Descentralice la lógica del flujo de trabajo y distribuya las responsabilidades a otros componentes dentro de un sistema.
Contexto y problema
Una aplicación basada en la nube se suele dividir en varios servicios pequeños que trabajan conjuntamente para procesar una transacción empresarial de un extremo a otro. Incluso una única operación (dentro de una transacción) puede dar lugar a varias llamadas punto a punto entre todos los servicios. Lo ideal sería que esos servicios tuvieran un acoplamiento flexible. Es difícil diseñar un flujo de trabajo distribuido, eficaz y escalable, ya que a menudo implica una comunicación entre servicios compleja.
Un patrón común para la comunicación es usar un servicio centralizado o un orquestador. Las solicitudes entrantes fluyen a través del orquestador a medida que delega las operaciones a los servicios respectivos. Cada servicio se limita a cumplir con su responsabilidad y no es consciente del flujo de trabajo global.
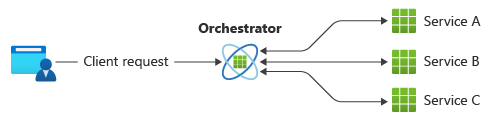
El patrón de orquestador se implementa normalmente como software personalizado y tiene conocimiento del dominio sobre las responsabilidades de esos servicios. Una ventaja es que el orquestador puede consolidar el estado de una transacción en función de los resultados de las operaciones individuales realizadas por los servicios descendentes.
No obstante, hay algunos inconvenientes. Agregar o quitar servicios puede romper la lógica existente porque hay que reorganizar partes de la ruta de comunicación. Esta dependencia hace que la implementación del orquestador sea compleja y difícil de mantener. El orquestador podría tener un impacto negativo en la fiabilidad de la carga de trabajo. Bajo carga, puede introducir cuellos de botella en el rendimiento y ser el único punto de fallo. También puede provocar errores en cascada en los servicios descendentes.
Solución
Delegue la lógica de control de transacciones entre los servicios. Deje que cada servicio decida y participe en el flujo de trabajo de comunicación para una operación empresarial.
El patrón es una manera de minimizar la dependencia del software personalizado que centraliza el flujo de trabajo de comunicación. Los componentes implementan lógica común a medida que organizan el flujo de trabajo entre sí sin tener comunicación directa entre sí.
Una manera común de implementar la organización es usar un agente de mensajes que almacena en búfer las solicitudes hasta que los componentes descendentes los reclaman y procesan. En la imagen se muestra el control de solicitudes a través de un modelo de publicador-suscriptor.
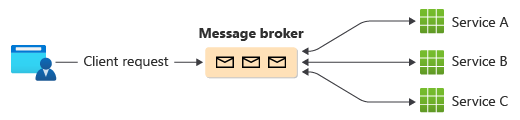
Las solicitudes de cliente se ponen en cola como mensajes en un agente de mensajes.
Los servicios o el suscriptor sondean al agente para determinar si pueden procesar ese mensaje en función de su lógica de negocios implementada. El agente también puede enviar mensajes a los suscriptores interesados en ese mensaje.
Cada servicio suscrito realiza su operación como se indica en el mensaje y responde al agente con éxito o error de la operación.
En caso de éxito, el servicio puede volver a insertar un mensaje en la misma cola o en una diferente para que otro servicio pueda continuar con el flujo de trabajo si es necesario. Si la operación falla, el agente de mensajes trabaja con otros servicios para compensar esa operación o toda la transacción.
Problemas y consideraciones
La descentralización del orquestador puede producir problemas mientras administra el flujo de trabajo.
Gestionar los errores puede ser un reto. Los componentes de una aplicación pueden realizar tareas atómicas, pero aún así pueden tener un nivel de dependencia. Un error en un componente puede afectar a otros, lo que puede provocar retrasos a la hora de completar la solicitud general.
Para controlar los errores correctamente, la implementación de transacciones de compensación podría presentar complejidad. La lógica de control de errores, como las transacciones compensatorias, también es propensa a errores.
