¿Qué es el texto a voz?
En esta introducción, conocerá las ventajas y funcionalidades de texto a voz para el servicio de Voz, que es parte de servicios de Azure AI.
La conversión de texto a voz permite que sus aplicaciones, herramientas o dispositivos conviertan el texto en voz sintetizada similar a la humana. La funcionalidad de texto a voz también se conoce como síntesis de voz. Use voces neuronales preconfiguradas, como las de los humanos, o cree una voz neuronal personalizada y exclusiva para su producto o marca. Para obtener una lista completa de las voces, idiomas y configuraciones regionales compatibles, consulte Compatibilidad con idiomas y voz para el servicio voz.
Características principales
La funcionalidad de texto a voz incluye las siguientes características:
| Característica | Resumen | Demostración |
|---|---|---|
| Voz neuronal pregenerada (denominada Neuronal en la página de precios) | Voces muy naturales y lista para su uso. Cree una suscripción de Azure y un recurso de Voz y, a continuación, use el SDK de Voz o visite el portal de Speech Studio y seleccione voces neuronales pregeneradas para empezar. Consulte los detalles de precios. | Consulte la Galería de voces y determine la voz adecuada para las necesidades de su empresa. |
| Voz neuronal personalizada (llamada Neuronal personalizada en la página de precios) | Autoservicio fácil de usar para crear una voz de marca natural, con acceso limitado para un uso responsable. Cree una suscripción Azure y un recurso de voz (con el nivel S0), y solicite usar la función de Voz personalizada. Después de conceder acceso, visite el portal de Speech Studio y seleccione Voz personalizada para empezar. Consulte los detalles de precios. | Compruebe las muestras de voz. |
Más información sobre las características neuronales del servicio de texto a voz
La conversión de texto a voz usa redes neuronales profundas para hacer que las voces de los equipos resulten prácticamente imposibles de distinguir de las grabaciones de las personas. Gracias a la clara articulación de las palabras, la funcionalidad de texto a voz neuronal reduce significativamente la fatiga auditiva cuando los usuarios interactúan con sistemas de inteligencia artificial.
Los patrones de acentuación y entonación en el lenguaje hablado se denominan prosodia. Los sistemas tradicionales de conversión de texto en voz desglosan la prosodia en pasos separados de análisis lingüístico y predicción acústica regidos por modelos independientes. Esto puede dar lugar a una síntesis de voz amortiguada y con ruido.
A continuación se proporciona más información sobre las características neuronales de texto a voz en el servicio de Voz y cómo superan los límites de los sistemas tradicionales de texto a voz:
Síntesis de voz en tiempo real: use el SDK de Voz o la API REST para convertir texto a voz mediante las voces neuronales pregeneradas o las voces neuronales personalizadas.
Síntesis asincrónica de audio de larga duración: use Batch synthesis API para sintetizar asincrónicamente archivos de texto a voz de más de 10 minutos (por ejemplo, audiolibros o conferencias). A diferencia de la síntesis realizada mediante el SDK de Voz o la API REST de conversión de voz en texto, las respuestas no se devuelven en tiempo real. La expectativa es que las solicitudes se envíen de forma asincrónica, se sondeen las respuestas y el audio sintetizado se descargue cuando el servicio lo permita.
Voces neuronales pregeneradas: Voz de Azure AI usa redes neuronales profundas para superar los límites de la síntesis de voz tradicional con respecto al estrés y la entonación en lenguaje hablado. La predicción de la prosodia y la síntesis de voz tienen lugar simultáneamente, lo que resulta en una voz más fluida y natural. Cada modelo de voz neuronal pregenerado está disponible en 24 kHz y 48 kHz de alta fidelidad. Mediante el uso de voces neuronales, podrá:
- Hacer que las interacciones con bots de chat y asistentes de voz sean más naturales y atractivas.
- Convertir textos digitales como libros electrónicos en audiolibros.
- Mejorar los sistemas de navegación en el automóvil.
Para obtener una lista completa de las voces neuronales precompiladas de Voz de Azure AI, consulte Soporte con lenguaje y voz para el servicio de voz.
Mejorar la salida de texto a voz con SSML: el lenguaje de marcado de síntesis de voz (SSML) es un lenguaje de marcado basado en XML que se usa para personalizar el texto a las salidas de voz. Mediante SSML, puede ajustar el tono, agregar pausas, mejorar la pronunciación, cambiar la velocidad del habla, ajustar el volumen y atribuir varias voces a un solo documento.
