Consideraciones sobre la plataforma de aplicaciones para las cargas de trabajo críticas
Un área de diseño clave de cualquier arquitectura crítica es la plataforma de aplicaciones. La plataforma hace referencia a los componentes de infraestructura y los servicios de Azure que se deben aprovisionar para admitir la aplicación. Estas son algunas recomendaciones generales.
Diseño en capas. Elija el conjunto adecuado de servicios, su configuración y las dependencias específicas de la aplicación. Este enfoque por capas ayuda a crear una segmentación lógica y física. Resulta útil para definir roles y funciones, así como para asignar privilegios adecuados y estrategias de implementación. En última instancia, este enfoque aumenta la confiabilidad del sistema.
Una aplicación crítica debe ser altamente confiable y resistente a los errores regionales y del centro de datos. La estrategia principal es la creación de redundancia de zona y regional en una configuración activo-activo. A medida que elija servicios de Azure para la plataforma de la aplicación, tenga en cuenta su compatibilidad e implementación con Availability Zones y los patrones operativos para usar varias regiones de Azure.
Use una arquitectura basada en unidades de escalado para controlar el aumento de la carga. Las unidades de escalado permiten agrupar lógicamente los recursos y una unidad se puede escalar independientemente de otras unidades o servicios de la arquitectura. Use el modelo de capacidad y el rendimiento esperado para definir los límites, el número y la escala de línea base de cada unidad.
En esta arquitectura, la plataforma de aplicaciones consta de recursos globales, de stamp de implementación y regionales. Los recursos regionales se aprovisionan como parte de un stamp de implementación. Cada stamp equivale a una unidad de escalado y, en caso de que pase a un estado incorrecto, se puede reemplazar completamente.
Los recursos de cada capa tienen características distintas: Para más información, consulte Patrón de arquitectura de una carga de trabajo crítica típica.
| Características | Consideraciones |
|---|---|
| Período de duración | ¿Cuál es la duración esperada del recurso, en relación con otros recursos de la solución? ¿El recurso debe sobrevivir o compartir la duración con todo el sistema o la región, o debería ser temporal? |
| State | ¿Qué impacto tendrá el estado persistente en esta capa en cuanto a confiabilidad o capacidad de administración? |
| Cobertura | ¿Es necesario distribuir globalmente el recurso? ¿El recurso se puede comunicar con otros recursos, globalmente o en regiones? |
| Dependencias | ¿Cuál es la dependencia de otros recursos, globalmente o en otras regiones? |
| Límites de escalado | ¿Cuál es el rendimiento esperado para ese recurso en esa capa? ¿Cuánta escala proporciona el recurso para ajustarse a esa demanda? |
| Disponibilidad y recuperación ante desastres | ¿Cuál es el impacto en la disponibilidad o la recuperación ante desastres en esta capa? ¿Provocaría una interrupción del sistema o solo una incidencia de disponibilidad o capacidad localizada? |
Recursos globales
Algunos recursos de esta arquitectura los comparten los recursos implementados en las regiones. En esta arquitectura, se usan para distribuir el tráfico entre varias regiones, almacenar el estado permanente de toda la aplicación y almacenar en caché los datos estáticos globales.
| Características | Consideraciones sobre las capas |
|---|---|
| Período de duración | Se espera que estos recursos sean de larga vida. Su duración abarca la vida del sistema o más tiempo. A menudo, los recursos se administran con actualizaciones locales del plano de datos y el plano de control, suponiendo que admitan operaciones de actualización sin tiempo de inactividad. |
| State | Dado que estos recursos existen durante al menos la duración del sistema, esta capa suele ser responsable de almacenar el estado global y replicado geográficamente. |
| Cobertura | Los recursos se deben distribuir globalmente. Se recomienda que estos recursos se comuniquen con los recursos regionales u otros recursos con baja latencia y la coherencia deseada. |
| Dependencias | Los recursos deben evitar dependencias de los recursos regionales, porque su falta de disponibilidad puede ser una causa de un error global. Por ejemplo, los certificados o secretos guardados en un único almacén podrían tener un impacto global si se produce un error en la región en la que se encuentra el almacén. |
| Límites de escalado | A menudo, estos recursos son instancias singleton del sistema y, por lo tanto, deben ser capaces de escalarse de forma que puedan controlar el rendimiento del sistema en su conjunto. |
| Disponibilidad y recuperación ante desastres | Dado que los recursos regionales y de stamp pueden consumir recursos globales o estos se colocan delante de ellos, es fundamental que los recursos globales estén configurados con alta disponibilidad y recuperación ante desastres para tener un estado correcto de todo el sistema. |
En esta arquitectura, los recursos de la capa global son Azure Front Door, Azure Cosmos DB, Azure Container Registry y Azure Log Analytics para almacenar los registros y las métricas de otros recursos de la capa global.
