Descripción de los idiomas de volumen en Azure NetApp Files
El idioma de volumen (similar a las configuraciones regionales del sistema en sistemas operativos cliente) en un volumen de Azure NetApp Files controla los idiomas y los juegos de caracteres admitidos al usar protocolos NFS y SMB. Azure NetApp Files usa un idioma de volumen predeterminado de C.UTF-8, que proporciona codificación UTF-8 compatible con POSIX para los juegos de caracteres. El idioma C.UTF-8 admite de forma nativa caracteres con un tamaño de 0-3 bytes, que incluye la mayoría de los idiomas del mundo en el plano multilingüe básico (BMP), (incluidos el japonés, el alemán y la mayoría de los idiomas hebreos y cirílicos). Para obtener más información sobre el BMP, consulte Unicode.
Los caracteres fuera de BMP a veces superan el tamaño de 3 bytes admitido por Azure NetApp Files. Por lo tanto, necesitan usar la lógica del par suplente, donde se combinan varios conjuntos de bytes de caracteres para formar nuevos caracteres. Los símbolos emoji, por ejemplo, entran en esta categoría y se admiten en Azure NetApp Files en escenarios en los que no se aplica UTF-8: por ejemplo, los clientes de Windows que usan codificación UTF-16 o NFSv3 que no aplica UTF-8. NFSv4.x aplica UTF-8, lo que significa que los caracteres de par suplente no se muestran correctamente al usar NFSv4.x.
La codificación no estándar, como Shift-JIS y caracteres CJK menos comunes, tampoco se muestran correctamente cuando se aplica UTF-8 en Azure NetApp Files.
Sugerencia
Debe enviar y recibir texto mediante UTF-8 para evitar situaciones en las que los caracteres no se puedan traducir correctamente, lo que puede provocar escenarios de error de creación/cambio de nombre o copia de archivos.
La configuración del idioma del volumen no se puede modificar actualmente en Azure NetApp Files. Para obtener más información, consulte Comportamientos de protocolo con juegos de caracteres especiales.
Para conocer los procedimientos recomendados, consulte Procedimientos recomendados del juego de caracteres.
Codificación de caracteres en volúmenes NFS y SMB de Azure NetApp Files
En un entorno de uso compartido de archivos de Azure NetApp Files, los nombres de archivos y carpetas se representan mediante una serie de caracteres que los usuarios finales leen e interpretan. La forma en que se muestran esos caracteres depende de cómo el cliente envía y recibe la codificación de esos caracteres. Por ejemplo, si un cliente envía codificación American Standard Code for Information Interchange (ASCII) heredada al volumen de Azure NetApp Files al acceder a él, se limita a mostrar solo los caracteres que se admiten en el formato ASCII.
Por ejemplo, el carácter japonés para datos es 資. Dado que este carácter no se puede representar en ASCII, un cliente que usa la codificación ASCII muestra un signo "?" en lugar de 資.
ASCII solo admite 95 caracteres imprimibles, principalmente los que se encuentran en el idioma inglés. Cada uno de esos caracteres usa 1 byte, que se tiene en cuenta en la longitud total de la ruta de acceso del archivo en un volumen de Azure NetApp Files. Esto limita la internacionalización de conjuntos de datos, ya que los nombres de archivo pueden tener una variedad de caracteres no reconocidos por ASCII, del japonés a cirílico a emoji. Un estándar internacional (ISO/IEC 8859) intentó admitir más caracteres internacionales, pero también tenía sus limitaciones. La mayoría de los clientes modernos envían y reciben caracteres mediante algún tipo de Unicode.
Unicode
Como resultado de las limitaciones de las codificaciones ASCII e ISO/IEC 8859, se estableció el estándar Unicode para que cualquier usuario pueda ver el idioma de su región principal desde sus dispositivos.
- Unicode admite más de un millón de juegos de caracteres aumentando el número de bytes por carácter permitido (hasta 4 bytes) y el número total de bytes permitidos en una ruta de acceso de archivo a diferencia de codificaciones anteriores, como ASCII.
- Unicode admite la compatibilidad con versiones anteriores reservando los primeros 128 caracteres para ASCII, al tiempo que garantiza que los primeros 256 puntos de código sean idénticos a los estándares ISO/IEC 8859.
- En el estándar Unicode, los juegos de caracteres se dividen en planos. Un plano es un grupo continuo de 65 536 puntos de código. En total, hay 17 planos (0-16) en el estándar Unicode. El límite es 17 debido a las limitaciones de UTF-16.
- El plano 0 es el plano multilingüe básico (BMP). Este plano contiene los caracteres más usados en varios idiomas.
- De los 17 planos, actualmente solo 5 tienen asignados juegos de caracteres a partir de la versión 15.1 de Unicode.
- Los planos 1-17 se conocen como Planos complementarios multilingües (SMP) y contienen juegos de caracteres menos usados, por ejemplo, sistemas de escritura antiguos como sistemas cuneiformes y jeroglíficos, así como caracteres especiales chinos/japoneses/coreanos (CJK).
- Para obtener métodos para ver las longitudes de los caracteres y los tamaños de ruta de acceso y para controlar la codificación enviada a un sistema, consulte Conversión de archivos a diferentes codificaciones.
Unicode usa el formato de transformación Unicode como estándar, con UTF-8 y UTF-16 como los dos formatos principales.
Planos Unicode
Unicode aprovecha 17 planos de 65 536 caracteres (256 puntos de código multiplicados por 256 cuadros en el plano), con el plano 0 como plano multilingüe básico (BMP). Este plano contiene los caracteres más usados en varios idiomas. Dado que los idiomas y juegos de caracteres del mundo superan los 65 536 caracteres, se necesitan más planos para admitir los juegos de caracteres menos usados.
