Supervisión del rendimiento mediante vistas de administración dinámica
Se aplica a: ![]() Azure SQL Database
Azure SQL Database ![]() Base de datos SQL en Fabric
Base de datos SQL en Fabric
Puede utilizar las vistas de administración dinámica (DMV) para supervisar el rendimiento de las cargas de trabajo y diagnosticar problemas que pueden deberse a consultas bloqueadas o de ejecución prolongada, cuellos de botella de recursos, planes de consulta deficientes y mucho más.
En este artículo se proporciona información sobre cómo detectar problemas comunes de rendimiento mediante la consulta de vistas de administración dinámica a través de T-SQL. Puede usar cualquier herramienta de consulta, como:
Permisos
En la base de datos de Azure SQL, según el tamaño de proceso, la opción de implementación y los datos en las DMV, una consulta DMV puede requerir el permiso VIEW DATABASE STATE, VIEW SERVER PERFORMANCE STATE o VIEW SERVER SECURITY STATE. Los dos últimos permisos se incluyen en el permiso VIEW SERVER STATE. Los permisos de estado del servidor de vista se conceden a través de la pertenencia a los roles de servidor correspondientes. Para determinar qué permisos son necesarios para consultar una DMV específica, consulte Vistas de administración dinámica y busque el artículo que describe la DMV.
Para conceder el permiso VIEW DATABASE STATE a un usuario de base de datos, ejecute la consulta siguiente y reemplace database_user por el nombre de la entidad de seguridad de usuario en la base de datos:
GRANT VIEW DATABASE STATE TO [database_user];
Para conceder pertenencia en el rol de servidor ##MS_ServerStateReader## a un inicio de sesión con el nombre login_name para el servidor lógico, conéctese a la base de datos master y, a continuación, ejecute la consulta siguiente como ejemplo:
ALTER SERVER ROLE [##MS_ServerStateReader##] ADD MEMBER [login_name];
El permiso concedido podría tardar unos minutos en surtir efecto. Para obtener más información, vea Limitaciones de los roles de nivel de servidor.
Supervisión del uso de recursos
Puede supervisar el uso de recursos en el nivel de base de datos mediante las siguientes vistas. Estas vistas son aplicables a bases de datos independientes y bases de datos de un grupo elástico.
Puede supervisar el uso de recursos en el nivel de grupo elástico mediante las siguientes vistas:
Puede supervisar el uso de recursos en el nivel de consulta mediante Información de rendimiento de consultas de SQL Database en el portal de Azure o el Almacén de consultas.
sys.dm_db_resource_stats
Puede usar la vista sys.dm_db_resource_stats en todas las bases de datos. En la vista sys.dm_db_resource_stats se muestran los datos de uso de recursos recientes en relación con los límites del tamaño de proceso. Los porcentajes de CPU, E/S de datos, escrituras de registros, subprocesos de trabajo y uso de memoria con respecto al límite se registran para cada intervalo de 15 segundos y se mantienen durante aproximadamente una hora.
Dado que esta vista proporciona datos granulares del uso de recursos, use sys.dm_db_resource_stats primero para cualquier análisis o solución de problemas de estado actual. Por ejemplo, esta consulta muestra el uso medio y máximo de recursos para la base de datos actual durante la última hora:
SELECT
database_name = DB_NAME(),
AVG(avg_cpu_percent) AS 'Average CPU use in percent',
MAX(avg_cpu_percent) AS 'Maximum CPU use in percent',
AVG(avg_data_io_percent) AS 'Average data IO in percent',
MAX(avg_data_io_percent) AS 'Maximum data IO in percent',
AVG(avg_log_write_percent) AS 'Average log write use in percent',
MAX(avg_log_write_percent) AS 'Maximum log write use in percent',
AVG(avg_memory_usage_percent) AS 'Average memory use in percent',
MAX(avg_memory_usage_percent) AS 'Maximum memory use in percent',
MAX(max_worker_percent) AS 'Maximum worker use in percent'
FROM sys.dm_db_resource_stats
Para otras consultas, consulte los ejemplos de sys.dm_db_resource_stats.
sys.resource_stats
La vista sys.resource_stats de la base de datos master proporciona información adicional que puede ayudar a supervisar el rendimiento de la base de datos en su nivel de servicio y tamaño de proceso específicos. Los datos se recopilan cada cinco minutos y se mantienen durante aproximadamente 14 días. Esta vista es útil para realizar análisis históricos a largo plazo de cómo la base de datos usa los recursos.
En el siguiente gráfico se muestra el uso de recursos de CPU para una base de datos Premium con el tamaño de proceso P2 durante cada hora de una semana. Este gráfico en concreto empieza el lunes, muestra cinco días laborables y, a continuación, un fin de semana cuando hay mucha menos actividad en la aplicación.
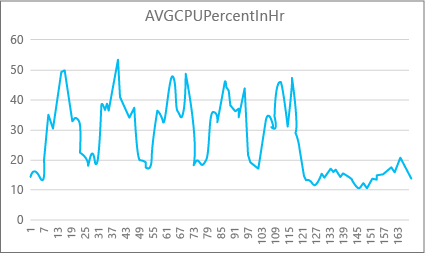
Según los datos, esta base de datos tiene actualmente una carga máxima de CPU superior al 50 % de uso de la CPU respecto al tamaño de proceso P2 (mediodía del martes). Si la CPU es el factor dominante en el perfil de recursos de la aplicación, puede decidir que P2 es el tamaño de proceso adecuado para garantizar que la carga de trabajo siempre sea la correcta. Si espera que una aplicación crezca con el tiempo, es una buena idea tener un búfer de recursos adicionales para que la aplicación no alcance el límite del nivel de rendimiento. Si aumenta el tamaño de proceso, puede ayudar a evitar errores visibles para el cliente que pueden producirse cuando una base de datos no tiene suficiente capacidad para procesar las solicitudes de manera eficaz, especialmente en entornos sensibles a la latencia.