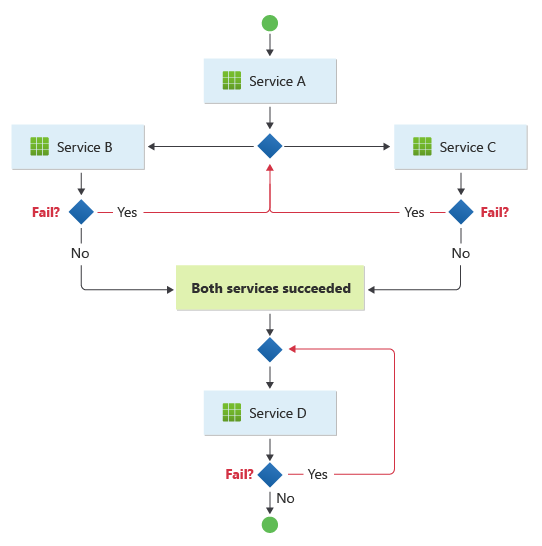
El patrón es adecuado para un flujo de trabajo en el que las operaciones empresariales independientes se procesan en paralelo. El flujo de trabajo puede ser complicado cuando la organización debe aparecer en una secuencia. Por ejemplo, el servicio D puede iniciar su operación solo después de que el servicio B y el servicio C hayan completado sus operaciones correctamente.
El patrón se convierte en un desafío si el número de servicios aumenta rápidamente. Dado el gran número de elementos móviles independientes, el flujo de trabajo entre servicios tiende a ser complejo. Además, el seguimiento distribuido se vuelve difícil, aunque las herramientas como ServiceInsight junto con NServiceBus pueden ayudar a reducir estos desafíos.
En un diseño dirigido por orquestador, el componente central puede participar parcialmente y delegar la lógica de resistencia a otro componente que reintenta errores transitorios, no transitorios y de tiempo de espera, de forma coherente. Con la disolución del orquestador en el patrón de coreografía, los componentes descendentes no deberían recoger esas tareas de resistencia. Las debe seguir controlando el controlador de resistencia. Pero ahora, los componentes descendentes deben comunicarse directamente con el controlador de resistencia, lo que aumenta la comunicación de punto a punto.
Cuándo usar este patrón
Use este patrón en los siguientes supuestos:
Los componentes descendentes controlan las operaciones atómicas de forma independiente. Piense en ello como un mecanismo de "disparar y olvidar". Un componente es responsable de una tarea que no necesita administrarse activamente. Una vez completada la tarea, envía una notificación a los demás componentes.
Se espera que los componentes se actualicen y reemplacen con frecuencia. El patrón permite modificar la aplicación con menos esfuerzo y una interrupción mínima de los servicios existentes.
El patrón es un ajuste natural para las arquitecturas sin servidor que son adecuadas para flujos de trabajo simples. Los componentes pueden ser efímeros y estar basados en eventos. Cuando se produce un evento, los componentes se activan, realizan sus tareas y se quitan una vez completada la tarea.
Este patrón puede ser una buena opción para las comunicaciones entre contextos enlazados. En el caso de las comunicaciones dentro de un contexto limitado individual, se puede considerar un patrón de orquestador.
Hay un cuello de botella de rendimiento introducido por el orquestador central.
Este modelo podría no ser útil en las situaciones siguientes:
La aplicación es compleja y requiere un componente central que controle la lógica compartida para mantener ligeros los componentes descendentes.
Hay situaciones en las que la comunicación de punto a punto entre los componentes es inevitable.
Debe consolidar todas las operaciones controladas por componentes descendentes mediante la lógica de negocios.
Diseño de cargas de trabajo
Un arquitecto debe evaluar cómo se puede usar el patrón Choreography en el diseño de su carga de trabajo para abordar los objetivos y principios descritos en los pilares del Marco de buena arquitectura de Azure. Por ejemplo:
| Fundamento | Cómo apoya este patrón los objetivos de los pilares |
|---|---|
| La excelencia operativa ayuda a ofrecer calidad de carga de trabajo a través de procesos estandarizados y cohesión de equipos. | Dado que los componentes distribuidos de este patrón son autónomos y están diseñados para poderlos reemplazar, puede modificar la carga de trabajo con menos cambios generales en el sistema. - OE:04 Herramientas y procesos |
| La eficiencia del rendimiento ayuda a que la carga de trabajo satisfaga eficazmente las demandas mediante optimizaciones en el escalado, los datos y el código. | Este patrón proporciona una alternativa cuando se producen cuellos de botella de rendimiento en una topología de orquestación centralizada. - PE:02 Planeamiento de capacidad - PE:05 Escapado y particiones |
Al igual que con cualquier decisión de diseño, hay que tener en cuenta las ventajas y desventajas con respecto a los objetivos de los otros pilares que podrían introducirse con este patrón.
