Muchos servicios usan un patrón de limitación para controlar los recursos que consumen, lo que impone límites en la velocidad a la que otras aplicaciones o servicios pueden acceder a ellos. Puede usar un patrón de limitación de velocidad para ayudarle a evitar o minimizar los errores de limitación relacionados con estos límites y para ayudarle a predecir con más precisión el rendimiento.
Un patrón de limitación de velocidad es adecuado en muchos escenarios, pero resulta especialmente útil para tareas automatizadas repetitivas a gran escala, como el procesamiento por lotes.
Contexto y problema
La realización de un gran número de operaciones mediante un servicio con limitaciones puede aumentar el tráfico y mejorar el rendimiento, ya que deberá realizar un seguimiento de las solicitudes rechazadas y, a continuación, reintentar esas operaciones. A medida que aumenta el número de operaciones, una limitación puede requerir varios pases de datos de reenvío, lo que resulta en un mayor impacto en el rendimiento.
Por ejemplo, considere el siguiente proceso de reintento simple en caso de error para ingerir datos en Azure Cosmos DB:
- La aplicación debe ingerir 10 000 registros en Azure Cosmos DB. La ingesta de cada registro cuesta 10 unidades de solicitud (RU), lo que requiere un total de 100 000 RU para completar el trabajo.
- La instancia de Azure Cosmos DB tiene 20 000 RU aprovisionadas.
- Envía los 10 000 registros a Azure Cosmos DB. 2000 registros se escriben correctamente y 8000 registros se rechazan.
- Los 8000 registros restantes se envían a Azure Cosmos DB. 2000 registros se escriben correctamente y 6000 registros se rechazan.
- Los 6000 registros restantes se envían a Azure Cosmos DB. 2000 registros se escriben correctamente y 4000 registros se rechazan.
- Los 4000 registros restantes se envían a Azure Cosmos DB. 2000 registros se escriben correctamente y 2000 registros se rechazan.
- Se envían los 2000 registros restantes a Azure Cosmos DB. Todos los registros se han escrito correctamente.
El trabajo de ingesta se completó correctamente, pero solo después de enviar 30 000 registros a Azure Cosmos DB, aunque todo el conjunto de datos solo conste de 10 000 registros.
Hay factores adicionales que se deben tener en cuenta en el ejemplo anterior:
- Un gran número de errores también puede dar lugar a trabajo adicional para registrar estos errores y procesar los datos de registro resultantes. Este enfoque simple habrá manipulado 20 000 errores y el registro de estos errores puede imponer un costo de recursos de procesamiento, memoria o almacenamiento.
- Al no conocer los límites del servicio de ingesta, el enfoque simple no tiene ninguna manera de establecer expectativas sobre cuánto tiempo llevará el procesamiento de datos. La limitación de velocidad puede permitirle calcular el tiempo necesario para la ingesta.
Solución
La limitación de velocidad puede reducir el tráfico y mejorar potencialmente el rendimiento al reducir el número de registros enviados a un servicio durante un período de tiempo determinado.
Un servicio puede imponer una limitación en función de métricas diferentes a lo largo del tiempo, como:
- Número de operaciones (por ejemplo, 20 solicitudes por segundo).
- Cantidad de datos (por ejemplo, 2 GiB por minuto).
- Costo relativo de las operaciones (por ejemplo, 20 000 RU por segundo).
Independientemente de la métrica usada para la limitación, la implementación de la limitación de velocidad implicará controlar el número o el tamaño de las operaciones enviadas al servicio durante un período de tiempo específico, optimizando el uso del servicio sin superar su capacidad de limitación.
En aquellos escenarios en los que las API pueden controlar las solicitudes más rápidamente de lo que lo permiten los servicios de ingesta con limitaciones, deberá administrar la rapidez con la que puede usar el servicio. Sin embargo, es arriesgado tratar la limitación únicamente como un problema de falta de coincidencia de la velocidad de datos y simplemente almacenar en búfer las solicitudes de ingesta hasta que el servicio con limitación pueda ponerse al día. Si la aplicación se bloquea en este escenario, corre el riesgo de perder cualquiera de estos datos almacenados en búfer.
