

Para cambiar la configuración de hardware de una base de datos SQL o un grupo existente
En el caso de una base de datos, en la página de información general, seleccione el vínculo Plan de tarifa:

En la página Información general, seleccione Configurar.
Siga los pasos para cambiar la configuración y seleccione la configuración de hardware como se describe en los pasos anteriores.
Disponibilidad de hardware
Para obtener información sobre el hardware de generación anterior, consulte disponibilidad de hardware de generación anterior.
Serie estándar (Gen5)
El hardware de la serie estándar (Gen5) está disponible en todas las regiones públicas de todo el mundo.
Serie premium de Hiperescala
El hardware optimizado para memoria de la serie Premium y de nivel de servicio de Hiperescala está disponible para bases de datos únicas y grupos elásticos en las siguientes regiones:
- Este de Australia **
- Sudeste de Australia
- Sur de Brasil **,*
- Centro de Canadá **
- Este de Canadá
- Asia Oriental
- Norte de Europa **
- Oeste de Europa **
- Centro de Francia
- Centro-oeste de Alemania
- Centro de la India
- Sur de la India
- Este de Japón **
- Oeste de Japón
- Sudeste Asiático**
- Norte de Suiza
- Centro de Suecia **,*
- Sur de Reino Unido **
- Oeste de Reino Unido *
- Centro de EE. UU. **
- Este de EE. UU. **
- Este de EE. UU. 2 **
- Centro-norte de EE. UU.
- Centro-sur de EE. UU.
- Centro-oeste de EE. UU.
- Oeste de EE. UU. 1
- Oeste de EE. UU. 2 **
- Oeste de EE. UU. 3 **
* El hardware optimizado para memoria de la serie Premium no está disponible actualmente.
** Incluye compatibilidad con la redundancia de zona.
Serie Fsv2
La serie Fsv2 está disponible en las siguientes regiones:
- Centro de Australia
- Centro de Australia 2
- Este de Australia
- Sudeste de Australia
- Sur de Brasil
- Centro de Canadá
- Asia Oriental
- Norte de Europa
- Oeste de Europa
- Centro de Francia
- Centro de la India
- Centro de Corea del Sur
- Corea del Sur
- Norte de Sudáfrica
- Sudeste Asiático
- Sur de Reino Unido
- Oeste de Reino Unido
- Este de EE. UU.
- Oeste de EE. UU. 2
Serie DC
La serie DC está disponible en las siguientes regiones:
- Centro de Canadá
- Oeste de Europa
- Norte de Europa
- Sudeste Asiático
- Sur de Reino Unido
- Oeste de EE. UU.
- Este de EE. UU.
Si necesita la serie DC en una región no admitida actualmente, envíe una solicitud de soporte técnico. En la página Datos básicos, proporcione los valores siguientes:
- En Tipo de problema, seleccione Técnico.
- Proporcione la suscripción deseada para el hardware. Seleccione Siguiente.
- Para Tipo de servicio, seleccione SQL Database.
- En Recurso, seleccione Pregunta general.
- Para Resumen, proporcione la disponibilidad y la región de hardware deseadas.
- Para el tipo de problema, seleccione Seguridad, Privacidad y Cumplimiento.
- En Subtipo de problema, seleccione Siempre cifrado.

Hardware de generación anterior
Gen4
El hardware Gen4 ha sido retirado y no está disponible para el aprovisionamiento o el escalado vertical. Migre la base de datos a una generación de hardware compatible para una gama más amplia de escalabilidad de núcleo virtual y almacenamiento, redes aceleradas, mejor rendimiento de E/S y latencia mínima. Revise las opciones de hardware de para bases de datos únicas y las opciones de hardware de para grupos elásticos. Para más información, consulte El soporte para el hardware de la generación 4 ha finalizado en Azure SQL Database.