Inicio rápido: Reconocimiento de intenciones con el reconocimiento del lenguaje conversacional
Documentación de referencia | Paquete (NuGet) | Ejemplos adicionales en GitHub
En este inicio rápido, usará los servicios Voz y Lenguaje para reconocer las intenciones de los datos de audio capturados de un micrófono. En concreto, usará el servicio Voz para reconocer voz y un modelo de reconocimiento del lenguaje conversacional (CLU) para identificar las intenciones.
Importante
El reconocimiento del lenguaje conversacional (CLU) está disponible para C# y C++ con la versión 1.25 o posterior del SDK de Voz.
Requisitos previos
- Suscripción a Azure. Puede crear una de forma gratuita.
- Cree un recurso de idioma en Azure Portal.
- Obtenga la clave y el punto de conexión del recurso de Lenguaje. Una vez implementado el recurso de Idioma, seleccione Ir al recurso para ver y administrar claves.
- Creación de un recurso de Voz en Azure Portal.
- Obtenga la clave y la región del recurso de Voz. Una vez implementado el recurso de Voz, seleccione Ir al recurso para ver y administrar claves.
Configuración del entorno
El SDK de Voz está disponible como paquete NuGet e implementa .NET Standard 2.0. La instalación del SDK de Voz se describe en una sección más adelante de esta guía; primero consulte la SDK installation guide, (guía de instalación del SDK), para conocer otros requisitos.
Establecimiento de variables de entorno
En este ejemplo se requieren variables de entorno denominadas LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY y SPEECH_REGION.
La aplicación debe autenticarse para acceder a los recursos de servicios de Azure AI. Este artículo le muestra cómo utilizar variables de entorno para almacenar sus credenciales. A continuación, puede acceder a las variables de entorno desde el código para autenticar la aplicación. Para producción, use una manera más segura de almacenar y acceder a sus credenciales.
Importante
Se recomienda la autenticación de Microsoft Entra ID con identidades administradas para los recursos de Azure para evitar almacenar credenciales con sus aplicaciones que se ejecutan en la nube.
Si usa una clave de API, almacénela de forma segura en otro lugar, como en Azure Key Vault. No incluya la clave de API directamente en el código ni la exponga nunca públicamente.
Para más información sobre la seguridad de los servicios de AI, consulte Autenticación de solicitudes a los servicios de Azure AI.
Para establecer las variables de entorno, abra una ventana de consola y siga las instrucciones correspondientes a su sistema operativo y entorno de desarrollo.
- Para establecer la variable de entorno
LANGUAGE_KEY, reemplaceyour-language-keypor una de las claves del recurso. - Para establecer la variable de entorno
LANGUAGE_ENDPOINT, reemplaceyour-language-endpointpor una de las regiones del recurso. - Para establecer la variable de entorno
SPEECH_KEY, reemplaceyour-speech-keypor una de las claves del recurso. - Para establecer la variable de entorno
SPEECH_REGION, reemplaceyour-speech-regionpor una de las regiones del recurso.
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Nota:
Si solo necesita acceder a la variable de entorno en la consola que se está ejecutando en este momento, puede establecer la variable de entorno con set en vez de con setx.
Después de agregar la variable de entorno, puede que tenga que reiniciar todos los programas en ejecución que necesiten leer la variable de entorno, incluida la ventana de consola. Por ejemplo, si usa Visual Studio como editor, reinícielo antes de ejecutar el ejemplo.
Creación de un proyecto de reconocimiento del lenguaje conversacional
Una vez que tenga un recurso de Lenguaje creado, cree un proyecto de reconocimiento del lenguaje conversacional en Language Studio. Un proyecto es un área de trabajo para compilar modelos de Machine Learning personalizados basados en los datos. A su proyecto solo puede acceder usted y otros usuarios que tengan acceso al recurso de idioma que se usa.
Vaya a Language Studio e inicie sesión con su cuenta de Azure.
Creación de un proyecto de reconocimiento del lenguaje conversacional
Para este inicio rápido, puede descargar este proyecto de automatización del hogar de ejemplo e importarlo. Este proyecto puede predecir las órdenes previstas a partir de la entrada del usuario, como encender y apagar las luces.
En la sección Descripción de preguntas y lenguaje conversacional de Language Studio, seleccione Reconocimiento del lenguaje conversacional.