Ejemplo
En este ejemplo se muestra el patrón de coreografía mediante la creación de funciones de ejecución de cargas de trabajo nativas de la nube controladas por eventos junto con microservicios. Cuando un cliente solicita que se envíe un paquete, la carga de trabajo asigna un dron. Una vez que el paquete está listo para ser recogido por el dron programado, se inicia el proceso de entrega. Mientras está en tránsito, la carga de trabajo gestiona la entrega hasta que adquiere el estado de enviado.
Este ejemplo es una refactorización de la implementación de Drone Delivery que reemplaza el patrón Orchestrator por el patrón Choreography.
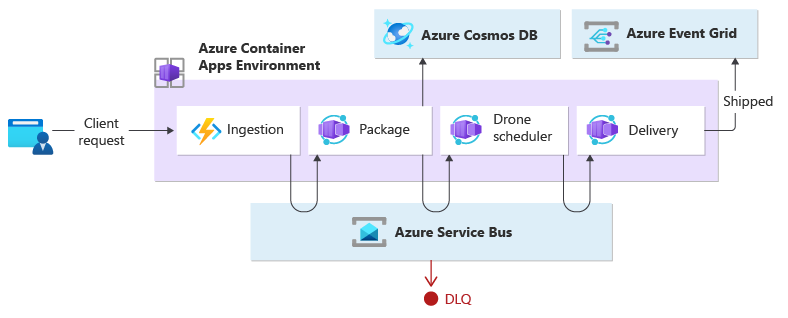
El servicio de ingesta controla las solicitudes del cliente y las convierte en mensajes, incluidos los detalles de entrega. Las transacciones empresariales se inician después de consumir esos nuevos mensajes.
Una sola transacción empresarial de cliente requiere tres operaciones empresariales distintas:
- Crear o actualizar un paquete
- Asignar un dron para entregar el paquete
- Gestionar la entrega que consiste en comprobar y, finalmente, dar a conocer cuando se envía.
Tres microservicios desempeñan el procesamiento empresarial: Servicios de empaquetado, Scheduler de drones y entrega. En lugar de un orquestador central, los servicios usan mensajería para comunicarse entre ellos. Cada servicio sería responsable de implementar un protocolo de antemano que coordine de forma descentralizada el flujo de trabajo empresarial.
Diseño
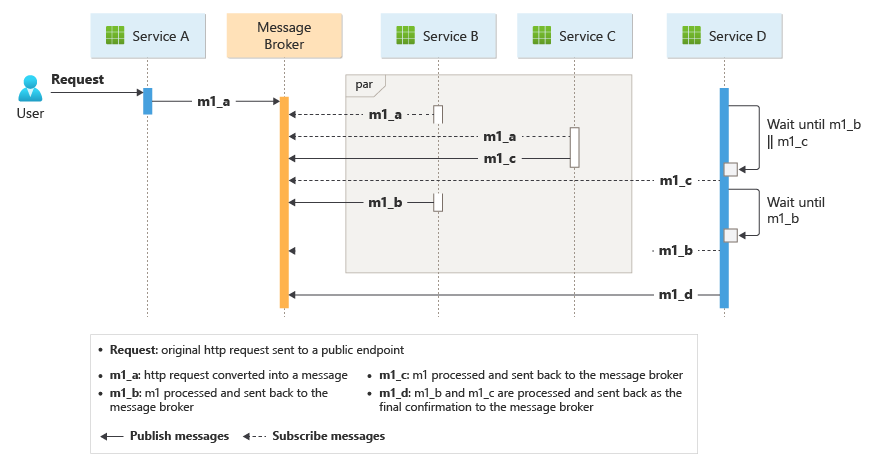
La transacción empresarial se procesa en una secuencia a través de varios saltos. Cada salto comparte un bus de un solo mensaje entre todos los servicios empresariales.
