Opciones de configuración: Application Insights de Azure Monitor para Java
En este artículo se muestra cómo configurar Application Insights de Azure Monitor para Java.
Para más información, consulte Introducción a OpenTelemetry, que incluye aplicaciones de muestra.
Cadena de conexión y nombre de rol
La cadena de conexión y el nombre de rol son las opciones de configuración más comunes que se necesitan para empezar:
{
"connectionString": "...",
"role": {
"name": "my cloud role name"
}
}
Se requiere la cadena de conexión. El nombre del rol es importante cada vez que se envían datos de diferentes aplicaciones al mismo recurso de Application Insights.
En las secciones siguientes se proporcionan más información y opciones de configuración.
Configuración de JSON
Configuración predeterminada
De forma predeterminada, Application Insights Java 3 espera que el archivo de configuración se denomine applicationinsights.json y que se encuentre en el mismo directorio que applicationinsights-agent-3.7.0.jar.
Configuraciones alternativas
Archivo de configuración personalizado
Puede especificar un archivo de configuración personalizado con
- la variable de entorno APPLICATIONINSIGHTS_CONFIGURATION_FILE o
- la propiedad applicationinsights.configuration.file system
Si proporciona una ruta de acceso relativa, se resolverá en relación con el directorio donde se encuentra applicationinsights-agent-3.7.0.jar.
Configuración de JSON
En lugar de usar un archivo de configuración, puede establecer la configuración JSON completa con:
- la variable de entorno APPLICATIONINSIGHTS_CONFIGURATION_CONTENT o
- la propiedad applicationinsights.configuration.content system
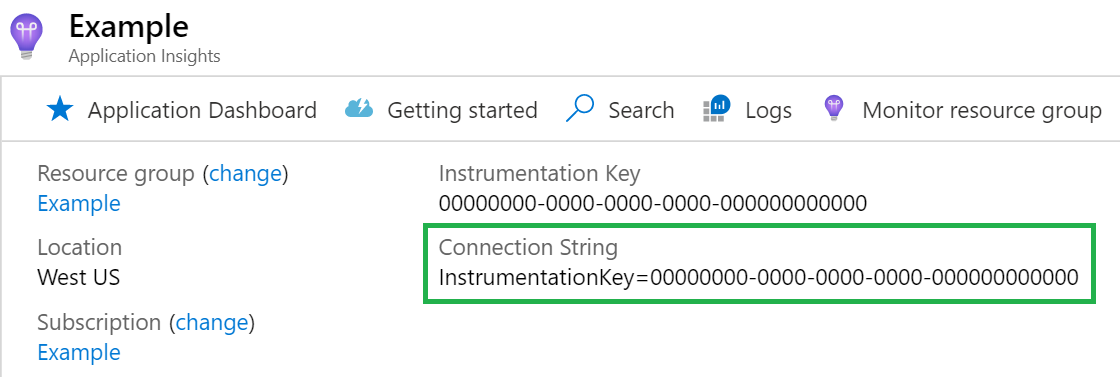
Cadena de conexión
Se requiere la cadena de conexión. Puede encontrar la cadena de conexión en el recurso de Application Insights.
{
"connectionString": "..."
}
También puede establecer la cadena de conexión mediante la variable de entorno APPLICATIONINSIGHTS_CONNECTION_STRING. Así, tiene prioridad sobre la cadena de conexión especificada en la configuración JSON.
O bien, puede establecer la cadena de conexión mediante la propiedad del sistema applicationinsights.connection.string Java. También tiene prioridad sobre la cadena de conexión especificada en la configuración JSON.
También puede establecer la cadena de conexión especificando un archivo desde donde cargar la cadena de conexión.
Si especifica una ruta de acceso relativa, se resuelve de forma relativa en el directorio en el que se encuentra applicationinsights-agent-3.7.0.jar.
{
"connectionString": "${file:connection-string-file.txt}"
}
El archivo solo debe contener la cadena de conexión y nada más.
Si no se establece la cadena de conexión, se deshabilita el agente de Java.