Esto lo llevará a la página Proyectos de reconocimiento del lenguaje conversacional. Junto al botón Crear nuevo proyecto, seleccione Importar.

En la ventana que aparece, cargue el archivo JSON que desea importar. Asegúrese de que el archivo sigue el formato JSON admitido.


Una vez completada la carga, llegará a la página Definición de esquema. En este inicio rápido, el esquema ya está compilado y las expresiones ya están etiquetadas con intenciones y entidades.
Entrenamiento de un modelo
Por lo general, después de crear un proyecto, debe compilar un esquema y expresiones de etiqueta. En este inicio rápido, ya importamos un proyecto listo con esquema compilado y expresiones etiquetadas.
Para entrenar un modelo, debe iniciar un trabajo de entrenamiento. La salida de un trabajo de entrenamiento correcto es el modelo entrenado.
Para empezar a entrenar el modelo desde Language Studio:
Seleccione Entrenar modelo en el menú de la izquierda.
Seleccione Iniciar un trabajo de entrenamiento en el menú superior.
Seleccione Entrenar un nuevo modelo y escriba el nombre del nuevo modelo en el cuadro de texto. De lo contrario, para reemplazar un modelo existente por un modelo entrenado en los nuevos datos, seleccione Sobrescribir un modelo existente y, a continuación, seleccione un modelo existente. La sobrescritura de un modelo entrenado es irreversible, pero no afectará a los modelos implementados hasta que implemente el nuevo modelo.
Seleccionar datos de entrenamiento. Puede elegir Entrenamiento estándar para un entrenamiento más rápido, pero solo está disponible para inglés. También puede elegir Formación avanzada compatible con otros idiomas y proyectos multilingües, pero implica tiempos de entrenamiento más largos. Más información sobre los modos de entrenamiento.
Seleccione un método de división de datos. Puede elegir Dividir automáticamente el conjunto de pruebas de los datos de entrenamiento, y el sistema dividirá las expresiones entre los conjuntos de entrenamiento y pruebas, según los porcentajes especificados. También puede usar una división manual de datos de entrenamiento y pruebas; esta opción solo se habilita si han agregado expresiones al conjunto de pruebas al etiquetar las expresiones.
Seleccione el botón Entrenar.

Seleccione el identificador del trabajo de entrenamiento de la lista. Aparecerá un panel en el que podrá comprobar el progreso del entrenamiento, el estado del trabajo y otros detalles de este trabajo.
Nota
- Los trabajos de entrenamiento completados correctamente serán los únicos que generarán modelos.
- El entrenamiento puede durar entre un par de minutos y un par de horas en función del número de expresiones.
- Solo puede haber un trabajo de entrenamiento ejecutándose en un momento dado. No se pueden iniciar otros trabajos de entrenamiento dentro del mismo proyecto hasta que se complete el trabajo en ejecución.
- El aprendizaje automático que se usa para entrenar modelos se actualiza periódicamente. Para entrenar en una versión de configuración anterior, seleccione Seleccione aquí para cambiar en la página Iniciar un trabajo de entrenamiento y elija una versión anterior.

Implementación del modelo
Por lo general, después de entrenar un modelo, revisaría sus detalles de evaluación. En este inicio rápido, solo implementará el modelo y lo tendrá disponible para probarlo en Language Studio, o bien puede llamar a la API de predicción.
Para implementar el modelo desde Language Studio:
Seleccione Implementación de un modelo en el menú de la izquierda.
Seleccione Agregar implementación para iniciar el asistente Agregar implementación.

Seleccione Crear un nuevo nombre de implementación para crear una nueva implementación y asignar un modelo entrenado de la lista desplegable siguiente. De lo contrario, puede seleccionar Sobrescribir un nombre de implementación existente para reemplazar eficazmente el modelo usado por una implementación existente.
Nota:
La sobrescritura de una implementación existente no requiere cambios en la llamada de la API de predicción, pero los resultados que obtendrá se basarán en el modelo recién asignado.