Puede usar SSML para definir sus propios léxicos o cambiar a diferentes estilos de habla. Con las voces multilingües, también puede ajustar los idiomas de habla mediante SSML. Para mejorar la salida de voz para su escenario, vea Mejora de la síntesis con lenguaje de marcado de síntesis de voz y Síntesis de voz con la herramienta Creación de contenido de audio.
Visemas: los visemas son los principales planteamientos de la voz observada, incluida la posición de los labios, mandíbula y lengua al producir un fonema determinado. Las visemas tienen una correlación fuerte con las voces y fonemas.
Mediante el uso de eventos de visema en el SDK de Voz, puede generar datos de animación facial. Estos datos se pueden usar para animar caras en la comunicación con lectura de labios, la educación, el entretenimiento y el servicio de atención al cliente. Actualmente, los visemas solo se admiten para las voces neuronales
en-US(Inglés de EE. UU.).
Nota:
Además de las voces neuronales de Voz de Azure AI (no HD), también puede usar Voces de alta definición de voz de Azure AI (HD) y voces neuronales de Azure OpenAI (HD y no HD). Las voces HD proporcionan una mayor calidad para escenarios más versátiles.
Algunas voces no admiten todas las etiquetas Lenguaje de marcado de síntesis de voz (SSML). Esto incluye voces HD neuronal de texto a voz, voces personales y voces incrustadas.
- Para las voces de alta definición de Voz de Azure AI (HD), compruebe la compatibilidad con SSML aquí.
- Para la voz personal, puede encontrar la compatibilidad con SSML aquí.
- Para las voces insertadas, compruebe la compatibilidad con SSML aquí.
Introducción
Para empezar a usar el servicio de texto a voz, consulte el inicio rápido. El servicio de texto a voz está disponible en el SDK de Voz, la API REST y la CLI de Voz.
Sugerencia
Para convertir texto a voz con un enfoque sin código, pruebe la herramienta Creación de contenido de audio en Speech Studio.
Código de ejemplo
El ejemplo de código para texto a voz está disponible en GitHub. Estos ejemplos tratan la conversión de texto a voz en los lenguajes de programación más populares:
Voz neuronal personalizada
Además de las voces neuronales pregeneradas, puede crear voces neuronales personalizadas exclusivas para su producto o marca. Todo lo que se necesita para empezar son unos cuantos archivos de audio y las transcripciones asociadas. Para más información, consulte Introducción a voz neuronal personalizada.
Nota de precios
Caracteres facturables
Cuando use la característica de texto a voz, se le cobrará por cada carácter que se convierta a voz, incluida la puntuación. Aunque el documento SSML en sí no es facturable, los elementos opcionales que se usan para ajustar cómo se convierte el texto a voz, como los fonemas y el tono, se cuentan como caracteres facturables. Aquí tiene una lista de lo que se puede facturar:
- El texto que se pase a la característica de texto a voz en el cuerpo SSML de la solicitud.
- Todas las marcas en el campo de texto del cuerpo de la solicitud que están en formato SSML, excepto las etiquetas
<speak>y<voice>. - Letras, puntuación, espacios, tabulaciones, marcas y todos los caracteres de espacios en blanco.
- Cada punto de código que se define en Unicode
Para obtener información detallada, consulte Precios del servicio voz.
Importante
Cada carácter chino cuenta como dos caracteres a efectos de facturación, incluidos el carácter Kanji usado en japonés, el carácter Hanja usado en coreano o el carácter Hanzi usado en otros idiomas.
Tiempo de hospedaje y entrenamiento del modelo para voz neuronal personalizada
El entrenamiento y el hospedaje de voz neuronal personalizada se calculan por hora y se facturan por segundo. Para conocer el precio unitario de facturación, consulte Precios del servicio de Voz.
