En este artículo se incluye una lista de elementos que debe tener en cuenta al mover una solución basada en IoT Hub a un entorno de producción.
Uso de sellos de implementación
Los stamps son unidades discretas de componentes principales de la solución que admiten un número definido de dispositivos. Cada copia se denomina stamp. o unidad de escalado. Por ejemplo, un stamp puede componerse de un conjunto de dispositivos establecido, una instancia de IoT Hub, un centro de eventos u otro punto de conexión de enrutamiento y un componente de procesamiento. Cada stamp admite un conjunto de dispositivos definido. Debe elegir el número máximo de dispositivos que puede contener el stamp. A medida que crece el conjunto de dispositivos, debe agregar instancias de stamp en lugar de escalar de forma independiente diferentes partes de la solución.
Si en lugar de agregar stamps, mueve una única instancia de la solución basada en IoT Hub a producción, puede encontrar las siguientes limitaciones:
Límites de escalado: la instancia única puede encontrar límites de escalado. Por ejemplo, puede que utilice servicios que establezcan límites con respecto al número de conexiones entrantes, los nombres de host, los sockets TCP u otros recursos.
Escalado o costo no lineal: es posible que los componentes de la solución no se escalen linealmente con el número de solicitudes realizadas o la cantidad de datos ingeridos. En cambio, en el caso de algunos componentes, puede haber una disminución en el rendimiento o un aumento en el costo una vez que se alcanza un umbral determinado. Al agregar stamps, el escalado vertical con más capacidad podría no ser una estrategia tan buena como el escalado horizontal.
Separación de clientes: en ocasiones, puede que necesite mantener los datos de algunos clientes separados de los de otros. También es posible que algunos clientes requieran más recursos del sistema que otros para atender sus solicitudes y que se plantee agruparlos en diferentes stamps.
Instancias únicas y multiinquilino: es posible que tenga algunos clientes grandes que necesiten sus propias instancias independientes de la solución. Además, es posible que tenga un grupo de clientes más pequeño que pueden compartir una implementación multiinquilino.
Requisitos de implementación complejos: es posible que tenga que implementar actualizaciones en el servicio de forma controlada e implementarlas en diferentes stamps en momentos diferentes.
Frecuencia de actualización: es posible que tenga clientes que acepten las actualizaciones frecuentes del sistema, mientras que otros pueden ser más reticentes a este riesgo y prefieran que el sistema que atiende sus solicitudes se actualice con poca frecuencia.
Restricciones geográficas o geopolíticas: para reducir la latencia o cumplir con los requisitos de soberanía de datos, puede implementar algunos de sus clientes en regiones específicas.
Para evitar los problemas anteriores, considere la posibilidad de agrupar el servicio en varios stamps. Los stamps funcionan de forma independiente entre sí y se pueden implementar y actualizar por separado. Una sola región geográfica puede contener un solo stamp, o bien varios stamps para proporcionar escalabilidad horizontal en la región. Cada stamp contiene un subconjunto de clientes.
Uso del retroceso cuando se produce un error transitorio
Todas las aplicaciones que se comunican con los recursos y servicios remotos deben ser sensibles a errores transitorios. Esto se aplica especialmente en el caso de aplicaciones que se ejecutan en la nube, donde la naturaleza del entorno y la conectividad a través de Internet significan que estos tipos de errores suelen encontrarse con más frecuencia. Entre estos errores transitorios se incluyen lo siguientes:
- Pérdida momentánea de conectividad de red con componentes y servicios.
- Servicios no disponibles temporalmente.
- Tiempos de espera que aumentan cuando un servicio está ocupado.
- Colisiones causadas cuando los dispositivos transmiten simultáneamente.