Hay otros recursos fundamentales en este diseño, como Microsoft Entra ID y Azure DNS. Se han omitido en esta imagen por motivos de brevedad.

Equilibrador de carga global
Azure Front Door se usa como único punto de entrada del tráfico de usuario. Azure garantiza que Azure Front Door entregará el contenido solicitado sin error el 99,99 % del tiempo. Para más información, consulte Límites de los servicios de nivel Estándar/Prémium de Azure Front Door. Si Front Door deja de estar disponible, el usuario final verá el sistema como inactivo.
La instancia de Front Door envía el tráfico a los servicios de back-end configurados, como el clúster de proceso que hospeda la API y la SPA de front-end. Las configuraciones incorrectas del back-end en Front Door pueden provocar interrupciones. Para evitar interrupciones debido a configuraciones incorrectas, debe probar exhaustivamente la configuración de Front Door.
Otro error común puede proceder de certificados TLS mal configurados o que faltan, lo que puede impedir que los usuarios usen el front-end o que Front Door se comunique con el back-end. La mitigación puede requerir intervención manual. Por ejemplo, puede optar por revertir a la configuración anterior y volver a emitir el certificado, si es posible. Independientemente, se espera una falta de disponibilidad mientras los cambios surten efecto. Se recomienda usar los certificados administrados ofrecidos por Front Door para reducir la sobrecarga operativa, como el control de la expiración.
Front Door ofrece muchas funcionalidades adicionales además del enrutamiento del tráfico global. Una funcionalidad importante es Web Application Firewall (WAF), ya que Front Door es capaz de inspeccionar el tráfico que pasa por él. Cuando se configura en el modo de prevención, bloqueará el tráfico sospechoso antes de llegar a cualquiera de los back-end.
Para más información sobre las funcionalidades de Front Door, consulte Preguntas más frecuentes sobre Azure Front Door.
Para conocer otras consideraciones sobre la distribución global del tráfico, consulte Guía crítica en el marco de buena arquitectura: enrutamiento global.
Container Registry
Azure Container Registry se usa para almacenar artefactos de Open Container Initiative (OCI), específicamente gráficos de Helm e imágenes de contenedor. No participa en el flujo de las solicitudes y solo se accede periódicamente. Es necesario que el registro de contenedor exista antes de implementar los recursos de stamp y no debe depender de los recursos de la capa regional.
Habilite la redundancia de zona y la replicación geográfica de los registros para que el acceso en tiempo de ejecución a las imágenes sea rápido y resistente a los errores. En caso de falta de disponibilidad, la instancia puede conmutar por error a las regiones de réplica y las solicitudes se vuelven a enrutar automáticamente a otra región. Se esperan errores transitorios en la extracción de imágenes hasta que se complete la conmutación por error.
También pueden producirse errores si las imágenes se eliminan accidentalmente, los nuevos nodos de proceso no podrán extraer imágenes, pero los nodos existentes todavía pueden usar las imágenes almacenadas en caché. La estrategia principal para la recuperación ante desastres es la reimplementación. Los artefactos de un registro de contenedor se pueden volver a generar desde canalizaciones. El registro de contenedor debe ser capaz de soportar muchas conexiones simultáneas para admitir todas las implementaciones.
Se recomienda usar la SKU Premium para habilitar la replicación geográfica. La característica de redundancia de zona garantiza la resistencia y la alta disponibilidad dentro de una región específica. En caso de una interrupción regional, las réplicas de otras regiones siguen estando disponibles para las operaciones del plano de datos. Con esta SKU, puede restringir el acceso a las imágenes mediante puntos de conexión privados.
Para obtener más información, consulte Procedimientos recomendados para Azure Container Registry.
