Tutorial: Pruebas de validación automatizadas
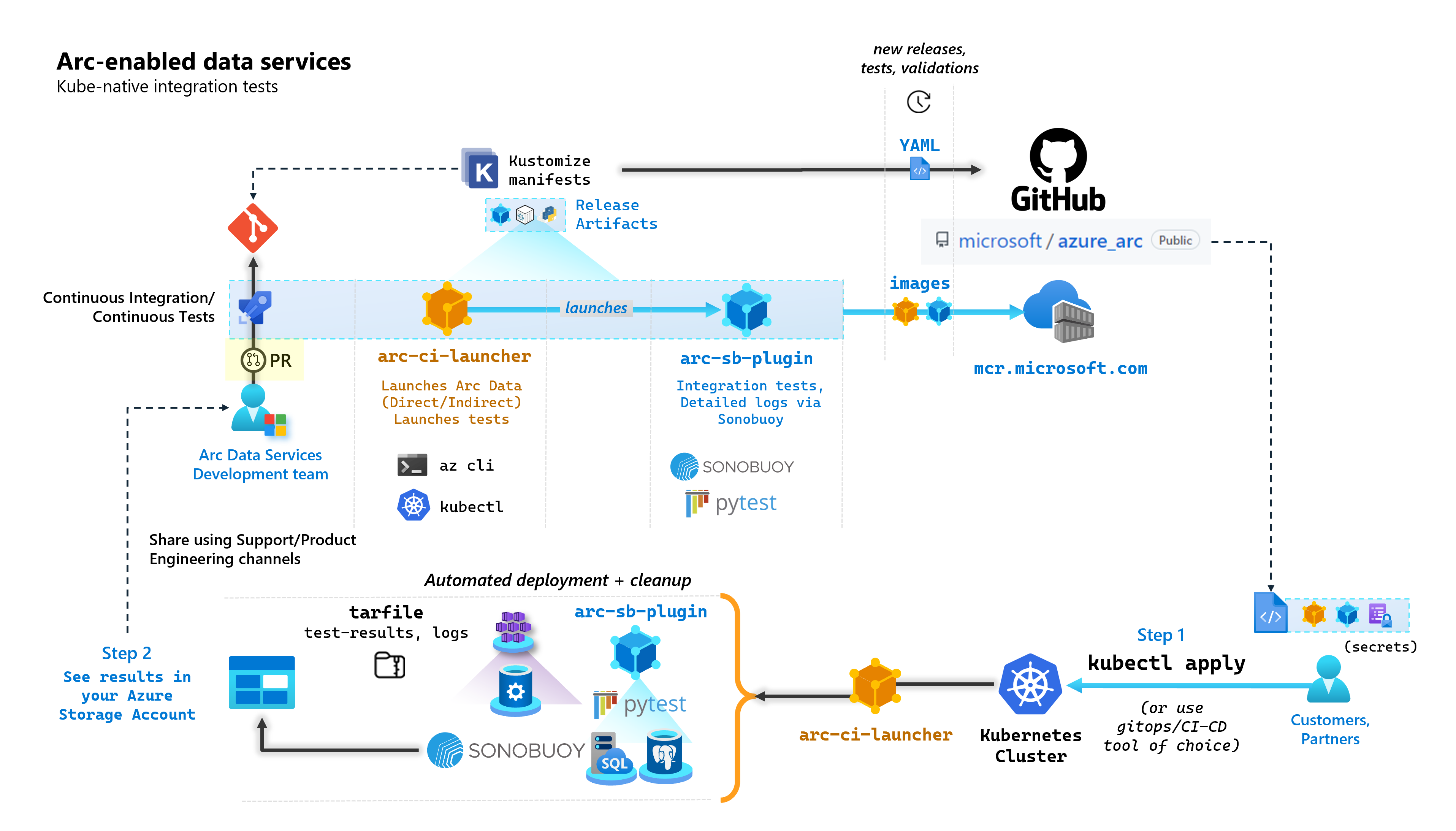
Como parte de cada compromiso que crea servicios de datos habilitados para Arc, Microsoft ejecuta canalizaciones automatizadas de CI/CD que realizan pruebas integrales. Estas pruebas se orquestan a través de dos contenedores que se mantienen junto con el producto principal (controlador de datos, SQL Managed Instance habilitado por Azure Arc y servidor PostgreSQL). Estos contenedores son:
arc-ci-launcher: contiene las dependencias de implementación (por ejemplo, las extensiones de la CLI), así como el código de implementación del producto (mediante la CLI de Azure) para los modos de conectividad directa e indirecta. Una vez incorporado Kubernetes al controlador de datos, el contenedor aprovecha Sonobuoy para desencadenar pruebas de integración paralelas.arc-sb-plugin: complemento Sonobuoy que contiene pruebas de integración completas basadas en Pytest, desde pruebas de humo sencillas (implementaciones, eliminaciones), hasta escenarios complejos de alta disponibilidad, pruebas de caos (eliminaciones de recursos), etc.
Estos contenedores de prueba están disponibles públicamente para que los clientes y asociados realicen pruebas de validación de servicios de datos habilitados para Arc en sus propios clústeres de Kubernetes, que se ejecutan en cualquier lugar, para validar:
- Las distribuciones y versiones de Kubernetes
- Las distribuciones y versiones del host
- El almacenamiento (
StorageClass/CSI), las redes (por ejemplo,LoadBalancer, DNS) - Otra configuración específica de Kubernetes o infraestructura
Los clientes que piensan ejecutar Data Services habilitado para Arc en una distribución no documentada, deben ejecutar estas pruebas de validación correctamente para que se consideren compatibles. Además, los asociados pueden usar este enfoque para certificar que su solución es compatible con Data Services habilitado para Arc. Consulte Validación de Kubernetes de los servicios de datos habilitados para Azure Arc.
En el diagrama siguiente se describe este proceso general:
En este tutorial, aprenderá a:
- Implementación de
arc-ci-launchermediantekubectl. - Examen de los resultados de la prueba de validación en la cuenta de Azure Blob Storage.