Para otros tipos de aplicaciones, puede interpretar el mismo gráfico de manera diferente. Por ejemplo, si una aplicación intenta procesar datos de nóminas todos los días y tiene el mismo gráfico, este tipo de modelo de "trabajo por lotes" podría funcionar bien en un tamaño de proceso P1. El tamaño de proceso P1 tiene 100 DTU en comparación con las 200 DTU en el tamaño de proceso P2. El tamaño de proceso P1 proporciona la mitad de rendimiento que el tamaño de proceso P2. Por lo tanto, el 50 por ciento de uso de CPU en P2 es igual al 100 por cien de uso de CPU en P1. Si la aplicación no tiene tiempos de espera, puede dar igual que un trabajo tarde 2 o 2,5 horas en completarse, siempre que se termine hoy. Una aplicación de esta categoría probablemente pueda usar un tamaño de proceso P1. Puede aprovechar el hecho de que hay períodos de tiempo durante el día en que el uso de recursos es menor, lo que significa que las "cargas elevadas" podrían retrasarse a uno de esos momentos más tarde ese día. El tamaño de proceso P1 podría ser conveniente para ese tipo de aplicación (y ahorrar dinero), siempre y cuando los trabajos se puedan finalizar a tiempo cada día.
El motor de base de datos muestra información sobre los recursos consumidos para cada base de datos activa en la vista sys.resource_stats de la base de datos master de cada servidor lógico. Los datos de la vista se agregan en intervalos de 5 minutos. Los datos pueden tardar varios minutos en aparecer en la tabla, así que sys.resource_stats es más útil para el análisis histórico que para el análisis casi en tiempo real. Consulte la vista sys.resource_stats para ver el historial reciente de una base de datos y para validar si el tamaño de proceso elegido proporciona el rendimiento que quiere cuando lo necesita.
Nota:
Debe conectarse a la base de datos master para poder consultar sys.resource_stats en los ejemplos siguientes.
En este ejemplo se muestran los datos de sys.resource_stats:
SELECT TOP 10 *
FROM sys.resource_stats
WHERE database_name = 'userdb1'
ORDER BY start_time DESC;
En el siguiente ejemplo se muestran distintas maneras en que puede usar la vista de catálogo sys.resource_stats para obtener información sobre cómo la base de datos usa los recursos:
Para ver el uso de los recursos la semana pasada para la base de datos de usuario
userdb1, puede ejecutar esta consulta, donde debe sustituir por el nombre de su base de datos:SELECT * FROM sys.resource_stats WHERE database_name = 'userdb1' AND start_time > DATEADD(day, -7, GETDATE()) ORDER BY start_time DESC;Para evaluar si la carga de trabajo se ajusta bien al tamaño de proceso, tiene que rastrear desagrupando datos de cada aspecto de las métricas de recursos: CPU, E/S de datos, escrituras de registro, número de trabajadores y número de sesiones. Esta es una consulta revisada con
sys.resource_statspara informar de los valores medio y máximo de estas métricas de recursos en cada tamaño de proceso para el que se ha aprovisionado la base de datos:SELECT rs.database_name , rs.sku , storage_mb = MAX(rs.storage_in_megabytes) , 'Average CPU Utilization In %' = AVG(rs.avg_cpu_percent) , 'Maximum CPU Utilization In %' = MAX(rs.avg_cpu_percent) , 'Average Data IO In %' = AVG(rs.avg_data_io_percent) , 'Maximum Data IO In %' = MAX(rs.avg_data_io_percent) , 'Average Log Write Utilization In %' = AVG(rs.avg_log_write_percent) , 'Maximum Log Write Utilization In %' = MAX(rs.avg_log_write_percent) , 'Maximum Requests In %' = MAX(rs.max_worker_percent) , 'Maximum Sessions In %' = MAX(rs.max_session_percent) FROM sys.resource_stats AS rs WHERE rs.database_name = 'userdb1' AND rs.start_time > DATEADD(day, -7, GETDATE()) GROUP BY rs.database_name, rs.sku;Con la información anterior sobre los valores promedio y máximo de cada métrica de recursos, puede evaluar si la carga de trabajo se ajusta bien al tamaño de proceso que eligió. Por lo general, los valores medios de
sys.resource_statsson una buena referencia para el tamaño de destino.Para las bases de datos del modelo de compra de DTU:
Por ejemplo, podría estar usando el nivel de servicio Estándar con el tamaño de proceso S2. Los porcentajes de uso medio de CPU y de lecturas y escrituras de E/S están por debajo del 40 por ciento, el número medio de trabajadores está por debajo de 50 y el número medio de sesiones está por debajo de 200. La carga de trabajo podría ajustarse al tamaño de proceso S1. Es fácil ver si la base de datos se ajusta a los límites de trabajadores y de sesión. Para ver si una base de datos se ajusta a un tamaño de proceso inferior, divida el número de DTU del tamaño de proceso inferior por el número de DTU de su tamaño de proceso actual y multiplique el resultado por 100:
S1 DTU / S2 DTU * 100 = 20 / 50 * 100 = 40El resultado es la diferencia porcentual de rendimiento relativa entre los dos tamaños de proceso. Si el uso de recursos no supera este porcentaje, la carga de trabajo podría ajustarse al tamaño de proceso inferior. Sin embargo, debe examinar todos los intervalos de valores de uso de recursos y determinar, según el porcentaje, con qué frecuencia se ajustaría la carga de trabajo de la base de datos al tamaño de proceso inferior. La siguiente consulta proporciona el porcentaje de ajuste por dimensión de recursos según el umbral del 40 % que hemos calculado en este ejemplo.