Por ejemplo, el plano 1 (los planos complementarios multilingües [SMP]) incluye scripts históricos como sistemas cuneiformes y jeroglíficos egipcios, así como algunos Osage, Warang Citi, Adlam, Wancho y Toto. El plano 1 también incluye algunos símbolos y caracteres de emoticonos.
Plano 2: Plano complementario ideográfico (SIP) – contiene caracteres ideográficos unificados chinos/japoneses/coreanos (CJK). Los caracteres de los planos 1 y 2 suelen tener un tamaño de 4 bytes.
Por ejemplo:
- El "emoticono de "cara sonriente con ojos grandes"😃" en el plano 1 tiene un tamaño de 4 bytes.
- El jeroglífico egipcio "𓀀" en el plano 1 tiene un tamaño de 4 bytes.
- El carácter de Osage "𐒸" en el plano 1 tiene un tamaño de 4 bytes.
- El carácter CJK "𫝁" en el plano 2 tiene un tamaño de 4 bytes.
Dado que estos caracteres tienen todos un tamaño de >3 bytes, requieren el uso de pares suplentes para que funcionen correctamente. Azure NetApp Files admite de forma nativa pares suplentes, pero la visualización de los caracteres varía en función del protocolo en uso, la configuración regional del cliente y la configuración de la aplicación de acceso de cliente remoto.
UTF-8
UTF-8 usa codificación de 8 bits y puede tener hasta 1 112 064 puntos de código (o caracteres). UTF-8 es la codificación estándar en todos los idiomas de los sistemas operativos basados en Linux. Dado que UTF-8 usa codificación de 8 bits, el entero sin signo más alto posible es 255 (2^8 – 1), que también es la longitud máxima del nombre de archivo para esa codificación. UTF-8 se usa en más del 98 % de las páginas de Internet, lo que lo convierte en el estándar de codificación más adoptado. El Web Hypertext Application Technology Working Group (WHATWG) considera que UTF-8 es "la codificación obligatoria para todos los [texto]" y que, por motivos de seguridad, las aplicaciones del explorador no deben usar UTF-16.
Los caracteres en formato UTF-8 usan de 1 a 4 bytes, pero casi todos los caracteres de todos los idiomas usan entre 1 y 3 bytes. Por ejemplo:
- La letra del alfabeto latino "A" usa 1 byte. (Uno de los 128 caracteres ASCII reservados)
- Un símbolo de copyright "©" usa 2 bytes.
- El carácter "ä" usa 2 bytes. (1 byte para "a" + 1 byte para la metafonía)
- El símbolo kanji japonés para datos (資) usa 3 bytes.
- Un emoji de cara sonriente (😃) usa 4 bytes.
Las configuraciones regionales de idioma pueden usar UTF-8 estándar del equipo (C.UTF-8) o un formato más específico de la región, como en en_US.UTF-8, ja.UTF-8, etc. Debe usar la codificación UTF-8 para clientes Linux al acceder a Azure NetApp Files siempre que sea posible. A partir del sistema operativo X, los clientes de macOS también usan UTF-8 para su codificación predeterminada y esto no se debería modificar.
Los clientes Windows usan UTF-16. En la mayoría de los casos, este valor debe dejarse como valor predeterminado para la configuración regional del sistema operativo, pero los clientes más recientes ofrecen compatibilidad beta con caracteres UTF-8 a través de una casilla. Los clientes de terminal en Windows también se pueden modificar para usar UTF-8 en PowerShell o CMD según sea necesario. Para obtener más información, consulte Comportamientos de protocolo dual con juegos de caracteres especiales.
UTF-16
UTF-16 usa codificación de 16 bits y es capaz de codificar los 1 112 064 puntos de código de Unicode. La codificación para UTF-16 puede usar una o dos unidades de código de 16 bits, cada una de 2 bytes de tamaño. Todos los caracteres de UTF-16 usan tamaños de 2 o 4 bytes. Los caracteres de UTF-16 que usan 4 bytes aprovechan pares suplentes, que combinan dos caracteres separados de 2 bytes para crear un carácter nuevo. Estos caracteres complementarios se encuentran fuera del plano BMP estándar y dentro de uno de los otros planos multilingües.
UTF-16 se usa en sistemas operativos Windows y API, Java y JavaScript. Puesto que no admite la compatibilidad con versiones anteriores con formatos ASCII, nunca ganó popularidad en la web. UTF-16 solo compone alrededor del 0,002 % de todas las páginas de Internet. El Web Hypertext Application Technology Working Group (WHATWG) considera que UTF-8 es "la codificación obligatoria para todo el texto" y recomienda que las aplicaciones no usen UTF-16 para la seguridad del explorador.
Azure NetApp Files admite la mayoría de los caracteres UTF-16, incluidos los pares suplentes. En los casos en los que no se admite el carácter, los clientes de Windows notifican un error de "el nombre de archivo especificado no es válido o es demasiado largo".
Control del juego de caracteres a través de clientes remotos
Las conexiones remotas a los clientes que montan volúmenes de Azure NetApp Files (como las conexiones SSH a los clientes Linux para acceder a los montajes NFS) se pueden configurar para enviar y recibir codificaciones de idioma de volumen específicas. La codificación de idioma enviada al cliente a través de la utilidad de conexión remota controla cómo se crean y cómo se ven los juegos de caracteres. Como resultado, una conexión remota que usa una codificación de idioma diferente a otra conexión remota (como dos ventanas PuTTY diferentes) puede mostrar resultados diferentes para los caracteres al enumerar nombres de archivo y carpeta en el volumen de Azure NetApp Files. En la mayoría de los casos, esto no creará discrepancias (por ejemplo, para caracteres latinos o en inglés), pero en los casos de caracteres especiales, como los emojis, los resultados pueden variar.
