Implementación y pruebas de cargas de trabajo críticas en Azure
La implementación y las pruebas del entorno crítico es una parte fundamental de la arquitectura de referencia general. Los stamps de aplicación individuales se implementan usando una infraestructura como código de un repositorio de código fuente. Las actualizaciones de la infraestructura y la aplicación en la parte superior deben implementarse sin tiempo de inactividad en la aplicación. Se recomienda una canalización de integración continua de DevOps para recuperar el código fuente del repositorio e implementar los sellos individuales en Azure.
La implementación y las actualizaciones son el proceso central en la arquitectura. Las actualizaciones relacionadas con la infraestructura y la aplicación deben implementarse en sellos totalmente independientes. Solo los componentes de infraestructura globales de la arquitectura se comparten entre stamps. Los stamps que ya había en la infraestructura no se tocan. Las actualizaciones de la infraestructura se implementan únicamente en estos nuevos stamps. Del mismo modo, las nuevas versiones de aplicación se implementan en estos nuevos sellos.
Los nuevos stamps se agregan a Azure Front Door. El tráfico se mueve gradualmente a los nuevos stamps. Cuando el tráfico se atiende desde los nuevos stamps sin problema, se eliminan los stamps anteriores.
Se recomienda realizar pruebas de penetración, caos y esfuerzo del entorno implementado. Las pruebas proactivas de la infraestructura detectan debilidades y cómo se comporta la aplicación implementada si se produce un error.
Despliegue
La implementación de la infraestructura en la arquitectura de referencia depende de los siguientes procesos y componentes:
DevOps - El código fuente de GitHub y las canalizaciones para la infraestructura.
es-ES: Actualizaciones sin tiempo de inactividad: las actualizaciones y las mejoras se implementan en el entorno sin causar tiempo de inactividad a la aplicación desplegada.
Entornos: entornos de corta duración y permanentes usados para la arquitectura.
Recursos compartidos y dedicados: recursos de Azure dedicados y compartidos con los stamps y la infraestructura global.
Para más información, consulte Implementación y pruebas de cargas de trabajo críticas en Azure: Consideraciones de diseño
Implementación: DevOps
Los componentes de DevOps proporcionan el repositorio de código fuente y las canalizaciones de CI/CD para la implementación de la infraestructura y las actualizaciones. GitHub y Azure Pipelines se eligieron como componentes.
gitHub: contiene los repositorios de código fuente de la aplicación y la infraestructura.
Azure Pipelines: Las canalizaciones que usa la arquitectura para todas las tareas de compilación, prueba e implementación.
Un componente adicional en el diseño usado para la implementación es agentes de compilación. Los agentes de compilación hospedados de Microsoft se usan como parte de Azure Pipelines para implementar la infraestructura y las actualizaciones. El uso de agentes de compilación hospedados de Microsoft elimina la carga de administración para que los desarrolladores mantengan y actualicen el agente de compilación.
Para más información sobre Azure Pipelines, consulte ¿Qué es Azure Pipelines?.

Para más información, consulte Implementación y pruebas de cargas de trabajo críticas en Azure: Implementaciones de infraestructura como código
Implementación: actualizaciones sin tiempo de inactividad
La estrategia de actualización sin tiempo de inactividad en la arquitectura de referencia es fundamental para la aplicación crítica general. La metodología de reemplazo en lugar de la actualización de los sellos garantiza una instalación nueva de la aplicación en un sello de infraestructura. La arquitectura de referencia utiliza un enfoque azul/verde y permite entornos de prueba y desarrollo independientes.
Hay dos componentes principales de la arquitectura de referencia:
infraestructura: servicios y recursos de Azure. Implementado con Terraform y su configuración asociada.
Application: el servicio hospedado o la aplicación que sirve a los usuarios. Se basa en contenedores de Docker y artefactos npm en HTML y JavaScript para la interfaz de usuario de la aplicación de página única (SPA).
En muchos sistemas, se supone que las actualizaciones de aplicaciones son más frecuentes que las actualizaciones de infraestructura. Como resultado, se desarrollan diferentes procedimientos de actualización para cada uno. Con una infraestructura de nube pública, los cambios pueden producirse a un ritmo más rápido. Se eligió un proceso de implementación para las actualizaciones de aplicaciones y las actualizaciones de infraestructura. Un enfoque garantiza que las actualizaciones de la infraestructura y de las aplicaciones estén siempre sincronizadas. Este enfoque permite:
un proceso coherente: menos posibilidades de errores si la infraestructura y las actualizaciones de aplicaciones se mezclan conjuntamente en una versión, intencionadamente o no.