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;En función de su objetivo de nivel de servicio de la base de datos, puede decidir si la carga de trabajo se ajusta al tamaño de proceso inferior. Si el objetivo de la carga de trabajo de la base de datos es del 99,9 % y la consulta anterior devuelve valores mayores que el 99,9 % para las tres dimensiones de recursos, es probable que la carga de trabajo se ajuste al tamaño de proceso inferior.
El porcentaje de ajuste también ofrece información detallada sobre si debería pasar al siguiente tamaño de proceso superior para cumplir su objetivo. Por ejemplo, el uso de CPU para una base de datos de ejemplo la semana pasada:
Porcentaje medio de CPU Porcentaje máximo de CPU 24,5 100,00 El promedio de CPU es aproximadamente un cuarto del límite del tamaño de proceso, que se ajustaría bien al tamaño de proceso de la base de datos.
Para las bases de datos del modelo de compra de DTU y del modelo de compra de núcleo virtual:
El valor máximo muestra que la base de datos alcanza el límite del tamaño de proceso. ¿Necesita pasar al siguiente tamaño de proceso superior? Observe cuántas veces la carga de trabajo alcanza el 100 % y compárelo con el objetivo de la carga de trabajo de la base de datos.
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Estos porcentajes son el número de muestras que la carga de trabajo encaja en el tamaño de proceso actual. Si esta consulta devuelve un valor inferior al 99,9 % para cualquiera de las tres dimensiones de recursos, la carga media de trabajo muestreada ha superado los límites. Considere la posibilidad de pasar al tamaño de proceso inmediatamente superior o de usar técnicas de optimización de aplicaciones para reducir la carga en la base de datos.
sys.dm_elastic_pool_resource_stats
Se aplica solo a: ![]() Azure SQL Database
Azure SQL Database
De forma similar a sys.dm_db_resource_stats, sys.dm_elastic_pool_resource_stats proporciona datos de uso de recursos recientes y granulares para un grupo elástico de Azure SQL Database. La vista se puede consultar en cualquier base de datos de un grupo elástico para proporcionar datos de uso de recursos para todo un grupo, en lugar de en cualquier base de datos específica. Los valores de porcentaje notificados por esta DMV se proporcionan con respecto a los límites del grupo elástico, que pueden ser superiores a los límites de una base de datos del grupo.
En este ejemplo se muestran los datos de uso de recursos resumidos para el grupo elástico actual en los últimos 15 minutos:
SELECT dso.elastic_pool_name,
AVG(eprs.avg_cpu_percent) AS avg_cpu_percent,
MAX(eprs.avg_cpu_percent) AS max_cpu_percent,
AVG(eprs.avg_data_io_percent) AS avg_data_io_percent,
MAX(eprs.avg_data_io_percent) AS max_data_io_percent,
AVG(eprs.avg_log_write_percent) AS avg_log_write_percent,
MAX(eprs.avg_log_write_percent) AS max_log_write_percent,
MAX(eprs.max_worker_percent) AS max_worker_percent,
MAX(eprs.used_storage_percent) AS max_used_storage_percent,
MAX(eprs.allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.dm_elastic_pool_resource_stats AS eprs
CROSS JOIN sys.database_service_objectives AS dso
WHERE eprs.end_time >= DATEADD(minute, -15, GETUTCDATE())
GROUP BY dso.elastic_pool_name;
Si observa que cualquier uso de recursos se aproxima al 100 % durante un período de tiempo significativo, es posible que tenga que revisar el uso de recursos para las bases de datos individuales del mismo grupo elástico a fin de determinar cuánto contribuye cada base de datos al uso de recursos a nivel de grupo.
sys.elastic_pool_resource_stats
Se aplica solo a: ![]() Azure SQL Database
Azure SQL Database
De forma similar a sys.resource_stats, sys.elastic_pool_resource_stats, en la base de datos master, proporciona datos históricos de uso de recursos para todos los grupos elásticos del servidor lógico. Puede utilizar sys.elastic_pool_resource_stats para la supervisión histórica en los últimos 14 días, incluido el análisis de tendencias de utilización.
En este ejemplo se muestran los datos de uso de recursos resumidos en los últimos siete días para todos los grupos elásticos del servidor lógico actual. Ejecute la consulta en la base de datos master.
SELECT elastic_pool_name,
AVG(avg_cpu_percent) AS avg_cpu_percent,
MAX(avg_cpu_percent) AS max_cpu_percent,
AVG(avg_data_io_percent) AS avg_data_io_percent,
MAX(avg_data_io_percent) AS max_data_io_percent,
AVG(avg_log_write_percent) AS avg_log_write_percent,
MAX(avg_log_write_percent) AS max_log_write_percent,
MAX(max_worker_percent) AS max_worker_percent,
AVG(avg_storage_percent) AS avg_used_storage_percent,
MAX(avg_storage_percent) AS max_used_storage_percent,
AVG(avg_allocated_storage_percent) AS avg_allocated_storage_percent,
MAX(avg_allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.elastic_pool_resource_stats
WHERE start_time >= DATEADD(day, -7, GETUTCDATE())
GROUP BY elastic_pool_name
ORDER BY elastic_pool_name ASC;
Solicitudes simultáneas
Para ver el número actual de solicitudes simultáneas, ejecute esta consulta en la base de datos de usuario:
SELECT COUNT(*) AS [Concurrent_Requests]
FROM sys.dm_exec_requests;
Se trata simplemente de una instantánea en un solo momento dado. Para comprender mejor la carga de trabajo y los requisitos de solicitudes simultáneas, debe recopilar muchas muestras durante un período de tiempo.
