Rendimiento de Oracle Database en varios volúmenes de Azure NetApp Files
La migración de bases de datos de nivel Exadata de alto rendimiento a la nube se está convirtiendo cada vez más en un imperativo para los clientes de Microsoft. Las suites de software de la cadena de suministro suelen poner el listón muy alto debido a las intensas demandas de E/S del almacenamiento con una carga de trabajo mixta de lectura y escritura impulsada por un único nodo informático. La infraestructura de Azure en combinación con Azure NetApp Files puede satisfacer las necesidades de esta carga de trabajo muy exigente. En este artículo se presenta un ejemplo de cómo se cumplió esta demanda para un cliente y cómo Azure puede satisfacer las demandas de las cargas de trabajo críticas de Oracle.
Rendimiento de Oracle de escala empresarial
Al explorar los límites superiores del rendimiento, es importante reconocer y reducir las restricciones que podrían sesgar los resultados de forma falsa. Por ejemplo, si la intención es demostrar las funcionalidades de rendimiento de un sistema de almacenamiento, el cliente debe configurarse idealmente para que la CPU no se convierta en un factor de mitigación antes de que se alcancen los límites de rendimiento del almacenamiento. Para ello, las pruebas comenzaron con el tipo de instancia de E104ids_v5, ya que esta máquina virtual viene equipada no solo con una interfaz de red de 100 Gbps, sino con un límite de salida igual a grande (100 Gbps).
Las pruebas se produjeron en dos fases:
- La primera fase se centró en las pruebas que usan la herramienta SLOB2 estándar del sector (Silly Little Oracle Benchmark) de Kevin Closson, versión 2.5.4. El objetivo es impulsar la mayor cantidad posible de E/S de Oracle desde una máquina virtual (VM) a varios volúmenes de Azure NetApp Files y, a continuación, escalar horizontalmente con más bases de datos para demostrar el escalado lineal.
- Después de probar los límites de escalado, nuestras pruebas se dinamizan a los menos costosos, pero casi tan capaces E96ds_v5 para una fase de prueba de clientes mediante una verdadera carga de trabajo de la aplicación de cadena de suministro y datos reales.
Rendimiento de escalado vertical de SLOB2
Los gráficos siguientes capturan el perfil de rendimiento de una sola máquina virtual de Azure E104ids_v5 que ejecuta una base de datos de Oracle 19c en ocho volúmenes de Azure NetApp Files con ocho puntos de conexión de almacenamiento. Los volúmenes se distribuyen entre tres grupos de discos ASM: datos, registro y archivo. Se asignaron cinco volúmenes al grupo de discos de datos, dos volúmenes al grupo de discos de registro y un volumen al grupo de discos de archivo. Todos los resultados capturados en este artículo se recopilaron mediante regiones de Azure de producción y servicios activos de Azure de producción.
Para implementar Oracle en máquinas virtuales de Azure mediante varios volúmenes de Azure NetApp Files en varios puntos de conexión de almacenamiento, use el grupo de volúmenes de aplicaciones para Oracle.
Arquitectura de host único
En el diagrama siguiente se muestra la arquitectura en la que se completaron las pruebas; tenga en cuenta que la base de datos de Oracle se distribuye entre varios volúmenes y puntos de conexión de Azure NetApp Files.

E/S de almacenamiento de host único
En el diagrama siguiente se muestra una carga de trabajo seleccionada aleatoriamente del 100 % con una proporción de aciertos del búfer de base de datos de aproximadamente un 8 %. SLOB2 pudo controlar aproximadamente 850 000 solicitudes de E/S por segundo mientras se mantiene una latencia secuencial de eventos de lectura secuencial del archivo de base de datos submillisegundos. Con un tamaño de bloque de base de datos de 8K que equivale a aproximadamente 6800 MiB/s de rendimiento de almacenamiento.

Rendimiento de host único
En el diagrama siguiente se muestra que, para cargas de trabajo de E/S secuenciales intensivas de ancho de banda, como recorridos de tabla completos o actividades de RMAN, Azure NetApp Files puede ofrecer las funcionalidades de ancho de banda completo de la propia máquina virtual de E104ids_v5.

Nota:
Dado que la instancia de proceso está en el máximo teórico de su ancho de banda, agregar simultaneidad de aplicaciones adicionales solo da como resultado un aumento de la latencia del lado cliente. Esto da como resultado que las cargas de trabajo SLOB2 superen el período de tiempo de finalización de destino, por lo que el número de subprocesos se limitó en seis.
Rendimiento de escalabilidad horizontal de SLOB2
En los gráficos siguientes se captura el perfil de rendimiento de tres máquinas virtuales de Azure E104ids_v5 cada una que ejecuta una base de datos única de Oracle 19c y cada una con su propio conjunto de volúmenes de Azure NetApp Files y un diseño de grupo de discos ASM idéntico, tal como se describe en la sección Escalado vertical del rendimiento. Los gráficos muestran que, con Azure NetApp Files de varios volúmenes o varios puntos de conexión, el rendimiento se escala horizontalmente fácilmente con coherencia y predictibilidad.
Arquitectura de varios hosts
En el diagrama siguiente se muestra la arquitectura en la que se completaron las pruebas; tenga en cuenta las tres bases de datos de Oracle distribuidas entre varios volúmenes y puntos de conexión de Azure NetApp Files. Los puntos de conexión se pueden dedicar a un único host, como se muestra con la máquina virtual de Oracle 1 o compartirse entre hosts, como se muestra con Oracle VM2 y Oracle VM 3.