Para evitar este riesgo, considere la posibilidad de enviar los registros a un sistema de mensajería duradero que pueda controlar la velocidad de ingesta total. (Los servicios como Azure Event Hubs pueden controlar millones de operaciones por segundo). Luego, puede usar uno o varios procesadores de trabajos para leer los registros del sistema de mensajería a una velocidad controlada que se encuentre dentro de los límites del servicio con limitaciones. El envío de registros al sistema de mensajería puede ahorrar memoria interna al permitirle quitar de la cola solo los registros que se pueden procesar durante un intervalo de tiempo determinado.
Azure proporciona varios servicios de mensajería duraderos que puede usar con este patrón, entre los que se incluyen:
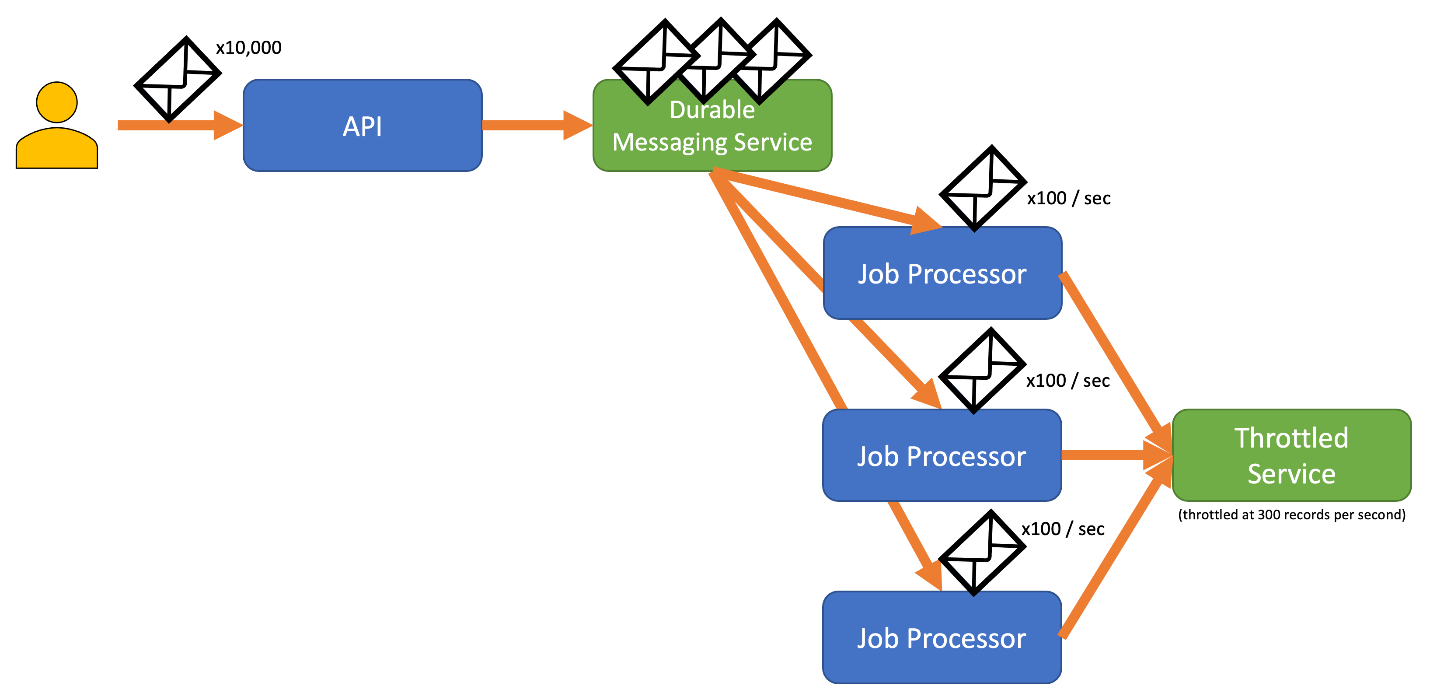
Al enviar registros, el período que se usa para liberar los registros puede ser más granular que el período en el que se limita el servicio. Los sistemas suelen establecer limitaciones basadas en períodos de tiempo que puede abarcar fácilmente y trabajar con ellos. Sin embargo, para el equipo que ejecuta un servicio, estos períodos de tiempo pueden ser muy largos en comparación con la rapidez con la que puede procesar la información. Por ejemplo, un sistema podría limitar por segundo o por minuto, pero normalmente el código se procesa en el orden de nanosegundos o milisegundos.