Base de datos
Se recomienda almacenar todo el estado globalmente en una base de datos independiente de los stamps regionales. Cree redundancia mediante la implementación de la base de datos en varias regiones. En el caso de las cargas de trabajo críticas, la sincronización de datos entre regiones debe ser la principal preocupación. Además, en caso de error, las solicitudes de escritura en la base de datos deben seguir siendo funcionales.
Se recomienda la replicación de datos en una configuración activo-activo. La aplicación debe poder conectarse al instante con otra región. Todas las instancias deben poder controlar las solicitudes de lectura y escritura.
Para más información, consulta Plataforma de datos para cargas de trabajo críticas.
Supervisión global
Azure Log Analytics se usa para almacenar registros de diagnóstico de todos los recursos globales. Se recomienda restringir la cuota diaria en el almacenamiento, especialmente en los entornos que se usan para las pruebas de carga. Además, establezca una directiva de retención. Estas restricciones impedirán cualquier exceso de gasto en el que se incurra al almacenar datos que no sean necesarios más allá de un límite.
Consideraciones sobre los servicios fundamentales
Es probable que el sistema use otros servicios de plataforma críticos que puedan hacer que todo el sistema esté en riesgo, como Azure DNS y Microsoft Entra ID. Azure DNS garantiza un Acuerdo de Nivel de Servicio de disponibilidad del 100 % para las solicitudes DNS válidas. Microsoft Entra garantiza al menos un tiempo de actividad del 99,99 %. Aun así, debe tener en cuenta el impacto en caso de error.
La dependencia sobre los servicios fundamentales es inevitable porque muchos servicios de Azure dependen de ellos. Si no están disponibles, se esperan interrupciones en el sistema. Por ejemplo:
- Azure Front Door usa Azure DNS para acceder al back-end y a otros servicios globales.
- Azure Container Registry usa Azure DNS para conmutar por error las solicitudes a otra región.
En ambos casos, ambos servicios de Azure se verán afectados si Azure DNS no está disponible. Se producirá un error en la resolución de nombres para las solicitudes de usuario de Front Door; las imágenes de Docker no se extraerán del registro. El uso de un servicio DNS externo como respaldo no mitigará el riesgo porque muchos servicios de Azure no permiten dicha configuración y dependen del DNS interno. Se espera una interrupción completa.
Del mismo modo, Microsoft Entra ID se usa para las operaciones del plano de control, como la creación de nuevos nodos de AKS, la extracción de imágenes de Container Registry o el acceso a Key Vault en el inicio del pod. Si Microsoft Entra ID no está disponible, los componentes existentes no deben verse afectados, pero el rendimiento general puede degradarse. Los nuevos pods y nodos de AKS no serán funcionales. Por lo tanto, en caso de que se requieran operaciones de escalado horizontal durante este tiempo, se espera una disminución de la experiencia del usuario.
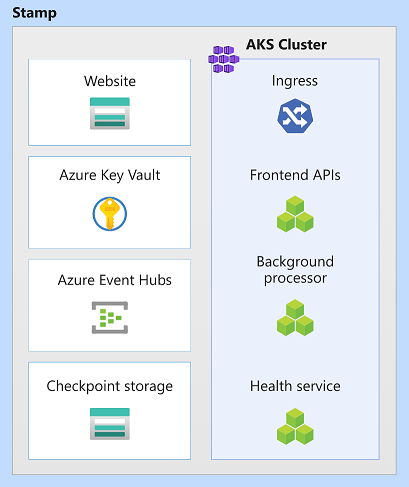
Recursos de stamp de implementación regional
En esta arquitectura, el stamp de implementación implementa la carga de trabajo y aprovisiona los recursos que participan en la finalización de las transacciones empresariales. Normalmente, un stamp se corresponde a una implementación en una región de Azure. Aunque una región puede tener más de un stamp.
