¿Qué es la observabilidad de la red de contenedor?
La observabilidad de red de contenedor es una característica del conjunto de Servicios avanzados de redes de contenedores. Proporciona herramientas de supervisión y diagnóstico de más alto nivel, de forma que se tiene una visibilidad sin precedentes de las cargas de trabajo contenedorizadas. Estas herramientas le permiten identificar y solucionar problemas de red con facilidad, lo que garantiza un rendimiento óptimo de las aplicaciones.
La observabilidad de red de contenedor es compatible con todas las cargas de trabajo de Linux que se integran perfectamente con Azure, independientemente de si el plano de datos subyacente es Cilium o no Cilium (ambos son compatibles) lo que garantiza la flexibilidad de las necesidades de red del contenedor.
Nota:
Para escenarios de plano de datos de Cilium, la observabilidad de la red de contenedor está disponible a partir de la versión 1.29 de Kubernetes. La observabilidad de red de contenedor se admite en todas las distribuciones de Linux, incluido Azure Linux a partir de la versión 2.0.
Características de observabilidad de red de contenedor
La observabilidad de red de contenedor ofrece las siguientes funcionalidades para supervisar los problemas relacionados con la red en el clúster:
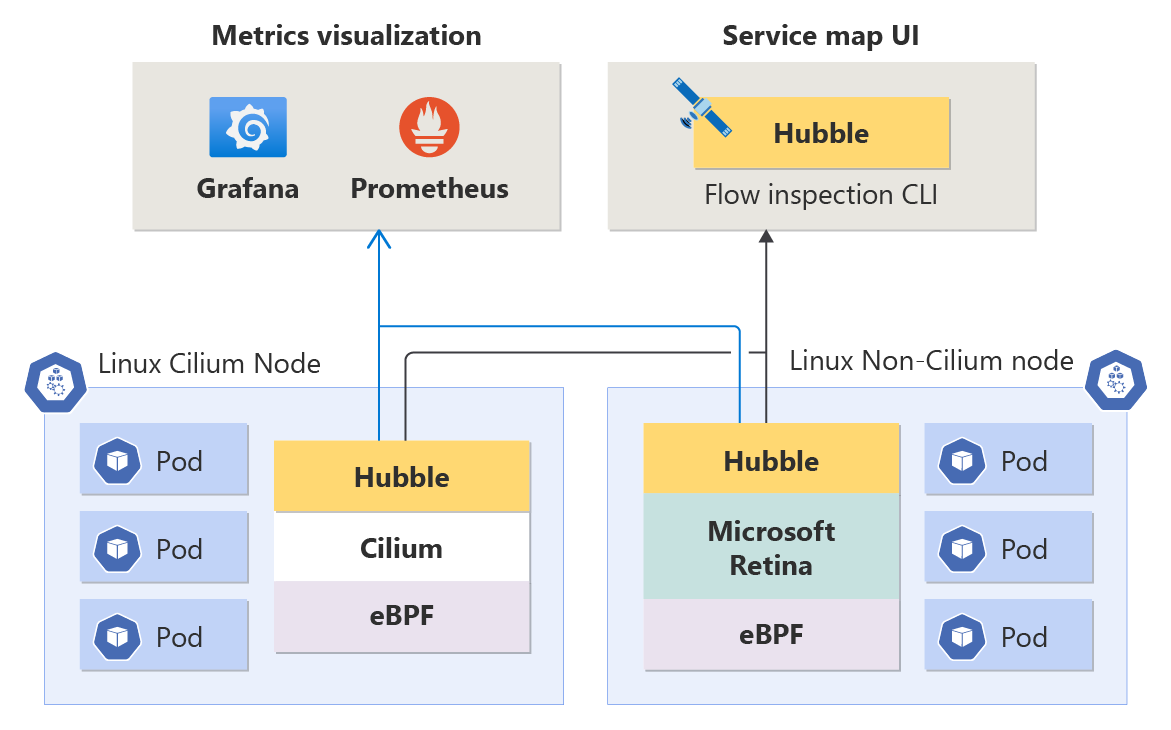
Métricas de nivel de nodo: comprender el estado de la red de contenedores a nivel de nodo es fundamental para mantener un rendimiento óptimo de la aplicación. Estas métricas proporcionan información sobre el volumen de tráfico, los paquetes descartados, el número de conexiones, etc., por nodo. Las métricas se almacenan en formato Prometheus y, como tal, puede verlas en Grafana.
Métricas de Hubble (métricas de nivel de Pod y DNS): estas métricas de Prometheus incluyen información del pod de origen y destino, lo que le permite identificar problemas relacionados con la red en un nivel granular. Las métricas abarcan el volumen de tráfico, los paquetes descartados, los restablecimientos TCP, los flujos de paquetes L4/L7, etc. También hay métricas de DNS (actualmente solo para planos de datos sin Cilium), que incluyen errores de DNS y solicitudes de DNS sin respuesta.
Registros de flujo de Flow de Hubble: los registros de flujo proporcionan una visibilidad profunda de la actividad de red del clúster. Todas las comunicaciones hacia y desde los pods se registran, lo que le permite investigar problemas de conectividad a lo largo del tiempo. Los registros de flujo ayudan a responder preguntas como: ¿el servidor recibió la solicitud del cliente? ¿Cuál es la latencia de ida y vuelta entre la solicitud del cliente y la respuesta del servidor?