Una implementación azul/verde: cada actualización se implementa usando una migración gradual del tráfico a la nueva versión.
Mayor facilidad de implementación y depuración de la aplicación: el stamp entero nunca hospeda varias versiones de la aplicación en paralelo.
Reversión sencilla: el tráfico se puede volver a enviar a los stamps que ejecutan la versión anterior si se encuentran errores o problemas.
Eliminación de cambios manuales y desfase de configuración: cada entorno es una implementación nueva.
Para más información, consulte Implementación y prueba de para cargas de trabajo críticas en Azure: implementaciones efímeras de tipo azul/verde
Estrategia de bifurcación
La base de la estrategia de actualización es el uso de ramas dentro del repositorio de Git. La arquitectura de referencia usa tres tipos de ramas:
| Sucursal | Descripción |
|---|---|
feature/* y fix/* |
Puntos de entrada para cualquier cambio. Los desarrolladores crean estas ramas y deben tener un nombre descriptivo, como feature/catalog-update o fix/worker-timeout-bug. Cuando los cambios están listos para fusionarlos mediante combinación, se crea una solicitud de incorporación de cambios (PR) en la rama main. Al menos un revisor debe aprobar todas las solicitudes de incorporación de cambios. Salvo algunas excepciones, todos los cambios propuestos en una solicitud de incorporación de cambios deben ejecutarse a través de la canalización de validación de un extremo a otro (E2E). Los desarrolladores deben usar el pipeline de E2E para probar y depurar los cambios en un entorno completo. |
main |
La rama que avanza continuamente hacia adelante y se mantiene estable. Se usa principalmente para las pruebas de integración. Los cambios en main solo se realizan a través de pull requests. Una directiva de rama prohíbe las operaciones de escritura directa. Las versiones nocturnas en el entorno permanente integration (int) se ejecutan automáticamente desde la rama main. La rama main se considera estable. Es seguro suponer que, en cualquier momento, se puede crear una versión a partir de ella. |
release/* |
Las ramas de versión solo se crean a partir de la rama main. Las ramas siguen el formato release/2021.7.X. Las directivas de rama se usan para que solo los administradores de repositorios puedan crear ramas release/*. Solo se usan estas ramas para las implementaciones en el entorno prod. |
Para más información, consulte Implementación y pruebas de cargas de trabajo críticas en Azure: Estrategia de bifurcación
Correcciones urgentes
Cuando se requiere una revisión urgentemente debido a un error u otro problema y no puede pasar por el proceso de versión normal, hay disponible una ruta de revisión. Las actualizaciones y correcciones de seguridad críticas que no se descubrieron durante las pruebas iniciales y que afectan la experiencia del usuario se consideran ejemplos válidos de correcciones rápidas.
La revisión debe crearse en una rama fix nueva y, después, fusionarse mediante combinación en main usando una solicitud de incorporación de cambios normal. En lugar de crear una nueva rama de versión, la revisión se "selecciona de forma exclusiva" en una rama de versión que ya existía. Esta rama ya está implementada en el entorno de prod. La canalización de CI/CD que implementó originalmente la rama de versión con todas las pruebas se ejecuta de nuevo y ahora implementa la revisión como parte de la canalización.
Para evitar problemas mayores, es importante que la revisión contenga algunas confirmaciones aisladas que se puedan seleccionar de forma exclusiva e integrar fácilmente en la rama de versión. Si no se pueden seleccionar exclusivamente confirmaciones aisladas para integrarlas en la rama de versión, es una indicación de que el cambio no es una revisión, Implemente el cambio como una nueva versión completa. Combínelo con una reversión a una versión estable anterior hasta que se pueda implementar la nueva versión.