Tasa media de solicitudes
En este ejemplo se muestra cómo buscar la tasa de media de solicitudes para una base de datos o para las bases de datos de un grupo elástico durante un período de tiempo. En este ejemplo, el período de tiempo se establece en 30 segundos. Puede ajustarlo modificando la instrucción WAITFOR DELAY. Ejecute esta consulta en la base de datos de usuario. Si la base de datos está en un grupo elástico y tiene permisos suficientes, los resultados incluirán otras bases de datos del grupo elástico.
DECLARE @DbRequestSnapshot TABLE (
database_name sysname PRIMARY KEY,
total_request_count bigint NOT NULL,
snapshot_time datetime2 NOT NULL DEFAULT (SYSDATETIME())
);
INSERT INTO @DbRequestSnapshot
(
database_name,
total_request_count
)
SELECT rg.database_name,
wg.total_request_count
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id);
WAITFOR DELAY '00:00:30';
SELECT rg.database_name,
(wg.total_request_count - drs.total_request_count) / DATEDIFF(second, drs.snapshot_time, SYSDATETIME()) AS requests_per_second
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
INNER JOIN @DbRequestSnapshot AS drs
ON rg.database_name = drs.database_name;
Sesiones actuales
Para ver el número de sesiones activas actuales, ejecute esta consulta en la base de datos:
SELECT COUNT(*) AS [Sessions]
FROM sys.dm_exec_sessions
WHERE is_user_process = 1;
Esta consulta devuelve un recuento de un momento dado. Si recopila varias muestras a lo largo de un tiempo, entenderá mejor el uso de la sesión.
Historial reciente de solicitudes, sesiones y trabajos
En este ejemplo se devuelve el uso histórico reciente de solicitudes, sesiones y subprocesos de trabajo para una base de datos o para las bases de datos de un grupo elástico. Cada fila representa una instantánea del uso de recursos en un momento dado para una base de datos. La columna requests_per_second es la tasa media de solicitudesmedia durante el intervalo de tiempo que termina a las snapshot_time. Si la base de datos está en un grupo elástico y tiene permisos suficientes, los resultados incluirán otras bases de datos del grupo elástico.
SELECT rg.database_name,
wg.snapshot_time,
wg.active_request_count,
wg.active_worker_count,
wg.active_session_count,
CAST(wg.delta_request_count AS decimal) / duration_ms * 1000 AS requests_per_second
FROM sys.dm_resource_governor_workload_groups_history_ex AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
ORDER BY snapshot_time DESC;
Calcular los tamaños de base de datos y objetos
La siguiente consulta devuelve el tamaño de los datos de la base de datos en megabytes:
-- Calculates the size of the database.
SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8192.) / 1024 / 1024 AS size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
La consulta siguiente devuelve el tamaño de objetos individuales (en megabytes) de la base de datos:
-- Calculates the size of individual database objects.
SELECT o.name, SUM(ps.reserved_page_count) * 8.0 / 1024 AS size_mb
FROM sys.dm_db_partition_stats AS ps
INNER JOIN sys.objects AS o
ON ps.object_id = o.object_id
GROUP BY o.name
ORDER BY size_mb DESC;
Identificar problemas de rendimiento de CPU
Esta sección le ayuda a identificar qué consultas individuales son los principales consumidores de CPU.
Si el consumo de CPU es superior al 80 % durante largos períodos de tiempo, tenga en cuenta los siguientes pasos de solución de problemas, independientemente de que el problema de CPU se esté produciendo ahora o se haya producido en el pasado. También puede seguir los pasos descritos en esta sección para identificar proactivamente las consultas que consumen más CPU y optimizarlas. En algunos casos, reducir el consumo de CPU podría permitirle reducir verticalmente las bases de datos y los grupos elásticos, y ahorrar costes.
Los pasos de solución de problemas son los mismos para las bases de datos independientes y las bases de datos de un grupo elástico. Ejecute todas las consultas en la base de datos de usuario.
El problema de CPU se produce en este momento
Si el problema se produce ahora mismo, hay dos escenarios posibles:
Muchas consultas individuales que consumen una gran cantidad de CPU de forma acumulativa
Utilice la siguiente consulta para identificar cuáles son las principales consultas por valor hash de la consulta:
PRINT '-- top 10 Active CPU Consuming Queries (aggregated)--';
SELECT TOP 10 GETDATE() runtime, *
FROM (SELECT query_stats.query_hash, SUM(query_stats.cpu_time) 'Total_Request_Cpu_Time_Ms', SUM(logical_reads) 'Total_Request_Logical_Reads', MIN(start_time) 'Earliest_Request_start_Time', COUNT(*) 'Number_Of_Requests', SUBSTRING(REPLACE(REPLACE(MIN(query_stats.statement_text), CHAR(10), ' '), CHAR(13), ' '), 1, 256) AS "Statement_Text"
FROM (SELECT req.*, SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ) AS query_stats
GROUP BY query_hash) AS t
ORDER BY Total_Request_Cpu_Time_Ms DESC;
Consultas de larga ejecución que consumen CPU siguen en ejecución
Utilice la siguiente consulta para identificar estas consultas:
PRINT '--top 10 Active CPU Consuming Queries by sessions--';
SELECT TOP 10 req.session_id, req.start_time, cpu_time 'cpu_time_ms', OBJECT_NAME(ST.objectid, ST.dbid) 'ObjectName', SUBSTRING(REPLACE(REPLACE(SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1), CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST
ORDER BY cpu_time DESC;
GO
El problema de CPU se produjo en el pasado
Si el problema se produjo en el pasado y quiere realizar el análisis de la causa principal, utilice Almacén de consultas. Los usuarios con acceso a la base de datos pueden utilizar T-SQL para consultar los datos del Almacén de consultas. De forma predeterminada, Almacén de consultas captura las estadísticas de consulta de funciones agregadas para intervalos de una hora.