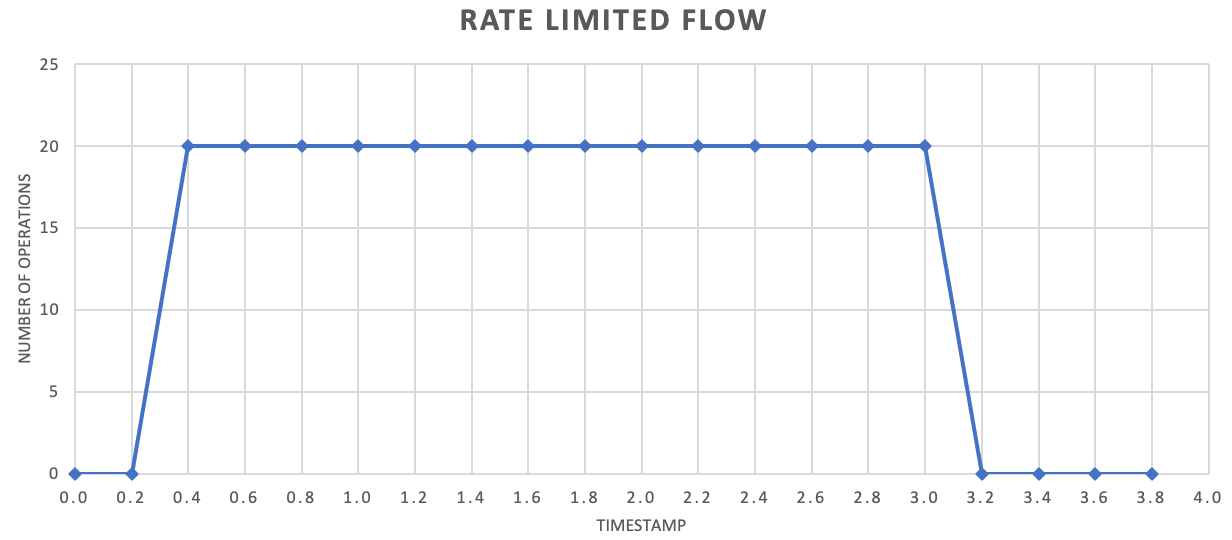
Aunque no es necesario, para mejorar el rendimiento a menudo se recomienda enviar cantidades más pequeñas de registros con mayor frecuencia. Por lo tanto, en lugar de intentar llevar a cabo un procesamiento por lotes para una liberación una vez por segundo o una vez por minuto, puede ser más granular que eso para mantener el consumo de recursos (memoria, CPU, red, etc.) fluyendo a una velocidad más uniforme, lo que evita posibles cuellos de botella debido a ráfagas repentinas de solicitudes. Por ejemplo, si un servicio permite 100 operaciones por segundo, la implementación de un limitador de velocidad puede incluso dar salida a las solicitudes liberando 20 operaciones cada 200 milisegundos, como se muestra en el gráfico siguiente.