Requisitos previos
Credenciales:
- El archivo
test.env.tmplcontiene las credenciales necesarias y es una combinación de los requisitos previos existentes necesarios para incorporar un clúster conectado habilitado para Azure Arc y un controlador de datos conectado directamente. La configuración de este archivo se explica a continuación con ejemplos. - Un archivo kubeconfig en el clúster de Kubernetes probado con acceso
cluster-admin(necesario para la incorporación de los clústeres que se conecten en este momento)
- El archivo
Herramientas de cliente:
kubectlinstalado: versión mínima (principal: "1", secundaria: "21")- Interfaz de línea de comandos
git(o alternativas basadas en la interfaz de usuario)
Preparación del manifiesto de Kubernetes
El iniciador está disponible como parte del repositorio microsoft/azure_arc, como manifiesto de Kustomize: Kustomize está integrado en kubectl, por lo que no se requieren más herramientas.
- Clone el repositorio en el entorno local:
git clone https://github.com/microsoft/azure_arc.git
- Vaya a
azure_arc/arc_data_services/test/launcherpara ver la siguiente estructura de carpetas:
├── base <- Comon base for all Kubernetes Clusters
│ ├── configs
│ │ └── .test.env.tmpl <- To be converted into .test.env with credentials for a Kubernetes Secret
│ ├── kustomization.yaml <- Defines the generated resources as part of the launcher
│ └── launcher.yaml <- Defines the Kubernetes resources that make up the launcher
└── overlays <- Overlays for specific Kubernetes Clusters
├── aks
│ ├── configs
│ │ └── patch.json.tmpl <- To be converted into patch.json, patch for Data Controller control.json
│ └── kustomization.yaml
├── kubeadm
│ ├── configs
│ │ └── patch.json.tmpl
│ └── kustomization.yaml
└── openshift
├── configs
│ └── patch.json.tmpl
├── kustomization.yaml
└── scc.yaml
En este tutorial nos centraremos en los pasos de AKS, pero la estructura de superposición anterior se puede ampliar para incluir otras distribuciones de Kubernetes.
El manifiesto listo para implementar representará lo siguiente:
├── base
│ ├── configs
│ │ ├── .test.env <- Config 1: For Kubernetes secret, see sample below
│ │ └── .test.env.tmpl
│ ├── kustomization.yaml
│ └── launcher.yaml
└── overlays
└── aks
├── configs
│ ├── patch.json.tmpl
│ └── patch.json <- Config 2: For control.json patching, see sample below
└── kustomization.yam
Hay dos archivos que deben generarse para localizar el iniciador y que se ejecute dentro de un entorno específico. Estos archivos se pueden generar al pegar una copia y rellenar cada uno de los archivos de plantilla (*.tmpl) anteriores:
.test.env: se rellena de.test.env.tmpl.patch.json: se rellena depatch.json.tmpl.
Sugerencia
.test.env es un único conjunto de variables de entorno que dirige el comportamiento del iniciador. Generarlo con cuidado para un entorno determinado garantizará la reproducibilidad del comportamiento del iniciador.
Configuración 1: .test.env.
A continuación se comparte un ejemplo del archivo .test.env relleno, generado en función de .test.env.tmpl, con comentarios en línea.
Importante
La sintaxis export VAR="value" siguiente no está pensada para ejecutarse localmente para las variables de entorno de origen de la máquina, sino para el iniciador. El iniciador monta este archivo .test.envtal como está, como secret de Kubernetes, mediante Kustomize (secretGenerator de Kustomize toma un archivo, codifica en base64 el contenido de todo el archivo y lo convierte en un secreto de Kubernetes). Durante la inicialización, el iniciador ejecuta el comando de Bash source, que importa las variables de entorno desde el archivo .test.env montado tal cual en el entorno del iniciador.
En otras palabras, después de pegar .test.env.tmpl y editar la copia para crear .test.env, el archivo generado debe ser similar al ejemplo siguiente. El proceso para rellenar el archivo .test.env es idéntico en todos los sistemas operativos y terminales.
Sugerencia
Hay una serie de variables de entorno que requieren una explicación adicional para mayor claridad en la reproducibilidad. Estos se comentarán con see detailed explanation below [X].
Sugerencia
Tenga en cuenta que el ejemplo .test.env siguiente es para el modo directo. Algunas de estas variables, como ARC_DATASERVICES_EXTENSION_VERSION_TAG, no se aplican al modo indirecto. Por motivos de simplicidad, es mejor configurar el archivo .test.env con variables de modo directo en mente, el cambio de CONNECTIVITY_MODE=indirect hará que el iniciador omita la configuración específica del modo directo y use un subconjunto de la lista.
En otras palabras, el planeamiento del modo directo nos permite cumplir con las variables de modo indirecto.
Ejemplo finalizado de .test.env:
# ======================================
# Arc Data Services deployment version =
# ======================================
# Controller deployment mode: direct, indirect
# For 'direct', the launcher will also onboard the Kubernetes Cluster to Azure Arc
# For 'indirect', the launcher will skip Azure Arc and extension onboarding, and proceed directly to Data Controller deployment - see `patch.json` file
export CONNECTIVITY_MODE="direct"
# The launcher supports deployment of both GA/pre-GA trains - see detailed explanation below [1]
export ARC_DATASERVICES_EXTENSION_RELEASE_TRAIN="stable"
export ARC_DATASERVICES_EXTENSION_VERSION_TAG="1.11.0"
# Image version
export DOCKER_IMAGE_POLICY="Always"
export DOCKER_REGISTRY="mcr.microsoft.com"
export DOCKER_REPOSITORY="arcdata"
export DOCKER_TAG="v1.11.0_2022-09-13"
# "arcdata" Azure CLI extension version override - see detailed explanation below [2]
export ARC_DATASERVICES_WHL_OVERRIDE=""
# ================
# ARM parameters =
# ================
# Custom Location Resource Provider Azure AD Object ID - this is a single, unique value per Azure AD tenant - see detailed explanation below [3]
export CUSTOM_LOCATION_OID="..."
# A pre-rexisting Resource Group is used if found with the same name. Otherwise, launcher will attempt to create a Resource Group
# with the name specified, using the Service Principal specified below (which will require `Owner/Contributor` at the Subscription level to work)
export LOCATION="eastus"
export RESOURCE_GROUP_NAME="..."
# A Service Principal with "sufficient" privileges - see detailed explanation below [4]
export SPN_CLIENT_ID="..."
export SPN_CLIENT_SECRET="..."
export SPN_TENANT_ID="..."
export SUBSCRIPTION_ID="..."