E/S de almacenamiento de varios hosts
En el diagrama siguiente se muestra una carga de trabajo seleccionada aleatoriamente del 100 % con una proporción de aciertos del búfer de base de datos de aproximadamente un 8 %. SLOB2 pudo conducir aproximadamente 850 000 solicitudes de E/S por segundo en los tres hosts individualmente. SLOB2 pudo hacerlo mientras se ejecutaba en paralelo a un total colectivo de aproximadamente 2500 000 solicitudes de E/S por segundo con cada host manteniendo una latencia de eventos de lectura secuencial de archivos de base de datos submillisegundos. Con un tamaño de bloque de base de datos de 8K, esto equivale a aproximadamente 20 000 MiB/s entre los tres hosts.

Rendimiento de varios hosts
En el diagrama siguiente se muestra que, para cargas de trabajo secuenciales, Azure NetApp Files todavía puede ofrecer las funcionalidades de ancho de banda completo de la propia máquina virtual de E104ids_v5 incluso a medida que se escala hacia fuera. SLOB2 pudo controlar la E/S totalando más de 30 000 MiB/s en los tres hosts mientras se ejecuta en paralelo.

Rendimiento real
Después de probar los límites de escalado con SLOB2, se realizaron pruebas con un conjunto de aplicaciones de cadena de suministro de palabras reales en Oracle en Azure NetApp files con excelentes resultados. Los siguientes datos del informe Repositorio automático de cargas de trabajo (AWR) de Oracle son un vistazo resaltado a cómo se ha realizado un trabajo crítico específico.
Esta base de datos tiene una E/S adicional significativa, además de la carga de trabajo de la aplicación debido a que la memoria flashback está habilitada y tiene un tamaño de bloque de base de datos de 16k. En la sección perfil de E/S del informe de AWR, es evidente que hay una gran proporción de escrituras en comparación con las lecturas.
| - | Lectura y escritura por segundo | Lectura por segundo | Escritura por segundo |
|---|---|---|---|
| Total (MB) | 4,988.1 | 1,395.2 | 3,592.9 |
A pesar del evento de espera de lectura secuencial del archivo de base de datos que muestra una latencia mayor a 2,2 ms que en las pruebas SLOB2, este cliente vio una reducción de quince minutos en el tiempo de ejecución del trabajo procedente de una base de datos de RAC en Exadata a una base de datos de instancia única en Azure.
Limitaciones de recursos de Azure
Todos los sistemas finalmente alcanzaron las restricciones de recursos, conocidos tradicionalmente como puntos de ahogo. Las cargas de trabajo de base de datos, especialmente exigentes, como los conjuntos de aplicaciones de la cadena de suministro, son entidades que consumen muchos recursos. Encontrar estas restricciones de recursos y trabajar a través de ellos es fundamental para cualquier implementación correcta. En esta sección se iluminan varias restricciones que puede esperar encontrar en un entorno de este tipo y cómo trabajar a través de ellas. En cada subsección, espere aprender tanto los procedimientos recomendados como la lógica detrás de ellos.
Máquinas virtuales
En esta sección se detallan los criterios que se deben tener en cuenta en la selección de máquinas virtuales para obtener el mejor rendimiento y la justificación de las selecciones realizadas para realizar pruebas. Azure NetApp Files es un servicio de almacenamiento conectado a la red (NAS), por lo que el ajuste de tamaño adecuado del ancho de banda de red es fundamental para un rendimiento óptimo.
Chipsets
El primer tema de interés es la selección del conjunto de chips. Asegúrese de que la SKU de máquina virtual que seleccione se basa en un único conjunto de chips por motivos de coherencia. La variante Intel de E_v5 máquinas virtuales se ejecuta en una configuración de Intel Xeon Platinum 8370C (Ice Lake) de tercera generación. Todas las máquinas virtuales de esta familia están equipadas con una sola interfaz de red de 100 Gbps. En cambio, la serie E_v3, mencionada por ejemplo, se basa en cuatro conjuntos de chips independientes, con varios anchos de banda de red físicos. Los cuatro conjuntos de chips usados en la familia E_v3 (Broadwell, Skylake, Cascade Lake, Haswell) tienen diferentes velocidades de procesador, que afectan a las características de rendimiento de la máquina.
Lea la documentación de Azure Compute cuidadosamente prestando atención a las opciones del conjunto de chips. Consulte también los procedimientos recomendados de SKU de máquina virtual de Azure para Azure NetApp Files. La selección de una máquina virtual con un único conjunto de chips es preferible para mejorar la coherencia.
Ancho de banda de red disponible
Es importante comprender la diferencia entre el ancho de banda disponible de la interfaz de red de la máquina virtual y el ancho de banda medido aplicado en el mismo. Cuando la documentación de Azure Compute habla sobre los límites de ancho de banda de red, estos límites solo se aplican a la salida (escritura). El tráfico de entrada (lectura) no se mide y, como tal, solo está limitado por el ancho de banda físico de la propia tarjeta de interfaz de red (NIC). El ancho de banda de red de la mayoría de las máquinas virtuales supera el límite de salida aplicado a la máquina.