| Características | Consideraciones |
|---|---|
| Período de duración | Se espera que los recursos tengan un período de vida corto (efímero) con la intención de que se puedan agregar y quitar dinámicamente mientras los recursos regionales fuera del stamp se continúan conservando. Esta naturaleza efímera es necesaria para proporcionar más resistencia, escala y proximidad a los usuarios. |
| State | Dado que los stamps son efímeros y se pueden destruir en cualquier momento, un stamp debe ser sin estado tanto como sea posible. |
| Cobertura | Pueden comunicarse con los recursos regionales y globales. Sin embargo, se debe evitar la comunicación con otras regiones u otros stamps. En esta arquitectura, no es necesario que estos recursos se distribuyan globalmente. |
| Dependencias | Los recursos de stamp deben ser independientes. Es decir, no deben depender de otros stamps ni de componentes de otras regiones. Se espera que tengan dependencias regionales y globales. El componente compartido principal es la capa de base de datos y el registro de contenedor. Este componente requiere sincronización en tiempo de ejecución. |
| Límites de escalado | El rendimiento se establece mediante las pruebas. El rendimiento general del stamp está limitado al recurso con menor rendimiento. El rendimiento del stamp debe tener en cuenta el alto nivel estimado de la demanda y cualquier conmutación por error como resultado de que otro stamp de la región deje de estar disponible. |
| Disponibilidad y recuperación ante desastres | Debido a la naturaleza temporal de los stamps, la recuperación ante desastres se lleva a cabo mediante la reimplementación del stamp. Si los recursos están en un estado incorrecto, se puede destruir y volver a implementar el stamp en su conjunto. |
En esta arquitectura, los recursos de stamp son Azure Kubernetes Service, Azure Event Hubs, Azure Key Vault y Azure Blob Storage.
Unidad de escalado
También se puede pensar en un stamp como una unidad de escalado (SU). Todos los componentes y servicios de un stamp determinado se configuran y prueban para atender solicitudes en un intervalo determinado. Este es un ejemplo de una unidad de escalado que se usa en la implementación.
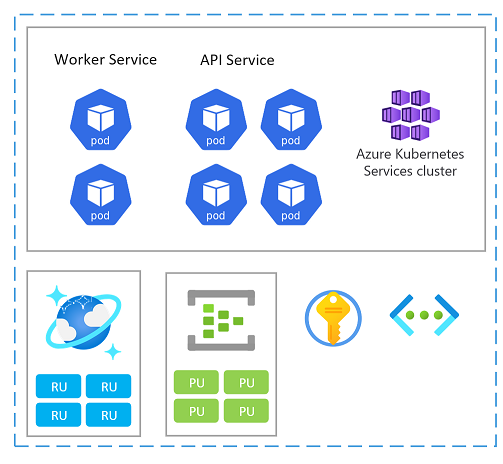
Cada unidad de escalado se implementa en una región de Azure y, por lo tanto, controla principalmente el tráfico de ese área determinada (aunque puede asumir el tráfico de otras regiones cuando sea necesario). Esta distribución geográfica probablemente dará lugar a patrones de carga y horas laborables que pueden variar de región a región y, por tanto, cada SU está diseñada para su reducción horizontal o vertical cuando está inactiva.
Para el escalado, puede implementar un nuevo stamp. Dentro de un stamp, los recursos individuales también pueden ser unidades de escalado.
Estas son algunas consideraciones sobre el escalado y la disponibilidad al elegir servicios de Azure en una unidad:
Evalúe las relaciones de capacidad entre todos los recursos de una unidad de escalado. Por ejemplo, para controlar 100 solicitudes entrantes, se necesitarían 5 pods de controlador de entrada y 3 pods de servicio de catálogo y 1000 RU en Azure Cosmos DB. Por lo tanto, al escalar automáticamente los pods de entrada, se espera el escalado del servicio de catálogo y las RU de Azure Cosmos DB según esos intervalos.
Lleve a cabo pruebas de carga de los servicios para determinar un intervalo dentro del cual se atenderán las solicitudes. En función de los resultados, configure las instancias mínimas y máximas, y las métricas objetivo. Cuando se alcance el objetivo, puede optar por automatizar el escalado de toda la unidad.
Revise los límites y cuotas de escalado de las suscripciones de Azure para admitir la capacidad y el modelo de costo establecidos por los requisitos empresariales. Compruebe también los límites de los servicios individuales en consideración. Dado que las unidades normalmente se implementan juntas, tenga en cuenta los límites de recursos de la suscripción necesarios para las implementaciones de valor controlado. Para más información, consulte Límites, cuotas y restricciones de suscripción y servicios de Microsoft Azure.
Elija servicios que admitan zonas de disponibilidad para crear redundancia. Esto podría limitar las opciones tecnológicas. Consulte Servicios de Azure compatibles con zonas de disponibilidad para obtener más información.
Para otras consideraciones sobre el tamaño de una unidad y la combinación de recursos, consulte Guía crítica en el marco de buena arquitectura: arquitectura de unidad de escalado.