Si tiene varias aplicaciones implementadas en la misma máquina virtual Java (JVM) y quiere que envíen telemetría a cadenas de conexión diferentes, consulte Invalidaciones de cadena de conexión (versión preliminar).
Nombre del rol en la nube
Este se usa para etiquetar el componente en el mapa de aplicación.
Si quiere establecer el nombre del rol de nube, haga lo siguiente:
{
"role": {
"name": "my cloud role name"
}
}
Si no se establece el nombre del rol en la nube, se usará el nombre del recurso de Application Insights para etiquetar el componente en el mapa de aplicación.
También puede establecer el nombre de rol en la nube mediante la variable de entorno APPLICATIONINSIGHTS_ROLE_NAME. Así, tiene prioridad sobre el nombre del rol en la nube especificado en la configuración JSON.
O bien, puede establecer el nombre del rol en la nube mediante la propiedad applicationinsights.role.name del sistema Java. También tiene prioridad sobre el nombre del rol en la nube especificado en la configuración JSON.
Si tiene varias aplicaciones implementadas en la misma JVM y quiere que envíen telemetría a nombres de rol en la nube diferentes, consulte Invalidaciones de nombre de rol en la nube (versión preliminar).
Instancia de rol en la nube
La instancia de rol de la nube tiene como valor predeterminado el nombre del equipo.
Si quiere establecer la instancia de rol de nube en un valor diferente en lugar del nombre del equipo, use lo siguiente:
{
"role": {
"name": "my cloud role name",
"instance": "my cloud role instance"
}
}
También puede establecer la instancia de rol en la nube mediante la variable de entorno APPLICATIONINSIGHTS_ROLE_INSTANCE. Así, tiene prioridad sobre la instancia del rol en la nube especificada en la configuración JSON.
O bien, puede establecer la instancia de rol en la nube mediante la propiedad applicationinsights.role.instance del sistema Java.
También tiene prioridad sobre la instancia de rol en la nube especificada en la configuración JSON.
muestreo
Nota:
El muestreo puede ser una excelente manera de reducir el costo de Application Insights. Asegúrese de configurar el muestreo correctamente para su caso de uso.
El muestreo se basa en la solicitud, lo que significa que si se captura (muestrea) una solicitud, también lo son sus dependencias, registros y excepciones.
Además, el muestreo se basa en el identificador de seguimiento para que pueda tomar decisiones de muestreo coherentes en diferentes servicios.
El muestreo solo se aplica a los registros dentro de una solicitud. Los registros que no están dentro de una solicitud (por ejemplo, los registros de inicio) siempre se recopilan de manera predeterminada. Si desea muestrear esos registros, puede usar las invalidaciones de muestreo.
Muestreo de velocidad limitada
A partir de la versión 3.4.0, el muestreo de velocidad limitada está disponible y ahora es el método predeterminado.
Si no se ha configurado ningún muestreo, el método predeterminado es el muestreo de velocidad limitada que se ha configurado para capturar como máximo cinco solicitudes por segundo (aproximadamente), junto con todas las dependencias y los registros de esas solicitudes.
Esta configuración reemplaza al método predeterminado anterior, que era capturar todas las solicitudes. Si quiere capturar todas las solicitudes, use el muestreo de porcentaje fijo y establezca el porcentaje de muestreo en 100.
Nota
El muestreo de velocidad limitada es aproximado, ya que internamente debe adaptar un porcentaje de muestreo "fijo" a lo largo del tiempo para emitir recuentos precisos de elementos en cada registro de telemetría. Internamente, el muestreo limitado de velocidad se ajusta para adaptarse rápidamente (0,1 segundos) a nuevas cargas de aplicación. Por este motivo, no debería ver que supera la tasa configurada por mucho, o por mucho tiempo.
Este ejemplo muestra cómo puede establecer el muestreo para capturar, como máximo, una solicitud por segundo (aproximadamente):
{
"sampling": {
"requestsPerSecond": 1.0
}
}
El requestsPerSecond puede ser un decimal, por lo que puede configurarlo para capturar menos de una solicitud por segundo si lo desea. Por ejemplo, un valor de 0.5 significa capturar como máximo una solicitud cada dos segundos.