# Optional: certain integration tests test upload to Log Analytics workspace:
# https://learn.microsoft.com/azure/azure-arc/data/upload-logs
export WORKSPACE_ID="..."
export WORKSPACE_SHARED_KEY="..."
# ====================================
# Data Controller deployment profile =
# ====================================
# Samples for AKS
# To see full list of CONTROLLER_PROFILE, run: az arcdata dc config list
export CONTROLLER_PROFILE="azure-arc-aks-default-storage"
# azure, aws, gcp, onpremises, alibaba, other
export DEPLOYMENT_INFRASTRUCTURE="azure"
# The StorageClass used for PVCs created during the tests
export KUBERNETES_STORAGECLASS="default"
# ==============================
# Launcher specific parameters =
# ==============================
# Log/test result upload from launcher container, via SAS URL - see detailed explanation below [5]
export LOGS_STORAGE_ACCOUNT="<your-storage-account>"
export LOGS_STORAGE_ACCOUNT_SAS="?sv=2021-06-08&ss=bfqt&srt=sco&sp=rwdlacupiytfx&se=...&spr=https&sig=..."
export LOGS_STORAGE_CONTAINER="arc-ci-launcher-1662513182"
# Test behavior parameters
# The test suites to execute - space seperated array,
# Use these default values that run short smoke tests, further elaborate test suites will be added in upcoming releases
export SQL_HA_TEST_REPLICA_COUNT="3"
export TESTS_DIRECT="direct-crud direct-hydration controldb"
export TESTS_INDIRECT="billing controldb kube-rbac"
export TEST_REPEAT_COUNT="1"
export TEST_TYPE="ci"
# Control launcher behavior by setting to '1':
#
# - SKIP_PRECLEAN: Skips initial cleanup
# - SKIP_SETUP: Skips Arc Data deployment
# - SKIP_TEST: Skips sonobuoy tests
# - SKIP_POSTCLEAN: Skips final cleanup
# - SKIP_UPLOAD: Skips log upload
#
# See detailed explanation below [6]
export SKIP_PRECLEAN="0"
export SKIP_SETUP="0"
export SKIP_TEST="0"
export SKIP_POSTCLEAN="0"
export SKIP_UPLOAD="0"
Importante
Si genera archivos de configuración en una máquina Windows, deberá convertir la secuencia de fin de línea de CRLF (Windows) a LF (Linux), ya que arc-ci-launcher se ejecuta como contenedor de Linux. Dejar el final de la línea como CRLF puede provocar un error al iniciar el contenedor de arc-ci-launcher, como /launcher/config/.test.env: $'\r': command not found. Por ejemplo, realice el cambio mediante VSCode (en la parte inferior derecha de la ventana):

Explicación detallada de determinadas variables
1. ARC_DATASERVICES_EXTENSION_*: versión de extensión y entrenamiento
Obligatorio: necesario para las implementaciones en modo
direct.
El iniciador puede implementar versiones tanto de disponibilidad general como de disponibilidad general previa.
La versión de extensión para la asignación de entrenamiento de versión (ARC_DATASERVICES_EXTENSION_RELEASE_TRAIN) se obtiene de aquí:
- Disponibilidad general:
stable- registro de versiones - Disponibilidad general previa:
preview- pruebas de la versión preliminar
2. ARC_DATASERVICES_WHL_OVERRIDE: dirección URL de descarga de la versión anterior de la CLI de Azure
Opcional: deje esta opción vacía en
.test.envpara usar el valor predeterminado empaquetado previamente.
La imagen del iniciador se empaqueta previamente con la versión más reciente de la CLI de arcdata en el momento de publicación de cada imagen de contenedor. Sin embargo, para trabajar con versiones anteriores y pruebas de actualización, puede que sea necesario proporcionar al iniciador el vínculo de descarga de la dirección URL del blob de la CLI de Azure para invalidar la versión empaquetada previamente; por ejemplo, para indicar al iniciador que instale la versión 1.4.3, rellene:
export ARC_DATASERVICES_WHL_OVERRIDE="https://azurearcdatacli.blob.core.windows.net/cli-extensions/arcdata-1.4.3-py2.py3-none-any.whl"
La versión de la CLI para la asignación de direcciones URL de blobs se encuentra aquí.
3. CUSTOM_LOCATION_OID: identificador de objeto de ubicaciones personalizadas de su inquilino de Microsoft Entra específico
Obligatorio: necesario para la creación de la ubicación personalizada del clúster conectado.
Los pasos siguientes proceden de Habilitación de ubicaciones personalizadas en el clúster y sirven para recuperar el identificador de objeto de ubicación personalizada único para el inquilino de Microsoft Entra.
Hay dos enfoques para obtener CUSTOM_LOCATION_OID para el inquilino de Microsoft Entra.
Mediante la CLI de Azure:
az ad sp show --id bc313c14-388c-4e7d-a58e-70017303ee3b --query objectId -o tsv # 51dfe1e8-70c6-4de... <--- This is for Microsoft's own tenant - do not use, the value for your tenant will be different, use that instead to align with the Service Principal for launcher.
Mediante Azure Portal: vaya a la hoja de Microsoft Entra y busque
Custom Locations RP: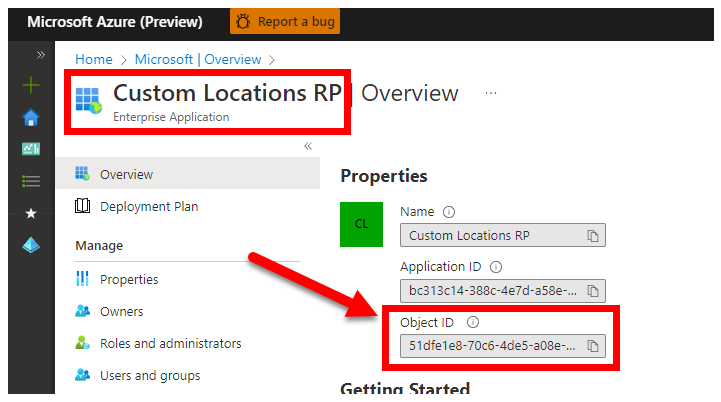
4. SPN_CLIENT_*: credenciales de entidad de servicio
Obligatorio: necesario para las implementaciones en modo directo.
El iniciador inicia sesión en Azure con estas credenciales.