Por ejemplo, el uso de una codificación de UTF-8 para la conexión remota muestra resultados predecibles para caracteres en volúmenes de Azure NetApp Files, ya que C.UTF-8 es el idioma de volumen. El carácter japonés para "datos" (資) se muestra de forma diferente en función de la codificación enviada por el terminal.
Codificación de caracteres en PuTTY
Cuando una ventana PuTTY usa UTF-8 (que se encuentra en la configuración de traducción de Windows), el carácter se representa correctamente para un volumen montado NFSv3 en Azure NetApp Files:

Si la ventana PuTTY usa una codificación diferente, como ISO-8859-1:1998 (Latin-1, Oeste de Europa), el mismo carácter se muestra de forma diferente aunque el nombre de archivo sea el mismo.

PuTTY, de manera predeterminada, no contiene codificaciones CJK. Hay revisiones disponibles para agregar esos conjuntos de idioma a PuTTY.
Codificaciones de caracteres en Bastion
Microsoft Azure recomienda usar Bastion para la conectividad remota con máquinas virtuales (VM) en Azure. Al usar Bastion, la codificación de idioma enviada y recibida no se expone en la configuración, pero aprovecha la codificación UTF-8 estándar. Como resultado, la mayoría de los juegos de caracteres vistos en PuTTY con UTF-8 también deben ser visibles en Bastion, siempre que los juegos de caracteres se admitan en el protocolo que se usa.

Sugerencia
Se pueden usar otros terminales SSH, como TeraTerm. TeraTerm proporciona una gama más amplia de juegos de caracteres admitidos de manera predeterminada, incluidas las codificaciones CJK y las codificaciones no estándar, como Shift-JIS.
Comportamientos de protocolo con juegos de caracteres especiales
Los volúmenes de Azure NetApp Files usan codificación UTF-8 y admiten caracteres de forma nativa que no superan los 3 bytes. Todos los caracteres del conjunto ASCII y UTF-8 se muestran correctamente porque se encuentran en el intervalo de 1 a 3 bytes. Por ejemplo:
- El carácter alfabético latino "A" usa 1 byte (uno de los 128 caracteres ASCII reservados).
- Un símbolo de copyright © usa 2 bytes.
- El carácter "ä" usa 2 bytes (1 byte para la "a" y 1 byte para la metafonía).
- El símbolo kanji japonés para datos (資) usa 3 bytes.
Azure NetApp Files también admite algunos caracteres que superan los 3 bytes a través de la lógica del par suplente (como los emojis), siempre que la codificación del cliente y la versión del protocolo las admitan. Para obtener más información sobre los comportamientos de protocolo, consulte:
Comportamientos de SMB
En volúmenes SMB, Azure NetApp Files crea y mantiene dos nombres para archivos o directorios en cualquier directorio que tenga acceso desde un cliente SMB: el nombre largo original y un nombre en formato 8.3.
Nombres de archivo en SMB con Azure NetApp Files
Cuando los nombres de archivo o directorio superan los bytes de caracteres permitidos o usan caracteres no admitidos, Azure NetApp Files genera un nombre en formato 8.3 como se indica a continuación:
- Trunca el nombre del archivo o directorio original.
- Anexa una tilde (~) y un número (1-5) a los nombres de archivo o directorio que ya no son únicos después de truncarse. Si hay más de cinco archivos con nombres no únicos, Azure NetApp Files crea un nombre único sin relación con el nombre original. En el caso de los archivos, Azure NetApp Files trunca la extensión de nombre de archivo en tres caracteres.
Por ejemplo, si un cliente de NFS crea un archivo denominado specifications.html, Azure NetApp Files crea el nombre de archivo specif~1.htm siguiendo el formato 8.3. Si este nombre ya existe, Azure NetApp Files usa un número diferente al final del nombre de archivo. Por ejemplo, si un cliente NFS crea otro archivo denominado specifications\_new.html, el formato 8.3 de specifications\_new.html es specif~2.htm.
Carácter especial en SMB con Azure NetApp Files
Cuando se usa SMB con volúmenes de Azure NetApp Files, se permiten caracteres que superan los 3 bytes usados en los nombres de archivo y carpeta (incluidos los emoticonos) debido a la compatibilidad con pares suplentes. A continuación se muestra lo que ve el Explorador de Windows para caracteres fuera del BMP en una carpeta creada desde un cliente de Windows cuando se usa inglés con la codificación UTF-16 predeterminada.
Nota:
La fuente predeterminada en el Explorador de Windows es Segoe UI. Los cambios de fuente pueden afectar a cómo se muestran algunos caracteres en los clientes.

La forma en que se muestran los caracteres en el cliente depende de la fuente del sistema y de la configuración regional y del idioma. En general, los caracteres que se encuentran en BMP se admiten en todos los protocolos, independientemente de si la codificación es UTF-8 o UTF-16.
Al usar CMD o PowerShell, la pantalla del juego de caracteres depende de la configuración de fuente. Estas utilidades tienen opciones de fuente limitadas de manera predeterminada. CMD usa Consolas como fuente predeterminada.
Es posible que los nombres de archivo no se muestren según lo esperado en función de la fuente usada, ya que algunas consolas no admiten de forma nativa Segoe UI u otras fuentes que representan caracteres especiales correctamente.