También puede establecer el porcentaje de muestreo mediante la variable de entorno APPLICATIONINSIGHTS_SAMPLING_REQUESTS_PER_SECOND. Así, tiene prioridad sobre el límite de velocidad especificado en la configuración JSON.
Muestreo de porcentaje fijo
En este ejemplo se muestra cómo establecer el muestreo para capturar aproximadamente un tercio de todas las solicitudes:
{
"sampling": {
"percentage": 33.333
}
}
También puede establecer el porcentaje de muestreo mediante la variable de entorno APPLICATIONINSIGHTS_SAMPLING_PERCENTAGE. Así, tiene prioridad sobre el porcentaje de muestreo especificado en la configuración JSON.
Nota
Para el porcentaje de muestreo, elija un porcentaje que esté cerca de 100/N, donde N es un número entero. Actualmente el muestreo no es compatible con otros valores.
Invalidaciones de muestreo
Las invalidaciones de muestreo permiten invalidar el porcentaje de muestreo predeterminado. Por ejemplo, puede:
- Establezca el porcentaje de muestreo en cero (o algún valor pequeño) para las comprobaciones de estado irrelevantes.
- Establezca el porcentaje de muestreo en cero (o algún valor pequeño) para las llamadas de dependencia irrelevantes.
- Establezca el porcentaje de muestreo en 100 para un tipo de solicitud importante. Por ejemplo, puede usar
/loginaunque tenga el muestreo predeterminado configurado en algún valor más bajo.
Para obtener más información, consulte la documentación sobre invalidaciones de muestreos.
Métricas de extensiones de administración de Java
Si desea recopilar otras métricas de Java Management Extensions (JMX):
{
"jmxMetrics": [
{
"name": "JVM uptime (millis)",
"objectName": "java.lang:type=Runtime",
"attribute": "Uptime"
},
{
"name": "MetaSpace Used",
"objectName": "java.lang:type=MemoryPool,name=Metaspace",
"attribute": "Usage.used"
}
]
}
En el ejemplo de configuración anterior:
-
namees el nombre de la métrica que se asigna a esta métrica de JMX (puede ser cualquier nombre). -
objectNamees el nombre de objeto delJMX MBeanque desea recopilar. Se admite el asterisco de caracteres comodín (*). -
attributees el atributo de nombre dentro delJMX MBeanque desea recopilar.
Se admiten los valores de métrica JMX numéricos y booleanos. Las métricas JMX booleanas se asignan a 0 para false y 1 para true.
Para obtener más información, consulte la documentación Métricas de JMX.
Dimensiones personalizadas
Si desea agregar dimensiones personalizadas a toda la telemetría:
{
"customDimensions": {
"mytag": "my value",
"anothertag": "${ANOTHER_VALUE}"
}
}
${...} se puede usar para leer el valor de la variable de entorno especificada en el inicio.
Nota
A partir de la versión 3.0.2, si agrega una dimensión personalizada denominada service.version, el valor se almacena en la columna application_Version de la tabla de registros de Application Insights en lugar de como una dimensión personalizada.
Atributo heredado (versión preliminar)
A partir de la versión 3.2.0, puede establecer una dimensión personalizada mediante programación en la telemetría de solicitud. Garantiza la herencia por dependencia y telemetría de registro. Todos se capturan en el contexto de esa solicitud.
{
"preview": {
"inheritedAttributes": [
{
"key": "mycustomer",
"type": "string"
}
]
}
}
Y, a continuación, al principio de cada solicitud, llame a:
Span.current().setAttribute("mycustomer", "xyz");
Consulte también: Adición de una propiedad personalizada a un intervalo.
Invalidaciones de la cadena de conexión (versión preliminar)
Esta característica se encuentra en versión preliminar desde la versión 3.4.0.