Las pruebas de validación están diseñadas para realizarse en suscripciones de Azure y en clústeres de Kubernetes que no son de producción o de prueba, y están enfocadas hacia la validación funcional de la configuración de Kubernetes y la infraestructura. Por lo tanto, para evitar el número de pasos manuales necesarios para los inicios, se recomienda proporcionar un SPN_CLIENT_ID/SECRET con Owner a nivel del grupo de recursos (o suscripción), ya que así se crearán varios recursos en este grupo de recursos, y asignar permisos a esos recursos en varias identidades administradas creadas como parte de la implementación (estas asignaciones de roles a su vez requieren que la entidad de servicio tenga Owner).
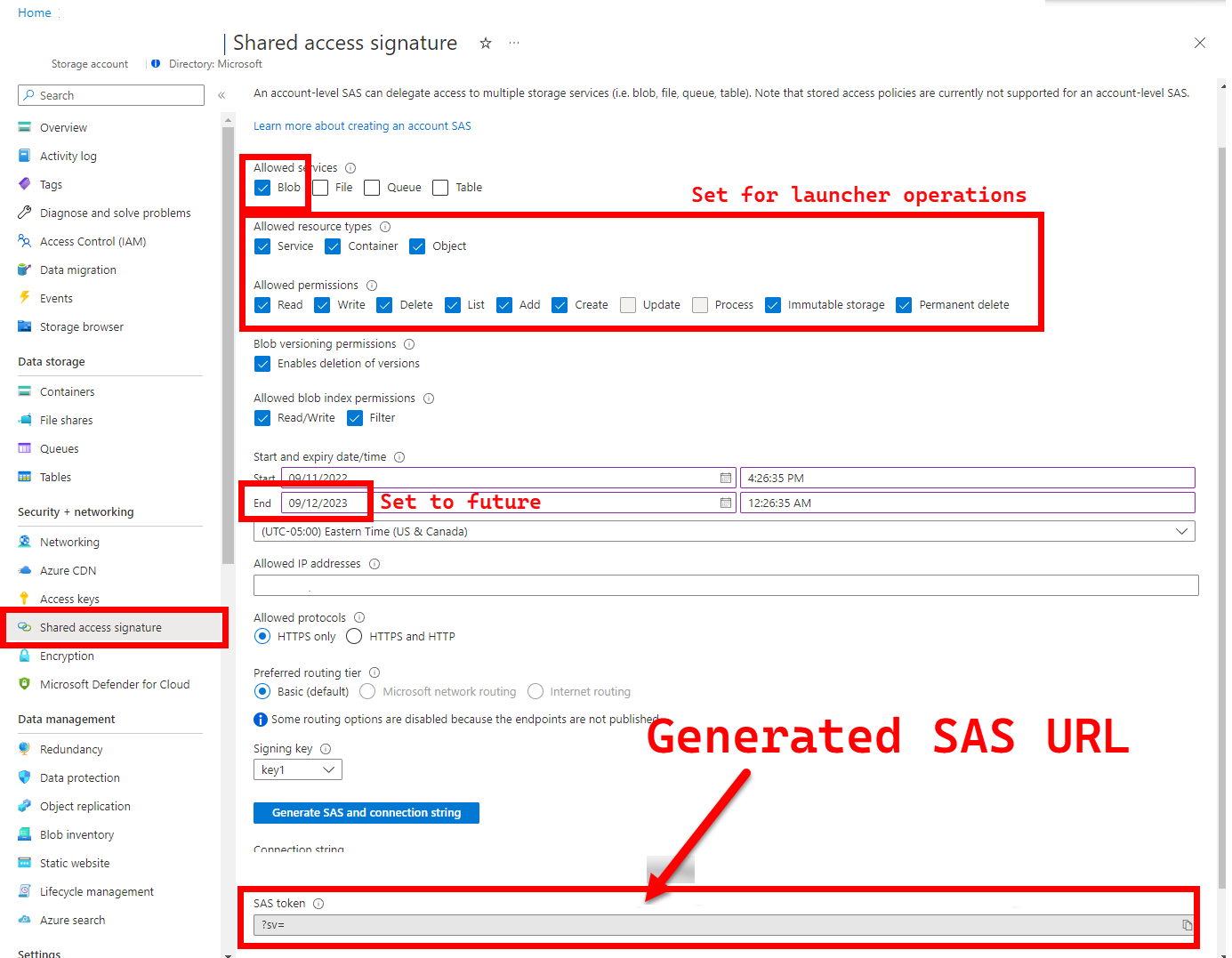
5. LOGS_STORAGE_ACCOUNT_SAS: dirección URL de SAS de la cuenta de Blob Storage
Recomendado: dejar esto vacío significa que no obtendrá resultados ni registros de prueba.
El iniciador necesita una ubicación persistente (Azure Blob Storage) para cargar los resultados, ya que Kubernetes (aún) no permite copiar archivos desde pods detenidos o completados: consulte esto. El iniciador logra la conectividad con Azure Blob Storage mediante una dirección URL de SAS con ámbito de cuenta (en lugar un ámbito de contenedor o blob): una dirección URL firmada con definición de acceso con límite de tiempo; consulte Otorgar acceso limitado a recursos de Azure Storage con firmas de acceso compartido (SAS) para:
- Crear un nuevo contenedor de almacenamiento en la cuenta de almacenamiento existente (
LOGS_STORAGE_ACCOUNT), si no existe (nombre basado enLOGS_STORAGE_CONTAINER). - Crear blobs con nombre único (archivos tar de registro de prueba).
Los pasos siguientes proceden de Otorgar acceso limitado a recursos de Azure Storage con firmas de acceso compartido (SAS).
Sugerencia
Las direcciones URL de SAS son diferentes de la clave de la cuenta de almacenamiento, las primeras tienen el formato siguiente.
?sv=2021-06-08&ss=bfqt&srt=sco&sp=rwdlacupiytfx&se=...&spr=https&sig=...
Hay varios enfoques para generar una dirección URL de SAS. En este ejemplo se muestra el portal:
Para usar la CLI de Azure en su lugar, consulte az storage account generate-sas.
6. SKIP_*: control del comportamiento del iniciador omitiendo ciertas fases
Opcional: deje esta opción vacía en
.test.envpara ejecutar todas las fases (equivalente a0o en blanco)
El iniciador expone variables SKIP_* para ejecutar y omitir fases específicas; por ejemplo, para realizar una ejecución de "solo limpieza".