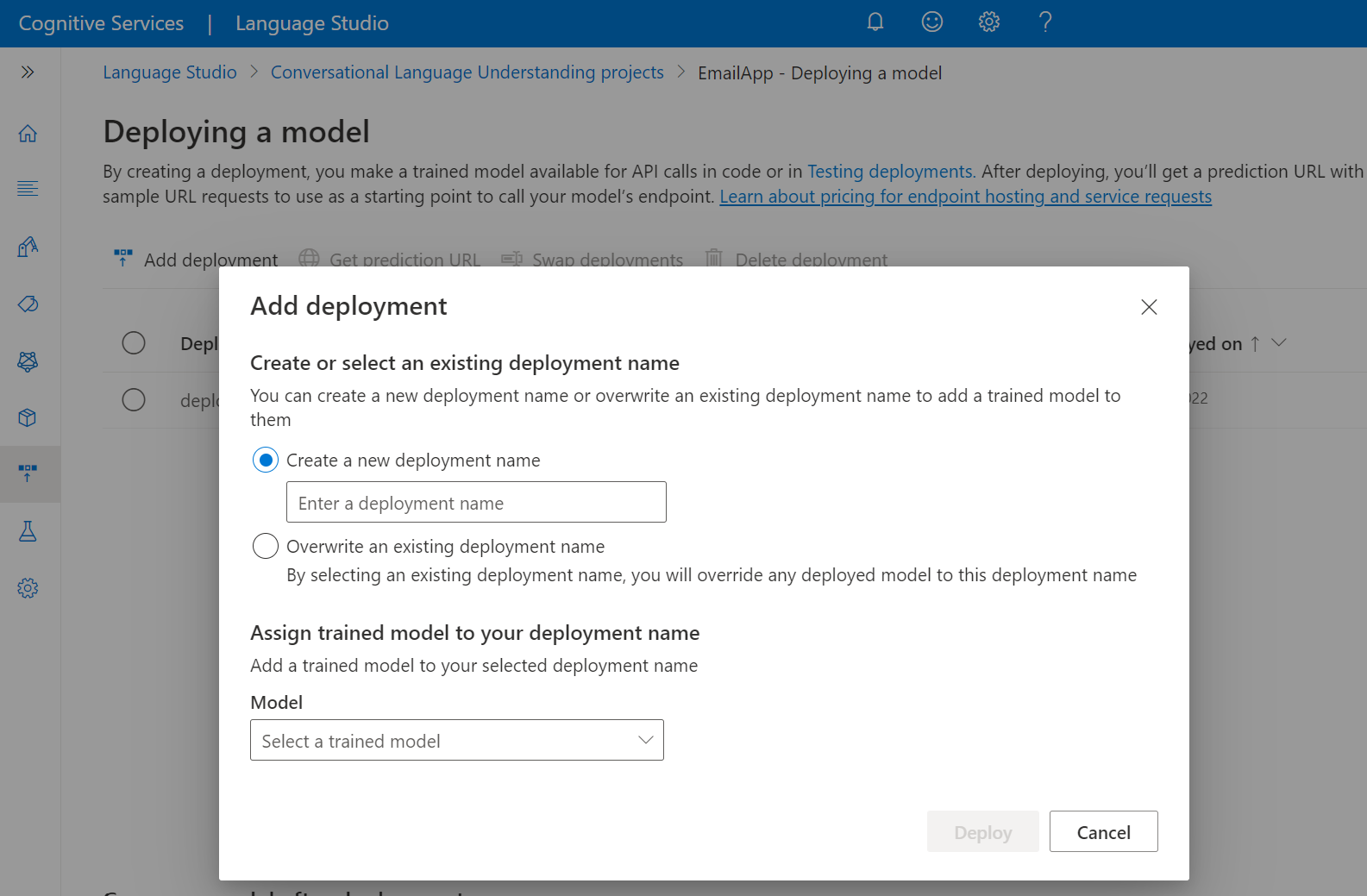
Seleccione un modelo entrenado de la lista desplegable Modelo.
Seleccione Implementar para iniciar el trabajo de implementación.
Después de que la implementación se realice correctamente, aparecerá una fecha de expiración junto a ella. La expiración de la implementación aparece cuando el modelo implementado deja de estar disponible para usarlo en la predicción, lo que suele ocurrir doce meses después de que expire una configuración de entrenamiento.


Usará el nombre del proyecto y el nombre de la implementación en la sección siguiente.
Reconocimiento de intenciones de un micrófono
Siga estos pasos para crear una nueva aplicación de consola e instalar el SDK de Voz.