Las invalidaciones de cadena de conexión permiten invalidar la cadena de conexión predeterminada. Por ejemplo, puede:
- Establezca una cadena de conexión para un prefijo de ruta de acceso HTTP
/myapp1. - Establezca otra cadena de conexión para otro prefijo de ruta de acceso HTTP
/myapp2/.
{
"preview": {
"connectionStringOverrides": [
{
"httpPathPrefix": "/myapp1",
"connectionString": "..."
},
{
"httpPathPrefix": "/myapp2",
"connectionString": "..."
}
]
}
}
Invalidaciones de nombre de rol en la nube (versión preliminar)
Esta característica se encuentra en versión preliminar desde la versión 3.3.0.
Las invalidaciones de nombre de rol en la nube permiten invalidar el nombre de rol en la nube predeterminado. Por ejemplo, puede:
- Establezca un nombre de rol en la nube para un prefijo de ruta de acceso HTTP
/myapp1. - Establezca otro nombre de rol en la nube para otro prefijo de ruta de acceso HTTP
/myapp2/.
{
"preview": {
"roleNameOverrides": [
{
"httpPathPrefix": "/myapp1",
"roleName": "Role A"
},
{
"httpPathPrefix": "/myapp2",
"roleName": "Role B"
}
]
}
}
Cadena de conexión configurada en el tiempo de ejecución
A partir de la versión 3.4.8, si necesita la capacidad de configurar la cadena de conexión en el tiempo de ejecución, agregue esta propiedad a la configuración json:
{
"connectionStringConfiguredAtRuntime": true
}
Agregue applicationinsights-core a la aplicación:
<dependency>
<groupId>com.microsoft.azure</groupId>
<artifactId>applicationinsights-core</artifactId>
<version>3.7.0</version>
</dependency>
Use el método de configure(String) estático en la clase com.microsoft.applicationinsights.connectionstring.ConnectionString.
Nota:
Cualquier telemetría que se capture antes de configurar la cadena de conexión se anulará, por lo que es mejor configurarla lo antes posible en el startup de la aplicación.
Colección automática de dependencias InProc (versión preliminar)
A partir de la versión 3.2.0, si desea capturar las dependencias "InProc" del controlador, use la configuración siguiente:
{
"preview": {
"captureControllerSpans": true
}
}
Cargador del SDK del explorador (versión preliminar)
Esta característica inserta automáticamente el cargador del SDK del explorador en las páginas HTML de la aplicación, incluida la configuración de la cadena de conexión adecuada.
Por ejemplo, cuando la aplicación java devuelve una respuesta como la siguiente:
<!DOCTYPE html>
<html lang="en">
<head>
<title>Title</title>
</head>
<body>
</body>
</html>
Modifica automáticamente para devolver:
<!DOCTYPE html>
<html lang="en">
<head>
<script type="text/javascript">
!function(v,y,T){var S=v.location,k="script"
<!-- Removed for brevity -->
connectionString: "YOUR_CONNECTION_STRING"
<!-- Removed for brevity --> }});
</script>
<title>Title</title>
</head>
<body>
</body>
</html>
El script tiene como objetivo ayudar a los clientes a realizar un seguimiento de los datos de usuario web y enviar la telemetría del lado servidor de vuelta a Azure Portal de los usuarios. Puede encontrar detalles en ApplicationInsights-JS.
Si quiere habilitar esta característica, agregue la siguiente opción de configuración:
{
"preview": {
"browserSdkLoader": {
"enabled": true
}
}
}
Procesadores de telemetría (versión preliminar)
Puede usar procesadores de telemetría para reglas que se aplican a la telemetría de solicitudes, dependencias y seguimientos. Por ejemplo, puede:
- Máscara de datos confidenciales.
- Adición de dimensiones personalizadas condicionalmente
- Actualizar el nombre del intervalo, que se usa para agregar telemetría similar en Azure Portal
- Anulación de atributos de intervalo específicos para controlar los costos de ingesta.
Para obtener más información, consulte la documentación del procesador de telemetría.
Nota
Si quiere anular intervalos específicos (completos) para controlar el costo de la ingesta, consulte las invalidaciones de muestreo.