Aunque el iniciador está diseñado para limpiar tanto al principio como al final de cada ejecución, es posible que los errores de lanzamiento o de prueba dejen restos de recursos. Para ejecutar el iniciador en modo "solo limpieza", establezca las siguientes variables en .test.env:
export SKIP_PRECLEAN="0" # Run cleanup
export SKIP_SETUP="1" # Do not setup Arc-enabled Data Services
export SKIP_TEST="1" # Do not run integration tests
export SKIP_POSTCLEAN="1" # POSTCLEAN is identical to PRECLEAN, although idempotent, not needed here
export SKIP_UPLOAD="1" # Do not upload logs from this run
La configuración anterior indica al iniciador que limpie todos los recursos de Arc y Data Services habilitado para Arc y que no implemente, pruebe o cargue registros.
Configuración 2: patch.json
A continuación se comparte un ejemplo del archivo patch.json relleno, generado en función de patch.json.tmpl:
Tenga en cuenta que
spec.docker.registry, repository, imageTagdebe ser idéntico a los valores de.test.envanteriores.
Ejemplo finalizado de patch.json:
{
"patch": [
{
"op": "add",
"path": "spec.docker",
"value": {
"registry": "mcr.microsoft.com",
"repository": "arcdata",
"imageTag": "v1.11.0_2022-09-13",
"imagePullPolicy": "Always"
}
},
{
"op": "add",
"path": "spec.storage.data.className",
"value": "default"
},
{
"op": "add",
"path": "spec.storage.logs.className",
"value": "default"
}
]
}
Implementación del iniciador
Se recomienda implementar el iniciador en un clúster que no sea de producción o de prueba, ya que realiza acciones destructivas en Arc y otros recursos de Kubernetes usados.
Especificación imageTag
El iniciador se define dentro del manifiesto de Kubernetes como Job, que requiere indicar a Kubernetes dónde encontrar la imagen del iniciador. Esto se establece en base/kustomization.yaml:
images:
- name: arc-ci-launcher
newName: mcr.microsoft.com/arcdata/arc-ci-launcher
newTag: v1.11.0_2022-09-13
Sugerencia
Para resumir, en este punto: hay 3 lugares especificados como imageTag. Para mayor claridad, esta es una explicación de los distintos usos de cada uno. Normalmente, al probar una versión determinada, los tres valores serían los mismos (alineados con una versión determinada):
| # | Filename | Nombre de la variable | ¿Por qué? | ¿Quién lo usa? |
|---|---|---|---|---|
| 1 | .test.env |
DOCKER_TAG |
Obtención de la imagen del programa previo como parte de la instalación de la extensión | az k8s-extension create en el iniciador |
| 2 | patch.json |
value.imageTag |
Obtención de la imagen del controlador de datos | az arcdata dc create en el iniciador |
| 3 | kustomization.yaml |
images.newTag |
Obtención de la imagen del iniciador | kubectl apply en el iniciador |
kubectl apply
Para validar que el manifiesto se ha configurado correctamente, intente la validación del lado cliente con --dry-run=client, que imprime los recursos de Kubernetes que se van a crear para el iniciador:
kubectl apply -k arc_data_services/test/launcher/overlays/aks --dry-run=client
# namespace/arc-ci-launcher created (dry run)
# serviceaccount/arc-ci-launcher created (dry run)
# clusterrolebinding.rbac.authorization.k8s.io/arc-ci-launcher created (dry run)
# secret/test-env-fdgfm8gtb5 created (dry run) <- Created from Config 1: `patch.json`
# configmap/control-patch-2hhhgk847m created (dry run) <- Created from Config 2: `.test.env`
# job.batch/arc-ci-launcher created (dry run)
Para implementar los registros de iniciador y cola, ejecute lo siguiente:
kubectl apply -k arc_data_services/test/launcher/overlays/aks
kubectl wait --for=condition=Ready --timeout=360s pod -l job-name=arc-ci-launcher -n arc-ci-launcher
kubectl logs job/arc-ci-launcher -n arc-ci-launcher --follow