Utilice la siguiente consulta para observar la actividad de las consultas que consumen mucha CPU. Esta consulta devuelve las 15 consultas que más consumen CPU. Recuerde cambiar
rsi.start_time >= DATEADD(hour, -2, GETUTCDATE()para examinar un período de tiempo distinto de las últimas dos horas:-- Top 15 CPU consuming queries by query hash -- Note that a query hash can have many query ids if not parameterized or not parameterized properly WITH AggregatedCPU AS ( SELECT q.query_hash ,SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms ,SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms ,MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms ,MAX(max_logical_io_reads) max_logical_reads ,COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans ,COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids ,SUM(CASE WHEN rs.execution_type_desc = 'Aborted' THEN count_executions ELSE 0 END) AS Aborted_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Regular' THEN count_executions ELSE 0 END) AS Regular_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Exception' THEN count_executions ELSE 0 END) AS Exception_Execution_Count ,SUM(count_executions) AS total_executions ,MIN(qt.query_sql_text) AS sampled_query_text FROM sys.query_store_query_text AS qt INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id WHERE rs.execution_type_desc IN ('Regular','Aborted','Exception') AND rsi.start_time >= DATEADD(HOUR, - 2, GETUTCDATE()) GROUP BY q.query_hash ) ,OrderedCPU AS ( SELECT query_hash ,total_cpu_ms ,avg_cpu_ms ,max_cpu_ms ,max_logical_reads ,number_of_distinct_plans ,number_of_distinct_query_ids ,total_executions ,Aborted_Execution_Count ,Regular_Execution_Count ,Exception_Execution_Count ,sampled_query_text ,ROW_NUMBER() OVER ( ORDER BY total_cpu_ms DESC ,query_hash ASC ) AS query_hash_row_number FROM AggregatedCPU ) SELECT OD.query_hash ,OD.total_cpu_ms ,OD.avg_cpu_ms ,OD.max_cpu_ms ,OD.max_logical_reads ,OD.number_of_distinct_plans ,OD.number_of_distinct_query_ids ,OD.total_executions ,OD.Aborted_Execution_Count ,OD.Regular_Execution_Count ,OD.Exception_Execution_Count ,OD.sampled_query_text ,OD.query_hash_row_number FROM OrderedCPU AS OD WHERE OD.query_hash_row_number <= 15 --get top 15 rows by total_cpu_ms ORDER BY total_cpu_ms DESC;Una vez identificadas las consultas problemáticas, es hora de optimizar las consultas para reducir el uso de CPU. Como alternativa, puede optar por aumentar el tamaño de proceso de la base de datos o el grupo elástico para solucionar el problema.
Obtenga más información sobre cómo controlar los problemas de rendimiento de CPU en Azure SQL Database en Diagnóstico y solución de problemas de CPU alta en Azure SQL Database.
Identificar problemas de rendimiento de E/S
Cuando se identifican problemas de rendimiento de entrada/salida (E/S), los principales tipos de espera son:
PAGEIOLATCH_*En el caso de problemas de E/S de archivos de datos (incluidos
PAGEIOLATCH_SH,PAGEIOLATCH_EXyPAGEIOLATCH_UP). Si en el nombre de tipo de espera se incluye IO, indica un problema de E/S. Cuando no hay ninguna E/S en el nombre de tiempo de espera de bloqueo temporal de la página, se infiere que hay otro tipo de problema no relacionado con el rendimiento del almacenamiento (por ejemplo, contención detempdb).WRITE_LOGEn el caso de problemas de E/S del registro de transacciones.
Si el problema de E/S se produce en este momento
Utilice la vista sys.dm_exec_requests o sys.dm_os_waiting_tasks para ver wait_type y wait_time.
Identificar el uso de E/S de registro y datos
Utilice la siguiente consulta para identificar el uso de E/S de registro y datos.
SELECT
database_name = DB_NAME()
, UTC_time = end_time
, 'Data IO In % of Limit' = rs.avg_data_io_percent
, 'Log Write Utilization In % of Limit' = rs.avg_log_write_percent
FROM sys.dm_db_resource_stats AS rs --past hour only
ORDER BY rs.end_time DESC;
Para obtener más ejemplos con sys.dm_db_resource_stats, consulte la sección Supervisión del uso de recursos más adelante en este artículo.
Si se ha alcanzado el límite de E/S, tiene dos opciones:
- Actualizar el tamaño de proceso o nivel de servicio
- Identifique y optimice las consultas que consumen la mayoría de E/S.
Ver E/S relacionadas con el búfer mediante el Almacén de consultas
Para identificar las principales consultas por esperas relacionadas con la E/S, puede usar la consulta siguiente en el Almacén de consultas para ver las dos últimas horas de actividad con seguimiento:
-- Top queries that waited on buffer
-- Note these are finished queries
WITH Aggregated AS (SELECT q.query_hash, SUM(total_query_wait_time_ms) total_wait_time_ms, SUM(total_query_wait_time_ms / avg_query_wait_time_ms) AS total_executions, MIN(qt.query_sql_text) AS sampled_query_text, MIN(wait_category_desc) AS wait_category_desc
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id=q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id=p.query_id
INNER JOIN sys.query_store_wait_stats AS waits ON waits.plan_id=p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id=waits.runtime_stats_interval_id
WHERE wait_category_desc='Buffer IO' AND rsi.start_time>=DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash), Ordered AS (SELECT query_hash, total_executions, total_wait_time_ms, sampled_query_text, wait_category_desc, ROW_NUMBER() OVER (ORDER BY total_wait_time_ms DESC, query_hash ASC) AS query_hash_row_number
FROM Aggregated)
SELECT OD.query_hash, OD.total_executions, OD.total_wait_time_ms, OD.sampled_query_text, OD.wait_category_desc, OD.query_hash_row_number
FROM Ordered AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_wait_time_ms
ORDER BY total_wait_time_ms DESC;
GO
También puede usar la vista sys.query_store_runtime_stats, centrándose en las consultas con valores grandes en las columnas avg_physical_io_reads y avg_num_physical_io_reads.