Clúster de proceso
Para ejecutar en contenedores la carga de trabajo, cada stamp debe ejecutar un clúster de proceso. En esta arquitectura, se ha elegido Azure Kubernetes Service (AKS) porque Kubernetes es la plataforma de proceso más popular para aplicaciones modernas y en contenedores.
La duración del clúster de AKS está enlazada a la naturaleza efímera del stamp. El clúster no tiene estado y no tiene volúmenes persistentes. Usa discos de SO efímero en lugar de discos administrados porque no se espera que reciban mantenimiento de nivel de sistema ni de aplicación.
Para aumentar la confiabilidad, el clúster está configurado para usar las tres zonas de disponibilidad de una región determinada. Además, para habilitar el SLA de tiempo de actividad de AKS con disponibilidad garantizada del SLA del 99,95 % del plano de control de AKS, el clúster debe usar el nivel Estándar o Premium. Para obtener más información, consulte Niveles de precios de AKS.
Otros factores también pueden afectar a la confiabilidad, como los límites de escala, la capacidad de proceso o la cuota de la suscripción. Si no hay suficiente capacidad o se alcanzan los límites, se producirá un error en las operaciones de escalado horizontal y escalado vertical, pero se espera que el recurso de proceso existente funcione.
El clúster tiene habilitado el escalado automático para permitir que los grupos de nodos se escalen horizontalmente automáticamente si es necesario, lo que mejora la confiabilidad. Cuando se usan varios grupos de nodos, todos los grupos de nodos se deben escalar automáticamente.
En el nivel de pod, Horizontal Pod Autoscaler (HPA) escala los pods en función de la memoria o CPU configuradas, o de métricas personalizadas. Lleve a cabo pruebas de carga de los componentes de la carga de trabajo para establecer una línea base para los valores de la escalabilidad automática y HPA.
El clúster también está configurado para las actualizaciones automáticas de imágenes de nodo y para escalar adecuadamente durante esas actualizaciones. Este escalado permite un tiempo de inactividad cero mientras se realizan las actualizaciones. Si se produce un error en el clúster de un stamp durante una actualización, otros clústeres de otros stamps no deben verse afectados, pero las actualizaciones en varios stamps se deben producir en momentos diferentes para mantener la disponibilidad. Además, las actualizaciones del clúster se desplazan automáticamente por los nodos para evitar que estén no disponibles al mismo tiempo.
Algunos componentes, como cert-manager e ingress-nginx, requieren imágenes de contenedor de registros de contenedor externos. Si esos repositorios o imágenes no están disponibles, es posible que las nuevas instancias de los nodos nuevos (en los que la imagen no está almacenada en caché) no se puedan iniciar. Este riesgo se podría mitigar importando estas imágenes a la instancia de Azure Container Registry del entorno.
La observabilidad es fundamental en esta arquitectura, ya que los stamps son efímeros. La configuración de diagnóstico se establece para almacenar todos los datos de registro y las métricas en un área de trabajo de Log Analytics regional. Además, AKS Container Insights está habilitado mediante un agente de OMS en clúster. Este agente permite al clúster enviar datos de supervisión al área de trabajo de Log Analytics.
Para conocer otras consideraciones sobre el clúster de proceso, consulte Guía crítica en el marco de buena arquitectura: orquestación de contenedores y Kubernetes.
Key Vault
Azure Key Vault se usa para almacenar secretos globales, como las cadenas de conexión a la base de datos y los secretos de stamp, como la cadena de conexión de Event Hubs.
Esta arquitectura usa un controlador CSI del almacén de secretos en el clúster de proceso para obtener los secretos de Key Vault. Los secretos son necesarios cuando se generan nuevos pods. Si Key Vault no está disponible, es posible que los nuevos pods no se inicien. Como resultado, podría haber interrupciones; las operaciones de escalado horizontal pueden verse afectadas, las actualizaciones pueden producir errores y no se pueden ejecutar nuevas implementaciones.
Key Vault tiene un límite en el número de operaciones. Debido a la actualización automática de los secretos, se puede alcanzar el límite si hay muchos pods. Puede optar por reducir la frecuencia de las actualizaciones para evitar esta situación.
Para conocer otras consideraciones sobre la administración de secretos, consulte Guía crítica en el marco de buena arquitectura: protección de la integridad de los datos.