Además, a veces es necesario que varios procesos no coordinados compartan un servicio con limitaciones. Para implementar la limitación de velocidad en este escenario, puede crear particiones lógicas de la capacidad del servicio y, después, usar un sistema de exclusión mutua distribuido para administrar bloqueos exclusivos en esas particiones. Los procesos no coordinados podrán entonces competir por los bloqueos en esas particiones siempre que necesiten capacidad. A cada partición en la que un proceso establecer un bloqueo, se le concede cierta cantidad de capacidad.
Por ejemplo, si el sistema con limitación permite 500 solicitudes por segundo, puede crear 20 particiones con 25 solicitudes por segundo cada una. Si un proceso necesitara generar 100 solicitudes, podría solicitar cuatro particiones al sistema de exclusión mutua distribuido. El sistema podría conceder dos particiones durante 10 segundos. Luego, el proceso limitaría la velocidad a 50 solicitudes por segundo, completaría la tarea en 2 segundos y liberaría el bloqueo.
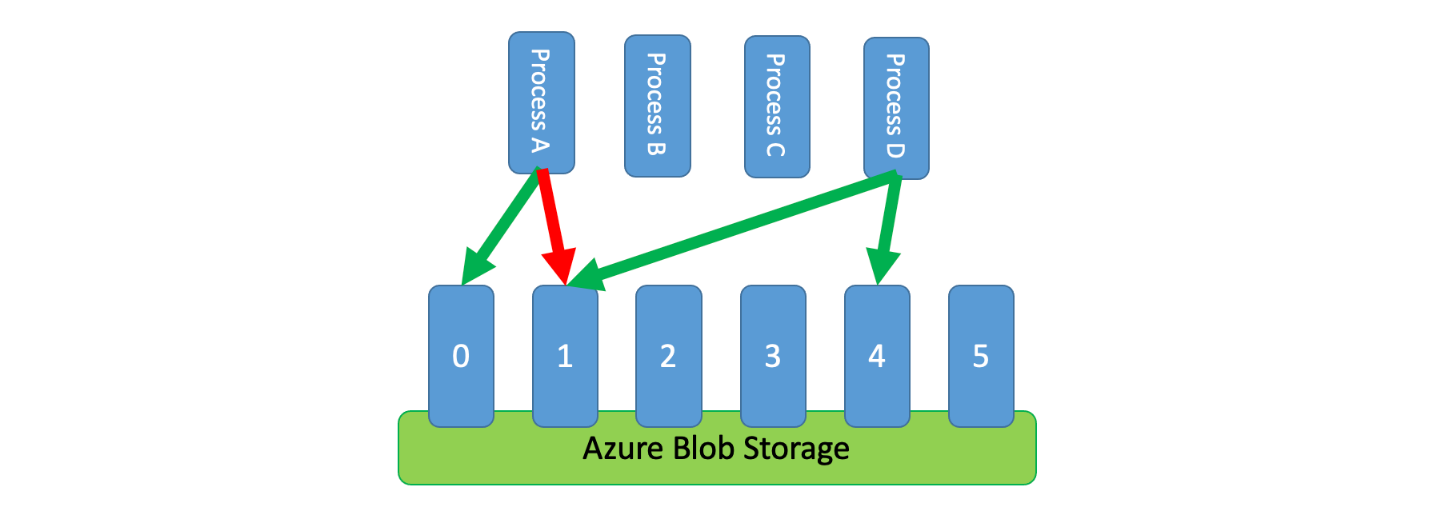
Una manera de implementar este patrón sería usar Azure Storage. En este escenario, creará un blob de 0 bytes por cada partición lógica en un contenedor. A continuación, las aplicaciones pueden obtener concesiones exclusivas directamente en esos blobs durante un breve período de tiempo (por ejemplo, 15 segundos). Para cada concesión que se concede a una aplicación, esta podrá usar la capacidad de esa partición. A continuación, la aplicación debe realizar un seguimiento del tiempo de concesión para que, cuando expire, pueda dejar de usar la capacidad que se le concedió. Al implementar este patrón, a menudo querrá que cada proceso intente obtener una concesión de una partición aleatoria cuando necesite capacidad.