Instrumentación personalizada (versión preliminar)
A partir de la versión 3.3.1, puede capturar intervalos para un método en la aplicación:
{
"preview": {
"customInstrumentation": [
{
"className": "my.package.MyClass",
"methodName": "myMethod"
}
]
}
}
Deshabilitación local del muestreo de ingesta (versión preliminar)
De manera predeterminada, cuando el porcentaje de muestreo efectivo del agente de Java es del 100 % y el muestreo de ingesta se ha configurado en el recurso de Application Insights, se aplicará el porcentaje de muestreo de ingesta.
Tenga en cuenta que este comportamiento se aplica al muestreo de frecuencia fijo del 100 % y también se aplica al muestreo limitado por frecuencia cuando la frecuencia de solicitud no supera el límite de frecuencia (y se captura de manera eficaz el 100 % durante la ventana de tiempo deslizante continuamente).
A partir de la versión 3.5.3, puede deshabilitar este comportamiento (y mantener el 100 % de telemetría en estos casos incluso cuando se ha configurado el muestreo de ingesta en el recurso de Application Insights):
{
"preview": {
"sampling": {
"ingestionSamplingEnabled": false
}
}
}
Registros recopilados automáticamente
Log4j, Logback, JBoss Logging y java.util.logging se instrumentan automáticamente. El registro realizado a través de estas plataformas de registro se recoge automáticamente.
El registro solo se captura si:
- Cumple el nivel configurado para la plataforma de registro.
- También cumple el nivel configurado para Application Insights.
Por ejemplo, si el marco de registro está configurado para registrar WARN (y lo configuró como se ha descrito anteriormente) del paquete com.exampley Application Insights está configurado para capturar INFO (y se configuró tal como se describe), Application Insights solo captura WARN (y más graves) del paquete com.example.
El nivel predeterminado configurado para Application Insights es INFO. Si quiere cambiar este nivel:
{
"instrumentation": {
"logging": {
"level": "WARN"
}
}
}
También puede establecer el nivel mediante la variable de entorno APPLICATIONINSIGHTS_INSTRUMENTATION_LOGGING_LEVEL. Así, tiene prioridad sobre el nivel especificado en la configuración JSON.
Puede usar estos valores level válidos para especificar en el archivo applicationinsights.json. En la tabla se muestra cómo se corresponden con los niveles de registro en diferentes plataformas de registro.
| Nivel | Log4j | Logback | JBoss | JUL |
|---|---|---|---|---|
| Apagado | Apagado | Apagado | Apagado | Apagado |
| FATAL | FATAL | ERROR | FATAL | SEVERE |
| ERROR (o SEVERE) | ERROR | ERROR | ERROR | SEVERE |
| WARN (o WARNING) | WARN | WARN | WARN | WARNING |
| INFO | INFO | INFO | INFO | INFO |
| CONFIG | DEBUG | DEBUG | DEBUG | CONFIG |
| DEBUG (o FINE) | DEBUG | DEBUG | DEBUG | FINE |
| FINER | DEBUG | DEBUG | DEBUG | FINER |
| TRACE (o FINEST) | TRACE | TRACE | TRACE | FINEST |
| ALL | ALL | ALL | ALL | ALL |
Nota
Si se pasa un objeto de excepción al registrador, el mensaje de registro (y los detalles del objeto de excepción) se mostrarán en Azure Portal en la tabla exceptions, en lugar de en la tabla traces. Si quiere ver los mensajes de registro en las tablas traces y exceptions, puede escribir una consulta de registros (Kusto) para unirlos. Por ejemplo:
union traces, (exceptions | extend message = outerMessage)
| project timestamp, message, itemType
Marcadores de registro (versión preliminar)
A partir de la versión 3.4.2, puede capturar los marcadores de registro para Logback y Log4j 2:
{
"preview": {
"captureLogbackMarker": true,
"captureLog4jMarker": true
}
}
Otros atributos de registro para Logback (versión preliminar)
A partir de la versión 3.4.3, puede capturar FileName, ClassName, MethodName y LineNumber, para Logback:
{
"preview": {
"captureLogbackCodeAttributes": true
}
}
Advertencia
La captura de atributos de código podría agregar una sobrecarga de rendimiento.