Ver el total de E/S de registros para esperas WRITELOG
Si el tipo de espera es WRITELOG, utilice la consulta siguiente para ver el total de E/S de registro por instrucción:
-- Top transaction log consumers
-- Adjust the time window by changing
-- rsi.start_time >= DATEADD(hour, -2, GETUTCDATE())
WITH AggregatedLogUsed
AS (SELECT q.query_hash,
SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms,
SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms,
SUM(count_executions * avg_log_bytes_used) AS total_log_bytes_used,
MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms,
MAX(max_logical_io_reads) max_logical_reads,
COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans,
COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids,
SUM( CASE
WHEN rs.execution_type_desc = 'Aborted' THEN
count_executions
ELSE 0
END
) AS Aborted_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Regular' THEN
count_executions
ELSE 0
END
) AS Regular_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Exception' THEN
count_executions
ELSE 0
END
) AS Exception_Execution_Count,
SUM(count_executions) AS total_executions,
MIN(qt.query_sql_text) AS sampled_query_text
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE rs.execution_type_desc IN ( 'Regular', 'Aborted', 'Exception' )
AND rsi.start_time >= DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash),
OrderedLogUsed
AS (SELECT query_hash,
total_log_bytes_used,
number_of_distinct_plans,
number_of_distinct_query_ids,
total_executions,
Aborted_Execution_Count,
Regular_Execution_Count,
Exception_Execution_Count,
sampled_query_text,
ROW_NUMBER() OVER (ORDER BY total_log_bytes_used DESC, query_hash ASC) AS query_hash_row_number
FROM AggregatedLogUsed)
SELECT OD.total_log_bytes_used,
OD.number_of_distinct_plans,
OD.number_of_distinct_query_ids,
OD.total_executions,
OD.Aborted_Execution_Count,
OD.Regular_Execution_Count,
OD.Exception_Execution_Count,
OD.sampled_query_text,
OD.query_hash_row_number
FROM OrderedLogUsed AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_log_bytes_used
ORDER BY total_log_bytes_used DESC;
GO
Identificación de problemas de rendimiento de tempdb
Los tipos de espera habituales asociados a los problemas de tempdb son PAGELATCH_* (no PAGEIOLATCH_*). Pero las esperas PAGELATCH_* no siempre significan que tenga contención tempdb. Esta espera también puede significar que tiene contención de páginas de datos de objeto de usuario debido a solicitudes simultáneas que se destinan a la misma página de datos. Para confirmar una vez más la contención tempdb, utilice sys.dm_exec_requests para confirmar que el valor wait_resource comienza con 2:x:y, donde 2 indica que tempdb es el id. de la base de datos, x es el id. del archivo y y es el id. de la página.
En el caso de la contención de tempdb, un método común consiste en reducir o reescribir el código de la aplicación que se basa en tempdb. Las áreas de uso de tempdb comunes incluyen:
- Tablas temporales
- Variables de tabla
- Parámetros con valores de tabla
- Consultas que tienen planes de consultas que usan ordenaciones, combinaciones hash y colas de impresión
Para obtener más información, consulte tempdb en Azure SQL.
Todas las bases de datos de un grupo elástico comparten la misma base de datos tempdb. Un uso elevado del espacio tempdb por parte de una base de datos podría afectar a otras bases de datos del mismo grupo elástico.
Principales consultas que utilizan tablas temporales y variables de tabla
Utilice la siguiente consulta para identificar las principales consultas que usan tablas temporales y variables de tabla:
SELECT plan_handle, execution_count, query_plan
INTO #tmpPlan
FROM sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_query_plan(plan_handle);
GO
WITH XMLNAMESPACES('http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS sp)
SELECT plan_handle, stmt.stmt_details.value('@Database', 'varchar(max)') AS 'Database'
, stmt.stmt_details.value('@Schema', 'varchar(max)') AS 'Schema'
, stmt.stmt_details.value('@Table', 'varchar(max)') AS 'table'
INTO #tmp2
FROM
(SELECT CAST(query_plan AS XML) sqlplan, plan_handle FROM #tmpPlan) AS p
CROSS APPLY sqlplan.nodes('//sp:Object') AS stmt(stmt_details);
GO
SELECT t.plan_handle, [Database], [Schema], [table], execution_count
FROM
(SELECT DISTINCT plan_handle, [Database], [Schema], [table]
FROM #tmp2
WHERE [table] LIKE '%@%' OR [table] LIKE '%#%') AS t
INNER JOIN #tmpPlan AS t2 ON t.plan_handle=t2.plan_handle;
GO
DROP TABLE #tmpPlan
DROP TABLE #tmp2
Identificar transacciones de larga ejecución
Utilice la siguiente consulta para identificar transacciones de larga ejecución. Las transacciones de larga duración impiden la limpieza del almacén de versiones persistente (PVS). Para obtener más información, consulte Solución de problemas de recuperación acelerada de bases de datos.