Abra un símbolo del sistema donde quiera el nuevo proyecto y cree una aplicación de consola con la CLI de .NET. El archivo
Program.csdebe crearse en el directorio del proyecto.dotnet new consoleInstale el SDK de Voz en el nuevo proyecto con la CLI de .NET.
dotnet add package Microsoft.CognitiveServices.SpeechReemplace el contenido de
Program.cspor el código siguiente.using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; using Microsoft.CognitiveServices.Speech.Intent; class Program { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" static string languageKey = Environment.GetEnvironmentVariable("LANGUAGE_KEY"); static string languageEndpoint = Environment.GetEnvironmentVariable("LANGUAGE_ENDPOINT"); static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); // Your CLU project name and deployment name. static string cluProjectName = "YourProjectNameGoesHere"; static string cluDeploymentName = "YourDeploymentNameGoesHere"; async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); // Creates an intent recognizer in the specified language using microphone as audio input. using (var intentRecognizer = new IntentRecognizer(speechConfig, audioConfig)) { var cluModel = new ConversationalLanguageUnderstandingModel( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); var collection = new LanguageUnderstandingModelCollection(); collection.Add(cluModel); intentRecognizer.ApplyLanguageModels(collection); Console.WriteLine("Speak into your microphone."); var recognitionResult = await intentRecognizer.RecognizeOnceAsync().ConfigureAwait(false); // Checks result. if (recognitionResult.Reason == ResultReason.RecognizedIntent) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent Id: {recognitionResult.IntentId}."); Console.WriteLine($" Language Understanding JSON: {recognitionResult.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult)}."); } else if (recognitionResult.Reason == ResultReason.RecognizedSpeech) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent not recognized."); } else if (recognitionResult.Reason == ResultReason.NoMatch) { Console.WriteLine($"NOMATCH: Speech could not be recognized."); } else if (recognitionResult.Reason == ResultReason.Canceled) { var cancellation = CancellationDetails.FromResult(recognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you update the subscription info?"); } } } } }En
Program.cs, establezca las variablescluProjectNameycluDeploymentNameen los nombres del proyecto y la implementación. Para obtener información sobre cómo crear un proyecto de CLU y una implementación, consulte Creación de un proyecto de reconocimiento del lenguaje conversacional.Para cambiar el idioma de reconocimiento de voz, reemplace
en-USpor otroen-US. Por ejemplo,es-ESpara Español (España). El idioma predeterminado esen-USsi no especifica un idioma. Para obtener más información sobre cómo identificar uno de los distintos idiomas que se pueden hablar, consulte Identificación del idioma.
Ejecute la nueva aplicación de consola para iniciar el reconocimiento de voz a través de un micrófono:
dotnet run
Importante
Asegúrese de establecer las variables de entorno LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY y SPEECH_REGION como se ha descrito anteriormente. Si no establece estas variables, se producirá un fallo en el ejemplo, con un mensaje de error.
Hable por el micrófono cuando se le solicite. Lo que diga debe devolverse como texto:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
Nota
Se agregó compatibilidad con la respuesta JSON para CLU a través de la propiedad LanguageUnderstandingServiceResponse_JsonResult en la versión 1.26 del SDK de voz.
Las intenciones se devuelven en un orden de mayor a menor probabilidad. A continuación se muestra una versión con formato de la salida JSON donde el topIntent es HomeAutomation.TurnOn con una puntuación de confianza de 0,97712576 (97,71 %). La segunda intención más probable podría ser HomeAutomation.TurnOff, con una puntuación de confianza de 0,8985081 (84,31 %).
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
Comentarios
Ahora que ha completado el artículo de inicio rápido, estas son algunas consideraciones adicionales:
- En este ejemplo se usa la operación
RecognizeOnceAsyncpara transcribir expresiones de hasta 30 segundos, o hasta que se detecta el silencio. Para obtener información sobre el reconocimiento continuo de audio más largo, incluidas las conversaciones en varios idiomas, consulte Reconocimiento de voz. - Para reconocer la voz de un archivo de audio, use
FromWavFileInputen lugar deFromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav"); - Para archivos de audio comprimidos como MP4, instale GStreamer y utilice
PullAudioInputStreamoPushAudioInputStream. Para más información, consulte Uso de entradas de audio comprimido.
Limpieza de recursos
Puede usar Azure Portal o la Interfaz de la línea de comandos (CLI) de Azure para quitar los recursos de Lenguaje y Voz que creó.