Para reducir aún más la latencia, puede asignar una pequeña cantidad de capacidad exclusiva para cada proceso. De ese modo, un proceso solo buscaría obtener una concesión de capacidad compartida si fuera necesario superar su capacidad reservada.
Como alternativa a Azure Storage, también podría implementar este tipo de sistema de administración de concesiones mediante tecnologías como Zookeeper, Consul, etcd, Redis y Redsync, entre otras.
Problemas y consideraciones
Tenga en cuenta lo siguiente al decidir cómo implementar este patrón:
- Aunque el patrón de limitación de velocidad puede reducir el número de errores de limitación, la aplicación seguirá necesitando controlar correctamente los errores de limitación que puedan producirse.
- Si la aplicación tiene varias series de tareas que acceden al mismo servicio limitado, deberá integrarlas todas en la estrategia de limitación de velocidad. Por ejemplo, puede admitir la carga masiva de registros en una base de datos, pero también consultar registros en esa misma base de datos. Puede administrar la capacidad asegurándose de que todas las secuencias de trabajo se hayan limitado mediante el mismo mecanismo de limitación de velocidad. Como alternativa, puede reservar grupos de capacidad independientes para cada flujo de trabajo.
- El servicio con limitación se puede usar en varias aplicaciones. En algunos casos, pero no en todos, es posible coordinar ese uso (como se mostró anteriormente). Si empieza a ver un número mayor del esperado de errores de limitación, esto puede ser un signo de contención entre las aplicaciones que acceden a un servicio. Si es así, es posible que tenga que considerar la posibilidad de reducir temporalmente el rendimiento impuesto por el mecanismo de limitación de velocidad hasta que se reduzca el uso desde otras aplicaciones.
Cuándo usar este patrón
Este patrón se usa para:
- Reducir los errores de limitación producidos por un servicio con limitación.
- Reducir el tráfico en comparación con un enfoque de reintento simple en caso de error.
- Reducir el consumo de memoria mediante la salida de la cola de los registros solo cuando haya capacidad para procesarlos.
Diseño de cargas de trabajo
Un arquitecto debe evaluar cómo se puede usar el patrón Rate Limiting en el diseño de su carga de trabajo para abordar los objetivos y principios descritos en los pilares del Marco de buena arquitectura de Azure. Por ejemplo:
| Fundamento | Cómo apoya este patrón los objetivos de los pilares |
|---|---|
| Las decisiones de diseño de la fiabilidad ayudan a que la carga de trabajo sea resistente a los errores y a garantizar que se recupere a un estado de pleno funcionamiento después de que se produzca un error. | Esta táctica protege al cliente al reconocer y respetar las limitaciones y los costes de comunicarse con un servicio cuando el servicio desea evitar un uso excesivo. - RE:07 Conservación automática |
Al igual que con cualquier decisión de diseño, hay que tener en cuenta las ventajas y desventajas con respecto a los objetivos de los otros pilares que podrían introducirse con este patrón.
Ejemplo
La siguiente aplicación de ejemplo permite a los usuarios enviar registros de varios tipos a una API. Hay un procesador de trabajos único para cada tipo de registro que realiza los pasos siguientes:
- Validación
- Enriquecimiento
- Inserción del registro en la base de datos
Todos los componentes de la aplicación (API, procesador de trabajos A y procesador de trabajos B) son procesos independientes que se pueden escalar de forma independiente. Los procesos no se comunican directamente entre sí.