A medida que los volúmenes de Azure NetApp Files están conectados a la red, el límite de salida se puede entender como aplicado en escrituras específicamente, mientras que la entrada se define como cargas de trabajo de lectura y de lectura similar. Aunque el límite de salida de la mayoría de las máquinas es mayor que el ancho de banda de red de la NIC, no se puede decir lo mismo para el E104_v5 usado en las pruebas de este artículo. El E104_v5 tiene una NIC de 100 Gbps con el límite de salida establecido en 100 Gbps también. En comparación, el E96_v5, con su NIC de 100 Gbps tiene un límite de salida de 35 Gbps con entrada sin límite a 100 Gbps. A medida que las máquinas virtuales se reducen en el tamaño, los límites de salida disminuyen, pero la entrada sigue sin límites establecidos lógicamente.
Los límites de salida son de toda la máquina virtual y se aplican como tal en todas las cargas de trabajo basadas en red. Al usar Oracle Data Guard, todas las escrituras se duplican en los registros de archivo y se deben factorizar para las consideraciones de límite de salida. Esto también es cierto para el registro de archivo con varios destinos y RMAN, si se usa. Al seleccionar máquinas virtuales, familiarícese con herramientas de línea de comandos como ethtool, que exponen la configuración de la NIC, ya que Azure no documenta configuraciones de interfaz de red.
Simultaneidad de red
Las máquinas virtuales de Azure y los volúmenes de Azure NetApp Files incluyen cantidades específicas de ancho de banda. Como se ha mostrado anteriormente, siempre que una máquina virtual tenga suficiente espacio para la CPU, una carga de trabajo puede consumir en teoría el ancho de banda disponible para ella, que está dentro de los límites de la tarjeta de red o el límite de salida aplicados. Sin embargo, en la práctica, la cantidad de rendimiento que se puede lograr se basa en la simultaneidad de la carga de trabajo en la red, es decir, el número de flujos de red y puntos de conexión de red.
Lea la sección Límites de flujo de red del documento de ancho de banda de red de la máquina virtual para comprender mejor. La conclusión: cuantos más flujos de red conecten el cliente al almacenamiento, más rico será el rendimiento potencial.
Oracle admite dos clientes NFS independientes, NFS de kernel y NFS directo (dNFS). NfS de kernel, hasta tarde, admitía un único flujo de red entre dos puntos de conexión (proceso y almacenamiento). NFS directo, cuanto más eficaz sean los dos, admite un número variable de flujos de red: las pruebas han mostrado cientos de conexiones únicas por punto de conexión, lo que aumenta o disminuye a medida que las demandas de carga. Debido al escalado de flujos de red entre dos puntos de conexión, se prefiere Direct NFS por encima de NFS del kernel y, como tal, la configuración recomendada. El grupo de productos de Azure NetApp Files no recomienda usar KERNEL NFS con cargas de trabajo de Oracle. Para más información, consulte las ventajas del uso de Azure NetApp Files con Oracle Database.
Simultaneidad de ejecución
El uso de NFS directo, un único conjunto de chips para la coherencia y la comprensión de las restricciones de ancho de banda de red solo le lleva hasta ahora. Al final, la aplicación impulsa el rendimiento. Las pruebas de concepto que usan SLOB2 y las pruebas de concepto mediante un conjunto de aplicaciones de cadena de suministro real contra los datos reales del cliente solo pudieron impulsar grandes cantidades de rendimiento porque las aplicaciones se ejecutaron en altos grados de simultaneidad; el primero que usa un número significativo de subprocesos por esquema, el último con varias conexiones de varios servidores de aplicaciones. En resumen, la carga de trabajo de las unidades de simultaneidad, un bajo rendimiento de simultaneidad y alto rendimiento de alta simultaneidad, siempre y cuando la infraestructura esté disponible para admitir lo mismo.
Redes aceleradas
Accelerated Networking habilita la virtualización de E/S de raíz única (SR-IOV) en una máquina virtual (VM), lo que mejora significativamente su rendimiento en la red. Este método de alto rendimiento omite el host de la ruta de acceso de datos, lo que reduce la latencia, la inestabilidad y el uso de la CPU para las cargas de trabajo de red más exigentes en los tipos de VM admitidos. Al implementar máquinas virtuales a través de utilidades de administración de configuración como terraform o línea de comandos, tenga en cuenta que las redes aceleradas no están habilitadas de forma predeterminada. Para obtener un rendimiento óptimo, habilite las redes aceleradas. Tome nota de que las redes aceleradas están habilitadas o deshabilitadas en una interfaz de red por interfaz de red. La característica de red acelerada es una que se puede habilitar o deshabilitar dinámicamente.
Nota:
Este artículo contiene referencias al término SLAVE, un término que Microsoft ya no usa. Cuando se quite el término del software, se quitará también del artículo.
Un enfoque autoritativo para las redes aceleradas subsiguientes está habilitado para una NIC es a través del terminal Linux. Si las redes aceleradas están habilitadas para una NIC, hay una segunda NIC virtual asociada a la primera NIC. El sistema configura esta segunda NIC con la SLAVE marca habilitada. Si no hay ninguna NIC presente con la marca SLAVE, las redes aceleradas no están habilitadas para esa interfaz.