CLI de Hubble: la interfaz de la línea de comandos (CLI) de Hubble puede recuperar registros de flujo en todo el clúster con filtrado y formato personalizables.
Interfaz de usuario de Hubble: la interfaz de usuario de Hubble es una interfaz basada en explorador fácil de usar para explorar la actividad de red del clúster. Crea un grafo de conexiones de servicio basado en los registros de flujo y muestra los registros de flujo del espacio de nombres seleccionado. Los usuarios son responsables de aprovisionar y administrar la infraestructura necesaria para ejecutar la interfaz de usuario de Hubble.
Principales ventajas de la observabilidad de la red de contenedores
Independiente de CNI: se admite en todas las variantes de Azure CNI, incluido kubenet.
Con Cilium y sin Cilium: proporciona una experiencia uniforme y fluida en planos de datos con Cilium y sin Cilium.
Observabilidad de red basada en eBPF: usa eBPF (filtro de paquetes de Berkeley extendido) para analizar el rendimiento y la escalabilidad con el fin de identificar posibles cuellos de botella y problemas de congestión antes de que afecten al rendimiento de las aplicaciones. Obtenga información sobre los indicadores clave de estado de red, incluido el volumen de tráfico, los paquetes descartados y la información de conexión.
Visibilidad profunda de la actividad de red: comprenda cómo se comunican las aplicaciones entre sí mediante registros de flujo de red detallados.
Opciones simplificadas de visualización y almacenamiento de métricas: elija entre:
- Prometheus y Grafana administrados por Azure: Azure administra la infraestructura y el mantenimiento, lo que permite a los usuarios centrarse en configurar y visualizar las métricas.
- Traiga su propio (BYO) Prometheus y Grafana: los usuarios implementan y configuran sus propias instancias y administran la infraestructura subyacente.
Métricas
Métricas de nivel de nodo
Las métricas siguientes se agregan por nodo. Todas las métricas incluyen etiquetas:
clusterinstance(nombre del nodo)
En el caso de escenarios de plano de datos de Cilium, la observabilidad de red de contenedor proporciona métricas solo para Linux, Windows no se admite actualmente. Cilium expone varias métricas, entre las que se incluyen las siguientes usadas por la observabilidad de la red de contenedor.
| Nombre de la métrica | Descripción | Etiquetas adicionales | Linux | Windows |
|---|---|---|---|---|
| cilium_forward_count_total | Recuento total de paquetes reenviados | direction |
✅ | ❌ |
| cilium_forward_bytes_total | Recuento total de bytes reenviados | direction |
✅ | ❌ |
| cilium_drop_count_total | Recuento total de paquetes descartados | direction, reason |
✅ | ❌ |
| cilium_drop_bytes_total | Recuento total de bytes descartados | direction, reason |
✅ | ❌ |
Métricas de nivel de pod (métricas de Hubble)
Las métricas siguientes se agregan por pod (se conserva la información del nodo). Todas las métricas incluyen etiquetas:
clusterinstance(nombre del nodo)sourceodestination
Para el tráfico saliente, habrá una etiqueta source con el espacio de nombres o el nombre del pod de origen.
Para el tráfico entrante, habrá una etiqueta destination con el espacio de nombres o el nombre del pod de destino.
| Nombre de la métrica | Descripción | Etiquetas adicionales | Linux | Windows |
|---|---|---|---|---|
| hubble_dns_queries_total | Total de solicitudes DNS por consulta | source o destination, query, qtypes (tipo de consulta) |
✅ | ❌ |
| hubble_dns_responses_total | Total de respuestas DNS por consulta o respuesta | source o destination, query, qtypes (tipo de consulta), rcode (código de retorno), ips_returned (número de direcciones IP) |
✅ | ❌ |
| hubble_drop_total | Recuento total de paquetes descartados | source o destination, protocol, reason |
✅ | ❌ |
| hubble_tcp_flags_total | Recuento de paquetes TCP totales por marca. | source o destination, flag |
✅ | ❌ |
| hubble_flows_processed_total | Total de flujos de red procesados (tráfico L4/L7) | source o destination, protocol, verdict, type, subtype |
✅ | ❌ |
Limitaciones
- Las métricas de nivel de pod solo están disponibles en Linux.
- Se admite el plano de datos con Cilium a partir de la versión 1.29 de Kubernetes.
- Las etiquetas de métricas pueden tener diferencias sutiles entre los clústeres con Cilium y sin Cilium.
- En el caso de los clústeres basados en Cilium, las métricas de DNS solo están disponibles para los pods que tienen directivas de red de Cilium (CNP) configuradas en sus clústeres.
- Los registros de flujo no están disponibles actualmente en la nube con disponibilidad inalámbrica.
- La retransmisión de Horizontal puede bloquearse si uno de los agentes de nodo de Azure deja de funcionar y puede provocar interrupciones en la CLI de Azure.
Escala
Se aplican ciertas limitaciones de escala cuando se utiliza Prometheus y Grafana administrados por Azure. Para más información, consulte Métricas de Scrape Prometheus a gran escala en Azure Monitor.
Precios
Importante
Los servicios avanzados de redes de contenedores es una oferta de pago. Para obtener más información sobre los precios, consulte Servicios avanzados de redes de contenedores: precios.
Pasos siguientes
- Para crear un clúster de AKS con observabilidad de red de contenedor, consulte Configuración de la observabilidad de la red de contenedor para Azure Kubernetes Service (AKS).

Azure Kubernetes Service