SELECT DB_NAME(dtr.database_id) 'database_name',
sess.session_id,
atr.name AS 'tran_name',
atr.transaction_id,
transaction_type,
transaction_begin_time,
database_transaction_begin_time,
transaction_state,
is_user_transaction,
sess.open_transaction_count,
TRIM(REPLACE(
REPLACE(
SUBSTRING(
SUBSTRING(
txt.text,
(req.statement_start_offset / 2) + 1,
((CASE req.statement_end_offset
WHEN -1 THEN
DATALENGTH(txt.text)
ELSE
req.statement_end_offset
END - req.statement_start_offset
) / 2
) + 1
),
1,
1000
),
CHAR(10),
' '
),
CHAR(13),
' '
)
) Running_stmt_text,
recenttxt.text 'MostRecentSQLText'
FROM sys.dm_tran_active_transactions AS atr
INNER JOIN sys.dm_tran_database_transactions AS dtr
ON dtr.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_tran_session_transactions AS sess
ON sess.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_exec_requests AS req
ON req.session_id = sess.session_id
AND req.transaction_id = sess.transaction_id
LEFT JOIN sys.dm_exec_connections AS conn
ON sess.session_id = conn.session_id
OUTER APPLY sys.dm_exec_sql_text(req.sql_handle) AS txt
OUTER APPLY sys.dm_exec_sql_text(conn.most_recent_sql_handle) AS recenttxt
WHERE atr.transaction_type != 2
AND sess.session_id != @@spid
ORDER BY start_time ASC;
Identificar problemas de rendimiento de espera de concesión de memoria
Si el tipo de espera principal es RESOURCE_SEMAPHORE, es posible que tenga un problema de espera de concesión de memoria en el que las consultas no puedan empezar a ejecutarse hasta que obtengan una concesión de memoria suficientemente grande.
Determine si una de las principales esperas es la de RESOURCE_SEMAPHORE
Utilice la consulta siguiente para determinar si una espera RESOURCE_SEMAPHORE es una espera principal. También sería indicativo un rango de tiempo de espera creciente de RESOURCE_SEMAPHORE en el historial reciente. Para obtener más información sobre cómo solucionar problemas de espera de concesión de memoria, consulte Solución de problemas de rendimiento lento o memoria baja causados por concesiones de memoria en SQL Server.
SELECT wait_type,
SUM(wait_time) AS total_wait_time_ms
FROM sys.dm_exec_requests AS req
INNER JOIN sys.dm_exec_sessions AS sess
ON req.session_id = sess.session_id
WHERE is_user_process = 1
GROUP BY wait_type
ORDER BY SUM(wait_time) DESC;
Identificar instrucciones con un alto consumo de memoria
Si se producen errores de memoria en Azure SQL Database, revise sys.dm_os_out_of_memory_events. Para obtener más información, consulte Solución de problemas de errores de memoria con Azure SQL Database.
En primer lugar, modifique el script siguiente para actualizar los valores pertinentes de start_time y end_time. A continuación, ejecute la consulta siguiente para identificar las instrucciones con un alto consumo de memoria:
SELECT IDENTITY(INT, 1, 1) rowId,
CAST(query_plan AS XML) query_plan,
p.query_id
INTO #tmp
FROM sys.query_store_plan AS p
INNER JOIN sys.query_store_runtime_stats AS r
ON p.plan_id = r.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS i
ON r.runtime_stats_interval_id = i.runtime_stats_interval_id
WHERE start_time > '2018-10-11 14:00:00.0000000'
AND end_time < '2018-10-17 20:00:00.0000000';
WITH cte
AS (SELECT query_id,
query_plan,
m.c.value('@SerialDesiredMemory', 'INT') AS SerialDesiredMemory
FROM #tmp AS t
CROSS APPLY t.query_plan.nodes('//*:MemoryGrantInfo[@SerialDesiredMemory[. > 0]]') AS m(c) )
SELECT TOP 50
cte.query_id,
t.query_sql_text,
cte.query_plan,
CAST(SerialDesiredMemory / 1024. AS DECIMAL(10, 2)) SerialDesiredMemory_MB
FROM cte
INNER JOIN sys.query_store_query AS q
ON cte.query_id = q.query_id
INNER JOIN sys.query_store_query_text AS t
ON q.query_text_id = t.query_text_id
ORDER BY SerialDesiredMemory DESC;
Identificar las 10 concesiones principales de memoria activa
Utilice la siguiente consulta para identificar las 10 concesiones principales de memoria activa:
SELECT TOP 10
CONVERT(VARCHAR(30), GETDATE(), 121) AS runtime,
r.session_id,
r.blocking_session_id,
r.cpu_time,
r.total_elapsed_time,
r.reads,
r.writes,
r.logical_reads,
r.row_count,
wait_time,
wait_type,
r.command,
OBJECT_NAME(txt.objectid, txt.dbid) 'Object_Name',
TRIM(REPLACE(REPLACE(SUBSTRING(SUBSTRING(TEXT, (r.statement_start_offset / 2) + 1,
( (
CASE r.statement_end_offset
WHEN - 1
THEN DATALENGTH(TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset
) / 2
) + 1), 1, 1000), CHAR(10), ' '), CHAR(13), ' ')) AS stmt_text,
mg.dop, --Degree of parallelism
mg.request_time, --Date and time when this query requested the memory grant.
mg.grant_time, --NULL means memory has not been granted
mg.requested_memory_kb / 1024.0 requested_memory_mb, --Total requested amount of memory in megabytes
mg.granted_memory_kb / 1024.0 AS granted_memory_mb, --Total amount of memory actually granted in megabytes. NULL if not granted
mg.required_memory_kb / 1024.0 AS required_memory_mb, --Minimum memory required to run this query in megabytes.
max_used_memory_kb / 1024.0 AS max_used_memory_mb,
mg.query_cost, --Estimated query cost.
mg.timeout_sec, --Time-out in seconds before this query gives up the memory grant request.
mg.resource_semaphore_id, --Non-unique ID of the resource semaphore on which this query is waiting.
mg.wait_time_ms, --Wait time in milliseconds. NULL if the memory is already granted.