Implementación: entornos
La arquitectura de referencia usa dos tipos de entornos para la infraestructura:
De corta duración: se usa la canalización de validación E2E para implementar entornos de corta duración. Los entornos de corta duración se usan para entornos de validación o depuración puros para desarrolladores. Los entornos de validación se pueden crear a partir de la rama
feature/*, sujetos a pruebas y luego destruirse si todas las pruebas fueron exitosas. Los entornos de depuración se implementan de la misma manera que la validación, pero no se destruyen inmediatamente. Estos entornos no deben existir durante más de unos días y deben eliminarse cuando se fusiona mediante combinación la solicitud de incorporación de cambios correspondiente de la rama de características.permanente: en los entornos permanentes hay versiones
integration (int)yproduction (prod). Estos entornos residen continuamente y no se destruyen. Los entornos usan nombres de dominio fijos comoint.mission-critical.app. En una implementación real de la arquitectura de referencia, debe agregarse un entornostaging(preproducción). El entorno destagingse usa para implementar y validar las ramas dereleasecon el mismo proceso de actualización queprod(despliegue azul/verde).Integración (int): la versión
intse implementa por la noche desde la ramamaincon el mismo proceso queprod. El cambio del tráfico es más rápido que en la unidad de versión anterior. En lugar de cambiar gradualmente el tráfico durante varios días, como enprod, el proceso deintse completa en unos minutos o horas. Este cambio más rápido garantiza que el entorno actualizado esté listo a la mañana siguiente. Los sellos antiguos se eliminan automáticamente si todas las pruebas de la canalización se realizan correctamente.Producción (prod): la versión
prodsolo se implementa desde ramasrelease/*. El cambio de tráfico usa pasos más detallados. Una puerta de aprobación manual está entre cada paso. Cada versión crea nuevos sellos regionales y despliega la nueva versión de la aplicación en los sellos. Los stamps que había no se tocan durante el proceso. El aspecto más importante que debe tenerse en cuenta paraprodes que debe estar "siempre activo". No debe producirse ningún tiempo de inactividad planeado o no planeado. La única excepción es los cambios fundamentales en la capa de base de datos. Es posible que se necesite una ventana de mantenimiento planeado.
Implementación: recursos compartidos y dedicados
Los entornos permanentes (int y prod) dentro de la arquitectura de referencia tienen diferentes tipos de recursos en función de si se comparten con toda la infraestructura o dedicadas a un sello individual. Los recursos se pueden dedicar a una versión determinada y solo existen hasta que la unidad de versión siguiente se haga cargo.
Unidades de versión
Una unidad de versión está formada por varios stamps regionales para una versión específica. Los sellos contienen todos los recursos que no se comparten con los demás sellos. Estos recursos son redes virtuales, clúster de Azure Kubernetes Service, Event Hubs y Azure Key Vault. Azure Cosmos DB y ACR están configurados con orígenes de datos de Terraform.
Recursos compartidos globalmente
Todos los recursos compartidos entre unidades de versión se definen en una plantilla independiente de Terraform. Estos recursos son Front Door, Azure Cosmos DB, Container Registry (ACR) y las áreas de trabajo de Log Analytics y otros recursos relacionados con la supervisión. Estos recursos se implementan antes de implementar el primer stamp regional de una unidad de versión. Se hace referencia a los recursos en las plantillas de Terraform para los sellos.
Puerta principal
Aunque Front Door es un recurso compartido global entre sellos, su configuración es ligeramente diferente de los demás recursos globales. Front Door debe volver a configurarse después de implementar un nuevo stamp. También debe volver a configurarse para cambiar gradualmente el tráfico a los nuevos stamps.
La configuración de back-end de Front Door no se puede definir directamente en la plantilla de Terraform. La configuración se inserta con variables de Terraform. Los valores de variable se construyen antes de iniciar la implementación de Terraform.
La configuración de componentes individuales para la implementación de Front Door se define como:
Frontend - la afinidad de sesión está configurada para asegurarse de que los usuarios no cambien entre distintas versiones de la interfaz de usuario durante una sola sesión.
Orígenes: Front Door está configurado con dos tipos de grupos de origen:
Un grupo de origen para el almacenamiento estático que sirve a la interfaz de usuario. El grupo contiene las cuentas de almacenamiento del sitio web de todas las unidades de versión activas actualmente. Se pueden asignar diferentes pesos a los orígenes de diferentes unidades de versión para mover gradualmente el tráfico a una unidad más reciente. Cada origen de una unidad de versión debe tener asignado el mismo peso.