Este problema se puede solucionar en los clientes de Windows mediante PowerShell ISE, lo que proporciona compatibilidad con fuentes más sólida. Por ejemplo, si se establece PowerShell ISE en Segoe UI, se muestran los nombres de archivo con los caracteres admitidos correctamente.

Sin embargo, PowerShell ISE está diseñado para scripting, en lugar de administrar recursos compartidos. Las versiones más recientes de Windows ofrecen Terminal Windows, que permite controlar las fuentes y los valores de codificación.
Nota:
Use el comando chcp para ver la codificación del terminal. Para obtener una lista completa de las páginas de códigos, consulte Identificadores de página de códigos.

Si el volumen está habilitado para el protocolo dual (NFS y SMB), es posible que observe comportamientos diferentes. Para obtener más información, consulte Comportamientos de protocolo dual con juegos de caracteres especiales.
Comportamientos de NFS
La forma en que NFS muestra caracteres especiales depende de la versión de NFS usada, la configuración regional del cliente, las fuentes instaladas y la configuración del cliente de conexión remota en uso. Por ejemplo, el uso de Bastion para tener acceso a un cliente Ubuntu controla la forma en que se muestran los caracteres de forma diferente que un cliente PuTTY establecido en una configuración regional diferente en la misma máquina virtual. Los ejemplos de NFS siguientes se basan en esta configuración regional para una máquina virtual Ubuntu:
~$ locale
LANG=C.UTF-8
LANGUAGE=
LC\_CTYPE="C.UTF-8"
LC\_NUMERIC="C.UTF-8"
LC\_TIME="C.UTF-8"
LC\_COLLATE="C.UTF-8"
LC\_MONETARY="C.UTF-8"
LC\_MESSAGES="C.UTF-8"
LC\_PAPER="C.UTF-8"
LC\_NAME="C.UTF-8"
LC\_ADDRESS="C.UTF-8"
LC\_TELEPHONE="C.UTF-8"
LC\_MEASUREMENT="C.UTF-8"
LC\_IDENTIFICATION="C.UTF-8"
LC\_ALL=
Comportamiento de NFSv3
NFSv3 no aplica la codificación UTF en archivos y carpetas. En la mayoría de los casos, los juegos de caracteres especiales no deberían tener ningún problema. Sin embargo, el cliente de conexión usado puede afectar la manera en que se envían y reciben los caracteres. Por ejemplo, el uso de caracteres Unicode fuera del BMP para un nombre de carpeta en el bastión del cliente de conexión de Azure puede dar lugar a un comportamiento inesperado debido a cómo funciona la codificación del cliente.
En la captura de pantalla siguiente, Bastion no puede copiar y pegar los valores en el símbolo del sistema de la CLI desde fuera del explorador al asignar un nombre a un directorio a través de NFSv3. Al intentar copiar y pegar el valor de NFSv3Bastion𓀀𫝁😃𐒸, los caracteres especiales se muestran como comillas en la entrada.

El comando copy-paste se permite a través de NFSv3, pero los caracteres se crean como valores numéricos, lo que afecta a su presentación:
NFSv3Bastion'$'\262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355
Esta presentación se debe a la codificación usada por Bastion para enviar valores de texto al copiar y pegar.
Cuando se usa PuTTY para crear una carpeta con los mismos caracteres a través de NFSv3, el nombre de la carpeta es diferente en Bastion que cuando se usó Bastion para crearla. El emoticono se muestra como se esperaba (debido a las fuentes instaladas y la configuración regional), pero los demás caracteres (como el Osage "𐒸") no.

Desde una ventana PuTTY, los caracteres se muestran correctamente:

Comportamiento de NFSv4.x
NFSv4.x aplica la codificación UTF-8 en los nombres de archivo y carpeta según las especificaciones de internacionalización RFC-8881.
Como resultado, si se envía un carácter especial con codificación que no sea UTF-8, NFSv4.x podría no permitir el valor.
En algunos casos, puede permitir un comando mediante un carácter fuera del plano multilingüe básico (BMP), pero es posible que no muestre el valor después de crearlo.
Por ejemplo, emitir mkdir con un nombre de carpeta, incluidos los caracteres "𓀀𫝁😃𐒸" (caracteres en los planos complementarios multilingües (SMP) y el Plano complementario ideográfico (SIP)) parecen tener éxito en NFSv4.x. La carpeta no estará visible al ejecutar el comando ls.
root@ubuntu:/NFSv4/NFS$ mkdir "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS$ ls -la
total 8
drwxrwxr-x 3 nobody 4294967294 4096 Jan 10 17:15 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
root@ubuntu:/NFSv4/NFS$
La carpeta existe en el volumen. Cambiar a ese nombre de directorio oculto funciona desde el cliente PuTTY y se puede crear un archivo dentro de ese directorio.
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ sudo touch Unicode.txt
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ ls -la
-rw-r--r-- 1 root root 0 Jan 10 17:31 Unicode.txt
Un comando de estadísticas de PuTTY también confirma que la carpeta existe:
root@ubuntu:/NFSv4/NFS$ stat "NFSv4 Putty 𓀀𫝁😃𐒸"
**File: NFSv4 Putty** **𓀀**** 𫝁 ****😃**** 𐒸**
Size: 4096 Blocks: 8 IO Block: 262144 **directory**
Device: 3ch/60d Inode: 101 Links: 2
Access: (0775/drwxrwxr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2024-01-10 17:15:44.860775000 +0000
Modify: 2024-01-10 17:31:35.049770000 +0000
Change: 2024-01-10 17:31:35.049770000 +0000
Birth: -
Aunque se confirme que la carpeta existe, los comandos de carácter comodín no funcionan, ya que el cliente no puede "ver" oficialmente la carpeta en la pantalla.
root@ubuntu:/NFSv4/NFS$ cp \* /NFSv3/
cp: can't stat '\*': No such file or directory
NFSv4.1 envía un error al cliente cuando encuentra un carácter que no se basa en la codificación UTF-8.