Documentación de referencia | Paquete (NuGet) | Ejemplos adicionales en GitHub
En este inicio rápido, usará los servicios Voz y Lenguaje para reconocer las intenciones de los datos de audio capturados de un micrófono. En concreto, usará el servicio Voz para reconocer voz y un modelo de reconocimiento del lenguaje conversacional (CLU) para identificar las intenciones.
Importante
El reconocimiento del lenguaje conversacional (CLU) está disponible para C# y C++ con la versión 1.25 o posterior del SDK de Voz.
Requisitos previos
- Suscripción a Azure. Puede crear una de forma gratuita.
- Cree un recurso de idioma en Azure Portal.
- Obtenga la clave y el punto de conexión del recurso de Lenguaje. Una vez implementado el recurso de Idioma, seleccione Ir al recurso para ver y administrar claves.
- Creación de un recurso de Voz en Azure Portal.
- Obtenga la clave y la región del recurso de Voz. Una vez implementado el recurso de Voz, seleccione Ir al recurso para ver y administrar claves.
Configuración del entorno
El SDK de Voz está disponible como paquete NuGet e implementa .NET Standard 2.0. La instalación del SDK de Voz se describe en una sección más adelante de esta guía; primero consulte la SDK installation guide, (guía de instalación del SDK), para conocer otros requisitos.
Establecimiento de variables de entorno
En este ejemplo se requieren variables de entorno denominadas LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY y SPEECH_REGION.
La aplicación debe autenticarse para acceder a los recursos de servicios de Azure AI. Este artículo le muestra cómo utilizar variables de entorno para almacenar sus credenciales. A continuación, puede acceder a las variables de entorno desde el código para autenticar la aplicación. Para producción, use una manera más segura de almacenar y acceder a sus credenciales.
Importante
Se recomienda la autenticación de Microsoft Entra ID con identidades administradas para los recursos de Azure para evitar almacenar credenciales con sus aplicaciones que se ejecutan en la nube.
Si usa una clave de API, almacénela de forma segura en otro lugar, como en Azure Key Vault. No incluya la clave de API directamente en el código ni la exponga nunca públicamente.
Para más información sobre la seguridad de los servicios de AI, consulte Autenticación de solicitudes a los servicios de Azure AI.
Para establecer las variables de entorno, abra una ventana de consola y siga las instrucciones correspondientes a su sistema operativo y entorno de desarrollo.
- Para establecer la variable de entorno
LANGUAGE_KEY, reemplaceyour-language-keypor una de las claves del recurso. - Para establecer la variable de entorno
LANGUAGE_ENDPOINT, reemplaceyour-language-endpointpor una de las regiones del recurso. - Para establecer la variable de entorno
SPEECH_KEY, reemplaceyour-speech-keypor una de las claves del recurso. - Para establecer la variable de entorno
SPEECH_REGION, reemplaceyour-speech-regionpor una de las regiones del recurso.
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Nota:
Si solo necesita acceder a la variable de entorno en la consola que se está ejecutando en este momento, puede establecer la variable de entorno con set en vez de con setx.
Después de agregar la variable de entorno, puede que tenga que reiniciar todos los programas en ejecución que necesiten leer la variable de entorno, incluida la ventana de consola. Por ejemplo, si usa Visual Studio como editor, reinícielo antes de ejecutar el ejemplo.
Creación de un proyecto de reconocimiento del lenguaje conversacional
Una vez que tenga un recurso de Lenguaje creado, cree un proyecto de reconocimiento del lenguaje conversacional en Language Studio. Un proyecto es un área de trabajo para compilar modelos de Machine Learning personalizados basados en los datos. A su proyecto solo puede acceder usted y otros usuarios que tengan acceso al recurso de idioma que se usa.
Vaya a Language Studio e inicie sesión con su cuenta de Azure.
Creación de un proyecto de reconocimiento del lenguaje conversacional
Para este inicio rápido, puede descargar este proyecto de automatización del hogar de ejemplo e importarlo. Este proyecto puede predecir las órdenes previstas a partir de la entrada del usuario, como encender y apagar las luces.
En la sección Descripción de preguntas y lenguaje conversacional de Language Studio, seleccione Reconocimiento del lenguaje conversacional.
Esto lo llevará a la página Proyectos de reconocimiento del lenguaje conversacional. Junto al botón Crear nuevo proyecto, seleccione Importar.