Un grupo de origen para la API, que se hospeda en Azure Kubernetes Service. Si hay unidades de versión con diferentes versiones de API, existe un grupo de origen de API para cada unidad de versión. Si todas las unidades de versión ofrecen la misma API compatible, todos los orígenes se agregan al mismo grupo y se asignan pesos diferentes.
reglas de enrutamiento: hay dos tipos de reglas de enrutamiento:
Regla de enrutamiento para la interfaz de usuario vinculada al grupo de origen de almacenamiento de la interfaz de usuario.
Una regla de enrutamiento para cada API admitida actualmente por los orígenes. Por ejemplo:
/api/1.0/*y/api/2.0/*.
Si una versión presenta una nueva versión de las API de back-end, los cambios se reflejan en la interfaz de usuario que se implementa como parte de la versión. Una versión específica de la interfaz de usuario siempre llama a una versión específica de la dirección URL de la API. Los usuarios servidos por una versión de la interfaz de usuario usan automáticamente la API de back-end correspondiente. Se necesitan reglas de enrutamiento específicas para diferentes instancias de la versión de la API. Estas reglas están vinculadas a los grupos de origen correspondientes. Si no se introdujo una nueva API, todas las reglas de enrutamiento relacionadas con la API se vinculan al grupo de origen único. En este caso, no importa si un usuario recibe la interfaz de usuario de una versión diferente de la API.
Implementación: proceso de implementación
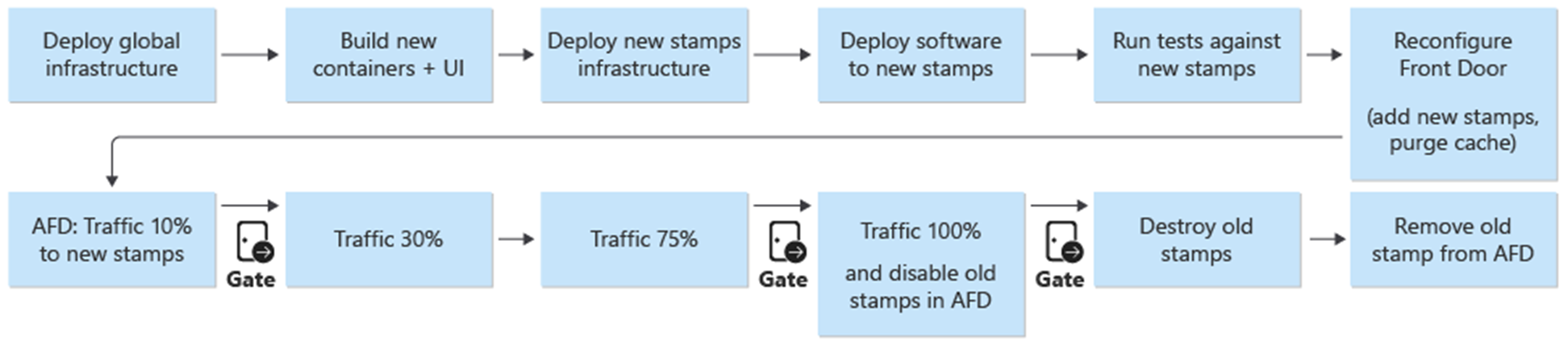
Una implementación azul/verde es el objetivo del proceso de implementación. Una nueva versión de una rama de release/* se implementa en el entorno de prod. El tráfico de usuario se desplaza gradualmente a los stamps de la nueva versión.
Como primer paso en el proceso de implementación de una nueva versión, la infraestructura de la nueva unidad de versión se implementa con Terraform. La ejecución de la canalización de implementación de la infraestructura implementa la nueva infraestructura desde una rama de versión seleccionada. En paralelo al aprovisionamiento de infraestructura, las imágenes de contenedor se compilan o importan e insertan en el registro de contenedor compartido global (ACR). Cuando se completan los procesos anteriores, la aplicación se implementa en los stamps. Desde el punto de vista de la implementación, es una canalización con varias fases dependientes. La misma canalización se puede volver a ejecutar para la implementación de revisiones.
Una vez implementada y validada la nueva unidad de versión, la nueva unidad se agrega a Front Door para recibir tráfico de usuario.
