Tutorial: Implementación de una base de datos distribuida geográficamente (Azure SQL Database)
Se aplica a:![]() Azure SQL Database
Azure SQL Database
Configure una base de datos en SQL Database y una aplicación cliente para realizar conmutación por error a una región remota y probar un plan de conmutación por error. Aprenderá a:
- Cree un grupo de conmutación por error.
- Ejecutar una aplicación de Java para consultar una base de datos en SQL Database
- Conmutación por error de prueba
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Requisitos previos
Nota:
En este artículo se usa el módulo Az de PowerShell, que es el módulo de PowerShell que se recomienda para interactuar con Azure. Para empezar a trabajar con el módulo Az de PowerShell, consulte Instalación de Azure PowerShell. Para más información sobre cómo migrar al módulo Az de PowerShell, consulte Migración de Azure PowerShell de AzureRM a Az.
Importante
El módulo Az reemplaza AzureRM. Todo el desarrollo futuro es para el módulo Az.Sql.
Para completar el tutorial, asegúrese de que instaló los elementos siguientes:
Una base de datos única en Azure SQL Database. Para crear uno, use:
Nota:
El tutorial usa la base de datos de ejemplo de AdventureWorksLT.
Importante
Asegúrese de configurar las reglas de firewall para usar la dirección IP pública del equipo en el que está realizando los pasos de este tutorial. Las reglas de firewall a nivel de base de datos se replicarán automáticamente al servidor secundario.
Para obtener más información, vea Create a database-level firewall rule (Creación de una regla de firewall a nivel de base de datos) o, para determinar la dirección IP que usa la regla de firewall a nivel de base de datos para el equipo, vea Create a server-level firewall (Crear un firewall de nivel de servidor).
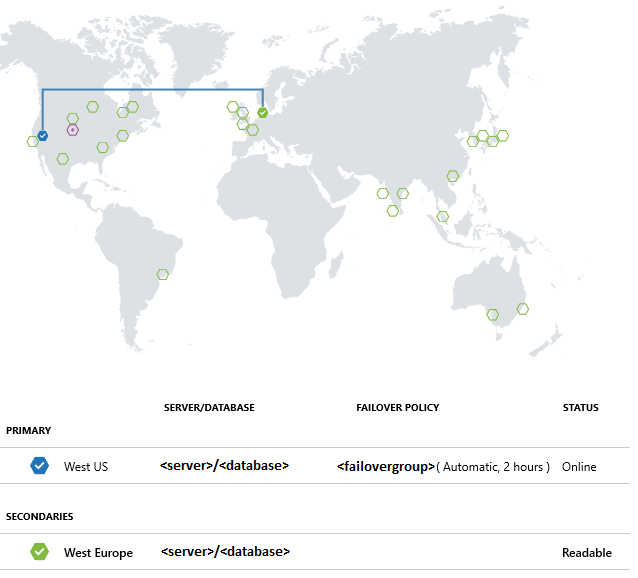
Creación de un grupo de conmutación por error
Con Azure PowerShell, cree grupos de conmutación por error entre un servidor existente y uno nuevo en otra región. A continuación, agregue la base de datos de ejemplo al grupo de conmutación por error.
Importante
Este ejemplo requiere Azure PowerShell Az 1.0, o cualquier versión posterior. Ejecute Get-Module -ListAvailable Az para ver qué versiones están instaladas.
Si necesita instalarlo, consulte Instalación del módulo de Azure PowerShell.
Ejecute Connect AzAccount para iniciar sesión en Azure.