Cuando un cliente envía una solicitud de entrega a través de un punto de conexión HTTP, el servicio de ingesta lo recibe, convierte la solicitud en un mensaje y, a continuación, publica el mensaje en el bus de mensajes compartido. Los servicios empresariales suscritos van a consumir nuevos mensajes añadidos al bus. Al recibir el mensaje, los servicios empresariales pueden completar la operación correcta o incorrectamente o la solicitud puede agotar el tiempo de espera. Si se realiza correctamente, el servicio responde al bus con el código de estado correcto, genera un nuevo mensaje de operación y lo envía al bus de mensajes. Si se produce un error o se agota el tiempo de espera, el servicio notifica el error enviando el código de motivo al bus de mensajes. Además, el mensaje se agrega a una cola de mensajes fallidos. También se cambia el DLQ de los mensajes que no se pudieron recibir o procesar dentro de un período de tiempo razonable y adecuado.
El diseño utiliza varios buses de mensajes para procesar toda la transacción empresarial. Microsoft Azure Service Bus y Microsoft Azure Event Grid se crean para proporcionar la plataforma del servicio de mensajería para este diseño. La carga de trabajo se implementa en Azure Container Apps que hospeda Azure Functions para la ingesta y las aplicaciones que controlan el procesamiento controlado por eventos que ejecuta la lógica empresarial.
El diseño garantiza que la coreografía se produzca en una secuencia. Un solo espacio de nombres de Azure Service Bus contiene un tema con dos suscripciones y una cola compatible con la sesión. El servicio de ingesta publica mensajes en el tema. El servicio de paquetes y el servicio Drone Scheduler se suscriben al tema y publican mensajes que comunican el éxito a la cola. Incluir un identificador de sesión común con un GUID que se asocie al identificador de entrega permite el control ordenado de secuencias sin enlazar de mensajes relacionados. El servicio de entrega espera dos mensajes relacionados por transacción. El primer mensaje indica que el paquete está listo para enviarse y el segundo indica que se programa un dron.
Este diseño usa Azure Service Bus para controlar mensajes de alto valor que no se pueden perder ni duplicar durante todo el proceso de entrega. Cuando se envía el paquete, también se publica un cambio de estado en Azure Event Grid. En este diseño, el emisor del evento no tiene ninguna expectativa sobre cómo se controla el cambio de estado. Los servicios de organización descendentes que no se incluyen como parte de este diseño podrían estar escuchando este tipo de evento y reaccionar ejecutando lógica de propósito empresarial específica (es decir, enviar por correo electrónico el estado del pedido enviado al usuario).
Si planea implementarlo en otro servicio de proceso, como AKS, el patrón pub-sub de aplicación reutilizable podría implementarse con dos contenedores en el mismo pod. Un contenedor ejecuta el embajador que interactúa con el bus de mensajes de preferencia mientras que el otro ejecuta la lógica empresarial. El enfoque con dos contenedores en el mismo pod mejora el rendimiento y la escalabilidad. El embajador y el servicio empresarial comparten la misma red, lo que permite una baja latencia y un alto rendimiento.
Para evitar las operaciones de reintento en cascada que pueden dar lugar a varios esfuerzos, los servicios empresariales deben marcar inmediatamente los mensajes inaceptables. Es posible enriquecer los mensajes mediante códigos de motivo conocidos o un código de aplicación definido, por lo que se puede mover a una cola de mensajes fallidos (DLQ). Considere la posibilidad de administrar problemas de coherencia que implementan Saga desde servicios de bajada. Por ejemplo, otro servicio podría controlar los mensajes fallidos con fines de corrección solo mediante la ejecución de una transacción dinámica, de reintento o de compensación.
Los servicios empresariales son idempotentes para asegurarse de que las operaciones de reintento no producen recursos duplicados. Por ejemplo, el servicio de empaquetado utiliza operaciones upsert para agregar datos al almacén de datos.
Recursos relacionados
Tenga en cuenta estos patrones en el diseño de la organización.
Modulación del servicio empresarial mediante el modelo de diseño de embajador.
Implementación del patrón de equilibrio de carga basado en colas para controlar los picos de la carga de trabajo.
Uso de la mensajería distribuida asincrónica a través del patrón de publicador y suscriptor.
Use transacciones de compensación para deshacer una serie de operaciones correctas en caso de que se produzca un error en una o varias operaciones relacionadas.
Para obtener información sobre el uso de un agente de mensajes en una infraestructura de mensajería, consulte Opciones de mensajería asincrónica en Azure.
Elección entre los distintos servicios de mensajería de Azure