El éxito de la solución en la nube depende de su confiabilidad. La confiabilidad se puede definir a nivel general como la probabilidad de que el sistema funcione según lo previsto, en las condiciones del entorno especificadas, durante un tiempo establecido. La ingeniería de confiabilidad de sitios (SRE) es un conjunto de principios y prácticas para crear sistemas de software escalables y de alta confiabilidad. Cada vez más, SRE se usa durante el diseño de servicios digitales para garantizar una mayor confiabilidad.
Para más información sobre las estrategias de SRE, vea AZ-400: Desarrollo de una estrategia de Ingeniería de confiabilidad de sitios (SRE).
Posibles casos de uso
Los conceptos de este artículo se aplican a lo siguiente:
- Servicios en la nube basados en API
- Aplicaciones web de acceso público
- Cargas de trabajo basadas en IoT o en eventos
Architecture

Descargue un archivo de PowerPoint de esta arquitectura.
La arquitectura que se considera aquí es la de una plataforma de API escalable. La solución consta de varios microservicios que usan una variedad de bases de datos y servicios de almacenamiento, incluidas soluciones de software como servicio (SaaS), como Dynamics 365 y Microsoft 365.
En este artículo se considera una solución que controla los casos de uso de marketplace y comercio electrónico de alto nivel para mostrar los bloques que se representan en el diagrama. Los casos de uso son los siguientes:
- Exploración del producto
- Registro e inicio de sesión
- Visualización de contenido, como artículos de noticias
- Administración de pedidos y suscripciones
Las aplicaciones cliente, como las aplicaciones web, las aplicaciones móviles e incluso las aplicaciones de servicio, consumen los servicios de la plataforma de API a través de una ruta de acceso unificada, https://api.contoso.com.
Componentes
- Azure Front Door proporciona un punto de entrada unificado y protegido para todas las solicitudes realizadas a la solución. Para más información, vea Introducción a la arquitectura de enrutamiento.
- Azure API Management proporciona una capa de gobernanza sobre todas las API publicadas. Puede usar directivas de Azure API Management para aplicar funcionalidades adicionales en el nivel de API, como restricciones de acceso, almacenamiento en caché y transformación de datos. API Management admite el escalado automático en los niveles Estándar y Premium.
- Azure Kubernetes Service (AKS) es la implementación de Azure de los clústeres de Kubernetes de código abierto. Al ser un servicio de Kubernetes hospedado, Azure controla tareas críticas como la supervisión del estado y el mantenimiento. Como Azure administra los maestros de Kubernetes, el usuario solo administra y mantiene los nodos de agente. En esta arquitectura, todos los microservicios se implementan en AKS.
- Application Gateway es un servicio de controlador de entrega de aplicaciones. Funciona en la capa 7, la capa de aplicación, y tiene varias funcionalidades de equilibrio de carga. El controlador de entrada de Application Gateway (AGIC) es una aplicación de Kubernetes que permite que los clientes de Azure Kubernetes Service (AKS) usen el equilibrador de carga L7 nativo de Azure Application Gateway para exponer software en la nube a Internet. El escalado automático y la redundancia de zona se admiten en la SKU v2.
- Azure Storage, Azure Data Lake Storage, Azure Cosmos DB y Azure SQL pueden almacenar contenido estructurado y no estructurado. Los contenedores y las bases de datos de Azure Cosmos DB se pueden crear con rendimiento de escalabilidad automática.
- Microsoft Dynamics 365 es una oferta de software como servicio (SaaS) de Microsoft que proporciona varias aplicaciones empresariales para el servicio al cliente, ventas, marketing y finanzas. En esta arquitectura, Dynamics 365 se usa principalmente para administrar catálogos de productos y para la administración del servicio al cliente. Las unidades de escalado proporcionan resistencia a las aplicaciones de Dynamics 365.
- Microsoft 365 (anteriormente, Office 365) se usa como un sistema de administración de contenido empresarial que se basa en Microsoft 365 SharePoint en Microsoft 365. Se usa para crear, administrar y publicar contenido, como documentos y recursos multimedia.
Alternativas
Dado que esta solución usa una arquitectura de alta escalabilidad basada en microservicios, tenga en cuenta estas alternativas para el plano de proceso:
- Azure Functions para servicios de API sin servidor
- Azure Spring Apps para microservicios basados en Java
Confiabilidad adecuada
El grado de confiabilidad necesario para una solución depende del contexto empresarial. Una tienda que está abierta durante 14 horas y que tiene un pico de uso del sistema durante ese intervalo, tiene necesidades diferentes a las de una empresa en línea que acepta pedidos a todas horas. Las prácticas de SRE se pueden adaptar para lograr el nivel adecuado de confiabilidad.
La confiabilidad se define y mide mediante objetivos de nivel de servicio (objetivos de nivel de servicio (SLO)) que determinan el nivel de confiabilidad de destino de un servicio. Lograr el nivel de destino garantiza la satisfacción de los consumidores. Los objetivos SLO pueden evolucionar o cambiar en función de las demandas de la empresa. Sin embargo, los propietarios del servicio deben medir constantemente la confiabilidad con respecto a los SLO para detectar problemas y tomar medidas correctivas. Los SLO normalmente se definen como un porcentaje de logros durante un período.
Otro término importante que se debe tener en cuenta es el indicador de nivel de servicio (SLI), que es la métrica que se usa para calcular el SLO. Los SLI se basan en información derivada de los datos que se capturan a medida que el cliente utiliza el servicio. Los SLI siempre se miden desde el punto de vista de un cliente.
Los SLO y los SLI siempre van de la mano y normalmente se definen de forma iterativa. Los SLO se basan en objetivos empresariales clave, mientras que los SLI se basan en lo que se puede medir al implementar el servicio.
A continuación se muestra la relación entre la métrica supervisada, el SLI y el SLO:
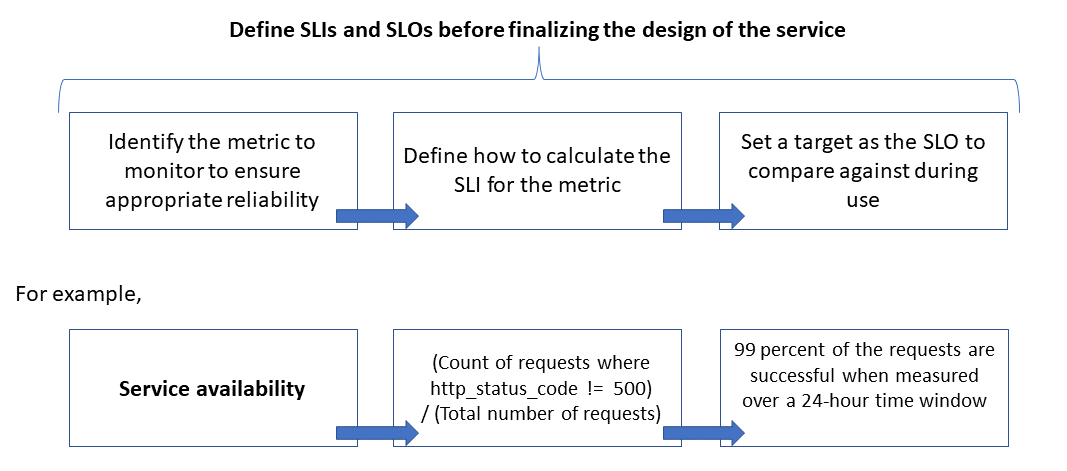
Esto se explica con más detalle en Definición de las métricas de SLI para calcular los SLO.
Modelado de las expectativas de escalabilidad y rendimiento
En el caso de un sistema de software, el rendimiento suele hacer referencia a la capacidad de respuesta general de un sistema al ejecutar una acción dentro de un tiempo especificado, mientras que la escalabilidad es la capacidad del sistema de controlar el aumento de las cargas del usuario sin mermar el rendimiento.
Un sistema se considera escalable si los recursos subyacentes están disponibles dinámicamente para admitir un aumento de la carga. Las aplicaciones en la nube deben diseñarse para la escalabilidad, y el volumen de tráfico es difícil de predecir a veces. Los picos estacionales pueden aumentar los requisitos de escalabilidad, especialmente cuando un servicio controla las solicitudes de varios inquilinos.
Es conveniente diseñar aplicaciones para que los recursos en la nube se escalen y reduzcan verticalmente de manera automática según sea necesario para satisfacer la carga. Básicamente, el sistema debe adaptarse al aumento de la carga de trabajo mediante el aprovisionamiento o la asignación de recursos de forma incremental para satisfacer la demanda. La escalabilidad no solo pertenece a las instancias de proceso, sino también a otros elementos, como la infraestructura de mensajería y almacenamiento de datos.
En este artículo se muestra cómo puede garantizar la confiabilidad adecuada para una aplicación en la nube mediante el modelado de escalabilidad y rendimiento de los escenarios de carga de trabajo y el uso de los resultados para definir los supervisores, los SLI y los SLO.
Consideraciones
Consulte los pilares Confiabilidad y Eficiencia del rendimiento del Marco de buena arquitectura de Azure para obtener instrucciones sobre la creación de aplicaciones escalables y confiables.
En este artículo se explora cómo aplicar técnicas de modelado de escalabilidad y rendimiento para adaptar la arquitectura y el diseño de la solución. Estas técnicas identifican los cambios en los flujos de transacciones para una experiencia de usuario óptima. Base sus decisiones técnicas en requisitos no funcionales de la solución. El proceso consiste en lo siguiente:
- Identificar los requisitos de escalabilidad
- Modelar la carga esperada
- Definir los SLI y los SLO para los escenarios de usuario
Nota
Azure Application Insights, que forma parte de Azure Monitor, es una eficaz herramienta de administración del rendimiento de aplicaciones (APM) que se puede integrar fácilmente con las aplicaciones para enviar telemetría y analizar métricas específicas de las aplicaciones. También proporciona paneles listos para usar y un explorador de métricas que puede usar para analizar los datos y explorar las necesidades empresariales.
Captura de los requisitos de escalabilidad
Suponga que existen estas métricas de carga máxima:
- Número de consumidores que usan la plataforma de API: 1,5 millones
- Consumidores activos por hora (30 % de 1,5 millones): 450 000
- Porcentaje de carga para cada actividad:
- Exploración del producto: 75 %
- Registro, incluida la creación de perfiles y el inicio de sesión: 10 %
- Administración de pedidos y suscripciones: 10 %
- Visualización de contenido: 5 %
La carga genera los siguientes requisitos de escalabilidad, con un pico de carga normal, para las API hospedadas en la plataforma:
- Microservicio de producto: aproximadamente 500 solicitudes por segundo (RPS)
- Microservicio de perfil: aproximadamente 100 RPS
- Microservicio de pedidos y pagos: aproximadamente 100 RPS
- Microservicio de contenido: aproximadamente 50 RPS
Estos requisitos de escalabilidad no tienen en cuenta los picos estacionales y aleatorios, ni los picos durante eventos especiales, como las promociones de marketing. Durante los picos, el requisito de escalabilidad para algunas actividades del usuario es hasta 10 veces la carga máxima normal. Tenga en cuenta estas restricciones y expectativas al tomar las decisiones de diseño para los microservicios.
Definición de métricas de SLI para calcular los SLO
Las métricas de SLI indican el grado en que un servicio proporciona una experiencia satisfactoria y se puede expresar como la proporción de eventos satisfactorios con respecto al total de eventos.
Para un servicio de API, los eventos hacen referencia a las métricas específicas de la aplicación que se capturan durante la ejecución, como datos de telemetría o procesados. Este ejemplo tiene las siguientes métricas de SLI:
| Métrica | Description |
|---|---|
| Disponibilidad | Si la API atendió la solicitud |
| Latencia | Tiempo para que la API procese la solicitud y devuelva una respuesta |
| Throughput | Número de solicitudes que la API atendió |
| Tasa de éxito | Número de solicitudes que la API atendió satisfactoriamente |
| Tasa de errores | Número de errores de las solicitudes que la API atendió |
| Actualización | Número de veces que el usuario recibió los datos más recientes para las operaciones de lectura en la API, a pesar de que el almacén de datos subyacente se actualiza con una latencia de escritura determinada |
Nota
Asegúrese de identificar los SLI adicionales que son importantes para la solución.
Estos son ejemplos de SLI:
- (Número de solicitudes que se completan correctamente en menos de 1000 ms)/(Número de solicitudes)
- (Número de resultados de búsqueda que devuelven, en un plazo de tres segundos, los productos que se publicaron en el catálogo) / (Número de búsquedas)
Después de definir los SLI, determine qué eventos o telemetría se capturarán para medirlos. Por ejemplo, para medir la disponibilidad, capture eventos para indicar si el servicio de API procesó correctamente una solicitud. Para los servicios basados en HTTP, el éxito o el error se indica con códigos de estado HTTP. El diseño y la implementación de la API deben proporcionar los códigos adecuados. En general, las métricas de SLI son una entrada importante para la implementación de la API.
En el caso de los sistemas basados en la nube, puede obtener algunas de las métricas mediante la compatibilidad con el diagnóstico y la supervisión que está disponible para los recursos. Azure Monitor es una solución completa para recopilar, analizar y actuar en la telemetría desde los servicios en la nube. En función de los requisitos de SLI, se pueden capturar más datos de supervisión para calcular las métricas.
Uso de distribuciones de percentiles
Algunos SLI se calculan mediante una técnica de distribución de percentiles. Esto proporciona mejores resultados si hay valores atípicos que pueden distorsionar otras técnicas, como las distribuciones de valores medios o medianas.
Por ejemplo, tenga en cuenta que la métrica es la latencia de las solicitudes de API, y tres segundos es el umbral para un rendimiento óptimo. Los tiempos de respuesta ordenados para una hora de solicitudes de API muestran que algunas solicitudes tardan más de tres segundos y la mayoría recibe respuestas dentro del límite del umbral. Este es el comportamiento esperado del sistema.
La distribución de percentiles está pensada para excluir valores atípicos causados por problemas intermitentes. Por ejemplo, si las respuestas de servicio adecuadas se encuentran en el percentil 90 o 95, se considera que se cumple el SLO.
Elección de períodos de medición adecuados
El período de medición para definir un SLO es muy importante. Debe capturar la actividad, no la inactividad, para que los resultados sean significativos para la experiencia del usuario. Esta ventana puede ser de cinco minutos a 24 horas, dependiendo de cómo quiera supervisar y calcular la métrica de SLI.
Establecimiento de un proceso de gobernanza del rendimiento
El rendimiento de una API debe administrarse desde su inicio hasta que quede en desuso o se retire. Debe haber un proceso de gobernanza sólido para asegurarse de que los problemas de rendimiento se detectan y se solucionan pronto, antes de provocar una interrupción importante que afecte al negocio.
Estos son los elementos de la gobernanza del rendimiento:
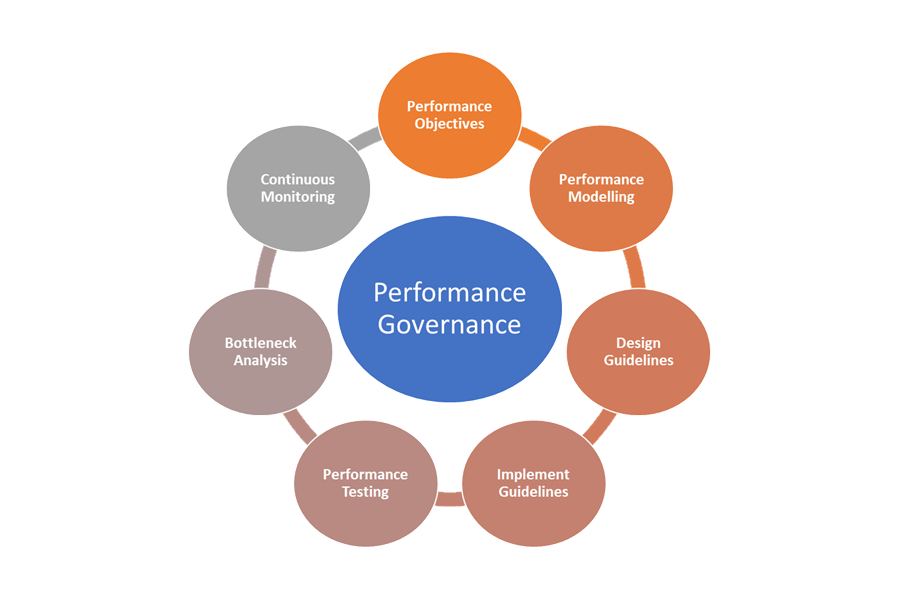
- Objetivos de rendimiento : defina los SLO de rendimiento esperados para los escenarios empresariales.
- Modelado del rendimiento: identifique flujos de trabajo y transacciones críticos para la empresa y realice el modelado para comprender las implicaciones relacionadas con el rendimiento. Capture esta información en un nivel granular para predicciones más precisas.
- Directrices de diseño: prepare las directrices de diseño de rendimiento y recomiende las modificaciones adecuadas del flujo de trabajo empresarial. Asegúrese de que los equipos entiendan estas directrices.
- Implementar las directrices: implemente directrices de diseño de rendimiento para los componentes de la solución, incluida la instrumentación para capturar las métricas. Realice revisiones de diseño de rendimiento. Es fundamental realizar un seguimiento de todos estos aspectos mediante elementos de trabajo pendiente de la arquitectura para los distintos equipos.
- Pruebas de rendimiento: realice pruebas de carga y esfuerzo de acuerdo con la distribución del perfil de carga para capturar las métricas relacionadas con el estado de la plataforma. También puede realizar estas pruebas para una carga limitada, a fin de medir los requisitos de la infraestructura de la solución.
- Análisis de cuellos de botella: use la inspección de código y las revisiones de código para identificar, analizar y eliminar cuellos de botella de rendimiento en varios componentes. Identifique las mejoras de escalado horizontal o vertical necesarias para admitir las cargas máximas.
- Supervisión continua: establezca una infraestructura de supervisión continua y alertas como parte de los procesos de DevOps. Asegúrese de que se notifica a los equipos afectados cuando los tiempos de respuesta se degradan significativamente en comparación con las pruebas comparativas.
- Gobernanza del rendimiento: establezca una gobernanza del rendimiento que conste de procesos y equipos bien definidos para mantener los SLO de rendimiento. Realice un seguimiento del cumplimiento después de cada lanzamiento para evitar cualquier degradación debido a las actualizaciones de compilación. Realice revisiones periódicamente para evaluar el aumento de la carga a fin de identificar las actualizaciones de la solución.
Asegúrese de repetir los pasos durante todo el desarrollo de la solución como parte del proceso de elaboración progresiva.
Seguimiento de los objetivos y las expectativas de rendimiento en el trabajo pendiente
Realice un seguimiento de los objetivos de rendimiento para ayudar a garantizar su cumplimiento. Capture casos de usuario detallados y pormenorizados para realizar el seguimiento. Esto ayudará a garantizar que los equipos de desarrollo otorguen máxima prioridad a las actividades de gobernanza del rendimiento.
Establecimiento de SLO esperados para la solución de destino
Estos son ejemplos de SLO esperados para la solución de la plataforma de API que se tienen en cuenta:
- Responde al 95 % de todas las solicitudes READ durante un día en un segundo.
- Responde al 95 % de todas las solicitudes CREATE y UPDATE durante un día en tres segundos.
- Responde al 99 % de todas las solicitudes durante un día en cinco segundos y sin errores.
- Responde al 99,9 % de todas las solicitudes durante un día correctamente en cinco minutos.
- Menos del 1 % de las solicitudes durante el error de la ventana máxima de una hora.
Los SLO se pueden adaptar para satisfacer los requisitos específicos de la aplicación. Sin embargo, es fundamental que estén lo suficientemente pormenorizados para tener la claridad necesaria para garantizar la confiabilidad.
Medición de los SLO iniciales basados en datos de los registros
Los registros de supervisión se crean automáticamente cuando el servicio de API está en uso. Suponga que una semana de datos muestra lo siguiente:
- Solicitudes: 123 456
- Solicitudes correctas: 123 204
- Latencia de percentil de 90: 497 ms
- Latencia de percentil de 95: 870 ms
- Latencia de percentil de 99: 1024 ms
Estos datos generan los siguientes SLI iniciales:
- Disponibilidad = (123 204 / 123 456) = 99,8 %
- Latencia = al menos el 90 % de las solicitudes se atendieron en un plazo de 500 ms
- Latencia = al menos el 98 % de las solicitudes se atendieron en un plazo de 1000 ms
Suponga que, durante el planeamiento, el objetivo de SLO de latencia esperado es que el 90 % de las solicitudes se procese en un plazo de 500 ms con una tasa de éxito del 99 % durante un período de una semana. Con los datos de registro, puede identificar fácilmente si se ha cumplido el destino de SLO. Si hace este tipo de análisis durante unas semanas, puede empezar a ver las tendencias en torno al cumplimiento de los SLO.
Guía para la mitigación de riesgos técnicos
Use la siguiente lista de comprobación de procedimientos recomendados para mitigar los riesgos de escalabilidad y rendimiento:
- Diseñar la escalabilidad y el rendimiento.
- Asegúrese de capturar los requisitos de escalabilidad para cada escenario de usuario y carga de trabajo, incluida la estacionalidad y los picos.
- Realice el modelado del rendimiento para identificar las restricciones y los cuellos de botella del sistema.
- Administrar la deuda técnica.
- Realice un seguimiento exhaustivo de las métricas de rendimiento.
- Considere la posibilidad de usar scripts para ejecutar herramientas como K6.io, Karate y JMeter en el entorno de ensayo de desarrollo con una variedad de cargas de usuario, por ejemplo, de 50 a 100 RPS. Esto proporcionará información en los registros para detectar problemas de diseño e implementación.
- Integre los scripts de prueba automatizada como parte de los procesos de implementación continua (CD) para detectar interrupciones de la compilación.
- Tener una mentalidad de producción.
- Ajuste los umbrales de escalabilidad automática tal y como indican las estadísticas de mantenimiento.
- Inclínese por técnicas de escalabilidad horizontal en lugar de vertical.
- Sea proactivo con la escalabilidad para controlar la estacionalidad.
- Decántese por la implementación basada en anillos.
- Use presupuestos de error para experimentar.
Precios
La confiabilidad, la eficacia del rendimiento y la optimización de costos van de la mano. Los servicios de Azure que se usan en la arquitectura ayudan a reducir los costos, ya que se escalan automáticamente para atender las cargas de usuario cambiantes.
Para AKS, inicialmente puede empezar con máquinas virtuales de tamaño estándar para el grupo de nodos. A continuación, puede supervisar los requisitos de recursos durante el desarrollo o el uso en producción y realizar los ajustes correspondientes.
La optimización de costos es un pilar del Marco de buena arquitectura de Microsoft Azure. Para más información, vea Información general del pilar de optimización de costos. Para calcular el costo de los productos y las configuraciones de Azure, use la calculadora de precios.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Autor principal:
- Subhajit Chatterjee | Ingeniero principal de software
Pasos siguientes
- Documentación de Azure
- Marco de buena arquitectura de Microsoft Azure
- Estilo de arquitectura de microservicios
- Diseño de escalado horizontal
- Elección de un servicio de proceso de Azure para la aplicación
- Arquitectura de microservicios en Azure Kubernetes Service
- ¿Qué es Azure Front Door?
- Acerca de API Management
- ¿Qué es el controlador de entrada de Application Gateway?
- Azure Kubernetes Service
- Escalabilidad automática y Application Gateway con redundancia de zona v2
- Escalar automáticamente un clúster para satisfacer las necesidades de la aplicación en Azure Kubernetes Service (AKS)
- Creación de contenedores y bases de datos de Azure Cosmos DB con rendimiento de escalabilidad automática
- Documentación de Microsoft Dynamics 365
- Documentación de Microsoft 365
- Documentación acerca de la ingeniería de confiabilidad de sitios
- AZ-400: Desarrollo de una estrategia de Ingeniería de confiabilidad de sitios (SRE)
- Aplicación web de línea base con redundancia de zona