En el escenario en el que se configuran varias NIC, debe determinar qué SLAVE interfaz está asociada a la NIC que se usa para montar el volumen NFS. Agregar tarjetas de interfaz de red a la máquina virtual no tiene ningún efecto en el rendimiento.
Use el siguiente proceso para identificar la asignación entre la interfaz de red configurada y su interfaz virtual asociada. Este proceso valida que las redes aceleradas están habilitadas para una NIC específica en la máquina Linux y muestran la velocidad de entrada física que puede lograr la NIC.
- Ejecute el comando
ip a: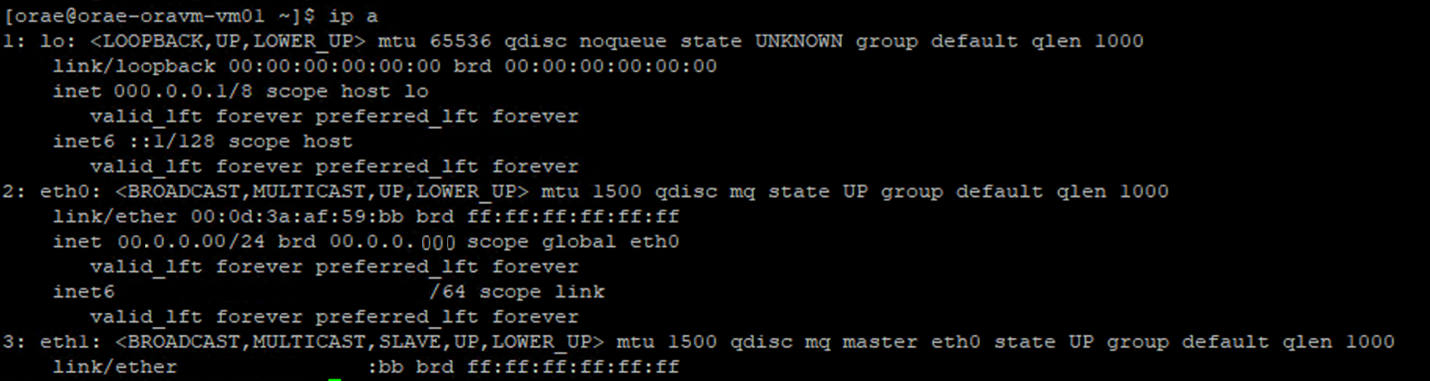
- Enumere el
/sys/class/net/directorio del identificador de NIC que está comprobando (eth0en el ejemplo) ygreppara la palabra inferior:ls /sys/class/net/eth0 | grep lower lower_eth1 - Ejecute el comando
ethtoolen el dispositivo Ethernet identificado como el dispositivo inferior en el paso anterior.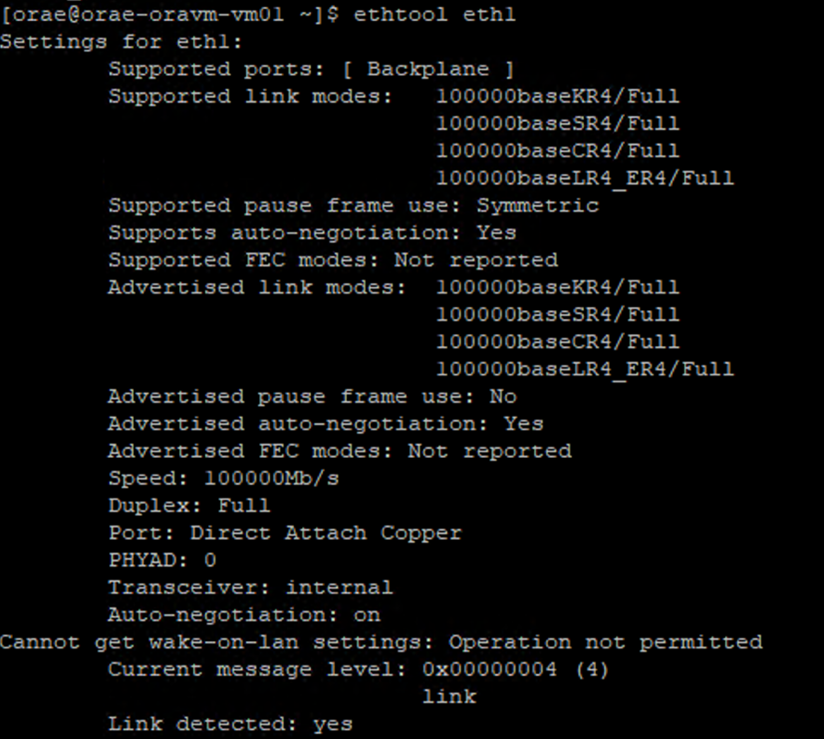
Máquina virtual de Azure: límites de ancho de banda de red frente a ancho de banda de disco
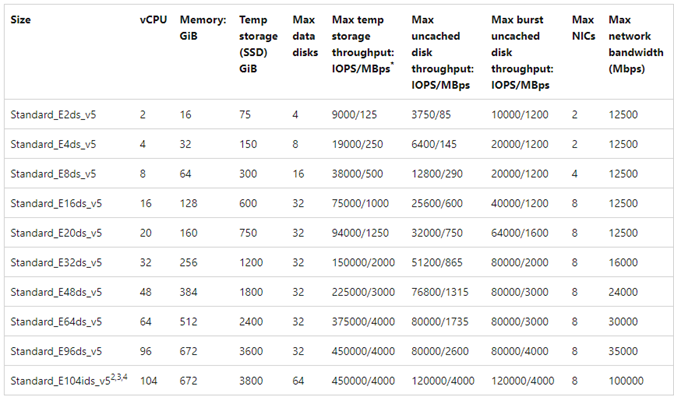
Se requiere un nivel de experiencia al leer la documentación sobre los límites de rendimiento de las máquinas virtuales de Azure. Tenga en cuenta lo siguiente:
- El rendimiento de almacenamiento temporal y los números de IOPS hacen referencia a las funcionalidades de rendimiento del almacenamiento en caja efímero conectado directamente a la máquina virtual.