Debe planearse un modificador o parámetro que distinga entre los lanzamientos que introducen y no introducen una nueva versión de API. En función de si la versión presenta una nueva versión de API, se debe crear un nuevo grupo de origen con los back-end de API. Como alternativa, se pueden agregar nuevos back-end de API a un grupo de origen existente. Las nuevas cuentas de almacenamiento de la interfaz de usuario se agregan al grupo de origen existente correspondiente. Los pesos de los nuevos orígenes deben establecerse según la división deseada del tráfico. Se debe crear una nueva regla de enrutamiento como se ha descrito anteriormente que corresponda al grupo de origen adecuado.
Al agregar la nueva unidad de versión, los pesos de los nuevos orígenes deben establecerse en el tráfico de usuario mínimo deseado. Si no se detecta ningún problema, la cantidad de tráfico de usuario debe aumentarse al nuevo grupo de origen durante un período de tiempo. Para ajustar los parámetros de peso, se deben volver a ejecutar los mismos pasos de implementación con los valores deseados.
Desmontaje de la unidad de versión
En la canalización de implementación de una unidad de versión, hay una fase de destrucción que quita todos los stamps una vez que ya no se necesita una unidad de versión. Todo el tráfico se mueve a una nueva versión de lanzamiento. Esta fase incluye la eliminación de referencias a unidades de versión en Front Door. Esta eliminación es fundamental para permitir el lanzamiento de una nueva versión en una fecha futura. Front Door debe apuntar a una sola unidad de versión para prepararse para la próxima versión en el futuro.
Listas de verificación
Como parte de la cadencia de lanzamiento, se debe usar una lista de comprobación previa y posterior al lanzamiento. El ejemplo siguiente es de elementos que deben estar en cualquier lista de comprobación como mínimo.
lista de comprobación de versión preliminar: antes de iniciar una versión, compruebe lo siguiente:
Asegúrese de que el estado más reciente de la rama
mainse ha implementado y probado satisfactoriamente en el entornoint.Actualice el archivo de registro de cambios con una solicitud de incorporación de cambios en la rama
main.Cree una rama de
release/desde la ramamain.
Lista de comprobación posterior a la versión: antes de destruir los stamps antiguos y de quitar sus referencias de Front Door, compruebe lo siguiente:
Los clústeres ya no reciben tráfico entrante.
Event Hubs y otras colas de mensajes no contienen ningún mensaje sin procesar.
Implementación: limitaciones y riesgos de la estrategia de actualización
La estrategia de actualización descrita en esta arquitectura de referencia tiene algunas limitaciones y riesgos que se deben mencionar:
Mayor costo: al publicar actualizaciones, muchos de los componentes de infraestructura están activos dos veces durante el período de lanzamiento.
Complejidad de Front Door: el proceso de actualización de Front Door es complejo de implementar y mantener. La capacidad de ejecutar implementaciones azules o verdes eficaces con cero tiempo de inactividad depende de que funcione correctamente.
Pequeños cambios lentos: el proceso de actualización da como resultado un proceso de versión más largo para pequeños cambios. Esta limitación se puede mitigar parcialmente con el proceso de corrección rápida descrito en la sección anterior.
Implementación: Consideraciones sobre la compatibilidad hacia el futuro de los datos de la aplicación
La estrategia de actualización puede admitir varias versiones de una API y componentes de trabajo que se ejecutan simultáneamente. Dado que Azure Cosmos DB se comparte entre dos o más versiones, existe la posibilidad de que los elementos de datos modificados por una versión no siempre coincidan con la versión de la API o los trabajos que lo consumen. Las capas de API y los trabajos deben implementar un diseño de compatibilidad con versiones posteriores. Las versiones anteriores de la API o los componentes de trabajo procesan los datos insertados por una versión posterior de la API o del componente de trabajo. Omite las partes que no entiende.
Ensayo
La arquitectura de referencia contiene diferentes pruebas usadas en distintas fases dentro de la implementación de pruebas.
Estas pruebas incluyen:
Pruebas unitarias: estas pruebas validan que la lógica de negocios de la aplicación funciona según lo previsto. La arquitectura de referencia contiene un conjunto de ejemplos de pruebas unitarias ejecutadas automáticamente antes de cada compilación de contenedor por Azure Pipelines. Si se produce un error en alguna prueba, la canalización se detiene. Se detiene la compilación e implementación. El desarrollador debe corregir el problema antes de que la canalización se pueda ejecutar de nuevo.