El tiempo de entrenamiento de voz neuronal personalizada (CNV) se mide mediante "horas de proceso" (una unidad para medir el tiempo de ejecución de la máquina). Normalmente, al entrenar un modelo de voz, se ejecutan en paralelo dos tareas de proceso. Por lo tanto, las horas de proceso calculadas son más largas que el tiempo de entrenamiento real. En promedio, se tarda menos de una hora de proceso en entrenar una voz CNV Lite, mientras que para CNV Pro, normalmente se tardan entre 20 y 40 horas de proceso para entrenar una voz de estilo único y alrededor de 90 horas de proceso para entrenar una voz de varios estilos. El tiempo de entrenamiento de CNV se factura con un límite de 96 horas de proceso. Por lo tanto, en caso de que un modelo de voz se entrene en 98 horas de proceso, solo se le cobrarán 96 horas de proceso.
El hospedaje del punto de conexión de voz neuronal personalizada (CNV) se mide con el tiempo real (horas). El tiempo de hospedaje (horas) de cada punto de conexión se calcula a las 00:00 UTC todos los días para las 24 horas anteriores. Por ejemplo, si el punto de enlace ha estado activo durante 24 horas el primer día, se facturarán 24 horas a las 00:00 UTC del segundo día. Si el punto de conexión se crea de nuevo o se suspende durante el día, se facturará por su tiempo de funcionamiento acumulado hasta las 00:00 UTC del segundo día. Si el punto de conexión no está hospedado actualmente, no se factura. Además del cálculo diario a las 00:00 UTC cada día, la facturación también se desencadena inmediatamente cuando se elimina o se suspende un punto de conexión. Por ejemplo, para un punto de conexión creado a las 08:00 UTC el 1 de diciembre, las horas de hospedaje se calcularán como 16 horas a las 00:00 UTC el 2 de diciembre y 24 horas a las 00:00 UTC del 3 de diciembre. Si el usuario suspende el hospedaje del punto de conexión a las 16:30 UTC del 3 de diciembre, se calculará la duración (16.5 horas) desde las 00:00 a las 16:30 UTC del 3 de diciembre para la facturación.
Voz personal
Al usar la característica de voz personal, se le factura tanto por el almacenamiento de perfiles como por la síntesis.
- Almacenamiento de perfiles: después de crear un perfil de voz personal, se facturará hasta que se elimine del sistema. La unidad de facturación es por voz al día. Si el almacenamiento de voz dura menos de 24 horas, se sigue facturando como un día completo.
- Síntesis: se factura por caracteres. Para obtener más información sobre los caracteres facturables, vea anteriormente los caracteres facturables.
Avatar de texto a voz
Cuando usa la característica de avatar de texto a voz, los cargos se facturan por segundo en función de la duración de la salida de vídeo. Sin embargo, para el avatar en tiempo real, los cargos se facturan por segundo en función del tiempo en que el avatar está activo, independientemente de si está hablando o permanece en silencio. Para optimizar los costos para el uso de avatares en tiempo real, consulte los consejos sobre "Uso de vídeo local para inactividad" proporcionados en el código de muestra del chat de avatares.
El tiempo de entrenamiento personalizado de avatares de texto a voz se mide por "hora de proceso" (tiempo de funcionamiento de la máquina) y se factura por segundo. La duración del entrenamiento varía en función de la cantidad de datos que use. Normalmente se tarda una media de 20-40 horas de proceso en entrenar un avatar personalizado. El tiempo de entrenamiento de avatar se factura con un límite de 96 horas de proceso. Por lo tanto, en caso de que un modelo de avatar se entrene en 98 horas de proceso, solo se le cobrará por 96 horas de proceso.
El hospedaje de avatares se factura por segundos por punto de conexión. Puede suspender el punto de conexión para ahorrar costos. Si desea suspender el punto de conexión, puede eliminarlo directamente. Para usarlo de nuevo, vuelva a implementar el punto de conexión.
Supervisión de las métricas de conversión de texto a voz de Azure
La supervisión de métricas clave asociadas con los servicios de texto a voz es fundamental para administrar el uso de los recursos y controlar los costos. Esta sección le guiará sobre cómo buscar información de uso en Azure Portal y le proporcionará definiciones detalladas de las métricas clave. Para más información sobre las métricas de Azure Monitor, consulte Introducción a las métricas de Azure Monitor.
Búsqueda de información de uso en Azure Portal
Para administrar eficazmente los recursos de Azure, es esencial acceder a la información de uso y revisarla periódicamente. Aquí se muestra cómo encontrar la información de uso:
Vaya a Azure Portal e inicie sesión con su cuenta de Azure.
Vaya a Recursos y seleccione el recurso que desea supervisar.
Seleccione Métricas en Supervisión en el menú de la izquierda.