- El rendimiento del disco sin almacenar en caché y los números de E/S hacen referencia específicamente a Azure Disk (Premium, Premium v2 y Ultra) y no tienen ningún efecto en el almacenamiento conectado a la red, como Azure NetApp Files.
- La asociación de NIC adicionales a la máquina virtual no afecta a los límites de rendimiento ni a las funcionalidades de rendimiento de la máquina virtual (documentadas y probadas para que sean verdaderas).
- El ancho de banda de red máximo hace referencia a los límites de salida (es decir, escribe cuando Azure NetApp Files está implicado) aplicado al ancho de banda de red de la máquina virtual. No se aplican límites de entrada (es decir, se lee cuando se aplica Azure NetApp Files). Dada suficiente CPU, suficiente simultaneidad de red y suficientes puntos de conexión enriquecidos, una máquina virtual podría impulsar teóricamente el tráfico de entrada a los límites de la NIC. Como se mencionó en la sección Ancho de banda de red disponible, use herramientas como
ethtoolpara ver el ancho de banda de la NIC.
Se muestra un gráfico de ejemplo como referencia:
Azure NetApp Files
El servicio de almacenamiento de primera entidad de Azure, Azure NetApp Files, proporciona una solución de almacenamiento totalmente administrada de alta disponibilidad capaz de admitir las exigentes cargas de trabajo de Oracle introducidas anteriormente.
A medida que se comprenden bien los límites del rendimiento del almacenamiento de escalado vertical en una base de datos de Oracle, este artículo se centra intencionadamente en el rendimiento del almacenamiento de escalabilidad horizontal. El escalado horizontal del rendimiento del almacenamiento implica proporcionar a una única instancia de Oracle acceso a muchos volúmenes de Azure NetApp Files en los que estos volúmenes se distribuyen a través de varios puntos de conexión de almacenamiento.
Al escalar una carga de trabajo de base de datos en varios volúmenes de tal manera, el rendimiento de la base de datos no está anclado a los límites superiores del volumen y del punto de conexión. Con el almacenamiento que ya no impone limitaciones de rendimiento, la arquitectura de máquina virtual (límites de salida de CPU, NIC y VM) se convierte en el punto de interrupción con el que competir. Como se indicó en la sección VM, se realizó la selección de las instancias de E104ids_v5 y E96ds_v5 teniendo esto en cuenta.
Si una base de datos se coloca en un único volumen de gran capacidad o se distribuye entre varios volúmenes más pequeños, el costo financiero total es el mismo. La ventaja de distribuir E/S entre varios volúmenes y puntos de conexión en contraste con un único volumen y un punto de conexión es la prevención de los límites de ancho de banda: se puede usar por completo lo que paga.
Importante
Para implementar mediante Azure NetApp Files en una configuración multiple volume:multiple endpoint, póngase en contacto con el especialista de Azure NetApp Files o el arquitecto de soluciones en la nube para obtener ayuda.
Base de datos
La versión 19c de la base de datos de Oracle es la versión de lanzamiento a largo plazo actual de Oracle y la que se usa para generar todos los resultados de las pruebas que se describen en este documento.
Para obtener el mejor rendimiento, todos los volúmenes de base de datos se montaron mediante el NFS Directo, se recomienda usar NFS de kernel debido a restricciones de rendimiento. Para obtener una comparación de rendimiento entre los dos clientes, consulte Rendimiento de la base de datos de Oracle en volúmenes únicos de Azure NetApp Files. Tenga en cuenta que se aplicaron todas las revisiones de dNFS pertinentes (id. de soporte técnico de Oracle 1495104), tal como se describen en el informe Bases de datos de Oracle en Microsoft Azure mediante Azure NetApp Files.
Aunque Oracle y Azure NetApp Files admiten NFSv3 y NFSv4.1, ya que NFSv3 es el protocolo más maduro, se ve generalmente como tener la mayor estabilidad y es la opción más confiable para los entornos que son altamente sensibles a la interrupción. Las pruebas descritas en este artículo se completaron en NFSv3.
Importante
Algunas de las revisiones recomendadas que documenta Oracle en el id. de soporte técnico 1495104 son fundamentales para mantener la integridad de los datos al usar dNFS. Se recomienda encarecidamente la aplicación de estas revisiones para entornos de producción.
La administración automática de almacenamiento (ASM) es compatible con volúmenes NFS. Aunque normalmente se asocia con el almacenamiento basado en bloques en el que ASM reemplaza la administración de volúmenes lógicos (LVM) y el sistema de archivos, ASM desempeña un papel valioso en escenarios NFS de varios volúmenes y merece una gran consideración. Una de estas ventajas de ASM, adición dinámica en línea y reequilibrio en volúmenes y puntos de conexión NFS recién agregados, simplifica la administración, lo que permite la expansión del rendimiento y la capacidad a voluntad. Aunque ASM no está en y por sí mismo aumenta el rendimiento de una base de datos, su uso evita archivos activos y la necesidad de mantener manualmente la distribución de archivos, una ventaja fácil de ver.