En la ventana que aparece, cargue el archivo JSON que desea importar. Asegúrese de que el archivo sigue el formato JSON admitido.
Una vez completada la carga, llegará a la página Definición de esquema. En este inicio rápido, el esquema ya está compilado y las expresiones ya están etiquetadas con intenciones y entidades.
Entrenamiento de un modelo
Por lo general, después de crear un proyecto, debe compilar un esquema y expresiones de etiqueta. En este inicio rápido, ya importamos un proyecto listo con esquema compilado y expresiones etiquetadas.
Para entrenar un modelo, debe iniciar un trabajo de entrenamiento. La salida de un trabajo de entrenamiento correcto es el modelo entrenado.
Para empezar a entrenar el modelo desde Language Studio:
Seleccione Entrenar modelo en el menú de la izquierda.
Seleccione Iniciar un trabajo de entrenamiento en el menú superior.
Seleccione Entrenar un nuevo modelo y escriba el nombre del nuevo modelo en el cuadro de texto. De lo contrario, para reemplazar un modelo existente por un modelo entrenado en los nuevos datos, seleccione Sobrescribir un modelo existente y, a continuación, seleccione un modelo existente. La sobrescritura de un modelo entrenado es irreversible, pero no afectará a los modelos implementados hasta que implemente el nuevo modelo.
Seleccionar datos de entrenamiento. Puede elegir Entrenamiento estándar para un entrenamiento más rápido, pero solo está disponible para inglés. También puede elegir Formación avanzada compatible con otros idiomas y proyectos multilingües, pero implica tiempos de entrenamiento más largos. Más información sobre los modos de entrenamiento.
Seleccione un método de división de datos. Puede elegir Dividir automáticamente el conjunto de pruebas de los datos de entrenamiento, y el sistema dividirá las expresiones entre los conjuntos de entrenamiento y pruebas, según los porcentajes especificados. También puede usar una división manual de datos de entrenamiento y pruebas; esta opción solo se habilita si han agregado expresiones al conjunto de pruebas al etiquetar las expresiones.
Seleccione el botón Entrenar.
Seleccione el identificador del trabajo de entrenamiento de la lista. Aparecerá un panel en el que podrá comprobar el progreso del entrenamiento, el estado del trabajo y otros detalles de este trabajo.
Nota
- Los trabajos de entrenamiento completados correctamente serán los únicos que generarán modelos.
- El entrenamiento puede durar entre un par de minutos y un par de horas en función del número de expresiones.
- Solo puede haber un trabajo de entrenamiento ejecutándose en un momento dado. No se pueden iniciar otros trabajos de entrenamiento dentro del mismo proyecto hasta que se complete el trabajo en ejecución.
- El aprendizaje automático que se usa para entrenar modelos se actualiza periódicamente. Para entrenar en una versión de configuración anterior, seleccione Seleccione aquí para cambiar en la página Iniciar un trabajo de entrenamiento y elija una versión anterior.
Implementación del modelo
Por lo general, después de entrenar un modelo, revisaría sus detalles de evaluación. En este inicio rápido, solo implementará el modelo y lo tendrá disponible para probarlo en Language Studio, o bien puede llamar a la API de predicción.
Para implementar el modelo desde Language Studio:
Seleccione Implementación de un modelo en el menú de la izquierda.
Seleccione Agregar implementación para iniciar el asistente Agregar implementación.
Seleccione Crear un nuevo nombre de implementación para crear una nueva implementación y asignar un modelo entrenado de la lista desplegable siguiente. De lo contrario, puede seleccionar Sobrescribir un nombre de implementación existente para reemplazar eficazmente el modelo usado por una implementación existente.
Nota:
La sobrescritura de una implementación existente no requiere cambios en la llamada de la API de predicción, pero los resultados que obtendrá se basarán en el modelo recién asignado.
Seleccione un modelo entrenado de la lista desplegable Modelo.
Seleccione Implementar para iniciar el trabajo de implementación.
Después de que la implementación se realice correctamente, aparecerá una fecha de expiración junto a ella. La expiración de la implementación aparece cuando el modelo implementado deja de estar disponible para usarlo en la predicción, lo que suele ocurrir doce meses después de que expire una configuración de entrenamiento.
Usará el nombre del proyecto y el nombre de la implementación en la sección siguiente.