Por ejemplo, al usar Bastion para intentar acceder al mismo directorio que creamos mediante PuTTY a través de NFSv4.1, este es el resultado:
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃�"
-bash: cd: $'NFSv4 Putty \262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355': Invalid argument
The "invalid argument" error message doesn't help diagnose the root cause, but a packet capture shines a light on the problem:
78 1.704856 y.y.y.y x.x.x.x NFS 346 V4 Call (Reply In 79) LOOKUP DH: 0x44caa451/NFSv4 Putty ��������
79 1.705058 x.x.x.x y.y.y.y NFS 166 V4 Reply (Call In 25) OPEN Status: NFS4ERR\_INVAL
NFS4ERR_INVAL se trata en RFC-8881.
Dado que se puede acceder a la carpeta desde PuTTY (debido a la codificación que se envía y se recibe), se puede copiar si se especifica el nombre. Después de copiar esa carpeta desde el volumen NFSv4.1 de Azure NetApp Files al volumen NFSv3 de Azure NetApp Files, el nombre de la carpeta muestra:
root@ubuntu:/NFSv4/NFS$ cp -r /NFSv4/NFS/"NFSv4 Putty 𓀀𫝁😃𐒸" /NFSv3/NFSv3/
root@ubuntu:/NFSv4/NFS$ ls -la /NFSv3/NFSv3 | grep v4
drwxrwxr-x 2 root root 4096 Jan 10 17:49 NFSv4 Putty 𓀀𫝁😃𐒸
Se puede ver el mismo error NFS4ERR\_INVAL si se intenta realizar una conversión de archivos (mediante "iconv") a un formato que no sea UTF-8, como Shift-JIS.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Para obtener más información, consulte Conversión de archivos a diferentes codificaciones.
Comportamientos del protocolo dual
Azure NetApp Files permite acceder a los volúmenes mediante NFS y SMB a través del acceso de protocolo dual. Debido a las enormes diferencias en la codificación de idioma usada por NFS (UTF-8) y SMB (UTF-16), los juegos de caracteres, los nombres de archivo y carpeta, y las longitudes de ruta de acceso pueden tener comportamientos muy diferentes entre protocolos.
Visualización de archivos y carpetas creados por NFS desde SMB
Cuando Azure NetApp Files se usa para el acceso de protocolo dual (SMB y NFS), podría usarse un juego de caracteres no admitido por UTF-16 en un nombre de archivo creado mediante UTF-8 a través de NFS. En esos escenarios, cuando SMB accede a un archivo con caracteres no admitidos, el nombre se trunca en SMB mediante la convención de nombre de archivo corto 8.3.
Comportamientos de SMB y archivos creados por NFSv3 con juegos de caracteres
NFSv3 no aplica la codificación UTF-8. Los caracteres que usan codificaciones de idioma no estándar (como Shift-JIS) funcionan con Azure NetApp Files al usar NFSv3.
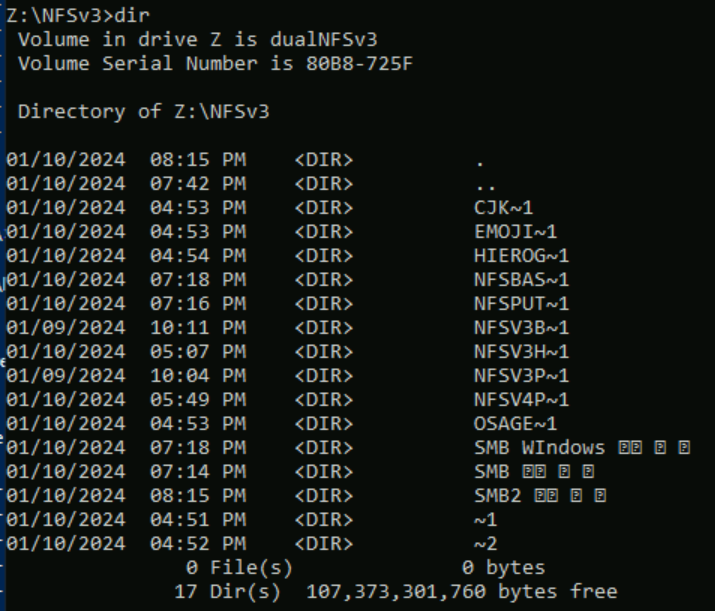
En el ejemplo siguiente, se creó una serie de nombres de carpeta mediante distintos conjuntos de caracteres desde varios planos de Unicode en un volumen de Azure NetApp Files mediante NFSv3. Cuando se ve desde NFSv3, se muestran correctamente.
root@ubuntu:/NFSv3/dual$ ls -la
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-English
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-Japanese-German-資ä
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-copyright-©
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-CJK-plane2-𫝁
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-emoji-plane1-😃
En Windows SMB, las carpetas con caracteres que se encuentran en BMP se muestran correctamente, pero los caracteres fuera de ese plano se muestran con el formato de nombre 8.3 debido a que la conversión UTF-8/UTF-16 no es compatible con esos caracteres.