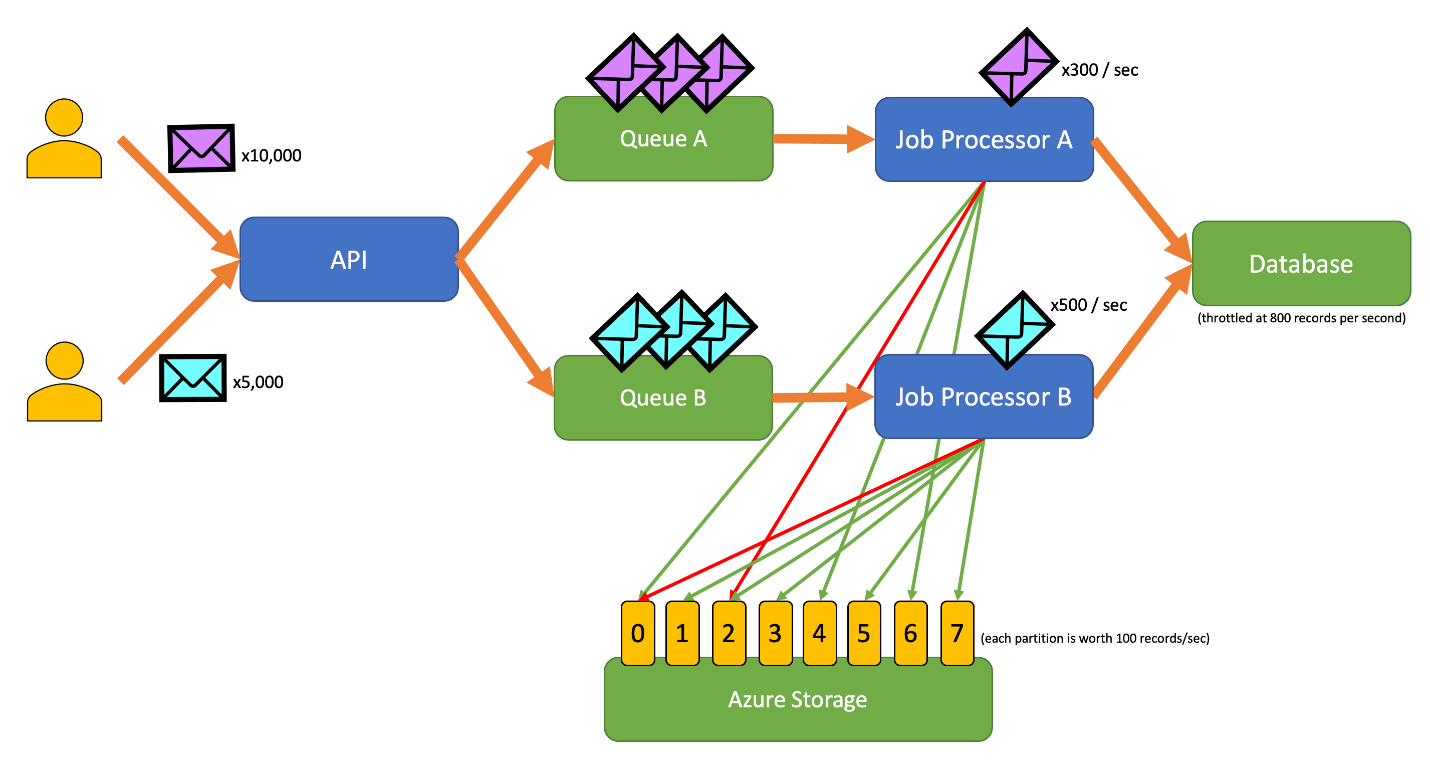
Este diagrama incorpora el siguiente flujo de trabajo:
- Un usuario envía 10 000 registros de tipo A a la API.
- La API pone en cola esos 10 000 registros en la cola A.
- Un usuario envía 5000 registros de tipo B a la API.
- La API pone en cola esos 5000 registros en la cola B.
- El procesador de trabajos A ve que la cola A tiene registros e intenta obtener una concesión exclusiva en el blob 2.
- El procesador de trabajos B ve que la cola B tiene registros e intenta obtener una concesión exclusiva en el blob 2.