CASE mg.is_next_candidate --Is this process the next candidate for a memory grant
WHEN 1 THEN
'Yes'
WHEN 0 THEN
'No'
ELSE
'Memory has been granted'
END AS 'Next Candidate for Memory Grant',
qp.query_plan
FROM sys.dm_exec_requests AS r
INNER JOIN sys.dm_exec_query_memory_grants AS mg
ON r.session_id = mg.session_id
AND r.request_id = mg.request_id
CROSS APPLY sys.dm_exec_sql_text(mg.sql_handle) AS txt
CROSS APPLY sys.dm_exec_query_plan(r.plan_handle) AS qp
ORDER BY mg.granted_memory_kb DESC;
Supervisión de conexiones
Puede utilizar la vista sys.dm_exec_connections para recuperar información sobre las conexiones establecidas a una base de datos específica y los detalles de cada conexión. Si una base de datos está en un grupo elástico y tiene permisos suficientes, la vista devolverá el conjunto de conexiones de todas las bases de datos del grupo elástico. Además, la vista sys.dm_exec_sessions resulta útil para recuperar información sobre todas las conexiones de usuario activas y las tareas internas.
Visualización de sesiones actuales
La consulta siguiente recupera información de la conexión y la sesión actuales. Para ver todas las conexiones y sesiones, elimine la cláusula WHERE.
Solo verá todas las sesiones en ejecución en la base de datos si tiene el permiso VIEW DATABASE STATE en la base de datos al ejecutar las vistas sys.dm_exec_requests y sys.dm_exec_sessions. De lo contrario, solo verá la sesión actual.
SELECT
c.session_id, c.net_transport, c.encrypt_option,
c.auth_scheme, s.host_name, s.program_name,
s.client_interface_name, s.login_name, s.nt_domain,
s.nt_user_name, s.original_login_name, c.connect_time,
s.login_time
FROM sys.dm_exec_connections AS c
INNER JOIN sys.dm_exec_sessions AS s
ON c.session_id = s.session_id
WHERE c.session_id = @@SPID; --Remove to view all sessions, if permissions allow
Supervisión del rendimiento de las consultas
Las consultas de ejecución lenta o prolongada pueden consumir una cantidad significativa de recursos del sistema. En esta sección se muestra cómo usar vistas de administración dinámica para detectar algunos problemas comunes de rendimiento de las consultas con la vista de administración dinámica sys.dm_exec_query_stats. La vista contiene una fila por cada instrucción de consulta dentro del plan en caché, y la duración de las filas está ligada al propio plan. Cuando se quita un plan de la caché, se eliminan las filas correspondientes de esta vista. Si una consulta no tiene un plan almacenado en caché, por ejemplo, porque se está utilizando OPTION (RECOMPILE), dicha consulta no estará presente en los resultados de esta vista.
Búsqueda de consultas principales por tiempo de CPU
El ejemplo siguiente devuelve información acerca de las 15 consultas principales clasificadas en función del tiempo promedio de CPU por ejecución. Este ejemplo agrega las consultas conforme a sus hash de consulta, por lo que las consultas lógicamente equivalentes se agrupan por sus consumos de recursos acumulativos.
SELECT TOP 15 query_stats.query_hash AS Query_Hash,
SUM(query_stats.total_worker_time) / SUM(query_stats.execution_count) AS Avg_CPU_Time,
MIN(query_stats.statement_text) AS Statement_Text
FROM
(SELECT QS.*,
SUBSTRING(ST.text, (QS.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(ST.text)
ELSE QS.statement_end_offset END
- QS.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) AS ST
) AS query_stats
GROUP BY query_stats.query_hash
ORDER BY Avg_CPU_Time DESC;
Supervisión de planes de consulta para el tiempo de CPU acumulado
Un plan de consulta ineficaz también puede aumentar el consumo de CPU. En el ejemplo siguiente se determina qué consulta emplea más tiempo de CPU acumulado en el historial reciente.
SELECT
highest_cpu_queries.plan_handle,
highest_cpu_queries.total_worker_time,
q.dbid,
q.objectid,
q.number,
q.encrypted,
q.[text]
FROM
(SELECT TOP 15
qs.plan_handle,
qs.total_worker_time
FROM
sys.dm_exec_query_stats AS qs
ORDER BY qs.total_worker_time desc
) AS highest_cpu_queries
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
ORDER BY highest_cpu_queries.total_worker_time DESC;
Supervisión de consultas bloqueadas
Las consultas lentas o de larga ejecución pueden contribuir al consumo excesivo de recursos y ser la consecuencia de consultas bloqueadas. La causa del bloqueo puede ser un diseño deficiente de las aplicaciones, los planes de consulta incorrectos, la falta de índices útiles, etc.
Puede usar la vista sys.dm_tran_locks para obtener información sobre la actividad de bloqueo actual en la base de datos. Para obtener códigos de ejemplo, consulte sys.dm_tran_locks. Para obtener más información sobre la solución de problemas de bloqueo, consulte Descripción y resolución de problemas de bloqueo en Azure SQL.
Supervisión de interbloqueos
En algunos casos, dos o más consultas pueden bloquearse mutuamente, lo que da lugar a un interbloqueo.
La creación de un seguimiento de eventos extendidos le permitirá capturar eventos de interbloqueo y, a continuación, buscar consultas relacionadas con estos y sus planes de ejecución en el Almacén de consultas. Obtenga más información en Análisis y prevención de interbloqueos en Azure SQL Database, incluido un laboratorio para Provocar un interbloqueo en AdventureWorksLT. Obtenga más información sobre los tipos de recursos que pueden causar interbloqueos.
Contenido relacionado
- Introducción a Azure SQL Database e Instancia administrada de Azure SQL
- Diagnóstico y solución de problemas de uso elevado de la CPU en Azure SQL Database
- Ajustar el rendimiento de aplicaciones de base de datos y bases de datos en Azure SQL Database
- Descripción y resolución de problemas de bloqueo en Azure SQL Database
- Análisis y prevención de interbloqueos en Azure SQL Database
- Supervisión de cargas de trabajo de Azure SQL con el monitor de base de datos (versión preliminar)