Para crear un grupo de conmutación por error, ejecute el siguiente script:
$admin = "<adminName>"
$password = "<password>"
$resourceGroup = "<resourceGroupName>"
$location = "<resourceGroupLocation>"
$server = "<serverName>"
$database = "<databaseName>"
$drLocation = "<disasterRecoveryLocation>"
$drServer = "<disasterRecoveryServerName>"
$failoverGroup = "<globallyUniqueFailoverGroupName>"
# create a backup server in the failover region
New-AzSqlServer -ResourceGroupName $resourceGroup -ServerName $drServer `
-Location $drLocation -SqlAdministratorCredentials $(New-Object -TypeName System.Management.Automation.PSCredential `
-ArgumentList $admin, $(ConvertTo-SecureString -String $password -AsPlainText -Force))
# create a failover group between the servers
New-AzSqlDatabaseFailoverGroup –ResourceGroupName $resourceGroup -ServerName $server `
-PartnerServerName $drServer –FailoverGroupName $failoverGroup –FailoverPolicy Automatic -GracePeriodWithDataLossHours 2
# add the database to the failover group
Get-AzSqlDatabase -ResourceGroupName $resourceGroup -ServerName $server -DatabaseName $database | `
Add-AzSqlDatabaseToFailoverGroup -ResourceGroupName $resourceGroup -ServerName $server -FailoverGroupName $failoverGroup
Las opciones de configuración de replicación geográfica también pueden cambiarse en Azure Portal mediante la selección de la base de datos y, después, Configuración>Replicación geográfica.
Ejecución del proyecto de ejemplo
En la consola, cree un proyecto de Maven con el siguiente comando:
mvn archetype:generate "-DgroupId=com.sqldbsamples" "-DartifactId=SqlDbSample" "-DarchetypeArtifactId=maven-archetype-quickstart" "-Dversion=1.0.0"Escriba Y y presione ENTRAR.
Cambie los directorios al nuevo proyecto.
cd SqlDbSampleCon el editor que prefiera, abra el archivo pom.xml de la carpeta del proyecto.
Agregue la dependencia Microsoft JDBC Driver para SQL Server mediante la adición de la sección
dependencysiguiente. La dependencia se debe pegar en la seccióndependenciesde mayor tamaño.<dependency> <groupId>com.microsoft.sqlserver</groupId> <artifactId>mssql-jdbc</artifactId> <version>6.1.0.jre8</version> </dependency>Especifique la versión de Java mediante la adición de la sección
propertiesdespués de la seccióndependencies:<properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> </properties>Admita archivos de manifiesto agregando la sección
builddespués de la secciónproperties:<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> <version>3.0.0</version> <configuration> <archive> <manifest> <mainClass>com.sqldbsamples.App</mainClass> </manifest> </archive> </configuration> </plugin> </plugins> </build>Guarde y cierre el archivo pom.xml.
Abra el archivo App.java ubicado en ..\SqlDbSample\src\main\java\com\sqldbsamples y sustituya el contenido por el código siguiente:
package com.sqldbsamples; import java.sql.Connection; import java.sql.Statement; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.Timestamp; import java.sql.DriverManager; import java.util.Date; import java.util.concurrent.TimeUnit; public class App { private static final String FAILOVER_GROUP_NAME = "<your failover group name>"; // add failover group name private static final String DB_NAME = "<your database>"; // add database name private static final String USER = "<your admin>"; // add database user private static final String PASSWORD = "<password>"; // add database password private static final String READ_WRITE_URL = String.format("jdbc:" + "sqlserver://%s.database.windows.net:1433;database=%s;user=%s;password=%s;encrypt=true;" + "hostNameInCertificate=*.database.windows.net;loginTimeout=30;", FAILOVER_GROUP_NAME, DB_NAME, USER, PASSWORD); private static final String READ_ONLY_URL = String.format("jdbc:" + "sqlserver://%s.secondary.database.windows.net:1433;database=%s;user=%s;password=%s;encrypt=true;" + "hostNameInCertificate=*.database.windows.net;loginTimeout=30;", FAILOVER_GROUP_NAME, DB_NAME, USER, PASSWORD); public static void main(String[] args) { System.out.println("#######################################"); System.out.println("## GEO