En este momento, el iniciador debe iniciarse y debería ver lo siguiente:
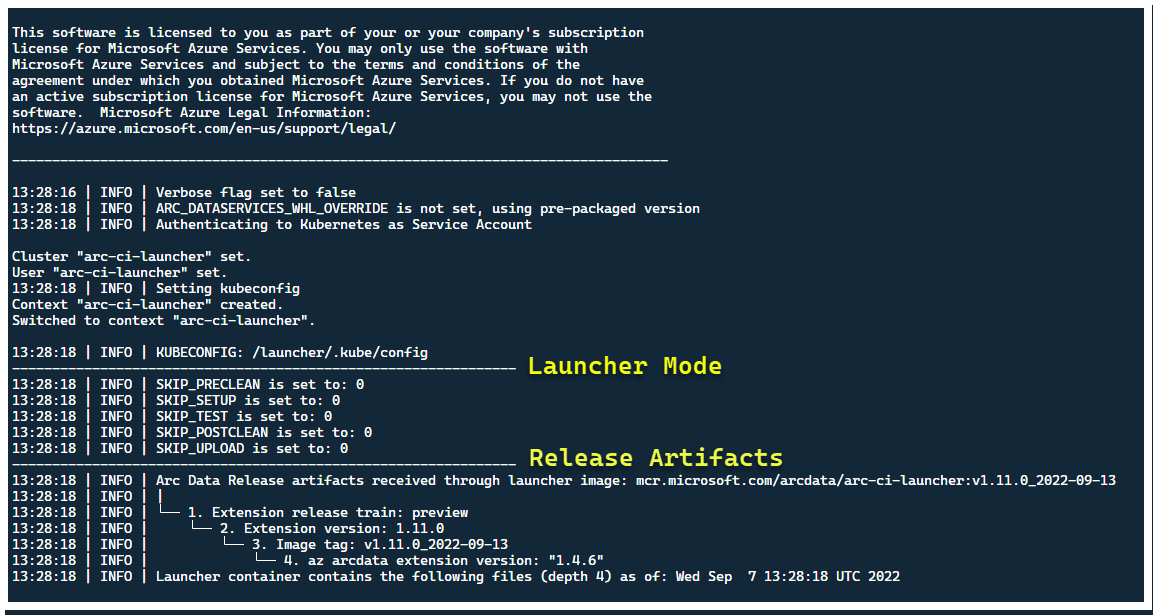
Aunque es mejor implementar el iniciador en un clúster sin recursos de Arc preexistentes, este contiene la validación de versión preliminar para detectar CRD de Arc y Data Services habilitado para Arc existentes y recursos de ARM, e intenta limpiarlos de forma óptima (mediante las credenciales de entidad de servicio proporcionadas), antes de implementar la nueva versión:
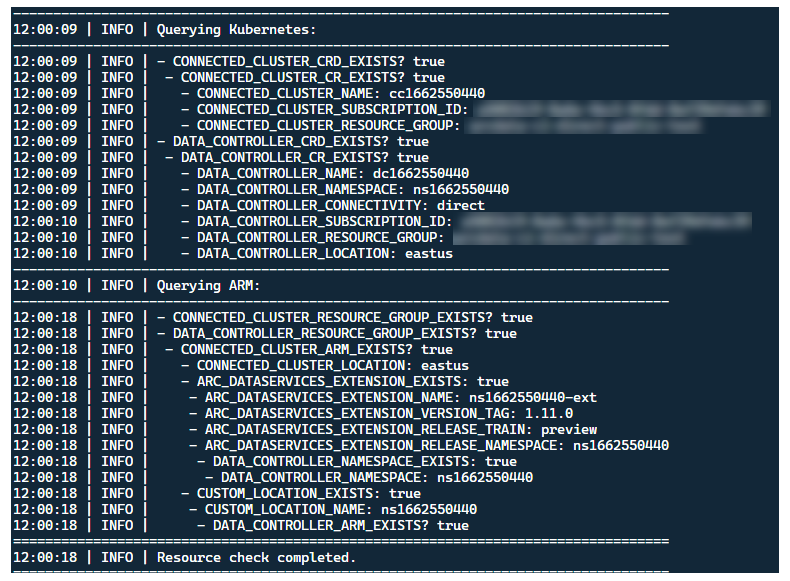
Este proceso de detección y limpieza de metadatos también se ejecuta al salir del iniciador para dejar el clúster lo más parecido posible a su estado preexistente antes del inicio.
Pasos realizados por el iniciador
En general, el iniciador realiza la siguiente secuencia de pasos:
Se autentica en la API de Kubernetes mediante una cuenta de servicio montada en pod
Se autentica en la API de ARM mediante una entidad de servicio montada en secreto
Examina los metadatos de CRD para detectar los recursos personalizados de Arc y de Data Services habilitado para Arc existentes
Limpia los recursos personalizados existentes en Kubernetes y los recursos posteriores de Azure. Si hay alguna discrepancia entre las credenciales de
.test.enven comparación con los recursos existentes en el clúster, deténgase.Genere un conjunto único de variables de entorno basadas en la marca de tiempo para el nombre del clúster de Arc, el controlador de datos y el espacio de nombres personalizados. Imprime las variables de entorno, ofuscando valores confidenciales (por ejemplo, contraseña de entidad de servicio, etc.).
a. Para el modo directo: incorpore el clúster a Azure Arc e implemente el controlador.
b. Para el modo indirecto: implemente el controlador de datos
Una vez que el controlador de datos tenga el estado
Ready, genere un conjunto de registros de la CLI de Azure (az arcdata dc debug) y almacénelos en el entorno local, con la etiquetasetup-complete, como base de referencia.Use la variable de entorno
TESTS_DIRECT/INDIRECTde.test.envpara iniciar un conjunto de ejecuciones de prueba de Sonobuoy en paralelo basadas en una matriz separada por espacios (TESTS_(IN)DIRECT). Estas se ejecutan en un nuevo espacio de nombressonobuoy, mediante el podarc-sb-pluginque contiene las pruebas de validación de Pytest.El agregador Sonobuoy acumula los
junitresultados de las pruebas y los registros por ejecución de prueba dearc-sb-pluginque se exportan al pod del iniciador.Devuelve el código de salida de las pruebas y genera otro conjunto de registros de depuración (CLI de Azure y
sonobuoy) que se almacenan en el entorno local con la etiquetatest-complete.Examine los metadatos de CRD, como en el paso 3, para detectar los recursos personalizados existentes de Arc y Data Services habilitado para Arc. A continuación, continúe con la destrucción de todos los recursos de Arc y Data habilitado para Arc en orden inverso al de la implementación, así como CRD, Role/ClusterRoles, PV/PVC, etc.
Intente usar el token de SAS
LOGS_STORAGE_ACCOUNT_SASproporcionado para crear un contenedor de la cuenta de almacenamiento cuyo nombre se base enLOGS_STORAGE_CONTAINERen la cuenta de almacenamientoLOGS_STORAGE_ACCOUNTpreexistente. Si el contenedor de la cuenta de almacenamiento ya existe, úselo. Cargue todos los resultados y registros de las pruebas locales en este contenedor de almacenamiento como tarball (consulte a continuación).Salir.
Pruebas realizadas por el conjunto de pruebas
Hay aproximadamente 375 pruebas de integración únicas disponibles en 27 conjuntos de pruebas: cada una de ellas prueba una funcionalidad independiente.