Nivel de registro como una dimensión personalizada
A partir de la versión 3.3.0, LoggingLevel no se captura de manera predeterminada como parte de la dimensión personalizada de seguimientos, puesto que esos datos ya están capturados en el campo SeverityLevel.
Si es necesario, puede volver a habilitar temporalmente el comportamiento anterior:
{
"preview": {
"captureLoggingLevelAsCustomDimension": true
}
}
Métricas de Micrometer recopiladas automáticamente (incluidas las métricas del accionador de Spring Boot)
Si la aplicación usa Micrometer, las métricas que se envían al registro global de Micrometer se recopilan automáticamente.
Además, si la aplicación usa el accionador de Spring Boot, las métricas configuradas por dicho accionador también se recopilan automáticamente.
Para enviar métricas personalizadas mediante el micrómetro:
Agregue Micrometer a la aplicación como se muestra en el ejemplo siguiente.
<dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-core</artifactId> <version>1.6.1</version> </dependency>Use el Registro global de Micrometer para crear un medidor como se muestra en el ejemplo siguiente.
static final Counter counter = Metrics.counter("test.counter");Use el contador para registrar métricas mediante el comando siguiente.
counter.increment();Las métricas se ingieren en la tabla customMetrics, con etiquetas capturadas en la columna
customDimensions. También puede ver las métricas en el Explorador de métricas, en el espacio de nombres de métricasLog-based metrics.Nota
Java de Application Insights reemplaza todos los caracteres no alfanuméricos (excepto guiones) en el nombre de la métrica Micrometer por guiones bajos. Como resultado, la métrica
test.counteranterior se mostrará comotest_counter.
Para deshabilitar la recopilación automática de métricas de Micrometer y del accionador de Spring Boot:
Nota
Las métricas personalizadas se facturan por separado y pueden generar costos adicionales. Asegúrese de consultar la información sobre los precios. Para deshabilitar las métricas de Micrometer y del accionador de Spring Boot, agregue la siguiente configuración al archivo de configuración.
{
"instrumentation": {
"micrometer": {
"enabled": false
}
}
}
Enmascaramiento de consultas de conectividad de bases de datos de Java
Los valores literales de las consultas de conectividad a bases de datos Java (JDBC) se enmascaran de forma predeterminada para evitar capturar accidentalmente datos confidenciales.
A partir de la versión 3.4.0, este comportamiento se puede deshabilitar. Por ejemplo:
{
"instrumentation": {
"jdbc": {
"masking": {
"enabled": false
}
}
}
}
Enmascaramiento de consultas de Mongo
Los valores literales de las consultas Mongo se enmascaran de forma predeterminada para evitar la captura accidental de datos confidenciales.
A partir de la versión 3.4.0, este comportamiento se puede deshabilitar. Por ejemplo:
{
"instrumentation": {
"mongo": {
"masking": {
"enabled": false
}
}
}
}
Encabezados HTTP
A partir de la versión 3.3.0 puede capturar los encabezados de solicitudes y respuestas de los datos de telemetría del servidor (solicitud):
{
"preview": {
"captureHttpServerHeaders": {
"requestHeaders": [
"My-Header-A"
],
"responseHeaders": [
"My-Header-B"
]
}
}
}
Las nombres de encabezado no distinguen mayúsculas de minúsculas.
Los ejemplos anteriores se capturan en los nombres de propiedad http.request.header.my_header_a y http.response.header.my_header_b.
Del mismo modo, puede capturar encabezados de solicitud y respuesta en la telemetría del cliente (dependencia):
{
"preview": {
"captureHttpClientHeaders": {
"requestHeaders": [
"My-Header-C"
],
"responseHeaders": [
"My-Header-D"
]
}
}
}
De nuevo, los nombres de encabezado no distinguen mayúsculas de minúsculas. Los ejemplos anteriores se capturan en los nombres de propiedad http.request.header.my_header_c y http.response.header.my_header_d.