Estos errores suelen ser de corrección automática y, si la acción se repite después de un intervalo adecuado, es probable que se realice correctamente. Sin embargo, es difícil determinar los intervalos adecuados entre reintentos. Las estrategias típicas usan los siguientes tipos de intervalos de reintentos:
- Interrupción exponencial. La aplicación espera poco tiempo antes del primer reintento y, a continuación, aumenta exponencialmente los tiempos entre cada intento posterior. Por ejemplo, puede reintentar la operación después de 3 segundos, 12 segundos, 30 segundos y así sucesivamente.
- Intervalos regulares. La aplicación espera el mismo período de tiempo entre cada intento. Por ejemplo, puede reintentar la operación cada 3 segundos.
- Reintento inmediato. A veces un error transitorio es breve, quizás debido a un evento como una colisión de paquetes de red o un pico en un componente de hardware. En este caso, es conveniente volver a intentar la operación inmediatamente porque puede tener éxito si se resolvió el problema en el tiempo que tarda la aplicación en ensamblar y enviar la solicitud siguiente. Sin embargo, nunca debería haber más de un reintento inmediato y debe cambiar a estrategias alternativas, como acciones de interrupción o de conmutación por error exponenciales si se produce un error en el reintento inmediato.
- Selección aleatoria. Cualquiera de las estrategias de reintento enumeradas anteriormente pueden incluir un elemento aleatorio para evitar que varias instancias del cliente envíen reintentos posteriores al mismo tiempo.
Evite también los siguientes elementos que no siguen ningún patrón:
- Las implementaciones no deben incluir capas duplicadas del código de reintento.
- Nunca implemente un mecanismo de reintento infinito.
- Nunca realice un reintento inmediato más de una vez.
- Evite usar un intervalo de reintentos normal.
- Evite que varias instancias del mismo cliente o varias instancias de clientes diferentes, envíen reintentos al mismo tiempo.
Aprovisionamiento sin intervención del usuario
El aprovisionamiento es el acto de inscribir un dispositivo en Azure IoT Hub. El aprovisionamiento hace que IoT Hub tenga en cuenta el dispositivo y el mecanismo de atestación que usa el dispositivo. Puede usar Azure IoT Hub Device Provisioning Service (DPS) o aprovisionar directamente a través de las API de administrador de registro de IoT Hub. El uso de DPS ofrece la ventaja del enlace en tiempo de ejecución, que permite quitar y reaprovisionar dispositivos de campo para IoT Hub sin cambiar el software del dispositivo.
En este ejemplo se muestra cómo implementar un flujo de trabajo de transición de entorno de prueba a producción mediante DPS.
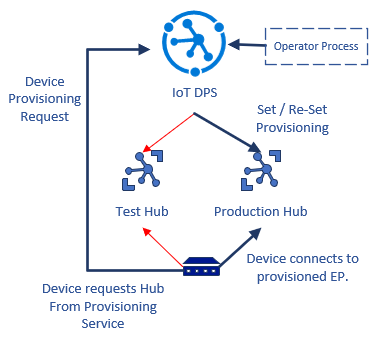
- El desarrollador de soluciones enlaza las nubes de IoT de producción y de prueba al servicio de aprovisionamiento.
- El dispositivo implementa el protocolo DPS para encontrar IoT Hub, si ya no se aprovisiona. El dispositivo se aprovisiona inicialmente en el entorno de prueba.
- Puesto que el dispositivo está registrado con el entorno de prueba, se conecta allí y se realizan las pruebas.
- El desarrollador reaprovisiona el dispositivo en el entorno de producción y lo quita de la central de pruebas. La central de pruebas rechaza el dispositivo la próxima vez que se vuelve a conectar.
- El dispositivo se conecta y vuelve a negociar el flujo de aprovisionamiento. DPS ahora dirige el dispositivo al entorno de producción y el dispositivo se conecta y se autentica allí.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Creadores de entidad de seguridad:
- Matthew Cosner | Administrador principal de ingeniería de software
- Ansley Yeo | Director de administración de programas
Para ver los perfiles no públicos de LinkedIn, inicie sesión en LinkedIn.