Event Hubs
El único servicio con estado en el stamp es el agente de mensajes, Azure Event Hubs, que almacena las solicitudes durante un breve período. El agente atiende la necesidad de almacenamiento en búfer y de mensajería confiable. Las solicitudes procesadas se conservan en la base de datos global.
En esta arquitectura, se usa la SKU Estándar y la redundancia de zona está habilitada para la alta disponibilidad.
El componente HealthService que se ejecuta en el clúster de proceso comprueba el estado de Event Hubs. Realiza comprobaciones periódicas en varios recursos. Esto es útil para detectar condiciones incorrectas. Por ejemplo, si no se pueden enviar mensajes al centro de eventos, no se puede usar el stamp para las operaciones de escritura. HealthService debe detectar automáticamente esta condición y notificar el estado incorrecto a Front Door, lo que quitará al stamp de la rotación.
Para la escalabilidad, se recomienda habilitar el inflado automático.
Para obtener más información, consulte Servicios de mensajería para cargas de trabajo críticas.
Para conocer otras consideraciones sobre la mensajería, consulte Guía crítica en el marco de buena arquitectura: mensajería asincrónica.
Cuentas de almacenamiento
En esta arquitectura, se aprovisionan dos cuentas de almacenamiento. Ambas cuentas se implementan en modo con redundancia de zona (ZRS).
Una cuenta se usa para los puntos de comprobación de Event Hubs. Si esta cuenta no responde, el stamp no podrá procesar los mensajes de Event Hubs e incluso puede afectar a otros servicios del stamp. HealthService comprueba periódicamente esta condición, que es uno de los componentes de la aplicación que se ejecutan en el clúster de proceso.
La otra se usa para hospedar la aplicación de página única de la interfaz de usuario. Si el servicio del sitio web estático tiene algún problema, Front Door detectará el problema y no enviará tráfico a esta cuenta de almacenamiento. Durante este tiempo, Front Door puede usar el contenido almacenado en caché.
Para obtener más información sobre la recuperación, consulte Recuperación ante desastres y conmutación por error de la cuenta de almacenamiento.
Recursos regionales
Un sistema puede tener recursos que se implementan en la región, pero pueden sobrevivir a los recursos de stamp. En esta arquitectura, los datos de observabilidad de los recursos de stamp se almacenan en almacenes de datos regionales.
| Características | Consideración |
|---|---|
| Período de duración | Los recursos comparten la duración de la región y sobreviven a los recursos de stamp. |
| State | El estado almacenado en una región no puede vivir más allá de la duración de la región. Si se debe compartir el estado entre regiones, considere la posibilidad de usar un almacén de datos global. |
| Cobertura | No es necesario distribuir globalmente los recursos. Se debe evitar la comunicación directa con otras regiones a toda costa. |
| Dependencias | Los recursos pueden tener dependencias en los recursos globales, pero no en los recursos de stamp, ya que los stamps están diseñados para ser de corta duración. |
| Límites de escalado | Determine el límite de escala de los recursos regionales mediante la combinación de todos los sellos de la región. |
Supervisión de los datos de los recursos de stamp
La implementación de recursos de supervisión es un ejemplo típico de recursos regionales. En esta arquitectura, cada región tiene un área de trabajo de Log Analytics individual configurada para almacenar todos los datos de registro y de métricas emitidos desde los recursos de stamp. Dado que los recursos regionales sobreviven a los recursos de stamp, los datos están disponibles incluso cuando se elimina el stamp.
Azure Log Analytics y Aplicación de Azure Insights se usan para almacenar los registros y las métricas de la plataforma. Se recomienda restringir la cuota diaria en el almacenamiento, especialmente en los entornos que se usan para las pruebas de carga. Además, establezca la directiva de retención para almacenar todos los datos. Estas restricciones impedirán cualquier exceso de gasto en el que se incurra al almacenar datos que no sean necesarios más allá de un límite.
De forma similar, Application Insights también se implementa como un recurso regional para recopilar todos los datos de supervisión de las aplicaciones.
Para obtener recomendaciones de diseño sobre la supervisión, consulte Guía crítica en el marco de buena arquitectura: modelado de estado.
Pasos siguientes
Implemente la implementación de referencia para comprender completamente los recursos utilizados en esta arquitectura y su configuración.