Códigos de respuesta 4xx del servidor HTTP
De forma predeterminada, las solicitudes de servidor HTTP que producen códigos de respuesta 4xx se capturan como errores.
A partir de la versión 3.3.0, puede cambiar este comportamiento para capturarlas como correctas:
{
"preview": {
"captureHttpServer4xxAsError": false
}
}
Supresión de la telemetría específica recopilada automáticamente
A partir de la versión 3.0.3, se puede suprimir la telemetría específica recopilada automáticamente mediante estas opciones de configuración:
{
"instrumentation": {
"azureSdk": {
"enabled": false
},
"cassandra": {
"enabled": false
},
"jdbc": {
"enabled": false
},
"jms": {
"enabled": false
},
"kafka": {
"enabled": false
},
"logging": {
"enabled": false
},
"micrometer": {
"enabled": false
},
"mongo": {
"enabled": false
},
"quartz": {
"enabled": false
},
"rabbitmq": {
"enabled": false
},
"redis": {
"enabled": false
},
"springScheduling": {
"enabled": false
}
}
}
También puede suprimir estas instrumentaciones estableciendo estas variables de entorno en false:
APPLICATIONINSIGHTS_INSTRUMENTATION_AZURE_SDK_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_CASSANDRA_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_JDBC_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_JMS_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_KAFKA_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_LOGGING_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_MICROMETER_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_MONGO_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_RABBITMQ_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_REDIS_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_SPRING_SCHEDULING_ENABLED
Estas variables tienen prioridad sobre las variables habilitadas especificadas en la configuración JSON.
Nota
Si busca un control más pormenorizado; por ejemplo, para suprimir algunas llamadas de Redis, pero no todas, consulte las invalidaciones de muestreos.
Instrumentaciones de la versión preliminar
A partir de la versión 3.2.0, puede habilitar las siguientes instrumentaciones de versión preliminar:
{
"preview": {
"instrumentation": {
"akka": {
"enabled": true
},
"apacheCamel": {
"enabled": true
},
"grizzly": {
"enabled": true
},
"ktor": {
"enabled": true
},
"play": {
"enabled": true
},
"r2dbc": {
"enabled": true
},
"springIntegration": {
"enabled": true
},
"vertx": {
"enabled": true
}
}
}
}
Nota
La instrumentación de Akka está disponible a partir de la versión 3.2.2. La instrumentación de la biblioteca HTTP de Vertx está disponible a partir de la versión 3.3.0.
Intervalo de métrica
De forma predeterminada, las métricas se capturan cada 60 segundos.
A partir de la versión 3.0.3, puede cambiar este intervalo:
{
"metricIntervalSeconds": 300
}
A partir de la versión de disponibilidad general 3.4.9, también puede establecer el objeto metricIntervalSeconds mediante la variable de entorno APPLICATIONINSIGHTS_METRIC_INTERVAL_SECONDS. Así, tiene prioridad sobre el objeto metricIntervalSeconds especificado en la configuración JSON.
La configuración se aplica a las métricas siguientes:
- Contadores de rendimiento predeterminados: por ejemplo, CPU y memoria.
- Métricas personalizadas predeterminadas: por ejemplo, tiempo de recolección de elementos no utilizados.
- Métricas de JMX configuradas: consulte la sección de métrica de JMX.
- Métricas de Micrometer: consulte la sección Métricas de Micrometer recopiladas automáticamente
Latido
De forma predeterminada, Application Insights Java 3.x envía una métrica de latido cada 15 minutos. Si está usando la métrica de latido para desencadenar las alertas, puede aumentar la frecuencia de este latido:
{
"heartbeat": {
"intervalSeconds": 60
}
}
Nota
No se puede aumentar el intervalo a más de 15 minutos, porque los datos de latido también se usan para hacer un seguimiento del uso de Application Insights.
Autenticación
Nota:
La característica de autenticación tiene disponibilidad general desde la versión 3.4.17.