- El procesador de trabajos A no puede obtener la concesión.
- El procesador de trabajos B obtiene la concesión en el blob 2 durante 15 segundos. Ahora puede limitar la velocidad de las solicitudes a la base de datos a una velocidad de 100 por segundo.
- El procesador de trabajos B quita 100 registros de la cola B y los escribe.
- Transcurre un segundo.
- El procesador de trabajos A ve que la cola A tiene más registros e intenta obtener una concesión exclusiva en el blob 6.
- El procesador de trabajos B ve que la cola B tiene más registros e intenta obtener una concesión exclusiva en el blob 3.
- El procesador de trabajos A obtiene la concesión en el blob 6 durante 15 segundos. Ahora puede limitar la velocidad de las solicitudes a la base de datos a una velocidad de 100 por segundo.
- El procesador de trabajos B obtiene la concesión en el blob 3 durante 15 segundos. Ahora puede limitar la velocidad de las solicitudes a la base de datos a una velocidad de 200 por segundo. (También mantiene la concesión del blob 2).
- El procesador de trabajos A quita 100 registros de la cola A y los escribe.
- El procesador de trabajos B quita 200 registros de la cola B y los escribe.
- Transcurre un segundo.
- El procesador de trabajos A ve que la cola A tiene más registros e intenta obtener una concesión exclusiva en el blob 0.
- El procesador de trabajos B ve que la cola B tiene más registros e intenta obtener una concesión exclusiva en el blob 1.
- El procesador de trabajos A obtiene la concesión en el blob 0 durante 15 segundos. Ahora puede limitar la velocidad de las solicitudes a la base de datos a una velocidad de 200 por segundo. (También mantiene la concesión del blob 6).
- El procesador de trabajos B obtiene la concesión en el blob 1 durante 15 segundos. Ahora puede limitar la velocidad de las solicitudes a la base de datos a una velocidad de 300 por segundo. (También mantiene la concesión de los blobs 2 y 3).
- El procesador de trabajos A quita 200 registros de la cola A y los escribe.
- El procesador de trabajos B quita 300 registros de la cola B y los escribe.
- y así sucesivamente.
Después de 15 segundos, uno o ambos trabajos todavía no se habrán completado. A medida que las concesiones expiran, un procesador también debe reducir el número de solicitudes que quita de la cola y escribe.
 Las implementaciones de este patrón están disponibles en diferentes lenguajes de programación:
Las implementaciones de este patrón están disponibles en diferentes lenguajes de programación:
- La implementación de Go está disponible en GitHub.
- La implementación de Java está disponible en GitHub.
Recursos relacionados
Los patrones y las directrices siguientes también pueden ser importantes a la hora de implementar este modelo:
- Limitaciones. El patrón de limitación de velocidad que se describe aquí normalmente se implementa en respuesta a un servicio que está limitado.
- Reintentar. Si las solicitudes a un servicio con limitación generan errores de limitación, por lo general es adecuado volver a intentar realizarlas después de un intervalo adecuado.
La nivelación de carga basada en colas es similar, pero difiere del patrón de limitación de velocidad de varias maneras principales:
- La limitación de velocidad no necesita usar colas para administrar la carga, pero sí que debe usar un servicio de mensajería duradero. Por ejemplo, un patrón de limitación de velocidad puede hacer uso de servicios como Apache Kafka o Azure Event Hubs.
- El patrón de limitación de velocidad introduce el concepto de un sistema de exclusión mutua distribuido en particiones, que permite administrar la capacidad de varios procesos no coordinados que se comunican con el mismo servicio limitado.
- El patrón de nivelación de carga basada en colas se puede aplicar siempre que haya una discrepancia de rendimiento entre los servicios o para mejorar la resistencia. Esto lo convierte en un patrón más amplio que la limitación de velocidad, que se preocupa más específicamente por el acceso eficaz a un servicio limitado.