Pruebas de carga: estas pruebas ayudan a evaluar la capacidad, la escalabilidad y los posibles cuellos de botella de una carga de trabajo o pila determinada. La implementación de referencia contiene un generador de carga de usuario para crear patrones de carga sintéticos que se pueden usar para simular el tráfico real. El generador de carga también se puede usar independientemente de la implementación de referencia.
Pruebas de humo: estas pruebas detectan si la infraestructura y la carga de trabajo están disponibles y actúan según lo previsto. Las pruebas de humo se ejecutan como parte de cada implementación.
pruebas de IU: estas pruebas validan que la interfaz de usuario se implementó y funciona según lo previsto. La implementación actual solo captura capturas de pantalla de varias páginas después de la implementación sin ninguna prueba real.
Pruebas de inyección de errores: estas pruebas se pueden automatizar o ejecutar manualmente. Las pruebas automatizadas en la arquitectura integran Azure Chaos Studio como parte de las canalizaciones de implementación.
Para más información, consulte Implementación y pruebas de cargas de trabajo críticas en Azure: Validación continua y pruebas
Pruebas: marcos
La implementación de referencia en línea utiliza la funcionalidad y los marcos de pruebas que hay siempre que es posible.
| Marco de referencia | Prueba | Descripción |
|---|---|---|
| NUnit | Unidad | Este marco se usa para probar unitariamente la parte de .NET Core de la implementación. Azure Pipelines ejecuta pruebas unitarias automáticamente antes de las compilaciones de contenedores. |
| JMeter con Azure Load Testing | Cargar | Azure Load Testing es un servicio administrado que se utiliza para ejecutar definiciones de pruebas de carga con Apache JMeter. |
| Locust | Cargar | Locust es un marco de pruebas de carga de código abierto escrito en Python. |
| dramaturgo | Interfaz de usuario y humo | Playwright es una biblioteca de código abierto Node.js para automatizar Chromium, Firefox y WebKit con una sola API. La definición de prueba de Playwright también se puede usar independientemente de la implementación de referencia. |
| Azure Chaos Studio | Inserción de errores | La implementación de referencia usa Azure Chaos Studio como paso opcional en la canalización de validación de extremo a extremo para introducir errores en la validación de resiliencia. |
Pruebas: pruebas de inserción de errores e ingeniería de caos
Las aplicaciones distribuidas deben ser resistentes a interrupciones de servicio y componentes. Las pruebas de inyección de errores (también conocidas como inyección de errores o ingeniería de caos) son la práctica de someter aplicaciones y servicios a tensiones y errores reales.
La resistencia es una propiedad de un sistema completo y la inserción de errores ayuda a encontrar problemas en la aplicación. Solucionar estos problemas ayuda a validar la resistencia de la aplicación a condiciones poco confiables, dependencias que faltan y otros errores.
Las pruebas manuales y automáticas se pueden ejecutar en la infraestructura para encontrar errores y problemas en la implementación.
Automático
La arquitectura de referencia integra Azure Chaos Studio para implementar y ejecutar un conjunto de experimentos de Azure Chaos Studio con el fin de insertar varios errores en el nivel de stamp. Los experimentos de Caos se pueden ejecutar como una parte opcional de la canalización de implementación E2E. Cuando se ejecutan las pruebas, la prueba de carga opcional siempre se ejecuta en paralelo. La prueba de carga se utiliza para generar carga en el clúster y validar el efecto de los fallos inyectados.
Manual
Las pruebas manuales de inserción de errores deben realizarse en un entorno de validación E2E. Este entorno garantiza pruebas completas representativas sin riesgo de interferencias de otros entornos. La mayoría de los errores generados con las pruebas se pueden observar directamente en la vista Métricas en directo de Application Insights. Los errores restantes están disponibles en la vista Errores y las tablas de registro correspondientes. Otros errores requieren una depuración más profunda, como el uso de kubectl para observar el comportamiento dentro de Azure Kubernetes Service.