Reconocimiento de intenciones de un micrófono
Siga estos pasos para crear una nueva aplicación de consola e instalar el SDK de Voz.
Cree un proyecto de consola de C++ en Visual Studio Community 2022 denominado
SpeechRecognition.Instale el SDK de Voz en el nuevo proyecto con el administrador de paquetes NuGet.
Install-Package Microsoft.CognitiveServices.SpeechReemplace el contenido de
SpeechRecognition.cpppor el código siguiente:#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; using namespace Microsoft::CognitiveServices::Speech::Intent; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" auto languageKey = GetEnvironmentVariable("LANGUAGE_KEY"); auto languageEndpoint = GetEnvironmentVariable("LANGUAGE_ENDPOINT"); auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); auto cluProjectName = "YourProjectNameGoesHere"; auto cluDeploymentName = "YourDeploymentNameGoesHere"; if ((size(languageKey) == 0) || (size(languageEndpoint) == 0) || (size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY, and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto intentRecognizer = IntentRecognizer::FromConfig(speechConfig, audioConfig); std::vector<std::shared_ptr<LanguageUnderstandingModel>> models; auto cluModel = ConversationalLanguageUnderstandingModel::FromResource( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); models.push_back(cluModel); intentRecognizer->ApplyLanguageModels(models); std::cout << "Speak into your microphone.\n"; auto result = intentRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedIntent) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; std::cout << " Intent Id: " << result->IntentId << std::endl; std::cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl; } else if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you update the subscription info?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }En
SpeechRecognition.cpp, establezca las variablescluProjectNameycluDeploymentNameen los nombres del proyecto y la implementación. Para obtener información sobre cómo crear un proyecto de CLU y una implementación, consulte Creación de un proyecto de reconocimiento del lenguaje conversacional.Para cambiar el idioma de reconocimiento de voz, reemplace
en-USpor otroen-US. Por ejemplo,es-ESpara Español (España). El idioma predeterminado esen-USsi no especifica un idioma. Para obtener más información sobre cómo identificar uno de los distintos idiomas que se pueden hablar, consulte Identificación del idioma.
Compile y ejecute la nueva aplicación de consola para iniciar el reconocimiento de voz a través de un micrófono.
Importante
Asegúrese de establecer las variables de entorno LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY y SPEECH_REGION como se ha descrito anteriormente. Si no establece estas variables, se producirá un fallo en el ejemplo, con un mensaje de error.
Hable por el micrófono cuando se le solicite. Lo que diga debe devolverse como texto:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
Nota
Se agregó compatibilidad con la respuesta JSON para CLU a través de la propiedad LanguageUnderstandingServiceResponse_JsonResult en la versión 1.26 del SDK de voz.
Las intenciones se devuelven en un orden de mayor a menor probabilidad. A continuación se muestra una versión con formato de la salida JSON donde el topIntent es HomeAutomation.TurnOn con una puntuación de confianza de 0,97712576 (97,71 %). La segunda intención más probable podría ser HomeAutomation.TurnOff, con una puntuación de confianza de 0,8985081 (84,31 %).
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
Comentarios
Ahora que ha completado el artículo de inicio rápido, estas son algunas consideraciones adicionales:
- En este ejemplo se usa la operación
RecognizeOnceAsyncpara transcribir expresiones de hasta 30 segundos, o hasta que se detecta el silencio. Para obtener información sobre el reconocimiento continuo de audio más largo, incluidas las conversaciones en varios idiomas, consulte Reconocimiento de voz. - Para reconocer la voz de un archivo de audio, use
FromWavFileInputen lugar deFromDefaultMicrophoneInput:auto audioInput = AudioConfig::FromWavFileInput("YourAudioFile.wav"); - Para archivos de audio comprimidos como MP4, instale GStreamer y utilice
PullAudioInputStreamoPushAudioInputStream. Para más información, consulte Uso de entradas de audio comprimido.
Limpieza de recursos
Puede usar Azure Portal o la Interfaz de la línea de comandos (CLI) de Azure para quitar los recursos de Lenguaje y Voz que creó.
Documentación de referencia | Ejemplos adicionales en GitHub
El SDK de Voz para Java no admite el reconocimiento de intenciones con reconocimiento del lenguaje conversacional (CLU). Seleccione otro lenguaje de programación o la referencia de Java y los ejemplos vinculados desde el principio de este artículo.