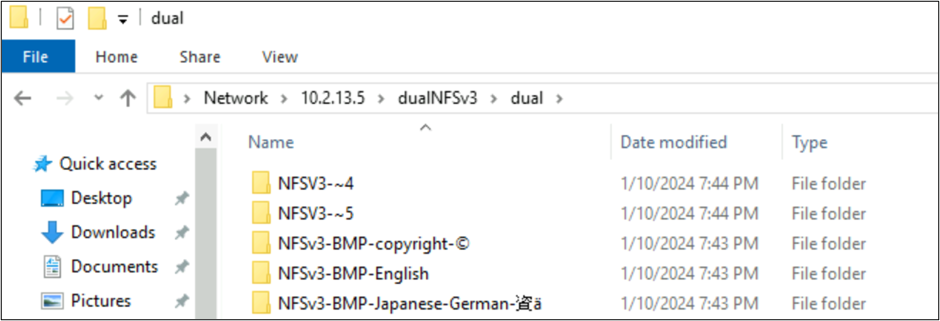
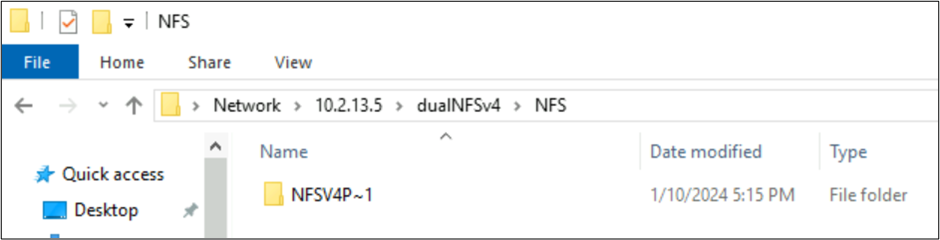
Comportamientos de SMB y archivos creados por NFSv4.1 con juegos de caracteres
En los ejemplos anteriores, se creó una carpeta denominada NFSv4 Putty 𓀀𫝁😃𐒸 en un volumen de Azure NetApp Files a través de NFSv4.1, pero no se pudo ver mediante NFSv4.1. Sin embargo, se puede ver mediante SMB. El nombre se trunca en SMB a un formato 8.3 compatible debido a los conjuntos de caracteres no admitidos creados a partir del cliente NFS y la conversión UTF-8/UTF-16 incompatible para caracteres en diferentes planos de Unicode.
Cuando un nombre de carpeta usa caracteres UTF-8 estándar que se encuentran en BMP (inglés o de otro modo), SMB traduce los nombres correctamente.
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-English
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-資ä
root@ubuntu:/NFSv4/NFS$ ls -la
total 16
drwxrwxr-x 5 nobody 4294967294 4096 Jan 10 18:26 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
**drwxrwxr-x 2 root root 4096 Jan 10 18:21 NFS-created-English**
**drwxrwxr-x 2 root root 4096 Jan 10 18:26 NFS-created-**** 資 ****ä**
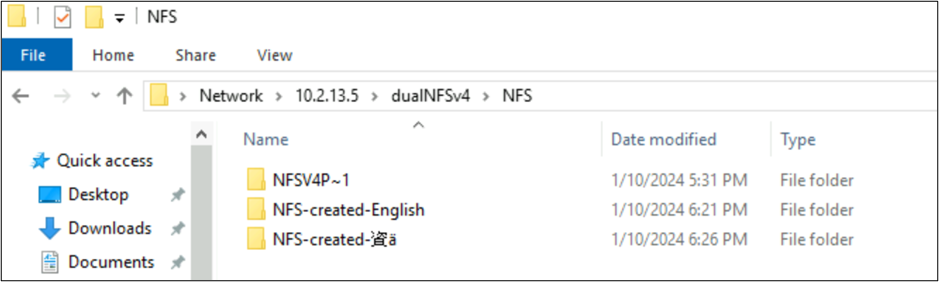
Archivos y carpetas creados por SMB a través de NFS
Los clientes de Windows son el tipo principal de clientes que se usan para acceder a los recursos compartidos de SMB. Estos clientes tienen como valor predeterminado la codificación UTF-16. Es posible admitir algunos caracteres codificados con UTF-8 en Windows si lo habilita en la configuración de la región:
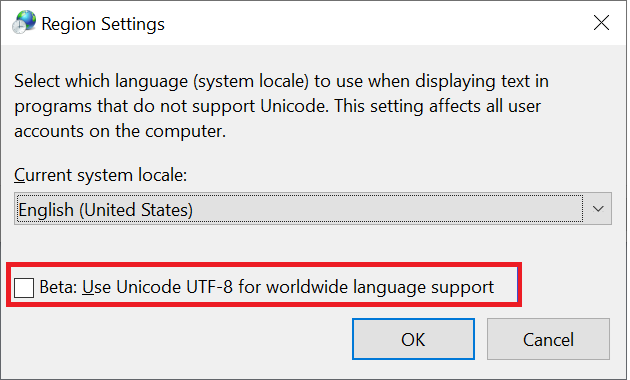
Cuando se crea un archivo o carpeta a través de un recurso compartido de SMB en Azure NetApp Files, el juego de caracteres codifica como UTF-16. Como resultado, es posible que los clientes que usen codificación UTF-8 (como clientes NFS basados en Linux) no puedan traducir correctamente algunos juegos de caracteres, especialmente los caracteres que se encuentran fuera del plano multilingüe básico (BMP).
Comportamiento de caracteres no admitidos
En esos escenarios, cuando un cliente NFS accede a un archivo creado mediante SMB con caracteres no admitidos, el nombre se muestra como una serie de valores numéricos que representan los valores Unicode para el carácter.
Por ejemplo, esta carpeta se creó en el Explorador de Windows con caracteres fuera del BMP.