Los siguientes son dos ejemplos de pruebas de inserción de errores realizadas en la arquitectura de referencia:
Inyección de fallos basada en DNS (servicio de nombres de dominio): un caso de prueba que puede simular varios problemas. Errores de resolución DNS debido al fallo de un servidor DNS o de Azure DNS. Las pruebas basadas en DNS pueden ayudar a simular problemas generales de conexiones entre un cliente y un servicio, por ejemplo, cuando el BackgroundProcessor no se puede conectar a Event Hubs.
En escenarios de host único, puede modificar el archivo local
hostspara sobrescribir la resolución de DNS. En un entorno mayor con varios servidores dinámicos como AKS, un archivohostsno es factible. Azure Private DNS Zones se pueden usar como una alternativa para probar escenarios de fallo.Azure Event Hubs y Azure Cosmos DB son dos de los servicios de Azure que se usan dentro de la implementación de referencia que se pueden usar para insertar errores basados en DNS. La resolución DNS de Event Hubs se puede manipular con una zona DNS privada de Azure vinculada a la red virtual de uno de los stamps. Azure Cosmos DB es un servicio replicado globalmente con puntos de conexión regionales específicos. La manipulación de los registros DNS para esos puntos de conexión puede simular un error para una región específica y probar la conmutación por error de los clientes.
bloqueo del firewall: la mayoría de los servicios de Azure admiten restricciones de acceso del firewall basadas en redes virtuales y/o direcciones IP. En la infraestructura de referencia, estas restricciones se usan para restringir el acceso a Azure Cosmos DB o Event Hubs. Un procedimiento sencillo consiste en quitar reglas Permitir o agregar nuevas reglas Bloquear. Este procedimiento puede simular errores de configuración del firewall o interrupciones de servicio.
Los siguientes servicios de ejemplo de la implementación de referencia se pueden probar con una prueba de firewall:
Servicio Resultado Key Vault Cuando se bloquea el acceso a Key Vault, el efecto más directo es el error de generación de los nuevos pods. El controlador CSI de Key Vault que captura secretos al iniciar el pod no puede realizar sus tareas e impide que el pod se inicie. Los mensajes de error correspondientes se pueden observar con kubectl describe po CatalogService-deploy-my-new-pod -n workload. Los pods que ya hay siguen funcionando, aunque se observa el mismo mensaje de error. Los resultados de la comprobación periódica de actualizaciones de secretos generan el mensaje de error. Aunque no se ha probado, la ejecución de una implementación no funciona mientras Key Vault no es accesible. Las tareas de Terraform y la CLI de Azure en la ejecución de la canalización realizan solicitudes a Key Vault.Centros de Eventos Cuando se bloquea el acceso a Event Hubs, los mensajes nuevos enviados por el CatalogService y el HealthService no se envían. Las recuperaciones de mensajes por el proceso en segundo plano fallan de manera gradual, fallando completamente en unos pocos minutos. Azure Cosmos DB La eliminación de la directiva de firewall actual para una red virtual da como resultado que el servicio de mantenimiento comience a dar error con un retraso mínimo. Este procedimiento solo simula un caso específico, una interrupción completa de Azure Cosmos DB. La mayoría de los casos de error que se producen en un nivel regional se mitigan automáticamente con la conmutación por error transparente del cliente en otra región de Azure Cosmos DB. Las pruebas de inyección de errores basadas en DNS descritas anteriormente son una prueba más significativa para Azure Cosmos DB. Registro de contenedores (ACR) Cuando se bloquea el acceso a ACR, la creación de nuevos pods que se habían extraído y almacenado en caché antes en un nodo de AKS continúa funcionando. La creación sigue funcionando por la marca de implementación K8s pullPolicy=IfNotPresent. Los nodos que no han extraído y almacenado en caché una imagen antes del bloqueo no pueden generar un nuevo pod y producen erroresErrImagePullde inmediato.kubectl describe podmuestra el mensaje de403 Forbiddencorrespondiente.Equilibrador de carga de entrada de AKS La modificación de las reglas de entrada para HTTP(S)(puertos 80 y 443) en el grupo de seguridad de red (NSG) administrado de AKS para Denegar los resultados en el tráfico de sondeo de estado o de usuario no llega al clúster. En la prueba de este error, es difícil identificar la causa principal, que se simula como un bloqueo entre la ruta de acceso de red de Front Door y un stamp regional. Front Door detecta inmediatamente este error y excluye el stamp de la rotación.