| Conjunto de pruebas # | Nombre del conjunto de pruebas | Descripción de la prueba |
|---|---|---|
| 1 | ad-connector |
Prueba la implementación y actualización de un conector de Active Directory (conector de AD). |
| 2 | billing |
Las pruebas de varios tipos de licencia críticas para la empresa se reflejan en la tabla de recursos del controlador, que se usa para la carga de facturación. |
| 3 | ci-billing |
Similar a billing, pero con más permutaciones de CPU y memoria. |
| 4 | ci-sqlinstance |
Pruebas de larga duración para la creación de varias réplicas, actualizaciones, actualizaciones de GP -> BC, validación de copias de seguridad y el Agente SQL Server. |
| 5 | controldb |
Comprueba la base de datos de control: comprobación de secretos de SA, comprobación de inicio de sesión del sistema, creación de auditorías y comprobaciones de integridad para la versión de compilación de SQL. |
| 6 | dc-export |
Carga de uso y facturación en modo indirecto. |
| 7 | direct-crud |
Crea una instancia de SQL mediante llamadas de ARM y se valida tanto en Kubernetes como en ARM. |
| 8 | direct-fog |
Crea varias instancias de SQL y crea un grupo de conmutación por error entre ellas mediante llamadas de ARM. |
| 9 | direct-hydration |
Crea una instancia de SQL con la API de Kubernetes y valida la presencia en ARM. |
| 10 | direct-upload |
Valida la carga de facturación en modo directo |
| 11 | kube-rbac |
Garantiza que los permisos de la cuenta de servicio de Kubernetes para servicios de datos de Arc coincidan con las expectativas de privilegios mínimos. |
| 12 | nonroot |
Garantiza que los contenedores se ejecuten como usuario no raíz |
| 13 | postgres |
Completa varias pruebas de creación, escalado y restauración de Postgres. |
| 14 | release-sanitychecks |
Comprobaciones de integridad de las versiones mes a mes, como las versiones de compilación de SQL Server. |
| 15 | sqlinstance |
Versión más corta de ci-sqlinstance para validaciones rápidas. |
| 16 | sqlinstance-ad |
Prueba la creación de instancias de SQL con el conector de Active Directory. |
| 17 | sqlinstance-credentialrotation |
Prueba la rotación automatizada de credenciales de uso general y crítico para la empresa. |
| 18 | sqlinstance-ha |
Varias pruebas de esfuerzo de alta disponibilidad, incluyendo reinicios de pods, conmutaciones por error forzadas y suspensiones. |
| 19 | sqlinstance-tde |
Varias pruebas de cifrado de datos transparentes. |
| 20 | telemetry-elasticsearch |
Valida la ingesta de registros en Elasticsearch. |
| 21 | telemetry-grafana |
Valida que se pueda acceder a Grafana. |
| 22 | telemetry-influxdb |
Valida la ingesta de métricas en InfluxDB. |
| 23 | telemetry-kafka |
Varias pruebas para Kafka mediante SSL, configuración de un solo agente de varios. |
| 24 | telemetry-monitorstack |
Comprueba que los componentes de supervisión, como Fluentbit y Collectd, sean funcionales. |
| 25 | telemetry-telemetryrouter |
Prueba la telemetría abierta. |
| 26 | telemetry-webhook |
Prueba webhook de servicios de datos con llamadas válidas y no válidas. |
| 27 | upgrade-arcdata |
Actualiza un conjunto completo de instancias de SQL (GP, réplica BC 2 y réplica BC 3, con Active Directory) y actualizaciones de la versión del mes anterior a la compilación más reciente. |
Por ejemplo, para sqlinstance-ha se realizarán las siguientes pruebas:
test_critical_configmaps_present: garantizará que ConfigMaps y los campos pertinentes estén presentes para una instancia de SQL.test_suspended_system_dbs_auto_heal_by_orchestrator: garantiza simasterymsdbse suspenderán por cualquier medio (en este caso, usuario). El mantenimiento del orquestador concilia la recuperación automática.test_suspended_user_db_does_not_auto_heal_by_orchestrator: garantizará que si un usuario suspendiera deliberadamente una base de datos de usuario, la conciliación de mantenimiento de Orchestrator no lo recuperará automáticamente.test_delete_active_orchestrator_twice_and_delete_primary_pod: eliminará el pod del orquestador varias veces, seguido de la réplica principal, y comprobará que se sincronicen todas las réplicas. Las expectativas de tiempo de conmutación por error para 2 réplicas son relajadas.test_delete_primary_pod: eliminará la réplica principal y comprobará que se sincronicen todas las réplicas. Las expectativas de tiempo de conmutación por error para 2 réplicas son relajadas.test_delete_primary_and_orchestrator_pod: eliminará la réplica principal y al pod del orquestador y comprobará que se sincronicen todas las réplicas.test_delete_primary_and_controller: eliminará la réplica principal y el pod del controlador de datos y comprobará que se pueda acceder al punto de conexión principal y se sincronice la nueva réplica principal. Las expectativas de tiempo de conmutación por error para 2 réplicas son relajadas.test_delete_one_secondary_pod: eliminará la réplica secundaria y el pod del controlador de datos y comprobará que se sincronicen todas las réplicas.test_delete_two_secondaries_pods: eliminará las réplicas secundarias y el pod del controlador de datos y comprobará que se sincronicen todas las réplicas.test_delete_controller_orchestrator_secondary_replica_pods:test_failaway: forzará la conmutación por error del grupo de disponibilidad fuera de la entidad de seguridad actual y garantizará que la nueva entidad de seguridad no sea la misma que la anterior. Comprobará que se sincronicen todas las réplicas.test_update_while_rebooting_all_non_primary_replicas: las actualizaciones controladas por el controlador de pruebas son resistentes con reintentos a pesar de varias circunstancias convulsas.
Nota
Algunas pruebas podrían requerir hardware específico, como el acceso con privilegios a los controladores de dominio para las pruebas ad para la creación de la cuenta y la entrada DNS, que puede que no estén disponibles en todos los entornos que traten usar arc-ci-launcher.