Se usó una configuración de ASM a través de dNFS para generar todos los resultados de pruebas descritos en este artículo. En el diagrama siguiente se muestra el diseño del archivo ASM dentro de los volúmenes de Azure NetApp Files y la asignación de archivos a los grupos de discos de ASM.

Existen algunas limitaciones con el uso de ASM a través de volúmenes montados NFS de Azure NetApp Files en lo que respecta a las instantáneas de almacenamiento que se pueden superar con ciertas consideraciones arquitectónicas. Póngase en contacto con el arquitecto de soluciones en la nube o especialista de Azure NetApp Files para obtener una revisión detallada de estas consideraciones.
Herramientas de prueba sintéticas y ajustables
En esta sección se describe la arquitectura de prueba, los ajustables y los detalles de configuración en detalles específicos. Aunque la sección anterior se centra en las razones por las que se toman decisiones de configuración, esta sección se centra específicamente en la "qué" de las decisiones de configuración.
Implementación automatizada
- Las máquinas virtuales de base de datos se implementan mediante scripts de Bash disponibles en GitHub.
- El diseño y la asignación de varios volúmenes y puntos de conexión de Azure NetApp Files se completan manualmente. Debe trabajar con el especialista de Azure NetApp Files o el arquitecto de soluciones en la nube para obtener ayuda.
- La instalación de la cuadrícula, la configuración de ASM, la creación y la configuración de la base de datos y el entorno SLOB2 en cada máquina se configura mediante Ansible para la coherencia.
- Las ejecuciones de prueba SLOB2 paralelas en varios hosts también se completan con Ansible para la coherencia y la ejecución simultánea.
Configuración de VM
| Configuración | Valor |
|---|---|
| Región de Azure | Oeste de Europa |
| SKU de la máquina virtual | E104ids_v5 |
| NIC (recuento) | 1 NOTA: Agregar vNICs no tiene ningún efecto en el recuento del sistema |
| Ancho de banda de red de salida máximo (Mbps) | 100 000 |
| GiB de almacenamiento temporal (SSD) | 3800 |
Configuración del sistema
Todas las opciones de configuración del sistema necesarias de Oracle para la versión 19c se implementaron según la documentación de Oracle.
Los parámetros siguientes se agregaron al archivo del sistema Linux /etc/sysctl.conf:
sunrpc.max_tcp_slot_table_entries: 128sunrpc.tcp_slot_table_entries = 128
Azure NetApp Files
Todos los volúmenes de Azure NetApp Files se montaron con las siguientes opciones de montaje NFS.
nfs rw,hard,rsize=262144,wsize=262144,sec=sys,vers=3,tcp
Parámetros de base de datos
| Parámetros | Valor |
|---|---|
db_cache_size |
2g |
large_pool_size |
2g |
pga_aggregate_target |
3G |
pga_aggregate_limit |
3G |
sga_target |
25g |
shared_io_pool_size |
500 m |
shared_pool_size |
5G |
db_files |
500 |
filesystemio_options |
SETALL |
job_queue_processes |
0 |
db_flash_cache_size |
0 |
_cursor_obsolete_threshold |
130 |
_db_block_prefetch_limit |
0 |
_db_block_prefetch_quota |
0 |
_db_file_noncontig_mblock_read_count |
0 |
Configuración de SLOB2
Toda la generación de cargas de trabajo para pruebas se completó mediante la versión 2.5.4 de la herramienta SLOB2.
Catorce esquemas SLOB2 se cargaron en un espacio de tablas estándar de Oracle y se ejecutaron en, que en combinación con los valores del archivo de configuración SLOB enumerados, colocaron el conjunto de datos SLOB2 en 7 TiB. La siguiente configuración refleja una ejecución de lectura aleatoria para SLOB2. El parámetro de configuración SCAN_PCT=0 se cambió a SCAN_PCT=100 durante las pruebas secuenciales.
UPDATE_PCT=0SCAN_PCT=0RUN_TIME=600SCALE=450GSCAN_TABLE_SZ=50GWORK_UNIT=32REDO_STRESS=LITETHREADS_PER_SCHEMA=1DATABASE_STATISTICS_TYPE=awr
En el caso de las pruebas de lectura aleatoria, se realizaron nueve ejecuciones SLOB2. El recuento de subprocesos se incrementó en seis con cada iteración de prueba a partir de una.
Para las pruebas secuenciales, se realizaron siete ejecuciones SLOB2. El número de subprocesos se ha aumentado en dos con cada iteración de prueba a partir de una. El número de subprocesos se limitó en seis debido a que alcanzó los límites máximos de ancho de banda de red.