PS Z:\SMB\> dir
Directory: Z:\SMB
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/9/2024 9:53 PM SMB𓀀𫝁😃𐒸
A través de NFSv3, se muestra la carpeta creada por SMB:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 9 21:53 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
A través de NFSv4.1, la carpeta creada por SMB se muestra de la siguiente manera:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 4 17:09 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
Comportamiento de caracteres admitidos
Cuando los caracteres están en BMP, no hay ningún problema entre los protocolos SMB y NFS y sus versiones.
Por ejemplo, un nombre de carpeta creado con SMB en un volumen de Azure NetApp Files con caracteres que se encuentran en BMP en varios idiomas (inglés, alemán, caracteres cirílicos y rúnicos) aparece bien en todos los protocolos y versiones.
- Latin básico "SMB"
- Griego "ͶΘΩ"
- Cirílico "ЁЄЊ"
- Rúnico "ᚠᚱᛯ"
- Caracteres Ideográficos con compatibilidad CJK "豈滑虜"
Así es como aparece el nombre en SMB:
PS Z:\SMB\> mkdir SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/11/2024 8:00 PM SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Así es como aparece el nombre de NFSv3:
$ ls | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Así es como aparece el nombre de NFSv4.1:
$ ls /NFSv4/SMB | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Conversión de archivos en diferentes codificaciones
Los nombres de archivo y carpeta no son las únicas partes de los objetos del sistema de archivos que usan codificaciones de idioma. El contenido del archivo (por ejemplo, caracteres especiales dentro de un archivo de texto) también puede intervenir. Por ejemplo, si se intenta guardar un archivo con caracteres especiales en un formato incompatible, se podrá ver un mensaje de error. En este caso, un archivo con caracteres Katakana no se puede guardar en ANSI, ya que esos caracteres no existen en esa codificación.
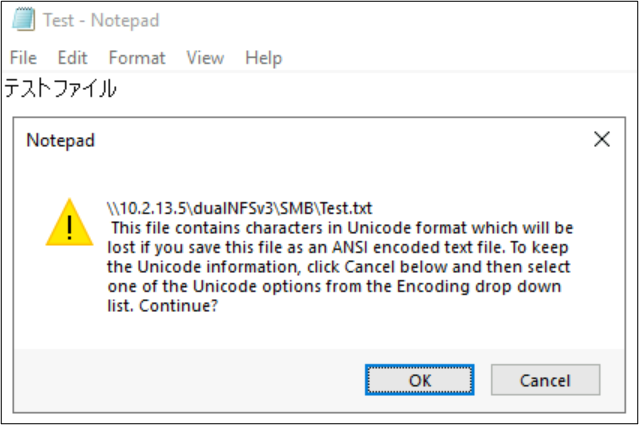
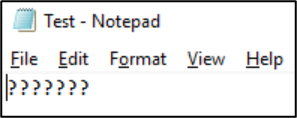
Una vez guardado ese archivo en ese formato, los caracteres se convierten en signos de interrogación:
Las codificaciones de archivos se pueden ver desde clientes NAS. En los clientes de Windows, puede usar una aplicación como el Bloc de notas o el Bloc de notas++ para ver la codificación de un archivo. Si el Subsistema de Windows para Linux (WSL) o Git están instalados en el cliente, se puede usar el comando file.
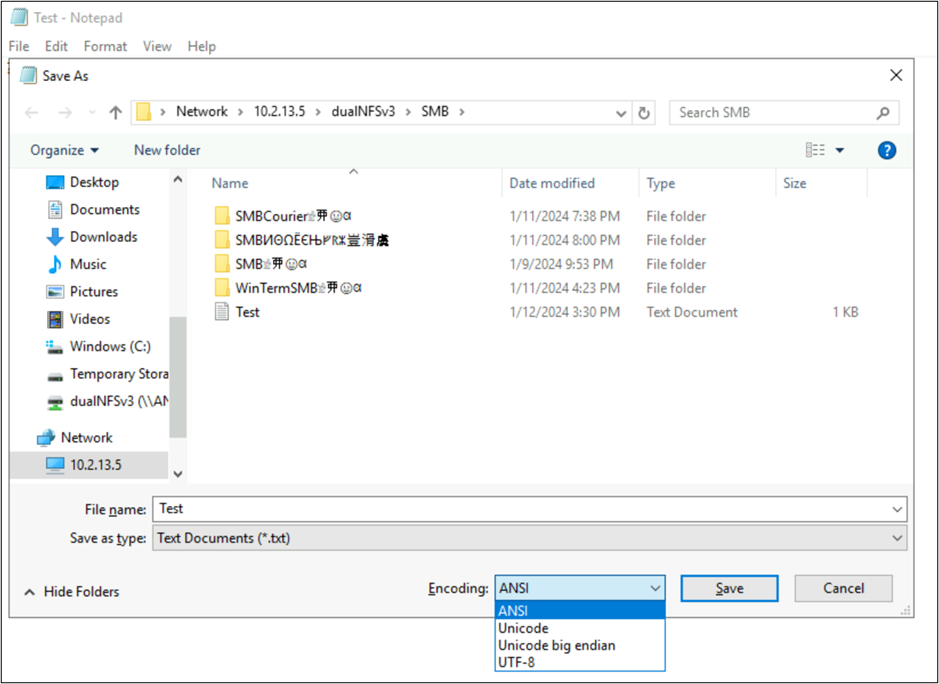
Estas aplicaciones también permiten cambiar la codificación del archivo guardando como tipos de codificación diferentes. Además, se puede usar PowerShell para convertir la codificación en archivos con los cmdlets Get-Content y Set-Content.