Examen de los resultados de pruebas
Ejemplo de contenedor de almacenamiento y de archivo cargados por el iniciador:
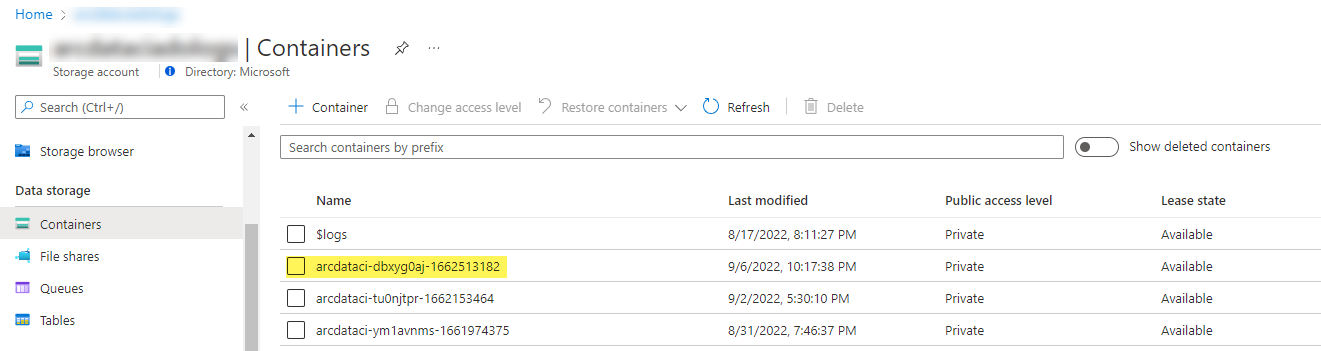
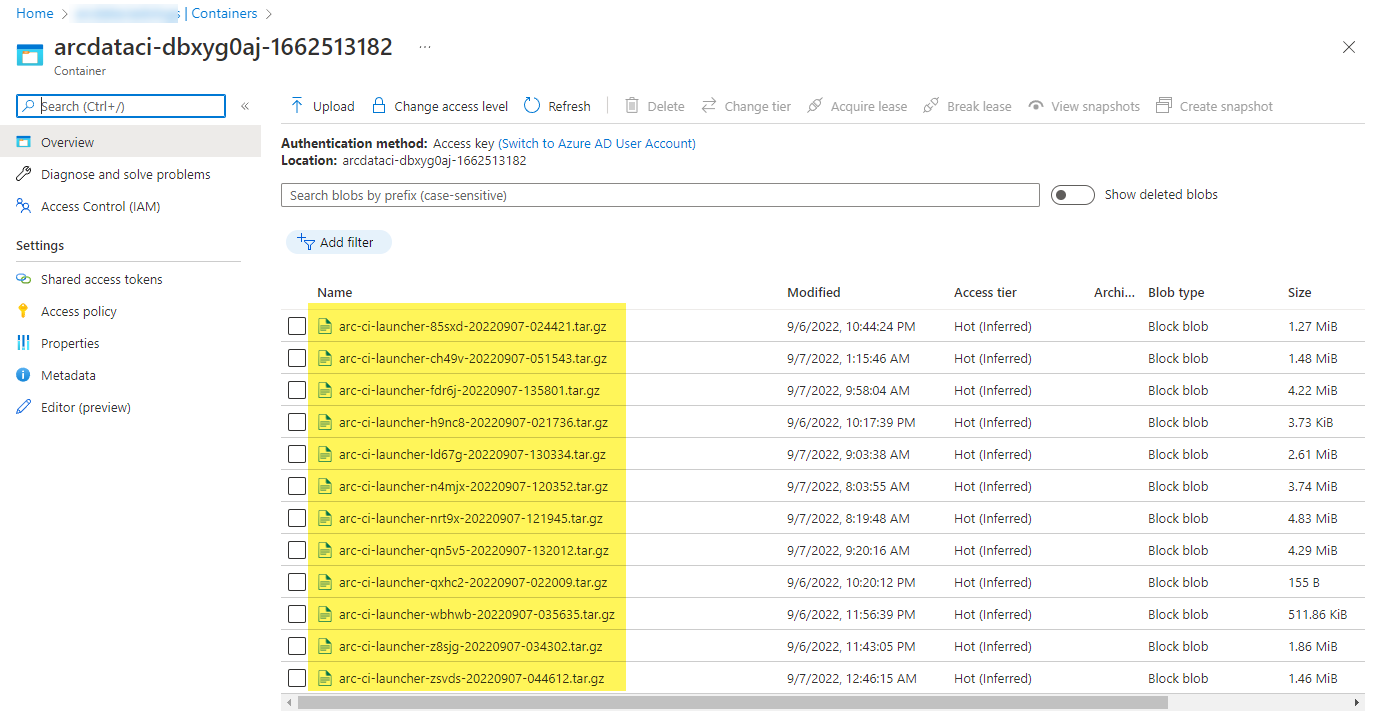
Y los resultados de la prueba generados a partir de la ejecución:
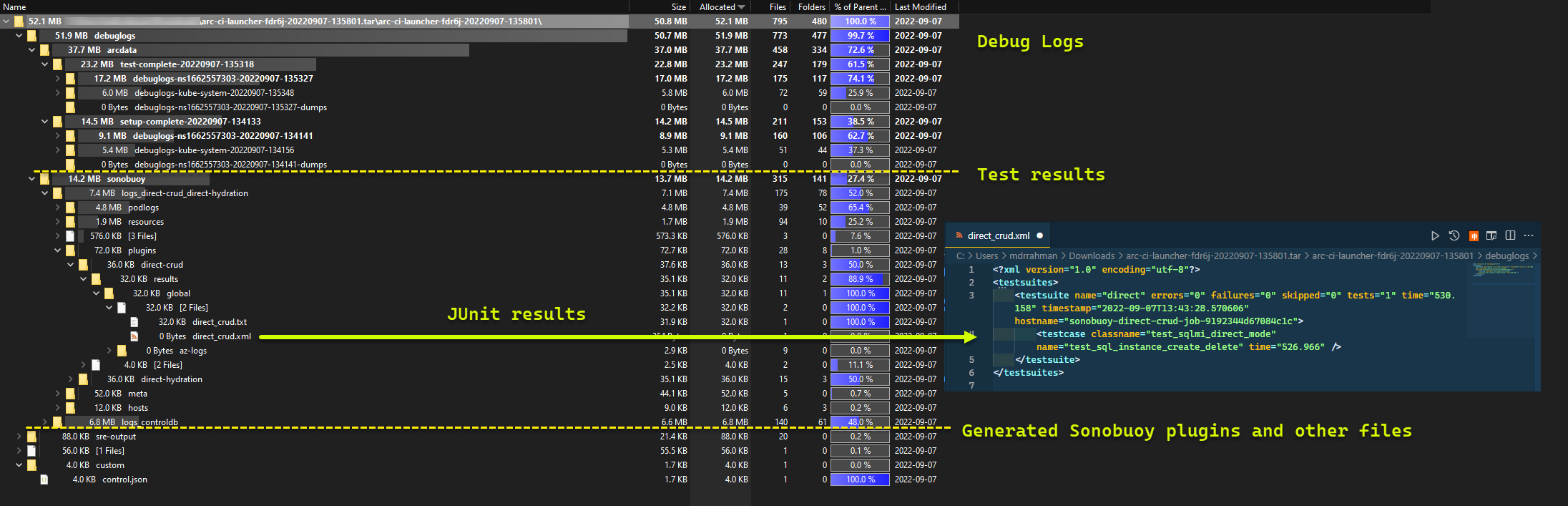
Limpieza de recursos
Para eliminar el iniciador, ejecute:
kubectl delete -k arc_data_services/test/launcher/overlays/aks
Esto limpia los manifiestos de los recursos implementados como parte del iniciador.