Métricas de AWR
Todas las métricas de rendimiento se notificaron a través del repositorio de cargas de trabajo automáticas de Oracle (AWR). A continuación se muestran las métricas presentadas en los resultados:
- Rendimiento: la suma del rendimiento medio de lectura y el rendimiento de escritura de la sección Perfil de carga de AWR
- Promedio de solicitudes de E/S de lectura de la sección Perfil de carga de AWR
- db file secuencial read event average wait time from the AWR Foreground Wait Events section
Migración desde sistemas diseñados y diseñados específicamente a la nube
Oracle Exadata es un sistema diseñado, una combinación de hardware y software que se considera la solución más optimizada para ejecutar cargas de trabajo de Oracle. Aunque la nube tiene importantes ventajas en el esquema general del mundo técnico, estos sistemas especializados pueden parecer increíblemente atractivos para aquellos que han leído y visto las optimizaciones que Oracle ha creado en torno a sus cargas de trabajo concretas.
Cuando se trata de ejecutar Oracle en Exadata, hay algunas razones comunes por las que se elige Exadata:
- 1-2 cargas de trabajo de E/S elevadas que son naturales para las características de Exadata y, dado que estas cargas de trabajo requieren características importantes diseñadas de Exadata, el resto de las bases de datos que se ejecutan junto con ellas se consolidaron en Exadata.
- Las cargas de trabajo OLTP complicadas o difíciles que requieren RAC para escalar y son difíciles de diseñar con hardware propietario sin conocimientos profundos de optimización de Oracle o pueden ser deudas técnicas que no se pueden optimizar.
- Exadata existente infrautilizado con varias cargas de trabajo: esto existe debido a migraciones anteriores, final de vida en una Exadata anterior o debido a un deseo de trabajar o probar un Exadata interno.
Es esencial que cualquier migración desde un sistema Exadata se comprenda desde la perspectiva de las cargas de trabajo y lo simple o compleja que puede ser la migración. Una necesidad secundaria es comprender el motivo de la compra de Exadata desde una perspectiva de estado. Las aptitudes de Exadata y RAC están en mayor demanda y pueden haber impulsado la recomendación de comprar una por parte de las partes interesadas técnicas.
Importante
Independientemente del escenario, la migración general debe ser, para cualquier carga de trabajo de base de datos procedente de Exadata, más características propietarias de Exadata usadas, más compleja es la migración y el planeamiento. Los entornos que no usan en gran medida las características propietarias de Exadata tienen oportunidades para un proceso de migración y planeamiento más sencillo.
Hay varias herramientas que se pueden usar para evaluar estas oportunidades de carga de trabajo:
- El Repositorio automático de cargas de trabajo (AWR):
- Todas las bases de datos de Exadata tienen licencia para usar informes de AWR y características de rendimiento y diagnóstico conectadas.
- Siempre está activado y recopila datos que se pueden usar para ver la información histórica de la carga de trabajo y evaluar el uso. Los valores máximos pueden evaluar el uso elevado en el sistema,
- Los informes de AWR de ventana más grandes pueden evaluar la carga de trabajo general, lo que proporciona información valiosa sobre el uso de características y cómo migrar la carga de trabajo a Exadata de forma eficaz. Los informes de AWR máximos en contraste son los mejores para la optimización del rendimiento y la solución de problemas.
- El informe AWR global (RAC-Aware) de Exadata también incluye una sección específica de Exadata, que profundiza en el uso específico de características de Exadata y proporciona información valiosa de la memoria caché flash de información, el registro de flash, la E/S y otro uso de características por base de datos y nodo de celda.
Desacoplamiento de Exadata
Al identificar las cargas de trabajo de Oracle Exadata para migrar a la nube, tenga en cuenta las siguientes preguntas y puntos de datos:
- ¿La carga de trabajo consume varias características de Exadata, fuera de las ventajas de hardware?
- Exámenes inteligentes
- Índices de almacenamiento
- Caché flash
- Registro de Flash
- Compresión de columnas híbrida
- ¿La carga de trabajo usa la descarga de Exadata de forma eficaz? En el primer momento de los eventos en primer plano, cuál es la relación (más del 10 % del tiempo de base de datos) de la carga de trabajo mediante:
- Examen de tabla inteligente de celdas (óptimo)
- Lectura física multibloque de celdas (menos óptima)
- Lectura física de bloque único de celda (menos óptima)
- Compresión de columnas híbridas (HCC/EHCC): cuál es la relación comprimida frente a sin comprimir:
- ¿La base de datos pasa más del 10 % del tiempo de la base de datos al comprimir y descomprimir datos?
- Inspeccione las mejoras de rendimiento de los predicados mediante la compresión en las consultas: ¿el valor obtenido vale la pena frente a la cantidad guardada con compresión?
- E/S física de celda: inspeccione los ahorros proporcionados de:
- la cantidad dirigida al nodo de base de datos para equilibrar la CPU.
- identificando el número de bytes devueltos por el examen inteligente. Estos valores se pueden restar en E/S para el porcentaje de lecturas físicas de bloque único de celda una vez que migra Exadata.
- Anote el número de lecturas lógicas de la memoria caché. Determine si la memoria caché flash será necesaria en una solución iaaS en la nube para la carga de trabajo.
- Compare los bytes totales de lectura y escritura físicos con la cantidad realizada en la memoria caché. ¿Se puede aumentar la memoria para eliminar los requisitos de lectura físicos (es habitual que algunos reduzcan la SGA para forzar la descarga de Exadata)?
- En Estadísticas del sistema, identifique qué objetos se ven afectados por la estadística. Si optimiza SQL, la indexación adicional, la creación de particiones u otro ajuste físico pueden optimizar considerablemente la carga de trabajo.