Puede usar la autenticación para configurar el agente para generar las credenciales de token necesarias para la autenticación de Microsoft Entra. Para obtener más información, vea la documentación de Autenticación.
Proxy HTTP
Si su aplicación está protegida por un firewall y no puede conectarse directamente a Application Insights, consulte Direcciones IP que emplea Application Insights.
Para solucionar este problema, puede configurar Application Insights Java 3.x para usar un proxy HTTP.
{
"proxy": {
"host": "myproxy",
"port": 8080
}
}
También puede establecer el proxy http mediante la variable de entorno APPLICATIONINSIGHTS_PROXY, que toma el formato https://<host>:<port>. Así, tiene prioridad sobre el proxy especificado en la configuración JSON.
Puede proporcionar un usuario y una contraseña para el proxy con la variable de entorno APPLICATIONINSIGHTS_PROXY : https://<user>:<password>@<host>:<port>.
Application Insights Java 3.x también respeta las propiedades del sistema https.proxyHost y https.proxyPort globales si se establecen (y http.nonProxyHosts si fuera necesario).
Recuperación de errores de ingesta
Cuando se produce un error en el envío de telemetría al servicio Application Insights, Application Insights Java 3.x almacena la telemetría en el disco y sigue reintentando desde el disco.
El límite predeterminado de la persistencia de disco es de 50 Mb. Si tiene un volumen elevado de telemetría o necesita poder recuperarse de interrupciones de servicio de ingesta o red más largas, puede aumentar este límite a partir de la versión 3.3.0:
{
"preview": {
"diskPersistenceMaxSizeMb": 50
}
}
Diagnóstico automático
"Diagnóstico automático" hace referencia al registro interno de Application Insights Java 3.x. Esta funcionalidad puede ser útil para detectar y diagnosticar problemas con Application Insights.
De forma predeterminada, Application Insights Java 3.x registra en el nivel INFO tanto en el archivo applicationinsights.log como en la consola, que se corresponde con esta configuración:
{
"selfDiagnostics": {
"destination": "file+console",
"level": "INFO",
"file": {
"path": "applicationinsights.log",
"maxSizeMb": 5,
"maxHistory": 1
}
}
}
En el ejemplo de configuración anterior:
-
levelpuede ser uno deOFF,ERROR,WARN,INFO,DEBUGoTRACE. -
pathincluye una ruta de acceso absoluta o relativa. Las rutas de acceso relativas se resuelven en el directorio donde se encuentraapplicationinsights-agent-3.7.0.jar.
A partir de la versión 3.0.2, también puede establecer la opción level de autodiagnóstico mediante la variable de entorno APPLICATIONINSIGHTS_SELF_DIAGNOSTICS_LEVEL. Así, tiene prioridad sobre el nivel especificado de autodiagnóstico en la configuración JSON.
A partir de la versión 3.0.3, también puede establecer la ubicación del archivo de autodiagnóstico mediante la variable de entorno APPLICATIONINSIGHTS_SELF_DIAGNOSTICS_FILE_PATH. Así, tiene prioridad sobre el archivo de autodiagnóstico especificado en la configuración JSON.
Correlación de telemetría
La correlación de telemetría está habilitada de forma predeterminada, pero puede deshabilitarla en la configuración.
{
"preview": {
"disablePropagation": true
}
}
Un ejemplo
Este ejemplo muestra el aspecto de un archivo de configuración con varios componentes. Configure opciones específicas en función de sus necesidades.
{
"connectionString": "...",
"role": {
"name": "my cloud role name"
},
"sampling": {
"percentage": 100
},
"jmxMetrics": [
],
"customDimensions": {
},
"instrumentation": {
"logging": {
"level": "INFO"
},
"micrometer": {
"enabled": true
}
},
"proxy": {
},
"preview": {
"processors": [
]
},
"selfDiagnostics": {
"destination": "file+console",
"level": "INFO",
"file": {
"path": "applicationinsights.log",
"maxSizeMb": 5,
"maxHistory": 1
}
}
}