DISTRIBUTED DATABASE TUTORIAL ##"); System.out.println("#######################################"); System.out.println(""); int highWaterMark = getHighWaterMarkId(); try { for(int i = 1; i < 1000; i++) { // loop will run for about 1 hour System.out.print(i + ": insert on primary " + (insertData((highWaterMark + i)) ? "successful" : "failed")); TimeUnit.SECONDS.sleep(1); System.out.print(", read from secondary " + (selectData((highWaterMark + i)) ? "successful" : "failed") + "\n"); TimeUnit.SECONDS.sleep(3); } } catch(Exception e) { e.printStackTrace(); } } private static boolean insertData(int id) { // Insert data into the product table with a unique product name so we can find the product again String sql = "INSERT INTO SalesLT.Product " + "(Name, ProductNumber, Color, StandardCost, ListPrice, SellStartDate) VALUES (?,?,?,?,?,?);"; try (Connection connection = DriverManager.getConnection(READ_WRITE_URL); PreparedStatement pstmt = connection.prepareStatement(sql)) { pstmt.setString(1, "BrandNewProduct" + id); pstmt.setInt(2, 200989 + id + 10000); pstmt.setString(3, "Blue"); pstmt.setDouble(4, 75.00); pstmt.setDouble(5, 89.99); pstmt.setTimestamp(6, new Timestamp(new Date().getTime())); return (1 == pstmt.executeUpdate()); } catch (Exception e) { return false; } } private static boolean selectData(int id) { // Query the data previously inserted into the primary database from the geo replicated database String sql = "SELECT Name, Color, ListPrice FROM SalesLT.Product WHERE Name = ?"; try (Connection connection = DriverManager.getConnection(READ_ONLY_URL); PreparedStatement pstmt = connection.prepareStatement(sql)) { pstmt.setString(1, "BrandNewProduct" + id); try (ResultSet resultSet = pstmt.executeQuery()) { return resultSet.next(); } } catch (Exception e) { return false; } } private static int getHighWaterMarkId() { // Query the high water mark id stored in the table to be able to make unique inserts String sql = "SELECT MAX(ProductId) FROM SalesLT.Product"; int result = 1; try (Connection connection = DriverManager.getConnection(READ_WRITE_URL); Statement stmt = connection.createStatement(); ResultSet resultSet = stmt.executeQuery(sql)) { if (resultSet.next()) { result = resultSet.getInt(1); } } catch (Exception e) { e.printStackTrace(); } return result; } }Guarde y cierre el archivoApp.java.
En la consola de comandos, ejecute el siguiente comando:
mvn packageInicie la aplicación que se ejecutará durante aproximadamente una hora hasta que se detenga manualmente, lo que le proporciona tiempo para ejecutar la prueba de conmutación por error.
mvn -q -e exec:java "-Dexec.mainClass=com.sqldbsamples.App"####################################### ## GEO DISTRIBUTED DATABASE TUTORIAL ## ####################################### 1. insert on primary successful, read from secondary successful 2. insert on primary successful, read from secondary successful 3. insert on primary successful, read from secondary successful ...
Conmutación por error de prueba
Ejecute los siguientes scripts para simular una conmutación por error y observar los resultados de la aplicación. Observe cómo se producirán errores en algunas inserciones y selecciones durante la migración de la base de datos.
Puede comprobar el rol del servidor de recuperación ante desastres durante la prueba con el siguiente comando:
(Get-AzSqlDatabaseFailoverGroup -FailoverGroupName $failoverGroup `
-ResourceGroupName $resourceGroup -ServerName $drServer).ReplicationRole
Para probar una conmutación por error:
Inicie la conmutación por error manual del grupo de conmutación por error:
Switch-AzSqlDatabaseFailoverGroup -ResourceGroupName $resourceGroup ` -ServerName $drServer -FailoverGroupName $failoverGroupRevierta el grupo de conmutación por error al servidor principal:
Switch-AzSqlDatabaseFailoverGroup -ResourceGroupName $resourceGroup ` -ServerName $server -FailoverGroupName $failoverGroup
Pasos siguientes
Consulta la lista de comprobación de alta disponibilidad y recuperación ante desastres de Azure SQL Database.
Contenido relacionado de Azure SQL Database: