En este artículo se describen algunas estrategias para crear particiones de datos en varios almacenes de datos de Azure. Para obtener instrucciones generales sobre cuándo crear particiones de datos y procedimientos recomendados, consulte Creación de particiones de datos.
Creación de particiones de Azure SQL Database
Una base de datos SQL única tiene un límite para el volumen de datos que puede contener. El rendimiento está restringido por factores arquitectónicos y el número de conexiones simultáneas que admite.
grupos elásticos admiten el escalado horizontal para una base de datos SQL. Con grupos elásticos, puede dividir los datos en particiones que se distribuyen entre varias bases de datos SQL. También puede agregar o quitar particiones a medida que el volumen de datos que necesita controlar crece y reduce. Los grupos elásticos también pueden ayudar a reducir la contención mediante la distribución de la carga entre bases de datos.
Cada partición se implementa como una base de datos SQL. Una partición puede contener más de un conjunto de datos (denominado shardlet). Cada base de datos mantiene metadatos que describen los shardlets que contiene. Un shardlet puede ser un solo elemento de datos o un grupo de elementos que comparten la misma clave de shardlet. Por ejemplo, en una aplicación multiinquilino, la clave shardlet puede ser el identificador de inquilino y todos los datos de un inquilino se pueden mantener en el mismo shardlet.
Las aplicaciones cliente son responsables de asociar un conjunto de datos con una clave de shardlet. Una base de datos SQL independiente actúa como administrador global de mapas de particiones. Esta base de datos tiene una lista de todas las particiones y shardlets del sistema. La aplicación se conecta a la base de datos del administrador de mapas de particiones para obtener una copia del mapa de particiones. Almacena en caché el mapa de particiones localmente y usa el mapa para enrutar las solicitudes de datos a la partición adecuada. Esta funcionalidad está oculta detrás de una serie de API contenidas en la biblioteca cliente de Elastic Database, que está disponible para Java y .NET.
Para más información sobre los grupos elásticos, consulte Escalado horizontal con Azure SQL Database.
Para reducir la latencia y mejorar la disponibilidad, puede replicar la base de datos global del administrador de mapas de particiones. Con los planes de tarifa Premium, puede configurar la replicación geográfica activa para copiar continuamente datos en bases de datos de diferentes regiones.
También puede usar azure SQL Data Sync o azure Data Factory para replicar la base de datos del administrador de mapas de particiones entre regiones. Esta forma de replicación se ejecuta periódicamente y es más adecuada si el mapa de particiones cambia con poca frecuencia y no requiere el nivel Premium.
Elastic Database proporciona dos esquemas para asignar datos a shardlets y almacenarlos en particiones:
Un mapa de particiones de lista asocia una sola clave a un shardlet. Por ejemplo, en un sistema multiinquilino, los datos de cada inquilino se pueden asociar a una clave única y almacenarse en su propio shardlet. Para garantizar el aislamiento, cada shardlet se puede mantener dentro de su propia partición.

Descargue un archivo de Visio de este diagrama.
Un mapa de particiones de intervalo de asocia un conjunto de valores de clave contiguos a un shardlet. Por ejemplo, puede agrupar los datos de un conjunto de inquilinos (cada uno con su propia clave) dentro del mismo shardlet. Este esquema es menos costoso que el primero, ya que los inquilinos comparten el almacenamiento de datos, pero tienen menos aislamiento.

Descargar un de archivo de Visio de de este diagrama
Una sola partición puede contener los datos de varios shardlets. Por ejemplo, puede usar shardlets de lista para almacenar datos para distintos inquilinos no contiguos en la misma partición. También puede mezclar shardlets de rango y shardlets de lista en la misma partición, aunque se abordarán a través de mapas diferentes. En el diagrama siguiente se muestra este enfoque:

Descargue un archivo de Visio de este diagrama.
Los grupos elásticos permiten agregar y quitar particiones a medida que el volumen de datos se reduce y crece. Las aplicaciones cliente pueden crear y eliminar particiones dinámicamente y actualizar de forma transparente el administrador de mapas de particiones. Sin embargo, quitar una partición es una operación destructiva que también requiere eliminar todos los datos de esa partición.
Si una aplicación necesita dividir una partición en dos particiones independientes o combinar particiones, use la herramienta de división y combinación de . Esta herramienta se ejecuta como un servicio web de Azure y migra datos de forma segura entre particiones.
El esquema de partición puede afectar significativamente al rendimiento del sistema. También puede afectar a la velocidad a la que se deben agregar o quitar particiones, o que los datos se deben volver a particionar entre particiones. Tenga en cuenta los siguientes puntos:
Agrupa los datos que se usan juntos en la misma partición y evitan las operaciones que acceden a los datos de varias particiones. Una partición es una base de datos SQL de su propio derecho y las combinaciones entre bases de datos deben realizarse en el lado cliente.
Aunque SQL Database no admite combinaciones entre bases de datos, puede usar las herramientas de Elastic Database para realizar consultas de varias particiones. Una consulta de varias particiones envía consultas individuales a cada base de datos y combina los resultados.
No diseñe un sistema que tenga dependencias entre particiones. Las restricciones de integridad referencial, los desencadenadores y los procedimientos almacenados de una base de datos no pueden hacer referencia a objetos de otra.
Si tiene datos de referencia que usan las consultas con frecuencia, considere la posibilidad de replicar estos datos entre particiones. Este enfoque puede quitar la necesidad de unir datos entre bases de datos. Idealmente, estos datos deben ser estáticos o de movimiento lento, para minimizar el esfuerzo de replicación y reducir las posibilidades de que se vuelva obsoleto.
Los Shardlets que pertenecen al mismo mapa de particiones deben tener el mismo esquema. Sql Database no aplica esta regla, pero la administración y la consulta de datos se vuelven muy complejas si cada shardlet tiene un esquema diferente. En su lugar, cree asignaciones de particiones independientes para cada esquema. Recuerde que los datos que pertenecen a diferentes shardlets se pueden almacenar en la misma partición.
Las operaciones transaccionales solo se admiten para los datos dentro de una partición y no entre particiones. Las transacciones pueden abarcar shardlets siempre que formen parte de la misma partición. Por lo tanto, si la lógica de negocios necesita realizar transacciones, almacene los datos en la misma partición o implemente la coherencia final.
Coloque particiones cerca de los usuarios que acceden a los datos de esas particiones. Esta estrategia ayuda a reducir la latencia.
Evite tener una mezcla de particiones muy activas y relativamente inactivas. Intente distribuir la carga uniformemente entre particiones. Esto puede requerir hash de las claves de particionamiento. Si está localizando geográficamente particiones, asegúrese de que las claves hash se asignan a shardlets contenidos en particiones almacenadas cerca de los usuarios que acceden a esos datos.
Creación de particiones en Azure Table Storage
Azure Table Storage es un almacén de clave-valor diseñado para crear particiones. Todas las entidades se almacenan en una partición y Azure Table Storage administra internamente las particiones. Cada entidad almacenada en una tabla debe proporcionar una clave de dos partes que incluya:
La clave de partición. Se trata de un valor de cadena que determina la partición donde Azure Table Storage colocará la entidad. Todas las entidades con la misma clave de partición se almacenan en la misma partición.
La clave de fila. Se trata de un valor de cadena que identifica la entidad dentro de la partición. Todas las entidades de una partición se ordenan léxicamente, en orden ascendente, por esta clave. La combinación de clave de partición o clave de fila debe ser única para cada entidad y no puede superar los 1 KB de longitud.
Si se agrega una entidad a una tabla con una clave de partición sin usar previamente, Azure Table Storage crea una nueva partición para esta entidad. Otras entidades con la misma clave de partición se almacenarán en la misma partición.
Este mecanismo implementa eficazmente una estrategia de escalado horizontal automático. Cada partición se almacena en el mismo servidor de un centro de datos de Azure para ayudar a garantizar que las consultas que recuperan datos de una sola partición se ejecutan rápidamente.
Microsoft ha publicado objetivos de escalabilidad para Azure Storage. Si es probable que el sistema supere estos límites, considere la posibilidad de dividir las entidades en varias tablas. Use la creación de particiones verticales para dividir los campos en los grupos a los que es más probable que se tenga acceso juntos.
En el diagrama siguiente se muestra la estructura lógica de una cuenta de almacenamiento de ejemplo. La cuenta de almacenamiento contiene tres tablas: Información del cliente, Información del producto e Información de pedido.
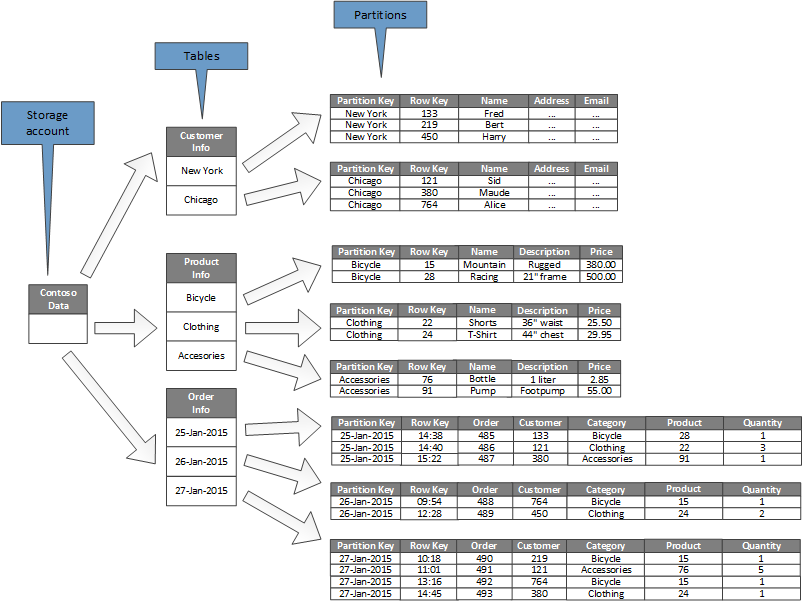
Cada tabla tiene varias particiones.
- En la tabla Información del cliente, los datos se particionan según la ciudad donde se encuentra el cliente. La clave de fila contiene el identificador de cliente.
- En la tabla Información del producto, los productos se particionan por categoría de producto y la clave de fila contiene el número de producto.
- En la tabla Información del pedido, los pedidos se particionan por fecha de pedido y la clave de fila especifica la hora en que se recibió el pedido. Todos los datos se ordenan mediante la clave de fila en cada partición.
Tenga en cuenta los siguientes puntos al diseñar las entidades para Azure Table Storage:
Seleccione una clave de partición y una clave de fila mediante el modo en que se accede a los datos. Elija una combinación de clave de partición o clave de fila que admita la mayoría de las consultas. Las consultas más eficaces recuperan datos especificando la clave de partición y la clave de fila. Las consultas que especifican una clave de partición y un intervalo de claves de fila se pueden completar mediante el examen de una sola partición. Esto es relativamente rápido porque los datos se mantienen en orden de clave de fila. Si las consultas no especifican qué partición se va a examinar, se deben examinar todas las particiones.
Si una entidad tiene una clave natural, úsela como clave de partición y especifique una cadena vacía como clave de fila. Si una entidad tiene una clave compuesta que consta de dos propiedades, seleccione la propiedad de cambio más lenta como clave de partición y la otra como clave de fila. Si una entidad tiene más de dos propiedades clave, use una concatenación de propiedades para proporcionar las claves de partición y fila.
Si realiza periódicamente consultas que buscan datos mediante campos distintos de las claves de partición y fila, considere la posibilidad de implementar el patrón de tabla de índice de o considere la posibilidad de usar un almacén de datos diferente que admita la indexación, como Azure Cosmos DB.
Si genera claves de partición mediante una secuencia monotonica (como "0001", "0002", "0003") y cada partición solo contiene una cantidad limitada de datos, Azure Table Storage puede agrupar físicamente estas particiones en el mismo servidor. Azure Storage supone que la aplicación es más probable que realice consultas en un intervalo contiguo de particiones (consultas de intervalo) y esté optimizado para este caso. Sin embargo, este enfoque puede dar lugar a zonas activas, ya que es probable que todas las inserciones de nuevas entidades se concentran en un extremo del intervalo contiguo. También puede reducir la escalabilidad. Para distribuir la carga de forma más uniforme, considere la posibilidad de aplicar un hash a la clave de partición.
Azure Table Storage admite operaciones transaccionales para entidades que pertenecen a la misma partición. Una aplicación puede realizar varias operaciones de inserción, actualización, eliminación, reemplazo o combinación como una unidad atómica, siempre y cuando la transacción no incluya más de 100 entidades y la carga de la solicitud no supere los 4 MB. Las operaciones que abarcan varias particiones no son transaccionales y pueden requerir que implemente la coherencia final. Para obtener más información sobre el almacenamiento de tablas y las transacciones, consulte Realizar transacciones de grupo de entidades.
Considere la granularidad de la clave de partición:
El uso de la misma clave de partición para cada entidad da como resultado una sola partición que se mantiene en un servidor. Esto impide que la partición se ecale horizontalmente y se centre la carga en un solo servidor. Como resultado, este enfoque solo es adecuado para almacenar un pequeño número de entidades. Sin embargo, garantiza que todas las entidades puedan participar en transacciones de grupo de entidades.
El uso de una clave de partición única para cada entidad hace que el servicio table storage cree una partición independiente para cada entidad, lo que puede dar lugar a un gran número de particiones pequeñas. Este enfoque es más escalable que usar una sola clave de partición, pero no se pueden realizar transacciones de grupo de entidades. Además, las consultas que capturan más de una entidad pueden implicar la lectura desde más de un servidor. Sin embargo, si la aplicación realiza consultas de intervalo, el uso de una secuencia monotónica para las claves de partición podría ayudar a optimizar estas consultas.
Compartir la clave de partición en un subconjunto de entidades permite agrupar entidades relacionadas en la misma partición. Las operaciones que implican entidades relacionadas se pueden realizar mediante transacciones de grupo de entidades y las consultas que capturan un conjunto de entidades relacionadas se pueden satisfacer accediendo a un único servidor.
Para más información, consulte guía de diseño de tablas de Azure Storage y estrategia de creación de particiones escalables.
Creación de particiones de Azure Blob Storage
Azure Blob Storage permite almacenar objetos binarios grandes. Use blobs en bloques en escenarios en los que necesite cargar o descargar grandes volúmenes de datos rápidamente. Use blobs en páginas para aplicaciones que requieren acceso aleatorio en lugar de serial a partes de los datos.
Cada blob (bloque o página) se mantiene en un contenedor de una cuenta de Azure Storage. Puede usar contenedores para agrupar blobs relacionados que tengan los mismos requisitos de seguridad. Esta agrupación es lógica en lugar de física. Dentro de un contenedor, cada blob tiene un nombre único.
La clave de partición de un blob es el nombre de cuenta + nombre del contenedor + nombre del blob. La clave de partición se usa para dividir los datos en intervalos y estos intervalos están equilibrados de carga en todo el sistema. Los blobs se pueden distribuir entre muchos servidores para escalar horizontalmente el acceso a ellos, pero un único blob solo puede ser servido por un único servidor.
Si el esquema de nomenclatura usa marcas de tiempo o identificadores numéricos, puede provocar un tráfico excesivo que va a una partición, lo que limita el sistema del equilibrio de carga de forma eficaz. Por ejemplo, si tiene operaciones diarias que usan un objeto de blob con una marca de tiempo como aaaa-mm-dd, todo el tráfico de esa operación irá a un único servidor de particiones. En su lugar, considere la posibilidad de prefijar el nombre con un hash de tres dígitos. Para obtener más información, consulte Convención de nomenclatura de particiones.
Las acciones de escritura de un solo bloque o página son atómicas, pero las operaciones que abarcan bloques, páginas o blobs no son. Si necesita garantizar la coherencia al realizar operaciones de escritura en bloques, páginas y blobs, sacar un bloqueo de escritura mediante una concesión de blobs.
Creación de particiones de colas de Azure Storage
Las colas de Azure Storage permiten implementar la mensajería asincrónica entre procesos. Una cuenta de Azure Storage puede contener cualquier número de colas y cada cola puede contener cualquier número de mensajes. La única limitación es el espacio disponible en la cuenta de almacenamiento. El tamaño máximo de un mensaje individual es de 64 KB. Si necesita mensajes más grandes que esto, considere la posibilidad de usar las colas de Azure Service Bus en su lugar.
Cada cola de almacenamiento tiene un nombre único dentro de la cuenta de almacenamiento que lo contiene. Las colas de particiones de Azure se basan en el nombre. Todos los mensajes de la misma cola se almacenan en la misma partición, que se controla mediante un único servidor. Los distintos servidores pueden administrar diferentes colas para ayudar a equilibrar la carga. La asignación de colas a servidores es transparente para las aplicaciones y los usuarios.
En una aplicación a gran escala, no use la misma cola de almacenamiento para todas las instancias de la aplicación, ya que este enfoque podría hacer que el servidor que hospeda la cola se convierta en un punto de acceso frecuente. En su lugar, use diferentes colas para diferentes áreas funcionales de la aplicación. Las colas de Azure Storage no admiten transacciones, por lo que dirigir los mensajes a diferentes colas debe tener poco efecto en la coherencia de la mensajería.
Una cola de Azure Storage puede controlar hasta 2000 mensajes por segundo. Si necesita procesar mensajes a una velocidad mayor que esta, considere la posibilidad de crear varias colas. Por ejemplo, en una aplicación global, cree colas de almacenamiento independientes en cuentas de almacenamiento independientes para controlar las instancias de aplicación que se ejecutan en cada región.
Creación de particiones de Azure Service Bus
Azure Service Bus usa un agente de mensajes para controlar los mensajes que se envían a una cola o tema de Service Bus. De forma predeterminada, todos los mensajes que se envían a una cola o tema se controlan mediante el mismo proceso de agente de mensajes. Esta arquitectura puede limitar el rendimiento general de la cola de mensajes. Sin embargo, también puede crear particiones de una cola o tema cuando se crea. Para ello, establezca la propiedad EnablePartitioning de la cola o descripción del tema en true.
Una cola o tema con particiones se divide en varios fragmentos, cada uno de los cuales está respaldado por un almacén de mensajes independiente y un agente de mensajes. Service Bus asume la responsabilidad de crear y administrar estos fragmentos. Cuando una aplicación publica un mensaje en una cola o tema con particiones, Service Bus asigna el mensaje a un fragmento de esa cola o tema. Cuando una aplicación recibe un mensaje de una cola o suscripción, Service Bus comprueba cada fragmento para el siguiente mensaje disponible y, a continuación, lo pasa a la aplicación para su procesamiento.
Esta estructura ayuda a distribuir la carga entre agentes de mensajes y almacenes de mensajes, lo que aumenta la escalabilidad y mejora la disponibilidad. Si el agente de mensajes o el almacén de mensajes de un fragmento no están disponibles temporalmente, Service Bus puede recuperar mensajes de uno de los fragmentos disponibles restantes.
Service Bus asigna un mensaje a un fragmento de la siguiente manera:
Si el mensaje pertenece a una sesión, todos los mensajes con el mismo valor para la propiedad SessionId de se envían al mismo fragmento.
Si el mensaje no pertenece a una sesión, pero el remitente ha especificado un valor para la propiedad PartitionKey de, todos los mensajes con el mismo valor partitionKey se envían al mismo fragmento.
Nota:
Si se especifican las propiedades SessionId y PartitionKey, deben establecerse en el mismo valor o se rechazará el mensaje.
Si no se especifican las propiedades SessionId y PartitionKey de un mensaje, pero la detección de duplicados está habilitada, se usará la propiedad MessageId. Todos los mensajes con la misma MessageId se dirigirán al mismo fragmento.
Si los mensajes no incluyen una propiedad de SessionId, PartitionKey, o MessageId, Service Bus asigna mensajes a fragmentos secuencialmente. Si un fragmento no está disponible, Service Bus pasará a la siguiente. Esto significa que un error temporal en la infraestructura de mensajería no hace que se produzca un error en la operación de envío de mensajes.
Tenga en cuenta los siguientes puntos al decidir si o cómo crear particiones de una cola de mensajes o un tema de Service Bus:
Las colas y temas de Service Bus se crean dentro del ámbito de un espacio de nombres de Service Bus. Service Bus actualmente permite hasta 100 colas o temas con particiones por espacio de nombres.
Cada espacio de nombres de Service Bus impone cuotas en los recursos disponibles, como el número de suscripciones por tema, el número de solicitudes de envío y recepción simultáneas por segundo y el número máximo de conexiones simultáneas que se pueden establecer. Estas cuotas se documentan en cuotas de Service Bus. Si espera superar estos valores, cree espacios de nombres adicionales con sus propias colas y temas, y propague el trabajo entre estos espacios de nombres. Por ejemplo, en una aplicación global, cree espacios de nombres independientes en cada región y configure instancias de aplicación para usar las colas y temas en el espacio de nombres más cercano.
Los mensajes que se envían como parte de una transacción deben especificar una clave de partición. Puede ser un SessionId, PartitionKeyo propiedad MessageId. Todos los mensajes que se envían como parte de la misma transacción deben especificar la misma clave de partición porque deben controlarse mediante el mismo proceso de agente de mensajes. No puede enviar mensajes a diferentes colas o temas dentro de la misma transacción.
Las colas y temas con particiones no se pueden configurar para que se eliminen automáticamente cuando se vuelven inactivas.
Las colas y temas con particiones no se pueden usar actualmente con el Protocolo advanced Message Queuing (AMQP) si va a crear soluciones híbridas o multiplataforma.
Creación de particiones de Azure Cosmos DB
Azure Cosmos DB para noSQL es una base de datos NoSQL para almacenar documentos JSON. Un documento de una base de datos de Azure Cosmos DB es una representación serializada por JSON de un objeto u otro fragmento de datos. No se aplican esquemas fijos, excepto que todos los documentos deben contener un identificador único.
Los documentos se organizan en colecciones. Puede agrupar documentos relacionados en una colección. Por ejemplo, en un sistema que mantiene entradas de blog, puede almacenar el contenido de cada entrada de blog como un documento de una colección. También puede crear colecciones para cada tipo de asunto. Como alternativa, en una aplicación multiinquilino, como un sistema en el que diferentes autores controlan y administran sus propias entradas de blog, puede crear particiones de blogs por autor y crear colecciones independientes para cada autor. El espacio de almacenamiento asignado a colecciones es elástico y puede reducirse o crecer según sea necesario.
Azure Cosmos DB admite la creación automática de particiones de datos en función de una clave de partición definida por la aplicación. Una partición lógica es una partición que almacena todos los datos para un único valor de clave de partición. Todos los documentos que comparten el mismo valor para la clave de partición se colocan dentro de la misma partición lógica. Azure Cosmos DB distribuye los valores según el hash de la clave de partición. Una partición lógica tiene un tamaño máximo de 20 GB. Por lo tanto, la elección de la clave de partición es una decisión importante en tiempo de diseño. Elija una propiedad con una amplia gama de valores e incluso patrones de acceso. Para más información, consulte Partición y escalado en Azure Cosmos DB.
Nota:
Cada base de datos de Azure Cosmos DB tiene un nivel de rendimiento que determina la cantidad de recursos que obtiene. Un nivel de rendimiento está asociado a un límite de velocidad de unidad de solicitud (RU). El límite de velocidad de RU especifica el volumen de recursos reservados y disponibles para uso exclusivo de esa colección. El costo de una colección depende del nivel de rendimiento seleccionado para esa colección. Cuanto mayor sea el nivel de rendimiento (y el límite de velocidad de RU) mayor será el cargo. Puede ajustar el nivel de rendimiento de una colección mediante Azure Portal. Para más información, consulte unidades de solicitud de en Azure Cosmos DB.
Si el mecanismo de creación de particiones que proporciona Azure Cosmos DB no es suficiente, es posible que tenga que particionar los datos en el nivel de aplicación. Las colecciones de documentos proporcionan un mecanismo natural para crear particiones de datos dentro de una base de datos única. La manera más sencilla de implementar el particionamiento es crear una colección para cada partición. Los contenedores son recursos lógicos y pueden abarcar uno o varios servidores. Los contenedores de tamaño fijo tienen un límite máximo de 20 GB y 10 000 RU/s de rendimiento. Los contenedores ilimitados no tienen un tamaño máximo de almacenamiento, pero deben especificar una clave de partición. Con el particionamiento de aplicaciones, la aplicación cliente debe dirigir las solicitudes a la partición adecuada, normalmente mediante la implementación de su propio mecanismo de asignación basado en algunos atributos de los datos que definen la clave de partición.
Todas las bases de datos se crean en el contexto de una cuenta de base de datos de Azure Cosmos DB. Una sola cuenta puede contener varias bases de datos y especifica en qué regiones se crean las bases de datos. Cada cuenta también aplica su propio control de acceso. Puede usar cuentas de Azure Cosmos DB para localizar geográficamente particiones (colecciones dentro de bases de datos) cerca de los usuarios que necesitan acceder a ellas y aplicar restricciones para que solo los usuarios puedan conectarse a ellas.
Tenga en cuenta los siguientes puntos al decidir cómo crear particiones de datos con Azure Cosmos DB para NoSQL:
Los recursos disponibles para una base de datos de Azure Cosmos DB están sujetos a las limitaciones de cuota de la cuenta. Cada base de datos puede contener una serie de colecciones y cada colección está asociada a un nivel de rendimiento que rige el límite de velocidad de RU (rendimiento reservado) para esa colección. Para más información, consulte límites, cuotas y restricciones de suscripción y servicio de Azure.
Cada documento debe tener un atributo que se pueda usar para identificar de forma única ese documento dentro de la colección en la que se mantiene. Este atributo es diferente de la clave de partición, que define qué colección contiene el documento. Una colección puede contener un gran número de documentos. En teoría, solo está limitado por la longitud máxima del identificador del documento. El identificador del documento puede tener hasta 255 caracteres.
Todas las operaciones en un documento se realizan en el contexto de una transacción. Las transacciones se limitan a la colección en la que está incluido el documento. Si se produce un error en una operación, el trabajo que ha realizado se revierte. Aunque un documento está sujeto a una operación, los cambios realizados están sujetos al aislamiento de nivel de instantánea. Este mecanismo garantiza que, si, por ejemplo, se produce un error en una solicitud para crear un nuevo documento, otro usuario que consulta la base de datos simultáneamente no verá un documento parcial que se quita.
Las consultas de base de datos también se limitan al nivel de colección. Una sola consulta solo puede recuperar datos de una colección. Si necesita recuperar datos de varias colecciones, debe consultar cada colección individualmente y combinar los resultados en el código de la aplicación.
Azure Cosmos DB admite elementos programables que se pueden almacenar en una colección junto con documentos. Entre ellos se incluyen procedimientos almacenados, funciones definidas por el usuario y desencadenadores (escritos en JavaScript). Estos elementos pueden tener acceso a cualquier documento de la misma colección. Además, estos elementos se ejecutan dentro del ámbito de la transacción ambiental (en el caso de un desencadenador que se desencadena como resultado de una operación de creación, eliminación o reemplazo realizada en un documento) o iniciando una nueva transacción (en el caso de un procedimiento almacenado que se ejecuta como resultado de una solicitud de cliente explícita). Si el código de un elemento programable produce una excepción, la transacción se revierte. Puede usar procedimientos almacenados y desencadenadores para mantener la integridad y la coherencia entre los documentos, pero estos documentos deben formar parte de la misma colección.
Es poco probable que las colecciones que tenga previsto contener en las bases de datos superen los límites de rendimiento definidos por los niveles de rendimiento de las colecciones. Para más información, consulte unidades de solicitud de en Azure Cosmos DB. Si prevé alcanzar estos límites, considere la posibilidad de dividir las recopilaciones entre bases de datos en distintas cuentas para reducir la carga por recopilación.
Creación de particiones de Azure AI Search
La capacidad de buscar datos suele ser el método principal de navegación y exploración proporcionado por muchas aplicaciones web. Ayuda a los usuarios a encontrar recursos rápidamente (por ejemplo, productos en una aplicación de comercio electrónico) en función de combinaciones de criterios de búsqueda. El servicio de búsqueda de IA proporciona funcionalidades de búsqueda de texto completo a través del contenido web e incluye características como escritura anticipada, consultas sugeridas basadas en coincidencias cercanas y navegación por facetas. Para obtener más información, consulte ¿Qué es la búsqueda de IA?.
AI Search almacena contenido que se puede buscar como documentos JSON en una base de datos. Los índices se definen que especifican los campos que se pueden buscar en estos documentos y se proporcionan estas definiciones a ai Search. Cuando un usuario envía una solicitud de búsqueda, AI Search usa los índices adecuados para buscar elementos coincidentes.
Para reducir la contención, el almacenamiento que usa AI Search se puede dividir en 1, 2, 3, 4, 6 o 12 particiones, y cada partición se puede replicar hasta 6 veces. El producto del número de particiones multiplicado por el número de réplicas se denomina unidad de búsqueda (SU) . Una sola instancia de AI Search puede contener un máximo de 36 SU (una base de datos con 12 particiones solo admite un máximo de 3 réplicas).
Se le factura por cada SU que se asigna al servicio. A medida que aumenta el volumen de contenido que se puede buscar o aumenta la tasa de solicitudes de búsqueda, puede agregar SU a una instancia existente de AI Search para controlar la carga adicional. AI Search distribuye los documentos uniformemente entre las particiones. Actualmente no se admiten estrategias de creación de particiones manuales.
Cada partición puede contener un máximo de 15 millones de documentos o ocupar 300 GB de espacio de almacenamiento (lo que sea menor). Puede crear hasta 50 índices. El rendimiento del servicio varía y depende de la complejidad de los documentos, de los índices disponibles y de los efectos de la latencia de red. En promedio, una sola réplica (1 SU) debe ser capaz de controlar 15 consultas por segundo (QPS), aunque se recomienda realizar pruebas comparativas con sus propios datos para obtener una medida más precisa del rendimiento. Para obtener más información, consulte límites del servicio en AI Search.
Nota:
Puede almacenar un conjunto limitado de tipos de datos en documentos que se pueden buscar, como cadenas, booleanos, datos numéricos, datos datetime y algunos datos geográficos. Para obtener más información, consulte la página tipos de datos admitidos (BÚSQUEDA de IA) en el sitio web de Microsoft.
Tiene un control limitado sobre cómo AI Search crea particiones de datos para cada instancia del servicio. Sin embargo, en un entorno global puede mejorar el rendimiento y reducir aún más la latencia y la contención mediante la creación de particiones del propio servicio mediante cualquiera de las estrategias siguientes:
Cree una instancia de AI Search en cada región geográfica y asegúrese de que las aplicaciones cliente se dirijan hacia la instancia disponible más cercana. Esta estrategia requiere que las actualizaciones del contenido que se pueda buscar se repliquen de forma oportuna en todas las instancias del servicio.
Cree dos niveles de búsqueda de IA:
- Un servicio local en cada región que contiene los datos a los que acceden los usuarios de esa región con más frecuencia. Los usuarios pueden dirigir las solicitudes aquí para obtener resultados rápidos pero limitados.
- Un servicio global que abarca todos los datos. Los usuarios pueden dirigir las solicitudes aquí para obtener resultados más lentos pero completos.
Este enfoque es más adecuado cuando hay una variación regional significativa en los datos que se buscan.
Creación de particiones de Azure Cache for Redis
Azure Cache for Redis proporciona un servicio de almacenamiento en caché compartido en la nube basado en el almacén de datos clave-valor de Redis. Como su nombre implica, Azure Cache for Redis está pensado como una solución de almacenamiento en caché. Úselo solo para almacenar datos provisionales y no como un almacén de datos permanentes. Las aplicaciones que usan Azure Cache for Redis deben poder seguir funcionando si la memoria caché no está disponible. Azure Cache for Redis admite la replicación principal o secundaria para proporcionar alta disponibilidad, pero actualmente limita el tamaño máximo de caché a 53 GB. Si necesita más espacio que este, debe crear cachés adicionales. Para más información, consulte Azure Cache for Redis.
Crear particiones en un almacén de datos Redis implica dividir los datos entre instancias del servicio Redis. Cada instancia constituye una sola partición. Azure Cache for Redis abstrae los servicios de Redis detrás de una fachada y no los expone directamente. La manera más sencilla de implementar la creación de particiones es crear varias instancias de Azure Cache for Redis y distribuir los datos entre ellas.
Puede asociar cada uno de los elementos de datos con un identificador (una clave de partición) que especifica en qué caché se almacenan. La lógica de la aplicación cliente puede usar luego este identificador para enrutar las solicitudes a la partición apropiada. Este esquema es muy sencillo, pero si cambia el esquema de partición (por ejemplo, si se crean instancias adicionales de Azure Cache for Redis), es posible que sea necesario volver a configurar las aplicaciones cliente.
Native Redis (no Azure Cache for Redis) admite la creación de particiones del lado servidor en función de la agrupación en clústeres de Redis. En este enfoque, puede dividir los datos uniformemente entre servidores mediante un mecanismo de hash. Cada servidor de Redis almacena metadatos que describen el intervalo de claves hash que contiene la partición y también contiene información sobre qué claves hash se encuentran en las particiones de otros servidores.
Las aplicaciones cliente simplemente envían solicitudes a cualquiera de los servidores de Redis participantes (probablemente el más cercano). El servidor de Redis examina la solicitud de cliente. Si se puede resolver localmente, realiza la operación solicitada. De lo contrario, reenvía la solicitud al servidor adecuado.
Este modelo se implementa mediante la agrupación en clústeres de Redis y se describe con más detalle en el tutorial del clúster de Redis página en el sitio web de Redis. La agrupación en clústeres de Redis es transparente para las aplicaciones cliente. Se pueden agregar servidores de Redis adicionales al clúster (y los datos se pueden volver a particionar) sin necesidad de volver a configurar los clientes.
Importante
Actualmente, Azure Cache for Redis admite la agrupación en clústeres de Redis en el nivel Premium.
La página Creación de particiones: cómo dividir datos entre varias instancias de Redis en el sitio web de Redis proporciona más información sobre la implementación de particiones con Redis. En el resto de esta sección se da por supuesto que está implementando particiones asistidas por proxy o del lado cliente.
Tenga en cuenta los siguientes puntos al decidir cómo crear particiones de datos con Azure Cache for Redis:
Azure Cache for Redis no está pensado para actuar como un almacén de datos permanente, por lo que sea el esquema de creación de particiones que implemente, el código de la aplicación debe poder recuperar datos de una ubicación que no sea la memoria caché.
Los datos a los que se accede con frecuencia deben conservarse en la misma partición. Redis es un almacén de clave-valor eficaz que proporciona varios mecanismos altamente optimizados para estructurar los datos. Estos mecanismos pueden ser uno de los siguientes:
- Cadenas simples (datos binarios de hasta 512 MB de longitud)
- Tipos agregados como listas (que pueden actuar como colas y pilas)
- Conjuntos (ordenados y sin ordenar)
- Hashes (que pueden agrupar campos relacionados, como los elementos que representan los campos de un objeto)
Los tipos de agregado permiten asociar muchos valores relacionados con la misma clave. Una clave de Redis identifica una lista, un conjunto o un hash en lugar de los elementos de datos que contiene. Estos tipos están disponibles con Azure Cache for Redis y se describen en la página tipos de datos de del sitio web de Redis. Por ejemplo, en parte de un sistema de comercio electrónico que realiza un seguimiento de los pedidos realizados por los clientes, los detalles de cada cliente se pueden almacenar en un hash de Redis que se clave mediante el identificador de cliente. Cada hash puede contener una colección de identificadores de pedido para el cliente. Un conjunto de Redis independiente puede contener los pedidos, de nuevo estructurados como hashes y con clave mediante el identificador de pedido. En la figura 8 se muestra esta estructura. Tenga en cuenta que Redis no implementa ninguna forma de integridad referencial, por lo que es responsabilidad del desarrollador mantener las relaciones entre los clientes y los pedidos.
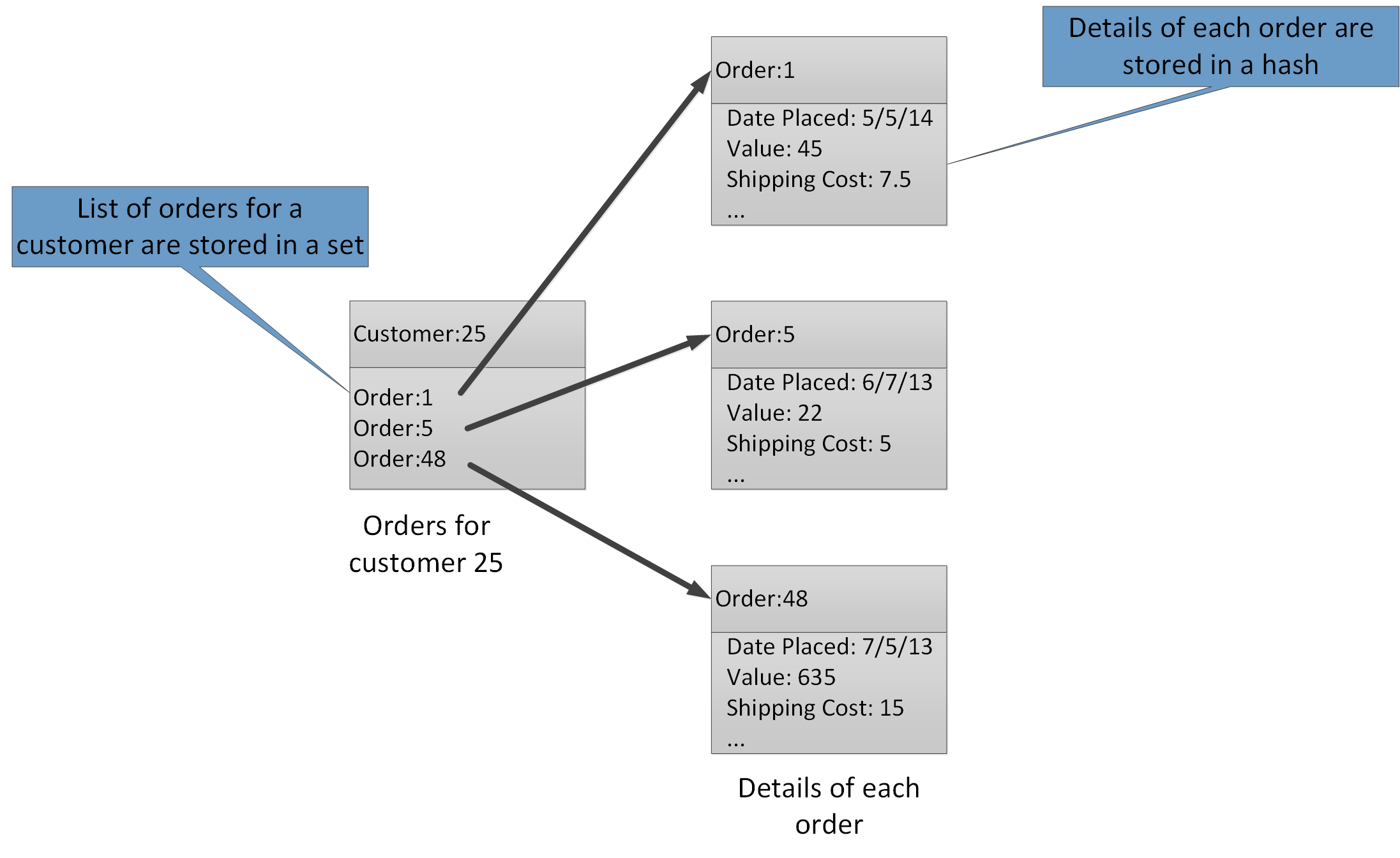
Figura 8. Estructura sugerida en El almacenamiento de Redis para registrar pedidos de clientes y sus detalles.
Nota:
En Redis, todas las claves son valores de datos binarios (como cadenas de Redis) y pueden contener hasta 512 MB de datos. En teoría, una clave puede contener casi cualquier información. Sin embargo, se recomienda adoptar una convención de nomenclatura coherente para las claves que es descriptiva del tipo de datos y que identifica la entidad, pero no es excesivamente larga. Un enfoque común consiste en usar claves del formulario "entity_type:ID". Por ejemplo, puede usar "customer:99" para indicar la clave de un cliente con el identificador 99.
Puede implementar la creación de particiones verticales almacenando información relacionada en diferentes agregaciones de la misma base de datos. Por ejemplo, en una aplicación de comercio electrónico, puede almacenar información a la que se accede con frecuencia sobre los productos en un hash de Redis y una información detallada menos usada en otra. Ambos hashes pueden usar el mismo identificador de producto como parte de la clave. Por ejemplo, puede usar "product: nn" (donde nn es el identificador del producto) para la información del producto y "product_details: nn" para los datos detallados. Esta estrategia puede ayudar a reducir el volumen de datos que es probable que la mayoría de las consultas recuperen.
Puede volver a particionar un almacén de datos de Redis, pero tenga en cuenta que es una tarea compleja y lenta. La agrupación en clústeres de Redis puede volver a particionar datos automáticamente, pero esta funcionalidad no está disponible con Azure Cache for Redis. Por lo tanto, al diseñar el esquema de partición, intente dejar suficiente espacio libre en cada partición para permitir el crecimiento esperado de los datos a lo largo del tiempo. Sin embargo, recuerde que Azure Cache for Redis está pensado para almacenar en caché los datos temporalmente y que los datos contenidos en la memoria caché pueden tener una duración limitada especificada como un valor de período de vida (TTL). Para los datos relativamente volátiles, el TTL puede ser corto, pero para los datos estáticos, el TTL puede ser mucho más largo. Evite almacenar grandes cantidades de datos de larga duración en la memoria caché si es probable que el volumen de estos datos rellene la memoria caché. Puede especificar una directiva de expulsión que haga que Azure Cache for Redis quite los datos si el espacio está en un nivel premium.
Nota:
Al usar Azure Cache for Redis, especifique el tamaño máximo de la caché (de 250 MB a 53 GB) seleccionando el plan de tarifa adecuado. Sin embargo, después de crear una instancia de Azure Cache for Redis, no puede aumentar (o disminuir) su tamaño.
Los lotes y transacciones de Redis no pueden abarcar varias conexiones, por lo que todos los datos afectados por un lote o transacción deben mantenerse en la misma base de datos (partición).
Nota:
Una secuencia de operaciones en una transacción de Redis no es necesariamente atómica. Los comandos que componen una transacción se comprueban y se ponen en cola antes de ejecutarse. Si se produce un error durante esta fase, se descarta toda la cola. Sin embargo, una vez enviada correctamente la transacción, los comandos en cola se ejecutan en secuencia. Si se produce un error en algún comando, solo ese comando deja de ejecutarse. Se realizan todos los comandos anteriores y subsiguientes de la cola. Para obtener más información, vaya a la página transacciones de en el sitio web de Redis.
Redis admite un número limitado de operaciones atómicas. Las únicas operaciones de este tipo que admiten varias claves y valores son las operaciones MGET y MSET. Las operaciones MGET devuelven una colección de valores para una lista especificada de claves y las operaciones MSET almacenan una colección de valores para una lista especificada de claves. Si necesita usar estas operaciones, los pares clave-valor a los que hacen referencia los comandos MSET y MGET deben almacenarse en la misma base de datos.
Creación de particiones de Azure Service Fabric
Azure Service Fabric es una plataforma de microservicios que proporciona un entorno de ejecución para aplicaciones distribuidas en la nube. Service Fabric admite ejecutables invitados de .NET, servicios con estado y sin estado, y contenedores. Los servicios con estado proporcionan una recopilación confiable para almacenar datos de forma persistente en una colección de clave-valor dentro del clúster de Service Fabric. Para más información sobre las estrategias para crear particiones de claves en una colección confiable, consulte Directrices y recomendaciones para colecciones confiables en Azure Service Fabric.
Pasos siguientes
Introducción a Azure Service Fabric es una introducción a Azure Service Fabric.
Partición de servicios de confianza de Service Fabric proporciona más información sobre los servicios de confianza en Azure Service Fabric.
Creación de particiones de Azure Event Hubs
azure Event Hubs está diseñado para el streaming de datos a gran escala y la creación de particiones está integrada en el servicio para habilitar el escalado horizontal. Cada consumidor solo lee una partición específica de la secuencia de mensajes.
El publicador de eventos solo conoce su clave de partición, no la partición en la que se publican los eventos. Este desacoplamiento de la clave y la partición evita al remitente la necesidad de conocer demasiado sobre el procesamiento de bajada. (También es posible enviar eventos directamente a una partición determinada, pero por lo general no se recomienda).
Considere la posibilidad de escalar a largo plazo al seleccionar el recuento de particiones. Después de crear un centro de eventos, no se puede cambiar el número de particiones.
Pasos siguientes
Para obtener más información sobre el uso de particiones en Event Hubs, consulte ¿Qué es Event Hubs?.
Para obtener consideraciones sobre el equilibrio entre disponibilidad y coherencia, consulte Disponibilidad y coherencia en Event Hubs.