- Inspeccione los parámetros de inicialización para los parámetros de subrayado (_) o en desuso, que deben justificarse debido al impacto en el nivel de base de datos que pueden estar causando el rendimiento.
Configuración del servidor Exadata
En la versión 12.2 y posteriores de Oracle, se incluirá una adición específica de Exadata en el informe global de AWR. Este informe tiene secciones que proporcionan un valor excepcional a una migración desde Exadata.
Detalles de la versión y del sistema de Exadata
Detalles de alertas del nodo de celda
Discos nononline de Exadata
Datos atípicos de las estadísticas del sistema operativo Exadata
Amarillo/rosa: de preocupación. Exadata no funciona de forma óptima.
Rojo: el rendimiento de Exadata se ve afectado significativamente.
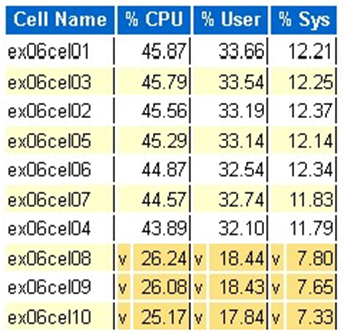
Estadísticas de CPU del sistema operativo Exadata: celdas superiores
- El sistema operativo recopila estas estadísticas en las celdas y no está restringida a esta base de datos o instancias
- Un
vfondo amarillo oscuro y un fondo amarillo oscuro indican un valor atípico por debajo del intervalo bajo - Un
^fondo amarillo claro y un fondo amarillo claro indican un valor atípico por encima del rango alto - Las celdas superiores por porcentaje de CPU se muestran y están en orden descendente de porcentaje de CPU
- Promedio: 39.34 % de CPU, 28.57 % de usuario, 10.77 % sys
Lecturas de bloque físico de una sola celda
Uso de caché flash
E/S temporal
Eficiencia de caché en columnas
Base de datos superior por rendimiento de E/S
Aunque se pueden realizar evaluaciones de ajuste de tamaño, hay algunas preguntas sobre los promedios y los picos simulados integrados en estos valores para cargas de trabajo de gran tamaño. Esta sección, que se encuentra al final de un informe de AWR, es excepcionalmente valiosa, ya que muestra el promedio de uso de memoria flash y disco de las 10 bases de datos principales de Exadata. Aunque muchos pueden suponer que quieren ajustar el tamaño de las bases de datos para obtener un rendimiento máximo en la nube, esto no tiene sentido para la mayoría de las implementaciones (más del 95 % está en el intervalo medio; con un pico simulado calculado en, el intervalo medio es mayor que el 98 %). Es importante pagar por lo que es necesario, incluso para las cargas de trabajo más altas de la demanda de Oracle e inspeccionar las principales bases de datos por rendimiento de E/S puede estar habilitada para comprender las necesidades de recursos de la base de datos.
Tamaño correcto de Oracle mediante AWR en Exadata
Al planear la capacidad de los sistemas locales, solo es natural tener una sobrecarga significativa integrada en el hardware. El hardware sobreaprovisionado debe atender la carga de trabajo de Oracle durante varios años, independientemente de las adiciones de cargas de trabajo debido al crecimiento de los datos, los cambios de código o las actualizaciones.
Una de las ventajas de la nube es escalar los recursos en un host de máquina virtual y el almacenamiento se puede realizar a medida que aumentan las demandas. Esto ayuda a conservar los costos de nube y los costos de licencia que están asociados al uso del procesador (pertinente con Oracle).
El ajuste de tamaño correcto implica quitar el hardware de la migración tradicional de lift-and-shift y usar la información de carga de trabajo proporcionada por el Repositorio automático de cargas de trabajo (AWR) de Oracle para elevar y desplazar la carga de trabajo al proceso y el almacenamiento que está especialmente diseñado para admitirlo en la nube de la elección del cliente. El proceso de ajuste de tamaño correcto garantiza que la arquitectura en el futuro quite la deuda técnica de infraestructura, la redundancia de arquitectura que se produciría si la duplicación del sistema local se replicase en la nube e implementa los servicios en la nube siempre que sea posible.
Los expertos en la materia de Oracle de Microsoft han estimado que más del 80 % de las bases de datos de Oracle están sobreaprovisionadas y experimentan el mismo costo o ahorro en la nube si tardan el tiempo en ajustar el tamaño adecuado de la carga de trabajo de la base de datos de Oracle antes de migrar a la nube. Esta evaluación requiere que los especialistas en bases de datos del equipo cambien su mentalidad sobre cómo pueden haber realizado el planeamiento de la capacidad en el pasado, pero vale la pena la inversión de las partes interesadas en la nube y la estrategia de nube de la empresa.
Pasos siguientes
- Ejecución de las cargas de trabajo de Oracle más exigentes en Azure sin sacrificar el rendimiento ni la escalabilidad
- Arquitecturas de las soluciones con Azure NetApp Files | Oracle
- Diseño e implementación de una base de datos de Oracle en Azure
- Herramienta de estimación para cambiar el tamaño de las cargas de trabajo de Oracle a máquinas virtuales IaaS de Azure
- Arquitecturas de referencia para Oracle Database Enterprise Edition en Azure
- Información sobre el grupo de volúmenes de aplicación de Azure NetApp Files para SAP HANA