Por ejemplo, el archivo utf8-text.txt se codifica como UTF-8 y contiene caracteres fuera del BMP. Dado que se usa UTF-8, los caracteres se muestran correctamente.
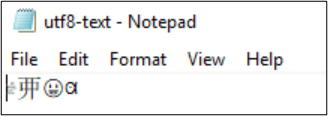
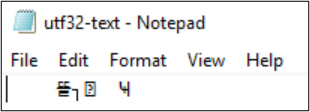
Si la codificación se convierte en UTF-32, los caracteres no se muestran correctamente.
PS Z:\SMB\> Get-Content .\utf8-text.txt |Set-Content -Encoding UTF32 -Path utf32-text.txt
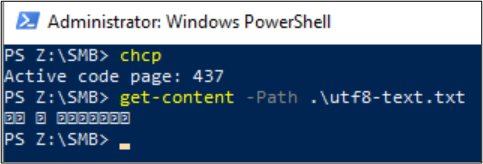
Get-Content también se puede usar para mostrar el contenido del archivo. De manera predeterminada, PowerShell usa codificación UTF-16 (página de códigos 437) y las selecciones de fuente para la consola están limitadas, por lo que el archivo con formato UTF-8 con caracteres especiales no se puede mostrar correctamente:
Los clientes de Linux pueden usar el comando file para ver la codificación del archivo. En entornos de protocolo dual, si se crea un archivo mediante SMB, el cliente Linux que usa NFS puede comprobar la codificación del archivo.
$ file -i utf8-text.txt
utf8-text.txt: text/plain; charset=utf-8
$ file -i utf32-text.txt
utf32-text.txt: text/plain; charset=utf-32le
La conversión de codificación de archivos se puede realizar en clientes Linux mediante el comando iconv. Para ver la lista de formatos de codificación admitidos, use iconv -l.
Por ejemplo, el archivo codificado con UTF-8 se puede convertir a UTF-16.
$ iconv -t UTF16 utf8-text.txt \> utf16-text.txt
$ file -i utf8-text.txt
utf8-text.txt: text/plain; **charset=utf-8**
$ file -i utf16-text.txt
utf16-text.txt: text/plain; **charset=utf-16le**
Si el juego de caracteres en el nombre del archivo o en el contenido del archivo no es compatible con la codificación de destino, no se permite la conversión. Por ejemplo, Shift-JIS no puede admitir los caracteres en el contenido del archivo.
$ iconv -t SJIS utf8-text.txt SJIS-text.txt
iconv: illegal input sequence at position 0
Si un archivo tiene caracteres compatibles con la codificación, la conversión se realizará correctamente. Por ejemplo, si el archivo contiene los caracteres Katakana テストファイル, la conversión shift-JIS se realizará correctamente a través de NFS. Dado que el cliente NFS que se usa aquí no entiende Shift-JIS debido a la configuración regional, la codificación muestra "unknown-8bit".
$ cat SJIS.txt
テストファイル
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
$ iconv -t SJIS SJIS.txt \> SJIS2.txt
$ file -i SJIS.txt
SJIS.txt: text/plain; **charset=utf-8**
$ file -i SJIS2.txt
SJIS2.txt: text/plain; **charset=unknown-8bit**
Dado que los volúmenes de Azure NetApp Files solo admiten un formato compatible con UTF-8, los caracteres Katakana se convierten a un formato ilegible.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
Cuando se usa NFSv4.x, se permite la conversión cuando hay caracteres no compatibles presentes dentro del contenido del archivo, aunque NFSv4.x aplique la codificación UTF-8. En este ejemplo, un archivo codificado con UTF-8 con caracteres Katakana ubicados en un volumen de Azure NetApp Files muestra el contenido de un archivo correctamente.
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
S$ cat SJIS.txt
テストファイル
Pero una vez convertido, los caracteres del archivo se muestran incorrectamente debido a la codificación incompatible.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
Si el nombre del archivo contiene caracteres no admitidos para UTF-8, la conversión se realiza correctamente en NFSv3, pero produce un error en NFSv4.x debido a la aplicación de UTF-8 de la versión del protocolo.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Procedimientos recomendados para el juego de caracteres
Al usar caracteres especiales o caracteres fuera del plano multilingüe básico (BMP) estándar en volúmenes de Azure NetApp Files, se deben tener en cuenta algunos procedimientos recomendados.
- Dado que los volúmenes de Azure NetApp Files usan el idioma de volumen UTF-8, la codificación de archivos para los clientes NFS también debe usar la codificación UTF-8 para obtener resultados coherentes.
- Los juegos de caracteres en los nombres de archivo o contenidos en el contenido del archivo deben ser compatibles con UTF-8 para lograr una visualización y la funcionalidad adecuadas.
- Dado que SMB usa codificación de caracteres con UTF-16, es posible que los caracteres fuera del BMP no se muestren correctamente en NFS en volúmenes de protocolo dual. Como sea posible, minimice el uso de caracteres especiales en el contenido del archivo.
- Evite usar caracteres especiales fuera del BMP en nombres de archivo, especialmente cuando se usan volúmenes NFSv4.1 o de protocolo dual.
- En el caso de los juegos de caracteres que no están en BMP, la codificación UTF-8 debe permitir la visualización de los caracteres en Azure NetApp Files al usar un único protocolo de archivo (solo SMB o NFS). Sin embargo, los volúmenes de protocolo dual no pueden adaptarse a estos juegos de caracteres en la mayoría de los casos.
- No se admite la codificación no estándar (como Shift-JIS) en volúmenes de Azure NetApp Files.
- Los caracteres de par suplente (como los emojis) se admiten en volúmenes de Azure NetApp Files.