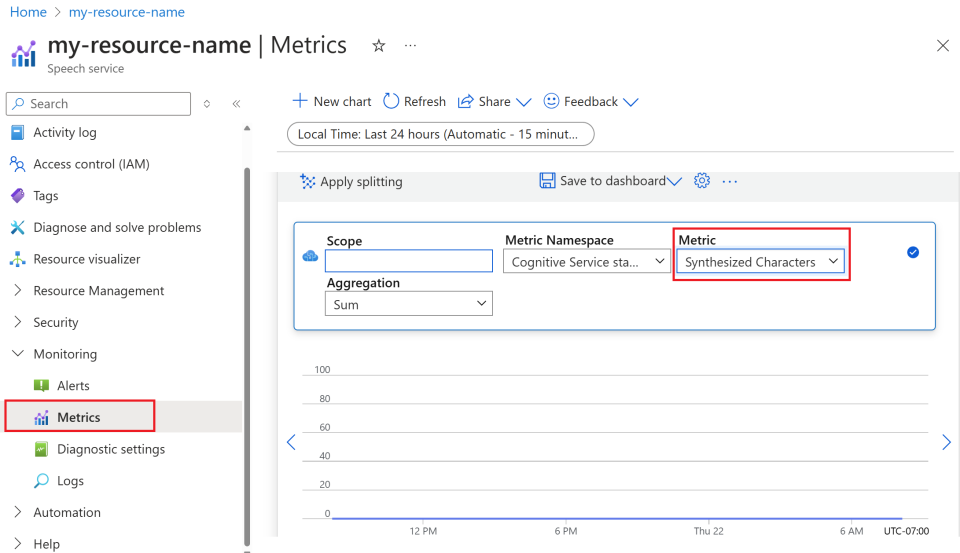
Personalice las vistas de métricas.
Puede filtrar los datos por tipo de recurso, tipo de métrica, intervalo de tiempo y otros parámetros para crear vistas personalizadas que se adapten a sus necesidades de supervisión. Además, puede guardar la vista de métricas en los paneles seleccionando Guardar en el panel para facilitar el acceso a las métricas usadas con frecuencia.
Configuración de alertas.
Para administrar el uso de forma más eficaz, configure alertas; para ello, vaya a la pestaña Alertas en Supervisión desde el menú izquierdo. Las alertas pueden notificarle cuándo el uso alcanza umbrales específicos, lo que ayuda a evitar costos inesperados.
Definición de métricas
Aquí tiene una tabla que resume las métricas clave de la conversión de texto a voz de Azure.
| Nombre de la métrica | Descripción |
|---|---|
| Caracteres sintetizados | Realiza un seguimiento del número de caracteres convertidos en voz, incluida la voz neuronal pregenerada y la voz neuronal personalizada. Para obtener más información sobre los caracteres facturables, consulte Caracteres facturables. |
| Segundos de vídeo sintetizados | Mide la duración total del vídeo sintetizado, incluida la síntesis de avatares por lotes, la síntesis de avatares en tiempo real y la síntesis de avatares personalizada. |
| Segundos de hosting del modelo de avatar | Realiza un seguimiento del tiempo total en segundos en que se hospeda el modelo de avatar personalizado. |
| Horas de hosting del modelo de voz | Realiza un seguimiento del tiempo total en horas que se hospeda el modelo de voz neuronal personalizado. |
| Minutos de entrenamiento del modelo de voz | Mide el tiempo total en minutos para entrenar el modelo de voz neuronal personalizado. |
Documentos de referencia
IA responsable
Los sistemas de inteligencia artificial no solo incluyen la tecnología, sino también las personas que la usan, las que se ven afectadas por ella y el entorno en el que se implementan. Lea las notas sobre transparencia para obtener información sobre el uso responsable de la inteligencia artificial y la implementación en los sistemas.
- Nota sobre transparencia y casos de uso de Voz neuronal personalizada
- Características y limitaciones de uso de Voz neuronal personalizada
- Acceso limitado a Voz neuronal personalizada
- Directrices para la implementación responsable de la tecnología de voz sintética
- Divulgación de talento de voz
- Directrices de diseño de divulgación de información
- Modelos de diseño de divulgación
- Código de conducta para las integraciones de texto a voz
- Datos, privacidad y seguridad de Voz neuronal personalizada